目录
文章目录
前言
1. 树的概念及结构
1.1 树的概念
1.2 树的基础概念
1.3 树的表示
1.4 树的应用
2. 二叉树
2.1 二叉树的概念
2.2 二叉树的遍历
前言
在计算机科学中,数据结构是解决问题的关键。而二叉树作为最基本、最常用的数据结构之一,不仅在算法和数据处理中发挥着重要作用,也在日常生活中有着丰富的应用。无论是搜索引擎的索引算法、文件系统的组织方式,还是编译器的语法分析,二叉树都扮演着不可或缺的角色。为了便于大家更好的入门二叉树,本期先向大家简单介绍一下二叉树的基本性质,以及代码理解实现,给大家预预热。
1. 树的概念及结构
1.1 树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
- 有一个特殊的结点,称为根结点,根节点没有前驱结点
- 除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i<= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继
- 因此,树是递归定义的。
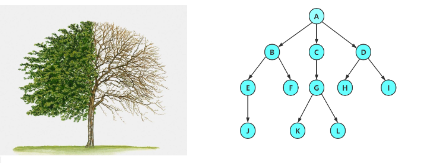
那这样是树还是非树?
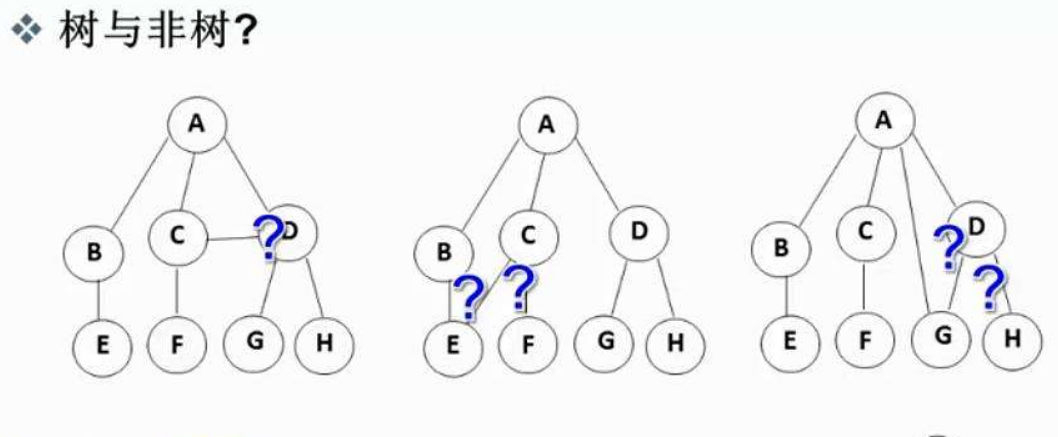
答案是非树,树形结构中,子树之间不能有交集,否则就不是树形结构。
1.2 树的基础概念
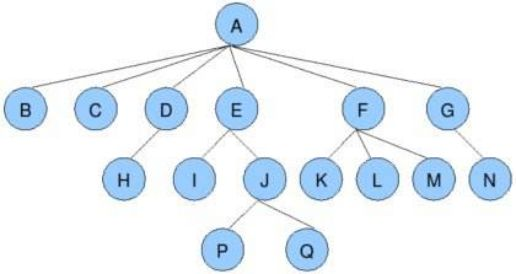
- 节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的为6
- 叶节点或终端节点:度为0的节点称为叶节点; 如上图:B、C、H、I...等节点为叶节点
- *非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G...等节点为分支节点
- 双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
- 兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
- 树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6
- *节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- *树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
- *堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
- *节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
- *子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
- *森林:由m(m>0)棵互不相交的树的集合称为森林;
带星号的了解即可。
这里我们重点说一下树的高度和节点层次,不同的数据结构书中一般有两种方式表示树的高度,一种是从0开始例如上述的树,根节点A高度就是0,到P、Q高度就是3。另外一种是从1开始,根节点1的高度为1,那P、Q的高度就是4。个人更推荐使用从1开始的,如果使用从0开始的,那如果是空树,在使用0表示就有点说不过去了,那空树的高度就只能是-1了。如果使用从1开始的,那空树就可以使用0来表示。
1.3 树的表示
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,既然保存值域,也要保存结点和结点之间的关系,实际中树有很多种表示方式如:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法等。
首先在定义树的节点时就很为难,一个节点到底要定义多少个指向子节点的指针:
struct TreeNode
{
Datatype x;
struct TreeNode* child1;
struct TreeNode* child2;
……
};要想定义一个节点就要先知道一个树的度,例如上述的树:
这棵树的度为6,那我们定义时就要定义6个指针变量吗?那大部分的节点的子节点并没有达到6个,这样就会很浪费,定义也很费劲。
在C++中,有这样一种定义方法:
struct TreeNode
{
Datatype x;
vector<struct TreeNode*> childs;
};可以不规定个数,它使用数组的方式来存储,如果不够还可以进行增容,这种方式是使用顺序表来存储孩子节点的信息。
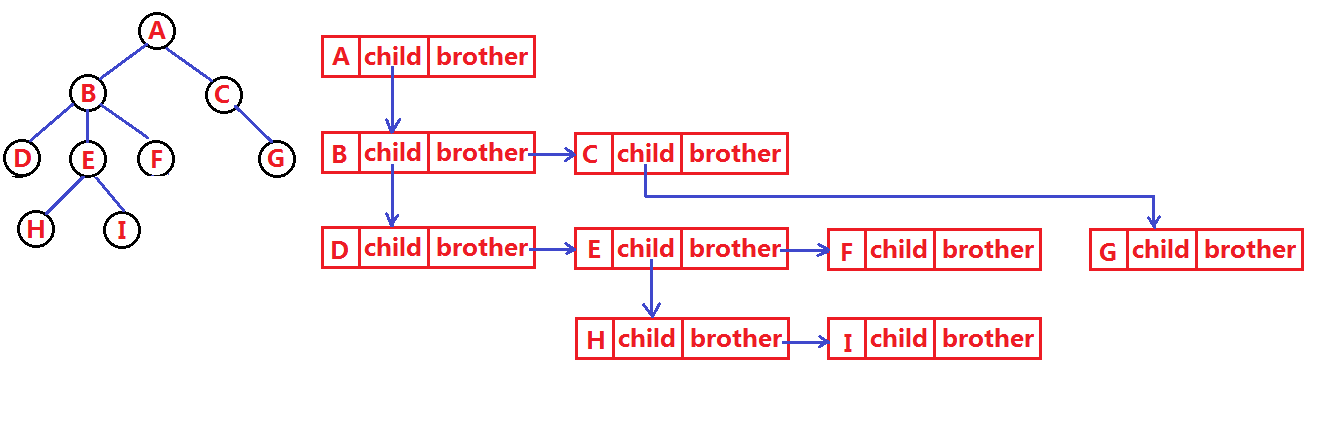
还有一种非常巧的方式,叫孩子兄弟表示法,即左孩子右兄弟。
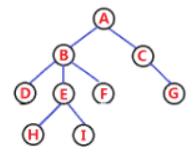
拿这棵树为例,这种方法在定义节点时就只定义两个指针,一个指针叫左孩子指针,一个指针叫右兄弟指针。怎么指向呢?就是说无论一个节点有多少个孩子,它的孩子指针就只指向第一个孩子(最左边的孩子节点),剩下的孩子用第一个孩子的兄弟指针指向第二个,第二个孩子的兄弟指针指向第三个。
表示出来就是这样的结构:
 除此之外还有其他的表示法,这里就不再一一列举。
除此之外还有其他的表示法,这里就不再一一列举。
1.4 树的应用
在现实生活中我们也经常使用到树状结构,例如:文件存储
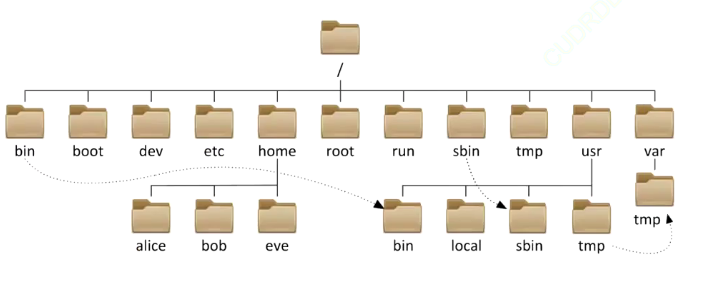
2. 二叉树
了解完树的基本概念后,我们接下来进入二叉树的学习。
2.1 二叉树的概念
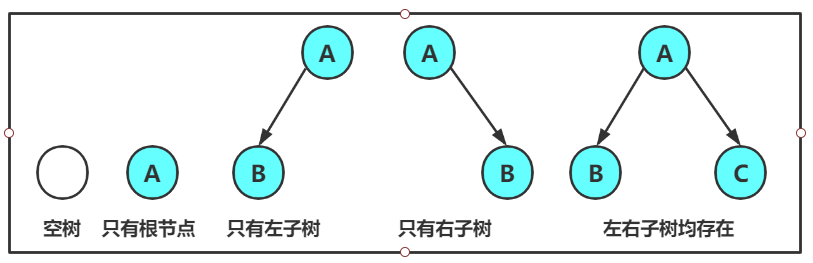
一棵二叉树是结点的一个有限集合,该集合:
- 或者为空
- 由一个根节点加上两棵别称为左子树和右子树的二叉树组成
二叉树的特点:
- 二叉树不存在度大于2的结点
- 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
对于任何一颗二叉树都是由一下几种情况复合而成。
当然关于二叉树的基础概念还有很多,今天就先简单介绍,接下来给大家来点干货,先让大家切身体验一下二叉树。
2.2 二叉树的遍历
当我们看到任何一颗二叉树都应该把它分为三个部分:
- 根节点
- 左子树
- 右子树
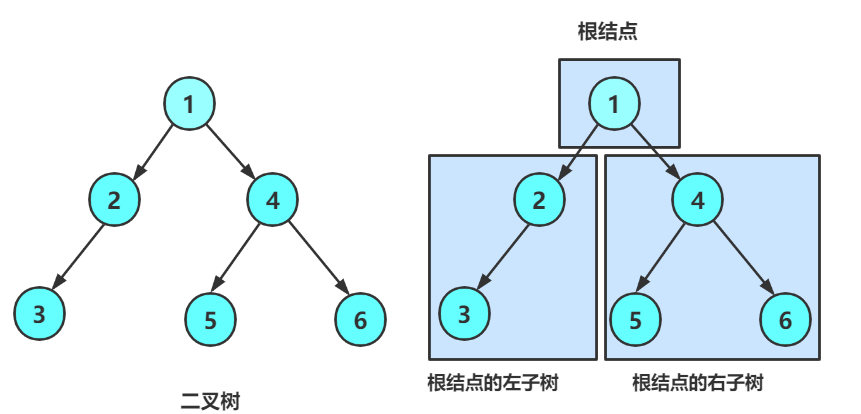
我们以这棵树为例进行分析:
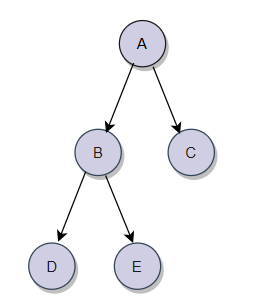
A为这棵树的根节点,B及其以下的节点(D、E)被称为左子树,C及其以下节点被称为右子树。然后B子树仍然可以分为D及其以下节点是左子树,E及其以下节点是右子树,然后再分,直到子节点为NULL,停止。
我们这里用的是分治算法。分治算法:
把大问题分成类似的子问题,子问题再分成子问题,……,直到子问题无法再分割为止。
遍历可分为三种:
前序:也叫先根遍历,遍历顺序为:根、左子树、右子树
中序:也叫中根遍历,遍历顺序为:左子树、根、右子树
后序:也叫后根遍历,遍历顺序为:左子树、右子树、根
我们先来尝试以下前序遍历,理解了前序遍历后两个就简单了。还是以这棵树为例:
前序遍历,我们是先访问根,然后是左子树、右子树。那应该先遍历A,然后遍历A的左子树B(及其以下节点),然后就以B为根继续遍历它的左子树D(及其以下节点),然后再次以D为根开始,遍历左子树(NULL),然后开始返回到D,D再遍历右子树(NULL),然后D(这个子树)就遍历完毕,返回到B,B开始遍历右子树E(及其以下节点),E左子树为NULL返回到E,然后遍历右子树,右子树也为空(E子树遍历完毕),然后返回E(B的右子树遍历完毕),接着返回B(B的所有子树遍历完毕),接着返回到A,A开始遍历右子树……这个规律很符合递归。
遍历完的顺序为:A、B、D、NULL、NULL、E、NULL、NULL、C、NULL、NULL。大部分学校讲的都是A、B、D、E、C。大部分同学应该都知道这个规律,但不知道为什么这样遍历。
根据这个思路我们再来写一下中序遍历,中序遍历先访问左子树,然后是跟,最后是右子树。还是从A开始找,A的左子树B,然后以B为根,找B的左子树,接着以D为根,找D的左子树,D的左子树为NULL(D左子树遍历结束),返回到D(根),开始遍历D的右子树……
最后遍历的顺序为:【NULL、D、NULL(B的左子树)、B(根)、NULL、E、NULL (B的右子树)、】(A的左子树)、A(根)、【NULL、C、NULL】(A的右子树)。整理一下:
NULL、D、NULL、B、NULL、E、NULL、A、NULL、C、NULL(D、B、E、C、A)。
我们接着写一下后序遍历:NULL、NULL、D、NULL、NULL、E、B、NULL、NULL、C、A(D、E、B、C、A)。
我们再来练一个:
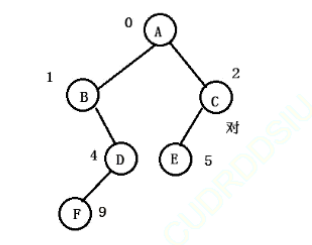
前序遍历:A(根)||这部分为整体二叉树的根、B(左子树)、NULL(B的左子树)、D(B的右子树)、F(D的左子树)、NULL(F的左子树)、NULL(F的右子树)、NULL(D的右子树)||这部分属于A的左子树、C、E、NULL(E的左子树)、NULL(E的右子树)、NULL(C的右子树)||这部分为A的右子树。
后续的中序遍历和后续遍历大家可以自己私下练一下。
好了我们已经了解了遍历,接下来我们来说实现以下前序遍历。给大家来点干货,便于大家更好理解。
我们依然以这个简单的二叉树为例进行实现。
我们先定义一个二叉树的节点:
typedef char Datatype;
typedef struct BinaryTreeNode
{
Datatype data;
struct BinaryTreeNode* left;
struct BinaryTreeNode* right;
}BTNode;
然后就是它的前序遍历的实现:
void PrevOrder(BTNode* root)
{
}我们知道前序遍历的顺序是根,然后是左子树,最后是右子树。因此在开始前我们先判断以下root是否为NULL,如果不为NULL我们就打印根节点的数据。
void PrevOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
printf("%c ", root->data);
}那如何遍历到左子树、右子树呢?其实很简单,我们之前介绍的时候说:二叉树的遍历复合递归结构,这里我们就可以使用递归来完成遍历,代码如下:
void PrevOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
printf("%c ", root->data);
PrevOrder(root->left);
PrevOrder(root->right);
}先遍历左子树,再遍历右子树,那调用的顺序就先调用自己传左孩子指针过去,以左孩子节点为根,再按照这个程序进行执行,再次传左孩子指针过去……,知道左孩子为NULL,返回上一层,开始遍历右子树。
我们可以简单粗暴的测试以下,测试代码如下:
#include<stdio.h>
#include<stdlib.h>
typedef char Datatype;
typedef struct BinaryTreeNode
{
Datatype data;
struct BinaryTreeNode* left;
struct BinaryTreeNode* right;
}BTNode;
void PrevOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
printf("%c ", root->data);
PrevOrder(root->left);
PrevOrder(root->right);
}
int main()
{
BTNode* A = (BTNode*)malloc(sizeof(BTNode));
A->data = 'A';
A->left = NULL;
A->right = NULL;
BTNode* B = (BTNode*)malloc(sizeof(BTNode));
B->data = 'B';
B->left = NULL;
B->right = NULL;
BTNode* C = (BTNode*)malloc(sizeof(BTNode));
C->data = 'C';
C->left = NULL;
C->right = NULL;
BTNode* D = (BTNode*)malloc(sizeof(BTNode));
D->data = 'D';
D->left = NULL;
D->right = NULL;
BTNode* E = (BTNode*)malloc(sizeof(BTNode));
E->data = 'E';
E->left = NULL;
E->right = NULL;
A->left = B;
A->right = C;
B->left = D;
B->right = E;
PrevOrder(A);
printf("\n");
return 0;
}执行结果:

和上述分析的结果一致。
那剩下的中序遍历和后序遍历也很简单,只需要改变一下递归调用函数的次序即可:
//中序遍历
void InOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
InOrder(root->left);
printf("%c ", root->data);
InOrder(root->right);
}
//后序遍历
void PostOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
PostOrder(root->left);
PostOrder(root->right);
printf("%c ", root->data);
}我们也可以测试以下看看执行结果,测试代码如下:
typedef struct BinaryTreeNode
{
Datatype data;
struct BinaryTreeNode* left;
struct BinaryTreeNode* right;
}BTNode;
void PrevOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
printf("%c ", root->data);
PrevOrder(root->left);
PrevOrder(root->right);
}
void InOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
InOrder(root->left);
printf("%c ", root->data);
InOrder(root->right);
}
void PostOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
PostOrder(root->left);
PostOrder(root->right);
printf("%c ", root->data);
}
int main()
{
BTNode* A = (BTNode*)malloc(sizeof(BTNode));
A->data = 'A';
A->left = NULL;
A->right = NULL;
BTNode* B = (BTNode*)malloc(sizeof(BTNode));
B->data = 'B';
B->left = NULL;
B->right = NULL;
BTNode* C = (BTNode*)malloc(sizeof(BTNode));
C->data = 'C';
C->left = NULL;
C->right = NULL;
BTNode* D = (BTNode*)malloc(sizeof(BTNode));
D->data = 'D';
D->left = NULL;
D->right = NULL;
BTNode* E = (BTNode*)malloc(sizeof(BTNode));
E->data = 'E';
E->left = NULL;
E->right = NULL;
A->left = B;
A->right = C;
B->left = D;
B->right = E;
printf("前序遍历:");
PrevOrder(A);
printf("\n");
printf("中序遍历:");
InOrder(A);
printf("\n");
printf("后序遍历:");
PostOrder(A);
printf("\n");
return 0;
}执行结果如下:

可以和上边的分析对比一下,没有问题,
总结
二叉树遍历是学习和理解二叉树的重要部分。通过遍历,我们可以按照特定的顺序访问二叉树的节点,从而深入了解它们的结构和关系。在这篇博客中,我们介绍了三种常见的二叉树遍历方式:前序遍历、中序遍历和后序遍历,并对它们的原理、特点和应用进行了详细讨论。本期内容为预热阶段,先让大家熟悉一下二叉树,以便于后续二叉树的学习,好的本期内容到此结束,感谢阅读!