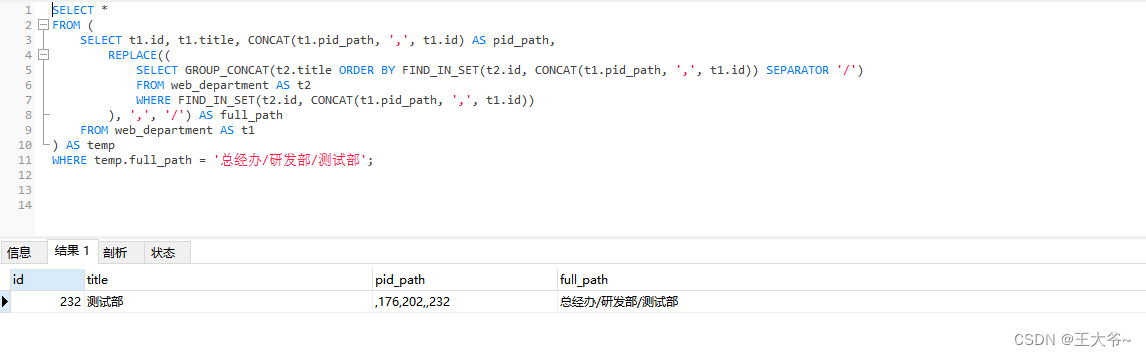
一、功能展示:
效果如图:

DB连接配置维护:


Schema功能:集成Screw生成文档,导出库的表结构,导出表结构和数据


表对象操作:翻页查询,查看创建SQL,生成代码
可以单个代码文件下载,也可以全部下载(打成zip包下载返回)
可以自定义文件名称,包路径和代码信息



二、实现过程
一开始只是想实现若依的生成代码功能:

然后我发现若依的这个只能使用SpringBoot配置的单例数据源
实际上来说应该可以像Navicat一样配置多个连接访问多个数据源
1、解决数据源问题
开动态数据源太麻烦了,我只是针对这个功能需要动态访问,所以第一步要解决的是访问DB的问题
在默认数据源下建了一张连接配置表来维护:
CREATE TABLE `db_conn` (
`id` int NOT NULL AUTO_INCREMENT,
`conn_name` varchar(32) COLLATE utf8mb4_general_ci NOT NULL,
`username` varchar(32) COLLATE utf8mb4_general_ci NOT NULL,
`password` varchar(32) COLLATE utf8mb4_general_ci NOT NULL,
`host` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`port` varchar(6) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`creator` varchar(24) COLLATE utf8mb4_general_ci DEFAULT NULL,
`updater` varchar(24) COLLATE utf8mb4_general_ci DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unq_idx_conn_name` (`conn_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;除了Mybatis,轻量级的操作工具类我选择了Hutool的DB操作
使用容器对象保管使用的数据源,每次动态操作都需要从容器存取
package cn.cloud9.server.tool.ds;
import cn.cloud9.server.struct.constant.ResultMessage;
import cn.cloud9.server.struct.file.FileProperty;
import cn.cloud9.server.struct.file.FileUtil;
import cn.cloud9.server.struct.spring.SpringContextHolder;
import cn.cloud9.server.struct.util.Assert;
import cn.cloud9.server.struct.util.DateUtils;
import cn.hutool.core.io.IoUtil;
import cn.hutool.db.Db;
import cn.hutool.db.Entity;
import cn.hutool.db.Page;
import cn.hutool.db.PageResult;
import com.alibaba.druid.pool.DruidDataSource;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.context.annotation.Lazy;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import javax.sql.DataSource;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.sql.SQLException;
import java.time.LocalDateTime;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
@Lazy
@Slf4j
@Service("dbConnService")
public class DbConnServiceImpl extends ServiceImpl<DbConnMapper, DbConnDTO> implements IDbConnService {
/* 数据源管理容器 */
private static final Map<Integer, DataSource> dsContainer = new ConcurrentHashMap<>();
private static final DbConnMapper dbConnMapper = SpringContextHolder.getBean("dbConnMapper", DbConnMapper.class);
/**
* 获取数据源对象的方法 (所有的接口操作都需要经过这个步骤)
* @param dbId 连接参数实体ID
* @return 参数对应的数据源对象
*/
public static DataSource getDsById(Integer dbId) {
DataSource dataSource = dsContainer.get(dbId);
boolean isEmpty = Objects.isNull(dataSource);
if (isEmpty) {
DbConnDTO dbConn = dbConnMapper.selectById(dbId);
Assert.isTrue(Objects.isNull(dbConn), ResultMessage.NOT_FOUND_ERROR, "连接配置");
DruidDataSource druidDs = new DruidDataSource();
druidDs.setUrl("jdbc:mysql://" + dbConn.getHost() + ":" + dbConn.getPort() + "/sys");
druidDs.setUsername(dbConn.getUsername());
druidDs.setPassword(dbConn.getPassword());
druidDs.addConnectionProperty("useInformationSchema", "true");
druidDs.addConnectionProperty("characterEncoding", "utf-8");
druidDs.addConnectionProperty("useSSL", "false");
druidDs.addConnectionProperty("serverTimezone", "UTC");
druidDs.addConnectionProperty("useAffectedRows", "true");
dataSource = druidDs;
/* 置入容器 */
dsContainer.put(dbId, druidDs);
}
return dataSource;
}
}2、界面信息的获取
只要有访问 information_schema 的权限就可以获取db的大部分信息了
【后面什么触发器,视图都没写,只是列在那留个坑以后来填】
就是hutool的翻页用的人很少没什么资料,我这里是自己看API注释琢磨的写的
这个pageResult我一开始以为和mp的page对象一样,结果发现是继承了ArrayList,序列化之后输出的只有结果集合,没有翻页的信息
所以要自己提取出来,他会算好放在里面
Entity就理解为一个Map对象,返回就是存键值对,按键值对取就行了,也可以作为SQL查询条件的封装对象
@SuppressWarnings("all")
@Override
public IPage<Entity> getTablePage(Integer dbId, String schemaName, DbTableDTO dto) throws SQLException {
Db db = Db.use(getDsById(dbId));
Entity condition = Entity.create();
condition.setTableName("`information_schema`.`TABLES`");
condition.set("`TABLE_TYPE`", "BASE TABLE");
condition.set("`TABLE_SCHEMA`", schemaName);
if (StringUtils.isNotBlank(dto.getTableName()))
condition.put("`TABLE_NAME`", "LIKE '%" + dto.getTableName() + "%'");
if (StringUtils.isNotBlank(dto.getTableComment()))
condition.put("`TABLE_COMMENT`", "LIKE '%" + dto.getTableComment() + "%'");
if (StringUtils.isNotBlank(dto.getStartCreateTime()) && StringUtils.isNotBlank(dto.getEndCreateTime())) {
condition.put("`CREATE_TIME`", "BETWEEN '" + dto.getStartCreateTime() + "' AND '" + dto.getEndCreateTime() + "'");
}
IPage<Entity> page = dto.getPage();
PageResult<Entity> pageResult = db.page(condition, new Page((int)page.getCurrent() - 1, (int)page.getSize()));
page.setRecords(pageResult);
page.setTotal(pageResult.getTotal());
page.setPages(pageResult.getTotalPage());
return page;
}3、生成代码的思路
生成这种模板文件肯定是用模板引擎来做的,若依用的是velocity好像,那我这里就还是用freemarker,因为对freemarker接触的多一点
这还外加了一个starter,不过我没怎么用到,有原始支持包就行了
<!-- https://mvnrepository.com/artifact/org.freemarker/freemarker -->
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.32</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-freemarker</artifactId>-->
<!-- </dependency>-->先写好模板文件,里面标记的变量名称,FreeMarker会通过一个Map参数去取出来打在模板文件里渲染

我先开了一个简单的测试Controller检查生成情况:
package cn.cloud9.server.test.controller;
import cn.cloud9.server.struct.common.BaseController;
import cn.cloud9.server.struct.file.FileUtil;
import cn.cloud9.server.struct.util.DateUtils;
import freemarker.cache.FileTemplateLoader;
import freemarker.cache.TemplateLoader;
import freemarker.template.Configuration;
import freemarker.template.Template;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.BufferedWriter;
import java.io.File;
import java.io.OutputStreamWriter;
import java.io.Writer;
import java.nio.charset.StandardCharsets;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
@RestController
@RequestMapping("/test/ftl")
public class TemplateTestController extends BaseController {
@GetMapping("/getTemplate")
public void getCodeFile() throws Exception {
Map<String, Object> paramMap = new ConcurrentHashMap<>();
paramMap.put("modelPath", "cn.cloud9.sever.test.model");
paramMap.put("author", "cloud9");
paramMap.put("tableName", "info_account");
paramMap.put("description", "测试模板代码生成");
paramMap.put("projectName", "tt-server");
paramMap.put("dateTime", DateUtils.format(LocalDateTime.now(), DateUtils.DEFAULT_DATE_TIME_FORMAT));
paramMap.put("modelName", "InfoAccount");
List<Map<String, String>> columns = new ArrayList<>();
Map<String, String> field1 = new ConcurrentHashMap<>();
field1.put("columnName", "id");
field1.put("fieldName", "id");
field1.put("type", "Integer");
columns.add(field1);
Map<String, String> field2 = new ConcurrentHashMap<>();
field2.put("columnName", "field_2");
field2.put("fieldName", "field2");
field2.put("type", "String");
columns.add(field2);
paramMap.put("columns", columns);
String path = this.getClass().getResource("/code-template").getFile();
File file = new File(path);
Configuration config = new Configuration();
TemplateLoader loader = new FileTemplateLoader(file);
config.setTemplateLoader(loader);
Template template = config.getTemplate("/java/Model.java.ftl", "UTF-8");
FileUtil.setDownloadResponseInfo(response, "TestDTO.java");
Writer out = new BufferedWriter(new OutputStreamWriter(response.getOutputStream(), StandardCharsets.UTF_8));
template.process(paramMap, out);
out.flush();
out.close();
}
}模板文件内容:
package ${modelPath};
import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.util.Date;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.EqualsAndHashCode;
/**
* @author ${author}
* @description ${tableName} 实体类 ${modelDescription!}
* @project ${projectName}
* @date ${dateTime}
*/
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("${tableName}")
public class ${modelName} {
<#list columns as column>
@TableField("${column.columnName}")
private ${column.type} ${column.fieldName};
</#list>
@TableField(exist = false)
private Page<${modelName}> page;
}然后要解决输出文件和输出内容的两个方式:
两个方法基本是一样的,就是输出对象不一样,一个流,一个Writter
/**
* 下载模板生成文件
* @param response 响应对象
* @param tp 模板参数
* @throws Exception IO异常
*/
public void downloadTemplateFile(HttpServletResponse response, TemplateParam tp) throws Exception {
TemplateType tt = tp.getTemplateTypeByCode();
tp.setDateTime();
if (TemplateType.MODEL.equals(tt)) getColumnsMetaData(tp);
Assert.isTrue(TemplateType.NONE.equals(tt), ResultMessage.NOT_FOUND_ERROR, "模板类型编号");
Map<String, Object> paramMap = BeanUtil.beanToMap(tp);
Template template = configuration.getTemplate(tt.getPath(), "UTF-8");
FileUtil.setDownloadResponseInfo(response, paramMap.get(tt.getFilenameKey()) + tt.getSuffix());
Writer out = new BufferedWriter(new OutputStreamWriter(response.getOutputStream(), StandardCharsets.UTF_8));
/* 输出成型的文件 */
template.process(paramMap, out);
out.flush();
out.close();
}
/**
* 获取模板生成的输出内容
* @param tp 模板参数
* @return 输出内容
* @throws Exception IO异常
*/
public String getTemplateContent(TemplateParam tp, TemplateType tt) throws Exception {
tp.setDateTime();
if (TemplateType.MODEL.equals(tt)) getColumnsMetaData(tp);
Assert.isTrue(TemplateType.NONE.equals(tt), ResultMessage.NOT_FOUND_ERROR, "模板类型编号");
Map<String, Object> paramMap = BeanUtil.beanToMap(tp);
Template template = configuration.getTemplate(tt.getPath(), "UTF-8");
/* 代替方法 String content = FreeMarkerTemplateUtils.processTemplateIntoString(template, paramMap); */
StringWriter result = new StringWriter(1024);
template.process(paramMap, result);
return result.toString();
}下载全部文件,返回的是zip包,就要先把文件在服务器上创建好打包返回,然后再删除缓存的文件:
/**
* 下载全部模板文件
* @param response
* @param tp
*/
public void downloadAllTemplateFile(HttpServletResponse response, TemplateParam tp) throws Exception {
final String cachePath = fileProperty.getBaseDirectory() + ROOT_PATH;
File file = new File(cachePath);
if (!file.exists()) file.mkdirs();
List<TemplateType> templateTypes = TemplateType.getAvailableTypes();
List<File> cacheFiles = new ArrayList<>(templateTypes.size());
for (TemplateType templateType : templateTypes) {
/* 获取输出的文件名 */
String fileName = ReflectUtil.getFieldValue(tp, templateType.getFilenameKey()).toString();
fileName = fileName + templateType.getSuffix();
/* 创建模板文件 */
String fullPath = cachePath + File.separator + fileName;
File templateFile = new File(fullPath);
if (!templateFile.exists()) file.createNewFile();
/* 获取输出的成型内容 */
tp.setTemplateCode(templateType.getCode());
String content = this.getTemplateContent(tp, templateType);
/* 写入本地文件 */
FileOutputStream fos = new FileOutputStream(fullPath);
fos.write(content.getBytes());
fos.close();
cacheFiles.add(templateFile);
}
/* 创建压缩文件 */
String zipFileName = cachePath + File.separator + tp.getTableName() + ".zip";
File zipFile = new File(zipFileName);
ZipUtil.zip(zipFile, false, cacheFiles.toArray(new File[]{}));
/* 给压缩文件设置信息 */
FileUtil.setDownloadResponseInfo(response, zipFile, zipFile.getName());
/* 输出压缩文件 */
BufferedInputStream in = cn.hutool.core.io.FileUtil.getInputStream(zipFile.getAbsolutePath());
ServletOutputStream os = response.getOutputStream();
IoUtil.copy(in, os, IoUtil.DEFAULT_BUFFER_SIZE);
in.close();
os.close();
/* 删除本地缓存 */
zipFile.delete();
cacheFiles.forEach(File::delete);
}上面的模板类型用枚举区分,枚举顺便存储一下模板的信息,这样取参数就方便了
一些没有写好的模板暂时设置null,逻辑就会跳过
package cn.cloud9.server.tool.template;
import lombok.Getter;
import java.util.Arrays;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
@Getter
public enum TemplateType {
/* 没有文件 */
NONE(null, null, null, null),
/* 后台文件 */
MODEL(1001, "/java/Model.java.ftl", "modelName", ".java"),
MAPPER(1002, "/java/Mapper.java.ftl", "mapperName", ".java"),
I_SERVICE(1003, "/java/IService.java.ftl", "iServiceName", ".java"),
SERVICE_IMPL(1004, "/java/ServiceImpl.java.ftl", "serviceImplName", ".java"),
CONTROLLER(1005, "/java/Controller.java.ftl", "controllerName", ".java"),
/* 前端文件 */
VUE_API(2001, "/vue/Api.js.ftl", "apiName", ".js"),
/* VUE_VIEW(2002, "/vue/View.vue.ftl", "viewName", ".vue"), */
VUE_VIEW(2002, "/vue/View.vue.ftl", null, null),
;
/* 编号和模板文件路径 */
private final Integer code;
private final String path;
private final String filenameKey;
private final String suffix;
TemplateType(Integer code, String path, String filenameKey, String suffix) {
this.code = code;
this.path = path;
this.filenameKey = filenameKey;
this.suffix = suffix;
}
/**
* 获取可用的模板类型集合
* @return List<TemplateType>
*/
public static List<TemplateType> getAvailableTypes() {
return Arrays
.stream(values())
.filter(t -> Objects.nonNull(t.code) && Objects.nonNull(t.path) && Objects.nonNull(t.filenameKey) && Objects.nonNull(t.suffix))
.collect(Collectors.toList());
}
}所有的模板参数统一用一个对象接受:
package cn.cloud9.server.tool.template;
import cn.cloud9.server.struct.util.DateUtils;
import cn.hutool.db.Entity;
import lombok.Data;
import java.time.LocalDateTime;
import java.util.List;
@Data
public class TemplateParam {
/* 注释信息部分 */
private String author;
private String projectName;
private String dateTime;
private String modelDescription;
private String mapperDescription;
private String iServiceDescription;
private String serviceImplDescription;
private String controllerDescription;
/* 包路径 */
private String modelPath;
private String mapperPath;
private String iServicePath;
private String serviceImplPath;
private String controllerPath;
/* 类名称 & 文件名 */
private String modelName;
private String mapperName;
private String iServiceName;
private String serviceImplName;
private String controllerName;
private String apiName;
/* controller接口与路径 */
private String urlPath;
/* 元数据信息 */
private Integer dbConnId;
private String schemaName;
private String tableName;
private List<Entity> columns;
/* 模板类型枚举编号 */
private Integer templateCode;
/**
* 设置当前时间
*/
public void setDateTime() {
dateTime = DateUtils.format(LocalDateTime.now(), DateUtils.DEFAULT_DATE_TIME_FORMAT);
}
public TemplateType getTemplateTypeByCode() {
return TemplateType.getAvailableTypes().stream()
.filter(tt -> tt.getCode().equals(templateCode))
.findFirst()
.orElse(TemplateType.NONE);
}
public static TemplateType getTemplateTypeByCode(Integer ttCode) {
return TemplateType.getAvailableTypes().stream()
.filter(tt -> tt.getCode().equals(ttCode))
.findFirst()
.orElse(TemplateType.NONE);
}
}解决字段列的模板参数问题:
/**
* 获取列的元数据
* @param tp
*/
private void getColumnsMetaData(TemplateParam tp) throws Exception {
Db db = Db.use(DbConnServiceImpl.getDsById(tp.getDbConnId()));
String querySql =
"SELECT\n" +
"\tCOLUMN_NAME AS `columnName`,\n" +
"\tREPLACE(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(\n" +
"\tLOWER(COLUMN_NAME), '_a','A'),'_b','B'),'_c','C'),'_d','D'),'_e','E'),'_f','F'),'_g','G'),'_h','H'),'_i','I'),'_j','J'),'_k','K'),'_l','L'),'_m','M'),'_n','N'),'_o','O'),'_p','P'),'_q','Q'),'_r','R'),'_s','S'),'_t','T'),'_u','U'),'_v','V'),'_w','W'),'_x','X'),'_y','Y'),'_z','Z') AS `fieldName`,\n" +
"\tCASE\n" +
"\t\tWHEN DATA_TYPE ='bit' THEN 'Boolean'\n" +
"\t\tWHEN DATA_TYPE ='tinyint' THEN 'Byte'\n" +
"\t\tWHEN LOCATE(DATA_TYPE, 'smallint,mediumint,int,integer') > 0 THEN 'Integer'\n" +
"\t\tWHEN DATA_TYPE = 'bigint' THEN 'Long'\n" +
"\t\tWHEN LOCATE(DATA_TYPE, 'float, double') > 0 THEN 'Double'\n" +
"\t\tWHEN DATA_TYPE = 'decimal' THEN 'BigDecimal'\n" +
"\t\tWHEN LOCATE(DATA_TYPE, 'time, date, year, datetime, timestamp') > 0 THEN 'LocalDateTime'\n" +
"\t\tWHEN LOCATE(DATA_TYPE, 'json, char, varchar, tinytext, text, mediumtext, longtext') > 0 THEN 'String'\n" +
"\tELSE 'String' END AS `type`\n" +
"FROM\n" +
"\t`information_schema`.`COLUMNS`\n" +
"WHERE\n" +
"\t`TABLE_SCHEMA` = ? \n" +
"\tAND `TABLE_NAME` = ? ";
List<Entity> entityList = db.query(querySql, tp.getSchemaName(), tp.getTableName());
tp.setColumns(entityList);
}数据类型可以用CASE WHEN 解决,但是头疼的问题是,怎么解决MySQL的下划线转驼峰处理
大部分提供的方法都是所有字母全部Replace一边,办法笨归笨,但是有效,所有我这里也是用这个办法,没有写成函数处理
但是牛逼的群友提供了一个子查询的办法来实现:
SET @target = 'ABC_DEF_gh_asdqw';
SELECT group_concat(
concat(
upper(substr(SUBSTRING_INDEX(SUBSTRING_index(@target,'_',help_topic_id+1),'_',-1) ,1,1)),
substr(lower(SUBSTRING_INDEX(SUBSTRING_index(@target,'_',help_topic_id+1),'_',-1)) ,2)
)
separator '') AS num
FROM mysql.help_topic
WHERE help_topic_id <= length(@target)-LENGTH(replace(@target,'_',''))
order by help_topic_id desc4、页面展示代码的几个功能问题:
一、展示代码块:
我看了若依源码是用了高亮JS,然后百度搜了下
"highlight.js": "^11.7.0",
"vue-highlightjs": "^1.3.3",全局注册:
/* 挂载highlightJS */
import VueHighlightJS from 'vue-highlightjs'
import 'highlight.js/styles/monokai-sublime.css'
Vue.use(VueHighlightJS)然后使用:
<pre v-loading="loadingFlag" v-highlightjs>
<code class="sql" v-text="createSQL" />
</pre>二、复制粘贴功能:
这个再vue-admin后台框架里面已经装了,而且有案例:
标签添加粘贴板指令:
<div class="dialog-bottom-bar">
<el-button v-clipboard:copy="createSQL" v-clipboard:success="clipboardSuccess" type="primary" size="mini" icon="el-icon-document">复制</el-button>
<el-button type="default" size="mini" icon="el-icon-close" @click="closeDialog">取消</el-button>
</div>这里我没有全局注册,因为案例也没这么做,应该是个别功能用用
在使用的组件中导入指令并注册:
import clipboard from '@/directive/clipboard' // use clipboard by v-directive
export default {
name: 'CreateSqlView',
directives: { clipboard }
}复制成功事件绑定一个方法:
clipboardSuccess() {
this.$message.success('复制成功')
},三、扩展延申
一、集成Screw文档生成:
这个之前写过一份固定的,用读取ini配置文件方式生成的
|
|
我想反正我都解决动态数据源的问题了,干脆把文档生成集成进来正好
文档参数对象:
package cn.cloud9.server.tool.doc;
import cn.smallbun.screw.core.engine.EngineFileType;
import lombok.Data;
import java.util.List;
@Data
public class DbDocDTO {
/* 文档名称 */
private String docName;
/* 文档标题 */
private String docTitle;
/* 组织名称 */
private String organization;
/* 组织连接 */
private String organizationUrl;
private String version;
private String description;
private Integer docType; /* 1,HTML 2,WORD 3,MD */
/* 按指定的表名生成 */
private List<String> specifyTables;
/* 按指定的表前缀生成 */
private List<String> specifyTablePrefixes;
/* 按指定的表后缀生成 */
private List<String> specifyTableSuffixes;
/* 需要忽略的表名 */
private List<String> ignoreTables;
/* 需要忽略的表前缀 */
private List<String> ignoreTablePrefixes;
/* 需要忽略的表后缀 */
private List<String> ignoreTableSuffixes;
public EngineFileType getDocType() {
switch (docType) {
case 2: return EngineFileType.WORD;
case 3: return EngineFileType.MD;
default: return EngineFileType.HTML;
}
}
}文档生成逻辑,就用官方Demo随便改改参数组合就OK了
package cn.cloud9.server.tool.doc;
import cn.cloud9.server.struct.file.FileProperty;
import cn.cloud9.server.struct.file.FileUtil;
import cn.cloud9.server.tool.ds.DbConnDTO;
import cn.cloud9.server.tool.ds.DbConnMapper;
import cn.hutool.core.io.IoUtil;
import cn.smallbun.screw.core.Configuration;
import cn.smallbun.screw.core.engine.EngineConfig;
import cn.smallbun.screw.core.engine.EngineTemplateType;
import cn.smallbun.screw.core.execute.DocumentationExecute;
import cn.smallbun.screw.core.process.ProcessConfig;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.IOException;
import java.util.Collections;
@Slf4j
@Service
public class DbDocService {
@Resource
private FileProperty fileProperty;
@Resource
private DbConnMapper dbConnMapper;
/**
* 生成mysql文档
* @param dbId 连接实体
* @param schemaName 约束名
* @param dto 文档参数实体
* @param response 响应对象
* @throws IOException IO异常
*/
public void getDbSchemaDoc(Integer dbId, String schemaName, DbDocDTO dto, HttpServletResponse response) throws IOException {
Configuration config = Configuration.builder()
.organization(dto.getOrganization()) // 组织机构
.organizationUrl(dto.getOrganizationUrl()) // 组织链接
.title(dto.getDocTitle()) // 文档标题
.version(dto.getVersion()) // 版本
.description(dto.getDescription()) // 描述
.dataSource(buildDataSource(dbId, schemaName)) // 数据源
.engineConfig(buildEngineConfig(dto)) // 引擎配置
.produceConfig(buildProcessConfig(dto)) // 处理配置
.build();
new DocumentationExecute(config).execute();
/* 从服务器本地读取生成的文档文件下载 */
final String fileName = dto.getDocName() + dto.getDocType().getFileSuffix();
final File docFile = new File(fileProperty.getBaseDirectory() + File.separator + fileName);
if (!docFile.exists()) return;
FileUtil.setDownloadResponseInfo(response, docFile, fileName);
/* 下载 */
BufferedInputStream in = cn.hutool.core.io.FileUtil.getInputStream(docFile.getAbsolutePath());
ServletOutputStream os = response.getOutputStream();
long copySize = IoUtil.copy(in, os, IoUtil.DEFAULT_BUFFER_SIZE);
log.info("文档生成成功! {}bytes", copySize);
in.close();
os.close();
/* 必须要等到其他IO流使用完毕资源释放了才能操作删除 */
docFile.delete();
}
private HikariDataSource buildDataSource(Integer dbId, String schemaName) {
DbConnDTO dbConn = dbConnMapper.selectById(dbId);
// 创建 HikariConfig 配置类
HikariConfig hikariConfig = new HikariConfig();
hikariConfig.setDriverClassName("com.mysql.cj.jdbc.Driver");
hikariConfig.setJdbcUrl("jdbc:mysql://" + dbConn.getHost() + ":" + dbConn.getPort() + "/" + schemaName);
hikariConfig.setUsername(dbConn.getUsername());
hikariConfig.setPassword(dbConn.getPassword());
// 设置可以获取 tables remarks 信息
hikariConfig.addDataSourceProperty("useInformationSchema", "true");
hikariConfig.addDataSourceProperty("characterEncoding", "utf-8");
hikariConfig.addDataSourceProperty("useSSL", "false");
hikariConfig.addDataSourceProperty("serverTimezone", "UTC");
hikariConfig.addDataSourceProperty("useAffectedRows", "true");
hikariConfig.setMinimumIdle(2);
hikariConfig.setMaximumPoolSize(5);
// 创建数据源
return new HikariDataSource(hikariConfig);
}
private ProcessConfig buildProcessConfig(DbDocDTO dto) {
return ProcessConfig.builder()
// 根据名称指定表生成
.designatedTableName(CollectionUtils.isEmpty(dto.getSpecifyTables()) ? Collections.emptyList() : dto.getSpecifyTables())
// 根据表前缀生成
.designatedTablePrefix(CollectionUtils.isEmpty(dto.getSpecifyTablePrefixes()) ? Collections.emptyList() : dto.getSpecifyTablePrefixes())
// 根据表后缀生成
.designatedTableSuffix(CollectionUtils.isEmpty(dto.getSpecifyTableSuffixes()) ? Collections.emptyList() : dto.getSpecifyTableSuffixes())
// 忽略数据库中address这个表名
.ignoreTableName(CollectionUtils.isEmpty(dto.getIgnoreTables()) ? Collections.emptyList() : dto.getIgnoreTables())
// 忽略表前缀,就是db1数据库中表名是t_开头的都不生产数据库文档(t_student,t_user这两张表)
.ignoreTablePrefix(CollectionUtils.isEmpty(dto.getIgnoreTablePrefixes()) ? Collections.emptyList() : dto.getIgnoreTablePrefixes())
// 忽略表后缀(就是db1数据库中表名是_teacher结尾的都不生产数据库文档:stu_teacher)
.ignoreTableSuffix(CollectionUtils.isEmpty(dto.getIgnoreTableSuffixes()) ? Collections.emptyList() : dto.getIgnoreTableSuffixes())
.build();
}
/**
* 引擎配置创建
* @param dto 文档参数实体
* @return EngineConfig
*/
private EngineConfig buildEngineConfig(DbDocDTO dto) {
return EngineConfig.builder()
// 生成文件路径
.fileOutputDir(fileProperty.getBaseDirectory())
// 打开目录
.openOutputDir(false)
// 文件类型
.fileType(dto.getDocType())
// 文件类型
.produceType(EngineTemplateType.freemarker)
// 自定义文件名称
.fileName(dto.getDocName())
.build();
}
}Vue前端表单view:
<template>
<div>
<el-form :ref="formRef" :model="form" :rules="formRules" size="small">
<el-row :gutter="$ui.layout.gutter.g10">
<el-col :span="$ui.layout.span.two">
<el-form-item label="文件名" prop="docName">
<el-input v-model="form.docName" placeholder="文件名" clearable maxlength="32" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="文档标题" prop="docTitle">
<el-input v-model="form.docTitle" placeholder="文档标题" clearable maxlength="32" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="文档版本" prop="version">
<el-input v-model="form.version" placeholder="文档版本" clearable maxlength="32" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="文档描述" prop="description">
<el-input v-model="form.description" placeholder="文档描述" clearable maxlength="32" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="组织机构" prop="organization">
<el-input v-model="form.organization" placeholder="组织机构" clearable maxlength="32" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="组织机构链接" prop="organizationUrl">
<el-input v-model="form.organizationUrl" placeholder="组织机构链接" clearable maxlength="64" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="指定生成的表" prop="specifyTables">
<el-input v-model="form.specifyTables" placeholder="指定生成的表" clearable maxlength="128" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="指定生成的表前缀" prop="specifyTablePrefixes">
<el-input v-model="form.specifyTablePrefixes" placeholder="指定生成的表前缀" clearable maxlength="128" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="指定生成的表后缀" prop="specifyTableSuffixes">
<el-input v-model="form.specifyTableSuffixes" placeholder="指定生成的表后缀" clearable maxlength="128" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="要忽略的表" prop="specifyTables">
<el-input v-model="form.ignoreTables" placeholder="要忽略的表" clearable maxlength="128" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="要忽略的表前缀" prop="specifyTablePrefixes">
<el-input v-model="form.ignoreTablePrefixes" placeholder="要忽略的表前缀" clearable maxlength="128" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="要忽略的表后缀" prop="specifyTableSuffixes">
<el-input v-model="form.ignoreTableSuffixes" placeholder="要忽略的表后缀" clearable maxlength="128" show-word-limit />
</el-form-item>
</el-col>
<el-col :span="$ui.layout.span.two">
<el-form-item label="文件类型" prop="docType">
<el-select v-model="form.docType" placeholder="请选择" clearable style="width: 100%">
<el-option v-for="item in docTypes" :key="item.value" :label="item.label" :value="item.value" />
</el-select>
</el-form-item>
</el-col>
</el-row>
</el-form>
<div align="center">
<el-button size="mini" type="primary" icon="el-icon-check" @click="formSubmit">确定</el-button>
<el-button size="mini" type="default" plain icon="el-icon-close" @click="formCancel">取消</el-button>
</div>
</div>
</template>
<script>
import { getDbSchemaDoc } from '@/api/tt-server/tool-lib/mysql-visualize'
import { axiosDownloadFile } from '@/utils'
export default {
name: 'CreateDocView',
props: {
param: {
type: Object,
required: true,
default: () => {}
}
},
data() {
return {
formRef: 'formRefKey',
form: {
docName: '',
docTitle: '',
version: 'V1.0.0',
docType: 1,
description: '',
organization: 'OnCloud9',
organizationUrl: 'https://www.cnblogs.com/mindzone/',
/* 输出的表指定参数 */
specifyTables: '',
specifyTablePrefixes: '',
specifyTableSuffixes: '',
ignoreTables: '',
ignoreTablePrefixes: '',
ignoreTableSuffixes: ''
},
formRules: {
docName: [{ required: true, message: '请填写文件名', trigger: 'blur' }],
docTitle: [{ required: true, message: '请填写文档标题', trigger: 'blur' }],
version: [{ required: true, message: '请填写文档版本', trigger: 'blur' }],
description: [{ required: true, message: '请填写文档描述', trigger: 'blur' }],
organization: [{ required: true, message: '请填写组织机构', trigger: 'blur' }],
organizationUrl: [{ required: true, message: '请填写组织机构链接', trigger: 'blur' }],
docType: [{ required: true, message: '请选择文件类型', trigger: 'blur' }]
},
docTypes: [
{ label: 'html | .html', value: 1 },
{ label: 'word | .docx', value: 2 },
{ label: 'markdown | .md', value: 3 }
]
}
},
methods: {
formSubmit() {
this.$refs[this.formRef].validate(async(isValid) => {
if (!isValid) return
const docParam = JSON.parse(JSON.stringify(this.form))
docParam.specifyTables = docParam.specifyTables ? docParam.specifyTables.split(',') : ''
docParam.specifyTablePrefixes = docParam.specifyTablePrefixes ? docParam.specifyTablePrefixes.split(',') : ''
docParam.specifyTableSuffixes = docParam.specifyTableSuffixes ? docParam.specifyTableSuffixes.split(',') : ''
docParam.ignoreTables = docParam.ignoreTables ? docParam.ignoreTables.split(',') : ''
docParam.ignoreTablePrefixes = docParam.ignoreTablePrefixes ? docParam.ignoreTablePrefixes.split(',') : ''
docParam.ignoreTableSuffixes = docParam.ignoreTableSuffixes ? docParam.ignoreTableSuffixes.split(',') : ''
const res = await getDbSchemaDoc(this.param.dbConnId, this.param.schemaName, docParam)
axiosDownloadFile(res)
})
},
formCancel() {
this.$parent.$parent['closeAllDrawer']()
}
}
}
</script>二、实现导出SQL脚本
先看导出表结构,表结构的SQL是有SQL可以直接查询的
mysql> SHOW CREATE TABLE sys_role;
+----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| sys_role | CREATE TABLE `sys_role` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '角色主键',
`role_name` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '角色名称',
`role_value` varchar(32) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '角色值',
`creator` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '创建人',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`updater` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '更新人',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='系统角色表' |
+----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.10 sec)
但是导出数据脚本就没有,这个SQL脚本难就难在这里,于是我百度了下看看别人的思路:
然后参考了这位的:
|
|
他的办法就是从查询的结果集里面提取key和value一个个拼过去
但是我们都知道,前面的INSERT的句式是固定的,只是值动态的,所以我不太接受他这个拼的做法
因为既然是固定的东西就不应该浪费资源去反复做,一开始就拼好固定句式再加动态值就行了
1、提取表的所有字段:
SQL我就不细说过程了,直接贴:
mysql> SELECT GROUP_CONCAT(DISTINCT CONCAT('`', COLUMN_NAME, '`') ORDER BY `ORDINAL_POSITION` ASC SEPARATOR ', ') AS `fields` FROM `information_schema`.`COLUMNS` WHERE TABLE_SCHEMA = 'tt' AND TABLE_NAME = 'sys_role';
+-------------------------------------------------------------------------------------+
| fields |
+-------------------------------------------------------------------------------------+
| `id`, `role_name`, `role_value`, `creator`, `create_time`, `updater`, `update_time` |
+-------------------------------------------------------------------------------------+
通过上面的SQL你就可以直接得到SELECT要查询的字段,
再把字段用SEPARATOR的字符分割成数组,就得到结果集需要按顺序遍历提取的字段了
由于Hutool的查询默认小写处理,所以这个结果默认也小处理,顺便移除反引号(解决key取不到的问题)
/* 获取这个表的字段, 按原始定位排序, 并列为一行, 逗号空格分隔 */
Entity fieldsEntity= db.queryOne("SELECT GROUP_CONCAT(DISTINCT CONCAT('`', COLUMN_NAME, '`') ORDER BY `ORDINAL_POSITION` ASC SEPARATOR ', ') AS `fields` FROM `information_schema`.`COLUMNS` WHERE TABLE_SCHEMA = ? AND TABLE_NAME = ?", schemaName, tableName);
String fields = fieldsEntity.get("fields").toString();
String[] columns = fields.trim().toLowerCase().replaceAll("`", "").split(", ");
有前面的字段,就有了固定句式了
| 1 2 |
|
再通过翻页查询,动态组装值就可以了
如果值是NULL,就写NULL,数值和时间都可以是字符型来存
/**
* 翻页查询来组装INSERT脚本 缓解IO压力
* @param builder 脚本组装对象
* @param db sql执行对象
* @param schemaName 库名
* @param tableName 表明
* @param insertSqlPrePart INSERT前半部分
* @param columns 列名数组
*/
public void batchBuildInsertSql(StringBuilder builder, Db db, String schemaName, String tableName, String insertSqlPrePart, String[] columns) {
try {
int pageIdx = 0;
int pageSize = 1000;
int pageTotal = 1;
final Entity condition = Entity.create();
condition.setTableName("`" + schemaName + "`.`" + tableName + "`");
while(pageIdx < pageTotal) {
PageResult<Entity> pageResult = db.page(condition, new Page(pageIdx, pageSize));
if (CollectionUtils.isEmpty(pageResult)) return;
pageTotal = pageResult.getTotalPage();
++ pageIdx;
/* 组装INSERT语句 */
for (Entity recordEntity : pageResult) {
builder.append(insertSqlPrePart);
List<String> valList = new ArrayList<>();
for (String column : columns) {
Object val = recordEntity.get(column.trim());
boolean isEmpty = Objects.isNull(val);
valList.add(isEmpty ? "NULL" : "'" + val + "'");
}
String joinedValues = String.join(", ", valList);
builder.append(joinedValues).append(");\n");
}
builder.append("\n\n");
}
} catch (Exception e) {
e.printStackTrace();
}
}
三、Axios下载文件的问题
1、文件的接口都需要声明响应类型是blob,这要才能认定为文件
/**
* 下载模板文件
* @param data
* @returns {*}
*/
export function downloadTemplate(data) {
return request({
url: `${PATH}/download`,
method: 'post',
responseType: 'blob',
data
})
}
/**
* 下载全部文件
* @param data
* @returns {*}
*/
export function downloadAllTemplate(data) {
return request({
url: `${PATH}/download-all`,
method: 'post',
responseType: 'blob',
data
})
}
2、改写Request.js,因为默认的axios是不接受任何文件形式的响应对象
只要没有code就直接报错,但是接口实际上是正常返回

改写就是追加前置条件,如果请求头说明了content-type信息,并且能在以下type中找到,就直接返回整个response对象
const fileHeaders = [
'text/plain',
'text/html',
'application/vnd.ms-word2006ml',
'text/x-web-markdown',
'application/x-rar-compressed',
'application/x-zip-compressed',
'application/octet-stream',
'application/zip',
'multipart/x-zip',
'text/x-sql'
]
然后axios包装的response,不能直接下载,要给浏览器包装之后通过超链接点击实现下载:
/**
* 转成文件流之后,可以通过模拟点击实现下载效果
* axios下载文件, 请求接口需要追加属性:responseType: 'blob'
* @param response
*/
export function axiosDownloadFile(response) {
/* js创建一个a标签 */
const element = document.createElement('a')
/* 文档流转化成Base64 */
const href = window.URL.createObjectURL(response.data)
element.href = href
/* 下载后文件名 */
element.download = decodeURIComponent(response.headers['content-disposition'].match(/filename=(.*)/)[1])
document.body.appendChild(element)
/* 点击下载 */
element.click()
/* 下载完成移除元素 */
document.body.removeChild(element)
window.URL.revokeObjectURL(href)
}
源码仓库,已开放访问:
https://download.csdn.net/download/askuld/88216937