文章目录
- 一、背景
- 二、方法
- 三、效果
论文:Masked Autoencoders Are Scalable Vision Learners
代码:https://github.com/facebookresearch/mae
出处:CVPR2022 Oral | 何凯明 | FAIR
一、背景
本文的标题突出了两个词:
- masked:借鉴了 BERT 中的 mask 方法,在视觉中引入了 mask 的操作,随机 mask 掉一些图像块,然后预测这个图像块
- scalable:说明模型有很好的扩展性
auto:自回归模型,特点就是标签和样本来自于同一个东西
- 比如 NLP 中一个被 mask 掉一些 word 的句子是输入样本, mask 掉的单词是学习的标签,这两个东西都来自于同一个句子。所以说不说 auto 都是可以的
- 但在视觉任务中,很少有样本和标签是来自于同一个东西的,一般标签是文本,样本是图片
- 所以这里的 auto 的意思就是说,在模型训练的时候,训练的样本和标签是来自于一个图片的,所以引入了 auto 这个前缀
- autoencoder 就表示自编码器
MAE 是怎么做的:
- 随机的盖住图片中的一些块儿,然后再去重构这些被盖住的像素
- 思想来自于 BERT,这里 mask 掉的是一个 patch
核心设计:
- 非对称的 encoder-decoder 架构,非对称是指编码器是作用在可见的像素上,解码器是作用在所有块的特征上的(对被 mask 掉的块来说,解码器是要学习不可见的块)。解码器相比编码器更小,开销不到编码器的 1/10
- 作者发现当遮掉图像中绝大部分的像素(如 75%)时,那么会得到一个很有意义的自监督的任务(因为如果遮住很少的部分可能插值就能重构了,而学习不到更深层的表征)
效果:
- 在 ViT-H 上使用小的数据集 ImageNet-1k 的时候,就能得到在 ViT 中使用百倍以上图片训练的效果(87.8%),而且是没有使用标签的
- MAE 主要是用来做迁移学习的,在迁移学习上表现的比较好,在物体检测、示例分割、语义分割上都挺好的,所以通过不带标签的数据使用自监督方法训练出来的模型,在迁移学习上的效果也很不错,达到了 BERT 在 NLP 中的效果。
MAE 和对比学习的不同(对比学习也是自监督学习的一种):
- MAE 是对一张图像随机 mask 掉像素,通过模型来还原像素
- 对比学习是使用代理任务(如数据增强)来将一张图像变成 两张不同的图像,通过对比学习来让模型学习哪些图像是正样本对,从而学习出图像特征
二、方法
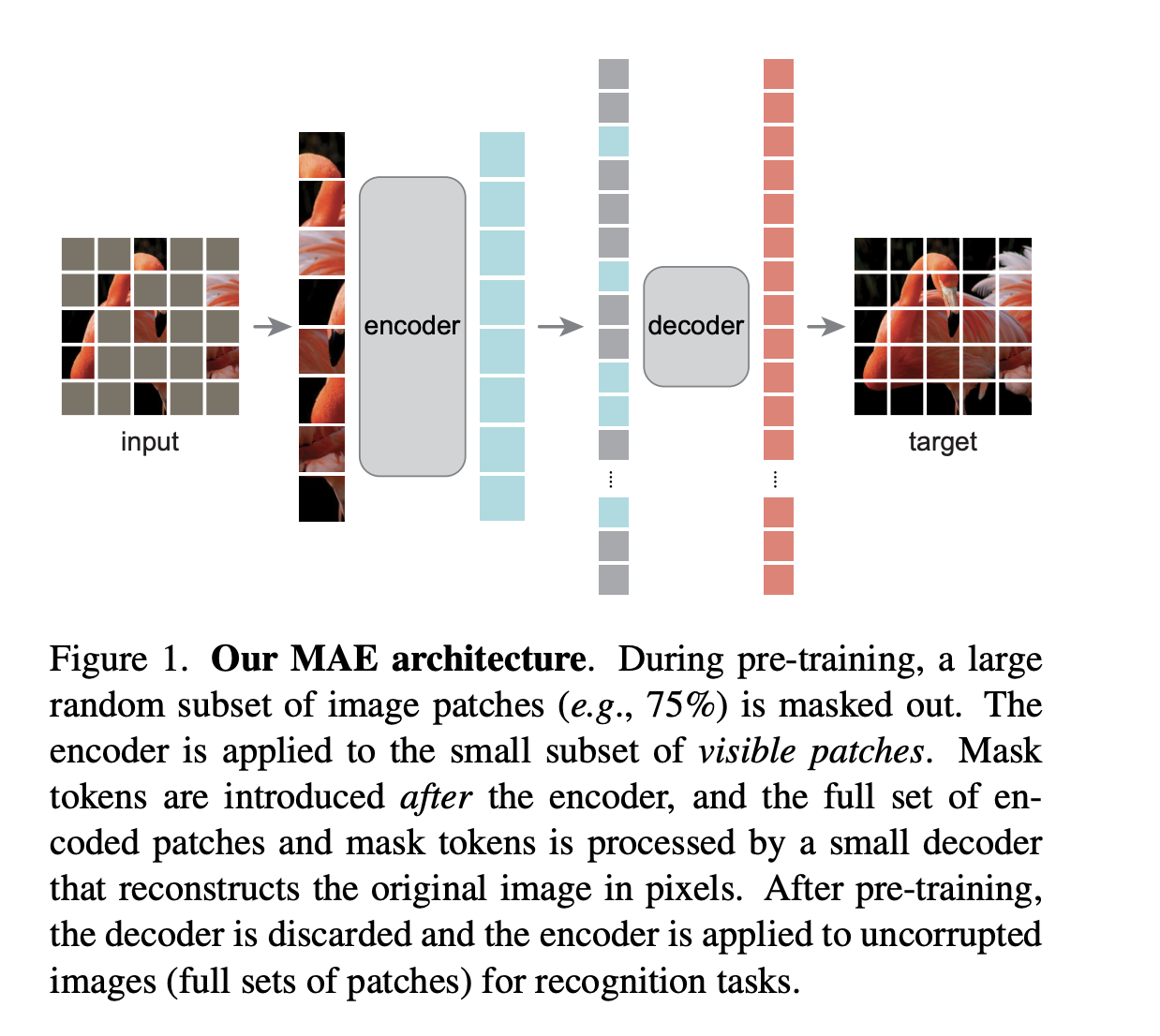
注意:
- encoder 的输入是经过 mask 的 patch embedding
- decoder 的输入是 encoder 的输出 embedding 被 mask 掉的 token 编码,这里 mask 掉的 token 编码是待学习的的向量,而不是直接把原图信息输入了
预训练过程:
- 输入是被打 patch 然后遮盖一些 patch,灰色表示被 mask 掉,对 patch 得到 patch embedding ,且加上位置编码,然后随机打乱这些 patch embedding,如果要删除80%的话,就把最后的 80% patch 拿掉就可以了,和随机抹除 mask 的意义是一样的。
- 把保留的可见的 patch embedding 送入 encoder(ViT),得到每个块的特征表示(较大的绿色块),经过提取后的特征块会根据之前块的编号重新拉长,也就是恢复到打乱顺序之前的顺序,被 mask 掉的块也会放上原来的像素特征(小的灰色块)
- 重新放回原来位置的特征序列送入 decoder,用于恢复全部的像素信息,然后计算 MSE loss
- 而且这里的编码器灰色块比解码器更大一些,说明主要的计算量来自编码器,因为对图像信息的编码很重要,而且编码器接收的是少量的没有被盖住的图片,计算量相对少一点
怎么重构出原图:
- 解码器的最后一层是线性层,如果一天 patch 是 16x16 的话,就输出 256 维度的特征,拿到后 reshape 到 16x16 即可
损失函数:MSE
- 预测像素和真正像素做相减,然后做平方和
- 而且只在被 mask 掉的像素块上做 MSE,因为有一些像素是没有被盖住的,本来模型就是可见的,所以不用计算 MSE
如果像用这个结构做一些其他的视觉任务:
- 只需要编码器,不需要解码器,将这个结构当做一个特征提取器
- 具体的做法就是,输入的图像不用 mask,只需要打成 patch 序列,然后经过 encoder 得到对应的特征就可以了
效果展示:
图 2 是使用 MAE 在 ImageNet 验证集上构造的图片,这些是测试结果,图像没有参与训练
- 左边一列是遮住 80% 的图像
- 中间一列是重构的图像
- 右边一列是真实的图片
- 虽然细节比较模糊,但是这种能重构的思路已经很惊人了


图 4 展示了遮盖不同比例的图像的重构效果:

BERT 在 NLP 上取得了很大的成功,计算机视觉这边也有很多使用 BERT 思想的方法,但都不是很成功,作者认为有三个原因:
- 第一,视觉任务上之前大多使用的都是 CNN 这种操作方式,通过不断叠加卷积核,来提取聚合的图像像素信息,但是 mask 这种操作不太适合 CNN,因为在 transformer 中,mask 掉的是一个单词,这个词是一个特定的词,会一直保留下来,和别的单词区分开来。如果在卷积上做 mask,也就是把部分像素盖住或者换上特定的值,在卷积时,无法把这部分所表达的信息识别出来,所以在后面的时候比较难还原这块到底是什么,不好加入位置编码。但现在 ViT 在视觉上的成功,已经能解决了。
- 第二,信息的粒度不同,NLP 中每个词表示的是有语义信息的,如果去掉某些词可能会导致语义变化。但是在图片中,会有冗余的像素信息,如果去掉一个块的话,可以使用插值还原。所以作者将高比率的块随机去掉,就能极大降低图像的冗余性。这样的策略是自监督的模式,就是图像自己监督自己,会驱使模型学习全局的信息,而不是局部的信息(可以看图 2 和图 4)
- 第三,解码器要还原的东西不同,在 NLP 中,mask 掉的是单词,解码器要还原的是单词,单词是有个哦层语义信息的,而在视觉中,mask 掉的像素,解码器要还原的是相似,像素是比较低层的信息。所以 BERT 中使用的一层全连接层解码器在图像中是不可用的,图像中需要更大的解码器来还原更复杂的特征
MAE 可以看做 BERT 在视觉上的扩展,但语言和视觉有很多不同:
- 语言中,一个单词是有语义信息的
- 图像中,一个 patch 虽然是图像的一部分,但不是独立的个体,不是一个含有语义信息的分割,可能是多个物体的一小块
- 但 MAE 学到了比较好的效果,也能做一些复杂的任务,所以说 MAE 或 transformer 确实能学习一些隐藏的表达
三、效果
- 左侧:ViT 原文在 ImageNet-1k 上训练的结果
- 中间:作者重构和改进的的 ViT 方法(因为原文训练的不太稳定),主要是加了一些正则化的方法,因为 BiT 论文当时说 transformer 需要在很大的数据集上才能训练好,但后面大佬们就发现加入一些正则化的项也能在小的数据集上训练出好的结果
- 右侧:MAE 在 ImageNet-1k 上预训练,再在 ImageNet 微调
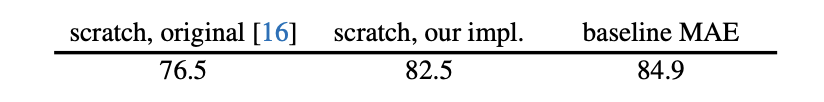
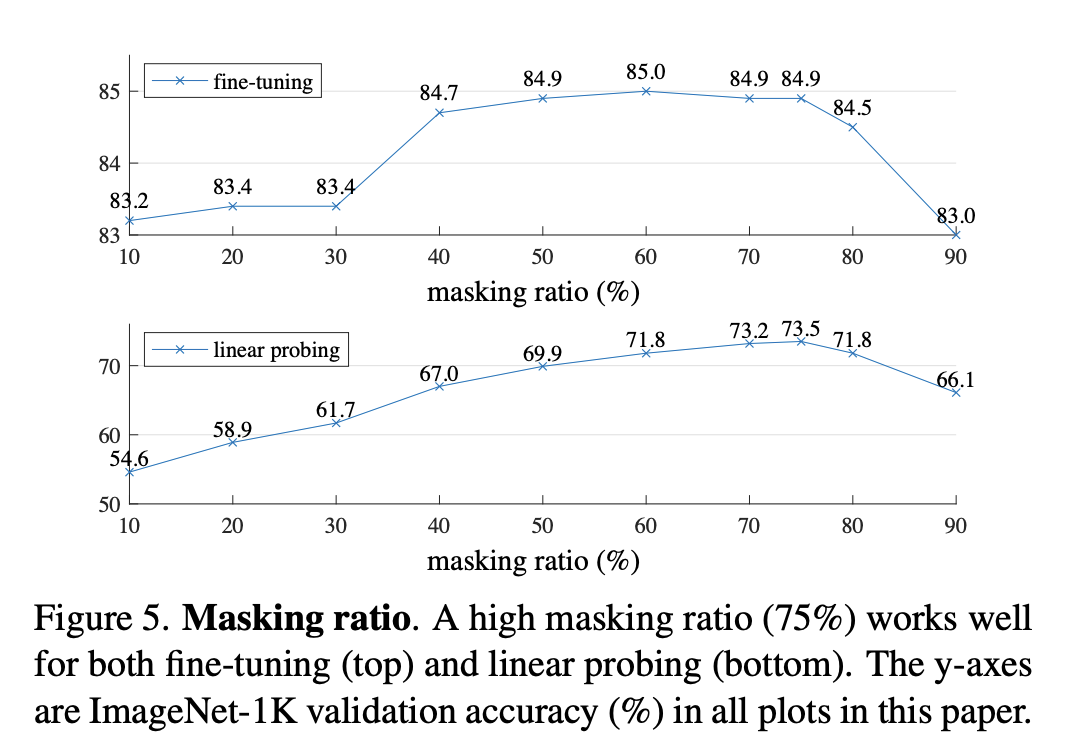
各种消融实验:

mask 比例:75% 最好
mask 方式:随机采样最好

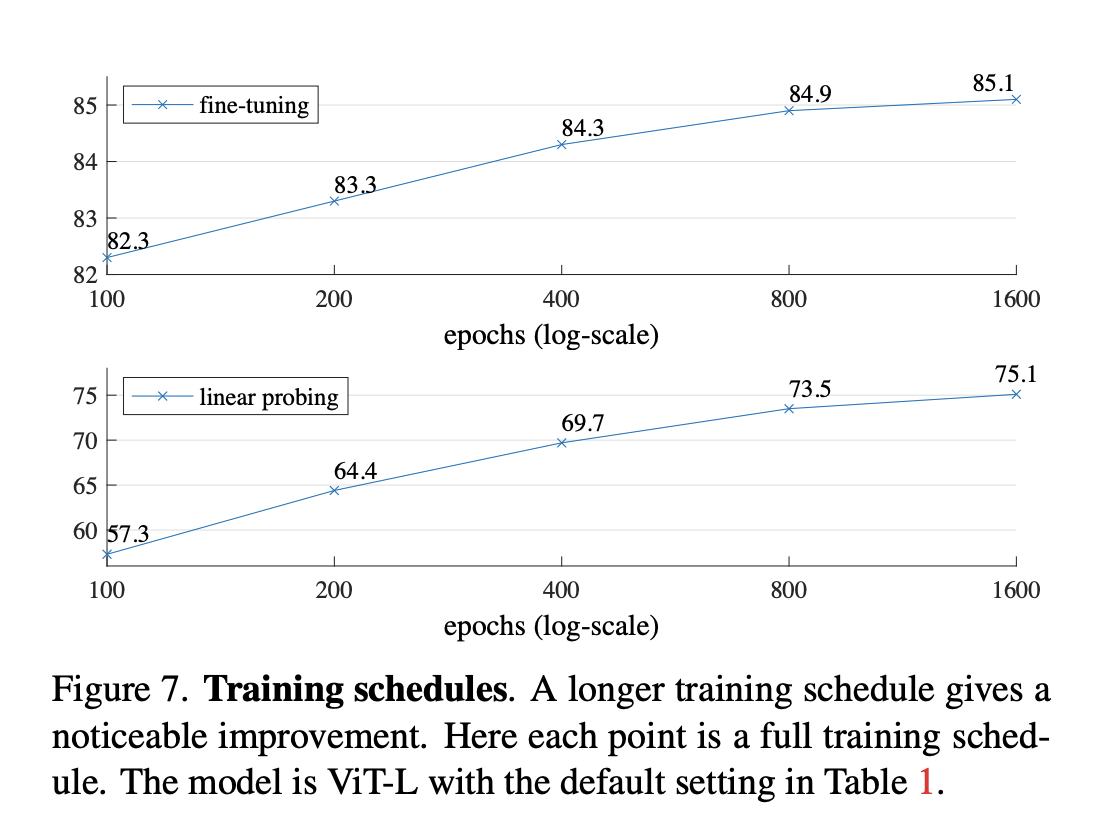
预训练轮数和微调轮数:
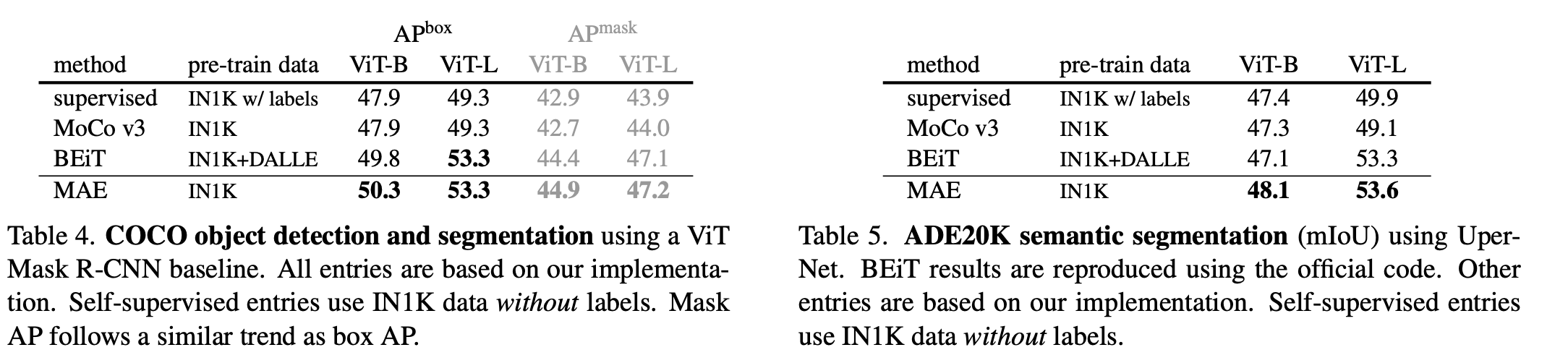
迁移学习效果:COCO 检测和分割