目录
- 前言
- 泛读
- 摘要
- Introduction
- Related Work
- 小结
- 精读
- 模型
- 基于LSTM的句子生成器
- Training
- Inference
- 实验
- 评价标准
- 数据集
- 训练细节
- 分数结果
- 生成结果多样性讨论
- 排名结果
- 人工评价结果
- 表征分析
- 结论
- 代码
前言
本课程来自深度之眼《多模态》训练营,部分截图来自课程视频。
文章标题:Show and Tell: A Neural Image Caption Generator
神经图像描述生成
作者:Oriol Vinyals等
单位:谷歌
发表时间:2015 CVPR
Latex 公式编辑器
泛读
和第二篇一样,这篇同样是cvpr 2015的一篇文章,这篇读完可以算是对图像描述这个方向有个大体的了解,里面所使用的编码-解码(Encoder-Decoder)的结构甚至到现在都是很实用的,后来的大多数这方面的文章都是在该模型的基础上进行的优化改良。
文章开篇就讲,这篇论文将最近比较火的计算机视觉和机器翻译两个领域融合起来,从而有了这个模型。图像描述比目标检测和图像分类更加难一点,因为好的描述不仅仅要抓住图像中的客观物体,更要表述出这些目标之间的关系。不仅如此,还得考虑语义,不同的语言还得考虑语法。那个时候现有的办法都是讲解决上述每个子问题的方法合在一起来生成图像描述,而这篇论文则首次提出用一个模型来解决所有的问题。
摘要
Automatically describing the content of an image is a fundamental problem in artificial intelligence that connects computer vision and natural language processing.
开门见山:自动描述图像内容是连接计算机视觉和自然语言处理的人工智能中的一个基本问题。
In this paper, we present a generative model based on a deep recurrent architecture that combines recent advances in computer vision and machine translation and that can be used to generate natural sentences describing an image. The model is trained to maximize the likelihood of the target description sentence given the training image.
我们干了什么:在本文中,我们提出了一种基于深度循环架构的生成模型,它结合了计算机视觉和机器翻译的最新进展,可用于生成描述图像的自然语句。该模型被训练以最大化给定训练图像的目标描述句子的可能性。
Experiments on several datasets show the accuracy of the model and the fluency of the language it learns solely from image descriptions. Our model is often quite accurate, which we verify both qualitatively and quantitatively. For instance, while the current state-of-the-art BLEU-1 score (the higher the better) on the Pascal dataset is 25, our approach yields 59, to be compared to human performance around 69. We also show BLEU-1 score improvements on Flickr30k, from 56 to 66, and on SBU, from 19 to 28. Lastly, on the newly released COCO dataset, we achieve a BLEU-4 of 27.7, which is the current state-of-the-art.
实验标志性mark:在多个数据集上的实验表明了模型的准确性以及它仅从图像描述中学习的语言的重要性。我们的模型通常非常准确,我们从定性和定量两方面进行了验证。例如,虽然Pascal数据集上当前最先进的BLEU-1得分(越高越好)为25,但我们的方法产生5 9,与人类绩效约6 9相比。我们还发现Flickr30k上的BLEU1得分从56提高到66,SBU上的BLUE-1分从19提高到28。最后,在最新发布的COCO 数据集上,我们实现了27.7的BLEU4,达到SOTA。
省流:提出了一种基于深度循环网络架构的图片描述生成架构,在xxxx数据集上取得SOTA的水平。
Introduction
第一段先强调能够用正确的英语句子自动描述图像的内容是一项非常艰巨的任务,但它可能会产生巨大的影响,例如帮助视障人士更好地理解网络上图像的内容。例如,这项任务要比经过充分研究的图像分类或目标识别任务困难得多,后者一直是计算机视觉界的主要焦点。
然后说这个任务为什么不简单:描述不仅必须捕捉图像中包含的对象,还必须表达这些对象之间的关系,以及它们的属性和它们所涉及的活动。此外,上述语义知识必须用英语等自然语言表达,这意味着除了视觉理解之外,还需要语言模型。
第二段,先提到当前现有的研究是将图文描述分解的子问题结合起来解决的,然后对比提出本文的做法是提出a single joint model,然后接一个从句来描述整个model:该模型将图像 I I I作为输入,并经过训练以最大限度地提高生成单词 S = { S 1 , S 2 , … } S=\{S_1,S_2,…\} S={S1,S2,…}的目标序列的可能性 p ( S ∣ I ) p(S|I) p(S∣I),其中每个单词S都来自一个给定的字典,能够充分描述图像。
然后第三段介绍上面的idea是如何从MT任务中得来的。假设源语言为S,目标语言为T,这机器翻译的目标是要最大化
p
(
T
∣
S
)
p(T|S)
p(T∣S),并提到完成MT任务,RNN是当前最佳选择。“编码器”RNN读取源语句,
并将其转换为丰富的固定长度向量表示,进而用作生成目标语句的“解码器”RNN的初始隐藏状态。
第四段,简单介绍本文方法,第一句的“方法”的英文表达值得借鉴:
Here, we propose to follow this elegant recipe
本文使用CNN作为图像“编码器”,首先对其进行图像分类任务的预训练,并使用最后一个隐藏层作为生成句子的RNN decoder的输入(见图1)。我们称这个模型为神经图像标题:Neural Image Caption,NIC。

最后一段介绍contribution:
First, we present an end-to-end system for the problem. It is a neural net which is fully trainable using stochastic gradient descent.
提出了一个 Neural Image Caption(NIC)模型来生成图像描述,该模型的优化目标可以使用梯度下降来训练。
Second, our model combines state-of-art sub-networks for vision and language models. These can be pre-trained on larger corpora and thus can take advantage of additional data.
该模型结合了现有的一些用于视觉和语言模型的最新子网,所以可以保证有足够的数据来进行预训练。
Finally, it yields significantly better performance compared to state-of-the-art approaches.
最后呢,当然是每篇论文都有的话,只不过这篇说的更拽一点:我们的模型优于现有的所有模型。
Related Work
早些时候研究人员独立使用视觉模型来识别图像物体与关系, 使用语言模型生成文本, 通常基于复杂的人工设计系统如模板等, 这些方法生成的文本很呆板(或者仅用在某些特定领域,例如:交通、体育)。后来为了解决这样的问题, 又有人将图片和文本映射到相同的向量空间, 通过寻找距离图像向量最近的文本向量来生成语句(这个讲的好像就是第一篇的工作)。即使最新的神经网络方法也没有解决无法描述未曾出现物体的问题。
最后一句就是指出当前研究的局限性。
在这项工作中,我们将用于图像分类的深度卷积网络[12]与用于序列建模的递归网络[10]相结合,以创建生成图像描述的单个网络。RNN在这个单一的“端到端”模型的上下文中进行训练。该模型受到最近机器翻译中序列生成成功的启发[3,2,30],不同之处在于,我们使用卷积网络作为输入,而不是从句子开始。最接近的工作是Kiros等人[15],他们使用神经网络,而不是前馈网络,来预测给定图像和先前单词的下一个单词。Mao等人[21]的一项最新研究将递归神经网络用于同一预测任务。这与目前的提议非常相似,但有一些重要的区别:我们使用更强大的RNN模型,并直接向RNN模型提供视觉输入,这使得RNN能够跟踪文本所解释的对象。由于这些看似微不足道的差异,我们的系统在既定基准上取得了显著更好的结果。最后,Kiros等人[14]提出使用强大的计算机视觉模型和编码文本的LSTM构建联合多模态嵌入空间。与我们的方法相反,他们使用两个分离路径(一个用于图像,一个用于文本)来定义联合项层理,并且,尽管他们可以生成文本,但他们的方法对排名进行了调整。
小结
Image Caption的难点有两个:
1.模型不仅要能够对图像中的每一个物体进行分类,还需要能够理解和描述它们的空间关系。
2.描述的生成要考虑语义信息,当前的输出高度依赖之前生成的内容。
这篇论文提供了一个Image Caption的基础框架:即用CNN作为特征提取器用于将图像转换为特征向量,之后用一个RNN作为解码器(生成器),用于生成对图像的描述。
精读
模型
第一段还是稍微把MT任务解释一点,然后引出本文模型:
和机器翻译类似,Image Caption的目标函数也是最大化标签值的概率,这里的标签即使训练集的描述内容S,表示为:
θ
∗
=
arg
max
θ
∑
(
I
,
θ
)
log
p
(
S
∣
I
;
θ
)
\theta^*=\arg\max_{\theta}\sum_{(I,\theta)}\log p(S|I;\theta)
θ∗=argθmax(I,θ)∑logp(S∣I;θ)
其中
I
I
I是输入图像,
θ
θ
θ是模型的参数。
log
p
(
S
∣
I
;
θ
)
\log p(S|I;\theta)
logp(S∣I;θ)表示为
N
N
N个输出的概率和,第
t
t
t时刻的内容是0到
t
−
1
t−1
t−1时刻以及图像编码的后验概率,可以表示为:
log
p
(
S
∣
I
;
θ
)
=
∑
t
=
0
N
log
p
(
S
t
∣
I
,
S
0
,
⋯
,
S
t
−
1
)
\log p(S|I;\theta)=\sum_{t=0}^N\log p(S_t|I,S_0,\cdots,S_{t-1})
logp(S∣I;θ)=t=0∑Nlogp(St∣I,S0,⋯,St−1)
可以使用RNN对这个概率进行建模, 将单词使用隐含层特征
h
t
h_t
ht表示,
h
t
=
f
(
h
t
−
1
,
x
t
−
1
)
h_t = f(h_{t-1}, x_{t-1})
ht=f(ht−1,xt−1), 为了提高性能,使用ILSVRC 2014比赛的最佳CNN模型和LSTM-RNN.
所以模型的损失函数是所有时间片的负log似然之和,表示为:
L
(
I
,
S
)
=
−
∑
i
=
1
N
log
p
t
(
S
t
)
L(I,S)=-\sum_{i=1}^N\log p_t(S_t)
L(I,S)=−i=1∑Nlogpt(St)
为了使上述RNN更具体,需要做出两个关键的设计选择:图像和文字如何作为输入输入;隐藏层
f
f
f的形式是什么。对于
f
f
f我们使用了一个长期短期记忆(LSTM)网络,它展示了翻译等序列任务的最新性能。下一节将概述该模型。对于图像的表示,我们使用卷积神经网络(CNN)。它们已被广泛用于图像任务,目前在目标识别和检测方面处于最先进水平。我们特别选择的CNN使用了一种新的批量归一化方法,并在ILSVRC 2014分类竞赛中获得了当前最佳性能[12]。此外,已经证明它们可以通过迁移学习推广到其他任务,如场景分类[4]。这些词用嵌入模型表示。
基于LSTM的句子生成器
这节主要是讲上面提到的
f
f
f,为了避免RNN的梯度爆炸与弥散问题,本文选择了LSTM进行解码。
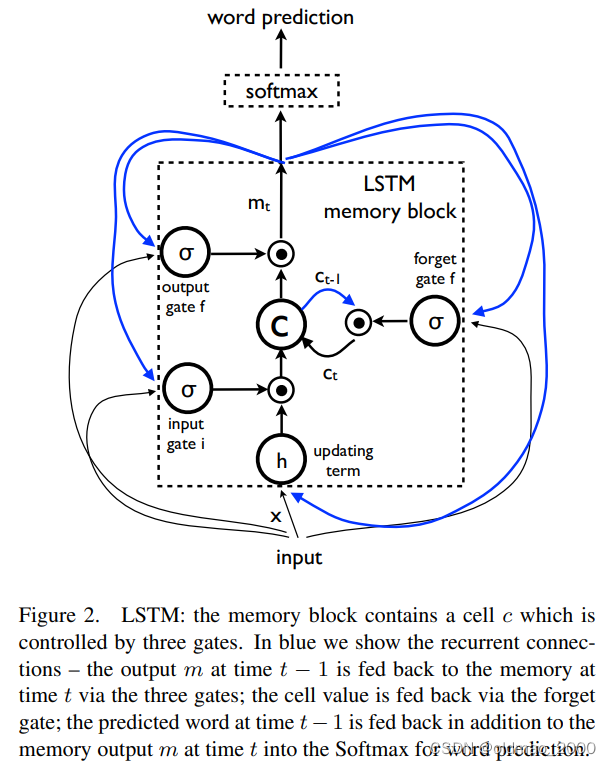
蓝色箭头代表循环连接,三个
σ
\sigma
σ代表三个门,通过上一个时刻的输出进行计算。
i
t
=
σ
(
W
i
x
x
t
)
+
W
i
m
m
t
−
1
f
t
=
σ
(
W
f
x
x
t
)
+
W
f
m
m
t
−
1
o
t
=
σ
(
W
o
x
x
t
)
+
W
o
m
m
t
−
1
i_t=\sigma(W_{ix}x_t)+W_{im}m_{t-1}\\ f_t=\sigma(W_{fx}x_t)+W_{fm}m_{t-1}\\ o_t=\sigma(W_{ox}x_t)+W_{om}m_{t-1}
it=σ(Wixxt)+Wimmt−1ft=σ(Wfxxt)+Wfmmt−1ot=σ(Woxxt)+Wommt−1
然后用
i
t
i_t
it和
f
t
f_t
ft结合
x
t
x_t
xt计算
c
t
c_t
ct:
KaTeX parse error: Can't use function '\)' in math mode at position 56: …t+W_{cm}m_{t-1}\̲)̲
然后经过输出门:
m
t
=
o
t
⊙
c
t
m_t=o_t\odot c_t
mt=ot⊙ct
然后走softmax
p
t
+
1
=
Softmax
(
m
t
)
p_{t+1}=\text{Softmax}(m_t)
pt+1=Softmax(mt)
Training
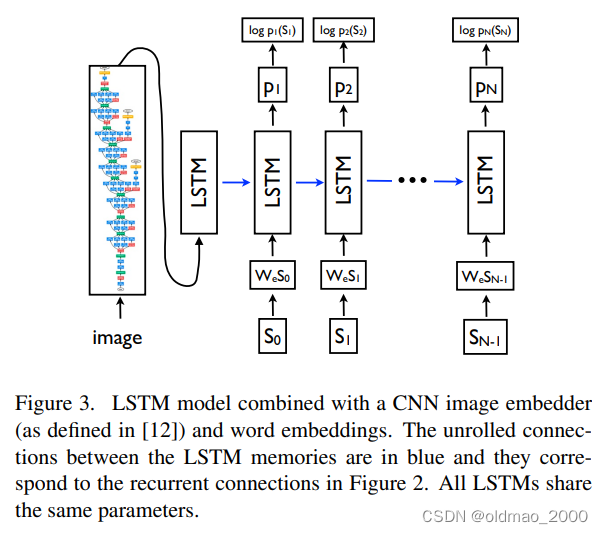
图的左半部分是编码器,由CNN组成,图中给的是GoogLeNet,在实际场景中我们可以根据自己的需求选择其它任意CNN。图的右侧是一个LSTM。
在训练时,输入图像表征
I
I
I只在最开始的t−1时刻输入,这里作者说通过实验结果表明如果每个时间片都输入会容易造成训练的过拟合且对噪声非常敏感。在预测第t+1时刻的内容时,我们会用到t时刻的输出的词编码作为特征输入,单词使用独热编码
S
t
S_t
St表示,整个过程表示为:
x
−
1
=
CNN
(
i
)
x
t
=
W
e
S
t
,
t
∈
{
0
⋯
N
−
1
}
p
t
+
1
=
LSTM
(
x
t
)
,
t
∈
{
0
⋯
N
−
1
}
\begin{align*}x_{-1}&=\text{CNN}(i)\\ x_t&=W_eS_t,t\in\{0\cdots N-1\}\\ p_{t+1}&=\text{LSTM}(x_t),t\in\{0\cdots N-1\}\end{align*}
x−1xtpt+1=CNN(i)=WeSt,t∈{0⋯N−1}=LSTM(xt),t∈{0⋯N−1}
Inference
NIC推理的方法有两种, 一种是通常的Sampling方法, 即每次只选择概率最大的值生成单词; 另一种是BeamSearch, 每次单词生成时选择概率最大的K个值进行组合。
实验
评价标准
除了自动化标准外(BLEU, METEOR, CIDER), 本文还使用了人工评价(AMT)的方式, 对每个句子在1-4之间打分.同时, 在调参时还使用Perplexity进行参数选择. 最后还可以将图像描述问题转换为描述排名问题,这样就可以利用排序评价标准比如 reacall@k, 但是还是应该更加关注于生成评价方法。
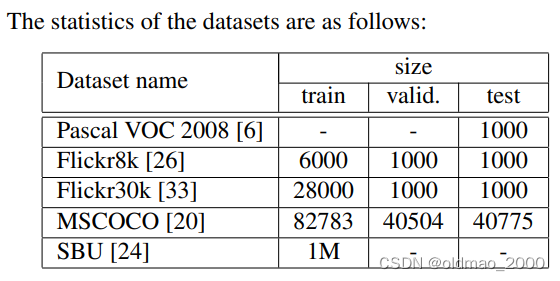
数据集
Pascal 数据集通常仅在系统经过不同数据(例如其他四个数据集中的任何一个)训练后才用于测试。 在 SBU的情况下,我们保留了 1000 张图像进行测试,并在 [18] 使用的其余图像上进行训练。 同样,我们从MSCOCO 验证集中保留 4K 随机图像作为测试,称为 COCO-4k,并在下一节中使用它来报告结果。
训练细节
由于图像描述数据集数据不够充分. 为了防止过拟合, NIC使用ImageNet等上的预训练模型来初始化CNN参数. 同时也使用大规模新闻语料库对语言模型参数 W e W_e We初始化, 但是并无明显效果, 所以最后为了简单没有使用新闻语料库初始化. 最后, 使用了一些模型方面的防过拟合方法, 如Dropout和模型融合以及修改网络模型尺寸等. 所有的参数使用固定学习率的SGD(无动量Momentum)进行优化; 使用512维向量作为词嵌入(Embedding)向量以及LSTM向量的尺寸。
分数结果
MSCOCO数据集上的BLEU-1, BLEU-4, METEOR, CIDER模型对比评分如下, 其中人工方法的评分是对5句人工描述计算BELU分数再取平均。
表1中人工描述取平均后NIC结果居然超过人类~!
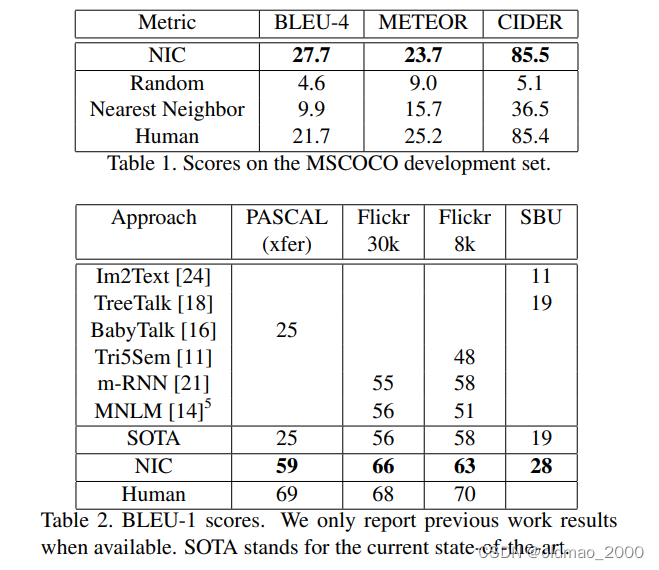
文中还对为什么SBU得分比较低的情况做了说明,其原因在于SBU数据集的标注质量不高(weak labeling),标注语句较短,非人为标注等,因此该数据集的标注噪音较大,得分较低。
对于PASCAL数据集,官方没有划分训练集,且该数据集与Flickr、MSCOCO是无关联的,因此文中将模型在Flickr、MSCOCO训练结果迁移到了PASCAL,所以PASCAL数据集分数也相对低一点。
Flickr8k和Flickr30k这两个数据集很相似. 且Flick30k训练数据大约是Flickr8k的4倍大小, 所以从30k训练迁移到8 k的结果提高了4个B E L U点; 但是从MSCOCO ( 5倍于Flickr30k)迁移到Flickr时, 由于数据相差很远, 所以最终降低了10点. 其他数据集间的迁移情况也类似。
生成结果多样性讨论
为了研究生成的图像描述是否具有多样性和创新性, 文章使用BeamSearch的方法选出N个得分最高的语句,其中每张图最好的15个句子的平均BLEU与人类的得分相近,并且这15个句子中很多是未曾出现在训练数据中的,因此具有很好的多样性。一些测试集上的BeamSearch方法生成语句如下所示:
| MSCOCO验证集中的TOP N示例 |
|---|
| A man throwing a frisbee in a park. A man holding a frisbee in his hand. A man standing in the grass with a frisbee. |
| A close up of a sandwich on a plate. A close up of a plate of food with french fries. A white plate topped with a cut in half sandwich. |
| A display case filled with lots of donuts. A display case filled with lots of cakes. A bakery display case filled with lots of donuts. |
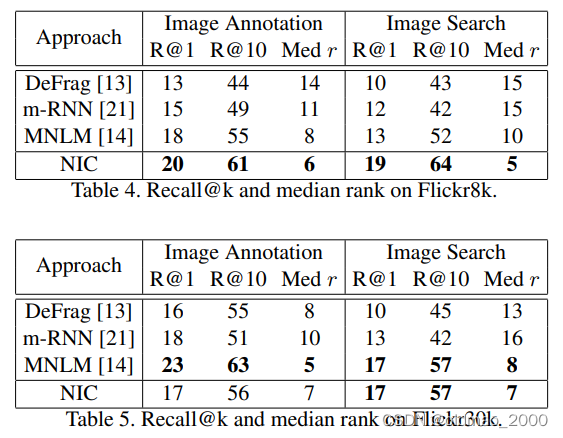
排名结果
给定图片对描述排名及给定描述对图片进行排序都取得了很好的结果(原话:NIC is doing surprisingly well on both ranking tasks),结果如图所示:
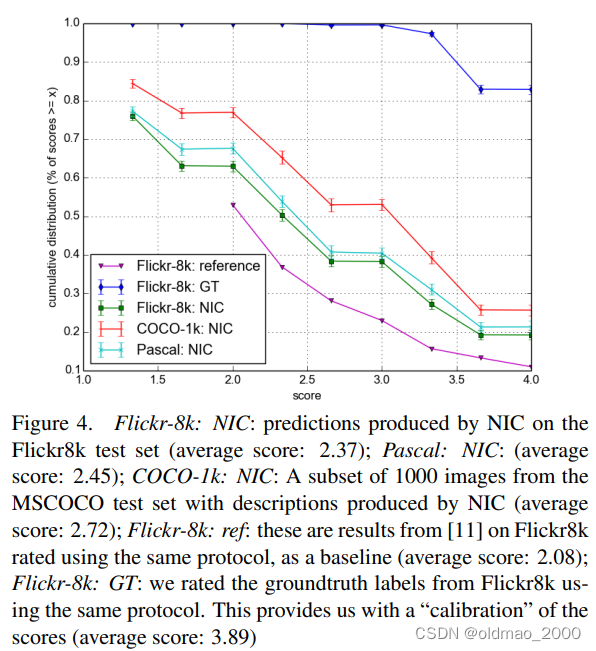
人工评价结果
人工评价结果如下图所示, 可见NIC模型优于参考系统但是差于Grond Truth,这的同时也表明BLEU并不是一个很好的评价指标。
文中还给出了生成的描述的例子,这里截取四张

作者指出左上角飞盘那张图片,模型能识别出尺寸较小的飞盘,显示出模型强大的识别能力。
表征分析
使用词嵌入作为LSTM解码器的输入, 可以学习到语言中相似的语义信息( W e W_e We),也有利于CNN提取相似的语义特征,一些最邻近单词的例子如下表所示:
| 单词 | 相邻词 |
|---|---|
| car | van, cab, suv, vehicule, jeep |
| boy | toddler, gentleman, daughter, son |
| street | road, streets, highway, freeway |
| horse | pony, donkey, pig, goat, mule |
| computer | computers, pc, crt, chip, compute |
结论
基于CNN和RNN的NIC模型多个数据集及多种评价标准下都展现了强大的生成性能和鲁棒性。显然,相关数据集的发展对NIC类似方法的提高也会有很大的帮助。更进一步,使用无监督数据集进行相关研究也是下一步工作。
代码
源代码是TF框架的,使用说明仔细看readme.md即可。大概步骤:
先下载COCO数据集,然后把COCO train2014 images放到train/images目录下,captions_train2014.json文件放到train目录下;同样的把COCO val2014 images放到val/images目录下,captions_val2014.json文件放到val目录下;下载VGG16网络对CNN部分的参数进行初始化(原文提供的下载链接已失效),当然也可以直接自己训练。
训练:
python3 main.py --phase=train \
--load_cnn \
--cnn_model_file='./vgg16_weights.npz'\
[--train_cnn]
如果使用–train_cnn参数,则会同时训练CNN+RNN,否则会固定使用VGG16的参数,只训练RNN部分。
验证:
python3 main.py --phase=eval \
--model_file='./models/xxxxxx.npy'
结果会直接显示在屏幕上,同时保存在val/results.json文件中。
测试:
python3 main.py --phase=test \
--model_file='./models/xxxxxx.npy'
可以看到程序的入口在main.py中,先是导入config配置,在config.py中给出了很多配置,包括CNN的模型选择,隐藏层的size等:
然后从model.py中导入模型,这里是从BaseModel基础上进行扩展的,BaseModel在baseModel.py中,主要实现了基于COCO数据集的训练模型,贴一段初始化代码:
def __init__(self, config):
self.config = config
self.is_train = True if config.phase == 'train' else False
self.train_cnn = self.is_train and config.train_cnn
self.image_loader = ImageLoader('./utils/ilsvrc_2012_mean.npy')
self.image_shape = [224, 224, 3]
self.nn = NN(config)
self.global_step = tf.Variable(0,
name = 'global_step',
trainable = False)
self.build()
当然我们主要是要在model.py中实现自己的模型。源代码是手搓的VGG16,现在VGG16已经写好了,直接加载即可,只需要剥离最后一层。
后面还手搓了一个LSTM,不细说了。