Python爬虫获取美女头像并保存本地(观山篇一)
- 前言
- 步骤一
- 步骤二
- 步骤三
- 步骤四
- 步骤五
- 最终效果
- 完整代码
- 结言
前言
最近某短视频平台上经常刷到,人生四大雅事:“品茗、抚琴、观山、听雨”。那么今天我们就利用python观山所看到的美景给记录起来,方便我们以后快捷的回忆观山美景。
好了,其他的不多说了,接下来我们所准备好所需环境:python3、requests、lxml。
步骤一
- 首先我们打开目标网页,然后F12打开浏览器控制台,分析网页元素。
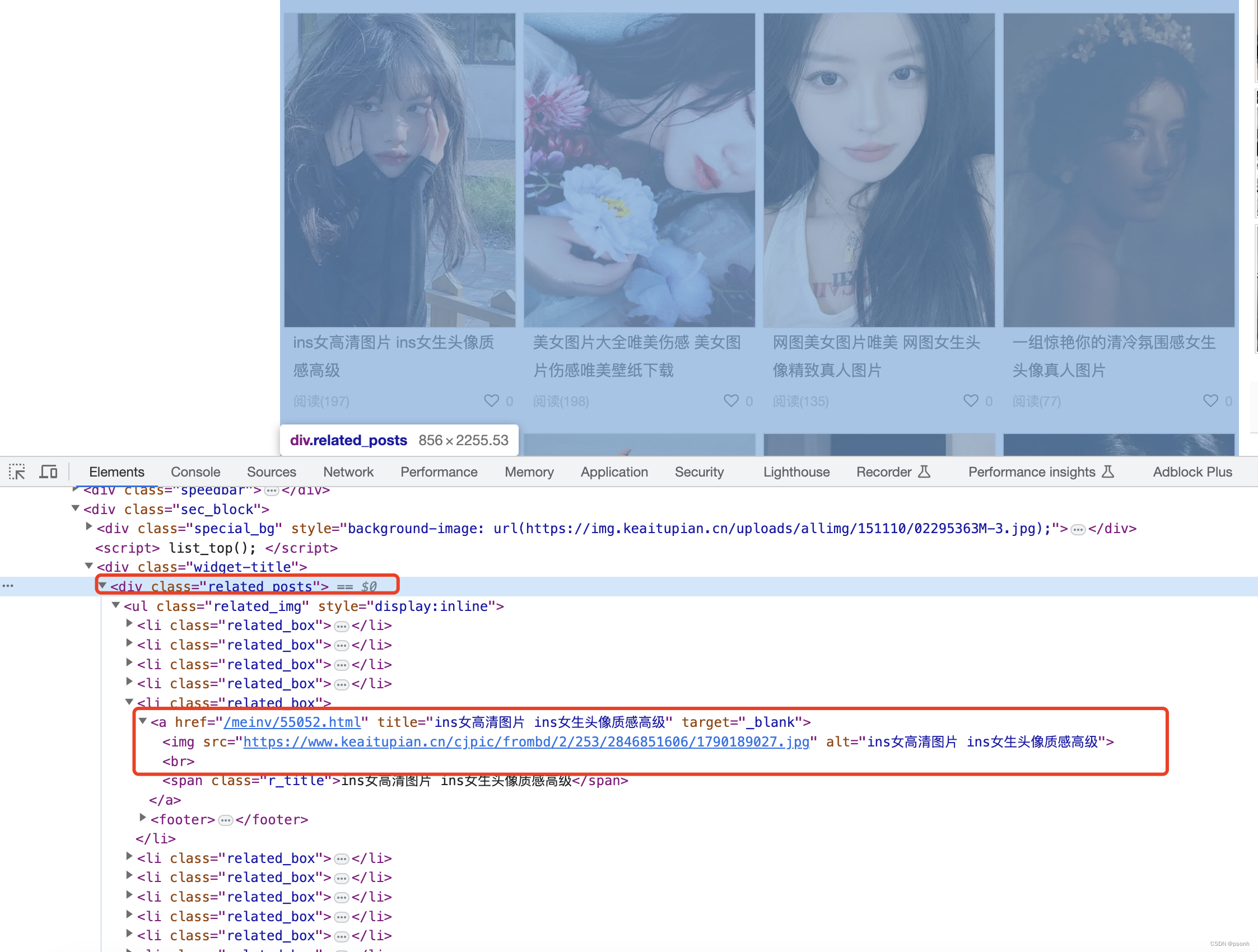
步骤二
- 仔细观察上面框框圈中的部分,一个ul列表包裹的a标签就是当前展示封面的详情页。此时我们要进入到详情页,并获取详情页内的图片:代码如下:
# 模拟浏览器发送请求
response = requests.get(url, headers=spider_header)
# 防止返回的HTML字符串乱码,设置一下编码
response.encoding = "utf-8"
# 将返回的HTML字符串用etree解析成HTML,方便下面用xpath语法进行操作
html = etree.HTML(response.text)
# 获取页面图片展示列表
lis = html.xpath("/html/body/section/div/div/div[2]/div[2]/div/ul/li/a")
# 定义一个临时集合,用于保存首页展示的列表链接
lis_hrefs = []
for li in lis:
lis_hrefs.append(f'{base_url}{li.xpath("@href")[0]}')
步骤三
- 打开某个封面的详情页,并分析构成,如图所示:
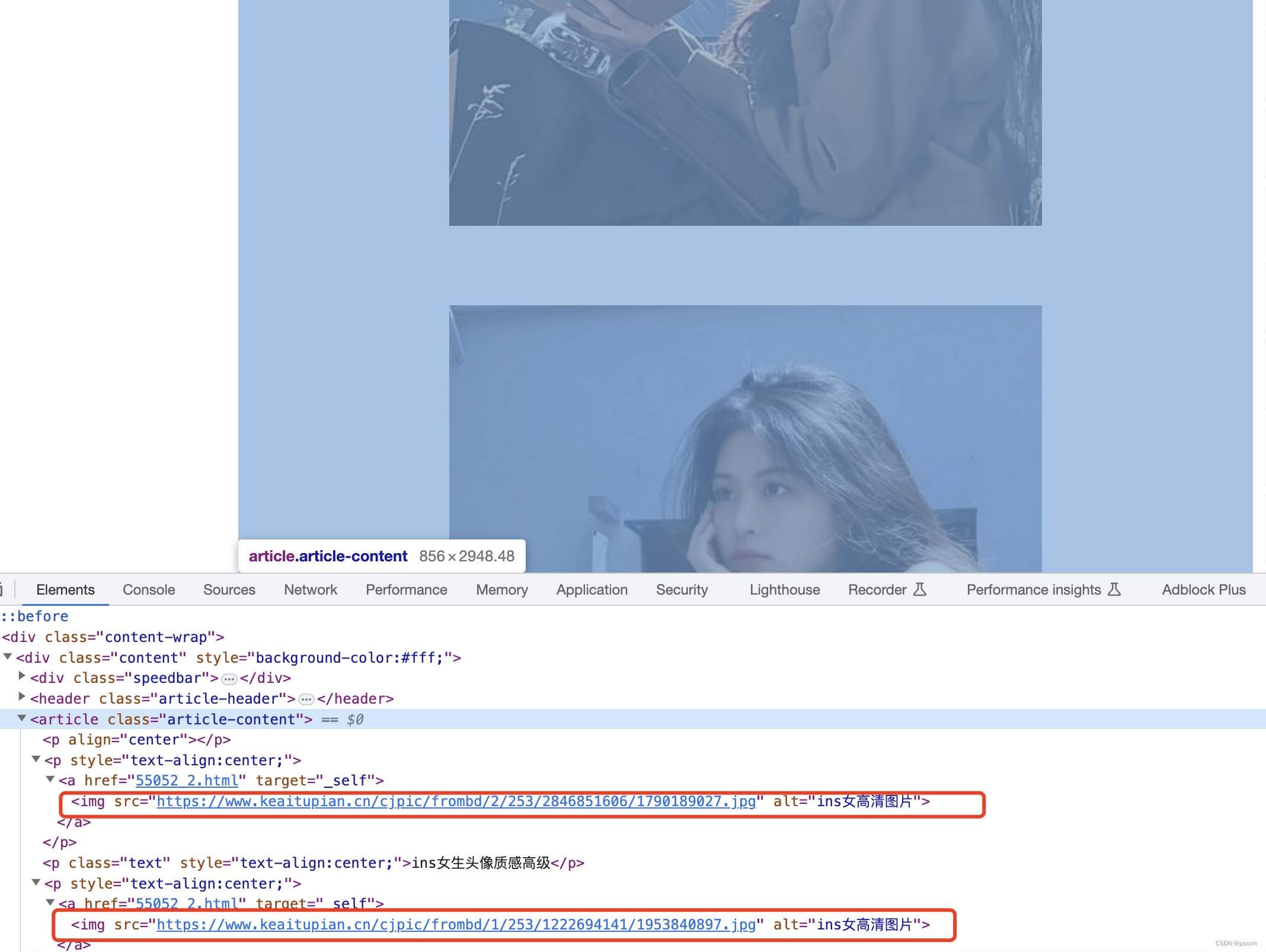
步骤四
- 经过步骤三的元素分析,直接获取
img里的src属性就行了,利用xpath语法提取,当我们分析完毕后,接下来就是遍历步骤二获取的封面集合,然后进入详情提取img的src属性,也就是下载地址了。代码如下:
# 循环便利访问临时集合内的链接
for href in lis_hrefs:
res = requests.get(href, headers=spider_header)
res.encoding = "utf-8"
res_html = etree.HTML(res.text)
# 获取所有图片集合
images = res_html.xpath("/html/body/section/div/div/article/p/a/img/@src")
header = res_html.xpath("/html/body/section/div/div/header/h1/text()")[0]
步骤五
- 将步骤四获取的src进行下载,代码如下:
root_path = os.getcwd()
os.mkdir(header)
file_path = f"{root_path}/{header}"
for image in images:
# 获取并设置保存图片的名称
file_name = re.findall("\d+.jpg", image)[0]
# 获取的图片链接,有重定向操作
response = requests.get(image, headers=down_header, allow_redirects=True)
with open(f"{file_path}/{file_name}", "wb") as f:
f.write(response.content)
time.sleep(0.5)
time.sleep(1)
print(f"首页:{header}的第一页图片保存完毕!")
注意
获取的图片链接,有重定向操作上述步骤五代码有注释说明。
最终效果
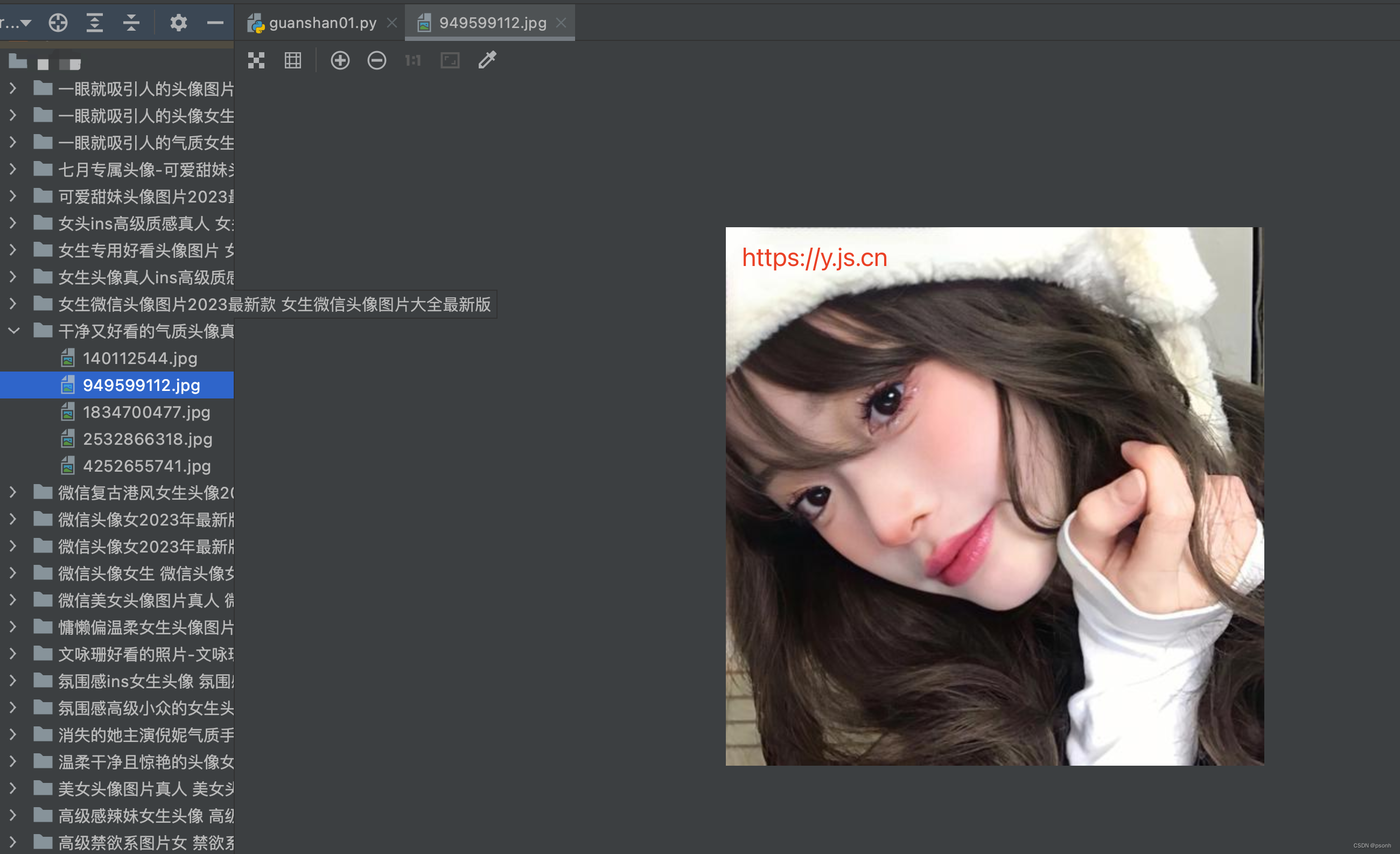
完整代码
import requests
from lxml import etree
import re
import time
import os
url = "https://www.keaitupian.cn/meinv/"
base_url = "https://www.keaitupian.cn"
spider_header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36",
"Referer": "https://www.keaitupian.cn",
"Host": "www.keaitupian.cn"
}
down_header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36",
}
# 模拟浏览器发送请求
response = requests.get(url, headers=spider_header)
# 防止返回的HTML字符串乱码,设置一下编码
response.encoding = "utf-8"
# 将返回的HTML字符串用etree解析成HTML,方便下面用xpath语法进行操作
html = etree.HTML(response.text)
# 获取页面图片展示列表
lis = html.xpath("/html/body/section/div/div/div[2]/div[2]/div/ul/li/a")
# 定义一个临时集合,用于保存首页展示的列表链接
lis_hrefs = []
for li in lis:
lis_hrefs.append(f'{base_url}{li.xpath("@href")[0]}')
# 循环便利访问临时集合内的链接
for href in lis_hrefs:
res = requests.get(href, headers=spider_header)
res.encoding = "utf-8"
res_html = etree.HTML(res.text)
# 获取所有图片集合
images = res_html.xpath("/html/body/section/div/div/article/p/a/img/@src")
header = res_html.xpath("/html/body/section/div/div/header/h1/text()")[0]
root_path = os.getcwd()
os.mkdir(header)
file_path = f"{root_path}/{header}"
for image in images:
# 获取并设置保存图片的名称
file_name = re.findall("\d+.jpg", image)[0]
# 获取的图片链接,有重定向操作
response = requests.get(image, headers=down_header, allow_redirects=True)
with open(f"{file_path}/{file_name}", "wb") as f:
f.write(response.content)
time.sleep(0.5)
time.sleep(1)
print(f"首页:{header}的第一页图片保存完毕!")
结言
上述代码只对第一页进行了保存,并没有进行分页保存,如需分页保存可自行学习或者私信联系。




![NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践](https://img-blog.csdnimg.cn/img_convert/155097bc963b24648129c24d307f4547.png)



