0x0. 前言
本文在对VLLM进行解析时只关注单卡情况,忽略基于ray做分布式推理的所有代码。
0x1. 运行流程梳理
先从使用VLLM调用opt-125M模型进行推理的脚本看起:
from vllm import LLM, SamplingParams
# Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Create an LLM.
llm = LLM(model="facebook/opt-125m")
# Generate texts from the prompts. The output is a list of RequestOutput objects
# that contain the prompt, generated text, and other information.
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
可以看到这里创建了一个LLM对象,然后调用了LLM对象的generate函数。这就是vllm的入口点,接下来我们对LLM这个类的generaet过程进行解析。首先看一下LLM类的初始化函数:
class LLM:
"""这是一个名为LLM(语言模型)的Python类,这个类用于从给定的提示和采样参数生成文本。
类的主要部分包括tokenizer(用于将输入文本分词)、语言模型(可能分布在多个GPU上执行)
以及为中间状态分配的GPU内存空间(也被称为KV缓存)。给定一批提示和采样参数,
该类将使用智能批处理机制和高效的内存管理从模型中生成文本。
这个类设计用于离线推理。在线服务的话,应使用AsyncLLMEngine类。
对于参数列表,可以参见EngineArgs。
Args:
model: HuggingFace Transformers模型的名称或路径.
tokenizer: HuggingFace Transformers分词器的名称或路径。默认为None。.
tokenizer_mode: 分词器模式。"auto"将使用快速分词器(如果可用),
"slow"将总是使用慢速分词器。默认为"auto"。.
trust_remote_code: 当下载模型和分词器时,是否信任远程代码
(例如,来自HuggingFace的代码)。默认为False。
tensor_parallel_size: 用于分布式执行的GPU数量,使用张量并行性。默认为1。
dtype: 模型权重和激活的数据类型。目前,我们支持float32、float16和bfloat16。
如果是auto,我们使用在模型配置文件中指定的torch_dtype属性。
但是,如果配置中的torch_dtype是float32,我们将使用float16。默认为"auto"。
seed: 初始化采样的随机数生成器的种子。默认为0。
"""
def __init__(
self,
model: str,
tokenizer: Optional[str] = None,
tokenizer_mode: str = "auto",
trust_remote_code: bool = False,
tensor_parallel_size: int = 1,
dtype: str = "auto",
seed: int = 0,
**kwargs, # 其它关键字参数。
) -> None:
# 在初始化函数中,首先检查kwargs中是否包含"disable_log_stats"键,
# 如果没有,则在kwargs中添加该键并设置其值为True。
if "disable_log_stats" not in kwargs:
kwargs["disable_log_stats"] = True
# 使用所有给定的参数(包括通过kwargs传递的任何额外参数)来初始化EngineArgs对象,
# 然后使用这些参数来初始化LLMEngine对象
engine_args = EngineArgs(
model=model,
tokenizer=tokenizer,
tokenizer_mode=tokenizer_mode,
trust_remote_code=trust_remote_code,
tensor_parallel_size=tensor_parallel_size,
dtype=dtype,
seed=seed,
**kwargs,
)
self.llm_engine = LLMEngine.from_engine_args(engine_args)
# 初始化一个名为request_counter的Counter对象,用于请求计数。
self.request_counter = Counter()
可以看到LLM类似于对LLMEngine进行了封装,一个LLM对象对应了一个LLMEngine对象。接下来我们解析一下EngineArgs和LLMEngine,首先来看EngineArgs:
# 这段代码定义了一个名为EngineArgs的Python数据类,该类包含vLLM engine 的所有参数。
@dataclass
class EngineArgs:
"""Arguments for vLLM engine."""
model: str # 字符串类型,指定模型的名称。
tokenizer: Optional[str] = None # 可选的字符串类型,用于指定分词器的名称。
tokenizer_mode: str = 'auto' # 字符串类型,指定分词器的模式。
trust_remote_code: bool = False # 布尔类型,是否信任远程代码。
download_dir: Optional[str] = None # 可选的字符串类型,指定模型和分词器的下载路径。
use_np_weights: bool = False # 布尔类型,是否使用numpy权重。
use_dummy_weights: bool = False # 布尔类型,是否使用虚拟权重。
dtype: str = 'auto' # 字符串类型,指定数据类型。
seed: int = 0 # 整型,用于初始化随机数生成器的种子。
worker_use_ray: bool = False # 布尔类型,worker节点是否使用ray库。
pipeline_parallel_size: int = 1 # 整型,指定流水线并行的大小。
tensor_parallel_size: int = 1 # 整型,指定张量并行的大小。
block_size: int = 16 # 整型,指定block_size的大小。
swap_space: int = 4 # GiB
gpu_memory_utilization: float = 0.90 # 浮点型,指定GPU内存使用率。
max_num_batched_tokens: int = 2560 # 整型,指定最大批量token数。
max_num_seqs: int = 256 # 整型,一个 iteration 最多处理多少个tokens。
disable_log_stats: bool = False # 布尔类型,是否禁用日志统计。
# 它在数据类实例化后立即执行。该函数将tokenizer设置为model(如果tokenizer为None),
# 并将max_num_seqs设置为max_num_seqs和max_num_batched_tokens之间的最小值。
def __post_init__(self):
if self.tokenizer is None:
self.tokenizer = self.model
self.max_num_seqs = min(self.max_num_seqs, self.max_num_batched_tokens)
# 它接受一个argparse.ArgumentParser实例,并添加共享的命令行接口参数。
@staticmethod
def add_cli_args(
parser: argparse.ArgumentParser) -> argparse.ArgumentParser:
"""Shared CLI arguments for vLLM engine."""
...
# 根据命令行接口参数创建EngineArgs实例。
@classmethod
def from_cli_args(cls, args: argparse.Namespace) -> 'EngineArgs':
# Get the list of attributes of this dataclass.
attrs = [attr.name for attr in dataclasses.fields(cls)]
# Set the attributes from the parsed arguments.
engine_args = cls(**{attr: getattr(args, attr) for attr in attrs})
return engine_args
# 根据EngineArgs实例的参数创建一组配置(ModelConfig、CacheConfig、
# ParallelConfig和SchedulerConfig)并返回它们。
def create_engine_configs(
self,
) -> Tuple[ModelConfig, CacheConfig, ParallelConfig, SchedulerConfig]:
# Initialize the configs.
# ModelConfig 包括了对 model 和 tokenizer 的定义,dtype 和随机数 seed
# 以及是否用 pretrained weights 还是 dummy weights 等。
model_config = ModelConfig(self.model, self.tokenizer,
self.tokenizer_mode, self.trust_remote_code,
self.download_dir, self.use_np_weights,
self.use_dummy_weights, self.dtype,
# CacheConfig 包括 block_size(每个 block 多大), gpu_utilization(GPU 利用率,
# 后面 allocate 的时候占多少 GPU)和 swap_space(swap 的空间大小)。
# 默认 block_size=16,swap_space=4GiB。
cache_config = CacheConfig(self.block_size,
self.gpu_memory_utilization,
self.swap_space)
# ParallelConfig 包括了 tensor_parallel_size 和 pipeline_parallel_size,
# 即张量并行和流水线并行的 size
parallel_config = ParallelConfig(self.pipeline_parallel_size,
self.tensor_parallel_size,
self.worker_use_ray)
# SchdulerConfig 包括了 max_num_batched_tokens(一个 iteration 最多处理多少个
# tokens),max_num_seqs(一个 iteration 最多能处理多少数量的 sequences)
# 以及 max_seq_len(最大生成多长的 context length,也就是一个 sequence 的最长长度,
# 包含 prompt 部分和 generated 部分)。
scheduler_config = SchedulerConfig(self.max_num_batched_tokens,
self.max_num_seqs,
model_config.get_max_model_len())
return model_config, cache_config, parallel_config, scheduler_config
接下来对LLMEngine进行解析:
class LLMEngine:
"""这段代码定义了一个名为 LLMEngine 的类,它是一个接收请求并生成文本的语言模型(LLM)引擎。
这个类是vLLM引擎的主要类,它从客户端接收请求,并从LLM生成文本。
这个类包含了一个分词器,一个语言模型(可能在多个GPU之间切分),
以及为中间状态(也称为KV缓存)分配的GPU内存空间。
此类使用了迭代级别的调度和有效的内存管理来最大化服务吞吐量。
LLM 类将此类封装用于离线批量推理,而 AsyncLLMEngine 类将此类封装用于在线服务
注意:配置参数源自 EngineArgs 类。有关参数的完整列表,请参见 EngineArgs。
Args:
model_config: 与LLM模型相关的配置。
cache_config: 与KV缓存内存管理相关的配置。
parallel_config: 与分布式执行相关的配置。
scheduler_config: 与分布式执行相关的配置。
distributed_init_method: 分布式执行的初始化方法,参见torch.distributed.init_process_group了解详情。
stage_devices: 每个stage的设备列表. 每个stage都是一个(rank, node_resource, device)元组.
log_stats: 是否记录统计数据。
"""
def __init__(
self,
model_config: ModelConfig,
cache_config: CacheConfig,
parallel_config: ParallelConfig,
scheduler_config: SchedulerConfig,
distributed_init_method: str,
placement_group: Optional["PlacementGroup"],
log_stats: bool,
) -> None:
logger.info(
"Initializing an LLM engine with config: "
f"model={model_config.model!r}, "
f"tokenizer={model_config.tokenizer!r}, "
f"tokenizer_mode={model_config.tokenizer_mode}, "
f"trust_remote_code={model_config.trust_remote_code}, "
f"dtype={model_config.dtype}, "
f"use_dummy_weights={model_config.use_dummy_weights}, "
f"download_dir={model_config.download_dir!r}, "
f"use_np_weights={model_config.use_np_weights}, "
f"tensor_parallel_size={parallel_config.tensor_parallel_size}, "
f"seed={model_config.seed})")
# TODO(woosuk): Print more configs in debug mode.
self.model_config = model_config
self.cache_config = cache_config
self.parallel_config = parallel_config
self.scheduler_config = scheduler_config
self.log_stats = log_stats
self._verify_args()
# 设置tokenizer
self.tokenizer = get_tokenizer(
model_config.tokenizer,
tokenizer_mode=model_config.tokenizer_mode,
trust_remote_code=model_config.trust_remote_code)
self.seq_counter = Counter()
# 对于每个 device(也即每张卡 / 每个 rank)创建一个 Worker。
# Worker 是运行 model 的单位。一个 Engine 管理所有的 workers。
# Create the parallel GPU workers.
if self.parallel_config.worker_use_ray:
self._init_workers_ray(placement_group)
else:
self._init_workers(distributed_init_method)
# 初始化这个 engine 的 KV cache。
# Profile the memory usage and initialize the cache.
self._init_cache()
# Create the scheduler.
self.scheduler = Scheduler(scheduler_config, cache_config)
# Logging.
self.last_logging_time = 0.0
# List of (timestamp, num_tokens)
self.num_prompt_tokens: List[Tuple[float, int]] = []
# List of (timestamp, num_tokens)
self.num_generation_tokens: List[Tuple[float, int]] = []
从LLMEngine的定义可以知道,它做了初始化tokenizer,创建并行的worker信息以及初始化KV Cache等事情,这里的worker是每个GPU对应一个,我们稍后会讲到。我们接着解析一下LLMEngine其它函数:
# _init_workers 这个方法是 LLMEngine 类的一个私有方法,其主要目的是初始化worker。
# 这些worker负责在硬件资源(如GPU)上执行计算任务。
# 这个函数只接受一个参数,即 distributed_init_method,它是一个字符串,用于指定分布式执行的初始化方法。
def _init_workers(self, distributed_init_method: str):
# 从vllm.worker.worker模块中导入Worker类。这个导入操作被放在了函数内部,
# 这样做的目的是为了避免在CUDA_VISIBLE_DEVICES被Worker类设定之前就导入
# 了torch.cuda/xformers,因为那样可能会产生问题。
from vllm.worker.worker import Worker # pylint: disable=import-outside-toplevel
# 断言self.parallel_config.world_size(并行世界的大小)等于1,如果不等于1,
# 则会抛出错误,提示用户需要使用Ray框架进行并行计算。
assert self.parallel_config.world_size == 1, (
"Ray is required if parallel_config.world_size > 1.")
self.workers: List[Worker] = []
# 创建一个新的 Worker 对象,并将其添加到 self.workers 列表中。
# 每个 Worker 对象都需要以下参数:
# self.model_config,self.parallel_config,self.scheduler_config,
# 以及工作节点的 rank(在这个例子中,rank 是0,表示这是第一个,也是唯一的工作节点)
# 和 distributed_init_method。
worker = Worker(
self.model_config,
self.parallel_config,
self.scheduler_config,
0,
distributed_init_method,
)
# 调用_run_workers方法,参数为 "init_model"
# 和 get_all_outputs=True,对所有的worker进行初始化。
self.workers.append(worker)
self._run_workers(
"init_model",
get_all_outputs=True,
)
def _verify_args(self) -> None:
# 这行代码调用model_config对象的verify_with_parallel_config方法来检查模型配置是否与并行配置兼容。
# self.model_config和self.parallel_config分别是ModelConfig和ParallelConfig对象,
# 它们包含了模型和并行计算的相关配置。
self.model_config.verify_with_parallel_config(self.parallel_config)
self.cache_config.verify_with_parallel_config(self.parallel_config)
# _init_cache函数是LLMEngine类的一个私有方法,不接受任何参数,没有返回值。
# 其目标是测量内存使用并初始化KV(键值)Cache。
def _init_cache(self) -> None:
"""Profiles the memory usage and initializes the KV cache."""
# Get the maximum number of blocks that can be allocated on GPU and CPU.
# 使用_run_workers方法来获取可以在GPU和CPU上分配的最大块数量。
# _run_workers函数执行的方法是profile_num_available_blocks,并且提供了如块大小、
# GPU内存使用率和CPU交换空间等参数,所有这些参数都是从cache_config对象中提取出来的。
num_blocks = self._run_workers(
"profile_num_available_blocks",
get_all_outputs=True,
block_size=self.cache_config.block_size,
gpu_memory_utilization=self.cache_config.gpu_memory_utilization,
cpu_swap_space=self.cache_config.swap_space_bytes,
)
# 找到所有workers中可用块的最小值,以确保所有的内存操作都可以应用到所有worker。
# 在这个步骤中,函数分别计算了GPU和CPU的块数量。
num_gpu_blocks = min(b[0] for b in num_blocks)
num_cpu_blocks = min(b[1] for b in num_blocks)
# FIXME(woosuk): Change to debug log.
logger.info(f"# GPU blocks: {num_gpu_blocks}, "
f"# CPU blocks: {num_cpu_blocks}")
# 如果GPU的块数量小于等于0,函数将抛出一个值错误。
# 这是为了确保在初始化引擎时,为缓存块提供足够的可用内存。
if num_gpu_blocks <= 0:
raise ValueError("No available memory for the cache blocks. "
"Try increasing `gpu_memory_utilization` when "
"initializing the engine.")
# 根据计算的块数量,更新cache_config对象的num_gpu_blocks和num_cpu_blocks属性。
self.cache_config.num_gpu_blocks = num_gpu_blocks
self.cache_config.num_cpu_blocks = num_cpu_blocks
# Initialize the cache.
# 使用_run_workers方法初始化缓存。此步骤中的_run_workers执行的方法
# 是init_cache_engine,并且提供了cache_config对象作为参数。
self._run_workers("init_cache_engine", cache_config=self.cache_config)
# from_engine_args是一个类方法(classmethod),这意味着它可以在没有创建类实例的情况下调用。
# 此方法需要接受一个EngineArgs类型的参数engine_args,并返回一个LLMEngine类型的对象。
@classmethod
def from_engine_args(cls, engine_args: EngineArgs) -> "LLMEngine":
"""Creates an LLM engine from the engine arguments."""
# Create the engine configs.
# 利用create_engine_configs方法从engine_args参数中创建引擎配置,该方法返回一个配置的列表,
# 其中包含了model_config、cache_config、parallel_config和scheduler_config。
# 这些配置都是初始化LLMEngine对象所需的。
engine_configs = engine_args.create_engine_configs()
# 提取并保存parallel_config,这是一个关于分布式执行的配置。
parallel_config = engine_configs[2]
# 使用initialize_cluster方法初始化集群,该方法接受parallel_config作为参数并返回两个结果:
# distributed_init_method(分布式执行的初始化方法)和placement_group。
distributed_init_method, placement_group = initialize_cluster(
parallel_config)
# 利用之前创建的引擎配置、初始化方法、放置组以及日志统计设置来创建一个新的LLMEngine对象。
# 这里使用了Python的*操作符,这样可以把列表中的每个元素分别作为单独的参数传递给LLMEngine类
# 的构造方法。log_stats参数用于决定是否需要记录统计数据,如果engine_args.disable_log_stats
# 为True,则不记录统计数据。
engine = cls(*engine_configs,
distributed_init_method,
placement_group,
log_stats=not engine_args.disable_log_stats)
return engine
# add_request函数是LLMEngine类的一个方法,它接受一个请求并将其加入到scheduler的请求池中。
# 这个请求在调用engine.step()函数时由调度器进行处理,具体的调度策略由调度器决定。
def add_request(
self,
request_id: str, # 请求的唯一ID。
prompt: Optional[str], # prompt字符串。如果提供了prompt_token_ids,这个参数可以为None。
sampling_params: SamplingParams, # 用于文本生成的采样参数。
# prompt的token ID。如果它为None,则使用分词器将提示转换为token ID。
prompt_token_ids: Optional[List[int]] = None,
arrival_time: Optional[float] = None, # 请求的到达时间。如果为None,则使用当前时间。
) -> None:
if arrival_time is None:
arrival_time = time.time()
if prompt_token_ids is None:
assert prompt is not None
prompt_token_ids = self.tokenizer.encode(prompt)
# Create the sequences.
# 每一个序列代表一次独立的文本生成任务。它们的数量由sampling_params.best_of决定。
# 每个序列都包含了唯一的seq_id,提示和标记ID,以及block_size(块大小)。
block_size = self.cache_config.block_size
seqs: List[Sequence] = []
for _ in range(sampling_params.best_of):
seq_id = next(self.seq_counter)
seq = Sequence(seq_id, prompt, prompt_token_ids, block_size)
seqs.append(seq)
# 创建序列组(SequenceGroup)。一个序列组包含了一组相关的序列,
# 它们共享相同的请求ID和采样参数,并且在同一时间到达。
seq_group = SequenceGroup(request_id, seqs, sampling_params,
arrival_time)
# Add the sequence group to the scheduler.
# 将序列组添加到调度器中。这样,当调用engine.step()函数时,
# 调度器就可以根据它的调度策略处理这些序列组。
self.scheduler.add_seq_group(seq_group)
# 此函数接受一个请求ID作为参数,并调用调度器的abort_seq_group方法来终止具有该ID的请求。
# 简单地说,这个函数的目的是取消一个特定的请求。
def abort_request(self, request_id: str) -> None:
"""Aborts a request with the given ID.
Args:
request_id: The ID of the request to abort.
"""
self.scheduler.abort_seq_group(request_id)
# 此函数没有参数,并返回当前的模型配置。模型配置是一个ModelConfig对象,
# 包含模型和分词器的配置信息,以及其他可能的模型相关的配置选项。
def get_model_config(self) -> ModelConfig:
"""Gets the model configuration."""
return self.model_config
# 此函数也没有参数,它返回未完成的请求的数量。它通过调用调度器的
# get_num_unfinished_seq_groups方法实现,该方法返回
# 未完成的序列组的数量,因为每个请求都对应一个序列组。
def get_num_unfinished_requests(self) -> int:
"""Gets the number of unfinished requests."""
return self.scheduler.get_num_unfinished_seq_groups()
# 此函数没有参数,并返回一个布尔值,指示是否有未完成的请求。
# 这是通过调用调度器的has_unfinished_seqs方法实现的。
# 如果有未完成的序列,该函数返回True,否则返回False。
def has_unfinished_requests(self) -> bool:
"""Returns True if there are unfinished requests."""
return self.scheduler.has_unfinished_seqs()
# 这个函数是 LLMEngine 类的一个关键函数,其功能是执行一次解码迭代并返回新生成的结果。
# 这个函数的执行过程可以分解为以下步骤:
def step(self) -> List[RequestOutput]:
"""Performs one decoding iteration and returns newly generated results.
This function performs one decoding iteration of the engine. It first
schedules the sequences to be executed in the next iteration and the
token blocks to be swapped in/out/copy. Then, it executes the model
and updates the scheduler with the model outputs. Finally, it decodes
the sequences and returns the newly generated results.
"""
# 首先,调用 self.scheduler.schedule() 进行调度,返回要在下一次迭代中执行的序列,
# 以及要被换入,换出,复制的 token 块。
seq_group_metadata_list, scheduler_outputs = self.scheduler.schedule()
# 然后,检查 scheduler_outputs 是否为空。如果为空并且没有被忽略的序列组,
# 则表示没有需要做的工作,函数返回空列表。如果存在被忽略的序列组,那么我们需要将它们作为请求输出返回。
if scheduler_outputs.is_empty():
if not scheduler_outputs.ignored_seq_groups:
# Nothing to do.
return []
# If there are ignored seq groups, we need to return them as the
# request outputs.
return [
RequestOutput.from_seq_group(seq_group)
for seq_group in scheduler_outputs.ignored_seq_groups
]
# Execute the model.
# 如果 scheduler_outputs 不为空,那么就会执行模型,将 seq_group_metadata_list、
# blocks_to_swap_in、blocks_to_swap_out 和 blocks_to_copy 作为参数传给 _run_workers
# 方法。这一步可能包括将一些状态从内存移到 GPU,执行模型计算,以及将一些状态从 GPU 移回内存。
output = self._run_workers(
"execute_model",
seq_group_metadata_list=seq_group_metadata_list,
blocks_to_swap_in=scheduler_outputs.blocks_to_swap_in,
blocks_to_swap_out=scheduler_outputs.blocks_to_swap_out,
blocks_to_copy=scheduler_outputs.blocks_to_copy,
)
# Update the scheduler with the model outputs.
# 之后,使用模型的输出结果来更新调度器。
seq_groups = self.scheduler.update(output)
# Decode the sequences.
# 然后对序列进行解码,并终止满足停止条件的序列。完成的序列组将被释放。
self._decode_sequences(seq_groups)
# Stop the sequences that meet the stopping criteria.
self._stop_sequences(seq_groups)
# Free the finished sequence groups.
self.scheduler.free_finished_seq_groups()
# Create the outputs.
# 最后,创建输出结果。对于每一个序列组,都将其转换为 RequestOutput 对象
# 并添加到输出列表中。如果 log_stats 为真,那么还会记录系统状态。
request_outputs: List[RequestOutput] = []
for seq_group in seq_groups + scheduler_outputs.ignored_seq_groups:
request_output = RequestOutput.from_seq_group(seq_group)
request_outputs.append(request_output)
if self.log_stats:
# Log the system stats.
self._log_system_stats(scheduler_outputs.prompt_run,
scheduler_outputs.num_batched_tokens)
return request_outputs
# _log_system_stats 函数的主要作用是记录和打印系统状态信息。
# 这些信息可以帮助理解系统的运行状态,包括吞吐量、请求的运行情况以及GPU和CPU的KV缓存使用情况等。
# 这是一个监控和调试工具,用于跟踪系统性能和资源使用情况。
def _log_system_stats(
self,
prompt_run: bool,
num_batched_tokens: int,
) -> None:
now = time.time()
# Log the number of batched input tokens.
# 函数首先记录当前时间,并根据prompt_run值,记录批处理输入标记的数量。
if prompt_run:
self.num_prompt_tokens.append((now, num_batched_tokens))
else:
self.num_generation_tokens.append((now, num_batched_tokens))
# 接下来,函数检查自上次记录日志以来是否已经过了足够的时间(由 _LOGGING_INTERVAL_SEC 定义)。
# 如果时间还没有过去足够,函数就会返回,不进行任何操作。
elapsed_time = now - self.last_logging_time
if elapsed_time < _LOGGING_INTERVAL_SEC:
return
# Discard the old stats.
# 如果已经过了足够的时间,函数会丢弃过旧的统计信息,
# 只保留在 _LOGGING_INTERVAL_SEC 时间窗口内的数据。
self.num_prompt_tokens = [(t, n) for t, n in self.num_prompt_tokens
if now - t < _LOGGING_INTERVAL_SEC]
self.num_generation_tokens = [(t, n)
for t, n in self.num_generation_tokens
if now - t < _LOGGING_INTERVAL_SEC]
# 函数然后计算prompt和genaration的平均吞吐量。
# 这是通过计算在指定时间窗口内处理的标记总数,然后除以时间窗口的长度来实现的。
if len(self.num_prompt_tokens) > 1:
total_num_tokens = sum(n for _, n in self.num_prompt_tokens[:-1])
window = now - self.num_prompt_tokens[0][0]
avg_prompt_throughput = total_num_tokens / window
else:
avg_prompt_throughput = 0.0
if len(self.num_generation_tokens) > 1:
total_num_tokens = sum(n
for _, n in self.num_generation_tokens[:-1])
window = now - self.num_generation_tokens[0][0]
avg_generation_throughput = total_num_tokens / window
else:
avg_generation_throughput = 0.0
# 函数接下来计算 GPU 和 CPU 的 KV 缓存使用情况。这是通过查看已使用的和总的缓存块的数量来实现的。
total_num_gpu_blocks = self.cache_config.num_gpu_blocks
num_free_gpu_blocks = (
self.scheduler.block_manager.get_num_free_gpu_blocks())
num_used_gpu_blocks = total_num_gpu_blocks - num_free_gpu_blocks
gpu_cache_usage = num_used_gpu_blocks / total_num_gpu_blocks
total_num_cpu_blocks = self.cache_config.num_cpu_blocks
if total_num_cpu_blocks > 0:
num_free_cpu_blocks = (
self.scheduler.block_manager.get_num_free_cpu_blocks())
num_used_cpu_blocks = total_num_cpu_blocks - num_free_cpu_blocks
cpu_cache_usage = num_used_cpu_blocks / total_num_cpu_blocks
else:
cpu_cache_usage = 0.0
# 最后,函数使用 logger.info 打印出所有的统计信息,并更新最后一次记录日志的时间。
logger.info("Avg prompt throughput: "
f"{avg_prompt_throughput:.1f} tokens/s, "
"Avg generation throughput: "
f"{avg_generation_throughput:.1f} tokens/s, "
f"Running: {len(self.scheduler.running)} reqs, "
f"Swapped: {len(self.scheduler.swapped)} reqs, "
f"Pending: {len(self.scheduler.waiting)} reqs, "
f"GPU KV cache usage: {gpu_cache_usage * 100:.1f}%, "
f"CPU KV cache usage: {cpu_cache_usage * 100:.1f}%")
self.last_logging_time = now
# 它遍历给定的序列组(seq_groups),并对每个处于运行状态的序列进行解码。
# 通过逐渐解码,它可以有效地处理和更新正在运行的序列,从而支持逐步生成和流式处理的用例。
def _decode_sequences(self, seq_groups: List[SequenceGroup]) -> None:
"""Decodes the sequence outputs."""
# 函数首先遍历传入的序列组列表。每个序列组都包含一组相关的序列。
for seq_group in seq_groups:
# 对于每个序列组,使用get_seqs方法并传入status=SequenceStatus.RUNNING参数,
# 从序列组中选择所有处于运行状态的序列。只有运行状态的序列才需要解码。
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
# 对于每个运行中的序列,函数调用detokenize_incrementally方法,
# 将序列的output_tokens逐渐解码为文本。这个解码过程考虑了最后一个
# 已经解码的标记,以及是否跳过特殊的标记。
# detokenize_incrementally方法返回新解码的token(new_token)
# 和新解码的输出文本(new_output_text)。
new_token, new_output_text = detokenize_incrementally(
self.tokenizer,
seq.output_tokens,
seq.get_last_token_id(),
skip_special_tokens=True,
)
# 如果有新的token被解码(new_token不是None),则将其追加到序列的output_tokens
# 列表中,并更新序列的output_text属性为新解码的文本。
if new_token is not None:
seq.output_tokens.append(new_token)
seq.output_text = new_output_text
# 这个函数_stop_sequences的主要目的是停止已完成的序列。完成可以由几种不同的条件定义,
# 例如序列生成了特定的停止字符串、达到了最大模型长度、达到了最大token数或生成了结束符(EOS)。
def _stop_sequences(self, seq_groups: List[SequenceGroup]) -> None:
"""Stop the finished sequences."""
# 函数开始通过遍历提供的序列组列表,检查每个组中的序列。
for seq_group in seq_groups:
# 当前序列组中获取采样参数sampling_params,它包含此序列组的特定设置,如停止字符串、最大标记数等。
sampling_params = seq_group.sampling_params
# 对于每个序列组,函数筛选出处于运行状态的序列进行处理。
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
# Check if the sequence has generated a stop string.
stopped = False
# 通过遍历sampling_params.stop中的每个停止字符串,
# 检查当前序列的输出文本是否以其中任何一个停止字符串结束。
for stop_str in sampling_params.stop:
if seq.output_text.endswith(stop_str):
# Truncate the output text so that the stop string is
# not included in the output.
# 如果序列以停止字符串结束,函数将截断该字符串,并将序列的状态设置为FINISHED_STOPPED。
seq.output_text = seq.output_text[:-len(stop_str)]
# 一旦找到停止字符串,就不再检查其余的停止字符串,并跳到下一个序列。
self.scheduler.free_seq(
seq, SequenceStatus.FINISHED_STOPPED)
stopped = True
break
if stopped:
continue
# Check if the sequence has reached max_model_len.
# 如果序列的长度大于scheduler_config.max_model_len,则将其状态设置
# 为FINISHED_LENGTH_CAPPED并继续处理下一个序列。
if seq.get_len() > self.scheduler_config.max_model_len:
self.scheduler.free_seq(
seq, SequenceStatus.FINISHED_LENGTH_CAPPED)
continue
# Check if the sequence has reached max_tokens.
# 如果序列的输出长度等于sampling_params.max_tokens,
# 则将其状态设置为FINISHED_LENGTH_CAPPED并继续处理下一个序列。
if seq.get_output_len() == sampling_params.max_tokens:
self.scheduler.free_seq(
seq, SequenceStatus.FINISHED_LENGTH_CAPPED)
continue
# Check if the sequence has generated the EOS token.
# 如果sampling_params.ignore_eos为False,并且序列的最后一个标记ID等于
# 分词器的eos_token_id,则将序列的状态设置为FINISHED_STOPPED并继续。
if not sampling_params.ignore_eos:
if seq.get_last_token_id() == self.tokenizer.eos_token_id:
self.scheduler.free_seq(
seq, SequenceStatus.FINISHED_STOPPED)
continue
def _run_workers(
self,
method: str,
*args,
get_all_outputs: bool = False,
**kwargs,
) -> Any:
"""Runs the given method on all workers."""
# 创建一个名为all_outputs的空列表,用于存储每个worker的输出。
all_outputs = []
# 通过遍历self.workers中的每个工作线程来运行给定的方法。
for worker in self.workers:
# 如果self.parallel_config.worker_use_ray为True,则使用远程执行(Ray框架的一部分)。
if self.parallel_config.worker_use_ray:
executor = partial(worker.execute_method.remote, method)
else:
# 如果为False,则直接在worker上获取和调用方法。
executor = getattr(worker, method)
# 用executor函数运行给定的方法,并将结果添加到all_outputs列表中。
output = executor(*args, **kwargs)
all_outputs.append(output)
# 如果使用了Ray进行远程执行,那么需要使用ray.get来获取远程执行的结果。
if self.parallel_config.worker_use_ray:
all_outputs = ray.get(all_outputs)
# 如果get_all_outputs参数为True,则返回all_outputs列表,其中包括每个worker的输出。
if get_all_outputs:
return all_outputs
# Make sure all workers have the same results.
# 如果为False,则确保所有工作线程的输出都相同,并仅返回第一个工作线程的输出。
output = all_outputs[0]
for other_output in all_outputs[1:]:
assert output == other_output
return output
LLMEngine实现了一个处理序列生成任务的引擎,我们对它的函数进行一个总结:
__init__:通过特定的EngineArgs来初始化LLMEngine,包括初始化tokenizer,创建并行的worker信息以及初始化KV Cache,创建调度器。_init_workers:初始化worker。这些worker负责在硬件资源(如GPU)上执行计算任务,一个GPU对应一个worker。_init_cache:profile gpu内存使用并初始化KV(键值)Cache。from_engine_args:此方法需要接受一个EngineArgs类型的参数engine_args,并返回一个LLMEngine类型的对象。add_request: 它接受一个请求并将其加入到scheduler的请求池中。 这个请求在调用engine.step()函数时由scheduler进行处理,具体的调度策略由scheduler决定。abort_request:终止某个请求id的请求。get_model_config返回当前的模型配置。get_num_unfinished_requests:返回scheduler中未完成的序列组(SequenceGroup)的数量,因为每个请求都对应一个序列组。has_unfinished_requests:scheduler中是否有未完成的序列(Sequence)。step:step 过程先从 scheduler 获取本次要作为输入的seq_group_metadata_list,同时产生一个scheduler_outputs和ignored_seq_groups。然后 engine 会调用 workers 的 execute_model。_log_system_stats:主要作用是记录和打印系统状态信息。这些信息可以帮助理解系统的运行状态,包括吞吐量、请求的运行情况以及GPU和CPU的KV缓存使用情况等。 这是一个监控和调试工具,用于跟踪系统性能和资源使用情况。_decode_sequences:它遍历给定的序列组(seq_groups),并对每个处于运行状态的序列进行解码。_stop_sequences: 这个函数的主要目的是停止已完成的序列。完成可以由几种不同的条件定义,例如序列生成了特定的停止字符串、达到了最大模型长度、达到了最大token数或生成了结束符(EOS)。_run_workers:在step函数中调用,实际上就是在每个GPU上的worker的模型推理。
从LLMEngine实现的函数来看,vllm关键的几个组件scheduler,worker,cache engine已经出现了。这三个组件的解析我们会分别单独开一节,这一节还是以走完整个vllm的generate流程为主旨。继续之前我们再看一下 detokenize_incrementally 这个函数的解析:
# 这个函数 detokenize_incrementally 负责将新token与之前的输出toke一起进行逐渐解码。
# tokenizer: 这是用于解码token的分词器对象.
# prev_output_tokens: 以前已解码的输出token列表。
# new_token_id: 要解码的新token ID。
# skip_special_tokens: 一个布尔值,如果为 True,特殊token将被跳过。
def detokenize_incrementally(
tokenizer: Union[PreTrainedTokenizer, PreTrainedTokenizerFast],
prev_output_tokens: List[str],
new_token_id: int,
skip_special_tokens: bool,
) -> Tuple[str, str]:
"""Detokenizes the new token in conjuction with the previous output tokens.
NOTE: This function does not update prev_output_tokens.
# 返回一个元组,其中包括新token作为字符串和新的输出文本作为字符串。
"""
# 如果 skip_special_tokens 为 True 并且新token ID是特殊令牌,
# 则直接返回 None 和 prev_output_tokens。
if skip_special_tokens and (new_token_id in tokenizer.all_special_ids):
return None, prev_output_tokens
# 使用 tokenizer.convert_ids_to_tokens 方法将新的token ID转换为token字符串。
new_token = tokenizer.convert_ids_to_tokens(
new_token_id, skip_special_tokens=skip_special_tokens)
# 将新token添加到先前的输出token列表中。
output_tokens = prev_output_tokens + [new_token]
# Convert the tokens to a string.
# Optimization: If the tokenizer does not have `added_tokens_encoder`,
# then we can directly use `convert_tokens_to_string`.
if not getattr(tokenizer, "added_tokens_encoder", {}):
# 如果分词器没有 added_tokens_encoder 属性,则可以直接使用
# convert_tokens_to_string 方法将输出token转换为字符串。
output_text = tokenizer.convert_tokens_to_string(output_tokens)
return new_token, output_text
# 否则,需要更复杂的逻辑来处理添加的token和特殊token,这涉及对输出token进行迭代并逐个解析。
# Adapted from
# https://github.com/huggingface/transformers/blob/v4.28.0/src/transformers/tokenization_utils.py#L921
# NOTE(woosuk): The following code is slow because it runs a for loop over
# the output_tokens. In Python, running a for loop over a list can be slow
# even when the loop body is very simple.
# 存储解析的子文本片段的列表。
sub_texts = []
# 存储当前正在处理的token的子文本的列表。
current_sub_text = []
# 对 output_tokens 中的每个token执行迭代。
for token in output_tokens:
# 如果 skip_special_tokens 为 True 并且token是特殊token,则跳过当前迭代。
if skip_special_tokens and token in tokenizer.all_special_tokens:
continue
# 如果token在 tokenizer.added_tokens_encoder 中,则:
if token in tokenizer.added_tokens_encoder:
if current_sub_text:
# 如果 current_sub_text 不为空,则使用 convert_tokens_to_string
# 将其转换为字符串,并将结果添加到 sub_texts 中。
sub_text = tokenizer.convert_tokens_to_string(current_sub_text)
sub_texts.append(sub_text)
# 清空 current_sub_text。
current_sub_text = []
# 将token本身添加到 sub_texts 中。
sub_texts.append(token)
else:
# 如果令牌不是特殊令牌也不是添加的令牌,则将其添加到 current_sub_text 中。
current_sub_text.append(token)
if current_sub_text:
# 如果遍历完成后 current_sub_text 不为空,则转换并添加到 sub_texts 中。
sub_text = tokenizer.convert_tokens_to_string(current_sub_text)
sub_texts.append(sub_text)
# 使用空格将 sub_texts 中的所有子文本连接在一起,形成最终的输出文本。
output_text = " ".join(sub_texts)
return new_token, output_text
接下来继续回到LLM类的generate过程解析:
# 个方法返回存储在类的 llm_engine 属性中的分词器对象。返回类型是 Union[PreTrainedTokenizer,
# PreTrainedTokenizerFast],表示可以返回这两种类型的任何一个。
def get_tokenizer(
self) -> Union[PreTrainedTokenizer, PreTrainedTokenizerFast]:
return self.llm_engine.tokenizer
# 这个方法接收一个参数 tokenizer,类型为 Union[PreTrainedTokenizer,
# PreTrainedTokenizerFast]。这个参数是新的分词器对象,将替换现有的分词器。
def set_tokenizer(
self,
tokenizer: Union[PreTrainedTokenizer, PreTrainedTokenizerFast],
) -> None:
self.llm_engine.tokenizer = tokenizer
# generate 函数是用于根据给定的prompts生成完整文本的核心方法。
def generate(
self,
prompts: Optional[Union[str, List[str]]] = None,
sampling_params: Optional[SamplingParams] = None,
prompt_token_ids: Optional[List[List[int]]] = None,
use_tqdm: bool = True,
) -> List[RequestOutput]:
"""Generates the completions for the input prompts.
NOTE: This class automatically batches the given prompts, considering
the memory constraint. For the best performance, put all of your prompts
into a single list and pass it to this method.
Args:
prompts: A list of prompts to generate completions for.
sampling_params: The sampling parameters for text generation. If
None, we use the default sampling parameters.
prompt_token_ids: A list of token IDs for the prompts. If None, we
use the tokenizer to convert the prompts to token IDs.
use_tqdm: Whether to use tqdm to display the progress bar.
Returns:
A list of `RequestOutput` objects containing the generated
completions in the same order as the input prompts.
"""
# 这段代码确保至少提供了prompts或prompts的token ID之一。
if prompts is None and prompt_token_ids is None:
raise ValueError("Either prompts or prompt_token_ids must be "
"provided.")
# 如果只提供了一个字符串prompts(而不是列表),这段代码将其转换为列表,以便后续处理。
if isinstance(prompts, str):
# Convert a single prompt to a list.
prompts = [prompts]
# 如果同时提供了prompts和prompts token ID,则此代码确保它们的长度相同。
if prompts is not None and prompt_token_ids is not None:
if len(prompts) != len(prompt_token_ids):
raise ValueError("The lengths of prompts and prompt_token_ids "
"must be the same.")
# 如果未提供采样参数,此代码将使用默认参数。
if sampling_params is None:
# Use default sampling params.
sampling_params = SamplingParams()
# Add requests to the engine.
# 此段代码循环遍历prompts或prompt token IDs,并使用它们调用 _add_request 方法
# 将请求添加到引擎。根据是否提供了prompts或token ID,适当地处理了参数。
if prompts is not None:
num_requests = len(prompts)
else:
num_requests = len(prompt_token_ids)
for i in range(num_requests):
prompt = prompts[i] if prompts is not None else None
if prompt_token_ids is None:
token_ids = None
else:
token_ids = prompt_token_ids[i]
self._add_request(prompt, sampling_params, token_ids)
# 此代码调用先前定义的 _run_engine 方法来运行引擎,并返回其输出。
# 这些输出是一个RequestOutput对象的列表,包含生成的完整文本,与输入prompt的顺序相同。
return self._run_engine(use_tqdm)
# LLM模型为 llm_engine 添加一个请求
def _add_request(
self,
prompt: Optional[str],
sampling_params: SamplingParams,
prompt_token_ids: Optional[List[int]],
) -> None:
# 从 self.request_counter 获取下一个值并转换为字符串来创建请求ID。
request_id = str(next(self.request_counter))
# 调用 llm_engine 的 add_request 方法,将请求添加到llm_engine中。
self.llm_engine.add_request(request_id, prompt, sampling_params,
prompt_token_ids)
# 这个函数负责运行 self.llm_engine的step函数,并收集已完成的请求的输出。
def _run_engine(self, use_tqdm: bool) -> List[RequestOutput]:
# Initialize tqdm.
# 如果参数 use_tqdm 为真,则代码初始化一个 tqdm 进度条来跟踪处理进度。
# tqdm 是一个流行的库,用于在命令行中显示循环的进度条。num_requests 是尚未完成的请求的数量。
if use_tqdm:
num_requests = self.llm_engine.get_num_unfinished_requests()
pbar = tqdm(total=num_requests, desc="Processed prompts")
# Run the engine.
outputs: List[RequestOutput] = []
# 主要的循环在引擎有未完成的请求时持续运行。在每个步骤中,通过调用引擎的 step 方法来处理请求。
# 如果输出表示已完成的请求,则将其添加到 outputs 列表中。如果使用 tqdm,进度条将相应地更新。
while self.llm_engine.has_unfinished_requests():
step_outputs = self.llm_engine.step()
for output in step_outputs:
if output.finished:
outputs.append(output)
if use_tqdm:
pbar.update(1)
# 如果使用了 tqdm,此代码段将关闭进度条。
if use_tqdm:
pbar.close()
# Sort the outputs by request ID.
# This is necessary because some requests may be finished earlier than
# its previous requests.
# 输出列表是按完成顺序排列的,这可能与原始请求顺序不同。
# 这一行代码通过请求ID将它们排序,确保输出按原始顺序排列。
outputs = sorted(outputs, key=lambda x: int(x.request_id))
return outputs
现在基本走完了vllm根据prompt,特定模型架构和特定采样参数去生成结果的全流程,我们再对这个流程总结一下。
首先,vllm进来之后先实例化一个LLM对象即:llm = LLM(model="facebook/opt-125m")。然后调用llm.generate函数,这个函数的输入是prompts(List[str]类型),采样参数,然后返回 List[RequestOutput],对应outputs = llm.generate(prompts, sampling_params)这行代码。从llm.generate的实现来看,对于每一个prompt都会生成一个request喂给llm_engine,然后执行_run_engine(这个函数负责运行 llm_engine.step函数,并收集已完成的请求的输出。)函数结束。llm_engine.step函数首先从scheduler获取当前的输入seq_group_metadata_list ,同时生成一个 scheduler_outputs,接下来会调用 workers 的 execute_model来指定模型的前向推理过程,拿到这个结果之后再进行解码(对应self._decode_sequences(seq_groups)这行)。最后scheduler再更新已经解码完毕的序列的状态,并释放序列占用的内存。
接下来,分别对vllm关键的几个组件scheduler,worker,cache engine进行解析。
0x2. worker
在llm_engine的实现中,和worker相关的就是_init_workers和_run_workers函数,_init_workers 用来初始化worker。这些worker负责在硬件资源(如GPU)上执行计算任务,一个GPU对应一个worker。llm_engine通过 _run_workers("<method_name>", *args, get_all_outputs, **kwargs) 来执行给定的方法。如果 get_all_outputs 参数为 True,那么它会将所有 workers 的返回结果包装成 List 来返回。否则,它只会返回第一个 worker 的结果,并且 assert 所有 workers 的输出都是一样的。
接下来我们对worker的实现做一个简要的解析,代码位置在 vllm/vllm/worker/worker.py 。
# 这个Worker类定义了一个执行模型在GPU上的工作单元。每个工作单元都与一个单独的GPU相关联。
# 在分布式推理的情况下,每个工作单元会被分配模型的一个部分。
class Worker:
# 这是类的构造函数,用于初始化Worker对象的新实例。它接受五个参数:
# model_config,parallel_config,scheduler_config,rank和distributed_init_method。
def __init__(
self,
model_config: ModelConfig,
parallel_config: ParallelConfig,
scheduler_config: SchedulerConfig,
rank: Optional[int] = None,
distributed_init_method: Optional[str] = None,
) -> None:
# 存储传入的配置
self.model_config = model_config
self.parallel_config = parallel_config
self.scheduler_config = scheduler_config
self.rank = rank
self.distributed_init_method = distributed_init_method
# 这部分代码设置了与缓存引擎相关的未初始化属性。从注释中可以了解,
# 这些属性将在之后的self.init_cache_engine()方法中进行初始化。
self.cache_config = None
self.block_size = None
self.cache_engine = None
self.cache_events = None
self.gpu_cache = None
# 在worker中初始化模型
def init_model(self):
# This env var set by Ray causes exceptions with graph building.
# 这行代码删除了名为NCCL_ASYNC_ERROR_HANDLING的环境变量。
# 从注释可以看出,这个环境变量会在构建计算图时导致异常。
os.environ.pop("NCCL_ASYNC_ERROR_HANDLING", None)
# Env vars will be set by Ray.
# 这部分代码首先检查self.rank是否已经设定。如果没有设定,它会尝试从环境变量中获取RANK的值。
# 然后,它从环境变量中获取LOCAL_RANK,这通常表示当前节点的编号或ID。
# 最后,它使用此local_rank为worker设置所使用的GPU设备。
self.rank = self.rank if self.rank is not None else int(
os.getenv("RANK", "-1"))
local_rank = int(os.getenv("LOCAL_RANK", "0"))
self.device = torch.device(f"cuda:{local_rank}")
# 这部分代码首先确保工作单元的rank有效。如果rank是一个无效值(小于0),
# 则会引发一个错误。接下来,它将当前CUDA设备设置为之前确定的self.device。
if self.rank < 0:
raise ValueError("Invalid or unspecified rank.")
torch.cuda.set_device(self.device)
# Initialize the distributed environment.
# 使用给定的并行配置、rank和分布式初始化方法来初始化分布式环境。
# 这涉及到设置必要的通信和同步机制以支持分布式训练或推理。
_init_distributed_environment(self.parallel_config, self.rank,
self.distributed_init_method)
# Initialize the model.
# 这里,首先设置随机种子以确保可重现性。然后,使用提供的model_config从
# get_model函数获取模型实例并存储在self.model中。
set_random_seed(self.model_config.seed)
self.model = get_model(self.model_config)
# 该函数主要用于基于配置的GPU和CPU内存约束来估计可以用于缓存块的最大数量。
@torch.inference_mode() # 使用PyTorch的inference_mode来确保在执行此函数时不会跟踪计算图或计算梯度。
# 函数名为profile_num_available_blocks,带有三个参数:块大小、GPU内存利用率和CPU交换空间。
# 函数返回一个包含两个整数的元组,分别代表可用的GPU和CPU块数。
def profile_num_available_blocks(
self,
block_size: int,
gpu_memory_utilization: float,
cpu_swap_space: int,
) -> Tuple[int, int]:
# Profile the memory usage of the model and get the maximum number of
# cache blocks that can be allocated with the remaining free memory.
# 清空CUDA内存缓存并重置内存使用峰值统计信息。
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
# Profile memory usage with max_num_sequences sequences and the total
# number of tokens equal to max_num_batched_tokens.
# Enable top-k sampling to reflect the accurate memory usage.
# 获取模型的词汇表大小,然后设置采样参数。
vocab_size = self.model.config.vocab_size
sampling_params = SamplingParams(top_p=0.99, top_k=vocab_size - 1)
# 从调度器配置中获取max_num_batched_tokens和max_num_seqs。
max_num_batched_tokens = self.scheduler_config.max_num_batched_tokens
max_num_seqs = self.scheduler_config.max_num_seqs
seqs = []
# 这部分代码为每个序列组生成一个SequenceGroupMetadata对象,并收集这些对象以供之后的模型输入准备。
for group_id in range(max_num_seqs):
seq_len = (max_num_batched_tokens // max_num_seqs +
(group_id < max_num_batched_tokens % max_num_seqs))
seq_data = SequenceData([0] * seq_len)
seq = SequenceGroupMetadata(
request_id=str(group_id),
is_prompt=True,
seq_data={group_id: seq_data},
sampling_params=sampling_params,
block_tables=None,
)
seqs.append(seq)
# 使用_prepare_inputs方法准备模型的输入数据。
input_tokens, input_positions, input_metadata = self._prepare_inputs(
seqs)
# Execute the model.
# 这部分代码运行模型来估计其在给定输入上的内存使用情况。
num_layers = self.model_config.get_num_layers(self.parallel_config)
self.model(
input_ids=input_tokens,
positions=input_positions,
kv_caches=[(None, None)] * num_layers,
input_metadata=input_metadata,
cache_events=None,
)
# Calculate the number of blocks that can be allocated with the
# profiled peak memory.
# 基于之前模型执行的内存使用情况来计算可以分配给缓存的块数。
torch.cuda.synchronize()
peak_memory = torch.cuda.max_memory_allocated()
total_gpu_memory = get_gpu_memory()
# 使用CacheEngine.get_cache_block_size方法根据给定的块大小、
# 模型配置和并行配置来计算缓存块的大小。
cache_block_size = CacheEngine.get_cache_block_size(
block_size, self.model_config, self.parallel_config)
# 这行代码计算了可以在GPU上分配的缓存块数量。首先,它考虑了GPU的总内存和指定的GPU内存利用率
#(gpu_memory_utilization)。从这个总量中减去了模型操作的峰值内存使用量,
# 然后将结果除以每个缓存块的大小来得到块的数量。
num_gpu_blocks = int(
(total_gpu_memory * gpu_memory_utilization - peak_memory) //
cache_block_size)
num_cpu_blocks = int(cpu_swap_space // cache_block_size)
num_gpu_blocks = max(num_gpu_blocks, 0)
num_cpu_blocks = max(num_cpu_blocks, 0)
# 再次清空CUDA的内存缓存。
torch.cuda.empty_cache()
# Reset the seed to ensure that the random state is not affected by
# the model initialization and profiling.
# 为确保此函数的执行不会影响模型的随机状态,重置随机种子。
set_random_seed(self.model_config.seed)
# 函数返回可以在GPU和CPU上分配的块数。
return num_gpu_blocks, num_cpu_blocks
# 这个函数的目的是初始化cache enegine
def init_cache_engine(self, cache_config: CacheConfig) -> None:
# 这里我们将cache_config参数(应该是一个缓存配置对象)赋值给该类的
# 成员变量self.cache_config,这样在类的其他部分也可以访问此配置。
self.cache_config = cache_config
# 从缓存配置中获取块大小并将其存储在self.block_size中。
self.block_size = cache_config.block_size
# 使用提供的缓存配置、模型配置和并行配置创建一个新的CacheEngine实例。
# CacheEngine 是一个专门负责处理和管理缓存的类。
self.cache_engine = CacheEngine(self.cache_config, self.model_config,
self.parallel_config)
self.cache_events = self.cache_engine.events
self.gpu_cache = self.cache_engine.gpu_cache
# 为模型准备输入数据
def _prepare_inputs(
self,
seq_group_metadata_list: List[SequenceGroupMetadata],
) -> Tuple[torch.Tensor, torch.Tensor, InputMetadata]:
# 初始化四个空列表,用于存储准备的数据。
seq_groups: List[Tuple[List[int], SamplingParams]] = []
input_tokens: List[int] = []
input_positions: List[int] = []
slot_mapping: List[int] = []
# Add prompt tokens.
# 初始化一个空列表,用于存储提示的长度。
prompt_lens: List[int] = []
# 遍历传入的seq_group_metadata_list列表。
for seq_group_metadata in seq_group_metadata_list:
# 如果当前seq_group_metadata不是提示,则跳过当前迭代。
if not seq_group_metadata.is_prompt:
continue
# 获取当前seq_group_metadata的序列ID和采样参数,并将它们添加到seq_groups列表中。
seq_ids = list(seq_group_metadata.seq_data.keys())
sampling_params = seq_group_metadata.sampling_params
seq_groups.append((seq_ids, sampling_params))
# Use any sequence in the group.
seq_id = seq_ids[0]
seq_data = seq_group_metadata.seq_data[seq_id]
prompt_tokens = seq_data.get_token_ids()
prompt_len = len(prompt_tokens)
prompt_lens.append(prompt_len)
# 将prompt tokens添加到input_tokens列表中,
# 并为每个token添加一个位置到input_positions列表中。
input_tokens.extend(prompt_tokens)
# NOTE(woosuk): Here we assume that the first token in the prompt
# is always the first token in the sequence.
input_positions.extend(range(len(prompt_tokens)))
# 如果当前的seq_group_metadata没有块表,为slot_mapping添加0,并跳过当前迭代。
if seq_group_metadata.block_tables is None:
# During memory profiling, the block tables are not initialized
# yet. In this case, we just use a dummy slot mapping.
slot_mapping.extend([0] * prompt_len)
continue
# Compute the slot mapping.
# 这个代码段计算了如何在内存中布局tokens,它使用了块大小和块表。
block_table = seq_group_metadata.block_tables[seq_id]
for i in range(prompt_len):
block_number = block_table[i // self.block_size]
block_offset = i % self.block_size
slot = block_number * self.block_size + block_offset
slot_mapping.append(slot)
# Add generation tokens.
# 这里初始化了两个整数用于存储最大的上下文长度和序列块表长度的最大值,
# 以及两个列表用于存储上下文的长度和每个生成的序列对应的块表。
max_context_len = 0
max_num_blocks_per_seq = 0
context_lens: List[int] = []
generation_block_tables: List[List[int]] = []
# 对seq_group_metadata_list中的每个seq_group_metadata进行迭代。
for seq_group_metadata in seq_group_metadata_list:
# 如果seq_group_metadata是一个提示,则跳过此次迭代,因为我们在这里只处理生成部分。
if seq_group_metadata.is_prompt:
continue
# 获取序列ID和采样参数,并将它们以元组形式添加到seq_groups列表中。
seq_ids = list(seq_group_metadata.seq_data.keys())
sampling_params = seq_group_metadata.sampling_params
seq_groups.append((seq_ids, sampling_params))
# 遍历每一个序列ID。
for seq_id in seq_ids:
# 对于当前的seq_id,获取其对应的序列数据。
seq_data = seq_group_metadata.seq_data[seq_id]
# 从seq_data获取最后一个token ID并将其添加到input_tokens列表中。
generation_token = seq_data.get_last_token_id()
input_tokens.append(generation_token)
# 取seq_data的长度,并计算位置(为最后一个token的位置),
# 然后将位置添加到input_positions列表中。
context_len = seq_data.get_len()
position = context_len - 1
input_positions.append(position)
# 获取seq_id对应的块表,并将其添加到generation_block_tables列表中。
block_table = seq_group_metadata.block_tables[seq_id]
generation_block_tables.append(block_table)
# 更新max_context_len和max_num_blocks_per_seq的值。
max_context_len = max(max_context_len, context_len)
max_num_blocks_per_seq = max(max_num_blocks_per_seq,
len(block_table))
# 将context_len添加到context_lens列表中。
context_lens.append(context_len)
# 计算当前token在内存中的插槽,并将其添加到slot_mapping列表中。
block_number = block_table[position // self.block_size]
block_offset = position % self.block_size
slot = block_number * self.block_size + block_offset
slot_mapping.append(slot)
# Optimization: Pad the input length to be a multiple of 8.
# This is required for utilizing the Tensor Cores in NVIDIA GPUs.
# 这里使用一个名为_pad_to_alignment的函数来将input_tokens和
# input_positions列表的长度填充到8的倍数。
# 这是一个针对NVIDIA Tensor Cores的优化,可以确保更高的性能。
input_tokens = _pad_to_alignment(input_tokens, multiple_of=8)
input_positions = _pad_to_alignment(input_positions, multiple_of=8)
# Convert to tensors.
# 上述代码将input_tokens和input_positions列表转化为PyTorch在CUDA上的LongTensor张量。
tokens_tensor = torch.cuda.LongTensor(input_tokens)
positions_tensor = torch.cuda.LongTensor(input_positions)
# 然后,slot_mapping和context_lens也被转换为在CUDA上的IntTensor张量。
slot_mapping_tensor = torch.cuda.IntTensor(slot_mapping)
context_lens_tensor = torch.cuda.IntTensor(context_lens)
# 对generation_block_tables中的每个block_table进行迭代,
# 并使用_pad_to_max函数来对其进行填充,确保其长度达到max_num_blocks_per_seq。
padded_block_tables = [
_pad_to_max(block_table, max_num_blocks_per_seq)
for block_table in generation_block_tables
]
# 将填充后的padded_block_tables转换为CUDA上的IntTensor张量。
block_tables_tensor = torch.cuda.IntTensor(padded_block_tables)
# 初始化一个空字典seq_data,然后遍历seq_group_metadata_list来收集所有的seq_data。
seq_data: Dict[int, SequenceData] = {}
for seq_group_metadata in seq_group_metadata_list:
seq_data.update(seq_group_metadata.seq_data)
# 使用收集到的数据来创建InputMetadata对象。
input_metadata = InputMetadata(
seq_groups=seq_groups,
seq_data=seq_data,
prompt_lens=prompt_lens,
slot_mapping=slot_mapping_tensor,
context_lens=context_lens_tensor,
max_context_len=max_context_len,
block_tables=block_tables_tensor,
)
return tokens_tensor, positions_tensor, input_metadata
@torch.inference_mode()
def execute_model(
self,
seq_group_metadata_list: List[SequenceGroupMetadata],
blocks_to_swap_in: Dict[int, int],
blocks_to_swap_out: Dict[int, int],
blocks_to_copy: Dict[int, List[int]],
) -> Dict[int, SequenceOutputs]:
# Issue cache operations.
issued_cache_op = False
if blocks_to_swap_in:
self.cache_engine.swap_in(blocks_to_swap_in)
issued_cache_op = True
if blocks_to_swap_out:
self.cache_engine.swap_out(blocks_to_swap_out)
issued_cache_op = True
if blocks_to_copy:
self.cache_engine.copy(blocks_to_copy)
issued_cache_op = True
if issued_cache_op:
cache_events = self.cache_events
else:
cache_events = None
# If there is no input, we don't need to execute the model.
if not seq_group_metadata_list:
if cache_events is not None:
for event in cache_events:
event.wait()
return {}
# Prepare input tensors.
input_tokens, input_positions, input_metadata = self._prepare_inputs(
seq_group_metadata_list)
# Execute the model.
output = self.model(
input_ids=input_tokens,
positions=input_positions,
kv_caches=self.gpu_cache,
input_metadata=input_metadata,
cache_events=cache_events,
)
return output
def _init_distributed_environment(
parallel_config: ParallelConfig,
rank: int,
distributed_init_method: Optional[str] = None,
) -> None:
"""Initialize the distributed environment."""
if torch.distributed.is_initialized():
torch_world_size = torch.distributed.get_world_size()
if torch_world_size != parallel_config.world_size:
raise RuntimeError(
"torch.distributed is already initialized but the torch world "
"size does not match parallel_config.world_size "
f"({torch_world_size} vs. {parallel_config.world_size}).")
elif not distributed_init_method:
raise ValueError(
"distributed_init_method must be set if torch.distributed "
"is not already initialized")
else:
torch.distributed.init_process_group(
backend="nccl",
world_size=parallel_config.world_size,
rank=rank,
init_method=distributed_init_method,
)
# A small all_reduce for warmup.
torch.distributed.all_reduce(torch.zeros(1).cuda())
initialize_model_parallel(parallel_config.tensor_parallel_size,
parallel_config.pipeline_parallel_size)
def _pad_to_alignment(x: List[int], multiple_of: int) -> List[int]:
return x + [0] * ((-len(x)) % multiple_of)
def _pad_to_max(x: List[int], max_len: int) -> List[int]:
return x + [0] * (max_len - len(x))
我们对worker的几个关键函数进行了解析,总结一下:
init_model:对模型进行初始化。profile_num_available_blocks: 这个函数首先运行一次模型来profile内存峰值占用并以次计算没张卡上的blocks个数。init_cache_engine:初始化 cache engine。execute_model:执行模型。
llm_engine通过 _run_workers("<method_name>", *args, get_all_outputs, **kwargs) 来和上面的三个函数建立起联系。从llm_engine.step函数我们基本可以看到scheduler,worker的关系:
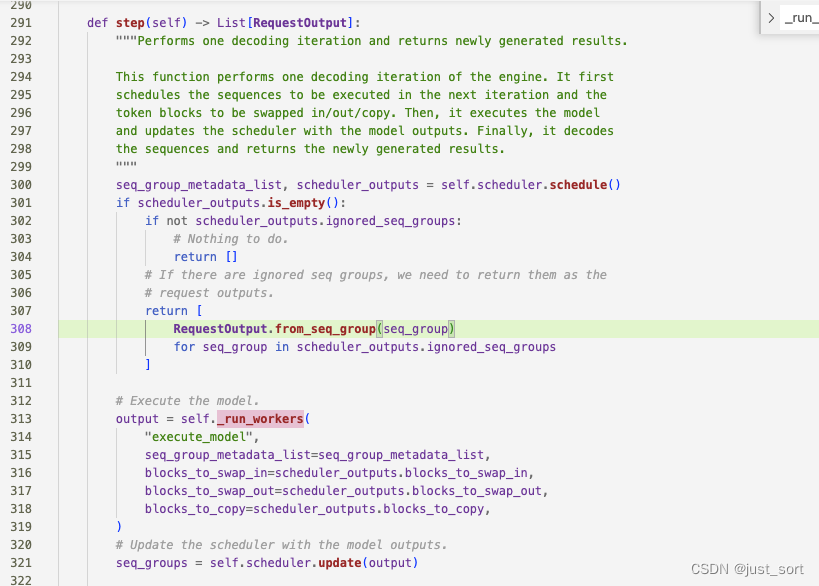 在原始的
在原始的LLM类的genarete函数中,对于每个输入的prompt,都会给 llm engine 生成一个 request并添加到scheduler里。然后调用 _run_engine 函数,这个函数的逻辑是对于所有未完成的 requests,就调用 llm engine 的 step 函数得到这一步的 outputs,然后 append 到返回的 List 里。在step函数里,由scheduler获取本次要作为输入的 seq_group_metadata_list ,同时产生一个 scheduler_outputs。然后 engine 会调用 worker 的 execute_model 来执行对 seq_group_metadata_list 的模型前向计算。
0x3. cache engine
上面的worker实现和普通的PyTorch执行模型前向最大的一个区别是它维护了一个cache engine,它是用管理模型的KV Cache的。下面仍然是对它的实现进行解析,它的实现在vllm/vllm/worker/cache_engine.py这个文件。
KVCache = Tuple[torch.Tensor, torch.Tensor]
# CacheEngine类的主要责任是初始化和管理GPU和CPU上的KV Cache,并为KV Cache 操作如交换和复制提供方法。
class CacheEngine:
"""Manages the KV cache.
This class is responsible for initializing and managing the GPU and CPU KV
caches. It also provides methods for performing KV cache operations, such
as swapping and copying.
"""
# 这个构造函数接受三个参数:cache_config、model_config和parallel_config,
# 分别对应缓存配置、模型配置和并行配置。
def __init__(
self,
cache_config: CacheConfig,
model_config: ModelConfig,
parallel_config: ParallelConfig,
) -> None:
# 下面三行代码保存了传入构造函数的配置信息,供类的其他方法使用。
self.cache_config = cache_config
self.model_config = model_config
self.parallel_config = parallel_config
# 根据模型配置提取了头的大小、层数、头的数量和数据类型,并保存为类的成员变量。
self.head_size = model_config.get_head_size()
self.num_layers = model_config.get_num_layers(parallel_config)
self.num_heads = model_config.get_num_heads(parallel_config)
self.dtype = model_config.dtype
# 这里从缓存配置中获取块的大小、GPU上的块数量和CPU上的块数量。
self.block_size = cache_config.block_size
self.num_gpu_blocks = cache_config.num_gpu_blocks
self.num_cpu_blocks = cache_config.num_cpu_blocks
# Initialize the cache.
# 这两行代码调用了这个类的2个成员函数来分配GPU和CPU缓存,并将结果保存为类的成员变量。
self.gpu_cache = self.allocate_gpu_cache()
self.cpu_cache = self.allocate_cpu_cache()
# Initialize the stream for caching operations.
# 首先创建了一个新的CUDA流并保存。接下来,它使用assert确保新创建的流不是当前的CUDA流。
self.cache_stream = torch.cuda.Stream()
assert self.cache_stream != torch.cuda.current_stream()
# Initialize the events for stream synchronization.
# 这行代码为每层创建了一个CUDA事件,并保存为一个列表。CUDA事件主要用于同步CUDA流。
self.events = [torch.cuda.Event() for _ in range(self.num_layers)]
# 这是CacheEngine类的一个成员函数get_key_block_shape,该函数的目的是返回KV Cache中key block的shape(维度)
def get_key_block_shape(self) -> Tuple[int, int, int, int]:
# torch.tensor([], dtype=self.dtype):创建一个空的Tensor,其数据类型由类的dtype属性指定。
# .element_size():此方法返回该Tensor的数据类型的元素大小(以字节为单位)。
# 例如,如果dtype是torch.float32(即32位浮点数),那么element_size将是4(字节)。
element_size = torch.tensor([], dtype=self.dtype).element_size()
# 这行代码将16除以前面计算得到的element_size(并执行整数除法),得到的结果赋值给变量x。
# 假设dtype是torch.float32(元素大小为4字节),那么x将是4。
x = 16 // element_size
# 这里构建并返回一个由四个整数构成的元组,这些整数描述了key block的形状。具体来说,形状的每个维度如下:
# 头的数量(由类的num_heads属性指定)。
# 头的大小除以x。
# 块的大小(由类的block_size属性指定)。
# x。
return (
self.num_heads,
self.head_size // x,
self.block_size,
x,
)
# 返回value block的形状
def get_value_block_shape(self) -> Tuple[int, int, int]:
return (
self.num_heads,
self.head_size,
self.block_size,
)
# 在GPU上申请key_block和value_block的内存
def allocate_gpu_cache(self) -> List[KVCache]:
gpu_cache: List[KVCache] = []
key_block_shape = self.get_key_block_shape()
value_block_shape = self.get_value_block_shape()
for _ in range(self.num_layers):
key_blocks = torch.empty(
size=(self.num_gpu_blocks, *key_block_shape),
dtype=self.dtype,
device="cuda",
)
value_blocks = torch.empty(
size=(self.num_gpu_blocks, *value_block_shape),
dtype=self.dtype,
device="cuda",
)
gpu_cache.append((key_blocks, value_blocks))
return gpu_cache
# 在CPU上申请key_block和value_block的内存
def allocate_cpu_cache(self) -> List[KVCache]:
cpu_cache: List[KVCache] = []
key_block_shape = self.get_key_block_shape()
value_block_shape = self.get_value_block_shape()
pin_memory = not in_wsl()
if not pin_memory:
# Pinning memory in WSL is not supported.
# https://docs.nvidia.com/cuda/wsl-user-guide/index.html#known-limitations-for-linux-cuda-applications
logger.warning("Using 'pin_memory=False' as WSL is detected. "
"This may slow down the performance.")
for _ in range(self.num_layers):
key_blocks = torch.empty(
size=(self.num_cpu_blocks, *key_block_shape),
dtype=self.dtype,
pin_memory=pin_memory,
)
value_blocks = torch.empty(
size=(self.num_cpu_blocks, *value_block_shape),
dtype=self.dtype,
pin_memory=pin_memory,
)
cpu_cache.append((key_blocks, value_blocks))
return cpu_cache
def _swap(
self,
src: List[KVCache],
dst: List[KVCache],
src_to_dst: Dict[int, int],
) -> None:
with torch.cuda.stream(self.cache_stream):
for i in range(self.num_layers):
src_key_cache, src_value_cache = src[i]
dst_key_cache, dst_value_cache = dst[i]
# Copy the key blocks.
cache_ops.swap_blocks(src_key_cache, dst_key_cache, src_to_dst)
# Copy the value blocks.
cache_ops.swap_blocks(src_value_cache, dst_value_cache,
src_to_dst)
event = self.events[i]
event.record(stream=self.cache_stream)
# paged attention的swap操作,有点像操作系统里的 swap 概念。in 就是 cpu to gpu,
# out 就是 gpu to cpu。内部实现由专门的 cu 函数 swap_blocks 支持。
def swap_in(self, src_to_dst: Dict[int, int]) -> None:
self._swap(self.cpu_cache, self.gpu_cache, src_to_dst)
def swap_out(self, src_to_dst: Dict[int, int]) -> None:
self._swap(self.gpu_cache, self.cpu_cache, src_to_dst)
# paged attention的copy操作,由专门的 cu 函数 copy_blocks 支持。
def copy(self, src_to_dsts: Dict[int, List[int]]) -> None:
key_caches = [key_cache for key_cache, _ in self.gpu_cache]
value_caches = [value_cache for _, value_cache in self.gpu_cache]
# NOTE(woosuk): This operation implicitly synchronizes the CPU and GPU.
cache_ops.copy_blocks(key_caches, value_caches, src_to_dsts)
# 这个函数get_cache_block_size是CacheEngine类的静态方法,用于计算缓存块的大小。
@staticmethod
def get_cache_block_size(
block_size: int,
model_config: ModelConfig,
parallel_config: ParallelConfig,
) -> int:
head_size = model_config.get_head_size()
num_heads = model_config.get_num_heads(parallel_config)
num_layers = model_config.get_num_layers(parallel_config)
key_cache_block = block_size * num_heads * head_size
value_cache_block = key_cache_block
total = num_layers * (key_cache_block + value_cache_block)
dtype_size = _get_dtype_size(model_config.dtype)
return dtype_size * total
def _get_dtype_size(dtype: torch.dtype) -> int:
return torch.tensor([], dtype=dtype).element_size()
Cache Engine根据之前调用workers里面profile 的数据(cpu/gpu blocks数)来申请 cache 内存。然后再给 caching 操作初始化一个 cuda Stream,并且为每个网络层创建了一个CUDA事件,并保存为一个列表。观察到key block的形状为[num_heads, head_size // x, block_size, x],符号的具体含义看上面的注释,这里为什么要// x 还不清楚,后续在cuda实现应该可以找到答案。接着我们看到Paged attention中对KV Cache的经典操作copy,swap_in/out都是由cuda kernel实现然后通过torch extension模块导出的。
接下来对cache相关的cuda算子进行解析。
0x4. Sequence相关的数据结构解析
回顾一下,在原始的LLM类的genarete函数中,对于每个输入的prompt,都会给 llm engine 生成一个 request并添加到scheduler里。然后调用 _run_engine 函数,这个函数的逻辑是对于所有未完成的 requests,就调用 llm engine 的 step 函数得到这一步的 outputs,然后 append 到返回的 List 里。在step函数里,由scheduler获取本次要作为输入的 seq_group_metadata_list ,同时产生一个 scheduler_outputs。然后 engine 会调用 worker 的 execute_model 来执行对 seq_group_metadata_list 的模型前向计算。
这里的对于每个输入prompt,都会给llm engine生成一个request对应了llm_engine.add_request函数:
# add_request函数是LLMEngine类的一个方法,它接受一个请求并将其加入到scheduler的请求池中。
# 这个请求在调用engine.step()函数时由调度器进行处理,具体的调度策略由调度器决定。
def add_request(
self,
request_id: str, # 请求的唯一ID。
prompt: Optional[str], # prompt字符串。如果提供了prompt_token_ids,这个参数可以为None。
sampling_params: SamplingParams, # 用于文本生成的采样参数。
# prompt的token ID。如果它为None,则使用分词器将提示转换为token ID。
prompt_token_ids: Optional[List[int]] = None,
arrival_time: Optional[float] = None, # 请求的到达时间。如果为None,则使用当前时间。
) -> None:
if arrival_time is None:
arrival_time = time.time()
if prompt_token_ids is None:
assert prompt is not None
prompt_token_ids = self.tokenizer.encode(prompt)
# Create the sequences.
# 每一个序列代表一次独立的文本生成任务。它们的数量由sampling_params.best_of决定。
# 每个序列都包含了唯一的seq_id,提示和标记ID,以及block_size(块大小)。
block_size = self.cache_config.block_size
seqs: List[Sequence] = []
for _ in range(sampling_params.best_of):
seq_id = next(self.seq_counter)
seq = Sequence(seq_id, prompt, prompt_token_ids, block_size)
seqs.append(seq)
# 创建序列组(SequenceGroup)。一个序列组包含了一组相关的序列,
# 它们共享相同的请求ID和采样参数,并且在同一时间到达。
seq_group = SequenceGroup(request_id, seqs, sampling_params,
arrival_time)
# Add the sequence group to the scheduler.
# 将序列组添加到调度器中。这样,当调用engine.step()函数时,
# 调度器就可以根据它的调度策略处理这些序列组。
self.scheduler.add_seq_group(seq_group)
可以看到对于每个request vllm都会生成sampling_params.best_of个输出序列,在使用 beam search 时候这个参数也作为 beam width。这里有2个数据结构Sequence和SequenceGroup,对于每一个request我们都会构造sampling_params.best_of个Sequence,然后这些Sequence组成一个SequenceGroup。在构造 Sequence 的时候会给这个 Sequence 分配相应的 logical_token_blocks(是一个List[LogicalTokenBlock])。一个 LogicalTokenBlock对象对应 block_size 个 token ids。初始化的时候会把 token ids 分段存储在 logical blocks里面,但最后一个logical block可能是存不满的。SequenceGroup构造好之后会给到Scheduler(self.scheduler.add_seq_group(seq_group)),然后在llm_engine.step函数中seq_group_metadata_list, scheduler_outputs = self.scheduler.schedule()这行代码会把schdule出来的序列包装成SequenceGroupMetadata。接下来,在执行worker的execute_model函数时会通过_prepare_inputs转成 tokens_tensor,position_tensor 和 InputMetadata,然后execute_model函数实际上包含模型的前向推理和Sample过程,它的返回值数据集结构是Dict[int, SequenceOutputs],也就是 seq id -> 对应的输出,输出包含着 log prob。 这个输出会被传到 scheduler 的 update 接口,用于更新对应的 running sequences。最后这个Dict[int, SequenceOutputs]数据结构对象还会经过_decode_sequences并最终被包装成RequestOutput返回出来。接下来对Sequnence涉及到的数据结构进行代码解析:
"""Sequence and its related classes."""
import copy
import enum
from typing import Dict, List, Optional, Union
from vllm.block import LogicalTokenBlock
from vllm.sampling_params import SamplingParams
# 这行代码定义了一个新的枚举类SequenceStatus,它继承自Python的内置enum.Enum类。
class SequenceStatus(enum.Enum):
"""Status of a sequence."""
# 这些都是序列可能的状态。enum.auto()是一个方便的方法,用于自动分配枚举值。
WAITING = enum.auto() # 序列正在等待运行。
RUNNING = enum.auto() # 序列正在运行。
SWAPPED = enum.auto() # 序列已被交换
FINISHED_STOPPED = enum.auto() # 序列已经完成,并且是因为遇到停止标志而停止的。
FINISHED_LENGTH_CAPPED = enum.auto() # 序列已经完成,并且是因为达到最大长度限制而停止的。
FINISHED_ABORTED = enum.auto() # 序列已经完成,并且是因为某种异常或错误而中止的。
FINISHED_IGNORED = enum.auto() # 序列已经完成,但是被忽略了。
# 这是一个静态方法,接受一个序列状态作为输入,并返回该序列是否已经完成。
# 它通过检查状态是否在完成的状态列表中来做出决策。
@staticmethod
def is_finished(status: "SequenceStatus") -> bool:
return status in [
SequenceStatus.FINISHED_STOPPED,
SequenceStatus.FINISHED_LENGTH_CAPPED,
SequenceStatus.FINISHED_ABORTED,
SequenceStatus.FINISHED_IGNORED,
]
# 这也是一个静态方法,它返回一个序列完成的原因。如果序列没有完成,它返回None。
# 它使用一个简单的条件语句来决定完成的原因。
@staticmethod
def get_finished_reason(status: "SequenceStatus") -> Union[str, None]:
if status == SequenceStatus.FINISHED_STOPPED:
finish_reason = "stop"
elif status == SequenceStatus.FINISHED_LENGTH_CAPPED:
finish_reason = "length"
elif status == SequenceStatus.FINISHED_ABORTED:
finish_reason = "abort"
elif status == SequenceStatus.FINISHED_IGNORED:
finish_reason = "length"
else:
finish_reason = None
return finish_reason
# SequenceData类代表与序列关联的数据。
class SequenceData:
"""Data associated with a sequence.
Args:
prompt_token_ids: The token IDs of the prompt.
Attributes:
prompt_token_ids: The token IDs of the prompt.
output_token_ids: The token IDs of the output.
cumulative_logprob: The cumulative log probability of the output.
"""
# 在初始化方法中,对象接收提示的token IDs(prompt_token_ids)作为参数,并初始化了
# 两个其他属性:输出的token IDs(output_token_ids)和累积的对数概率(cumulative_logprob)。
def __init__(
self,
prompt_token_ids: List[int],
) -> None:
self.prompt_token_ids = prompt_token_ids
self.output_token_ids: List[int] = []
self.cumulative_logprob = 0.0
# 此方法接收一个token ID和其对应的对数概率,然后将token添加到output_token_ids列表,并累积对数概率。
def append_token_id(self, token_id: int, logprob: float) -> None:
self.output_token_ids.append(token_id)
self.cumulative_logprob += logprob
# 这个方法返回整个序列(提示+输出)的长度。
def get_len(self) -> int:
return len(self.output_token_ids) + len(self.prompt_token_ids)
# 此方法仅返回输出的长度。
def get_output_len(self) -> int:
return len(self.output_token_ids)
# 该方法返回整个token ID序列,包括提示和输出。
def get_token_ids(self) -> List[int]:
return self.prompt_token_ids + self.output_token_ids
# 此方法返回整个序列的最后一个token ID。如果没有输出,它会返回提示的最后一个token。
def get_last_token_id(self) -> int:
if not self.output_token_ids:
return self.prompt_token_ids[-1]
return self.output_token_ids[-1]
# 此方法提供了SequenceData对象的字符串表示形式,有助于调试和可读性。
def __repr__(self) -> str:
return (f"SequenceData("
f"prompt_token_ids={self.prompt_token_ids}, "
f"output_token_ids={self.output_token_ids}, "
f"cumulative_logprob={self.cumulative_logprob})")
# 这个类Sequence存储了一个序列的数据、状态和块信息。
class Sequence:
"""Stores the data, status, and block information of a sequence.
Args:
seq_id: The ID of the sequence.
prompt: The prompt of the sequence.
prompt_token_ids: The token IDs of the prompt.
block_size: The block size of the sequence. Should be the same as the
block size used by the block manager and cache engine.
"""
# 对象初始化时需要序列ID、prompt、prompt_token_ids和块大小作为参数。
def __init__(
self,
seq_id: int,
prompt: str,
prompt_token_ids: List[int],
block_size: int,
) -> None:
self.seq_id = seq_id
self.prompt = prompt
self.block_size = block_size
# 它还为序列设置了其他初始属性,如数据(使用SequenceData类)、
# 输出的对数概率、输出的token和输出文本。
self.data = SequenceData(prompt_token_ids)
self.output_logprobs: List[Dict[int, float]] = []
self.output_tokens: List[str] = []
self.output_text = ""
self.logical_token_blocks: List[LogicalTokenBlock] = []
# Initialize the logical token blocks with the prompt token ids.
self._append_tokens_to_blocks(prompt_token_ids)
self.status = SequenceStatus.WAITING
# 为logical_token_blocks列表添加新的LogicalTokenBlock。
def _append_logical_block(self) -> None:
block = LogicalTokenBlock(
block_number=len(self.logical_token_blocks),
block_size=self.block_size,
)
self.logical_token_blocks.append(block)
# 这个方法的目的是将给定的token_ids逐个添加到逻辑token块中。
def _append_tokens_to_blocks(self, token_ids: List[int]) -> None:
# 设置一个cursor变量为0,它用于迭代token_ids列表。
cursor = 0
while cursor < len(token_ids):
# 首先检查是否已经存在任何逻辑token块。如果没有,
# 则调用_append_logical_block方法添加一个新块。
if not self.logical_token_blocks:
self._append_logical_block()
# 获取logical_token_blocks的最后一个块。
last_block = self.logical_token_blocks[-1]
# 如果这个块已经满了(没有空位放置新tokens),那么就添加一个新块。
if last_block.is_full():
self._append_logical_block()
last_block = self.logical_token_blocks[-1]
# 计算上一个块中的空槽数量。
num_empty_slots = last_block.get_num_empty_slots()
# 添加尽可能多的token_ids到最后一个块中,不超过块的容量。
last_block.append_tokens(token_ids[cursor:cursor +
num_empty_slots])
# 更新cursor,使其指向下一个尚未处理的token。
cursor += num_empty_slots
# 将一个token ID及其对应的对数概率添加到序列中:
def append_token_id(
self,
token_id: int,
logprobs: Dict[int, float],
) -> None:
# 断言确保给定的token_id存在于logprobs字典中。
assert token_id in logprobs
# 断言确保给定的token_id存在于logprobs字典中。
self._append_tokens_to_blocks([token_id])
# 将logprobs添加到output_logprobs列表。
self.output_logprobs.append(logprobs)
# 更新data对象,添加token ID和其对数概率。
self.data.append_token_id(token_id, logprobs[token_id])
def get_len(self) -> int: # 返回整个序列的长度。
return self.data.get_len()
def get_output_len(self) -> int: # 返回序列输出的长度。
return self.data.get_output_len()
def get_token_ids(self) -> List[int]: # 返回整个token ID序列。
return self.data.get_token_ids()
def get_last_token_id(self) -> int: # 返回整个序列的最后一个token ID。
return self.data.get_last_token_id()
def get_output_token_ids(self) -> List[int]: # 返回序列输出的token IDs。
return self.data.output_token_ids
def get_cumulative_logprob(self) -> float: # 返回输出的累积对数概率。
return self.data.cumulative_logprob
def is_finished(self) -> bool: # 检查该序列是否已完成。
return SequenceStatus.is_finished(self.status)
# 这个方法用于创建一个当前序列的复制,并将其设置到另一个序列对象中。
# 它会深度复制当前序列的逻辑token块、输出对数概率和数据。
def fork(self, child_seq: "Sequence") -> None:
child_seq.logical_token_blocks = copy.deepcopy(
self.logical_token_blocks)
child_seq.output_logprobs = copy.deepcopy(self.output_logprobs)
child_seq.data = copy.deepcopy(self.data)
# 提供了Sequence对象的字符串表示形式,用于调试和可读性。
def __repr__(self) -> str:
return (f"Sequence(seq_id={self.seq_id}, "
f"status={self.status.name}, "
f"num_blocks={len(self.logical_token_blocks)})")
# 这是一个名为SequenceGroup的类,表示从相同提示生成的一组序列。
class SequenceGroup:
"""SequenceGroup表示从同一提示生成的序列集合。它有以下属性:
Args:
request_id: 请求的ID。
seqs: 序列列表。
sampling_params: 用于生成输出的采样参数。
arrival_time: 请求的到达时间。
"""
# 初始化方法设置了上述描述的属性。当创建一个SequenceGroup对象时,这些属性必须由用户提供。
def __init__(
self,
request_id: str,
seqs: List[Sequence],
sampling_params: SamplingParams,
arrival_time: float,
) -> None:
self.request_id = request_id
self.seqs = seqs
self.sampling_params = sampling_params
self.arrival_time = arrival_time
# 根据给定的状态返回序列列表。
def get_seqs(
self,
status: Optional[SequenceStatus] = None,
) -> List[Sequence]:
# 如果没有提供状态(默认为None),则返回所有序列。
if status is None:
return self.seqs
# 否则,返回具有给定状态的序列。
else:
return [seq for seq in self.seqs if seq.status == status]
# 返回具有给定状态的序列数量。如果没有提供状态,则返回所有序列的数量。
def num_seqs(self, status: Optional[SequenceStatus] = None) -> int:
return len(self.get_seqs(status))
# 在序列组中查找具有给定ID的序列。
def find(self, seq_id: int) -> Sequence:
for seq in self.seqs:
if seq.seq_id == seq_id:
return seq
raise ValueError(f"Sequence {seq_id} not found.")
# 检查序列组中的所有序列是否都已完成。
def is_finished(self) -> bool:
return all(seq.is_finished() for seq in self.seqs)
# 返回SequenceGroup对象的字符串表示形式,通常用于调试和可读性。
# 这将提供关于请求ID、采样参数和序列数量的简要信息。
def __repr__(self) -> str:
return (f"SequenceGroup(request_id={self.request_id}, "
f"sampling_params={self.sampling_params}, "
f"num_seqs={len(self.seqs)})")
# 这是一个名为SequenceGroupMetadata的类,它表示序列组的元数据。
# 这个类的主要目的是为了保存与特定SequenceGroup关联的元数据,可以用来创建InputMetadata。
class SequenceGroupMetadata:
"""Metadata for a sequence group. Used to create `InputMetadata`.
Args:
request_id: The ID of the request.
is_prompt: Whether the request is at prompt stage.
seq_data: The sequence data. (Seq id -> sequence data)
sampling_params: The sampling parameters used to generate the outputs.
block_tables: The block tables. (Seq id -> list of physical block
numbers)
"""
# 初始化方法会接收上述属性作为参数,并将它们设置为类的属性。
# 这意味着当你创建一个SequenceGroupMetadata对象时,必须提供这些参数。
def __init__(
self,
request_id: str,
is_prompt: bool,
seq_data: Dict[int, SequenceData],
sampling_params: SamplingParams,
block_tables: Dict[int, List[int]],
) -> None:
self.request_id = request_id
self.is_prompt = is_prompt
self.seq_data = seq_data
self.sampling_params = sampling_params
self.block_tables = block_tables
# 这是一个名为SequenceOutputs的类,代表与一个序列关联的模型输出。
class SequenceOutputs:
"""The model output associated with a sequence.
Args:
seq_id: The ID of the sequence.
parent_seq_id: The ID of the parent sequence (for forking in beam
search).
output_token: The output token ID.
logprobs: The logprobs of the output token.
(Token id -> logP(x_i+1 | x_0, ..., x_i))
"""
def __init__(
self,
seq_id: int, # 表示序列的ID。
# 表示父序列的ID。在进行如束搜索(beam search)这样的算法时,
# 可能会"分叉"或"分裂"序列,此时,新序列将具有一个"父序列"。
parent_seq_id: int,
output_token: int,
logprobs: Dict[int, float],
) -> None:
self.seq_id = seq_id
self.parent_seq_id = parent_seq_id
self.output_token = output_token # 输出的token ID。
# 这是一个字典,表示输出token的对数概率。键是token的ID,
# 值是给定先前所有token后,下一个token是当前token的对数概率。
self.logprobs = logprobs
def __repr__(self) -> str:
return (f"SequenceOutputs(seq_id={self.seq_id}, "
f"parent_seq_id={self.parent_seq_id}, "
f"output_token={self.output_token}), "
f"logprobs={self.logprobs}")
# 这是一个特殊的方法,允许对象进行等值比较。它定义了当两个SequenceOutputs对象
# 是否应该被认为是"相等"的条件。
def __eq__(self, other: object) -> bool:
if not isinstance(other, SequenceOutputs):
return NotImplemented
return (self.seq_id == other.seq_id
and self.parent_seq_id == other.parent_seq_id
and self.output_token == other.output_token
and self.logprobs == other.logprobs)
对于一个Sequence对象来说,它会被加到一个或者多个LogicalTokenBlock中,我们这里也简单解析一下LogicalTokenBlock和PhysicalTokenBlock的定义代码。
"""Token blocks."""
from typing import List
from vllm.utils import Device
# 这定义了一个私有常数_BLANK_TOKEN_ID,其值为-1。此常数用于在逻辑块中表示空位置。
_BLANK_TOKEN_ID = -1
# 这个类表示了一个逻辑块,其设计用于在KV Cache中代表相应的物理块的状态。
class LogicalTokenBlock:
"""A block that stores a contiguous chunk of tokens from left to right.
Logical blocks are used to represent the states of the corresponding
physical blocks in the KV cache.
"""
def __init__(
self,
block_number: int, # 表示此块的编号。
block_size: int, # 块的大小,即块可以容纳的最大token数量。
) -> None:
self.block_number = block_number
self.block_size = block_size
# 存储在这个块中的token的ID。初始化为_BLANK_TOKEN_ID的列表,长度为block_size。
self.token_ids = [_BLANK_TOKEN_ID] * block_size
# 块中当前token的数量。
self.num_tokens = 0
# 判断块是否为空。如果num_tokens为0,则块为空。
def is_empty(self) -> bool:
return self.num_tokens == 0
# 获取块中的空闲位置数量。这通过块的总大小和当前的token数量计算得出。
def get_num_empty_slots(self) -> int:
return self.block_size - self.num_tokens
# 判断块是否已满。如果num_tokens等于块的大小,则块已满。
def is_full(self) -> bool:
return self.num_tokens == self.block_size
# 将token ID列表追加到块中。函数首先检查新添加的token数量是否超出了块的空闲空间,
# 然后将新的token追加到块中,并更新num_tokens。
def append_tokens(self, token_ids: List[int]) -> None:
assert len(token_ids) <= self.get_num_empty_slots()
curr_idx = self.num_tokens
self.token_ids[curr_idx:curr_idx + len(token_ids)] = token_ids
self.num_tokens += len(token_ids)
# 获取存储在块中的token的ID列表。
def get_token_ids(self) -> List[int]:
return self.token_ids[:self.num_tokens]
# 获取块中的最后一个token的ID。如果块是空的,则会引发断言错误。
def get_last_token_id(self) -> int:
assert self.num_tokens > 0
return self.token_ids[self.num_tokens - 1]
# 这段代码定义了一个名为PhysicalTokenBlock的类。这个类代表KV Cache中一个块的状态。
class PhysicalTokenBlock:
"""Represents the state of a block in the KV cache."""
def __init__(
self,
device: Device,
block_number: int,
block_size: int,
) -> None:
self.device = device # 表示此块所在的设备,如CPU、GPU等。具体类型为Device,
self.block_number = block_number # 这是块的编号,用于识别或索引它。
self.block_size = block_size # 块的大小。这可能代表块可以容纳的数据量。
self.ref_count = 0 # 引用计数,通常用于跟踪有多少其他对象或操作正在引用或使用此物理块
def __repr__(self) -> str:
return (f'PhysicalTokenBlock(device={self.device}, '
f'block_number={self.block_number}, '
f'ref_count={self.ref_count})')
这一节介绍的Sequence相关的数据结构和Block相关的数据结构本质上都是在为Scheduler服务,来一起完成Paged Attention的内存管理功能。下一节我们对Scheduler也叫vllm的调度策略进行解析,它也包含了对在这里定义的Block的管理细节。
0x5. Scheduler
有了上面的铺垫,接下来我们可以对Scheduler进行解析了,对应源码在vllm/vllm/core/scheduler.py。在解析Scheduler的代码实现之前,我们解析一下vllm/vllm/core/目录下的policy.py和block_manager.py,它们分别负责实现Scheduler的队列中的优先法则以及KV Cache块的管理过程,并且实现都非常简单和简短。
首先来看 vllm/vllm/core/policy.py:
# 这是一个抽象的策略类。
class Policy:
# 计算一个 SequenceGroup 的优先级。子类需要重写这个方法来提供具体的优先级计算逻辑。
def get_priority(
self,
now: float,
seq_group: SequenceGroup,
) -> float:
raise NotImplementedError
# 根据优先级对一组 SequenceGroup 进行排序。这是一个通用方法,使用了前面的 get_priority() 方法。
def sort_by_priority(
self,
now: float,
seq_groups: List[SequenceGroup],
) -> List[SequenceGroup]:
return sorted(
seq_groups,
key=lambda seq_group: self.get_priority(now, seq_group),
reverse=True,
)
# 这是 Policy 的一个具体子类,它实现了先到先得(First-Come-First-Serve, FCFS)的调度策略。
# 它重写了 get_priority() 方法,以便为每个 SequenceGroup 分配一个与其到达时间相关的优先级。
# 此处,优先级是当前时间减去序列组的到达时间,这意味着越早到达的 SequenceGroup 优先级越高。
class FCFS(Policy):
def get_priority(
self,
now: float,
seq_group: SequenceGroup,
) -> float:
return now - seq_group.arrival_time
# 这是一个工厂类,用于创建和返回特定的策略对象。它使用一个名为 _POLICY_REGISTRY
# 的字典来注册策略类,其中键是策略的名称(如 'fcfs'),值是相应的策略类。
class PolicyFactory:
_POLICY_REGISTRY = {
'fcfs': FCFS,
}
# get_policy(): 是一个类方法,它接受策略名称作为参数,
# 查找 _POLICY_REGISTRY 字典并返回对应的策略对象实例。
@classmethod
def get_policy(cls, policy_name: str, **kwargs) -> Policy:
return cls._POLICY_REGISTRY[policy_name](**kwargs)
接下来解析一下 vllm/vllm/core/block_manager.py :
"""A block manager that manages token blocks."""
from typing import Dict, List, Optional, Set, Tuple
from vllm.block import PhysicalTokenBlock
from vllm.sequence import Sequence, SequenceGroup, SequenceStatus
from vllm.utils import Device
# 这段代码定义了一个 BlockAllocator 类,它管理设备上的PhysicalTokenBlock的分配和释放
class BlockAllocator:
"""这个类维护了一个空闲块列表,并在请求时分配一个块。当块被释放时,它的引用计数会减少。
当引用计数变为零时,该块会被重新添加到空闲列表中。
"""
# 这是类的初始化方法,当创建 BlockAllocator 的实例时,它会被调用。
# 方法接受三个参数:设备 (device)、块大小 (block_size) 和块数 (num_blocks)。
# 这三个参数分别保存在类的属性中。
def __init__(
self,
device: Device,
block_size: int,
num_blocks: int,
) -> None:
self.device = device
self.block_size = block_size
self.num_blocks = num_blocks
# Initialize the free blocks.
# 这段代码初始化了空闲块列表。它为每个块创建了一个 PhysicalTokenBlock 实例,
# 并添加到 free_blocks 列表中。
self.free_blocks: List[PhysicalTokenBlock] = []
for i in range(num_blocks):
block = PhysicalTokenBlock(device=device,
block_number=i,
block_size=block_size)
self.free_blocks.append(block)
# 这个方法用于分配一个空闲的PhysicalTokenBlock。如果没有可用的空闲块,
# 它会引发一个值错误。分配的块的引用计数被设置为1。
def allocate(self) -> PhysicalTokenBlock:
if not self.free_blocks:
raise ValueError("Out of memory! No free blocks are available.")
block = self.free_blocks.pop()
block.ref_count = 1
return block
# 这个方法释放一个先前分配的块。如果块的引用计数已经是0,它会引发一个值错误,
# 因为这意味着块已经被释放。块的引用计数减少,如果引用计数变为零,块被重新添加到空闲列表中。
def free(self, block: PhysicalTokenBlock) -> None:
if block.ref_count == 0:
raise ValueError(f"Double free! {block} is already freed.")
block.ref_count -= 1
if block.ref_count == 0:
self.free_blocks.append(block)
# 这个方法返回当前可用的空闲块的数量。
def get_num_free_blocks(self) -> int:
return len(self.free_blocks)
# Mapping: logical block number -> physical block.
BlockTable = List[PhysicalTokenBlock]
# BlockTable 是一个类型别名,表示的是从逻辑块号映射到物理块的列表。
class BlockSpaceManager:
"""Manages the mapping between logical and physical token blocks."""
# 这是类的初始化方法,它接受四个参数:块大小 (block_size)、GPU上的块数 (num_gpu_blocks)、
# CPU上的块数 (num_cpu_blocks) 和一个水印值 (watermark)。
# 水印是一个比例,用于确定当GPU块数量低于这个水印值时可能需要采取的措施。
def __init__(
self,
block_size: int,
num_gpu_blocks: int,
num_cpu_blocks: int,
watermark: float = 0.01,
) -> None:
# 这段代码初始化了类的属性,并确保提供的水位值是非负的。
self.block_size = block_size
self.num_total_gpu_blocks = num_gpu_blocks
self.num_total_cpu_blocks = num_cpu_blocks
self.watermark = watermark
assert watermark >= 0.0
# 首先,基于给定的水位值和GPU上的块数,计算出一个整数值的水位块数。
# 然后,为GPU和CPU初始化块分配器。
self.watermark_blocks = int(watermark * num_gpu_blocks)
self.gpu_allocator = BlockAllocator(Device.GPU, block_size,
num_gpu_blocks)
self.cpu_allocator = BlockAllocator(Device.CPU, block_size,
num_cpu_blocks)
# Mapping: seq_id -> BlockTable.
# 这里初始化了一个块映射表,它是一个字典,其键是序列ID (seq_id),
# 值是上面定义的 BlockTable 类型。这个字典将帮助我们跟踪每个序列ID与哪些物理块相关联。
self.block_tables: Dict[int, BlockTable] = {}
# can_allocate 函数接受一个参数 seq_group(类型为 SequenceGroup)并返回一个布尔值。
def can_allocate(self, seq_group: SequenceGroup) -> bool:
# 此注释标识了一个潜在的问题或假设。该注释提到在当前实现中,我们假设在 seq_group
# 中的所有序列共享相同的提示(prompt)。但是,这个假设可能对于被preempted的序列并不成立。
# 由于这是一个 FIXME 注释,它意味着这个问题在未来需要被修复或重新审视。
# FIXME(woosuk): Here we assume that all sequences in the group share
# the same prompt. This may not be true for preempted sequences.
# 这里,代码首先从 seq_group 中获取序列列表并选择第一个序列
#(假设在该组中的所有序列都有相同数量的块)。然后,计算该序列所需的逻辑块数量。
seq = seq_group.get_seqs()[0]
num_required_blocks = len(seq.logical_token_blocks)
# 该行代码调用 gpu_allocator(即GPU块分配器)的 get_num_free_blocks 方法,
# 来得到当前可用的空闲GPU块数量。
num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks()
# Use watermark to avoid frequent cache eviction.
# 此行代码检查当前空闲的GPU块数量是否足以满足序列的需求,
# 并且剩余的块数量是否大于或等于水位块数量(watermark_blocks)。
# 使用水位是为了避免频繁地清除缓存,确保始终有一定数量的块保持空闲。
# 如果满足这些条件,函数返回 True,表示可以为 seq_group 分配所需的块;否则,返回 False。
return (num_free_gpu_blocks - num_required_blocks >=
self.watermark_blocks)
# 这段代码定义了BlockSpaceManager类中的allocate成员函数,
# 该函数用于为给定的seq_group分配PhysicalTokenBlock
def allocate(self, seq_group: SequenceGroup) -> None:
# NOTE: Here we assume that all sequences in the group have the same
# prompt.
# 此行从seq_group中选择了第一个序列。由于之前的注释提到所有的序列都有相同的提示,
# 因此我们可以通过查看第一个序列来确定需要的块数量。
seq = seq_group.get_seqs()[0]
# Allocate new physical token blocks that will store the prompt tokens.
# 首先,初始化一个空的block_table,用于存储分配给序列的PhysicalTokenBlock。
# 然后,根据第一个序列的logical_token_blocks的数量进行循环,为每个logical_token_blocks分配一个PhysicalTokenBlock。
# PhysicalTokenBlock的引用计数被设置为序列组中的序列数量。这可能意味着每个
# PhysicalTokenBlock可以被多个序列共享。每分配一个PhysicalTokenBlock,
# 就将其添加到block_table中。
block_table: BlockTable = []
for _ in range(len(seq.logical_token_blocks)):
block = self.gpu_allocator.allocate()
# Set the reference counts of the token blocks.
block.ref_count = seq_group.num_seqs()
block_table.append(block)
# Assign the block table for each sequence.
# 对于seq_group中的每个序列,将block_table复制并分配给该序列。
# 这意味着,尽管每个序列都有自己的块表副本,但它们都引用同一组PhysicalTokenBlock。
for seq in seq_group.get_seqs():
self.block_tables[seq.seq_id] = block_table.copy()
# 此函数是BlockSpaceManager类的一个成员函数,名为can_append_slot。
# 它决定是否可以为给定的seq_group追加一个新的token块(slot)。
# 函数的逻辑是基于一个简单的启发式方法:如果有足够的自由块(free blocks)
# 来满足序列组中每个序列的需求,那么就可以追加。
def can_append_slot(self, seq_group: SequenceGroup) -> bool:
# Simple heuristic: If there is at least one free block
# for each sequence, we can append.
# 此行从gpu_allocator获取GPU上当前的空闲块数量,并将其存储在num_free_gpu_blocks变量中。
num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks()
# 使用num_seqs方法,函数从seq_group获取当前状态为RUNNING的序列数量。
num_seqs = seq_group.num_seqs(status=SequenceStatus.RUNNING)
# 函数返回一个布尔值,这个布尔值是基于一个简单的判断:
# 如果当前RUNNING状态的序列数量num_seqs小于或等于GPU上的空闲块数量num_free_gpu_blocks,
# 则返回True(表示可以追加新的slot),否则返回False。
return num_seqs <= num_free_gpu_blocks
# 这段代码定义了BlockSpaceManager类中的append_slot函数,
# 该函数的主要目标是为一个新的token分配一个物理slot。
def append_slot(self, seq: Sequence) -> Optional[Tuple[int, int]]:
"""Allocate a physical slot for a new token."""
# 从输入的序列seq中提取逻辑块,并从块表中获取与该序列ID关联的块表。
logical_blocks = seq.logical_token_blocks
block_table = self.block_tables[seq.seq_id]
# 如果块表的长度小于逻辑块的数量,这意味着序列有一个新的逻辑块。
# 因此,分配一个新的物理块并将其添加到块表中。
if len(block_table) < len(logical_blocks):
# The sequence has a new logical block.
# Allocate a new physical block.
block = self.gpu_allocator.allocate()
block_table.append(block)
return None
# We want to append the token to the last physical block.
# 获取块表中的最后一个块,并确保它在GPU设备上。
last_block = block_table[-1]
assert last_block.device == Device.GPU
# 如果最后一个块的引用计数为1,这意味着它不与其他序列共享,因此可以直接追加token。
if last_block.ref_count == 1:
# Not shared with other sequences. Appendable.
return None
else:
# The last block is shared with other sequences.
# Copy on Write: Allocate a new block and copy the tokens.
# 如果最后一个块与其他序列共享,我们将使用“Copy on Write”策略:
# 为新的token分配一个新的块,并复制旧块中的tokens。
# 然后,释放旧块,并在块表中更新块的引用。
# 函数返回旧块和新块的块编号,以便外部调用者知道哪些块已更改。
new_block = self.gpu_allocator.allocate()
block_table[-1] = new_block
self.gpu_allocator.free(last_block)
return last_block.block_number, new_block.block_number
# 这段代码定义了BlockSpaceManager类中的fork方法,该方法的目的是为子序列创建一个块表,
# 该表是基于其父序列的块表的副本。此函数确保每个物理块的引用计数在分叉时正确地增加,
# 这是因为两个序列(父序列和子序列)现在共享相同的物理块。
def fork(self, parent_seq: Sequence, child_seq: Sequence) -> None:
# NOTE: fork does not allocate a new physical block.
# Thus, it is always safe from OOM.
# 从块表映射中,根据父序列的ID获取其块表。
src_block_table = self.block_tables[parent_seq.seq_id]
# 为子序列创建一个新的块表,这个块表是父序列块表的一个副本。这
# 意味着父序列和子序列现在都引用相同的物理块,但是它们有各自独立的逻辑块。
self.block_tables[child_seq.seq_id] = src_block_table.copy()
# 由于子序列现在也引用相同的物理块,所以需要增加每个物理块的引用计数。
# 这确保了物理块不会在它仍然被使用时被意外释放。
for block in src_block_table:
block.ref_count += 1
# 这段代码定义了BlockSpaceManager类中的一个私有方法_get_physical_blocks,
# 它的目的是获取一个SequenceGroup内部所有序列所使用的所有物理块,而没有重复。
# 这个方法接受一个SequenceGroup对象作为参数,并返回一个PhysicalTokenBlock对象的列表。
def _get_physical_blocks(
self, seq_group: SequenceGroup) -> List[PhysicalTokenBlock]:
# 这个注释提到一个关键的假设:物理块只能在同一组内的序列之间共享。
# 这意味着不同组之间的序列不会共享相同的物理块。
# NOTE: Here, we assume that the physical blocks are only shared by
# the sequences in the same group.
# 这里使用了一个集合(set)来存储物理块,因为集合不允许有重复的元素。
# 这样可以确保,即使多个序列引用同一个物理块,该块也只会在集合中出现一次。
blocks: Set[PhysicalTokenBlock] = set()
# 首先,对序列组内的每个序列进行遍历。
for seq in seq_group.get_seqs():
# 使用seq.is_finished()来检查该序列是否已完成。如果已完成,那么我们跳过这个序列,继续下一个。
if seq.is_finished():
continue
# 如果该序列没有完成,我们从self.block_tables中获取与该序列ID关联的块表。
block_table = self.block_tables[seq.seq_id]
# 遍历这个块表中的每个物理块,并将其添加到blocks集合中。
# 由于使用了集合,重复的块不会被多次添加。
for block in block_table:
blocks.add(block)
return list(blocks)
# 这段代码定义了BlockSpaceManager类中的一个方法can_swap_in,
# 这个方法的目的是确定给定的SequenceGroup是否可以被交换到GPU中。
# 该方法接受一个SequenceGroup对象作为参数,并返回一个布尔值,
# 表示该SequenceGroup是否可以被交换到GPU中。
def can_swap_in(self, seq_group: SequenceGroup) -> bool:
# 使用之前定义的_get_physical_blocks方法来获取seq_group中所有序列所使用的物理块的列表。
blocks = self._get_physical_blocks(seq_group)
# 计算seq_group中状态为SWAPPED的序列的数量。
num_swapped_seqs = seq_group.num_seqs(status=SequenceStatus.SWAPPED)
# 使用gpu_allocator来获取当前可用于GPU的空闲块的数量。
num_free_blocks = self.gpu_allocator.get_num_free_blocks()
# NOTE: Conservatively, we assume that every sequence will allocate
# at least one free block right after the swap-in.
# NOTE: This should match the logic in can_append_slot().
# 这里的逻辑有两个关键的假设:
# 1. 每一个被交换进来的序列都会在交换后立即分配至少一个空闲块。
# 2. 这种分配逻辑应该与can_append_slot()中的逻辑匹配。
# 因此,为了确定我们是否有足够的块来满足这个要求,我们需要将当前物理块的数量
# 与SWAPPED状态的序列的数量相加
num_required_blocks = len(blocks) + num_swapped_seqs
# 最终的决策是基于空闲块的数量是否超过所需块的数量加上一个阈值self.watermark_blocks。
# 如果是,则返回True,表示该SequenceGroup可以被交换到GPU中;否则,返回False。
return num_free_blocks - num_required_blocks >= self.watermark_blocks
# 这个函数是BlockSpaceManager类的swap_in方法,其作用是将一个序列组(seq_group)从CPU交换到GPU,
# 并为此过程中涉及的每个CPU块与GPU块创建映射关系。
def swap_in(self, seq_group: SequenceGroup) -> Dict[int, int]:
# CPU block -> GPU block.
# 这里初始化一个字典来记录从CPU块到GPU块的映射关系。
mapping: Dict[PhysicalTokenBlock, PhysicalTokenBlock] = {}
# 遍历SequenceGroup中的每一个序列。如果这个序列已经完成,我们就跳过它。
for seq in seq_group.get_seqs():
if seq.is_finished():
continue
# 这里我们为当前的序列初始化一个新的GPU块表。block_table是原来与这个序列关联的CPU块列表。
new_block_table: BlockTable = []
block_table = self.block_tables[seq.seq_id]
# 对于每个CPU块:
for cpu_block in block_table:
# 我们首先检查它是否已经有一个关联的GPU块(通过mapping字典)。
# 如果有,我们简单地增加这个GPU块的引用计数。
if cpu_block in mapping:
gpu_block = mapping[cpu_block]
gpu_block.ref_count += 1
else:
# 如果没有,则为该CPU块分配一个新的GPU块,并在mapping字典中记录这种关联。
gpu_block = self.gpu_allocator.allocate()
mapping[cpu_block] = gpu_block
# 把新的GPU块添加到new_block_table列表中。
new_block_table.append(gpu_block)
# Free the CPU block swapped in to GPU.
# 释放原来的CPU块,因为我们现在在GPU上有了一个拷贝。
self.cpu_allocator.free(cpu_block)
# 我们使用新的GPU块列表更新当前序列的块映射。
self.block_tables[seq.seq_id] = new_block_table
# 在这个方法的最后,我们创建并返回一个新的映射,这个映射使用块号
#(而不是块对象)来表示从CPU块到GPU块的关联。这样的表示方式可能更加方便和简洁。
block_number_mapping = {
cpu_block.block_number: gpu_block.block_number
for cpu_block, gpu_block in mapping.items()
}
return block_number_mapping
# 这个方法是BlockSpaceManager类中的一个成员函数,其名称为can_swap_out。
# 其作用是判断是否可以将指定的seq_group(序列组)从GPU交换出到CPU。
def can_swap_out(self, seq_group: SequenceGroup) -> bool:
# 首先,使用内部方法_get_physical_blocks获取序列组seq_group当前在GPU上的所有物理块。
blocks = self._get_physical_blocks(seq_group)
# 这里检查序列组中的物理块数量是否小于或等于CPU上的空闲块数量。
# 这确保我们有足够的空间在CPU上容纳所有要交换的块。
return len(blocks) <= self.cpu_allocator.get_num_free_blocks()
# 这个swap_out方法是BlockSpaceManager类的成员函数。其核心功能是从GPU将特定的seq_group
#(序列组)交换出到CPU。在此过程中,方法还返回一个字典,
# 说明GPU上的块号与交换到CPU上的块号之间的映射关系。
def swap_out(self, seq_group: SequenceGroup) -> Dict[int, int]:
# GPU block -> CPU block.
# 这是一个映射字典,其键是在GPU上的块,值是在CPU上的块。
mapping: Dict[PhysicalTokenBlock, PhysicalTokenBlock] = {}
# 为了交换整个序列组,我们遍历其中的每一个序列。
for seq in seq_group.get_seqs():
# 如果当前序列已经完成,则跳过该序列,继续处理下一个。
if seq.is_finished():
continue
new_block_table: BlockTable = []
block_table = self.block_tables[seq.seq_id]
# 我们现在开始处理每一个在GPU上的块。
for gpu_block in block_table:
# 如果当前GPU块已经有一个映射到CPU的块,我们增加该CPU块的引用计数。
if gpu_block in mapping:
cpu_block = mapping[gpu_block]
cpu_block.ref_count += 1
else:
# 如果当前GPU块不在映射中,我们在CPU上为其分配一个新块,
# 并将此映射关系添加到mapping字典中。
cpu_block = self.cpu_allocator.allocate()
mapping[gpu_block] = cpu_block
# 我们将新分配或已映射的CPU块添加到new_block_table中。
new_block_table.append(cpu_block)
# Free the GPU block swapped out to CPU.
# 当一个GPU块被成功交换到CPU上后,我们释放该GPU块,使其可以被其他数据使用。
self.gpu_allocator.free(gpu_block)
# 我们用新的new_block_table更新当前序列的块映射。
self.block_tables[seq.seq_id] = new_block_table
# 最后,我们创建一个块号的映射字典,其键是GPU块号,值是CPU块号。
block_number_mapping = {
gpu_block.block_number: cpu_block.block_number
for gpu_block, cpu_block in mapping.items()
}
return block_number_mapping
# 这是一个私有方法(由下划线_开始,通常表示这个方法是内部方法,不应该在类的外部直接调用),
# 名为_free_block_table,它的主要任务是释放提供的块表(block_table)中的块。
def _free_block_table(self, block_table: BlockTable) -> None:
for block in block_table:
if block.device == Device.GPU:
self.gpu_allocator.free(block)
else:
self.cpu_allocator.free(block)
# 它的主要任务是释放与指定seq(一个Sequence对象)相关的资源
def free(self, seq: Sequence) -> None:
if seq.seq_id not in self.block_tables:
# Already freed or haven't been scheduled yet.
return
block_table = self.block_tables[seq.seq_id]
self._free_block_table(block_table)
del self.block_tables[seq.seq_id]
# 这个方法的目的是重置BlockSpaceManager的状态,释放所有与之相关的块,并清空block_tables字典。
def reset(self) -> None:
for block_table in self.block_tables.values():
self._free_block_table(block_table)
self.block_tables.clear()
# 这个方法的目的是根据给定的seq(一个Sequence对象),返回与该序列关联的块表中所有块的块编号。
def get_block_table(self, seq: Sequence) -> List[int]:
block_table = self.block_tables[seq.seq_id]
return [block.block_number for block in block_table]
# 这个方法返回当前可用的GPU块的数量。
def get_num_free_gpu_blocks(self) -> int:
return self.gpu_allocator.get_num_free_blocks()
# 这个方法返回当前可用的CPU块的数量。
def get_num_free_cpu_blocks(self) -> int:
return self.cpu_allocator.get_num_free_blocks()
vllm/vllm/core/目录下的policy.py和block_manager.py这两个文件为Scheduler定义了队列优先出队的规则即时间优先,换句话说就是先到达的请求先出队被推理。然后BlockSpaceManager定义了Paged Attention中对一个SequenceGroup来说物理块是怎么申请的,以及逻辑块和物理块是怎么映射的,最后还实现了swap_in,swap_out 等在CPU/GPU移动物理块的函数。接下来我们对scheduler.py进行解析,梳理清楚它的调度逻辑:
import enum
import time
from typing import Dict, List, Optional, Tuple
from vllm.config import CacheConfig, SchedulerConfig
from vllm.core.block_manager import BlockSpaceManager
from vllm.core.policy import PolicyFactory
from vllm.logger import init_logger
from vllm.sequence import (Sequence, SequenceData, SequenceGroup,
SequenceGroupMetadata, SequenceOutputs,
SequenceStatus)
logger = init_logger(__name__)
# 这定义了一个新的枚举类PreemptionMode,它继承自Python的内置enum.Enum类。
# PreemptionMode枚举为预占模式提供了一个明确的类型化表示,有两种可选的模式:SWAP和RECOMPUTE。
class PreemptionMode(enum.Enum):
# 这是一段解释预占模式的文档字符串。它描述了两种不同的预占模式:
# Swapping: 当序列被抢占时,将其块交换到CPU内存中,并在恢复序列时将它们再次交换回来。
# Recomputation: 当序列被抢占时,丢弃其块,并在恢复序列时重新计算它们,将序列视为新的提示。
"""Preemption modes.
1. Swapping: Swap out the blocks of the preempted sequences to CPU memory
and swap them back in when the sequences are resumed.
2. Recomputation: Discard the blocks of the preempted sequences and
recompute them when the sequences are resumed, treating the sequences as
new prompts.
"""
SWAP = enum.auto()
RECOMPUTE = enum.auto()
# 这段代码定义了一个名为SchedulerOutputs的类。该类似乎旨在为某种调度操作提供输出或结果。
class SchedulerOutputs:
def __init__(
self,
scheduled_seq_groups: List[SequenceGroup], # 被调度的序列组的列表。
prompt_run: bool, # 一个布尔值,可能表示是否根据给定的提示执行了某种运行。
num_batched_tokens: int, # 批处理的token数。
blocks_to_swap_in: Dict[int, int],
blocks_to_swap_out: Dict[int, int],
blocks_to_copy: Dict[int, List[int]],
ignored_seq_groups: List[SequenceGroup], # 被忽略的序列组的列表。
) -> None:
self.scheduled_seq_groups = scheduled_seq_groups
self.prompt_run = prompt_run
self.num_batched_tokens = num_batched_tokens
self.blocks_to_swap_in = blocks_to_swap_in
self.blocks_to_swap_out = blocks_to_swap_out
self.blocks_to_copy = blocks_to_copy
# Swap in and swap out should never happen at the same time.
assert not (blocks_to_swap_in and blocks_to_swap_out)
self.ignored_seq_groups = ignored_seq_groups
def is_empty(self) -> bool:
# NOTE: We do not consider the ignored sequence groups.
return (not self.scheduled_seq_groups and not self.blocks_to_swap_in
and not self.blocks_to_swap_out and not self.blocks_to_copy)
class Scheduler:
def __init__(
self,
# scheduler_config: 调度器的配置,类型为 SchedulerConfig。
scheduler_config: SchedulerConfig,
# cache_config: 缓存的配置,类型为 CacheConfig。
cache_config: CacheConfig,
) -> None:
self.scheduler_config = scheduler_config
self.cache_config = cache_config
# Instantiate the scheduling policy.
# 使用 PolicyFactory 的 get_policy 方法为调度策略分配一个实例。
# 这里固定选择了 "fcfs"(可能表示"先来先服务")策略。
self.policy = PolicyFactory.get_policy(policy_name="fcfs")
# Create the block space manager.
# 创建一个 BlockSpaceManager 的实例,该实例管理数据块的空间。
# 它使用 cache_config 中的配置数据,包括块大小、GPU块数和CPU块数。
self.block_manager = BlockSpaceManager(
block_size=self.cache_config.block_size,
num_gpu_blocks=self.cache_config.num_gpu_blocks,
num_cpu_blocks=self.cache_config.num_cpu_blocks,
)
# Sequence groups in the WAITING state.
self.waiting: List[SequenceGroup] = []
# Sequence groups in the RUNNING state.
self.running: List[SequenceGroup] = []
# Sequence groups in the SWAPPED state.
self.swapped: List[SequenceGroup] = []
# 这个函数是 Scheduler 类的成员函数,用于将新的 SequenceGroup 添加到等待队列中。
def add_seq_group(self, seq_group: SequenceGroup) -> None:
# Add sequence groups to the waiting queue.
self.waiting.append(seq_group)
# 该函数是 Scheduler 类的成员函数,用于根据提供的 request_id 中止一个 SequenceGroup。
def abort_seq_group(self, request_id: str) -> None:
# 这是一个外层循环,它遍历三个队列:等待、运行和交换。
# 这意味着它会检查所有的 SequenceGroup,无论它们处于哪种状态。
for state_queue in [self.waiting, self.running, self.swapped]:
# 这是一个内部循环,遍历当前状态队列中的每一个 SequenceGroup
for seq_group in state_queue:
if seq_group.request_id == request_id:
# Remove the sequence group from the state queue.
state_queue.remove(seq_group)
for seq in seq_group.seqs:
if seq.is_finished():
continue
self.free_seq(seq, SequenceStatus.FINISHED_ABORTED)
return
# 如果三个队列中的任何一个非空,那么这意味着仍有未完成的序列,函数返回True,否则返回False。
def has_unfinished_seqs(self) -> bool:
return self.waiting or self.running or self.swapped
# 该方法返回三个队列(waiting, running, swapped)中的SequenceGroup的总数。
# 它通过取每个队列的长度并将它们加在一起来做到这一点。
def get_num_unfinished_seq_groups(self) -> int:
return len(self.waiting) + len(self.running) + len(self.swapped)
# 这个函数是Scheduler类中的一个复杂的私有方法,它尝试安排SequenceGroup实例的执行,
# 可能需要进行资源的分配、替换和拷贝。函数的主要目的是返回一个SchedulerOutputs对象,
# 它包含了执行的相关信息。
def _schedule(self) -> SchedulerOutputs:
# Blocks that need to be swaped or copied before model execution.
# 初始化几个字典,用于跟踪需要在模型执行前需要换入,换出,复制的块
blocks_to_swap_in: Dict[int, int] = {}
blocks_to_swap_out: Dict[int, int] = {}
blocks_to_copy: Dict[int, List[int]] = {}
# Fix the current time.
# 获取当前时间,这可能会被用来决定哪些任务应该被优先调度。
now = time.time()
# Join waiting sequences if possible.
# 检查是否有序列组被交换到CPU。如果没有,尝试合并等待中的序列。
if not self.swapped:
ignored_seq_groups: List[SequenceGroup] = []
scheduled: List[SequenceGroup] = []
num_batched_tokens = 0
# Optimization: We do not sort the waiting queue since the preempted
# sequence groups are added to the front and the new sequence groups
# are added to the back.
# 当等待队列不为空时,获取队列中的第一个序列组。
while self.waiting:
seq_group = self.waiting[0]
# 获取当前序列组中的第一个序列的长度(tokens数量)。
num_prompt_tokens = seq_group.get_seqs()[0].get_len()
# 计算允许的最大prompt长度。
prompt_limit = min(
self.scheduler_config.max_model_len,
self.scheduler_config.max_num_batched_tokens)
# 如果当前序列超过了上述限制,发出警告并将该序列组标记为被忽略。
if num_prompt_tokens > prompt_limit:
logger.warning(
f"Input prompt ({num_prompt_tokens} tokens) is too long"
f" and exceeds limit of {prompt_limit}")
for seq in seq_group.get_seqs():
seq.status = SequenceStatus.FINISHED_IGNORED
ignored_seq_groups.append(seq_group)
self.waiting.pop(0)
break
# If the sequence group cannot be allocated, stop.
# 检查是否有足够的块空间来为该序列组分配资源。
if not self.block_manager.can_allocate(seq_group):
break
# 这里检查已经批处理的token数量(num_batched_tokens)加上当前序列组
#(seq_group)的token数量(num_prompt_tokens)是否超过了配置中的
# 最大token限制。如果超过了,循环就会中断。
if (num_batched_tokens + num_prompt_tokens >
self.scheduler_config.max_num_batched_tokens):
break
# 这里获取等待状态下的序列数。
num_new_seqs = seq_group.num_seqs(
status=SequenceStatus.WAITING)
# 这里计算了当前正在运行状态的所有序列组中的序列数量。
num_curr_seqs = sum(
seq_group.num_seqs(status=SequenceStatus.RUNNING)
for seq_group in self.running)
# 检查当前正在运行的序列数量和新的序列数量的总和是否超过配置中的最大序列限制。
# 如果超过了,循环就会中断。
if (num_curr_seqs + num_new_seqs >
self.scheduler_config.max_num_seqs):
break
# 从等待队列的前端移除并获取一个序列组。
seq_group = self.waiting.pop(0)
# 为从等待队列中获取的序列组分配资源。
self._allocate(seq_group)
# 将这个序列组添加到正在运行的队列中。
self.running.append(seq_group)
# 更新已批处理的token数量,加上当前序列组的token数量。
num_batched_tokens += num_prompt_tokens
# 将这个序列组添加到已调度的队列中。
scheduled.append(seq_group)
# 这里检查scheduled列表是否不为空。scheduled列表保存了在当前调度周期中被成功调度的序列组。
if scheduled:
# 这行开始创建一个SchedulerOutputs对象,并将以下参数传递给它:
# 将被成功调度的序列组列表传递给scheduled_seq_groups参数。
# 这是一个标识符,说明序列组是基于输入提示运行的。
# 当前已批处理的token数量。
# 需要从CPU内存中换入的块的映射。
# 需要换出到CPU内存的块的映射。
# 需要在GPU内存中复制的块的映射。
# 由于某种原因(如输入提示太长)而被忽略的序列组列表。
scheduler_outputs = SchedulerOutputs(
scheduled_seq_groups=scheduled,
prompt_run=True,
num_batched_tokens=num_batched_tokens,
blocks_to_swap_in=blocks_to_swap_in,
blocks_to_swap_out=blocks_to_swap_out,
blocks_to_copy=blocks_to_copy,
ignored_seq_groups=ignored_seq_groups,
)
return scheduler_outputs
# 这段代码关注在没有足够的空闲插槽可用以保持所有序列组处于RUNNING状态时的抢占策略。
# 它包括了哪些序列组应该被抢占,以及如何为当前运行的序列组分配新的token插槽。
# NOTE(woosuk): Preemption happens only when there is no available slot
# to keep all the sequence groups in the RUNNING state.
# In this case, the policy is responsible for deciding which sequence
# groups to preempt.
# 这是一个注释,解释了接下来的代码部分。当没有足够的插槽来保持所有序列组处于RUNNING状态时,
# 就会发生抢占。决定哪个序列组被抢占是由策略决定
# 这行代码使用策略对象对当前正在运行的序列组列表按优先级进行排序。
self.running = self.policy.sort_by_priority(now, self.running)
# Reserve new token slots for the running sequence groups.
# 这两行代码初始化两个新的列表:running(将要运行的序列组)和preempted(被抢占的序列组)。
running: List[SequenceGroup] = []
preempted: List[SequenceGroup] = []
# 这是一个循环,处理每一个当前正在运行的序列组。每次迭代中,它从self.running列表中取出一个序列组。
while self.running:
seq_group = self.running.pop(0)
# 检查当前序列组是否可以增加新的token插槽。如果不能,进入下面的循环。
while not self.block_manager.can_append_slot(seq_group):
# 如果self.running列表仍有序列组,则取出最后一个(优先级最低的)序列组进行抢占。
if self.running:
# Preempt the lowest-priority sequence groups.
victim_seq_group = self.running.pop(-1)
self._preempt(victim_seq_group, blocks_to_swap_out)
preempted.append(victim_seq_group)
else:
# 否则,抢占当前的seq_group序列组。
# No other sequence groups can be preempted.
# Preempt the current sequence group.
self._preempt(seq_group, blocks_to_swap_out)
preempted.append(seq_group)
break
# 如果seq_group能够增加新的token插槽,则调用_append_slot方法
# 为其增加新的插槽,并将其添加到running列表中。
else:
# Append new slots to the sequence group.
self._append_slot(seq_group, blocks_to_copy)
running.append(seq_group)
# 在循环结束后,更新self.running为running列表。
# 这意味着self.running现在包含了所有已成功分配了新插槽的序列组。
self.running = running
# Swap in the sequence groups in the SWAPPED state if possible.
# 这段代码涉及尝试将处于SWAPPED状态的序列组切换回(swap in)为运行状态,如果可能的话。
# 首先,使用策略对象按优先级对swapped中的序列组进行排序。
self.swapped = self.policy.sort_by_priority(now, self.swapped)
# 开始一个循环,只要swapped列表不为空,并且没有块要被换出,就继续循环。
while self.swapped and not blocks_to_swap_out:
# 获取swapped列表中的第一个序列组。
seq_group = self.swapped[0]
# If the sequence group has been preempted in this step, stop.
# 检查这个序列组是否在这个步骤中被抢占。如果是,就终止循环。
if seq_group in preempted:
break
# If the sequence group cannot be swapped in, stop.
# 检查是否可以将这个序列组从SWAPPED状态切换回来。如果不可以,就终止循环。
if not self.block_manager.can_swap_in(seq_group):
break
# The total number of sequences in the RUNNING state should not
# exceed the maximum number of sequences.
# 这部分代码确保运行状态的序列总数不超过最大序列数。
# 它首先计算SWAPPED状态和RUNNING状态的序列数,并检查它们的总和是否超过允许的最大值。
# 如果超过,就终止循环。
num_new_seqs = seq_group.num_seqs(status=SequenceStatus.SWAPPED)
num_curr_seqs = sum(
seq_group.num_seqs(status=SequenceStatus.RUNNING)
for seq_group in self.running)
if (num_curr_seqs + num_new_seqs >
self.scheduler_config.max_num_seqs):
break
# 从swapped列表中移除并获取第一个序列组。
seq_group = self.swapped.pop(0)
# 将这个序列组从SWAPPED状态切换回来。
self._swap_in(seq_group, blocks_to_swap_in)
# 为这个序列组添加新的插槽。
self._append_slot(seq_group, blocks_to_copy)
# 将这个序列组添加到running列表中,意味着现在它正在运行。
self.running.append(seq_group)
# 最后,计算RUNNING状态的所有序列的总数。
num_batched_tokens = sum(
seq_group.num_seqs(status=SequenceStatus.RUNNING)
for seq_group in self.running)
# 包装成SchedulerOutputs对象返回
scheduler_outputs = SchedulerOutputs(
scheduled_seq_groups=self.running,
prompt_run=False,
num_batched_tokens=num_batched_tokens,
blocks_to_swap_in=blocks_to_swap_in,
blocks_to_swap_out=blocks_to_swap_out,
blocks_to_copy=blocks_to_copy,
ignored_seq_groups=[],
)
return scheduler_outputs
# 这段代码定义了一个名为schedule的方法。这个方法的目的是根据调度器的内部状态
# 生成一系列SequenceGroupMetadata对象,并将这些对象与调度的输出结果一起返回。
def schedule(self) -> Tuple[List[SequenceGroupMetadata], SchedulerOutputs]:
# Schedule sequence groups.
# This function call changes the internal states of the scheduler
# such as self.running, self.swapped, and self.waiting.
# 首先调用_schedule()方法,对序列组进行调度,并将其结果存储在scheduler_outputs变量中。
# 此方法可能会更改调度器的内部状态,如self.running、self.swapped和self.waiting。
scheduler_outputs = self._schedule()
# Create input data structures.
# 初始化一个列表seq_group_metadata_list来存储计划好的SequenceGroupMetadata。
seq_group_metadata_list: List[SequenceGroupMetadata] = []
# 开始遍历已计划好的所有序列组。
for seq_group in scheduler_outputs.scheduled_seq_groups:
# 为每个序列组初始化两个字典:seq_data(用于存储序列数据)和block_tables(用于存储块表)。
seq_data: Dict[int, List[SequenceData]] = {}
block_tables: Dict[int, List[int]] = {}
# 遍历序列组中所有处于RUNNING状态的序列。
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
seq_id = seq.seq_id
# 将当前序列的数据存储在seq_data字典中。
seq_data[seq_id] = seq.data
# 使用block_manager为当前序列获取块表,并将其存储在block_tables字典中。
block_tables[seq_id] = self.block_manager.get_block_table(seq)
# 为当前的序列组创建一个新的SequenceGroupMetadata对象,它包含了该组的所有元数据。
seq_group_metadata = SequenceGroupMetadata(
request_id=seq_group.request_id,
is_prompt=scheduler_outputs.prompt_run,
seq_data=seq_data,
sampling_params=seq_group.sampling_params,
block_tables=block_tables,
)
# 将新创建的SequenceGroupMetadata对象添加到列表seq_group_metadata_list中。
seq_group_metadata_list.append(seq_group_metadata)
return seq_group_metadata_list, scheduler_outputs
# 这段代码定义了一个名为update的函数,用于更新序列组的状态并处理新的序列输出。
def update(
self,
seq_outputs: Dict[int, SequenceOutputs],
) -> List[SequenceGroup]:
# 这是一个空列表,稍后将用来存储正在运行且其输出在seq_outputs中的序列组
scheduled: List[SequenceGroup] = []
# 这部分代码首先迭代self.running中的所有正在运行的序列组。
# 对于每一个序列组,它检查该序列组中正在运行的序列是否其输出在seq_outputs中。
# 如果是,则将该序列组添加到scheduled列表中。
for seq_group in self.running:
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
if seq.seq_id in seq_outputs:
scheduled.append(seq_group)
break
# Update the scheduled sequences and free blocks.
for seq_group in scheduled:
# Process beam search results before processing the new tokens.
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
output = seq_outputs[seq.seq_id]
# 对于每一个正在运行的序列,它首先检查该序列是否是父序列的一个fork
#(这是束搜索的一个特性)。如果是,它释放当前序列,并对父序列进行fork。
if seq.seq_id != output.parent_seq_id:
# The sequence is a fork of the parent sequence (beam
# search). Free the current sequence.
self.block_manager.free(seq)
# Fork the parent sequence.
parent_seq = seq_group.find(output.parent_seq_id)
parent_seq.fork(seq)
self.block_manager.fork(parent_seq, seq)
# Process the new tokens.
# 对于每一个正在运行的序列,它将新的token追加到该序列中。
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
# Append a new token to the sequence.
output = seq_outputs[seq.seq_id]
seq.append_token_id(output.output_token, output.logprobs)
return scheduled
# free_seq 是一个方法,用于释放与一个给定序列关联的资源,并更新该序列的状态。
def free_seq(self, seq: Sequence, finish_status: SequenceStatus) -> None:
seq.status = finish_status
self.block_manager.free(seq)
# free_finished_seq_groups方法则负责从self.running列表中移除已完成的序列组。
def free_finished_seq_groups(self) -> None:
self.running = [
seq_group for seq_group in self.running
if not seq_group.is_finished()
]
# 这段代码定义了一个名为_allocate的方法。这个方法的主要目的是为一个指定的SequenceGroup分配资源,
# 并将其中的所有序列的状态设置为RUNNING。
def _allocate(self, seq_group: SequenceGroup) -> None:
self.block_manager.allocate(seq_group)
for seq in seq_group.get_seqs():
seq.status = SequenceStatus.RUNNING
# 这段代码定义了一个名为_append_slot的方法。它的主要功能是为SequenceGroup
# 中正在运行的序列追加一个资源或内存块,并同时更新一个叫做blocks_to_copy的字典。
def _append_slot(
self,
seq_group: SequenceGroup,
blocks_to_copy: Dict[int, List[int]],
) -> None:
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
# 对每一个正在运行的序列`seq`,调用`self.block_manager`
# 的`append_slot`方法尝试为其追加一个资源或内存块。
ret = self.block_manager.append_slot(seq)
# 返回值`ret`可能是一个包含两个整数的元组,或者为`None`。
if ret is not None:
# 如果`ret`不是`None`,则将其解包为两个整数`src_block`和`dst_block`。
src_block, dst_block = ret
# 检查`src_block`是否已经在`blocks_to_copy`字典中:
if src_block in blocks_to_copy:
# 如果是,将`dst_block`追加到对应的列表中。
blocks_to_copy[src_block].append(dst_block)
else:
# 如果不是,创建一个新的条目,其中`src_block`是键,
# 值是一个包含`dst_block`的新列表。
blocks_to_copy[src_block] = [dst_block]
# 这段代码定义了一个名为_preempt的私有方法,这个方法负责预占或
# 中断SequenceGroup的执行,要么通过重新计算,要么通过交换内存。
def _preempt(
self,
seq_group: SequenceGroup,
blocks_to_swap_out: Dict[int, int],
preemption_mode: Optional[PreemptionMode] = None,
) -> None:
# If preemption mode is not specified, we determine the mode as follows:
# We use recomputation by default since it incurs lower overhead than
# swapping. However, when the sequence group has multiple sequences
# (e.g., beam search), recomputation is not supported. In such a case,
# we use swapping instead.
# FIXME(woosuk): This makes our scheduling policy a bit bizarre.
# As swapped sequences are prioritized over waiting sequences,
# sequence groups with multiple sequences are implicitly prioritized
# over sequence groups with a single sequence.
# TODO(woosuk): Support recomputation for sequence groups with multiple
# sequences. This may require a more sophisticated CUDA kernel.
# 如果调用时没有明确指定预占模式,那么这部分代码会根据SequenceGroup中
# 运行状态的序列数量来决定使用哪种模式。
if preemption_mode is None:
seqs = seq_group.get_seqs(status=SequenceStatus.RUNNING)
# 如果有一个正在运行的序列,则默认使用RECOMPUTE模式。
if len(seqs) == 1:
preemption_mode = PreemptionMode.RECOMPUTE
else:
preemption_mode = PreemptionMode.SWAP
# 如果是RECOMPUTE,调用_preempt_by_recompute方法。
if preemption_mode == PreemptionMode.RECOMPUTE:
self._preempt_by_recompute(seq_group)
# 如果是SWAP,调用_preempt_by_swap方法并传入blocks_to_swap_out。
elif preemption_mode == PreemptionMode.SWAP:
self._preempt_by_swap(seq_group, blocks_to_swap_out)
else:
assert False, "Invalid preemption mode."
def _preempt_by_recompute(
self,
seq_group: SequenceGroup,
) -> None:
seqs = seq_group.get_seqs(status=SequenceStatus.RUNNING)
assert len(seqs) == 1
for seq in seqs:
seq.status = SequenceStatus.WAITING
self.block_manager.free(seq)
# NOTE: For FCFS, we insert the preempted sequence group to the front
# of the waiting queue.
self.waiting.insert(0, seq_group)
def _preempt_by_swap(
self,
seq_group: SequenceGroup,
blocks_to_swap_out: Dict[int, int],
) -> None:
seqs = seq_group.get_seqs(status=SequenceStatus.RUNNING)
for seq in seqs:
seq.status = SequenceStatus.SWAPPED
self._swap_out(seq_group, blocks_to_swap_out)
self.swapped.append(seq_group)
def _swap_in(
self,
seq_group: SequenceGroup,
blocks_to_swap_in: Dict[int, int],
) -> None:
mapping = self.block_manager.swap_in(seq_group)
blocks_to_swap_in.update(mapping)
for seq in seq_group.get_seqs(status=SequenceStatus.SWAPPED):
seq.status = SequenceStatus.RUNNING
def _swap_out(
self,
seq_group: SequenceGroup,
blocks_to_swap_out: Dict[int, int],
) -> None:
if not self.block_manager.can_swap_out(seq_group):
# FIXME(woosuk): Abort the sequence group instead of aborting the
# entire engine.
raise RuntimeError(
"Aborted due to the lack of CPU swap space. Please increase "
"the swap space to avoid this error.")
mapping = self.block_manager.swap_out(seq_group)
blocks_to_swap_out.update(mapping)
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
seq.status = SequenceStatus.SWAPPED
上面完整解析了scheduler的代码,我们这里来总结一下流程。首先在llm_engine.add_request函数中把根据输入prompt构造好的SequenceGroup添加到 scheduler 的 waiting 队列里(self.scheduler.add_seq_group(seq_group))。scheduler的初始化函数中定义了三个代表状态的List[SequenceGroup] waiting, running, swapped 以及初始化了一个block_manager来管理 logical blocks 和 physical blocks 之间的映射关系。然后在scheduler的代码实现中,schedule函数尤其关键。
首先,当waiting不空时,它会把一些waiting中的SequenceGroup加到running中,但需要满足一些条件比如block_manager里面是否还有足够的空间可以塞得下这个SequenceGroup(对应 if not self.block_manager.can_allocate(seq_group): break),当前序列的prompt长度是否超出了prompt_limit,已经批处理的token数量(num_batched_tokens)加上当前序列组(seq_group)的token数量(num_prompt_tokens)是否超过了配置中的最大token限制,如果超过了,循环就会中断。还有一些限制可以看上面的代码。
然后,scheduler会遍历running里面的每个SequenceGroup,然后检查block_manager是否够塞得下。 如果不行,则它会驱逐 running 队列中优先级最低的SequenceGroup,如果空间够的话,则会对这个SequenceGroup allocate 相应的 physical blocks,然后将其放入 update 后的 running 列表中。经过这个过程,scheduler 更新了 running 列表,并把部分任务驱逐掉。
接下来,scheduler会过一遍swapped里面的每个SequenceGroup,尝试 swap in 那些能够 swap 的 SequenceGroup,并把它们放到新的 running 列表中。
scheduler做完上述过程之后,最后会把相应的信息(swap in/out 的 blocks,blocks_to_copy)包装成SchedulerOutputs对象供后面worker进行Model Execution(也包含序列本身相关的信息叫 seq_group_metadata_list)。
0x6. Model Execution
接下来我们对Model Execution做一个介绍,Model Execution是scheduler.schedule函数之后执行的,对应这几行代码:
seq_group_metadata_list, scheduler_outputs = self.scheduler.schedule()
if scheduler_outputs.is_empty():
if not scheduler_outputs.ignored_seq_groups:
# Nothing to do.
return []
# If there are ignored seq groups, we need to return them as the
# request outputs.
return [
RequestOutput.from_seq_group(seq_group)
for seq_group in scheduler_outputs.ignored_seq_groups
]
# Execute the model.
output = self._run_workers(
"execute_model",
seq_group_metadata_list=seq_group_metadata_list,
blocks_to_swap_in=scheduler_outputs.blocks_to_swap_in,
blocks_to_swap_out=scheduler_outputs.blocks_to_swap_out,
blocks_to_copy=scheduler_outputs.blocks_to_copy,
)
这里调用了worker的execute_model函数来做模型的推理,在模型推理中比较特殊的一点就是使用了PagedAttention,以及如果在模型执行前传入的SchedulerOutputs对象中的swap in/out 的 blocks,blocks_to_copy等不空的话,我们需要在获取KV Cache之间做一个全局同步让Block相关的操作做完,这是通过在Transformer的每一层插入一个cuda Event来实现的。这里我们来分析一下模型执行过程里面最核心的部分也就是PagedAttention。
class PagedAttention(nn.Module):
# pylint: disable=line-too-long
"""GPT-style multi-head PagedAttention.
This class takes flattened 1D query, key, and value tensors as input. The
input 1D tensors can either contain prompt tokens or generation tokens, in
addition to paddings.
If the input tensors contain prompt tokens, the layout is as follows:
|<---------------------- num_valid_tokens ---------------------->|
|<--------------- num_prompt_tokens -------------->|
|<--prompt_0-->|<--prompt_1-->|...|<--prompt_N-1-->|<--padding-->|
Otherwise, the layout is as follows:
|<------------------ num_valid_tokens ------------------->|
|<------- num_generation_tokens (M) ------->|
|<--generation_0-->|...|<--generation_M-1-->|<--padding-->|
The prompts might have different lengths, while the generation tokens always
have length 1. The paddings are appended to make the input length a multiple
of 8, which is desirable for Tensor Cores.
The class does the following:
1. Perform multi_query_kv_attention for the prompts. This operation does
not use the KV cache.
2. Wait for the cache operations (e.g., swap, copy) to finish. The cache
operations are issued by the cache engine before executing the forward
pass of the model, and they are executed asynchronously.
3. Reshape and store the input key and value tensors in the KV cache.
4. Perform single_query_cached_kv_attention for the generation tokens.
This operation reads the previous key and value tensors from the KV
cache.
5. Output a flattened 1D tensor.
"""
def __init__(self,
num_heads: int,
head_size: int,
scale: float,
num_kv_heads: Optional[int] = None) -> None:
super().__init__()
self.num_heads = num_heads # 多头注意力中的“头”的数量。
self.head_size = head_size # 每个“头”的大小。
self.scale = float(scale) # 缩放因子。
# 使用了一个外部库xops.fmha.cutlass.FwOp()来实现注意力操作,但这里没有提供具体细节。
self.attn_op = xops.fmha.cutlass.FwOp()
# 键值对头的数量。默认为None,这意味着它的默认值与num_heads相同。
self.num_kv_heads = num_heads if num_kv_heads is None else num_kv_heads
# 对num_heads和num_kv_heads之间的关系进行了断言,确保num_heads是num_kv_heads的倍数。
assert self.num_heads % self.num_kv_heads == 0
# 一个query共用多少个k, v
self.num_queries_per_kv = self.num_heads // self.num_kv_heads
# 根据num_kv_heads和num_queries_per_kv来计算head_mapping。
self.head_mapping = torch.repeat_interleave(
torch.arange(self.num_kv_heads, dtype=torch.int32, device="cuda"),
self.num_queries_per_kv)
# 检查是否支持head_size,如果不支持则抛出错误。
if self.head_size not in _SUPPORTED_HEAD_SIZES:
raise ValueError(f"head_size ({self.head_size}) is not supported. "
f"Supported head sizes: {_SUPPORTED_HEAD_SIZES}.")
# 此成员函数set_attn_bias的目的是设置注意力偏置(attention bias)。
# 这里的注意力偏置就是mask矩阵
def set_attn_bias(self, input_metadata: InputMetadata) -> None:
# 检查input_metadata对象中的attn_bias属性是否已经设置。
# 如果attn_bias是真值(例如,它是一个非空列表或其他真值),则进入此条件语句。
if input_metadata.attn_bias:
# Already set by a previous layer.
# 如果注意力偏置已经被设置,则提前退出函数。
return
# 从input_metadata对象中获取prompt_lens属性,该属性可能表示各提示的长度。
prompt_lens = input_metadata.prompt_lens
# 使用BlockDiagonalCausalMask.from_seqlens方法从prompt_lens(提示的长度列表)
# 生成一个块对角因果掩码,并将其赋值给attn_bias。这个掩码可能被用于实现自回归模型中的
# 因果注意力,确保一个位置的输出只依赖于该位置之前的输入。
attn_bias = BlockDiagonalCausalMask.from_seqlens(prompt_lens)
# 将新生成的attn_bias添加到input_metadata对象中的attn_bias属性。
input_metadata.attn_bias.append(attn_bias)
def multi_query_kv_attention(
self,
output: torch.Tensor,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
input_metadata: InputMetadata,
) -> torch.Tensor:
"""对 prompt tokens 做正常的attention.
Args:
output: shape = [num_prompt_tokens, num_heads, head_size]
query: shape = [num_prompt_tokens, num_heads, head_size]
key: shape = [num_prompt_tokens, num_kv_heads, head_size]
value: shape = [num_prompt_tokens, num_kv_heads, head_size]
input_metadata: paged attention的元信息.
"""
# 判断num_kv_heads(键值对头的数量)是否不等于num_heads(注意力的头的数量)。
if self.num_kv_heads != self.num_heads:
# Project the key and value tensors to the desired number of heads.
# 如果上述条件为真,那么对key和value进行调整,使其头的数量与num_heads匹配。
# 具体来说,它会使用torch.repeat_interleave函数沿着第1个维度重复
# 每个key和value self.num_queries_per_kv次。
key = torch.repeat_interleave(key, self.num_queries_per_kv, dim=1)
value = torch.repeat_interleave(value,
self.num_queries_per_kv,
dim=1)
# TODO(woosuk): The unsqueeze op may incur some CPU overhead. Optimize.
# 使用xtransformer库中的memory_efficient_attention_forward方法来计算注意力。
# 输入的query、key、value张量都增加了一个额外的维度(使用unsqueeze(0))。
# 此外,它还接受了input_metadata.attn_bias[0]作为注意力偏置、
# self.scale作为缩放因子以及self.attn_op作为操作符。
out = xops.memory_efficient_attention_forward(
query.unsqueeze(0),
key.unsqueeze(0),
value.unsqueeze(0),
attn_bias=input_metadata.attn_bias[0],
p=0.0,
scale=self.scale,
op=self.attn_op,
)
# TODO(woosuk): Unnecessary copy. Optimize.
output.copy_(out.squeeze(0))
return output
# 这段代码定义了single_query_cached_kv_attention方法,它用于单个query时的KV缓存注意力操作。
def single_query_cached_kv_attention(
self,
output: torch.Tensor,
query: torch.Tensor,
key_cache: torch.Tensor,
value_cache: torch.Tensor,
input_metadata: InputMetadata,
) -> None:
"""PagedAttention for the generation tokens.
Args:
output: shape = [num_generation_tokens, num_heads, head_size]
query: shape = [num_generation_tokens, num_heads, head_size]
key_cache: shape = [num_blocks, num_kv_heads, head_size/x,
block_size, x]
value_cache: shape = [num_blocks, num_kv_heads, head_size,
block_size]
input_metadata: metadata for paged attention.
"""
block_size = value_cache.shape[3]
attention_ops.single_query_cached_kv_attention(
output,
query,
key_cache,
value_cache,
self.head_mapping,
self.scale,
input_metadata.block_tables,
input_metadata.context_lens,
block_size,
input_metadata.max_context_len,
None, # alibi_slopes
)
# 这是PagedAttention类的forward方法,表示该模块的前向传播操作。
def forward(
self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
key_cache: Optional[torch.Tensor],
value_cache: Optional[torch.Tensor],
input_metadata: InputMetadata,
cache_event: Optional[torch.cuda.Event],
) -> torch.Tensor:
"""PagedAttention forward pass.
NOTE: The query, key, and value tensors must be sliced from a qkv
tensor of shape [num_tokens, 3 * num_heads * head_size].
Args:
query: shape = [num_tokens, num_heads * head_size]
key: shape = [num_tokens, num_kv_heads * head_size]
value: shape = [num_tokens, num_kv_heads * head_size]
key_cache: shape = [num_blocks, num_kv_heads, head_size/x,
block_size, x]
value_cache: shape = [num_blocks, num_kv_heads, head_size,
block_size]
input_metadata: metadata for paged attention.
cache_event: event to wait for the cache operations to finish.
Returns:
shape = [num_tokens, num_heads * head_size]
"""
# Reshape the query, key, and value tensors.
# 将输入的query, key, value张量重新调整为具有三个维度的形状。
query = query.view(-1, self.num_heads, self.head_size)
key = key.view(-1, self.num_kv_heads, self.head_size)
value = value.view(-1, self.num_kv_heads, self.head_size)
# Pre-allocate the output tensor.
# 创建一个与查询张量形状相同但未初始化的输出张量。
output = torch.empty_like(query)
# Compute the attention op for prompts.
# 这段代码处理prompt tokens的注意力:
num_prompt_tokens = input_metadata.num_prompt_tokens
# 如果存在prompt token,则使用multi_query_kv_attention方法为prompt tokens计算注意力。
if num_prompt_tokens > 0:
# Prompt run.
assert input_metadata.num_generation_tokens == 0
self.set_attn_bias(input_metadata)
self.multi_query_kv_attention(
output[:num_prompt_tokens],
query[:num_prompt_tokens],
key[:num_prompt_tokens],
value[:num_prompt_tokens],
input_metadata,
)
# Wait until the cache op is done.
# 等待缓存操作完成
if cache_event is not None:
cache_event.wait()
# Reshape the keys and values and store them in the cache.
# When key_cache and value_cache are not provided, the new key
# and value vectors will not be cached.
# 这里的input_metadata.num_valid_tokens对应了这个类开头的解释
num_valid_tokens = input_metadata.num_valid_tokens
if (num_valid_tokens > 0 and key_cache is not None
and value_cache is not None):
# The stride is 3 because the key and value are sliced from qkv.
cache_ops.reshape_and_cache(
key[:num_valid_tokens],
value[:num_valid_tokens],
key_cache,
value_cache,
input_metadata.slot_mapping,
)
if input_metadata.num_generation_tokens > 0:
# Decoding run.
assert input_metadata.num_prompt_tokens == 0
assert key_cache is not None and value_cache is not None, (
"key_cache and value_cache must be provided when "
"generating tokens.")
# Compute the attention op for generation tokens.
self.single_query_cached_kv_attention(
output[num_prompt_tokens:num_valid_tokens],
query[num_prompt_tokens:num_valid_tokens], key_cache,
value_cache, input_metadata)
# Reshape the output tensor.
# NOTE(woosuk): The output tensor may include paddings.
return output.view(-1, self.num_heads * self.head_size)
这里的key_cache有些特殊,暂时还不清楚为什么它的维度和value_cache不一样,相比于value_cache的shape,它在head_size维度拆分了一个x出来,感觉是一种加速策略后续在解析cuda kernel实现时希望可以找到答案。然后可以看到对于prompt的attention的计算是由xtransformers库的算子来完成的,在生成阶段则是由VLLM自己实现的cuda kernel(attention_ops.single_query_cached_kv_attention)来完成计算,因为这里涉及到Paged Attention特有的cache访问策略。
0x7. Continue Batch机制
接下来讲一下VLLM的Continue Batch是怎么做的,VLLM的Continue Batch就是把所有的序列拼接成一个大的序列,然后tokenizer之后变成一个大的Tensor,同时记录一下每个prompt的长度作为meta信息传给模型。以PagedAttentionWithALiBi模块为例子,在它的multi_query_kv_attention函数中通过prompt_len信息对一个Batch的序列进行切分和推理,而不需要对每个序列都进行padding。
# 这段代码定义了一个名为 PagedAttentionWithALiBi 的类,
# 它扩展了另一个名为 PagedAttention 的类,增加了ALiBi注意力偏置(attention bias)的功能。
class PagedAttentionWithALiBi(PagedAttention):
"""PagedAttention with ALiBi attention bias."""
def __init__(self,
num_heads: int,
head_size: int,
scale: float,
slopes: List[float],
num_kv_heads: Optional[int] = None) -> None:
super().__init__(num_heads, head_size, scale, num_kv_heads)
# 确保 slopes 的长度与 num_heads 相等。
assert len(slopes) == num_heads
slopes = torch.tensor(slopes, dtype=torch.float32)
# 在PyTorch模型中,如果你有一个你不希望被认为是模型参数的张量,你可以使用
# register_buffer 将它注册为一个缓冲区。这里,它注册了一个名为 "alibi_slopes" 的缓冲区。
self.register_buffer("alibi_slopes", slopes, persistent=False)
# 这个方法的目的是根据输入的元数据(input_metadata)设置注意力偏置。
def set_attn_bias(self, input_metadata: InputMetadata) -> None:
# 如果注意力偏置已经被之前的层设置,直接返回。
if input_metadata.attn_bias:
# Already set by a previous layer.
return
# Generates ALiBi mask for each prompt.
# 遍历每个提示的长度,生成ALiBi的掩码。
for prompt_len in input_metadata.prompt_lens:
# 创建一个偏置矩阵,其基于两种方式的差异形成注意力偏置。
bias = torch.arange(prompt_len)
# Note(zhuohan): HF uses
# `bias = bias[None, :].repeat(prompt_len, 1)`
# here. We find that both biases give the same results, but
# the bias below more accurately follows the original ALiBi
# paper.
bias = bias[None, :] - bias[:, None]
bias = bias.to(self.alibi_slopes.device)
# When using custom attention bias, xformers requires the bias to
# be sliced from a tensor whose length is a multiple of 8.
# 确保偏置张量的长度是8的倍数。
padded_len = (prompt_len + 7) // 8 * 8
# 用 alibi_slopes 修改偏置。
bias = torch.empty(
self.num_heads,
padded_len,
padded_len,
device=self.alibi_slopes.device,
)[:, :prompt_len, :prompt_len].copy_(bias)
bias.mul_(self.alibi_slopes[:, None, None])
# 使用偏置创建一个下三角掩码。
attn_bias = LowerTriangularMaskWithTensorBias(bias)
# 将新的注意力偏置添加到输入元数据中。
input_metadata.attn_bias.append(attn_bias)
# 这个函数 multi_query_kv_attention 是一个执行注意力机制的函数,
# 特别是使用了ALiBi的偏置来处理prompt tokens。
def multi_query_kv_attention(
self,
output: torch.Tensor,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
input_metadata: InputMetadata,
) -> torch.Tensor:
"""Attention with ALiBi bias for the prompt tokens.
Args:
output: shape = [num_prompt_tokens, num_heads, head_size]
query: shape = [num_prompt_tokens, num_heads, head_size]
key: shape = [num_prompt_tokens, num_kv_heads, head_size]
value: shape = [num_prompt_tokens, num_kv_heads, head_size]
input_metadata: metadata for paged attention.
"""
# 如果key/value的头数量与query的头数量不同,则它会对key和value进行
# 重复扩展,使其与query的头数量匹配。
if self.num_kv_heads != self.num_heads:
# Project the key and value tensors to the desired number of heads.
key = torch.repeat_interleave(key, self.num_queries_per_kv, dim=1)
value = torch.repeat_interleave(value,
self.num_queries_per_kv,
dim=1)
# FIXME(woosuk): Because xformers does not support dynamic sequence
# lengths with custom attention bias, we process each prompt one by
# one. This is inefficient, especially when we have many short prompts.
start = 0
# 它遍历每个提示的长度,并对每个prompt执行以下步骤:
for i, prompt_len in enumerate(input_metadata.prompt_lens):
end = start + prompt_len
# 使用当前的 start 和 end 索引切片 query, key, value 张量。
# 使用 xops.memory_efficient_attention_forward 执行注意力操作。
# 将结果复制到 output 张量的相应位置。
out = xops.memory_efficient_attention_forward(
query[None, start:end],
key[None, start:end],
value[None, start:end],
attn_bias=input_metadata.attn_bias[i],
p=0.0,
scale=self.scale,
op=self.attn_op,
)
# TODO(woosuk): Unnecessary copy. Optimize.
output[start:end].copy_(out.squeeze(0))
start += prompt_len
return output
def single_query_cached_kv_attention(
self,
output: torch.Tensor,
query: torch.Tensor,
key_cache: torch.Tensor,
value_cache: torch.Tensor,
input_metadata: InputMetadata,
) -> None:
"""PagedAttention with ALiBi bias for the generation tokens.
Args:
output: shape = [num_generation_tokens, num_heads, head_size]
query: shape = [num_generation_tokens, num_heads, head_size]
key_cache: shape = [num_blocks, num_kv_heads, head_size/x,
block_size, x]
value_cache: shape = [num_blocks, num_kv_heads, head_size,
block_size]
input_metadata: metadata for paged attention.
"""
block_size = value_cache.shape[3]
attention_ops.single_query_cached_kv_attention(
output,
query,
key_cache,
value_cache,
self.head_mapping,
self.scale,
input_metadata.block_tables,
input_metadata.context_lens,
block_size,
input_metadata.max_context_len,
self.alibi_slopes,
)
通过这种方法, 就不需要把所有序列都padding到一个长度了浪费计算资源了,并且可以塞下更多的序列使得吞吐量增加。但是VLLM这里也有个缺点就是无法显示控制Batch的数量,只要Cache Engine还有空闲空间就可以持续往scheduler里面塞序列。
0x8. Sampler & Copy-On-Write 机制
一般来说模型执行之后的输出Tensor维度是[batch_size, hidden_dim],也就是下图中的hidden_states。然后hidden_states会被传入到到sampler进行处理,在sampler这里包含一个 lm_head proj 将hidden_states的维度映射成 [batch_size, vocab_size]。
 Sampler的具体过程有些复杂,我们还是要仔细分析一下代码,对应
Sampler的具体过程有些复杂,我们还是要仔细分析一下代码,对应vllm/vllm/model_executor/layers/sampler.py这个文件。
_SAMPLING_EPS = 1e-5
# Sampler是一个nn.Module子类,负责从模型的输出中采样下一个token。
# 该类的功能基于预定义的一系列步骤来调整和处理模型的输出。
class Sampler(nn.Module):
"""Samples the next tokens from the model's outputs.
This layer does the following:
1. Discard the hidden states that are not used for sampling (i.e., all
tokens except the final one in each prompt).
2. Compute the logits for the next tokens.
3. Apply presence and frequency penalties.
4. Apply temperature scaling.
5. Apply top-p and top-k truncation.
6. Sample the next tokens.
Here, each sequence group within the batch can have different sampling
parameters (e.g., sampling method, temperature, top-p, top-k, etc.).
"""
def __init__(self, vocab_size: int) -> None:
super().__init__()
self.vocab_size = vocab_size
def forward(
self,
embedding: torch.Tensor,
hidden_states: torch.Tensor,
input_metadata: InputMetadata,
embedding_bias: Optional[torch.Tensor] = None,
) -> Dict[int, SequenceOutputs]:
# Get the hidden states that we use for sampling.
# 按输入元数据剪枝隐藏状态,只保留用于采样的状态。
hidden_states = _prune_hidden_states(hidden_states, input_metadata)
# Get the logits for the next tokens.
# 这是通过将hidden_states与embedding矩阵的转置进行矩阵乘法得到的。
# 如果存在embedding_bias,则将其添加到logits上。
logits = torch.matmul(hidden_states, embedding.t())
if embedding_bias is not None:
logits += embedding_bias
# 由于可能使用了模型并行,这里调用gather通信原语同步模型参数
logits = gather_from_tensor_model_parallel_region(logits)
# Remove paddings in vocab (if any).
# 删除词汇表中的任何padding
logits = logits[:, :self.vocab_size]
# Apply presence and frequency penalties.
# 应用存在和频率惩罚:这是通过一个函数_apply_penalties来完成的,它使用input_metadata中的信息。
output_tokens = _get_output_tokens(input_metadata)
assert len(output_tokens) == logits.shape[0]
presence_penalties, frequency_penalties = _get_penalties(
input_metadata)
assert len(presence_penalties) == logits.shape[0]
assert len(frequency_penalties) == logits.shape[0]
logits = _apply_penalties(logits, output_tokens, presence_penalties,
frequency_penalties, self.vocab_size)
# Apply temperature scaling.
# 应用温度缩放:temperatures是根据input_metadata获得的。
# 如果temperatures中的任何值不为1.0,则将逻辑值除以对应的温度。
temperatures = _get_temperatures(input_metadata)
assert len(temperatures) == logits.shape[0]
if any(t != 1.0 for t in temperatures):
t = torch.tensor(temperatures,
dtype=logits.dtype,
device=logits.device)
# Use in-place division to avoid creating a new tensor.
logits.div_(t.unsqueeze(dim=1))
# We use float32 for probabilities and log probabilities.
# Compute the probabilities.
# 计算概率:通过对逻辑值应用softmax函数来计算。
probs = torch.softmax(logits, dim=-1, dtype=torch.float)
# Compute the log probabilities (before applying top-p and top-k).
# 计算对数概率:通过取概率的对数来计算。
logprobs = torch.log(probs)
# Apply top-p and top-k truncation.
# 应用top-p和top-k截断:这是通过函数_apply_top_p_top_k完成的,它使用input_metadata中的信息。
top_ps, top_ks = _get_top_p_top_k(input_metadata, self.vocab_size)
assert len(top_ps) == len(top_ks) == probs.shape[0]
do_top_p = any(p < 1.0 - _SAMPLING_EPS for p in top_ps)
do_top_k = any(k != self.vocab_size for k in top_ks)
if do_top_p or do_top_k:
probs = _apply_top_p_top_k(probs, top_ps, top_ks)
# Sample the next tokens.
# 采样下一个token:这是通过函数_sample完成的。
return _sample(probs, logprobs, input_metadata)
# 这个函数_prune_hidden_states的目的是从给定的hidden_states中选择特定的隐藏状态,
# 这些状态对应于输入序列中每个prompt的最后一个token以及所有生成的token。
def _prune_hidden_states(
hidden_states: torch.Tensor,
input_metadata: InputMetadata,
) -> torch.Tensor:
# 初始化一个start_idx为0,这个变量将用于迭代和获取每个prompt的最后一个token的索引。
start_idx = 0
# 初始化一个空列表last_token_indicies,它将用于存储每个prompt的最后一个token的索引。
last_token_indicies: List[int] = []
# 通过循环迭代input_metadata.prompt_lens中的每个prompt长度来更新last_token_indicies
for prompt_len in input_metadata.prompt_lens:
last_token_indicies.append(start_idx + prompt_len - 1)
start_idx += prompt_len
# 在处理完所有prompt后,添加所有生成的token的索引到last_token_indicies列表。
last_token_indicies.extend(
range(start_idx, start_idx + input_metadata.num_generation_tokens))
return hidden_states[last_token_indicies]
# 这个函数_get_penalties的目的是获取输入元数据中的存在性惩罚和频率惩罚,并将它们组织为两个列表。
def _get_penalties(
input_metadata: InputMetadata) -> Tuple[List[float], List[float]]:
# Collect the presence and frequency penalties.
# 初始化两个空列表presence_penalties和frequency_penalties。
# 这些列表将分别用于存储存在性惩罚和频率惩罚的值。
presence_penalties: List[float] = []
frequency_penalties: List[float] = []
# 循环迭代input_metadata.seq_groups中的每个序列组:
for i, seq_group in enumerate(input_metadata.seq_groups):
# 从seq_group中提取seq_ids(序列标识符)和sampling_params(采样参数)。
seq_ids, sampling_params = seq_group
# 从sampling_params中提取presence_penalty(存在性惩罚)
# 到变量p和frequency_penalty(频率惩罚)到变量f。
p = sampling_params.presence_penalty
f = sampling_params.frequency_penalty
# 检查当前迭代的索引i是否小于input_metadata.num_prompts,以确定当前的序列组是否为prompt输入。
if i < input_metadata.num_prompts:
# A prompt input.
presence_penalties.append(p)
frequency_penalties.append(f)
else:
# A generation token.
presence_penalties += [p] * len(seq_ids)
frequency_penalties += [f] * len(seq_ids)
return presence_penalties, frequency_penalties
# 这个函数的目的是从input_metadata中提取输出token,并将它们组织为一个列表。
def _get_output_tokens(input_metadata: InputMetadata) -> List[List[int]]:
# 初始化一个空列表output_tokens,用于存储输出token的列表。
output_tokens: List[List[int]] = []
# 循环迭代input_metadata.seq_groups中的每个序列组:
for i, seq_group in enumerate(input_metadata.seq_groups):
# 从seq_group中提取seq_ids(序列标识符)。_表示我们不使用sampling_params。
seq_ids, _ = seq_group
# 检查当前迭代的索引i是否小于input_metadata.num_prompts,以确定当前的序列组是否为prompt输入。
if i < input_metadata.num_prompts:
# A prompt input.
# NOTE: While the prompt input usually has no output tokens,
# it may have output tokens in the case of recomputation.
# 这里的recompute指的是什么?
seq_id = seq_ids[0]
seq_data = input_metadata.seq_data[seq_id]
output_tokens.append(seq_data.output_token_ids)
else:
# A generation token.
for seq_id in seq_ids:
seq_data = input_metadata.seq_data[seq_id]
output_tokens.append(seq_data.output_token_ids)
return output_tokens
# 这个函数_apply_penalties是用于在logits上应用特定的惩罚,具体来说是频率惩罚
#(frequency penalties)和存在惩罚(presence penalties)。
# 这些惩罚通常用于对模型生成的输出进行微调,从而控制模型的行为。
def _apply_penalties(
logits: torch.Tensor, # 一个张量,表示模型输出的原始得分。
output_tokens: List[List[int]], # 一个整数列表的列表,表示每个序列的输出token IDs。
presence_penalties: List[float], # 浮点数列表,表示存在和频率惩罚。
frequency_penalties: List[float],
vocab_size: int,
) -> torch.Tensor:
num_seqs = logits.shape[0]
# Collect the indices of sequences that have non-zero penalties.
# 首先,函数检查每个序列是否具有非零存在或频率惩罚,并收集这些序列的索引。
indices = []
for i in range(num_seqs):
if not output_tokens[i]:
continue
p = presence_penalties[i]
f = frequency_penalties[i]
if p < _SAMPLING_EPS and f < _SAMPLING_EPS:
continue
indices.append(i)
# Return early if all sequences have zero penalties.
# 如果所有序列的惩罚都为零,则直接返回原始logits,无需应用任何惩罚
if not indices:
return logits
# 对于每个具有非零惩罚的序列,使用np.bincount计算输出token的频率计数,并将它们堆叠到一个张量中。
bin_counts = []
for i in indices:
bin_counts.append(np.bincount(output_tokens[i], minlength=vocab_size))
bin_counts = np.stack(bin_counts, axis=0)
bin_counts = torch.from_numpy(bin_counts).to(dtype=logits.dtype,
device=logits.device)
# 从非零惩罚的序列索引中选择对应的频率和存在惩罚,并将它们转换为张量。
frequency_penalties = [frequency_penalties[i] for i in indices]
frequency_penalties = torch.tensor(frequency_penalties,
dtype=logits.dtype,
device=logits.device)
presence_penalties = [presence_penalties[i] for i in indices]
presence_penalties = torch.tensor(presence_penalties,
dtype=logits.dtype,
device=logits.device)
# We follow the definition in OpenAI API.
# Refer to https://platform.openai.com/docs/api-reference/parameter-details
# 对于每个具有非零惩罚的序列,频率惩罚乘以bin计数,并从对应的logits中减去结果。
logits[indices] -= frequency_penalties.unsqueeze(dim=1) * bin_counts
# 创建一个掩码,该掩码表示哪些token在序列中出现(即bin计数大于0)。
# 然后,存在惩罚乘以此掩码,并从对应的logits中减去结果。
presence_mask = (bin_counts > 0.0).to(dtype=logits.dtype)
logits[indices] -= presence_penalties.unsqueeze(dim=1) * presence_mask
return logits
# 这个函数_get_temperatures的目的是从输入元数据中获取每个序列的温度值。
# 温度是在随机采样过程中使用的一个参数,它控制了模型输出的多样性。
# 较高的温度会使输出更加随机,而较低的温度会使模型更加确定性地选择最有可能的输出。
def _get_temperatures(input_metadata: InputMetadata) -> List[float]:
# Collect the temperatures for the logits.
temperatures: List[float] = []
for i, seq_group in enumerate(input_metadata.seq_groups):
seq_ids, sampling_params = seq_group
temperature = sampling_params.temperature
if temperature < _SAMPLING_EPS:
# NOTE: Zero temperature means deterministic sampling
# (i.e., greedy sampling or beam search).
# Set the temperature to 1 to avoid division by zero.
temperature = 1.0
if i < input_metadata.num_prompts:
# A prompt input.
temperatures.append(temperature)
else:
# A generation token.
temperatures += [temperature] * len(seq_ids)
return temperatures
# 这个函数 _get_top_p_top_k 的目的是从输入元数据中提取每个序列的 top_p 和 top_k 值。
# 这两个参数都是用于控制模型在随机采样时如何裁剪概率分布的。
def _get_top_p_top_k(
input_metadata: InputMetadata,
vocab_size: int,
) -> Tuple[List[float], List[int]]:
top_ps: List[float] = []
top_ks: List[int] = []
for i, seq_group in enumerate(input_metadata.seq_groups):
seq_ids, sampling_params = seq_group
top_p = sampling_params.top_p
# k should not be greater than the vocab size.
top_k = min(sampling_params.top_k, vocab_size)
# k=-1 means no truncation.
top_k = vocab_size if top_k == -1 else top_k
if i < input_metadata.num_prompts:
# A prompt input.
top_ps.append(top_p)
top_ks.append(top_k)
else:
# A generation token.
top_ps += [top_p] * len(seq_ids)
top_ks += [top_k] * len(seq_ids)
return top_ps, top_ks
# 这个函数的 _apply_top_p_top_k 主要目的是在随机采样过程中裁剪模型的输出概率分布。
# 其基本思路是根据 top_p 和 top_k 的值,保留概率最高的一些token,而不是根据其完整
# 的概率分布来随机选择token。这是一个控制模型输出多样性的常见方法。
def _apply_top_p_top_k(
probs: torch.Tensor,
top_ps: List[float],
top_ks: List[int],
) -> torch.Tensor:
p = torch.tensor(top_ps, dtype=probs.dtype, device=probs.device)
k = torch.tensor(top_ks, dtype=torch.int, device=probs.device)
# 对 probs Tensor按降序排序,得到排序后的概率 probs_sort 和相应的索引 probs_idx。
probs_sort, probs_idx = probs.sort(dim=-1, descending=True)
# Apply top-p.
# 计算累积和 probs_sum。
probs_sum = torch.cumsum(probs_sort, dim=-1)
# 创建一个遮罩 top_p_mask,表示哪些token的概率应该被设置为0,以便保证累积概率低于给定的 top_p 值。
top_p_mask = (probs_sum - probs_sort) > p.unsqueeze(dim=1)
# 使用此遮罩将不满足条件的token的概率设置为0。
probs_sort[top_p_mask] = 0.0
# Apply top-k.
# Create a mask for the top-k elements.
# 创建一个遮罩 top_k_mask,表示哪些token的概率应该被设置为0,以便只保留 top_k 最高的概率的token。
top_k_mask = torch.arange(probs_idx.shape[-1], device=probs_idx.device)
top_k_mask = top_k_mask.expand(probs_idx.shape[0], -1)
top_k_mask = top_k_mask >= k.unsqueeze(dim=1)
# 使用此遮罩将不满足条件的token的概率设置为0。
probs_sort[top_k_mask] = 0.0
# Re-sort the probabilities.
# 使用原始索引 probs_idx 将裁剪后的概率 probs_sort 还原到其原始顺序,得到最终的裁剪后的概率 probs。
probs = torch.gather(probs_sort,
dim=-1,
index=torch.argsort(probs_idx, dim=-1))
return probs
# 这个函数 _get_topk_logprobs 的主要目的是从输入的 logprobs Tensor中
# 提取最大的 num_logprobs 个对数概率值,并返回一个字典,其中键是token的ID,值是对应的对数概率值。
def _get_topk_logprobs(
logprobs: torch.Tensor,
num_logprobs: Optional[int],
) -> Dict[int, float]:
if num_logprobs is None or num_logprobs == 0:
return {}
# 使用 torch.topk 函数从 logprobs 中提取最大的 num_logprobs 个
# 对数概率值和对应的token的ID。这个函数返回两个值:最大的对数概率值和对应的token的ID。
topk_logprobs, topk_ids = torch.topk(logprobs, num_logprobs)
# 如果 num_logprobs 是1,那么 topk_logprobs 和 topk_ids 都是标量。
# 在这种情况下,我们需要调用 .item() 来从这些Tensor中获取Python的数值。
# 否则,我们调用 .tolist() 将这两个Tensor转换为Python的列表。
if num_logprobs == 1:
topk_logprobs = [topk_logprobs.item()]
topk_ids = [topk_ids.item()]
else:
topk_logprobs = topk_logprobs.tolist()
topk_ids = topk_ids.tolist()
# 初始化一个空字典 token_to_logprob。
token_to_logprob: Dict[int, float] = {}
# 使用 zip 函数遍历 topk_ids 和 topk_logprobs,并将每个token的ID和对应的对数概率值添加到字典中。
for token_id, logprob in zip(topk_ids, topk_logprobs):
token_to_logprob[token_id] = logprob
return token_to_logprob
# 这个函数 _sample_from_prompt 的目的是根据给定的概率分布 prob 和
# 采样参数 sampling_params 从一个prompt中进行采样,并返回采样得到的token的ID列表。
def _sample_from_prompt(
prob: torch.Tensor,
sampling_params: SamplingParams,
) -> List[int]:
if sampling_params.use_beam_search:
# Beam search.
# beam_width 设置为 sampling_params.best_of 的值。
# 束搜索通常会选择多个可能的路径,并在每一步保持这些路径的数量。
beam_width = sampling_params.best_of
# 使用 torch.topk 函数从 prob 中选择 beam_width 个具有最大概率的tokens。
_, next_token_ids = torch.topk(prob, beam_width)
# 将得到的tokens转化为Python列表。
next_token_ids = next_token_ids.tolist()
elif sampling_params.temperature < _SAMPLING_EPS:
# Greedy sampling.
# 确认 sampling_params.best_of 的值为1。因为贪心采样只选择一个具有最高概率的token。
assert sampling_params.best_of == 1
# 使用 torch.argmax 函数从 prob 中选择具有最大概率的token。
next_token_id = torch.argmax(prob)
next_token_ids = [next_token_id.item()]
else:
# Random sampling.
# Sample `best_of` tokens for the prompt.
# 设置 num_seqs 为 sampling_params.best_of 的值。这表示我们要采样多少个tokens。
num_seqs = sampling_params.best_of
# 使用 torch.multinomial 函数从 prob 中随机采样 num_seqs 个tokens。
# replacement=True 表示可以重复采样同一个token。
next_token_ids = torch.multinomial(prob,
num_samples=num_seqs,
replacement=True)
next_token_ids = next_token_ids.tolist()
# 返回 next_token_ids 列表,这是从提示中采样得到的token的ID列表。
return next_token_ids
# 这个函数 _sample_from_generation_tokens 主要是根据给定的概率分布和参数来对生成的token进行采样。
def _sample_from_generation_tokens(
seq_ids: List[int],
probs: torch.Tensor,
logprobs: torch.Tensor,
seq_logprobs: List[float],
sampling_params: SamplingParams,
) -> Tuple[List[int], List[int]]:
# NOTE(woosuk): sampling_params.best_of can be greater than
# len(seq_ids) because some sequences in the group might have
# been already terminated.
if sampling_params.use_beam_search:
# Beam search.
# Add cumulative logprobs for the sequences in the group.
# 首先,将 seq_logprobs 添加到每个token的 logprobs 中,
# 因为束搜索的计算需要考虑整个序列的累计对数概率。
seq_logprobs = torch.tensor(seq_logprobs,
dtype=torch.float,
device=logprobs.device)
logprobs = logprobs + seq_logprobs.unsqueeze(dim=1)
# 确定词汇表大小和束宽。
vocab_size = logprobs.size(-1)
beam_width = len(seq_ids)
# 从扁平化的 logprobs 中获取最高的 beam_width 个对数概率及其对应的索引。
_, topk_ids = torch.topk(logprobs.flatten(), beam_width)
# 根据获取的最高的索引,计算出对应的序列索引 seq_idx 和token索引 token_ids。
topk_ids = topk_ids.tolist()
seq_idx = [i // vocab_size for i in topk_ids]
beam_seq_ids = [seq_ids[i] for i in seq_idx]
token_ids = [i % vocab_size for i in topk_ids]
# 初始化一个空的字典 beam_outputs 来存储当前步的最佳序列和token。
beam_outputs: Dict[int, Tuple[int, int]] = {}
outstanding_beams: List[Tuple[int, int]] = []
# If a beam survives, continue with it.
# 遍历序列和token,将它们添加到 beam_outputs 中。
# 如果某个序列已经存在于 beam_outputs 中,则将它添加到 outstanding_beams 列表中。
for seq_id, token_id in zip(beam_seq_ids, token_ids):
if seq_id not in beam_outputs:
beam_outputs[seq_id] = (seq_id, token_id)
else:
outstanding_beams.append((seq_id, token_id))
# If a beam is discarded, fork another beam.
# 如果某个序列没有在 beam_outputs 中,
# 则从 outstanding_beams 中弹出一个并添加到 beam_outputs 中。
for seq_id in seq_ids:
if seq_id not in beam_outputs:
beam_outputs[seq_id] = outstanding_beams.pop()
assert not outstanding_beams
# 最后,从 beam_outputs 中提取父序列ID和下一个token ID。
parent_seq_ids = [beam_outputs[seq_id][0] for seq_id in seq_ids]
next_token_ids = [beam_outputs[seq_id][1] for seq_id in seq_ids]
elif sampling_params.temperature < _SAMPLING_EPS:
# Greedy sampling.
assert len(seq_ids) == 1
next_token_id = torch.argmax(probs, dim=-1)
next_token_ids = [int(next_token_id.item())]
parent_seq_ids = seq_ids
else:
# Random sampling.
# Sample 1 token for each sequence in the group.
next_token_ids = torch.multinomial(probs,
num_samples=1,
replacement=True)
next_token_ids = next_token_ids.squeeze(dim=-1).tolist()
parent_seq_ids = seq_ids
return parent_seq_ids, next_token_ids
# 这个函数 _sample 的目的是基于给定的概率分布和输入元数据来对token进行采样,并为每个序列返回一个采样结果。
def _sample(
probs: torch.Tensor,
logprobs: torch.Tensor,
input_metadata: InputMetadata,
) -> Dict[int, SequenceOutputs]:
seq_outputs: Dict[int, SequenceOutputs] = {}
# TODO(woosuk): Optimize.
idx = 0
# 对于input_metadata.seq_groups中的每个seq_group:
for i, seq_group in enumerate(input_metadata.seq_groups):
# 提取seq_ids(序列ID)和sampling_params(采样参数)。
seq_ids, sampling_params = seq_group
# 处理prompt
if i < input_metadata.num_prompts:
# Generate the next tokens for a prompt input.
assert len(seq_ids) == sampling_params.best_of
prob = probs[idx]
logprob = logprobs[idx]
idx += 1
# Sample the next tokens.
next_token_ids = _sample_from_prompt(prob, sampling_params)
# Get top-k log probabilities for the next tokens.
next_logprobs = _get_topk_logprobs(logprob,
sampling_params.logprobs)
# Build the output.
for seq_id, next_token_id in zip(seq_ids, next_token_ids):
output_logprobs = next_logprobs.copy()
output_logprobs[next_token_id] = logprob[next_token_id].item()
seq_outputs[seq_id] = SequenceOutputs(seq_id, seq_id,
next_token_id,
output_logprobs)
# 处理生成的token
else:
# Generate the next tokens for generation tokens.
prob = probs[idx:idx + len(seq_ids)]
logprob = logprobs[idx:idx + len(seq_ids)]
idx += len(seq_ids)
# Sample the next tokens.
seq_logprobs = [
input_metadata.seq_data[seq_id].cumulative_logprob
for seq_id in seq_ids
]
parent_seq_ids, next_token_ids = _sample_from_generation_tokens(
seq_ids, prob, logprob, seq_logprobs, sampling_params)
# Get top-k log probabilities for the next tokens.
next_logprobs: Dict[int, Dict[int, float]] = {}
for j, seq_id in enumerate(seq_ids):
next_logprobs[seq_id] = _get_topk_logprobs(
logprob[j], sampling_params.logprobs)
# Build the output.
for seq_id, parent_seq_id, next_token_id in zip(
seq_ids, parent_seq_ids, next_token_ids):
j = seq_ids.index(parent_seq_id)
output_logprobs = next_logprobs[parent_seq_id].copy()
output_logprobs[next_token_id] = logprob[j,
next_token_id].item()
seq_outputs[seq_id] = SequenceOutputs(
seq_id,
parent_seq_id,
next_token_id,
output_logprobs,
)
return seq_outputs
在_sample这个函数中,分别对prompt和generation进行了处理。我们可以从_sample_from_prompt和_sample_from_generation_tokens这两个函数中发现,只有在beam search方法时对prompt和generation的处理方式不一样。如果我们输入有n个prompt,也就是n个seq_group,然后每个seq_group有 best_of 个 seqs。我们在prompt阶段要做的就是对于每个 seq_group,我们从对应分布中取 top best_of 的结果,然后把它们和每个 seq_id 对应。而对于后续的 generation 阶段,注意现在每一次下一步都有 best_of * vocab_size 的空间,然后会在这个空间中取topk(_, topk_ids = torch.topk(logprobs.flatten(), beam_width))。然后我们知道这些 topk 可能有多个来自同一个 parent seq。然后它的策略是,一个 parent id 对应的第一个 output 会放到对应的位置,其它的 output 会被放到某个驱逐的 parent id 对应的位置。这里也就是了VLLM的fork机制,Fork 的过程在 Block Manager 里实现就是,child seq 会拷贝 parent seq 的 block table,同时给对应的 block 加上 ref counter。这个fork不是在sampler阶段做的,而是在scheduler update 的位置 fork。
在scheduler的update函数里面,涉及到针对beam search采样的fork调用:
以及Block Manager的fork函数:
# 这段代码定义了BlockSpaceManager类中的fork方法,该方法的目的是为子序列创建一个块表,
# 该表是基于其父序列的块表的副本。此函数确保每个物理块的引用计数在分叉时正确地增加,
# 这是因为两个序列(父序列和子序列)现在共享相同的物理块。
def fork(self, parent_seq: Sequence, child_seq: Sequence) -> None:
# NOTE: fork does not allocate a new physical block.
# Thus, it is always safe from OOM.
# 从块表映射中,根据父序列的ID获取其块表。
src_block_table = self.block_tables[parent_seq.seq_id]
# 为子序列创建一个新的块表,这个块表是父序列块表的一个副本。这
# 意味着父序列和子序列现在都引用相同的物理块,但是它们有各自独立的逻辑块。
self.block_tables[child_seq.seq_id] = src_block_table.copy()
# 由于子序列现在也引用相同的物理块,所以需要增加每个物理块的引用计数。
# 这确保了物理块不会在它仍然被使用时被意外释放。
for block in src_block_table:
block.ref_count += 1
可以看到fork只是增加parent seq的物理块引用计数,而在给新的 token allocate 物理块的时候,如果发现之前的 block 是引用,则会在此时 allocate 真正的 block,并且拷贝数据(拷贝是先在 scheduler 的_schedule函数里生成 blocks_to_copy 这个信息包,传到 engine 部分进一步传给worker由对应的 cuda kernel真正执行)。这个过程也就是VLLM的copy on write,对应了以下的几张图:
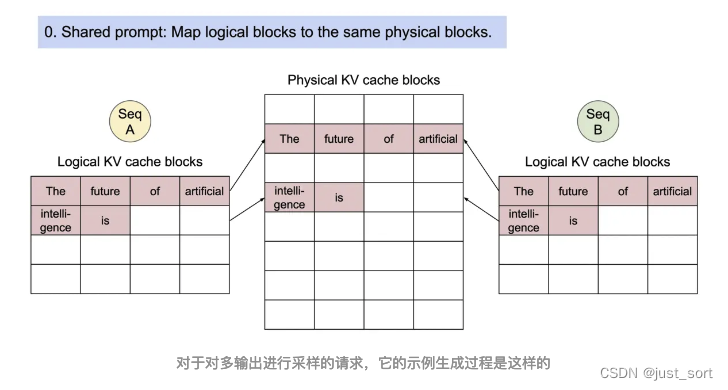
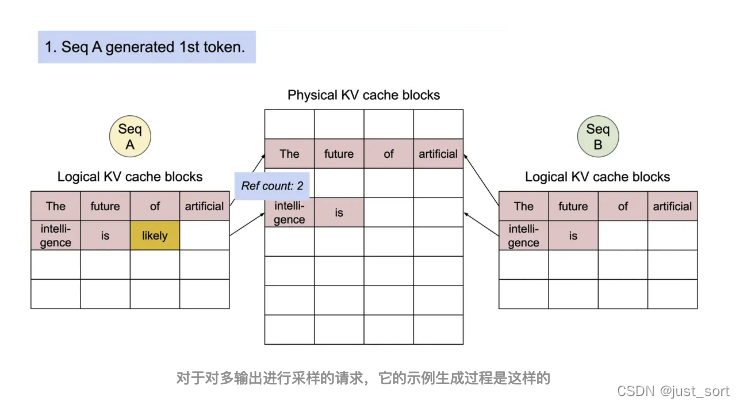
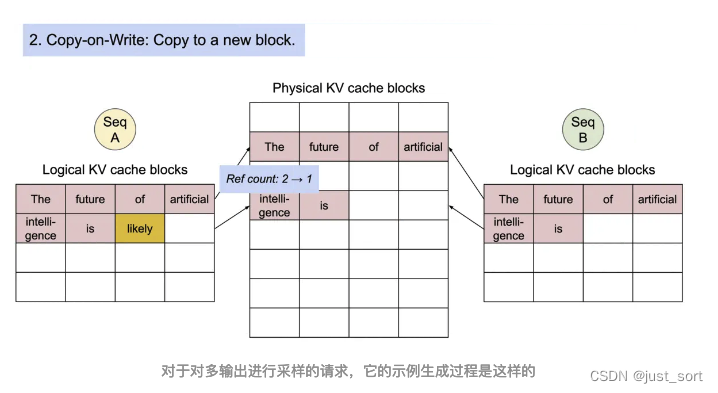
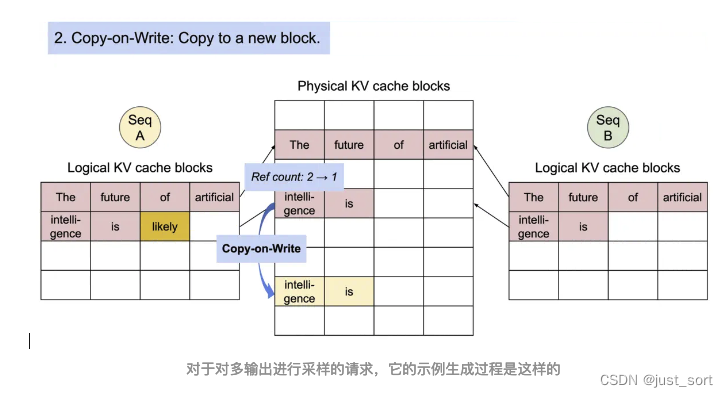
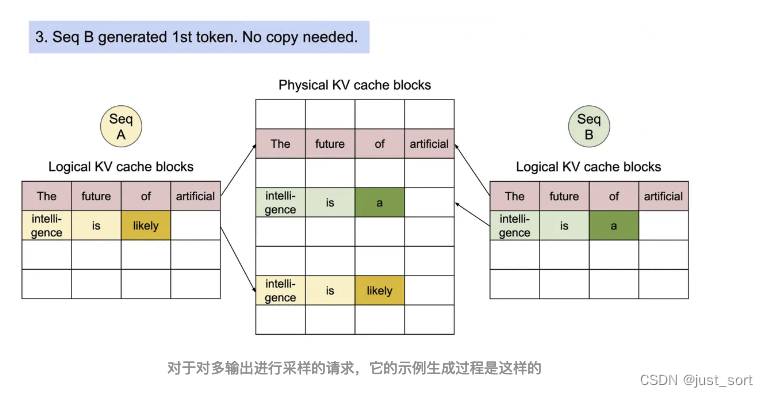
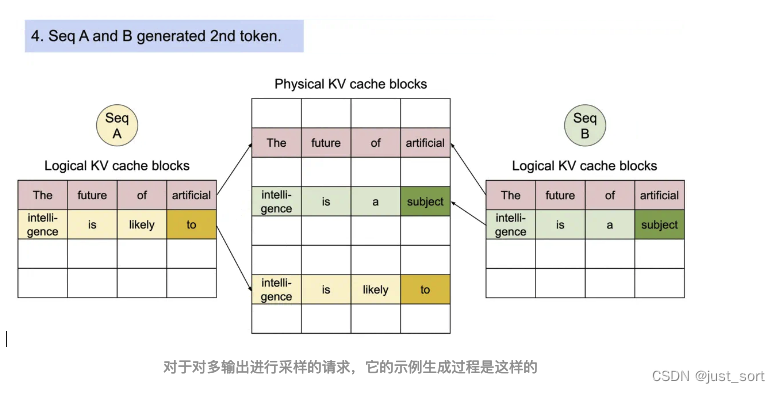
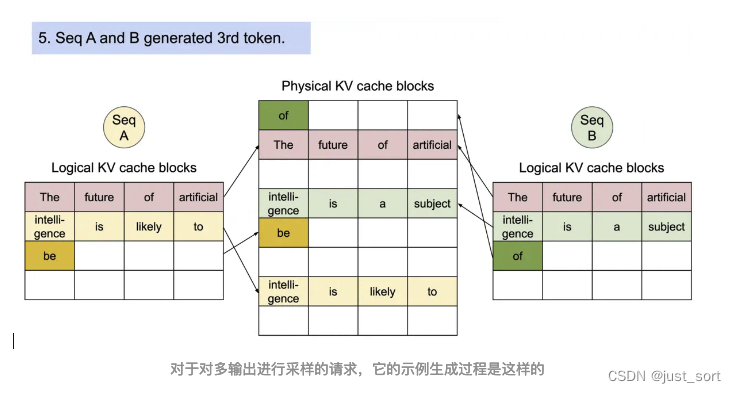
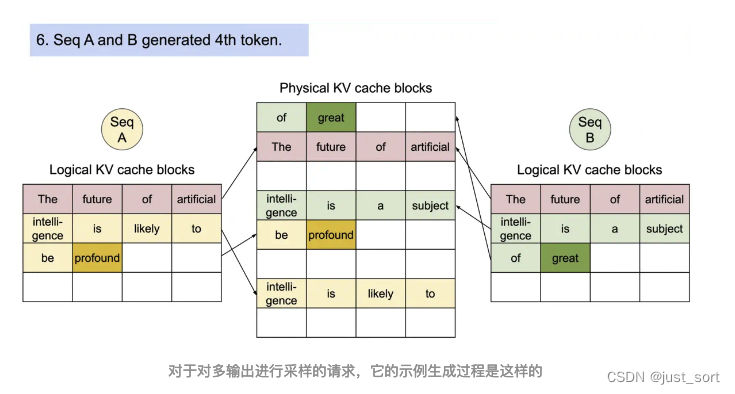
0x9. Paged Attention 机制
在模型执行这一节,大概了解了Paged Attention的注意力计算分成2个部分,第一个部分(generated by prompts)注意力计算是通过 multi_query_kv_attention 执行,实现上直接用了 xformers。算完之后会把 key 和 value 的值 cache 进去(reshape_and_cache)。在后续的生成(generated by generation tokens)是通过 single_query_kv_attention 实现的,也就是 vLLM 的 Paged Attention。
这个地方比较重要,细节也比较多,后续打算单独再研究和讲一下。
0x10. 总结
这篇文章主要是对VLLM的流程进行了梳理,还没有解析Paged Attention的实现,等下次有空再研究一下。