线性表:

顺序表
概念及结构
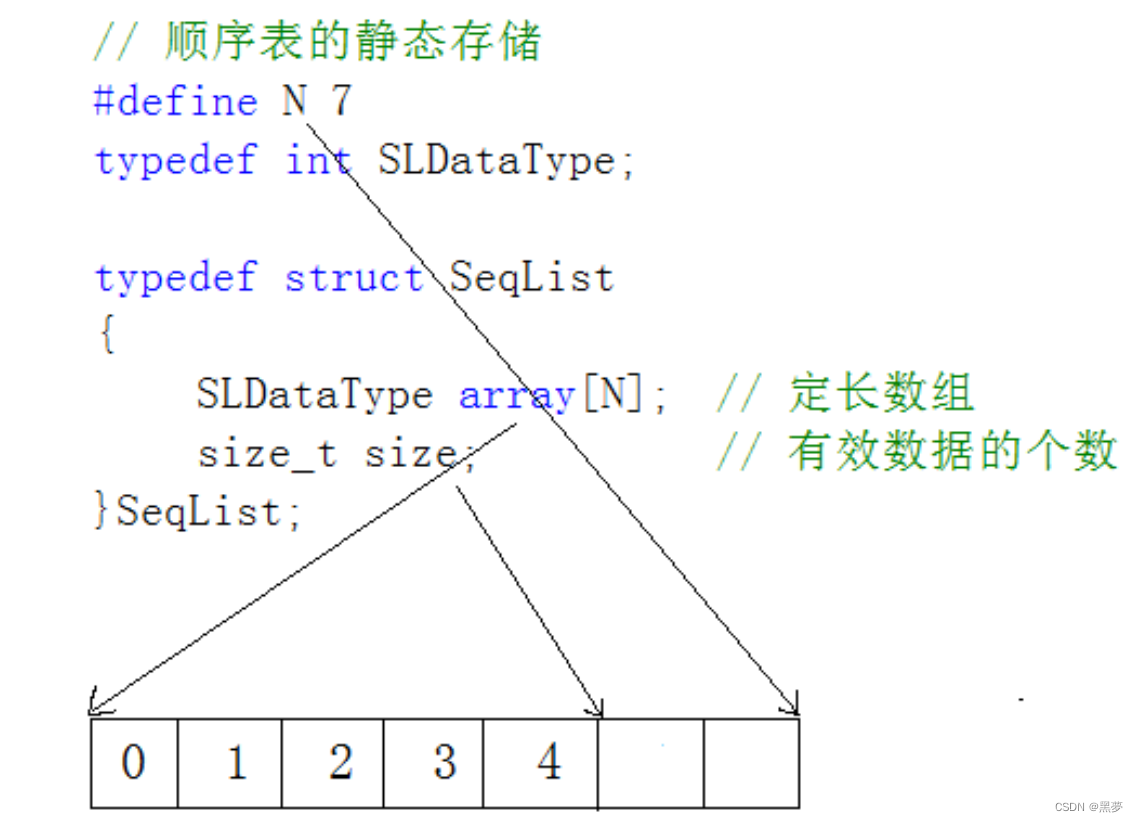
静态顺序表:使用定长数组存储元素。
动态顺序表:使用动态开辟的数组存储。
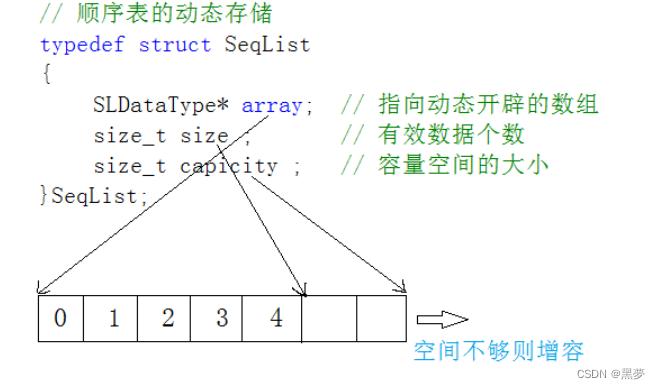
如果将一开始动态开辟的内存填满,则会进行扩容,
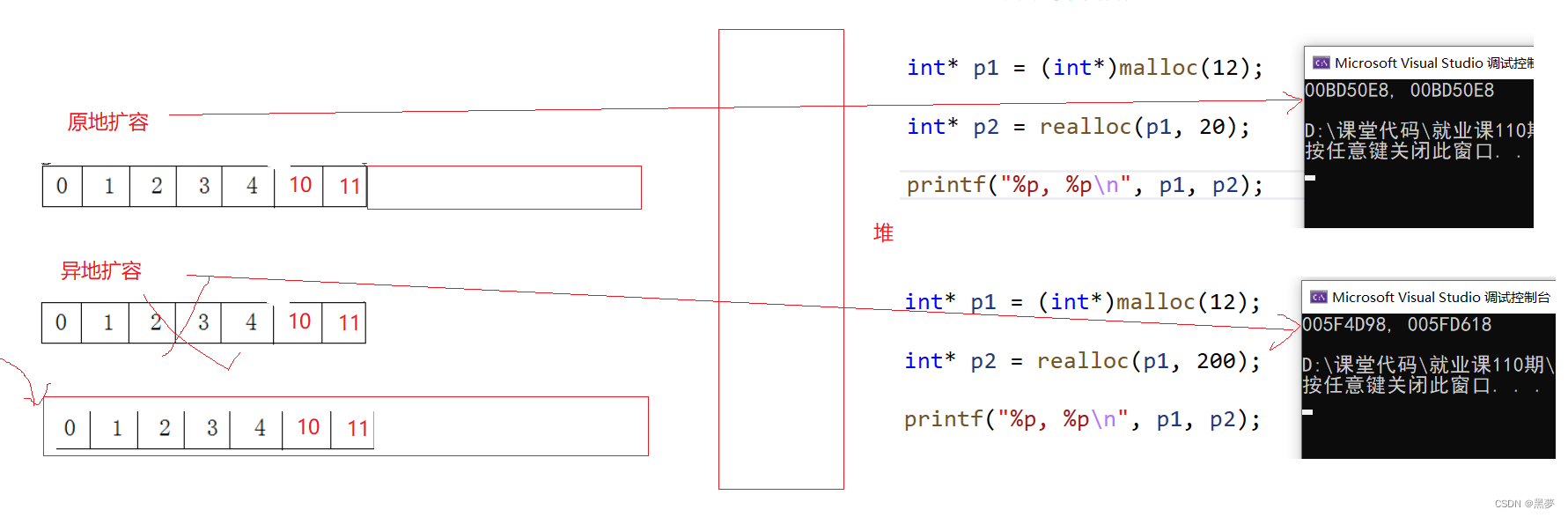
扩容分两种情况:
原地扩容:在已开辟的动态内存后进行判断,如果后方内存大小足够扩容到新定义的大小,则在之前开辟的内存后面加上一段,以达到新定义内存大小;
异地扩容:如果在已开辟的动态内存后进行判断,后方的大小不足以扩容到新定义的大小,则会在内存中寻找一块新的足够容纳新定义大小的空间,并将之前的数据拷贝到新空间,再释放之前定义的动态内存空间;
接口实现
typedef int SLDateType;
typedef struct SeqList
{
SLDateType* a;//动态开辟的数组
int size; //数据个数
int capacity;//容量空间大小
}SL;
//初始化
void SLInit(SL* ps);//释放或销毁
void SLDestroy(SL* ps);//显示或打印
void SLPrintf(SL* ps);//尾插
void SLPushBack(SL* ps, SLDateType x);
//尾删
void SLPopBack(SL* ps);
//头插
void SLPushFront(SL* ps, SLDateType x);
//头删
void SLPopFront(SL* ps);//扩容
void SLCheckDestroy(SL* ps);//顺序表查找
int SLFind(SL* ps,int n);// 顺序表在pos位置插入x
void SLInsert(SL* ps, int pos, SLDateType x);// 顺序表删除pos位置的值
void SLErase(SL* ps, int pos);//顺序表修改
void SLModify(SL* ps,int pos,SLDateType x);
#define _CRT_SECURE_NO_WARNINGS 1
#include "Sequence.h"
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
//初始化
void SLInit(SL* ps)
{
ps->a = (SLDateType*)malloc(sizeof(SLDateType*)*4);
if (ps->a == NULL)
{
perror("malloc failed");
exit(-1);
}
ps->size = 0;
ps->capacity = 4;
}
//释放或销毁
void SLDestroy(SL* ps)
{
free(ps->a);
ps->a = NULL;
ps->capacity = ps->size = 0;
}
//显示或打印
void SLPrintf(SL* ps)
{
int i = 0;
for (i = 0; i < ps->size; i++)
{
printf("%d ", ps->a[i]);
}
printf("\n");
}//扩容
void SLCheckDestroy(SL* ps)
{
if (ps->size == ps->capacity)
{
SLDateType* tmp = (SLDateType*)realloc(ps->a, sizeof(SLDateType) * 2 * ps->capacity);
if (tmp == NULL)
{
perror("realloc failed");
exit(-1);
}
ps->a = tmp;
ps->capacity *= 2;
}
}
//尾插void SLPushBack(SL* ps, SLDateType x)
{
SLCheckDestroy(ps);//ps->a[ps->size] = x;
//ps->size++;SLInsert(ps,ps->size,x);
}//尾删
void SLPopBack(SL* ps)
{
assert(ps);
//温柔型
//if (ps->size == 0)
//{
// return;
//}
//暴力型
//assert(ps->size > 0);//ps->size--;
SLErase(ps, ps->size - 1);
}
//头插void SLPushFront(SL* ps, SLDateType x)
{
assert(ps);
SLCheckDestroy(ps);
//int i = 0;
//for (i = 0; i < ps->size ; i++)
//{
// ps->a[ps->size-i] = ps->a[ps->size - i -1];
//}
//ps->a[0] = x;
//ps->size++;
SLInsert(ps, 0, x);
}//头删
void SLPopFront(SL* ps)
{
//防止越界
assert(ps->size > 0);//int i = 0;
//for (i = 0; i < ps->size - 1; i++)
//{
// ps->a[i] = ps->a[i+1];
//}
//ps->size--;SLErase(ps, 0);
}//查找
int SLFind(SL* ps, int n)
{
int i = 0;
for (i = 0; i < ps->size; i++)
{
if (ps->a[i] == n)
{
return i;
}
}
return -1;
}
// 顺序表在pos位置插入xvoid SLInsert(SL* ps, int pos, SLDateType x)
{
assert(ps);
//=0相当于头插,=size等于尾插
assert(pos >= 0 && pos <= ps->size);SLCheckDestroy(ps);
int start = ps->size - 1 ;
while (start >= pos)
{
ps->a[start + 1] = ps->a[start];
start--;
}
ps->a[pos] = x;
ps->size++;
}
// 顺序表删除pos位置的值void SLErase(SL* ps, int pos)
{
assert(ps);assert(pos >= 0 && pos < ps->size);
int begin = pos + 1;
while (begin < ps->size)
{
ps->a[begin - 1] = ps->a[begin];
begin++;
}
ps->size--;
}//顺序表修改
void SLModify(SL* ps, int pos, SLDateType x)
{
assert(ps);
assert(pos >= 0 && pos < ps->size);ps->a[pos];
}
值得注意的是:


如果没有使用温柔型或者暴力型判断,可能会发生数组越界,但是一般情况下,编译器不会报错,因为编译器只在数组两天的特定位置放置了越界标记,需要触发才会报错,触发一般是在编译结束时到数组越界标记访问,此时越界了,但没有在此处赋值,也不会报错。
顺序表总结:
缺点:
1.头部和中部插入和删除效率不高O(n);
2.空间不足时,扩容有一定的消耗(尤其是异地扩容)如:开辟空间,拷贝,释放旧空间;
3.扩容逻辑,可能存在空间浪费(200个,但是只用110个)。
优点:
1.尾插尾删足够快;
2.下标的随机访问和修改。
链表
链表的概念及结构:
特点:按需申请释放
逻辑上分析链表如图:

值得注意:
1.上图,链式结构在逻辑上是连续的,在物理上不一定是连续的;
2.现实中的结点一般是在堆上申请;
3.堆上申请的空间,可能连续,也可能不连续。
物理上分析链表如下:

1.单向链表的实现:
// 1 、无头 + 单向 + 非循环链表增删查改实现typedef int SLTDateType ;typedef struct SListNode{SLTDateType data ;struct SListNode * next ;} SListNode ;// 动态申请一个结点SListNode * BuySListNode ( SLTDateType x );// 单链表打印void SListPrint ( SListNode * plist );// 单链表尾插void SListPushBack ( SListNode ** pplist , SLTDateType x );// 单链表的头插void SListPushFront ( SListNode ** pplist , SLTDateType x );// 单链表的尾删void SListPopBack ( SListNode ** pplist );// 单链表头删void SListPopFront ( SListNode ** pplist );// 单链表查找SListNode * SListFind ( SListNode * plist , SLTDateType x );// 单链表在 pos 位置之后插入 x// 分析思考为什么不在 pos位置之前插入?void SListInsertAfter ( SListNode * pos , SLTDateType x );// 单链表删除 pos 位置之后的值// 分析思考为什么不删除 pos 位置?void SListEraseAfter ( SListNode * pos );//销毁
void SListDestory ( SListNode** phead );
// 动态申请一个结点
SListNode* BuySListNode(SLDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}// 单链表打印
void SListPrint(SListNode* phead)
{
SListNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}特别需要注意的是

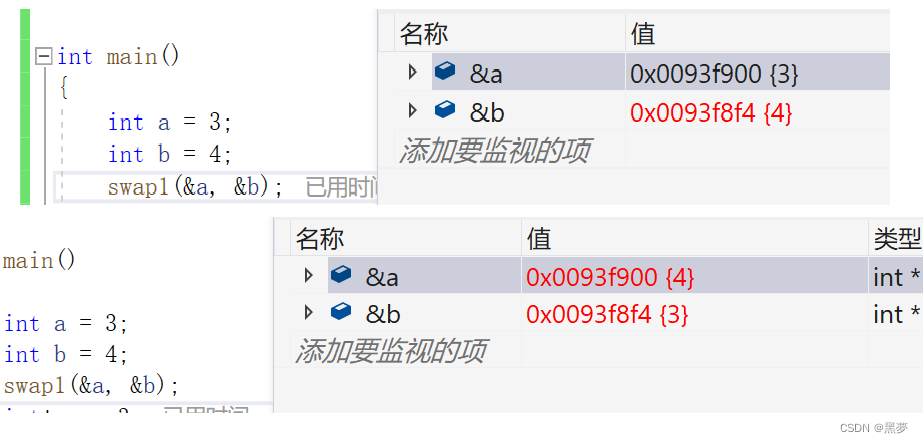

上面两张图中,图一说明改变成员,要用成员的指针,
图二说明改变成员的指针,要用成员的指针的指针(二级指针)

// 单链表尾插
void SListPushBack(SListNode** phead, SLDataType x)
{
assert(phead);
SListNode* newnode = BuySListNode(x);
if (*phead == NULL)
{
// 改变的结构体的指针,所以要用二级指针
*phead = newnode;
}
else
{
SListNode* tail = *phead;
while (tail->next != NULL)
{
tail = tail->next;
}
// 改变的结构体,用结构体的指针即可
tail->next = newnode;
}
}
// 单链表的头插
void SListPushFront(SListNode** phead, SLDataType x)
{
assert(phead);
SListNode* newnode = BuySListNode(x);
newnode->next = *phead;
*phead = newnode;
}// 单链表的尾删
void SListPopBack(SListNode** phead)
{
assert(phead);
//0个
assert(*phead);
//1个或以上
if ((*phead)->next == NULL)
{
free(*phead);
*phead = NULL;
}
else
{
SListNode* tail = *phead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}// 单链表头删
void SListPopFront(SListNode** phead)
{
assert(phead);
assert(*phead);
SListNode* newnode = (*phead)->next;
free(*phead);
*phead = newnode;
}//查找
SListNode* SListFind(SListNode* phead, SLDataType x)
{
SListNode* newnode = phead;
while (newnode)
{
if (newnode->data == x)
{
return newnode;
}
newnode = newnode->next;
}
return NULL;
}//在pos之后插入x
void SListInsertAfter(SListNode* pos, SLDataType x)
{
assert(pos);
SListNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}//在pos之前插x
void SLTInsert(SListNode** phead, SListNode* pos, SLDataType x)
{
assert(pos);
//方法一
if (pos == *phead)
{
SListPushFront(phead, x);
}
else
{
SListNode* tail = *phead;
while (tail->next != pos)
{
tail = tail->next;
}
SListNode* newnode = BuySListNode(x);
tail->next = newnode;
newnode->next = pos;
}
//方法二
//SListNode* tail = *phead;
//while (newnode->next == NULL)
//{
// if (*phead == pos)
// {
// newnode->next = tail;
// *phead = newnode;
// }
// if (tail->next == pos)
// {
// newnode->next = tail->next;
// tail->next = newnode;
// }
// else
// {
// tail = tail->next;
// }
//}
}
// 删除pos位置
void SLTErase(SListNode** phead, SListNode* pos)
{
assert(phead);
assert(pos);
SListNode* tail = *phead;
if (*phead == pos)
{
SListPopFront(phead);
//*phead = pos->next;
//return;
}
while (tail->next != pos->next)
{
if (tail->next == pos)
{
tail->next = tail->next->next;
}
else
{
tail = tail->next;
}
}
free(pos);
//pos = NULL;//形参不改变实参,在调用外面置空
}// 删除pos的后一个位置
void SLTEraseAfter(SListNode* pos)
{
assert(pos);
assert(pos->next);//如果pos没有下一个,报错
SListNode* postNext = pos->next;
pos->next = pos->next->next;
free(postNext);
postNext = NULL;
}//销毁
void SListDestory(SListNode** phead)
{
assert(phead);
SListNode* cur = *phead;
while (cur)
{
SListNode* node = cur->next;
free(cur);
cur = node;
}
*phead = NULL;
}替换发删除:
将下一个节点的值给pos,然后删除pos->next的节点。
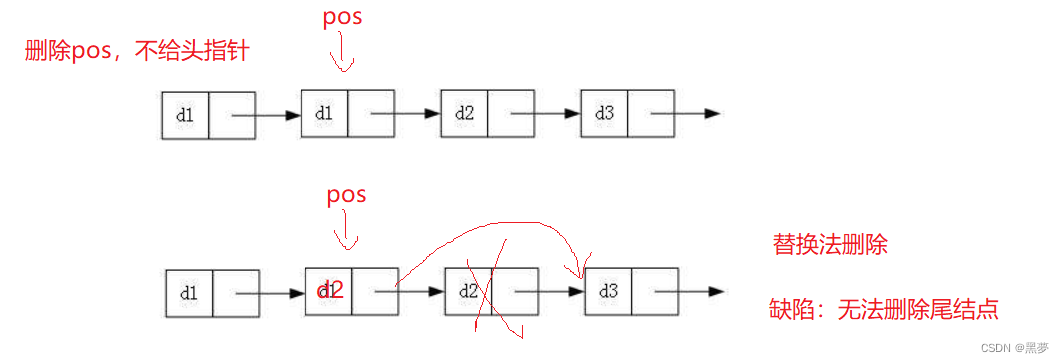
2.双向链表的实现:
// 2 、带头 + 双向 + 循环链表增删查改实现typedef int LTDataType ;typedef struct ListNode{LTDataType _data ;struct ListNode * next ;struct ListNode * prev ;} ListNode ;// 创建返回链表的头结点 .ListNode * ListCreate ();// 双向链表销毁void ListDestory ( ListNode * plist );// 双向链表打印void ListPrint ( ListNode * plist );// 双向链表尾插void ListPushBack ( ListNode * plist , LTDataType x );// 双向链表尾删void ListPopBack ( ListNode * plist );// 双向链表头插void ListPushFront ( ListNode * plist , LTDataType x );// 双向链表头删void ListPopFront ( ListNode * plist );// 双向链表查找ListNode * ListFind ( ListNode * plist , LTDataType x );// 双向链表在 pos 的前面进行插入void ListInsert ( ListNode * pos , LTDataType x );// 双向链表删除 pos 位置的结点void ListErase ( ListNode * pos );
// 创建返回链表的头结点
ListNode* BuyLTNode(LTDataType x)
{
ListNode* node = (ListNode*)malloc(sizeof(ListNode));
if (node == NULL)
{
perror("malloc fail");
exit(-1);
}
node->data = x;
node->next = NULL;
node->prev = NULL;
return node;
}
// 创建返回链表的头结点.
ListNode* ListCreate()
{
ListNode* head = BuyLTNode(0);
head->next = head;
head->prev = head;
return head;
}// 双向链表打印
// 双向链表打印
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* node = pHead->next;
while (node != pHead)
{
printf("%d->",node->data);
node = node->next;
}
printf("NULL\n");
}// 双向链表在pos的前面进行插入
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* newnode = BuyLTNode(x);
ListNode* oldnode = pos->prev;
newnode->prev = oldnode;
oldnode->next = newnode;
newnode->next = pos;
pos->prev = newnode;
}// 双向链表删除pos位置的节点
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* oldnode = pos->prev;
oldnode->next = pos->next;
pos->next->prev = oldnode;
free(pos);
}// 双向链表尾插
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListInsert(pHead,x);
}// 双向链表头插
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListInsert(pHead->next,x);
}// 双向链表尾删
// 双向链表尾删
void ListPopBack(ListNode* pHead)
{
assert(pHead);
//
assert(pHead->next != pHead);
ListErase(pHead->prev);
}
// 双向链表头删
// 双向链表头删
void ListPopFront(ListNode* pHead)
{
assert(pHead);
//
assert(pHead->next != pHead);
ListErase(pHead->next);
}// 双向链表查找
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* node = pHead->next;
while(node != pHead)
{
if (node->data == x)
{
return node;
}
node = node->next;
}
return NULL;
}// 双向链表销毁
// 双向链表销毁
void ListDestory(ListNode* pHead)
{
assert(pHead);
ListNode* oldnode = pHead->next;
while (oldnode != pHead)
{
ListNode* oldnode1 = oldnode->next;
free(oldnode);
oldnode = oldnode1;
}
free(pHead);
printf("销毁完成!\n");
}链表和顺序表的区别:

缓存利用率:

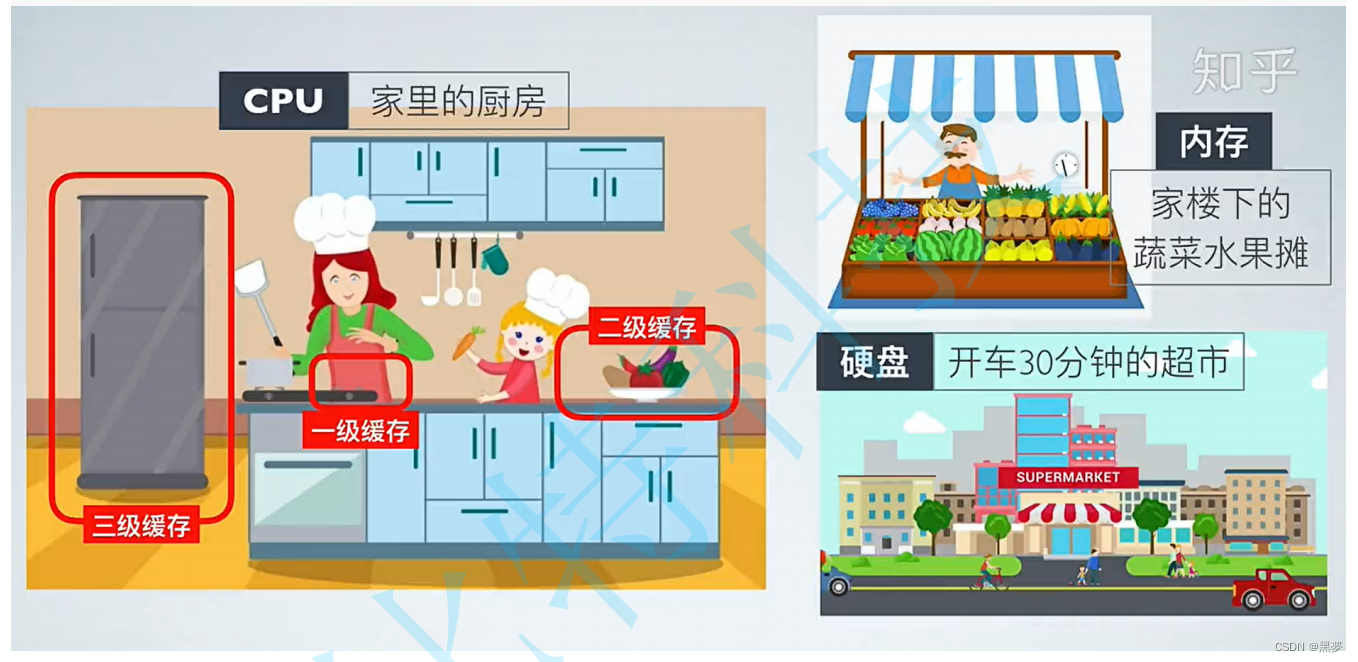
以上就是个人学习线性表的个人见解和学习的解析,欢迎各位大佬在评论区探讨!
感谢大佬们的一键三连! 感谢大佬们的一键三连! 感谢大佬们的一键三连!

![[Docker精进篇] Docker部署和实践 (二)](https://img-blog.csdnimg.cn/d04569087a4d424192bf2cbdb53d7177.png#pic_center)