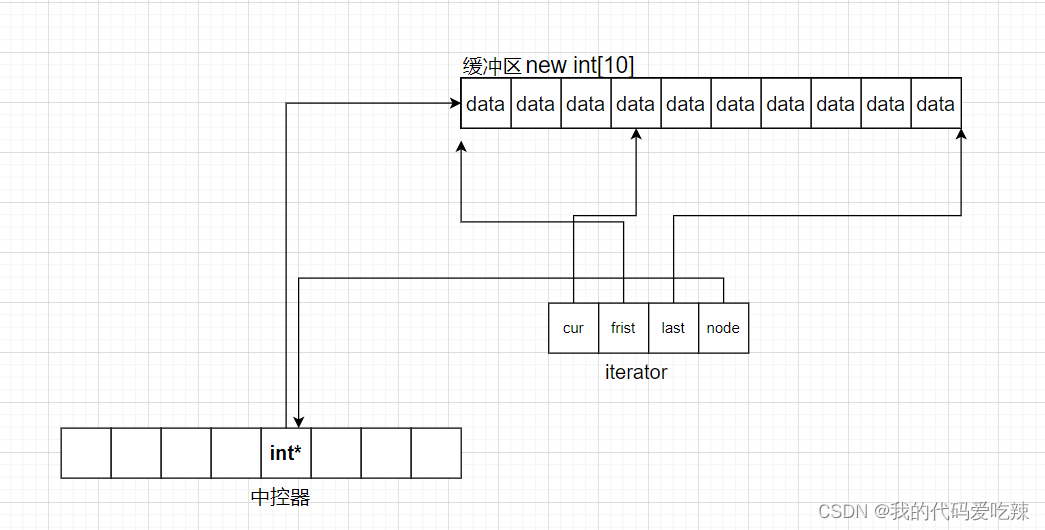
2023年8月第1~2周大模型荟萃
- 2023.8.14
- 版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、黑客制造了一款基于 AI 的恶意工具 FraudGPT
早先,有黑客制作了一个“没有道德限制”的 WormGPT 聊天机器人,可以自动生成一系列钓鱼邮件。目前,又有黑客制造了一个基于 AI 的恶意工具 FraudGPT,黑客在售卖页表示,该工具可用于编写恶意代码、创建出“一系列杀毒软件无法检测的恶意软件”、检测网站漏洞、自动进行密码撞库。据称不到一周已经有逾 3000 名买家下单。
Netenrich 公司研究员 Rakesh Krishnan 声称,FraudGPT 自 7 月 22 日以来,一直在暗网流通,订阅费用为每月 200 美元(约 1429.46 元人民币)、六个月 1000 美元(约 7147.3 元人民币),一年 1700 美元(约 12150.41 元人民币)。
2、小米大模型首次曝光
小米大模型MiLM-6B于近日现身C-Eval大模型评测榜单,在C-Eval榜单中排名第9,排在阿里的通义千问大模型之前,仍然落后于清华的ChatGLM2-12B。
小米于今年4月正式组建AI实验室大模型团队,号称投入AI领域人员超1200人,短短4月就初步完成了大模型的训练和部署,成绩显著。小米总裁卢伟冰发言表示,会积极拥抱大模型,但不会像Open AI一样做通用大模型,而是会深度和业务结合协同,利用AI技术提升内部效率。但是从目前公开的信息来看,做的仍然是通用大模型。
3、鸿蒙4.0集成大模型应用
8 月 4 日华为正式发布了 HarmonyOS 4.0,其中一个显著的特点是接入了盘古AI大模型,在智能助手小艺的功能中引入了AI对话和文本生成能力。小艺可以帮助用户识别图片中的内容和文字,朗读文字内容,接入更多服务。在原有的语音交互基础上,小艺扩展了文字、图片、文档等多种形式的输入。用日常说话的方式自然地与 AI 交流,小艺就可以自动帮用户完成任务。
华为针对终端消费者场景构建了大量的场景数据与精调模型后的L1层对话模型,并将该模型用在了智慧助手小艺中,华为也成为国内率先将大模型能力融入智慧助手并面向消费者落地的科技公司。这种思路值得点赞。
4、OPPO引入阿里通义千问大模型
今年4月,阿里云宣布将与OPPO安第斯智能云联合打造OPPO大模型基础设施,基于通义千问完成大模型的持续学习、精调及前端提示工程,建设服务于OPPO终端用户的AI服务。OPPO中国区总裁刘波曾在接受采访时提到,OPPO内部在思考大模型在手机端的应用。OPPO的小布助手团队一直在AI技术领域开展大量研究,包括语音识别、语义理解、对话生成、知识问答系统、开放域聊天、多模态等。
5、微软亚洲研究院探索将LLM用于工业控制
最近,微软亚洲研究院提出可以将LLM用于工业控制,而且仅需少量示例样本就能达成优于传统强化学习方法的效果。该研究尝试使用GPT-4来控制空气调节系统(HVAC),得到了相当积极的结果。研究团队设计了一种机制来从专家演示和历史交互挑选示例,还设计了一种可将目标、指示、演示和当前状态转换为prompt的prompt生成器。然后,再使用生成的prompt,通过LLM来给出控制。
6、英伟达发布CALMAI模型
英伟达近日和以色列理工学院、巴伊兰大学和西蒙弗雷泽大学合作,发布了一篇关于CALMAI模型的技术论文。英伟达表示CALM的全称是条件对抗潜在模型(Conditional Adversarial Latent Models),用于训练定制虚拟角色。英伟达表示,在真实世界训练10天,相当于在模拟世界里训练10年时间。CALMAI模型在训练之后,可以模拟50亿个人体动作,涵盖行走、站立、坐姿、跑步、用剑战斗等人类动作。CALMAI模型的实用价值极大。
7、湖北算力与大数据产业联盟成立
湖北算力与大数据产业联盟于8月11日宣布成立,首批20家联盟成员单位包括中国移动、中国电信、中国联通、华为、科大讯飞、达梦数据库、武汉大学、华中科技大学、华中农业大学、武汉理工大学、武汉人工智能研究院、中国科学院、中国长江三峡集团、湖北数据集团、长江计算、湖北科投、武汉云、芯动科技、利川振业等,目标是形成上下游、大中小、产学研用深度融合的数字化协同发展生态,为湖北省算力与大数据产业规模实现“一年夯基、两年成势、三年跃升”的目标提供强力支撑。
8、阿里字节等向英伟达订50亿美元芯片
最近,中国互联网巨头们向英伟达下单订购50亿美元的芯片。百度、字节跳动、腾讯、阿里巴巴已下单10亿美元,采购约10万张英伟达A800 GPU,将于今年交付。两位接近英伟达的人士称,这些中国科技巨头还采购了40亿美元的GPU,将于2024年交付。之前有报道表示,字节跳动已储备了至少10000张英伟达GPU。字节还订购了近70000张A800芯片,将于明年交付,价值约7亿美元。据两位接近阿里巴巴的人士透露,阿里云从英伟达收到了数千块H800芯片。
9、大模型基准测试工具AgentBench发布
8月7日,来自清华大学、俄亥俄州立大学、加州大学伯克利分校的研究人员们在预印本平台arXiv发表一篇新论文,介绍了一个面向大型语言模型的多维基准测试工具AgentBench。AgentBench由8个不同的任务组成,可评估大语言模型在多轮开放式生成环境中的推理和决策能力。研究团队对25个大型语言模型的广泛测试表明,顶级商业大型语言模型在复杂环境中表现出强大的代理能力,但它们与开源竞争对手之间的性能存在显著差异。
10、IBM计划在watsonx平台上提供LLAMA 2模型
8月9日,IBM宣布计划在watsonx.ai工作室中托管Meta的Llama 2-chat 700亿参数模型,现可供部分客户及合作伙伴提前访问。这将建立在IBM与Meta在AI开放创新方面的合作基础上,包括与Meta开发的开源项目合作,例如PyTorch机器学习框架和watsonx.data中使用的Presto查询引擎。
目前通过watsonx.ai,AI构建者既可使用IBM的模型,也可使用Hugging Face社区的模型,这些模型经过预训练,来支持一系列自然语言处理(NLP)的任务,包括问答、内容生成和摘要、文本分类和提取。预计随后还将发布其AI调优平台,watsonx.ai 模型的fact sheets,以及新增的AI模型。
11、Stability AI推出生成式AI编程产品StableCode
8月8日,Stability AI宣布推出其首个用于编码的大型语言模型生成式AI产品StableCode。该产品旨在帮助程序员进行日常工作,同时也为准备将技能提升的新开发人员提供了一个很好的学习工具。StableCode通过使用三种不同的模型来帮助开发人员编程,提高效率,分别是基础模型、用于解决复杂编程任务的指令模型、为用户提供单行和多行自动补全建议的长上下文窗口模型。

12、英伟达推出下一代GH200 Grace Hopper超级芯片
2023 年 8 月 8 日,NVIDIA 发布新一代 NVIDIA GH200 Grace Hopper 平台,该平台基于全球首款搭载 HBM3e 处理器的 Grace Hopper 超级芯片,专为加速计算和生成式 AI 时代而构建。新平台专为处理大语言模型、推荐系统、矢量数据库等全球最复杂的生成式 AI 工作负载而构建,将提供多种配置选择。
GH200由72核Grace CPU和4PFLOPS Hopper GPU组成,在全球最快内存HBM3e的“助攻”下,内存容量高达141GB,提供每秒5TB的带宽。其每个GPU的容量达到NVIDIA H100 GPU的1.7倍,带宽达到H100的1.55倍。与当前一代产品相比,新的双GH200系统共有144个Grace CPU核心、8PFLOPS计算性能的GPU、282GB HBM3e内存,内存容量达3.5倍,带宽达3倍。如果将连接到CPU的LPDDR内存包括在内,那么总共集成了1.2TB超快内存。
13、清华大学沈阳教授团队发布《大语言模型综合性能评估报告》
清华大学沈阳教授团队于8月7日发布了《大语言模型综合性能评估报告》。其中对文心一言(v2.2.0)、讯飞星火(v1.5)、通义千问(v1.0.3)、昆仑天工(v3.5)、GPT-4、ChatGPT 3.5、Claude(v1.3)七款大模型进行了测评。评估截止时间为2023年6月30日。
LLM领域发展迅猛,故时效性很重要,而写报告花了一个多月?难以理解。从报告的内容来看,评测范围窄,内容一般,像是研究生们的实习练手之作。因此报告也就可以一读,价值不大。比如对比Claude v1.3实在是选错了对象,Claude 2的性能才是业界关注的重点。