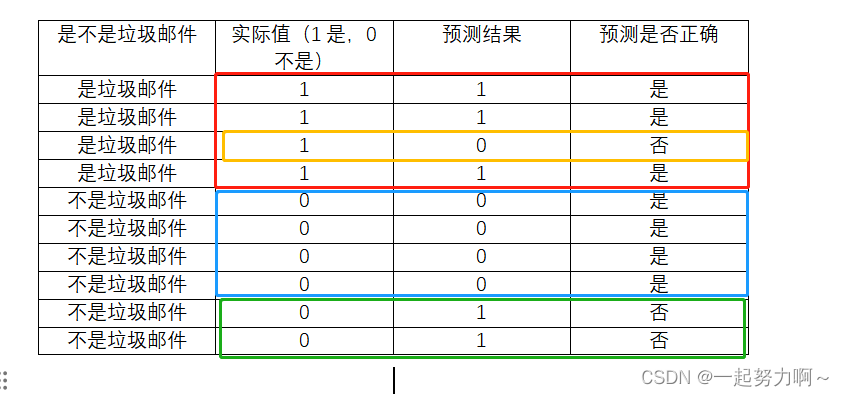
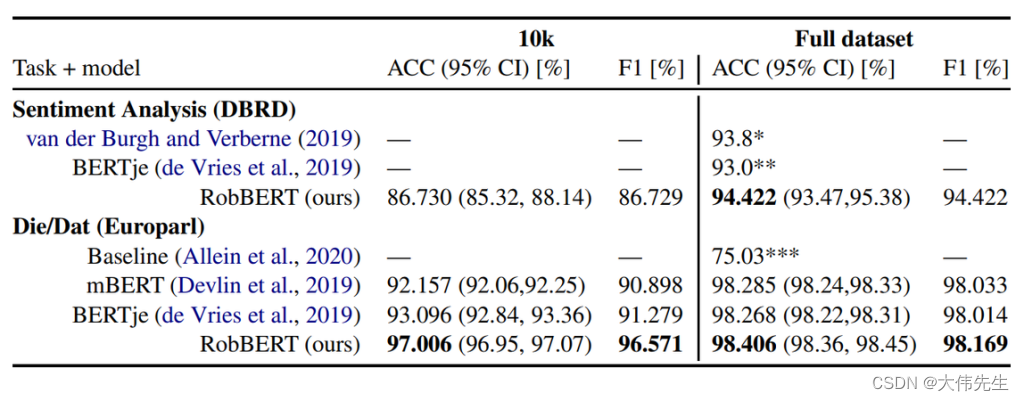
混淆矩阵(Confusion Matrix)

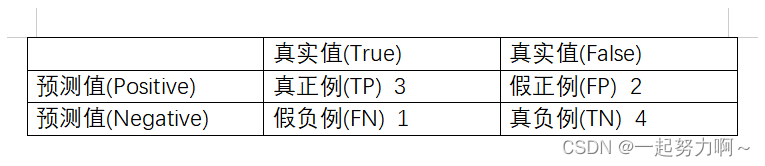
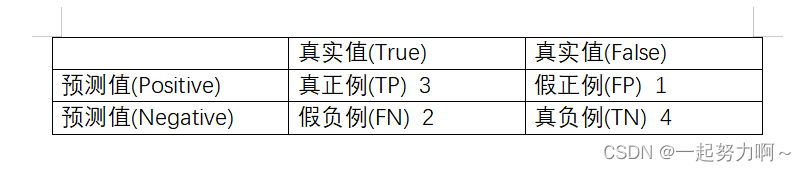
TP(True Positives):真正例,预测为正例而且实际上也是正例;
FP(False Positives):假正例,预测为正例然而实际上却是负例;
FN(false Negatives):假负例,预测为负例然而实际上却是正例;
TN(True Negatives):真负例,预测为负例而且实际上也是负例。
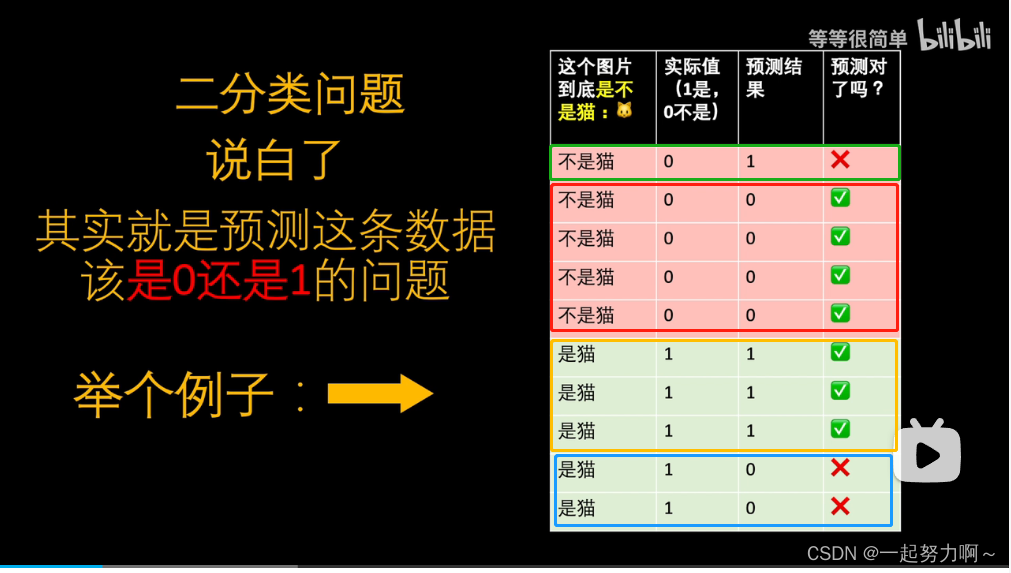
如上图所示:
- 绿色框中 实际上不是猫但预测结果是猫,这属于把负预测成正 为FP;1
- 红色框中 实际上不是猫且预测结果也不是猫,这属于把负预测成负 为TN;4
- 黄色框中 实际上是猫且预测结果也是猫,这属于把正预测成正 为TP;3
- 蓝色框中 实际上是猫但预测结果不是猫,这属于把正预测成负 为FN;2
准确率(accuracy):
所有预测正确的样本(包含正例或负例均预测正确,即正例预测为正TP或负例预测为负TN)占总样本的比例。
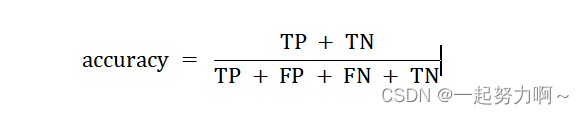
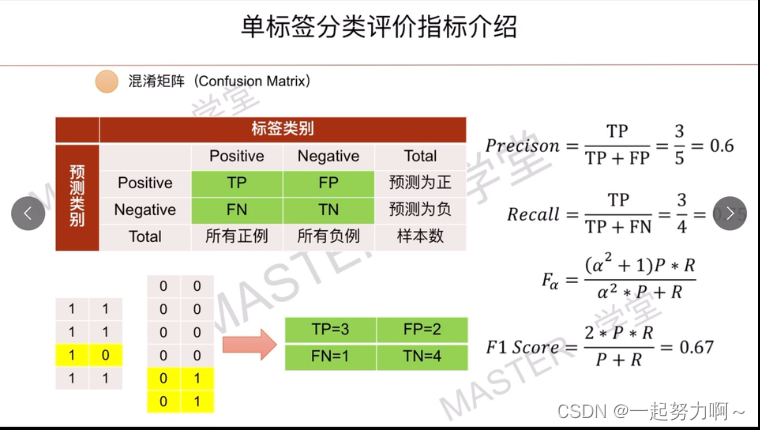
由图例上可知总样本(10个)中预测正确的有七个,准确率为7/10=70%。
虽然准确率能够判断总的正确率,但是在样本不均衡的情况下,并不能作为很好的指标来衡量结果。在样本不平衡的情况下,得到的高准确率没有任何意义,此时准确率就会失效。
精确率(也叫查准率,precision)
预测为正的正例样本与全部预测为正例的样本 (对于预测而言,包括真正例TP,假正例FP)的比值。即正确预测为正的占全部预测为正的比例,(真正正确的占所有预测为正的比例)
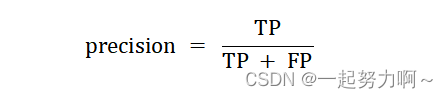
由上图例可知预测为正的样本中(4个)实际为正的由3个,精确率为3/4 = 75%。
我们关心的主要部分是正例,所以查准率就是相对正例的预测结果而言,正例预测的准确度。直白的意思就是模型预测为正例的样本中,其中真正的正例占预测为正例样本的比例,用此标准来评估预测正例的准确度。精确率代表对正样本结果中的预测准确程度,准确率则代表整体的预测准确程度,包括正样本和负样本。
即Precision是针对预测结果而言的。预测结果中,预测为正的样本中预测正确的概率。**类似于一个考生在考卷上写出来的答案中,正确了多少。**体现模型的精准度,模型说:我说哪个对哪个就是对的。
召回率(也叫查全率,recall)
预测为正的正例占全部实际为正例的样本 (可能将实际正例预测为正例即真正例TP,也可能实际正例预测为负例即假负例FN)的比例(真正正确的占所有实际为正的比例)
以实际样本为判断依据,实际为正例的样本中,被预测正确的正例占总实际正例样本的比例。

由上图例知实际为正的样本(5个)中预测为正的正样本为3个,召回率:3/5 = 60%。
Recall是针对数据样本而言的。数据样本中,正样本中预测正确的概率。**类似于一个考生在考卷上回答了多少题。**体现一个模型的全面性,模型说:所有对的我都能找出来。
F1-score
F-score 是一种用于评估二分类模型性能的指标,分别从两个角度,结合了模型的精确度(Precision)和召回率(Recall),主观(Predicted)和客观(Actual)上去综合的分析TP够不够大,帮助我们综合考虑模型的预测准确性和对正样本的捕捉能力。
- FP/TP影响的是主观判断上TP够不够分量,也就是主观上TP这个值到底够不够大
- FN/TP影响的是客观判断上TP够不够分量,也就是客观上TP这个值到底够不够大
精确率和召回率互相影响,理想状态下肯定追求两个都高,但是实际情况是两者相互“制约”:
追求精确率高,则召回率就低;追求召回率高,则通常会影响精确率。
我们当然希望预测的结果精确率越高越好,召回率越高越好, 但事实上这两者在某些情况下是矛盾的。
这样就需要综合考虑它们,最常见的方法就是F-score。 也可以绘制出P-R曲线图,观察它们的分布情况。
F1值为算数平均数除以几何平均数,且越大越好,将Precision和Recall的上述公式带入会发现,
当F1值小时,True Positive相对增加,而false相对减少,
即Precision和Recall都相对增加,即F1对Precision和Recall都进行了加权。
可以思考F1什么时候趋近于1,什么时候趋近于0?
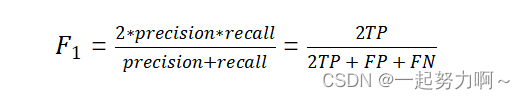
由上图例可知F1= (23) / (23 + 1 + 2) = 66.6%。
F1的核心思想在于,在尽可能的提高Precision和Recall的同时,也希望两者之间的差异尽可能小。F1-score适用于二分类问题,对于多分类问题,将二分类的F1-score推广,有Micro-F1和Macro-F1两种度量。
结论: F-score的值 只有在Precision 和 Recall 都大的时候 才会大。
更一般的
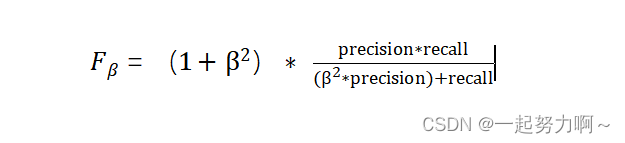 除了F1分数之外,F0.5分数和F2分数,在统计学中也得到了大量应用,其中,F2分数中,召回率的权重高于精确率,而F0.5分数中,精确率的权重高于召回率。
除了F1分数之外,F0.5分数和F2分数,在统计学中也得到了大量应用,其中,F2分数中,召回率的权重高于精确率,而F0.5分数中,精确率的权重高于召回率。
Macro-F1和Micro-F1
- Macro-F1和Micro-F1是相对于多标签分类而言的。
- Micro-F1,计算出所有类别总的Precision和Recall,然后计算F1。
- Macro-F1,计算出每一个类的Precison和Recall后计算F1,最后将F1平均。
思考题:
下图中TN、FN、TP、FP、准确率、精确率、召回率、F1-score分别为多少?
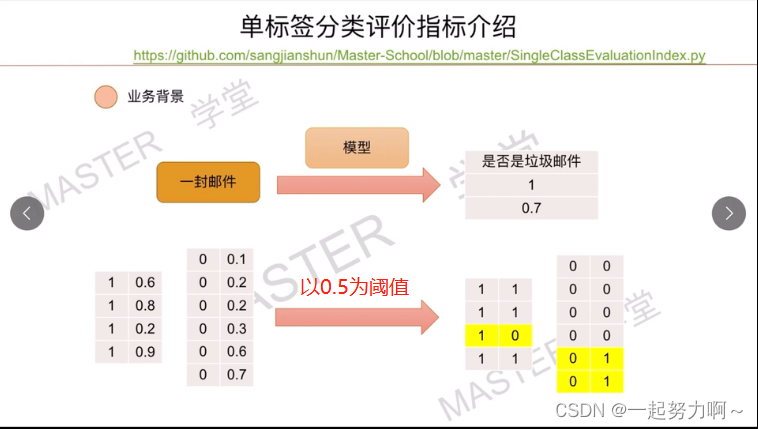
参考1
参考2混淆矩阵五分钟入门
参考3
答案:
- F-score = 0 (实际上是无限趋近于0)
主观上TP很小 OR 客观上TP很小
即 FP 或 FN 远大于TP,这里做极限假设我们可以知道F-score趋近于0 - F-score = 1
主观上和客观上来说TP都很大,也就是FP和FN都等于0(下限)。