CAS
概述
CAS全称为Compare-And-Swap。它是一条CPU的原子指令,是硬件对于并发操作共享数据的支持。其作用是CPU在某个时刻比较两个值是否相等
核心原理:在操作期间CAS先比较下主存中的值和线程中工作内存中的值是否相等,如果相等才会将主存中的值更新为新值,不相等则不交换(如果不相等则会一直通过自旋方式尝试更新值)
CAS指令存在如下问题:
- ABA问题:两个时刻比较值都会存在ABA问题,原来是A,中间变成B,又变回A,CAS检测认为值没有发生变化,但实际上确实发生变化了。
- 解决方案:JDK1.5中的AtomicStampedReference可以用来解决ABA问题。基本思路是增加版本号,修改的当前值和逾期值是否一致。AtomicStampedReference是通过当前引用和逾期的引用是否相等,来进行CAS操作。
-
循环时间长开销大:如果CAS失败,则会一直通过自旋进行尝试。如果CAS长时间一直不成功,可能会给CPU带来很大的开销。因此冲突如果过于频繁的场景不建议使用
CAS原语进行处理(CAS是乐观锁机制,乐观锁不适合冲突频繁的场景,这时候可以选择悲观锁的机制)。
CAS算法示例
package com.bierce;
public class TestCAS {
public static void main(String[] args) {
final CAS cas = new CAS();
for (int i = 0; i < 10; i++) {
new Thread(() -> {
int expectedValue = cas.getValue();//每次更新前必须获取内存中最新的值,因为可能与compareAndSwap中第一次获取的Vaule不一样
boolean updateRes = cas.compareAndSet(expectedValue, (int) Math.random() * 101);
System.out.print(updateRes + " "); // true true true true true true true true true true
}).start();
}
}
}
class CAS{
private int value;
//获取内存值
public synchronized int getValue(){
return value;
}
//比较内存值
public synchronized int compareAndSwap(int expectedValue, int newValue){
int oldValue = value;//
if (oldValue == expectedValue){
this.value = newValue;
}
return oldValue;
}
//设置内存值
public synchronized boolean compareAndSet(int expectedValue, int newValue){
return expectedValue == compareAndSwap(expectedValue, newValue);
}
}
原子类
概述
在多线程环境下我们可以通过加锁(synchronized/Lock)保证数据操作的一致性,但效率显得过于笨重。因此java提供java.util.concurrent.atomic包,里面是原子操作的封装类,使用起来方便且高性能高效。Atomic 类方法没有任何加锁,底层核心就是通过 volatile 保证了线程可见性以及Unsafe类的CAS算法操作保证数据操作的原子性
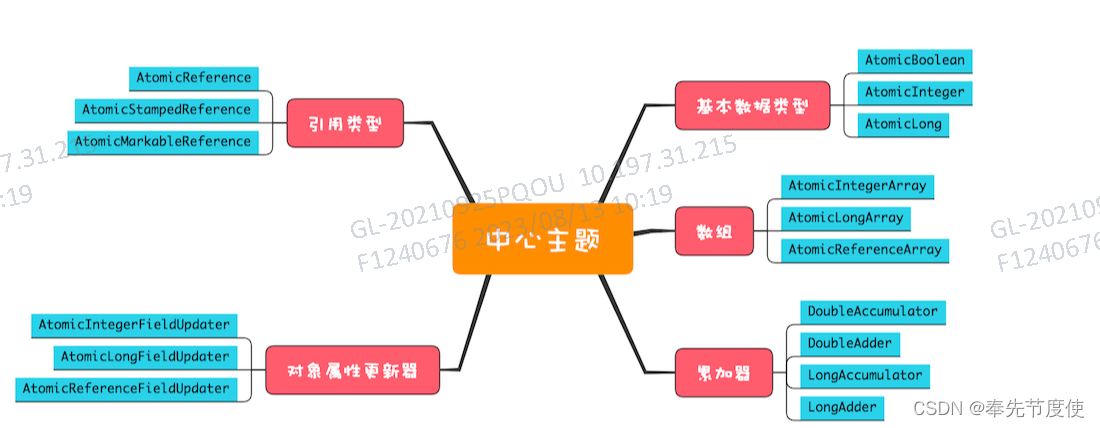
分类
AtomicInteger实践
package com.bierce;
import java.util.concurrent.atomic.AtomicInteger;
public class TestAtomicDemo {
public static void main(String[] args) {
AtomicDemo atomicDemo = new AtomicDemo();
//模拟多线程,通过原子类保证变量的原子性
for(int i =0; i < 10; i++){
new Thread(atomicDemo).start();
}
}
}
class AtomicDemo implements Runnable{
//AtomicInteger原子类提供很多API,根据需求使用
private AtomicInteger sn = new AtomicInteger();
@Override
public void run() {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
//getAndIncrement() :类似于 i++
//incrementAndGet() :类似于 ++i
//System.out.print(sn.getAndIncrement() + " "); // 输出:1 9 8 7 0 5 2 6 4 3
System.out.print(sn.incrementAndGet() + " "); // 输出:1 10 9 5 2 8 3 6 7 4
}
}同步容器类
- ConcurrentHashMap: 同步的HashMap的并发实现
- ConcurrentSkipListMap: 同步的TreeMap的并发实现
- CopyOnWriteArrayList:适合于并发读取或者遍历集合数据需求远大于列表更新需求时
- ThreadLocal: 利用空间换时间思想,为每个线程复制一个副本,通过隔离线程实现线程安全
- BlockingQueue
- ConcurrentLinkedQueue: 通过CAS保证线程安全,采用延时更新策略,提高吞吐量
ConcurrentHashMap
ConcurrentHashMap内部采用了“锁分段”思想替代HashTable的独占锁,增加了同步的操作来控制并发,且提高了性能,但JDK1.7&&JDK1.8版本中底层实现有所区别
- JDK1.7版本: 底层为ReentrantLock+Segment+HashEntry,JDK1.8版本: 底层为synchronized+CAS+HashEntry+红黑树
- JDK1.8中降低了锁的粒度:JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
- JDK1.8中数据结构更加简单:JDK1.8使用synchronized来进行同步,所以不需要Segment这种数据结构
- JDK1.8使用红黑树来优化链表:基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快
- 扩展:为何用synchronized来代替reentrantLock
- 因为粒度降低了,synchronized并不比ReentrantLock差;在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界而更加灵活,而在低粒度中,Condition的优势就没有了
- JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
- 在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存
CopyOnWriteArrayList实践
package com.bierce;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
/**
* CopyOnWriteArrayList : 支持并发读取时写入
* 注意:添加数据操作多时,效率比较低,因为每次添加都会进行复制一个新的列表,开销大;
* 而并发迭代操作多时效率高
*/
public class TestCopyOnWriteArrayList {
public static void main(String[] args) throws InterruptedException {
CopyOnWriteArrayListDemo copyOnWriteArrayListDemo = new CopyOnWriteArrayListDemo();
for (int i = 0; i < 10; i++) {
new Thread(copyOnWriteArrayListDemo).start();
}
}
}
class CopyOnWriteArrayListDemo implements Runnable{
// 不支持并发修改场景,Exception in thread "Thread-1" java.util.ConcurrentModificationException
//private static List<String> list = Collections.synchronizedList(new ArrayList<String>());
public static CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
static{
list.add("贾宝玉");
list.add("林黛玉");
list.add("薛宝钗");
}
@Override
public void run() {
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
list.add("test");
}
}
}同步工具类
- 倒计时器CountDownLatch
- 循环栅栏CyclicBarrier
- 资源访问控制Semaphore
CountDownLatch(闭锁)
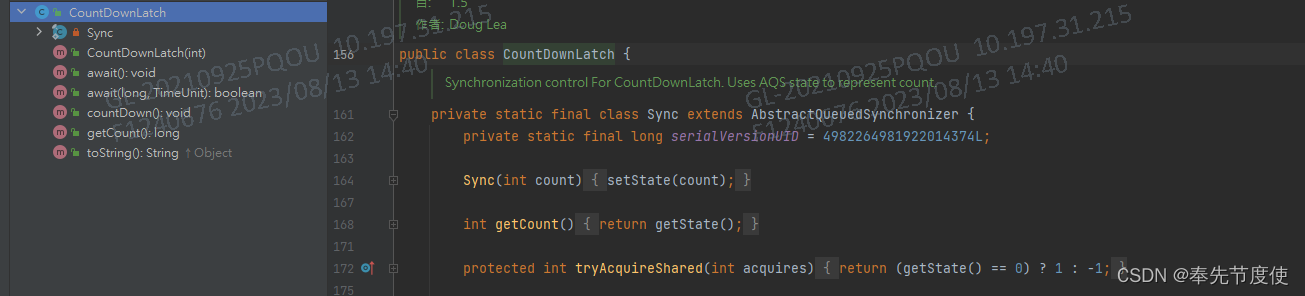
概述
- CountDownLatch是一个同步工具类,用来协调多个线程之间的同步,用来实现线程间的通信
- CountDownLatch适用于一个线程在等待另外一些线程完成各自工作之后,再继续执行的场景
原理
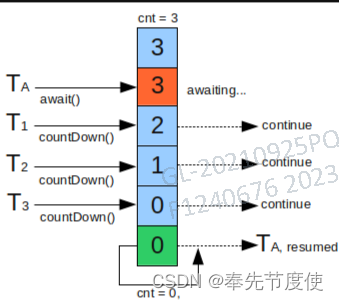
CountDownLatch底层是通过一个计数器来实现的,计数器的初始化值为线程的数量。每当一个线程完成了自己的任务后,计数器的值就相应的减1。当计数器到达0时,表示所有的线程都已完成任务,然后在闭锁上等待的线程就可以继续执行任务
实践
package com.bierce;
import java.time.Duration;
import java.time.Instant;
import java.util.concurrent.CountDownLatch;
public class TestCountDownLatchDemo {
public static void main(String[] args) {
final CountDownLatch countDownLatch = new CountDownLatch(5);//声明5个线程
CountDownLatchDemo countDownLatchDemo = new CountDownLatchDemo(countDownLatch);
//long start = System.currentTimeMillis();
Instant start = Instant.now();//JDK8新特性API
for (int i = 0; i < 5; i++) { //此处循环次数必须和countDownLatch创建的线程个数一致
new Thread(countDownLatchDemo).start();
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
}
//long end = System.currentTimeMillis();
Instant end = Instant.now();
//System.out.println("执行完成耗费时长: " + (end - start));
System.out.println("执行完成耗费时长: " + Duration.between(end, start).toMillis()); // 110ms
}
}
class CountDownLatchDemo implements Runnable{
private CountDownLatch countDownLatch;
public CountDownLatchDemo(CountDownLatch countDownLatch) {
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
synchronized (this){ //加锁保证并发安全
try {
for (int i = 0; i < 10000; i++) {
if (i % 2 == 0) {
System.out.println(i);
}
}
}finally {
countDownLatch.countDown(); //线程完成后执行减一
}
}
}
}






![[C语言] 指针](https://img-blog.csdnimg.cn/7ddf4693bdd240649bd29576419ad7bf.png)






![当执行MOV [0001H] 01H指令时,CPU都做了什么?](https://img-blog.csdnimg.cn/8fba2176cb0b4130a5fb01c77bf402f2.png)