kafka 02——三个重要的kafka客户端
- 1. 前言
- 1.1 关于 Kafka 的安装
- 1.2 常用客户端简介
- 1.3 依赖
- 2. AdminClient
- 2.1 Admin Configs
- 2.2 AdminClient API
- 2.2.1 设置 AdminClient 对象
- 2.2.2 创建 topic + 获取 topic 列表
- 2.2.3 删除topic
- 2.2.4 查看 topic 的描述信息
- 2.2.5 查看 topic 的配置信息
- 2.2.6 修改 topic 的配置信息
- 2.2.7 新增 Partition
- 2.2.7.1 相关概念
- 2.2.7.2 演示
- 2.3 附代码
- 3. 生产者(Producer API)
- 3.1 Producer Configs
- 3.1.1 参考官网
- 3.1.2 关于acks 的配置(消息传递保障)
- 3.2 Producer API
- 3.2.1 异步发送
- 3.2.2 异步阻塞发送(同步发送)
- 3.2.3 异步发送并回调
- 3.2.4 总结 ( 异步阻塞发送 与 异步发送)
- 3.2.3.1 异步阻塞发送
- 3.2.3.2 异步发送
- 3.2.3.3 参考
- 3.3 Producer 自定义Partition分区规则(负载均衡)
- 3.3.1 把 Partition 增加到3
- 3.3.2 核心代码
- 3.3.3 效果
- 4. 消费者
- 4.1 Consumer Configs
- 4.2 消费者消费例子
- 4.2.1 官网参考
- 4.2.2 简单入门例子——自动偏移提交
- 4.2.2 手动偏移控制
- 4.2.3.1 解释
- 4.2.3.2 代码
- 4.2.3 每个 partition 单独处理
- 4.2.3.1 解释
- 4.2.3.2 代码
- 4.2.3.3 注意
- 4.2.4 手动控制消费哪个partition(手动分区分配)
- 4.2.4.1 描述
- 4.2.4.2 代码
- 4.2.4.3 效果
- 4.2.5 消费者多线程处理
- 4.2.5.1 消费者线程不安全
- 4.2.5.2 两种方式实现
- 4.2.5.2.1 每个线程一个消费者
- 4.2.5.2.1 将消费和处理分离
- 4.2.5.3 典型的模式(每个线程一个消费者)
- 4.2.5.4 将消费和处理分离(线程池处理)
- 4.2.6
- 4.3
1. 前言
1.1 关于 Kafka 的安装
- 请参考下面的文章:
Kafka 01——Kafka的安装及简单入门使用.
1.2 常用客户端简介
- AdminClient API:
允许管理和检测Topic、Broker以及其他Kafka对象。 - Producer API:
发布消息到一个或多个API。 - Consumer API:
订阅一个或多个Topic,并处理产生的消息。
1.3 依赖
-
如下:

<!--kafka客户端--> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.8.2</version> </dependency> -
完整的pom
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.7.6</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.liu.susu</groupId> <artifactId>kafka-api</artifactId> <version>0.0.1-SNAPSHOT</version> <name>kafka-api</name> <description>kafka-api</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.2.11</version> </dependency> <!--kafka客户端--> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.8.2</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
2. AdminClient
2.1 Admin Configs
- 关于配置,可参考官网:
https://kafka.apache.org/documentation/#adminclientconfigs.
2.2 AdminClient API
2.2.1 设置 AdminClient 对象
-
详细配置请参考官网,简单配置使用,如下:
package com.liu.susu.admin; import org.apache.kafka.clients.admin.AdminClient; import org.apache.kafka.clients.admin.AdminClientConfig; import java.util.Arrays; import java.util.List; import java.util.Properties; /** * @Description * @Author susu */ public class AdminExample1 { public final static String TOPIC_NAME = ""; /** * 1. 创建并设置 AdminClient 对象 */ public static AdminClient getAdminClient(){ Properties properties = new Properties(); properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "Kafka服务IP:9092"); AdminClient adminClient = AdminClient.create(properties); return adminClient; } public static void main(String[] args) { //1. 测试 创建并设置 AdminClient 对象 AdminClient adminClient = AdminExample1.getAdminClient(); System.out.println("adminClient==>" + adminClient); } }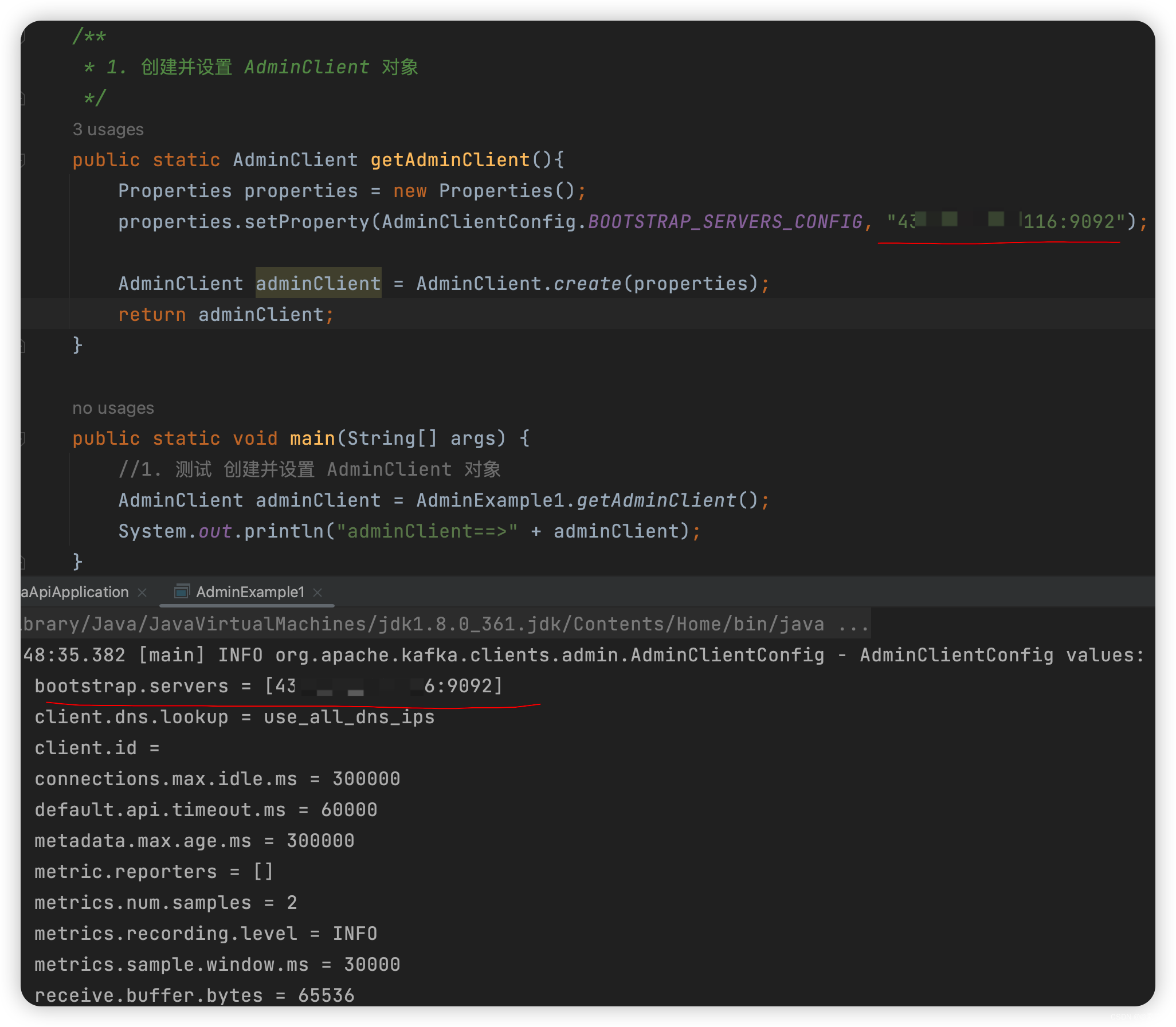
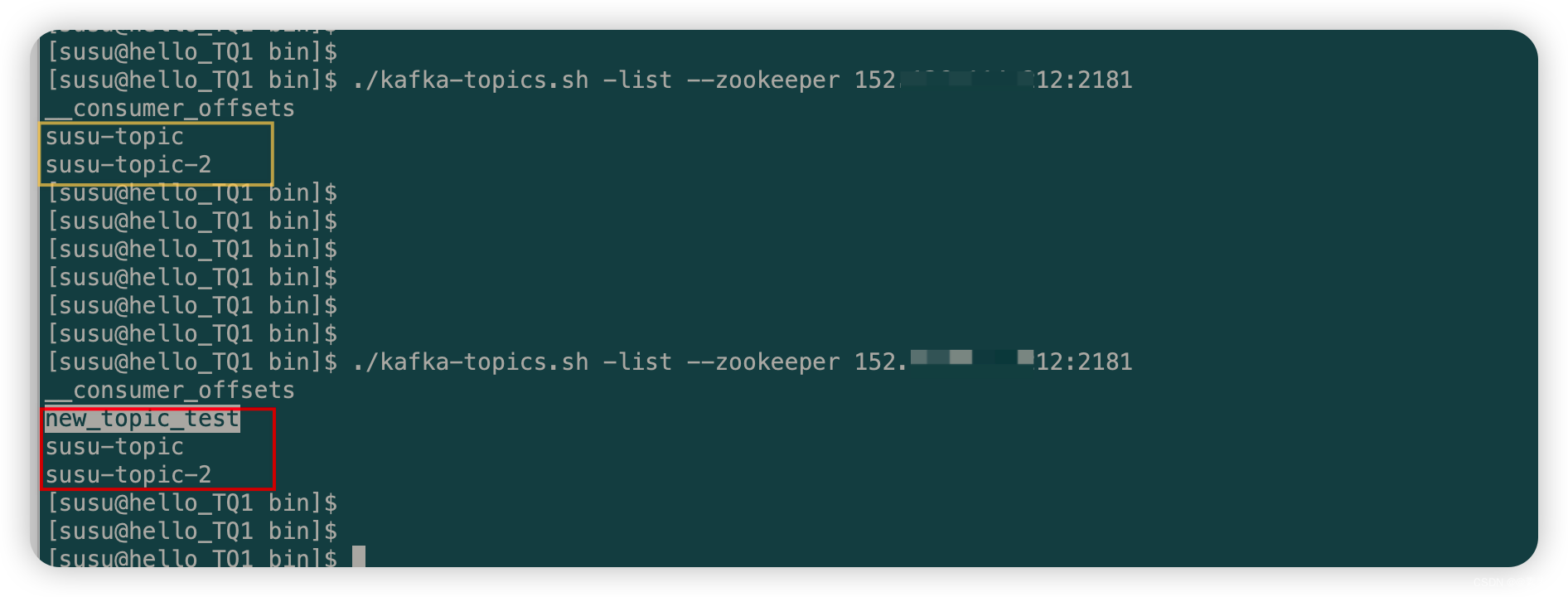
2.2.2 创建 topic + 获取 topic 列表
-
如下:
/** * 2. 创建topic */ public static void createTopic(){ AdminClient adminClient = getAdminClient(); // 副本因子 short rs = 1; NewTopic newTopic = new NewTopic("new_topic_test", 1, rs);//new_topic_test 是 topic的name CreateTopicsResult topics = adminClient.createTopics(Arrays.asList(newTopic)); System.out.println("创建的新topic为::::" + topics); } /** * 3. 获取已经创建的 topic 的列表 */ public static ListTopicsResult getTopicList(){ AdminClient adminClient = getAdminClient(); ListTopicsResult topicList = adminClient.listTopics(); return topicList; } -
测试如下:
public static void main(String[] args) throws ExecutionException, InterruptedException { //1. 测试 创建并设置 AdminClient 对象 // AdminClient adminClient = AdminExample1.getAdminClient(); // System.out.println("adminClient==>" + adminClient); //2. 测试 创建topic createTopic(); //3. 获取已经创建的 topic 的列表 ListTopicsResult topicList = getTopicList(); Collection<TopicListing> topicListings = topicList.listings().get(); for (TopicListing topic : topicListings) { System.out.println(topic); } }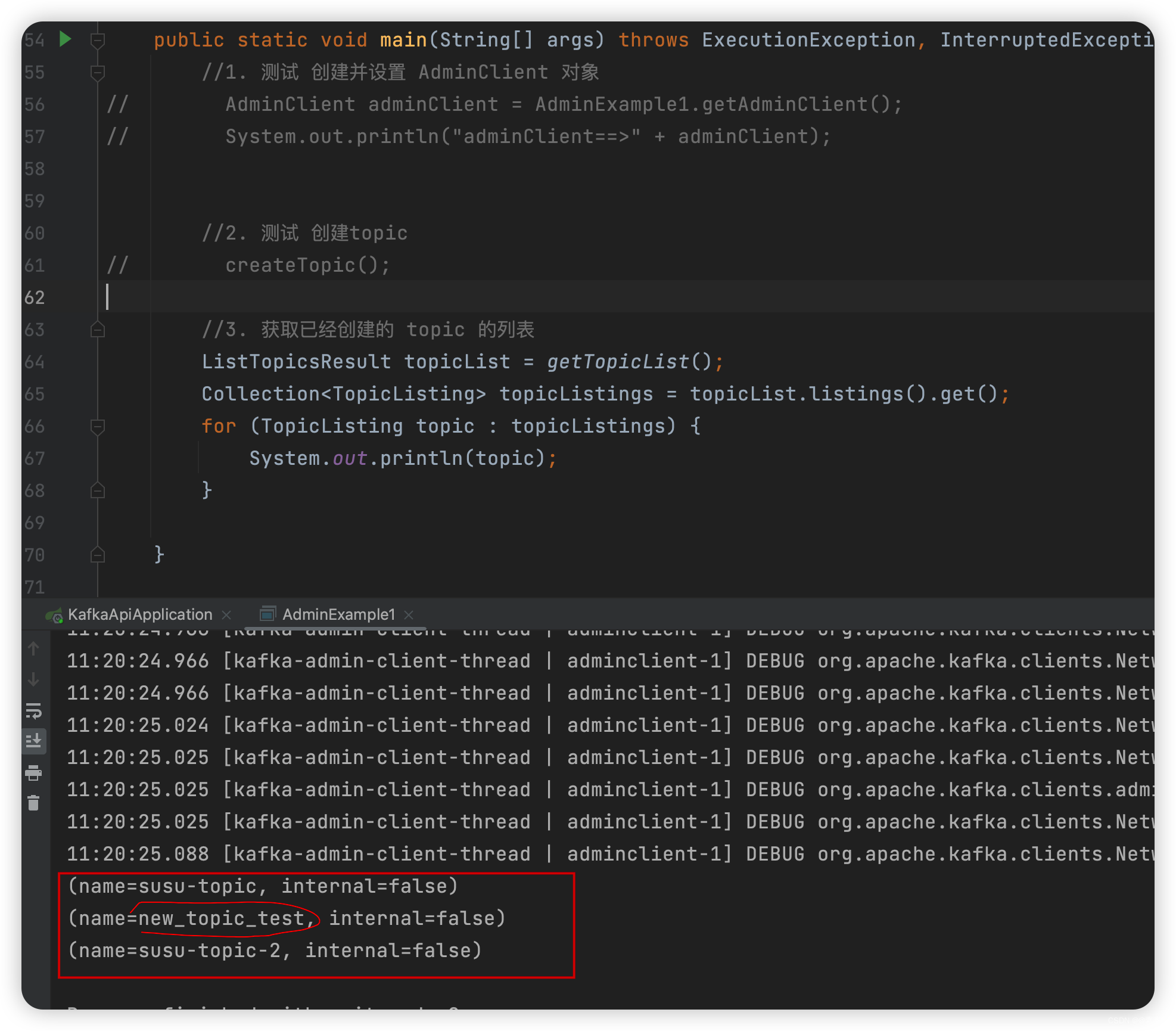
2.2.3 删除topic
- 如下:
/** * 4. 删除 topic */ public static void deleteTopic(String topicName) throws ExecutionException, InterruptedException { AdminClient adminClient = getAdminClient(); DeleteTopicsResult deleteTopicsResult = adminClient.deleteTopics(Arrays.asList(topicName)); deleteTopicsResult.all().get(); }
2.2.4 查看 topic 的描述信息
-
如下:
/** * 5. 获取描述 topic 的信息 */ public static void getDescribeTopics(String topicName) throws ExecutionException, InterruptedException { AdminClient adminClient = getAdminClient(); DescribeTopicsResult result = adminClient.describeTopics(Arrays.asList(topicName)); Map<String, TopicDescription> descriptionMap = result.all().get(); descriptionMap.forEach((k,v)->{ System.out.println("k==>"+k +",v===>"+v); }); }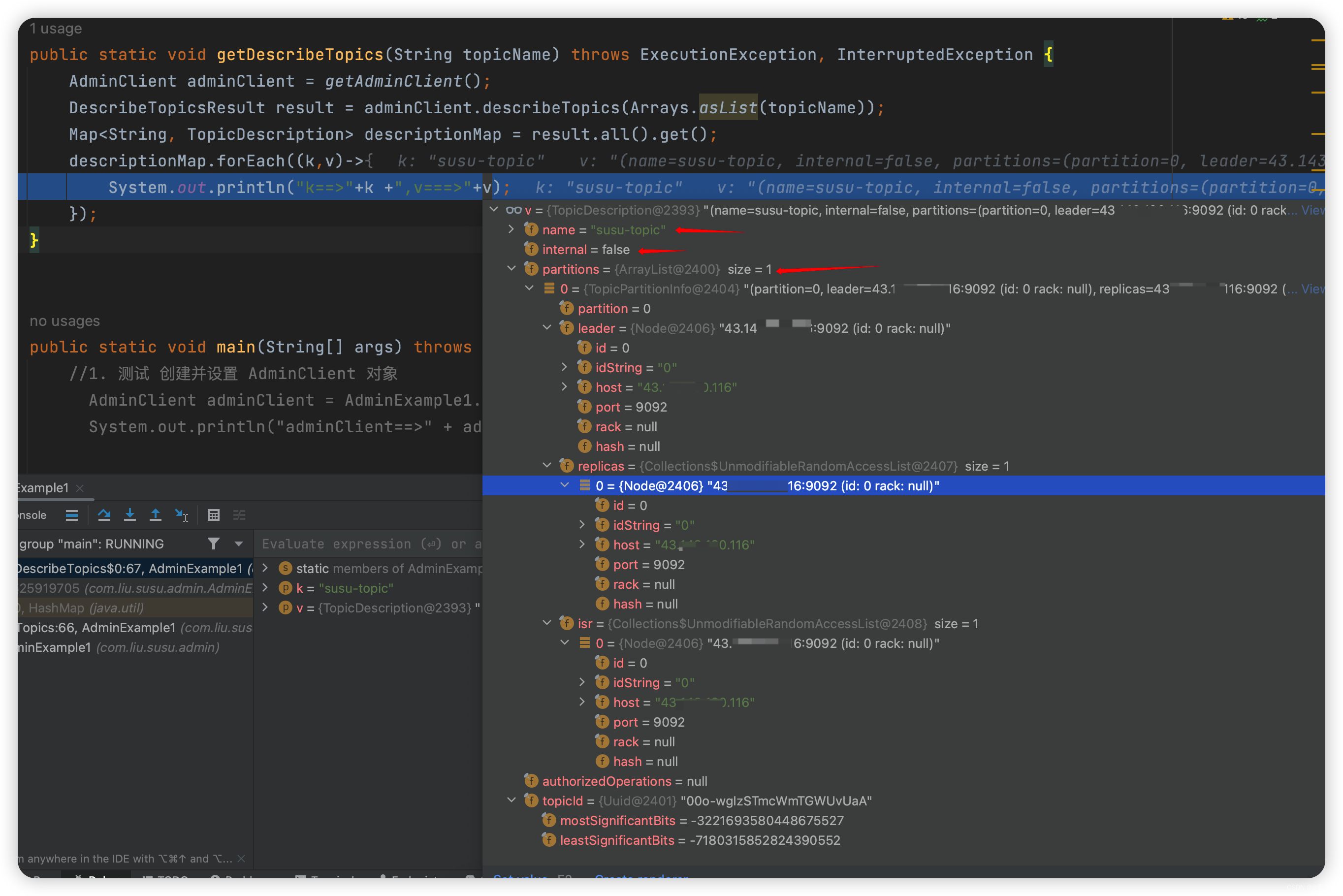
k==>susu-topic,v===>(name=susu-topic, internal=false, partitions=(partition=0, leader=IP:9092 (id: 0 rack: null), replicas=IP:9092 (id: 0 rack: null), isr=IP:9092 (id: 0 rack: null)), authorizedOperations=null)
2.2.5 查看 topic 的配置信息
- 如下:
/** * 6. 获取 topic 的配置信息 */ public static void getDescribeConfig(String topicName) throws ExecutionException, InterruptedException{ AdminClient adminClient = getAdminClient(); ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC,topicName); DescribeConfigsResult configsResult = adminClient.describeConfigs(Arrays.asList(resource)); Map<ConfigResource, Config> configMap = configsResult.all().get(); configMap.forEach((k,v)->{ System.out.println("k==>"+k +",v===>"+v); }); } //查看某一项配置(eg:message.downconversion.enable)的值 Config config = configMap.get(resource); ConfigEntry configEntry = config.get("message.downconversion.enable"); System.out.println("message.downconversion.enable===>" + configEntry.value());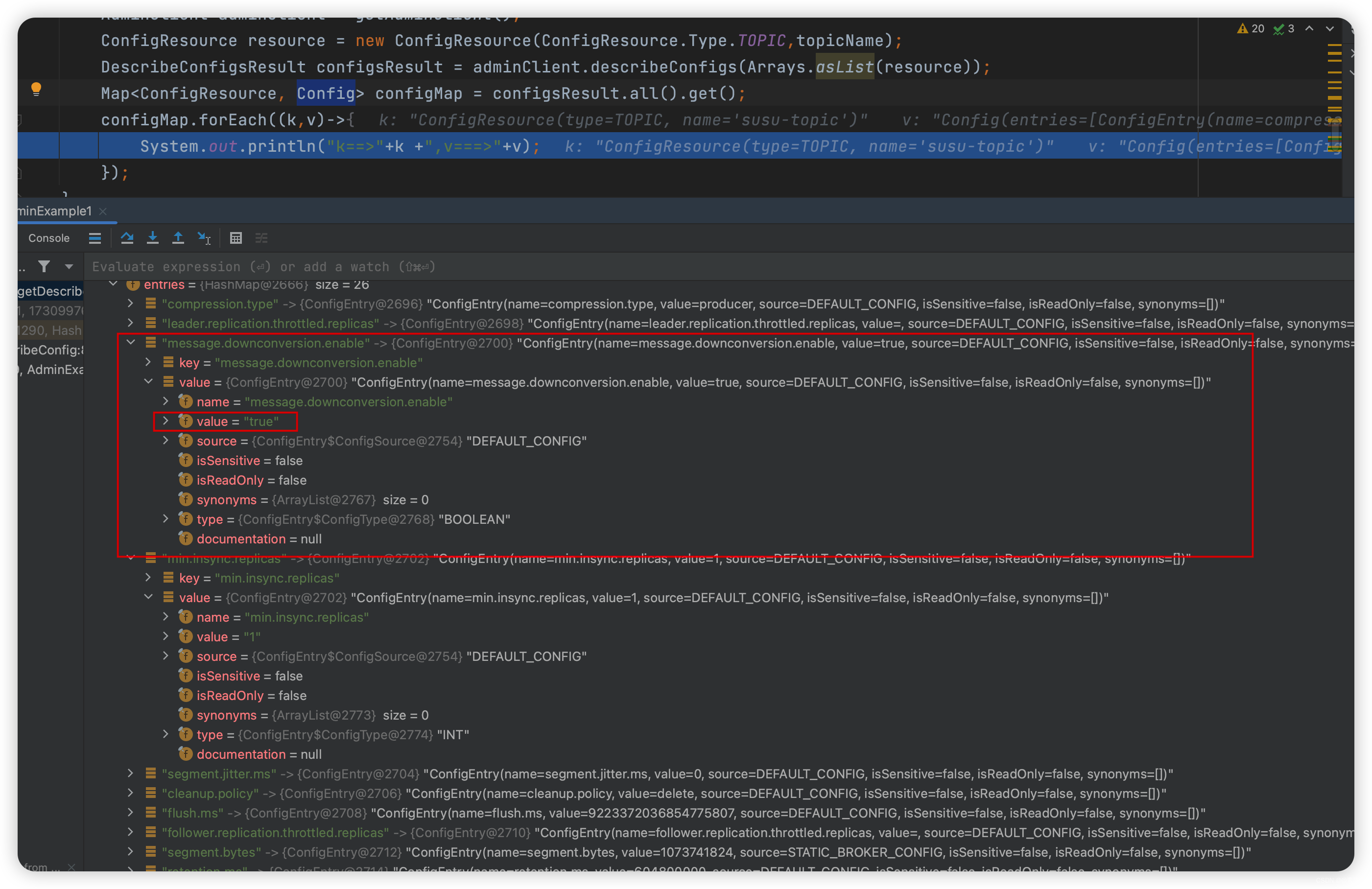
2.2.6 修改 topic 的配置信息
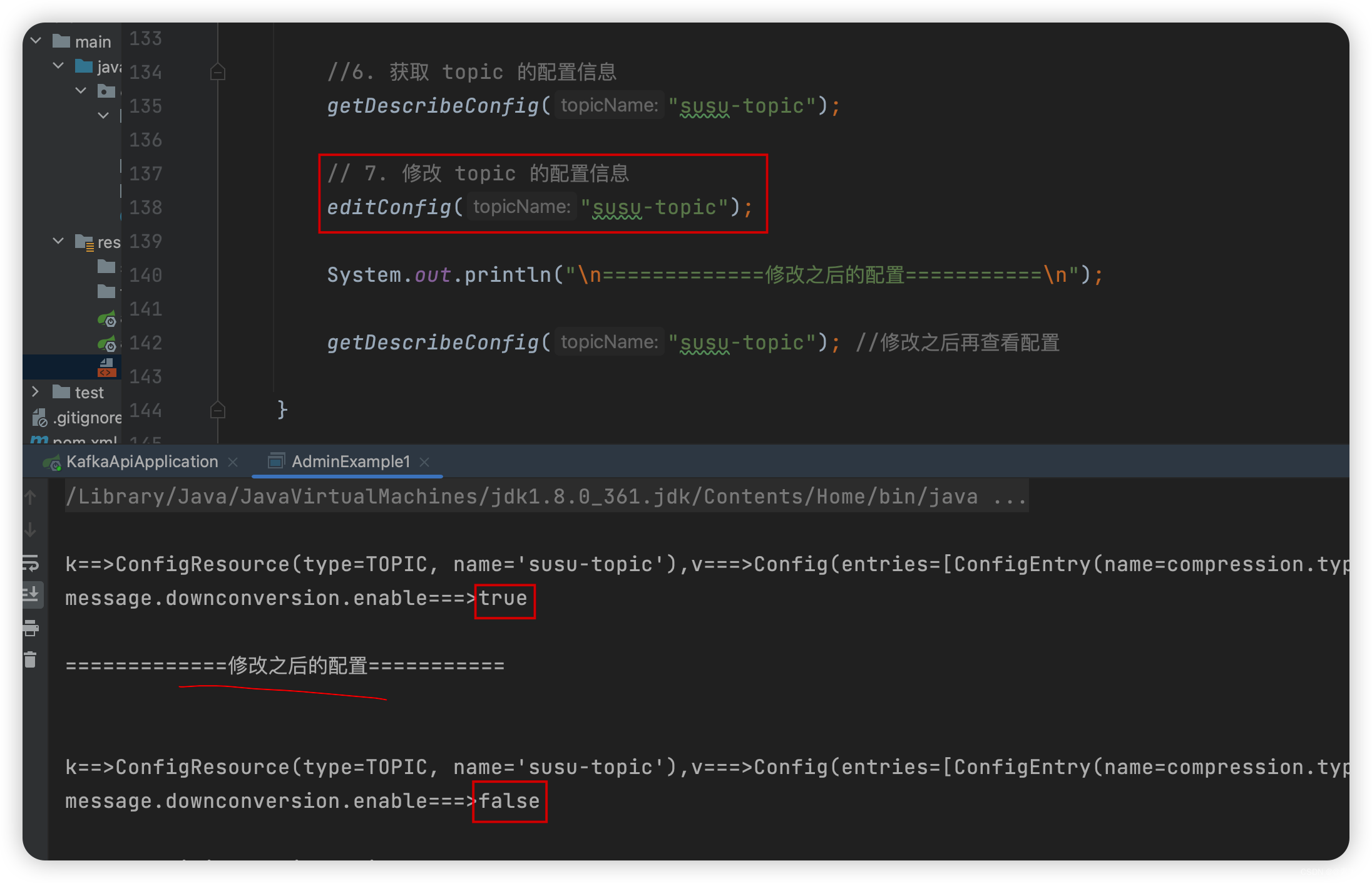
- 如下:
/** * 7. 修改 topic 的配置信息 * 本例修改 message.downconversion.enable,将默认的 true 改为 false */ public static void editConfig(String topicName) throws ExecutionException, InterruptedException { AdminClient adminClient = getAdminClient(); Map<ConfigResource,Config> configMap = new HashMap<>(); ConfigResource configResource = new ConfigResource(ConfigResource.Type.TOPIC,topicName); String keyName = "message.downconversion.enable"; String value = "false"; ConfigEntry configEntry = new ConfigEntry(keyName, value); Config config = new Config(Arrays.asList(configEntry)); configMap.put(configResource,config); AlterConfigsResult alterConfigsResult = adminClient.alterConfigs(configMap); alterConfigsResult.all().get(); } - 效果如下:
2.2.7 新增 Partition
2.2.7.1 相关概念
- Topic:主题,一个虚拟的概念,由1到多个 Partitions 组成,可以理解为一个队列,生产者和消费者都是面向一个Topic。
- Partition:分区,实际消息存储单位。为了实现扩展性,一个非常大的 Topic 可以分布到多个 Broker 上,一个Topic 可以分为多个 Partition,每个 Partition 是一个有序的队列(分区有序,不能保证全局有序)。
- Producer:消息生产者,向 Kafka 中发布消息的角色。
- Consumer:消息消费者,从 Kafka 中拉取消息消费的客户端。
- Broker:经纪人,一台 Kafka 服务器就是一个 Broker,一个集群由多个 Broker 组成,一个 Broker 可以容纳多个 Topic。
2.2.7.2 演示
- 代码如下:
/** * 8. 增加 topic 的Partitions */ public static void addPartitionNum(String topicName, int partitionNum) throws ExecutionException, InterruptedException { AdminClient adminClient = getAdminClient(); Map<String,NewPartitions> partitionsMap = new HashMap<>() ; NewPartitions newPartitions = NewPartitions.increaseTo(partitionNum);//增加到的数量 partitionsMap.put(topicName,newPartitions); CreatePartitionsResult request = adminClient.createPartitions(partitionsMap); request.all().get(); } - 效果如下:
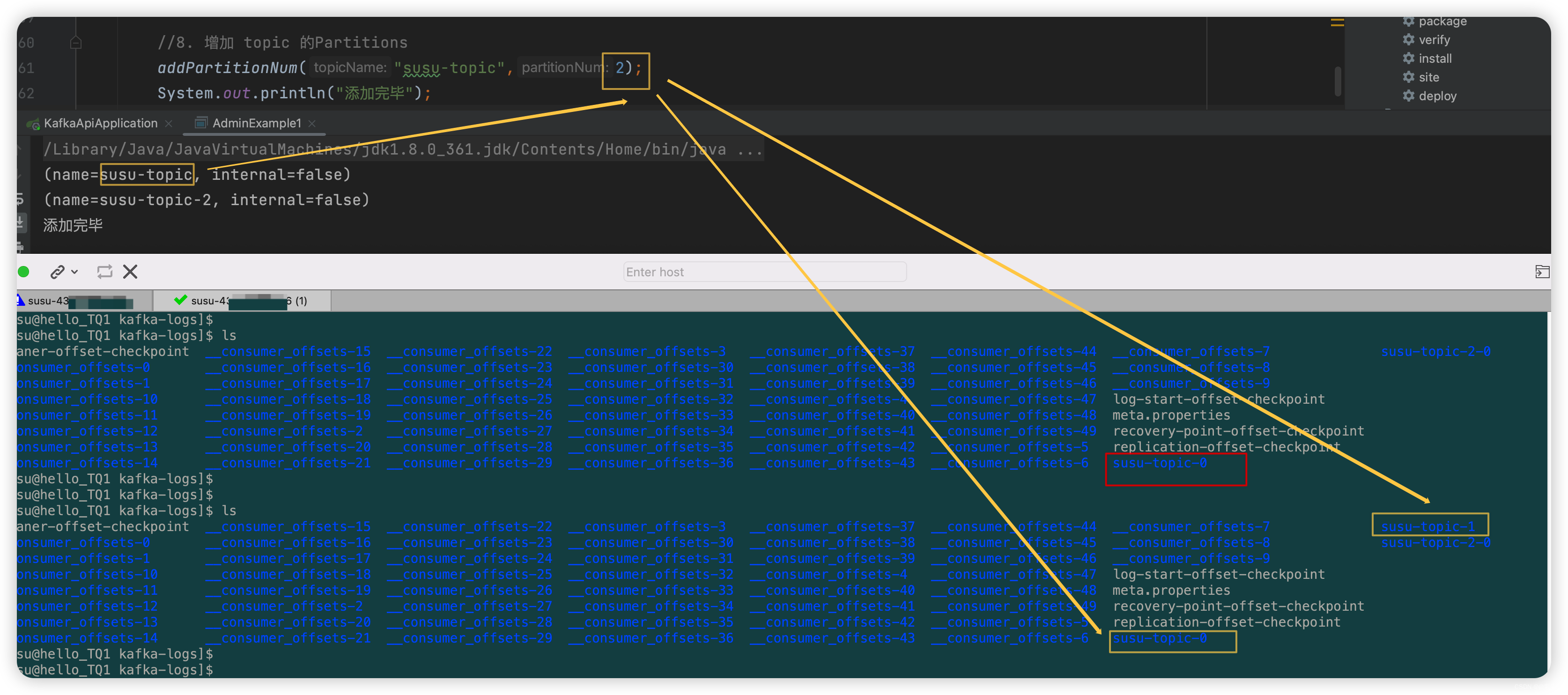
2.3 附代码
- 如下:
package com.liu.susu.admin; import org.apache.kafka.clients.admin.*; import org.apache.kafka.common.KafkaFuture; import org.apache.kafka.common.config.ConfigResource; import org.apache.kafka.common.requests.CreatePartitionsRequest; import java.util.*; import java.util.concurrent.ExecutionException; /** * @Description * @Author susu */ public class AdminExample1 { public final static String TOPIC_NAME = "new_topic_test"; /** * 1. 创建并设置 AdminClient 对象 */ public static AdminClient getAdminClient(){ Properties properties = new Properties(); properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "43.143.190.116:9092"); AdminClient adminClient = AdminClient.create(properties); return adminClient; } /** * 2. 创建topic */ public static void createTopic(){ AdminClient adminClient = getAdminClient(); // 副本因子 short rs = 1; NewTopic newTopic = new NewTopic("new_topic_test", 1, rs); CreateTopicsResult topics = adminClient.createTopics(Arrays.asList(newTopic)); System.out.println("创建的新topic为::::" + topics); } /** * 3. 获取已经创建的 topic 的列表 */ public static ListTopicsResult getTopicList(){ AdminClient adminClient = getAdminClient(); ListTopicsResult topicList = adminClient.listTopics(); return topicList; } /** * 4. 删除 topic */ public static void deleteTopic(String topicName) throws ExecutionException, InterruptedException { AdminClient adminClient = getAdminClient(); DeleteTopicsResult deleteTopicsResult = adminClient.deleteTopics(Arrays.asList(topicName)); deleteTopicsResult.all().get(); } /** * 5. 获取描述 topic 的信息 */ public static void getDescribeTopics(String topicName) throws ExecutionException, InterruptedException { AdminClient adminClient = getAdminClient(); DescribeTopicsResult result = adminClient.describeTopics(Arrays.asList(topicName)); Map<String, TopicDescription> descriptionMap = result.all().get(); descriptionMap.forEach((k,v)->{ System.out.println("k==>"+k +",v===>"+v); }); } /** * 6. 获取 topic 的配置信息 */ public static void getDescribeConfig(String topicName) throws ExecutionException, InterruptedException{ AdminClient adminClient = getAdminClient(); ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC,topicName); DescribeConfigsResult configsResult = adminClient.describeConfigs(Arrays.asList(resource)); Map<ConfigResource, Config> configMap = configsResult.all().get(); configMap.forEach((k,v)->{ System.out.println("\nk==>"+k +",v===>"+v); }); //查看某一项配置(eg:message.downconversion.enable)的值 Config config = configMap.get(resource); ConfigEntry configEntry = config.get("message.downconversion.enable"); System.out.println("message.downconversion.enable===>" + configEntry.value()); } /** * 7. 修改 topic 的配置信息 * 本例修改 message.downconversion.enable,将默认的 true 改为 false */ public static void editConfig(String topicName) throws ExecutionException, InterruptedException { AdminClient adminClient = getAdminClient(); Map<ConfigResource,Config> configMap = new HashMap<>(); ConfigResource configResource = new ConfigResource(ConfigResource.Type.TOPIC,topicName); String keyName = "message.downconversion.enable"; String value = "false"; ConfigEntry configEntry = new ConfigEntry(keyName, value); Config config = new Config(Arrays.asList(configEntry)); configMap.put(configResource,config); AlterConfigsResult alterConfigsResult = adminClient.alterConfigs(configMap); alterConfigsResult.all().get(); } /** * 8. 增加 topic 的Partitions */ public static void addPartitionNum(String topicName, int partitionNum) throws ExecutionException, InterruptedException { AdminClient adminClient = getAdminClient(); Map<String,NewPartitions> partitionsMap = new HashMap<>() ; NewPartitions newPartitions = NewPartitions.increaseTo(partitionNum);//增加到的数量 partitionsMap.put(topicName,newPartitions); CreatePartitionsResult request = adminClient.createPartitions(partitionsMap); request.all().get(); } public static void main(String[] args) throws ExecutionException, InterruptedException { //1. 测试 创建并设置 AdminClient 对象 // AdminClient adminClient = AdminExample1.getAdminClient(); // System.out.println("adminClient==>" + adminClient); //2. 测试 创建topic // createTopic(); //3. 获取已经创建的 topic 的列表 ListTopicsResult topicList = getTopicList(); Collection<TopicListing> topicListings = topicList.listings().get(); for (TopicListing topic : topicListings) { System.out.println(topic); } // 4. 删除topic // deleteTopic("new_topic_test"); // 5. // getDescribeTopics("susu-topic"); //6. 获取 topic 的配置信息 // getDescribeConfig("susu-topic"); // 7. 修改 topic 的配置信息 // editConfig("susu-topic"); // // System.out.println("\n=============修改之后的配置===========\n"); // // getDescribeConfig("susu-topic"); //修改之后再查看配置 //8. 增加 topic 的Partitions addPartitionNum("susu-topic",2); System.out.println("添加完毕"); } }
3. 生产者(Producer API)
3.1 Producer Configs
3.1.1 参考官网
-
关于 Producer Configs 更多配置,参考官网
https://kafka.apache.org/documentation/#producerconfigs. -
简单看个配置,如下:


3.1.2 关于acks 的配置(消息传递保障)
关于 acks 的配置,在考虑请求完成之前,生产者要求领导已收到的确认次数。这控制发送的记录的持久性。允许以下设置:
-
acks=0 ,如果设置为0,那么生产者将不会等待服务器的任何确认。(即:消息发送之后就不管了,无论消息是否写成功)
- 该记录将立即添加到套接字缓冲区并被认为已发送。
- 在这种情况下,不能保证服务器已经接收到记录,重试配置将不会生效(因为客户端通常不会知道任何失败)。为每条记录返回的偏移量将始终设置为-1。
- 即:这种情况消息发送之后,要么根本没收到要么收到一次,所以,
最多收到一次消息(收到0次或多次)。
-
acks=1 ,这将意味着leader将记录写入其本地日志,但将在不等待所有follower完全确认的情况下进行响应。
- 在这种情况下,如果leader在确认记录后立即失败,但在follower复制它之前,那么记录将丢失。
- 两种情况:
- 一是,没收到消息没有回应的重复发送,这时还是收到1次;
- 二是,收到消息但是回应出了问题,即仅没收到回应的重发,这时就会重复收到消息,所以多次。
- 即:这种情况
至少收到一次消息(一次或多次)。
-
acks=all(或者acks=-1) ,这意味着leader将等待同步副本的完整集合来确认记录。
- 这保证了只要至少有一个同步副本保持活动状态,记录就不会丢失。这是最有力的保证。
- 即:这种情况下
收到消息有且仅有一次,如果重复发送会拒收。
-
注意,启用幂等性需要这个配置值为“all”。如果设置了冲突的配置,并且幂等性没有显式启用,则幂等性被禁用。
3.2 Producer API
3.2.1 异步发送
- 代码如下:
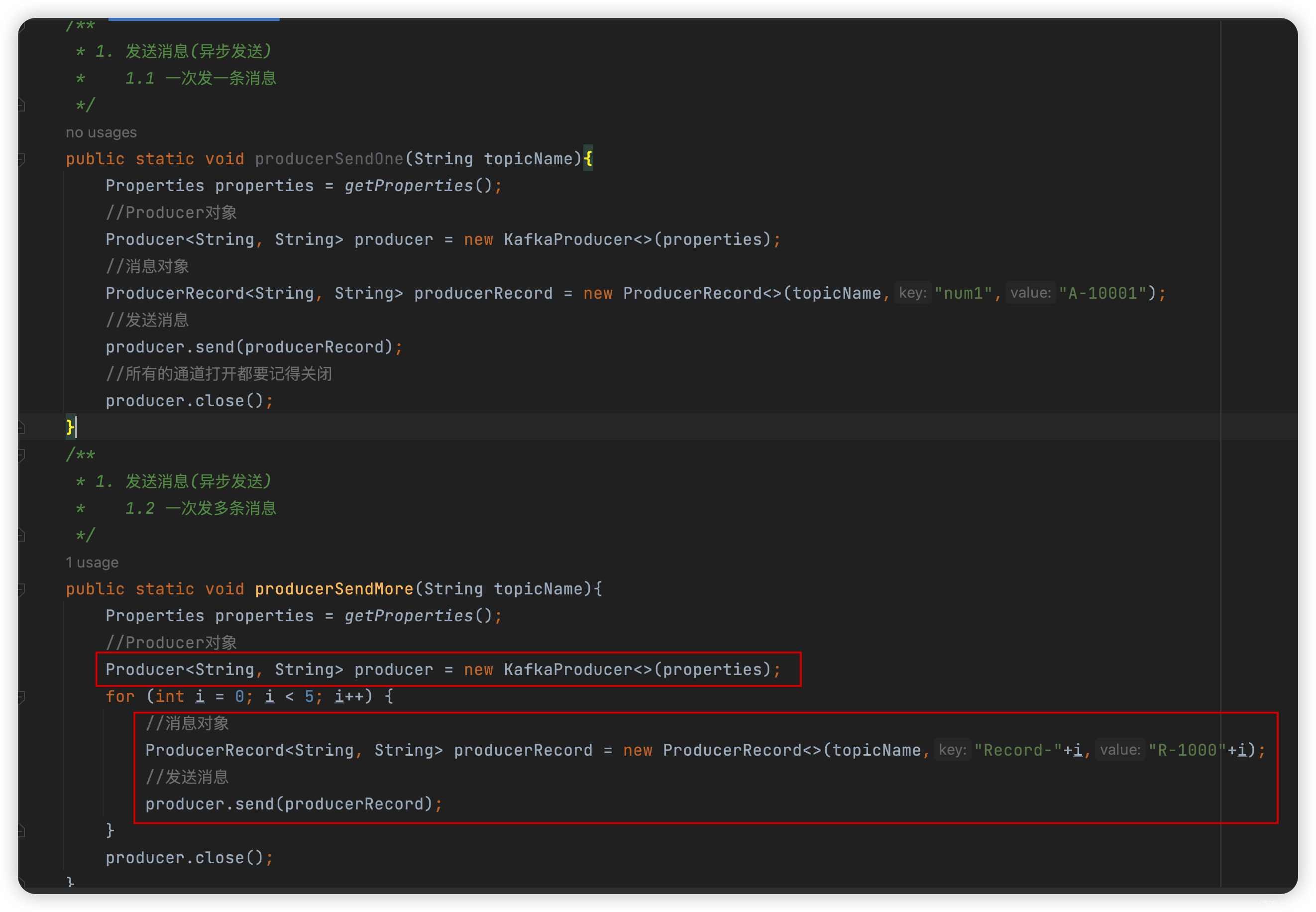
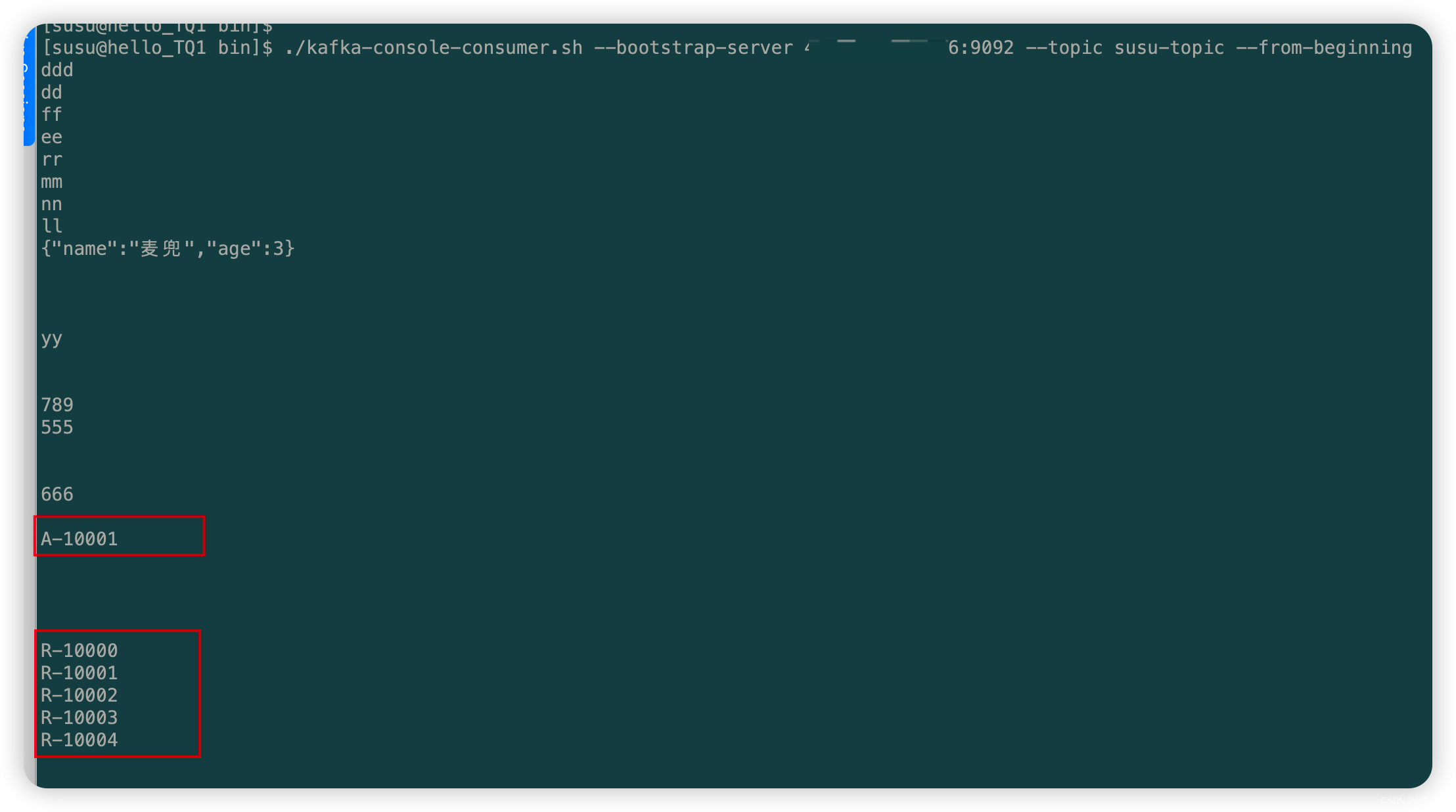
package com.liu.susu.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; /** * @Description * @Author susu */ public class ProducerExample1 { public static Properties getProperties(){ Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "IP:9092"); properties.put(ProducerConfig.ACKS_CONFIG, "all"); properties.put(ProducerConfig.RETRIES_CONFIG, "0"); properties.put(ProducerConfig.BATCH_SIZE_CONFIG, "16348"); properties.put(ProducerConfig.LINGER_MS_CONFIG, "1"); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, "33554432"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); return properties; } /** * 1. 发送消息(异步发送) * 1.1 一次发一条消息 */ public static void producerSendOne(String topicName){ Properties properties = getProperties(); //Producer对象 Producer<String, String> producer = new KafkaProducer<>(properties); //消息对象 ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topicName,"num1","A-10001"); //发送消息 producer.send(producerRecord); //所有的通道打开都要记得关闭 producer.close(); } /** * 1. 发送消息(异步发送) * 1.2 一次发多条消息 */ public static void producerSendMore(String topicName){ Properties properties = getProperties(); //Producer对象 Producer<String, String> producer = new KafkaProducer<>(properties); for (int i = 0; i < 5; i++) { //消息对象 ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topicName,"Record-"+i,"R-1000"+i); //发送消息 producer.send(producerRecord); } producer.close(); } public static void main(String[] args) { //1.1 一次发一条消息 // producerSendOne("susu-topic"); //1.2 一次发多条消息 producerSendMore("susu-topic"); } } - 测试效果如下:
3.2.2 异步阻塞发送(同步发送)
-
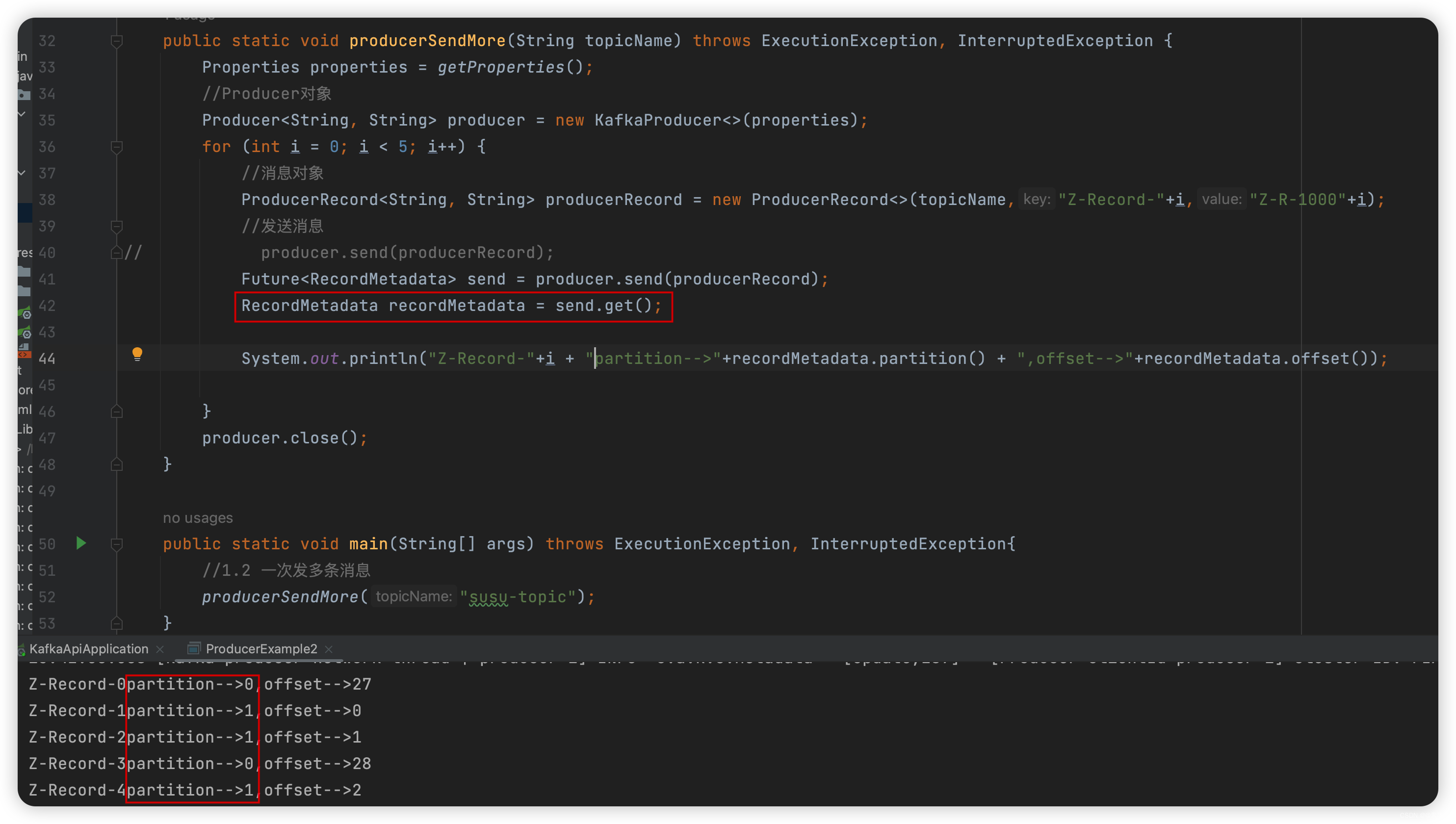
代码如下:
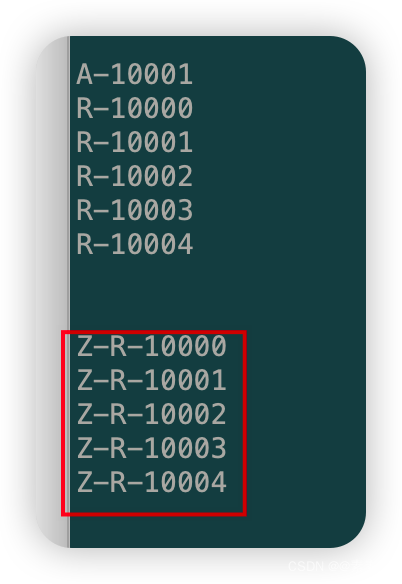
package com.liu.susu.producer; import org.apache.kafka.clients.producer.*; import java.util.Properties; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; /** * @Description * @Author susu */ public class ProducerExample2 { public static Properties getProperties(){ Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "43.143.190.116:9092"); properties.put(ProducerConfig.ACKS_CONFIG, "all"); properties.put(ProducerConfig.RETRIES_CONFIG, "0"); properties.put(ProducerConfig.BATCH_SIZE_CONFIG, "16348"); properties.put(ProducerConfig.LINGER_MS_CONFIG, "1"); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, "33554432"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); return properties; } /** * 1. 异步阻塞发送(同步发送) */ public static void producerSendMore(String topicName) throws ExecutionException, InterruptedException { Properties properties = getProperties(); //Producer对象 Producer<String, String> producer = new KafkaProducer<>(properties); for (int i = 0; i < 5; i++) { //消息对象 ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topicName,"Z-Record-"+i,"Z-R-1000"+i); //发送消息 // producer.send(producerRecord); Future<RecordMetadata> send = producer.send(producerRecord); RecordMetadata recordMetadata = send.get();//future.get会进行阻塞直到返回数据表示发送成功,才会继续下一条消息的发送 System.out.println("Z-Record-"+i + ",partition-->"+recordMetadata.partition() + ",offset-->"+recordMetadata.offset()); } producer.close(); } public static void main(String[] args) throws ExecutionException, InterruptedException{ //1. 异步阻塞发送(同步发送) producerSendMore("susu-topic"); } } -
测试如下:
3.2.3 异步发送并回调
-
生产者发消息,发送完之后不用等待broker给回复,直接执行下面的业务逻辑。可以提供回调方法,让broker异步的调用callback,告知生产者,消息发送的结果。这种方式就不用像异步阻塞那样,发送完之后还得阻塞等着。
-
效果如下:
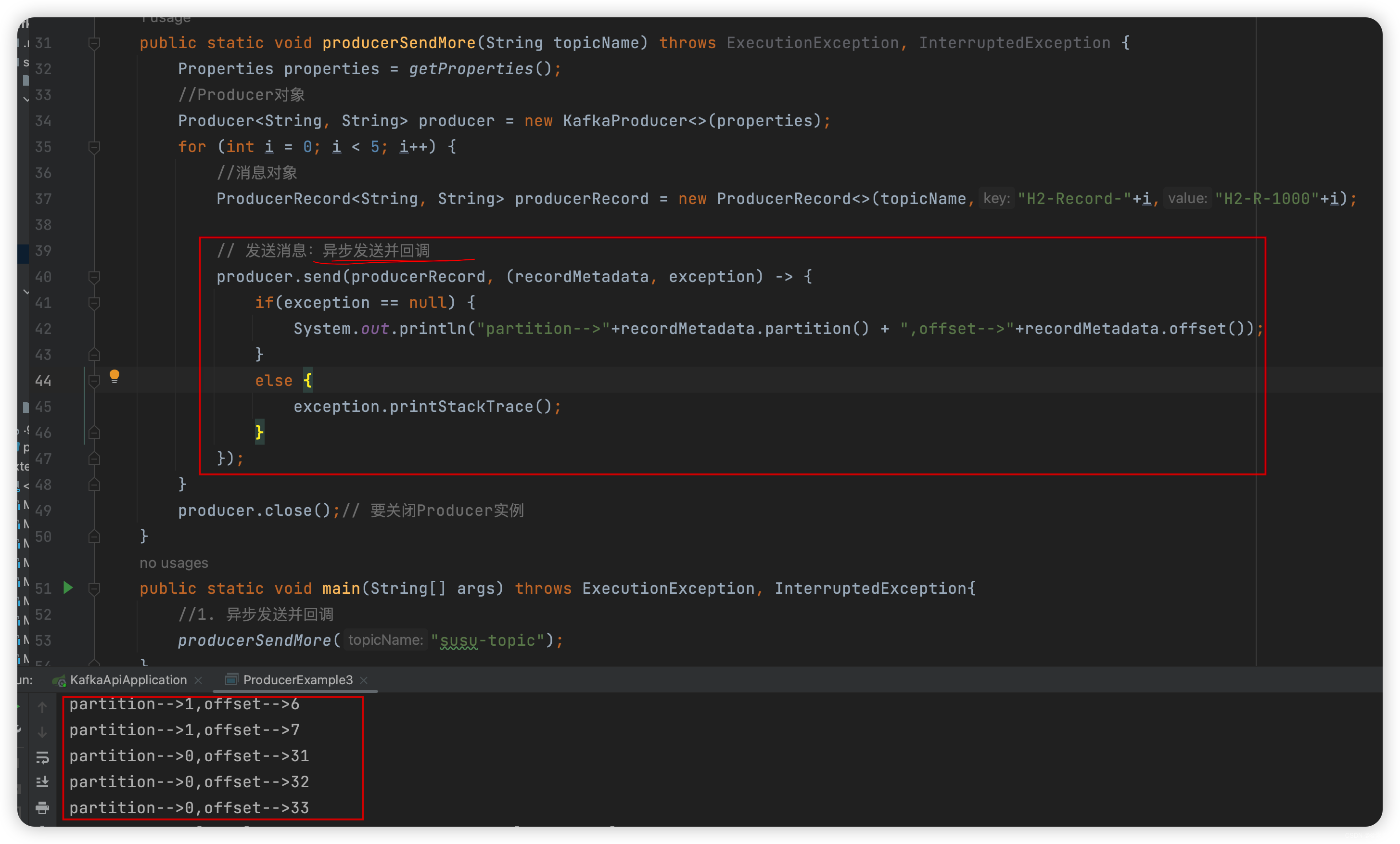
-
代码如下:
package com.liu.susu.producer; import org.apache.kafka.clients.producer.*; import java.util.Properties; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; /** * @Description * @Author susu */ public class ProducerExample3 { public static Properties getProperties(){ Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "43.143.190.116:9092"); properties.put(ProducerConfig.ACKS_CONFIG, "all"); properties.put(ProducerConfig.RETRIES_CONFIG, "0"); properties.put(ProducerConfig.BATCH_SIZE_CONFIG, "16348"); properties.put(ProducerConfig.LINGER_MS_CONFIG, "1"); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, "33554432"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); return properties; } /** * 1. 异步发送并回调 */ public static void producerSendMore(String topicName) throws ExecutionException, InterruptedException { Properties properties = getProperties(); //Producer对象 Producer<String, String> producer = new KafkaProducer<>(properties); for (int i = 0; i < 5; i++) { //消息对象 ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topicName,"H4-Record-"+i,"H4-R-1000"+i); //1 发送消息:异步发送并回调 producer.send(producerRecord, (recordMetadata, exception) -> { if(exception == null) { System.out.println("partition-->"+recordMetadata.partition() + ",offset-->"+recordMetadata.offset()); } else { exception.printStackTrace(); } }); //2 发送消息:异步发送并回调 // producer.send(producerRecord, new Callback() { // @Override // public void onCompletion(RecordMetadata recordMetadata, Exception e) { // if(e == null) { // System.out.println("partition-->"+recordMetadata.partition() + ",offset-->"+recordMetadata.offset()); // } // else { // e.printStackTrace(); // } // } // }); } producer.close();// 要关闭Producer实例 } public static void main(String[] args) throws ExecutionException, InterruptedException{ //1. 异步发送并回调 producerSendMore("susu-topic"); } }
3.2.4 总结 ( 异步阻塞发送 与 异步发送)
3.2.3.1 异步阻塞发送
- 此方式可理解为同步发送(即:同步就是逐条发送。)。
- 一定是逐条发送的,第一条响应到达后,才会请求第二条。会对每条消息的结果进行判断,
future.get()会进行阻塞直到返回数据表示发送成功,才会继续下一条消息的发送,可以直到每条信息的发送情况。 - 此方式如果发送失败会进行重试并抛出异常,直至重试达到retries最大次数,此方式也是最大程度确保数据可靠性,可以记录对应的结果日志。
- 一定是逐条发送的,第一条响应到达后,才会请求第二条。会对每条消息的结果进行判断,
3.2.3.2 异步发送
- 异步就是批量发送。
- 如果设置成异步的模式,可以运行生产者以batch的形式push数据,这样会极大的提高broker的性能,但是这样会增加丢失数据的风险。
- 异步方式,可以发送一条,也可以批量发送多条,特性是不需等第一次(注意这里单位是次,因为单次可以是单条,也可以是批量数据)响应,就立即发送第二次。
3.2.3.3 参考
- Kafka同步发送与异步发送消息.
3.3 Producer 自定义Partition分区规则(负载均衡)
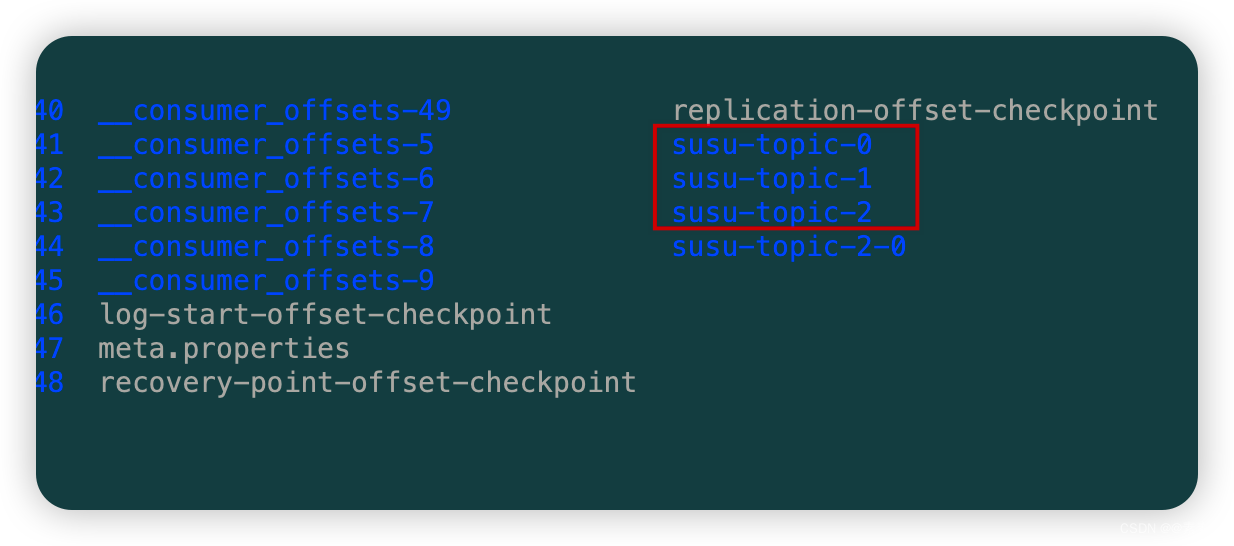
3.3.1 把 Partition 增加到3
- 如下,0 ,1 ,2:
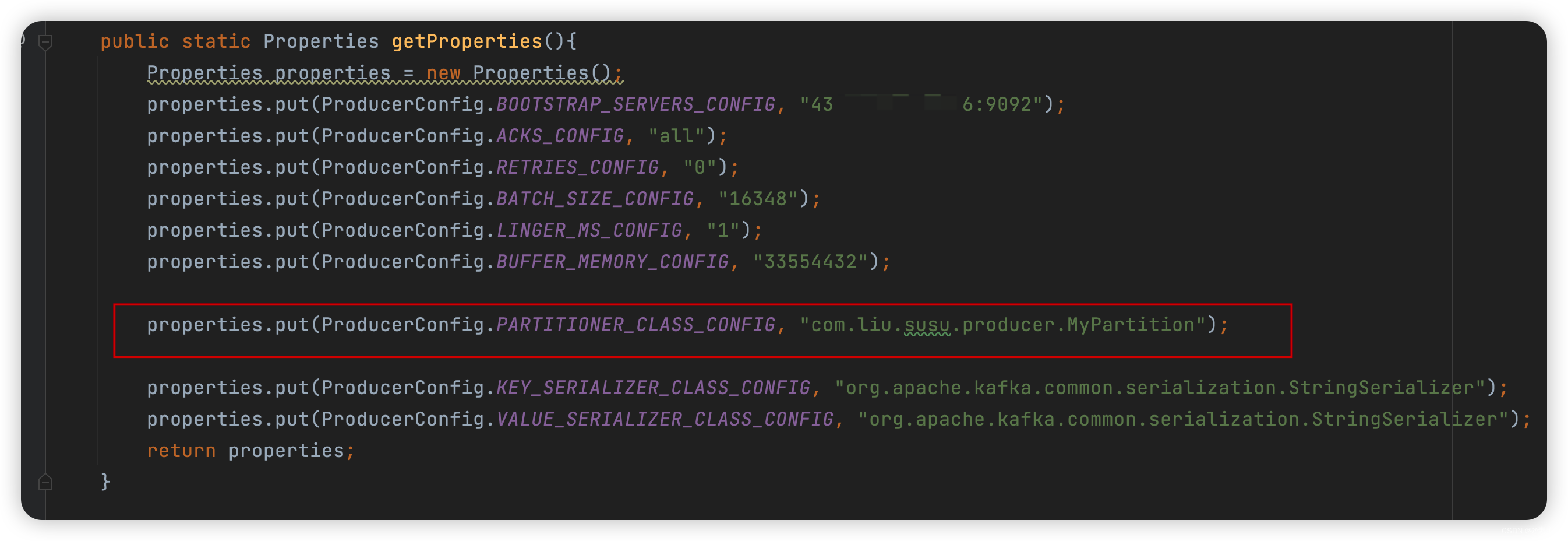
3.3.2 核心代码
-
如下:

-
MyPartition.java
package com.liu.susu.producer; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; /** * @Description * @Author susu */ public class MyPartition implements Partitioner { @Override public int partition(String topic, Object key, byte[] bytes, Object value, byte[] bytes1, Cluster cluster) { String newsKey = key + ""; //格式:"P-Record-"+i String newKeyNum = newsKey.substring(newsKey.length()-1);//取最后一位 int keyNum = Integer.parseInt(newKeyNum); int partition = keyNum % 3; System.out.println("newsKey--->"+newsKey + ",newKeyNum-->"+newKeyNum+",partition-->"+partition); return partition; } @Override public void close() { } @Override public void configure(Map<String, ?> map) { } } -
例子:
package com.liu.susu.producer; import org.apache.kafka.clients.producer.*; import java.util.Properties; import java.util.concurrent.ExecutionException; /** * @Description * @Author susu */ public class ProducerExample4 { public static Properties getProperties(){ Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "43.143.190.116:9092"); properties.put(ProducerConfig.ACKS_CONFIG, "all"); properties.put(ProducerConfig.RETRIES_CONFIG, "0"); properties.put(ProducerConfig.BATCH_SIZE_CONFIG, "16348"); properties.put(ProducerConfig.LINGER_MS_CONFIG, "1"); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, "33554432"); properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.liu.susu.producer.MyPartition"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); return properties; } /** * 1. 异步发送并回调 */ public static void producerSendMore(String topicName) throws ExecutionException, InterruptedException { Properties properties = getProperties(); //Producer对象 Producer<String, String> producer = new KafkaProducer<>(properties); for (int i = 1; i <= 15; i++) { //消息对象 ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topicName,"P-Record-"+i,"P-R-1000"+i); //发送消息:异步发送并回调 producer.send(producerRecord, new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if(e == null) { System.out.println("partition-->"+recordMetadata.partition() + ",offset-->"+recordMetadata.offset()); } else { e.printStackTrace(); } } }); } producer.close();// 要关闭Producer实例 } public static void main(String[] args) throws ExecutionException, InterruptedException{ // 异步发送并回调 producerSendMore("susu-topic"); } }
3.3.3 效果
- 使用异步发送并回调,效果如下:

4. 消费者
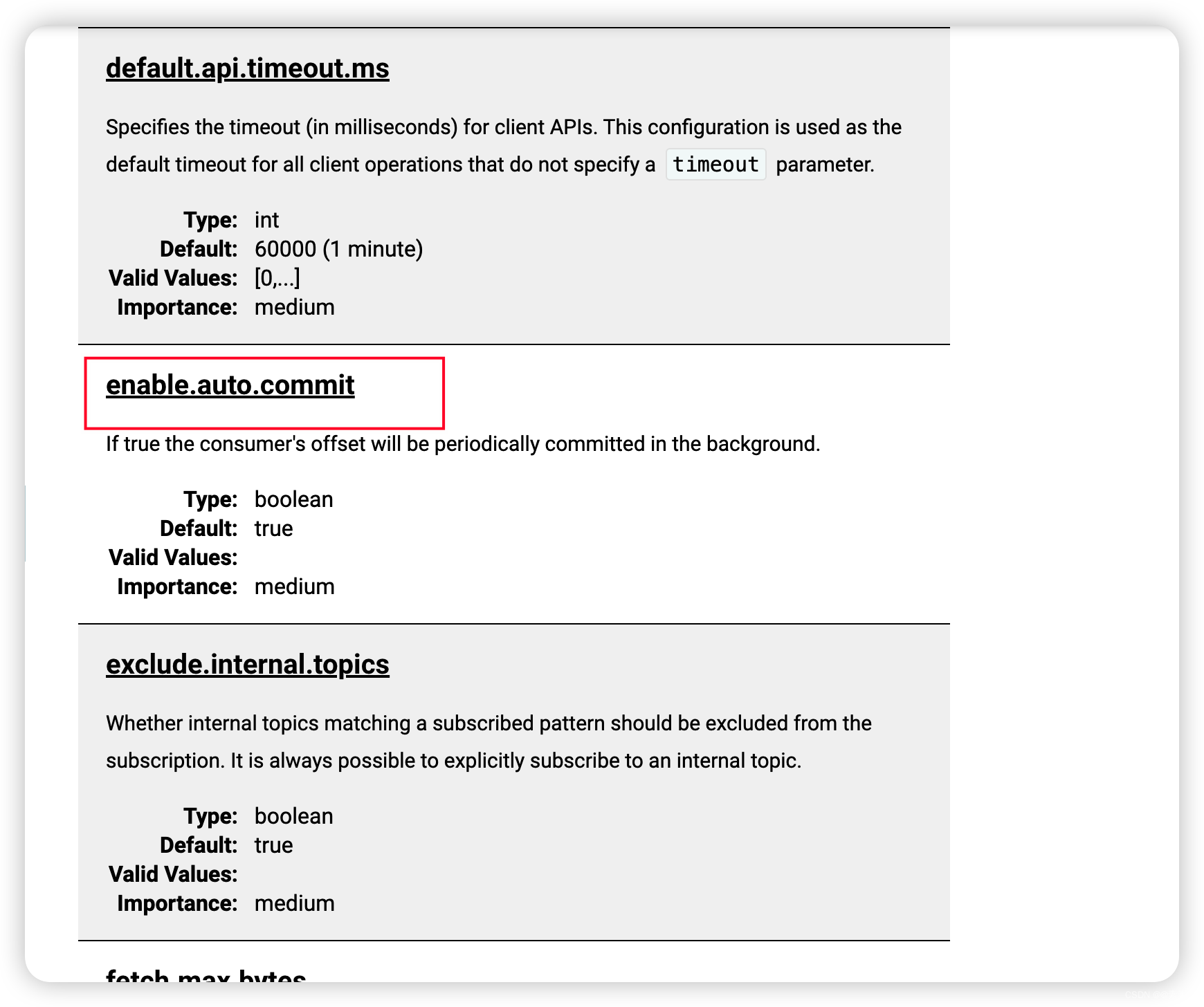
4.1 Consumer Configs
- 参考官网:
https://kafka.apache.org/documentation/#consumerconfigs.
4.2 消费者消费例子
4.2.1 官网参考
- 如下:
https://kafka.apache.org/28/javadoc/org/apache/kafka/clients/consumer/KafkaConsumer.html. - 例子可参考 Class
KafkaConsumer<K,V>
4.2.2 简单入门例子——自动偏移提交
-
这种情况下,消费过的不会再消费,代码如下:
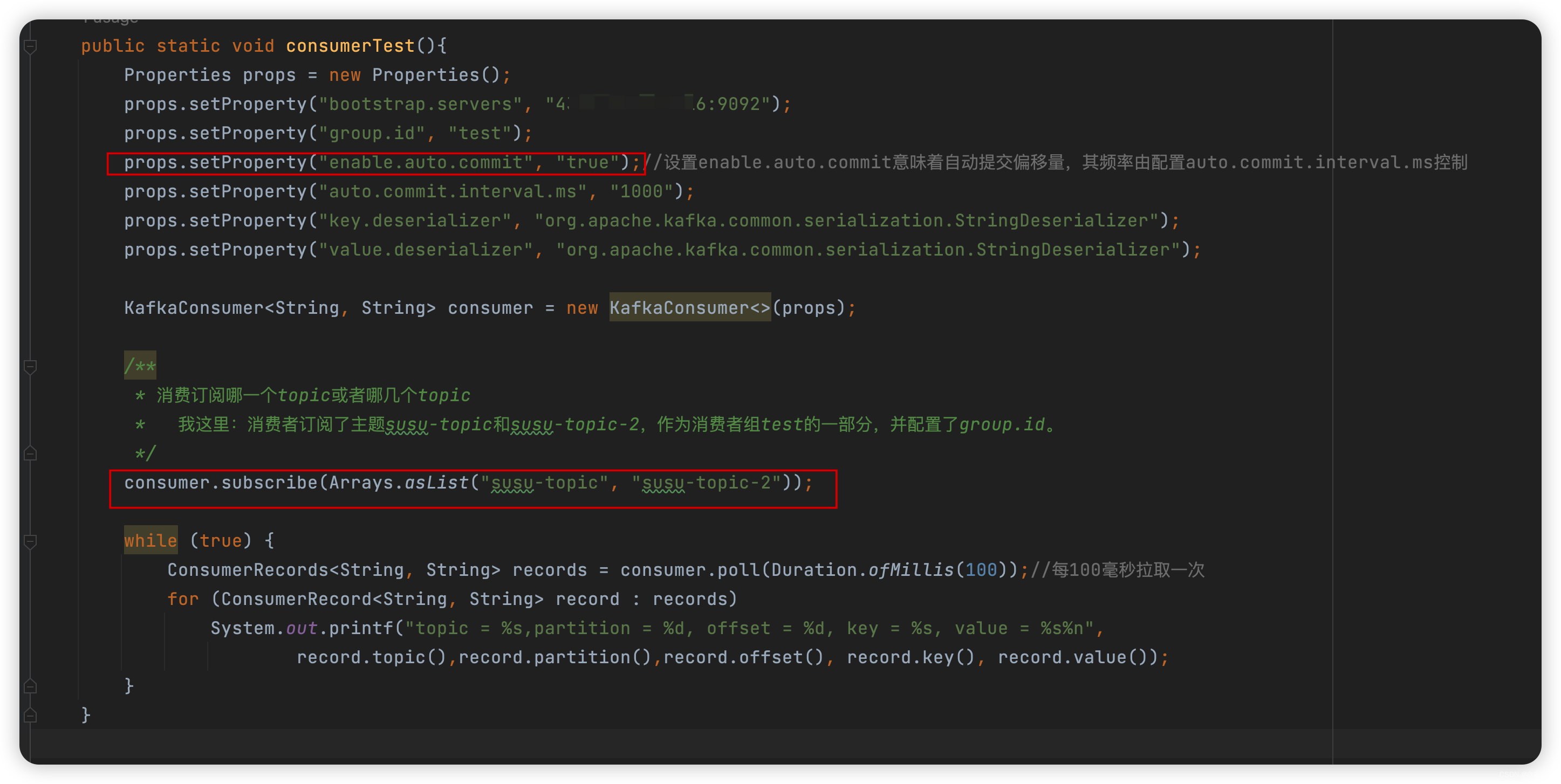
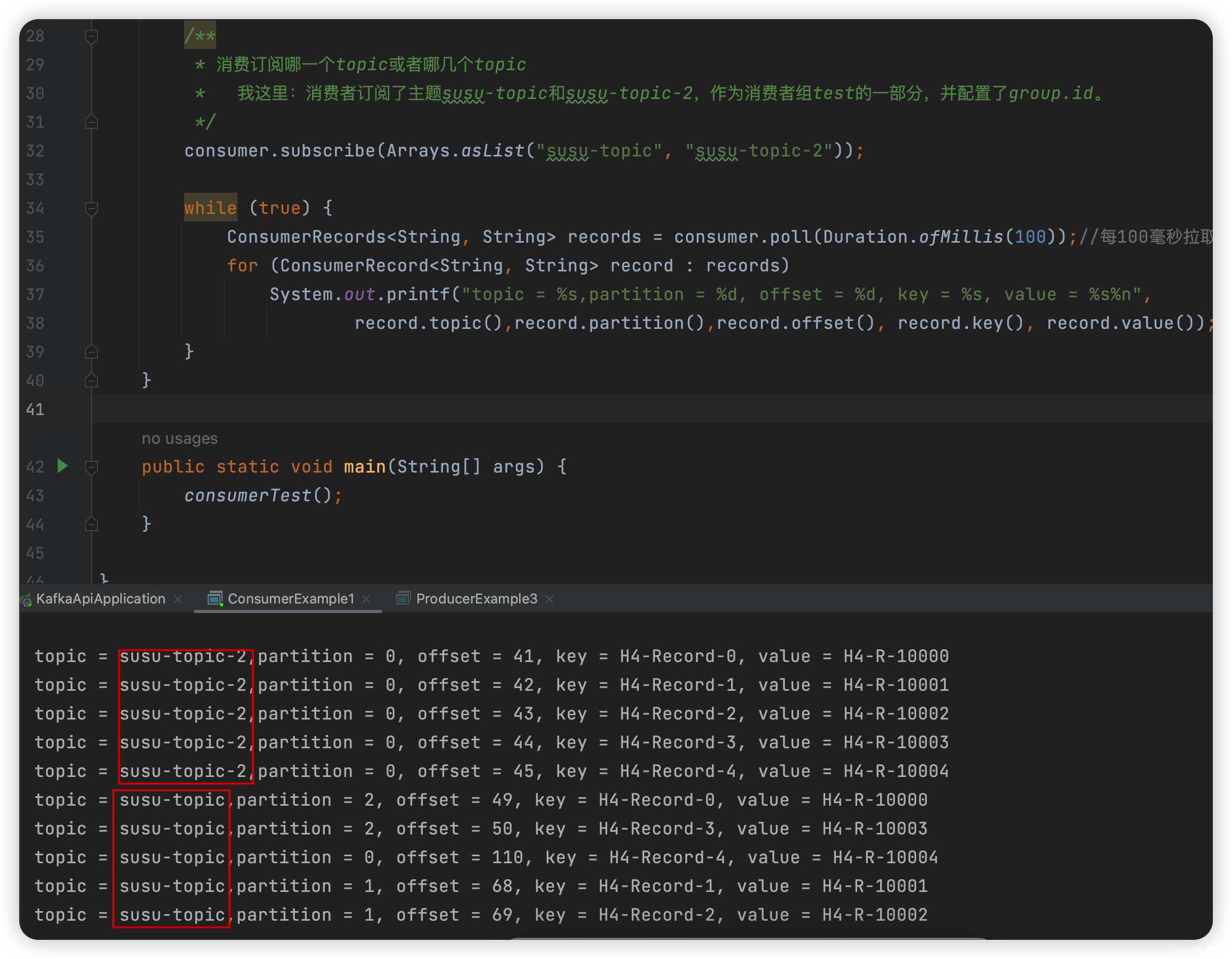
package com.liu.susu.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration; import java.util.Arrays; import java.util.Properties; /** * @Description * @Author susu */ public class ConsumerExample1 { public static void consumerTest(){ Properties props = new Properties(); props.setProperty("bootstrap.servers", "IP:9092"); props.setProperty("group.id", "test"); props.setProperty("enable.auto.commit", "true");//设置enable.auto.commit意味着自动提交偏移量,其频率由配置auto.commit.interval.ms控制 props.setProperty("auto.commit.interval.ms", "1000"); props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); /** * 消费订阅哪一个topic或者哪几个topic * 我这里:消费者订阅了主题susu-topic和susu-topic-2,作为消费者组test的一部分,并配置了group.id。 */ consumer.subscribe(Arrays.asList("susu-topic", "susu-topic-2")); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));//每100毫秒拉取一次 for (ConsumerRecord<String, String> record : records) System.out.printf("topic = %s,partition = %d, offset = %d, key = %s, value = %s%n", record.topic(),record.partition(),record.offset(), record.key(), record.value()); } } public static void main(String[] args) { consumerTest(); } } -
效果如下:
4.2.2 手动偏移控制
4.2.3.1 解释
- 用户还可以控制何时将记录视为已消耗记录,从而提交其偏移量,而不是依赖于消费者定期提交所消耗的偏移量。当消息的消费与一些处理逻辑相结合时,这很有用,因此在消息完成处理之前不应将其视为消费。
- 在本例中,我们将使用一批记录并在内存中批量处理它们。当我们有足够的记录时,我们将把它们插入到数据库中。如果我们像前面的例子一样允许偏移量自动提交,那么记录在poll中返回给用户后就会被认为是消耗了。这样,我们的流程就有可能在对记录进行批处理之后,但在将它们插入数据库之前失败。
为了避免这种情况,我们将只在将相应的记录插入数据库之后手动提交偏移量。这使我们能够精确控制记录何时被消费。这引发了相反的可能性:进程可能在插入数据库之后但在提交之前的时间间隔内失败(尽管这可能只有几毫秒,但这是有可能的)。在这种情况下,接管消费的进程将从最后提交的偏移量中消费,并将重复插入最后一批数据。使用这种方式,Kafka提供了通常被称为==“至少一次”的交付保证==,因为每个记录可能只交付一次,但在失败的情况下可以复制。
4.2.3.2 代码
-
代码如下:
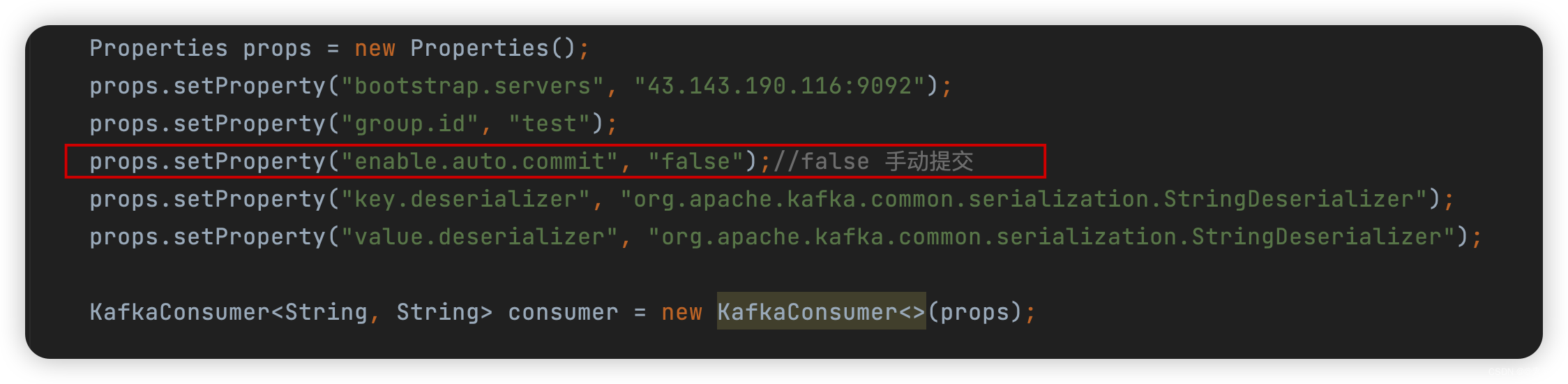
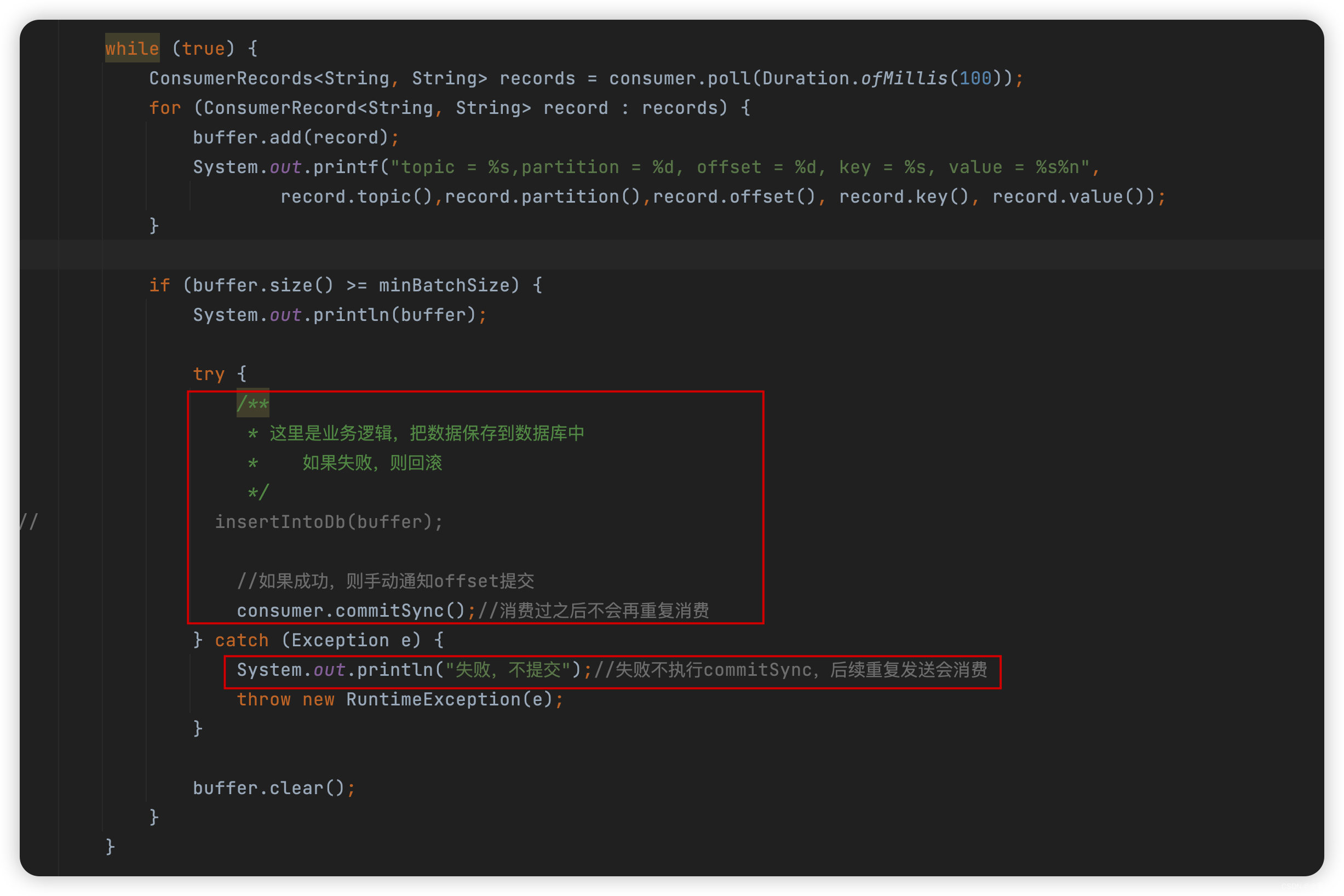
package com.liu.susu.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import java.util.Properties; /** * @Description 手动提交 * @Author susu */ public class ConsumerExample2 { public static void consumerTest(){ Properties props = new Properties(); props.setProperty("bootstrap.servers", "43.143.190.116:9092"); props.setProperty("group.id", "test"); props.setProperty("enable.auto.commit", "false");//false 手动提交 props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); // consumer.subscribe(Arrays.asList("susu-topic", "susu-topic-2")); consumer.subscribe(Arrays.asList("susu-topic")); final int minBatchSize = 20; List<ConsumerRecord<String, String>> buffer = new ArrayList<>(); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) { buffer.add(record); System.out.printf("topic = %s,partition = %d, offset = %d, key = %s, value = %s%n", record.topic(),record.partition(),record.offset(), record.key(), record.value()); } if (buffer.size() >= minBatchSize) { System.out.println(buffer); try { /** * 这里是业务逻辑,把数据保存到数据库中 * 如果失败,则回滚 */ // insertIntoDb(buffer); //如果成功,则手动通知offset提交 consumer.commitSync();//消费过之后不会再重复消费 } catch (Exception e) { System.out.println("失败,不提交");//失败不执行commitSync,后续重复发送会消费 throw new RuntimeException(e); } buffer.clear(); } } } public static void main(String[] args) { consumerTest(); } }
4.2.3 每个 partition 单独处理
4.2.3.1 解释
- 上面的例子使用
commitSync将所有收到的记录标记为已提交。在某些情况下,你可能希望通过显式指定偏移量来更好地控制已提交的记录。在本示例中,我们在处理完每个分区中的记录后提交偏移量。
4.2.3.2 代码
-
代码如下:
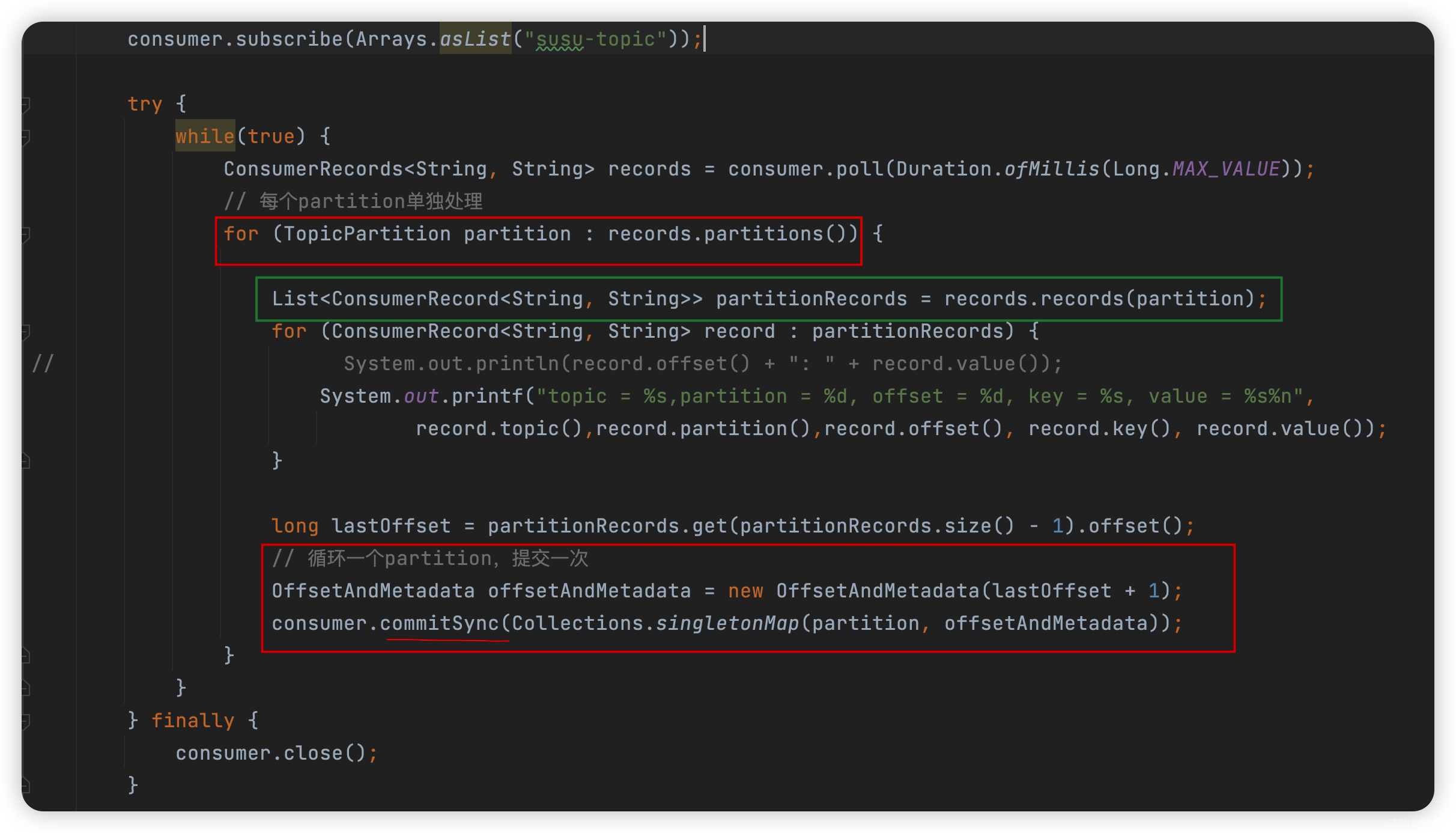
package com.liu.susu.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.OffsetAndMetadata; import org.apache.kafka.common.TopicPartition; import java.time.Duration; import java.util.*; /** * @Description 处理完每个分区中的记录后提交偏移量 * @Author susu */ public class ConsumerExample3 { public static void consumerTest(){ Properties props = new Properties(); props.setProperty("bootstrap.servers", "43.143.190.116:9092"); props.setProperty("group.id", "test"); props.setProperty("enable.auto.commit", "false");//false 手动提交 props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); // consumer.subscribe(Arrays.asList("susu-topic", "susu-topic-2")); consumer.subscribe(Arrays.asList("susu-topic")); try { while(true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(Long.MAX_VALUE)); // 每个partition单独处理 for (TopicPartition partition : records.partitions()) { List<ConsumerRecord<String, String>> partitionRecords = records.records(partition); for (ConsumerRecord<String, String> record : partitionRecords) { // System.out.println(record.offset() + ": " + record.value()); System.out.printf("topic = %s,partition = %d, offset = %d, key = %s, value = %s%n", record.topic(),record.partition(),record.offset(), record.key(), record.value()); } long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset(); // 循环一个partition,提交一次 OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(lastOffset + 1); consumer.commitSync(Collections.singletonMap(partition, offsetAndMetadata)); } } } finally { consumer.close(); } } public static void main(String[] args) { consumerTest(); } } -
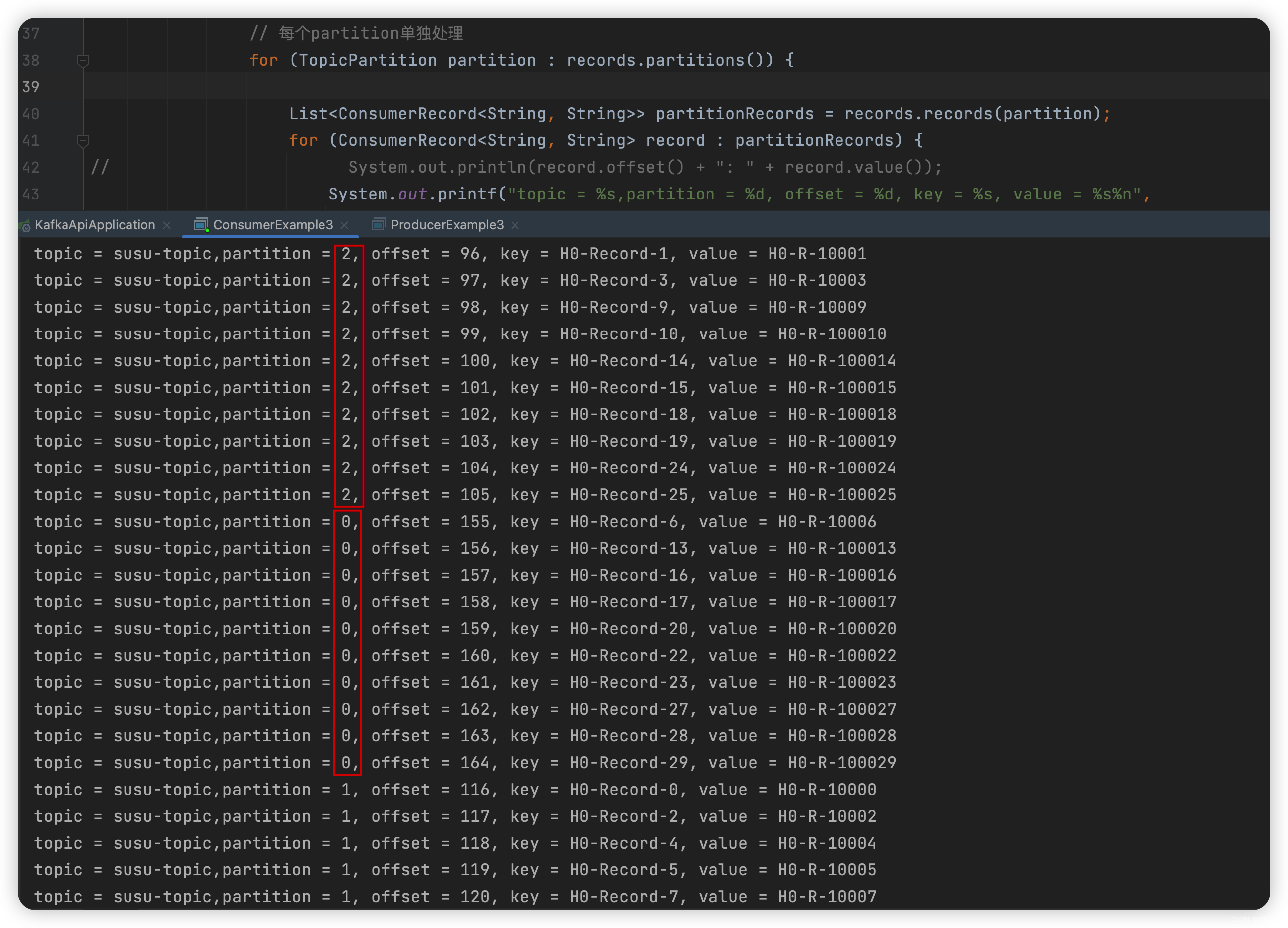
效果如下:
4.2.3.3 注意
- 注意:提交的偏移量应该始终是应用程序将读取的下一条消息的偏移量。因此,在调用commitSync(offsets)时,应该在最后处理的消息的偏移量上添加一个。
4.2.4 手动控制消费哪个partition(手动分区分配)
4.2.4.1 描述
- 在前面的例子中,我们订阅了我们感兴趣的主题,并让Kafka根据组中活跃的消费者动态地为这些主题分配公平的分区份额。但是,在某些情况下,您可能需要对分配的特定分区进行更好的控制。例如:
- 如果进程正在维护与该分区相关的某种本地状态(比如本地磁盘上的键值存储),那么它应该只获取它在磁盘上维护的分区的记录。
- 如果进程本身是高可用的,并且在失败时将重新启动(可能使用像YARN、Mesos或AWS设施这样的集群管理框架,或者作为流处理框架的一部分)。在这种情况下,Kafka不需要检测故障并重新分配分区,因为消费进程将在另一台机器上重新启动。
- 要使用这种模式,不需要使用subscribe订阅主题,只需调用
assign(Collection),其中包含要使用的分区的完整列表。
4.2.4.2 代码
-
如下:
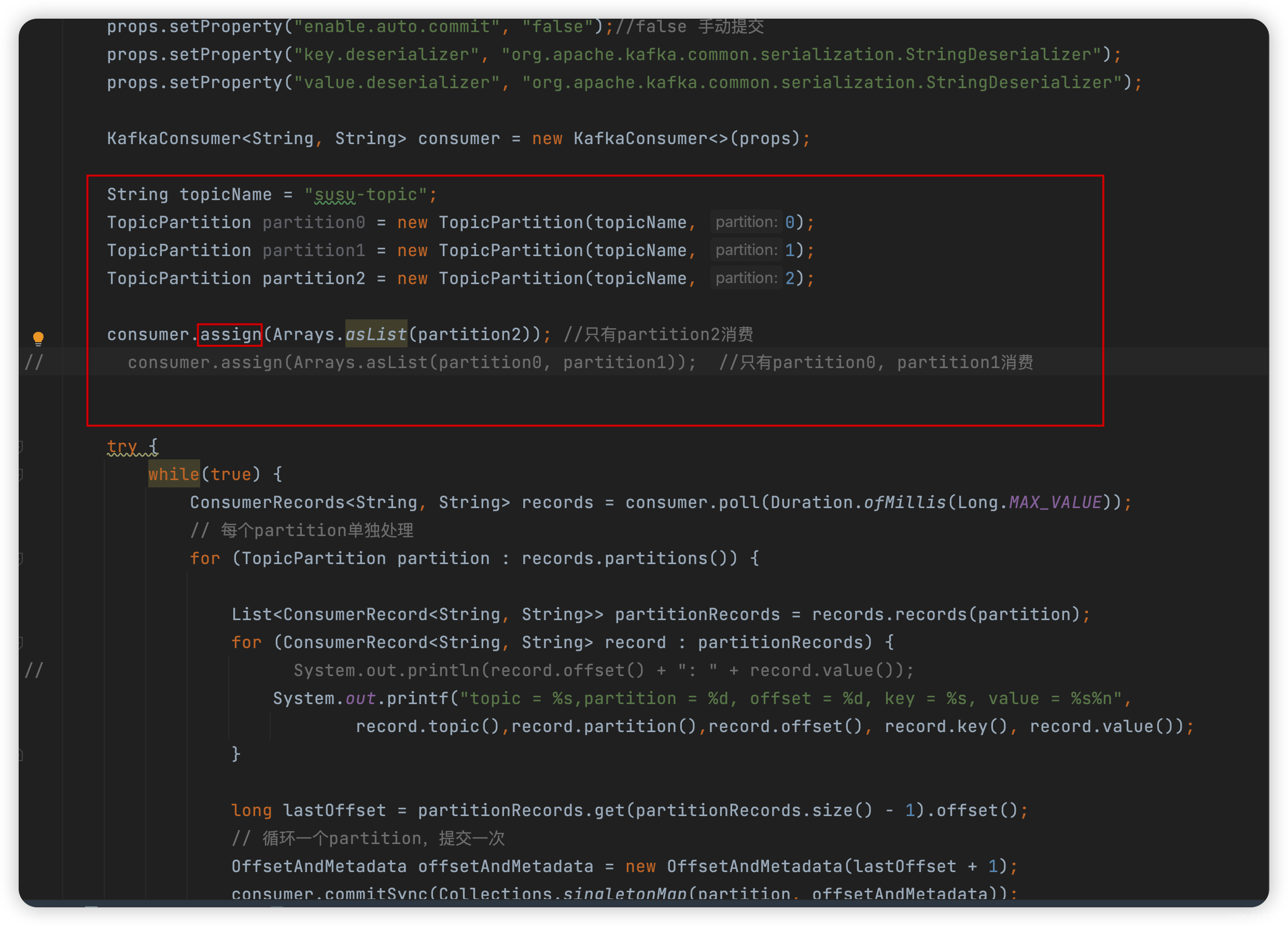
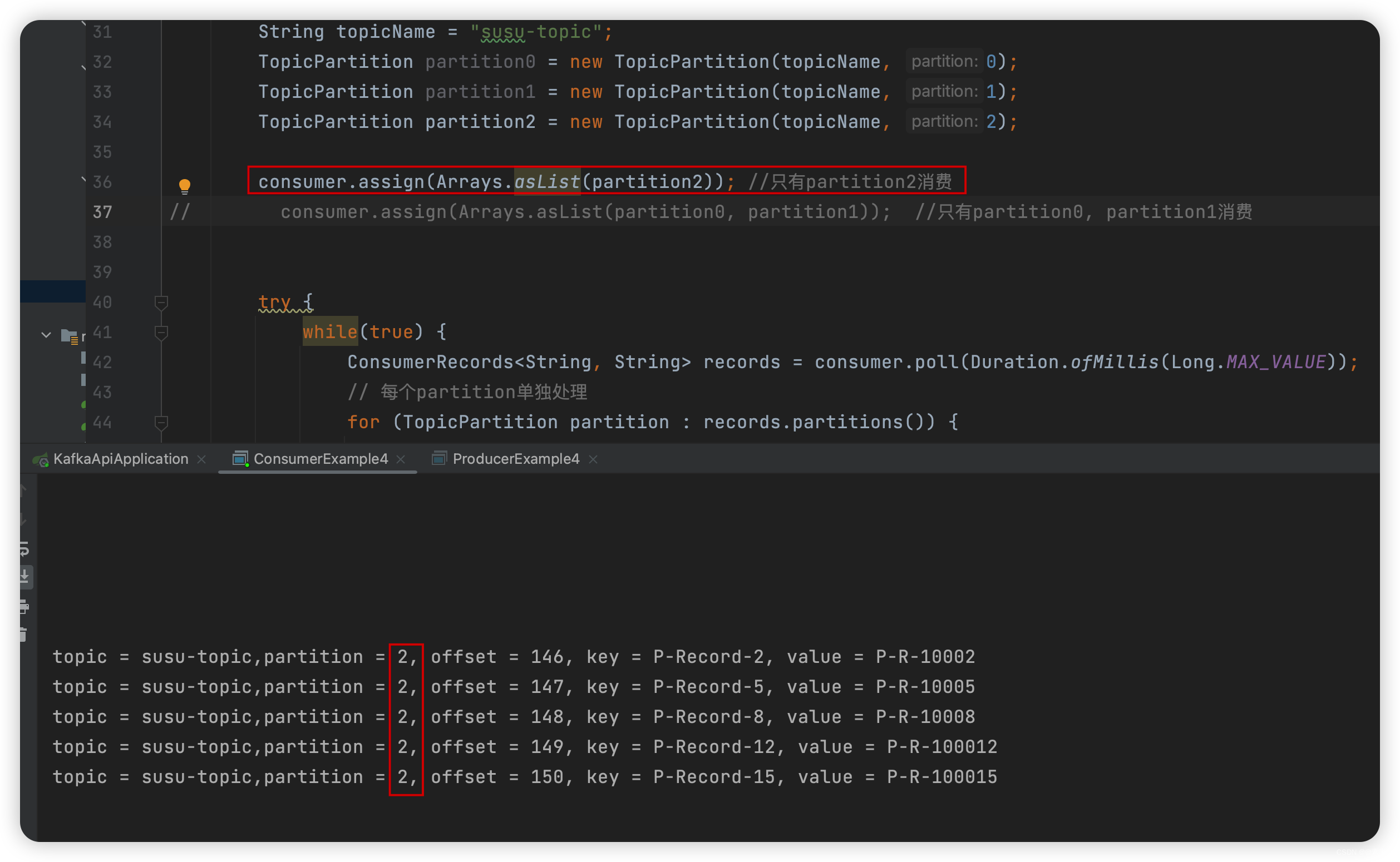
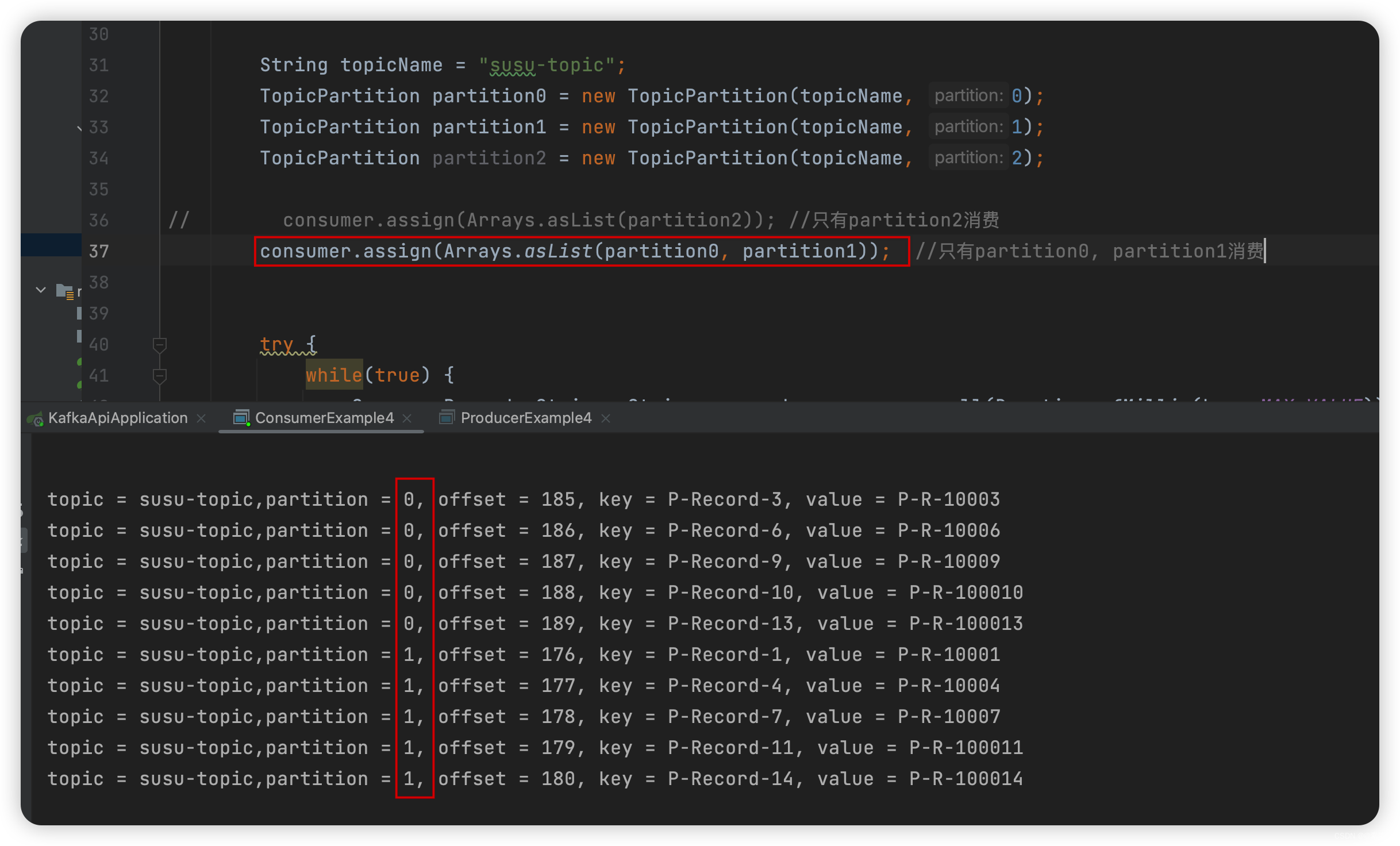
package com.liu.susu.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.OffsetAndMetadata; import org.apache.kafka.common.TopicPartition; import java.time.Duration; import java.util.Arrays; import java.util.Collections; import java.util.List; import java.util.Properties; /** * @Description 指定消费某个分区 * @Author susu */ public class ConsumerExample4 { public static void consumerTest(){ Properties props = new Properties(); props.setProperty("bootstrap.servers", "43.143.190.116:9092"); props.setProperty("group.id", "test"); props.setProperty("enable.auto.commit", "false");//false 手动提交 props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); String topicName = "susu-topic"; TopicPartition partition0 = new TopicPartition(topicName, 0); TopicPartition partition1 = new TopicPartition(topicName, 1); TopicPartition partition2 = new TopicPartition(topicName, 2); consumer.assign(Arrays.asList(partition2)); //只有partition2消费 // consumer.assign(Arrays.asList(partition0, partition1)); //只有partition0, partition1消费 try { while(true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(Long.MAX_VALUE)); // 每个partition单独处理 for (TopicPartition partition : records.partitions()) { List<ConsumerRecord<String, String>> partitionRecords = records.records(partition); for (ConsumerRecord<String, String> record : partitionRecords) { // System.out.println(record.offset() + ": " + record.value()); System.out.printf("topic = %s,partition = %d, offset = %d, key = %s, value = %s%n", record.topic(),record.partition(),record.offset(), record.key(), record.value()); } long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset(); // 循环一个partition,提交一次 OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(lastOffset + 1); consumer.commitSync(Collections.singletonMap(partition, offsetAndMetadata)); } } } finally { consumer.close(); } } public static void main(String[] args) { consumerTest(); } }
4.2.4.3 效果
-
如下:
4.2.5 消费者多线程处理
4.2.5.1 消费者线程不安全
- Kafka消费者不是线程安全的。所有网络I/O都发生在发出调用的应用程序线程中。确保多线程访问正确同步是用户的责任。非同步访问将导致ConcurrentModificationException。
- 该规则的唯一例外是wakeup(),它可以安全地从外部线程中断活动操作。在这种情况下,阻塞操作的线程将抛出WakeupException。这可以用于从另一个线程关闭消费者。
- 然后在一个单独的线程中,可以通过设置closed标志并唤醒消费者来关闭消费者。
closed.set(true); consumer.wakeup ();
- 然后在一个单独的线程中,可以通过设置closed标志并唤醒消费者来关闭消费者。
4.2.5.2 两种方式实现
4.2.5.2.1 每个线程一个消费者
- 一个简单的选择是为每个线程提供自己的消费者实例。以下是这种方法的优点和缺点:
- 利:这是最容易实现的
- 优点:它通常是最快的,因为不需要线程间的协调
- 优点:它使得基于每个分区的有序处理非常容易实现(每个线程只按照接收消息的顺序处理消息)。
- 缺点:更多的消费者意味着更多的TCP连接到集群(每个线程一个)。一般来说,Kafka处理连接非常有效,所以这通常是一个小成本。
- 缺点:多个消费者意味着更多的请求被发送到服务器,稍微少一些数据批处理,这可能会导致I/O吞吐量下降。
- 缺点:所有进程的线程总数将受到分区总数的限制。
4.2.5.2.1 将消费和处理分离
- 这种方法是让一个或多个消费者线程完成所有数据消费,并将ConsumerRecords实例交给阻塞队列,该队列由实际处理记录处理的处理器线程池使用。这个选项同样也有利弊:
- 优点:这个选项允许独立地扩展消费者和处理器的数量。这使得单个消费者可以为多个处理器线程提供服务,从而避免了对分区的任何限制。
- 缺点:保证跨处理器的顺序需要特别注意,因为线程将独立执行,由于线程执行时间的运气,较早的数据块实际上可能在较晚的数据块之后处理。对于没有订购要求的处理,这不是问题。
- 缺点:手动提交位置变得更加困难,因为它需要所有线程协调以确保对该分区的处理完成。
这种方法有许多可能的变体。例如,每个处理器线程可以有自己的队列,消费者线程可以使用TopicPartition散列到这些队列中,以确保有序消费并简化提交。
4.2.5.3 典型的模式(每个线程一个消费者)
-
代码如下:
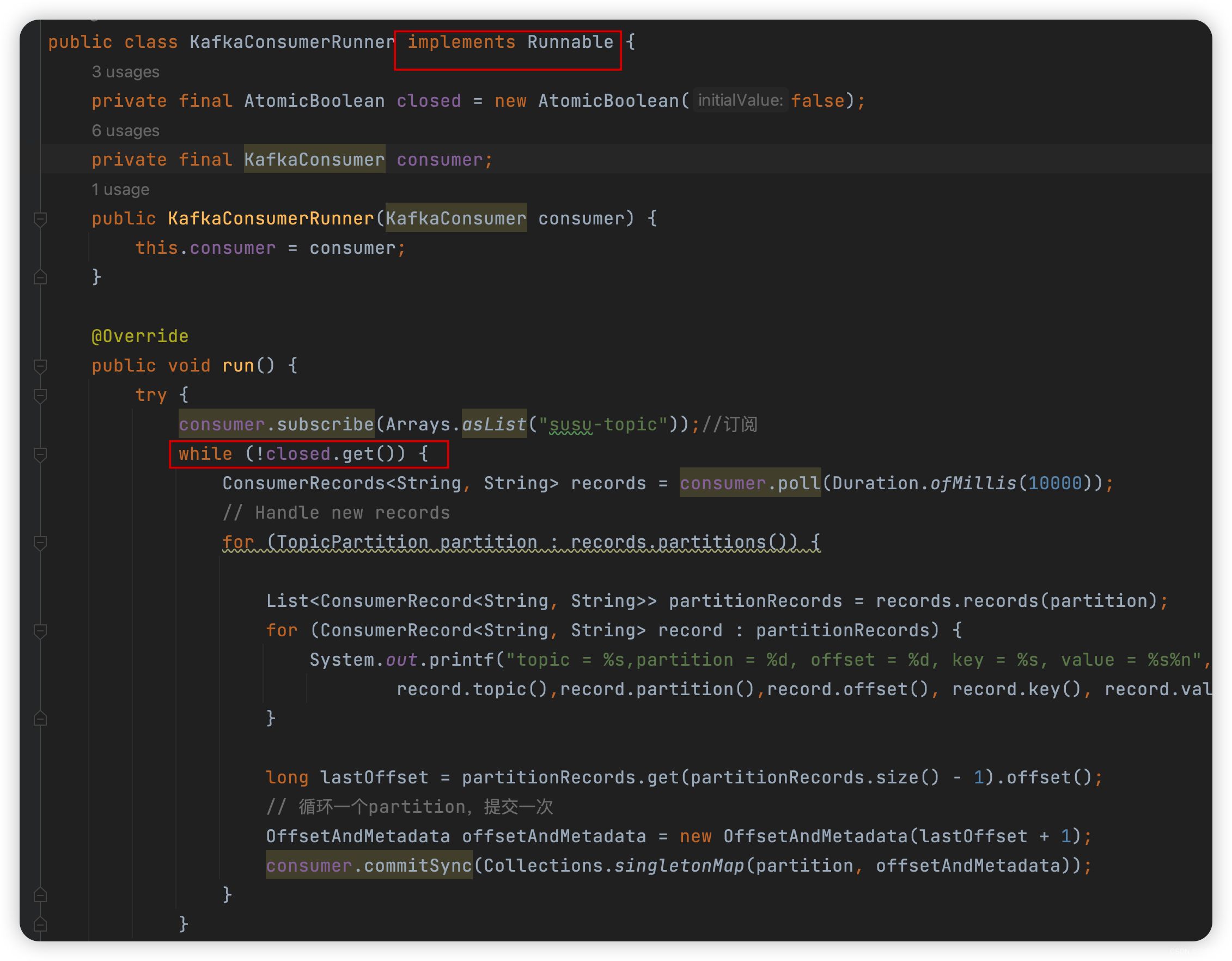
package com.liu.susu.consumer.thread; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.OffsetAndMetadata; import org.apache.kafka.common.TopicPartition; import org.apache.kafka.common.errors.WakeupException; import java.time.Duration; import java.util.*; import java.util.concurrent.atomic.AtomicBoolean; /** * @Description * @Author susu */ public class KafkaConsumerRunner implements Runnable { private final AtomicBoolean closed = new AtomicBoolean(false); private final KafkaConsumer consumer; public KafkaConsumerRunner(KafkaConsumer consumer) { this.consumer = consumer; } @Override public void run() { try { consumer.subscribe(Arrays.asList("susu-topic"));//订阅 while (!closed.get()) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000)); // Handle new records for (TopicPartition partition : records.partitions()) { List<ConsumerRecord<String, String>> partitionRecords = records.records(partition); for (ConsumerRecord<String, String> record : partitionRecords) { System.out.printf("Thread = %s,topic = %s,partition = %d, offset = %d, key = %s, value = %s%n", Thread.currentThread().getName(), record.topic(),record.partition(),record.offset(), record.key(), record.value()); } long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset(); // 循环一个partition,提交一次 OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(lastOffset + 1); consumer.commitSync(Collections.singletonMap(partition, offsetAndMetadata)); } } } catch (WakeupException e) { // Ignore exception if closing if (!closed.get()) throw e; } finally { consumer.close(); } } // Shutdown hook which can be called from a separate thread public void shutdown() { closed.set(true); consumer.wakeup(); } /** * 构建 consumer * @return consumer */ public static KafkaConsumer<String, String> getKafkaConsumer(){ Properties props = new Properties(); props.setProperty("bootstrap.servers", "43.143.190.116:9092"); props.setProperty("group.id", "test"); props.setProperty("enable.auto.commit", "false");//false 手动提交 props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); return consumer; } public static void main(String[] args) { KafkaConsumer<String, String> consumer = getKafkaConsumer(); KafkaConsumerRunner runner = new KafkaConsumerRunner(consumer); Thread thread = new Thread(runner); thread.start(); // runner.shutdown(); } }





![rocketMq启动broker报错找不到或无法加载主类 Files\Java\jdk1.8.0_171\lib\dt.jar;C:\Program]](https://img-blog.csdnimg.cn/0961fa78d7b34300a7ec1cc93908d7f7.png)