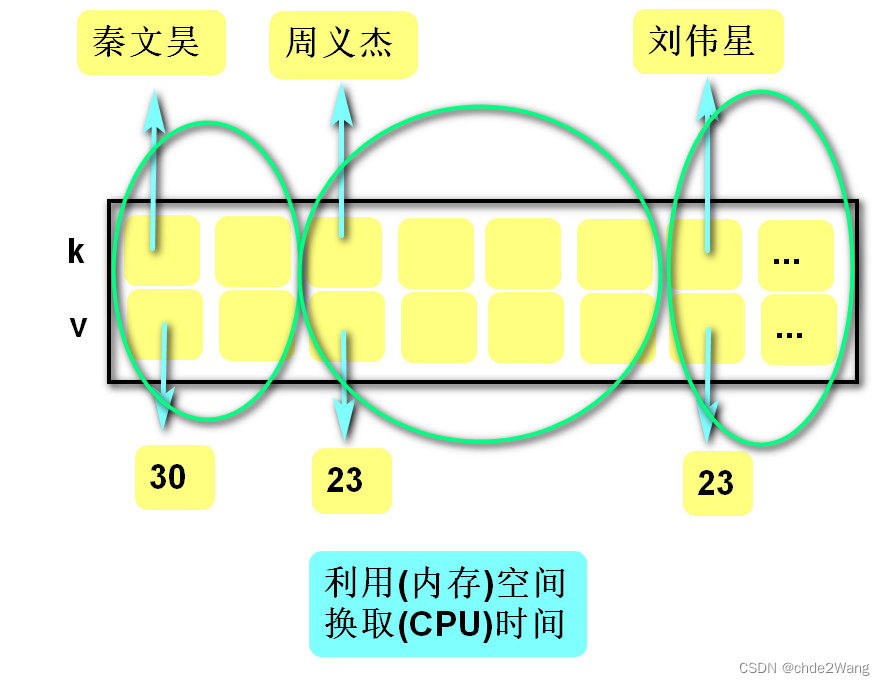
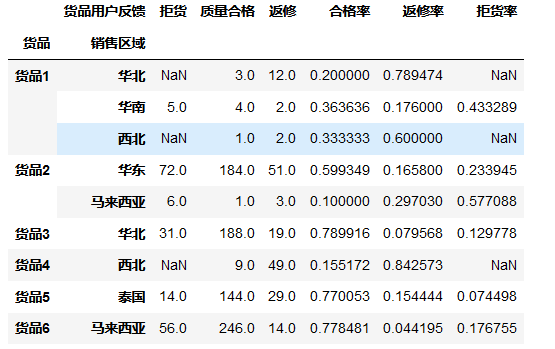
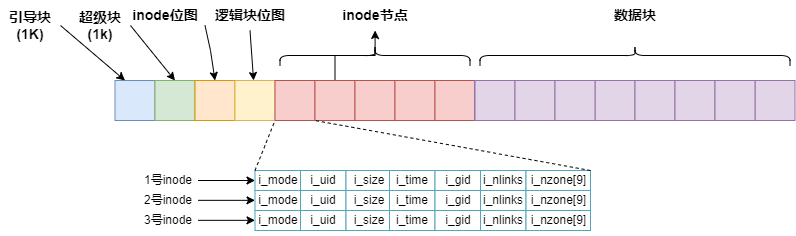
文件系统在磁盘中的体现
下面是磁盘的内容,其中i节点就是一个inode数组,逻辑块就是数据块可用于存放数据
操作系统通过将磁盘数据读入到内存中指定的缓冲区块来与磁盘交互,对内存中的缓冲区块修改后写回磁盘。
进程(task_struct * task[NR_TASKS] = {&(init_task.task), }; )、
系统打开文件表(file file_table[NR_FILE])、
超级块、
inode
等等在linux中都有唯一且有限的全局数组,比如创建新进程或者打开新的文件时就需要在这个数组中找到一个空位(槽)填写相应内容否则不允许进行,因为这些都是系统资源,你可以理解为os只能管理有限的资源
bread(int dev,int block)函数返回一个缓冲区块的头部(用于解释缓冲区,其内部有指针指向具体缓冲区块的地址)的地址,作用是从设备号为dev的设备中读取第block块数据块,缓冲区块和文件系统的块大小一样!
若干个…的扇区作为一个数据块(linux0.11中1个数据块是两个扇区即1MB),若干个数据块作为一个簇,因为随着磁盘容量增大,如果分配空间的单位不增大会导致数据块位图增大从而又浪费了磁盘空间。其中,数据块是逻辑上的,也就是通过软件实现的,具体到读写数据块(即利用汇编提供的读写磁盘中断)时,仍然是以扇区为单位读写
inode的i_count和file的f_count区别
inode的i_count:
file的f_count:
磁盘上的inode表并不会被加载到OS
只有当具体某个文件被读或写时,其inode才会被加载到内存的inode缓存表中,即inode_table[NR_INODE],每个inode元素都被初始化为0了,相当于提前先生成inode对象,使得内存中常驻NR_INODE个inode可被使用,而不必临时new一个,只需要直接初始化空闲inode的每个属性,这会快很多
linux0.11需要手动将脏缓冲区同步到磁盘上
除了少数条件会自动触发自动同步之外,码农需要手动调用sys_sync系统调用使得刚刚写的文件会立刻同步到磁盘上,否则你得等。linux0.11做的仅仅是标记该缓冲区为脏。在2.6版本,linux会专门有个pdflush线程周期性地检查是否有脏缓冲区并且自动同步到磁盘
linux0.11下设备文件的inode->i_zone[0]是设备号,而0.11后用inode->rdev代表设备号
多个空闲缓冲区是资源,共用一个等待队列,当没有空闲缓冲区时,申请空闲缓冲区的进程加入到该等待队列并阻塞,但每个缓冲区自身还有一个等待队列用于互斥,比如这时候突然有一个空闲缓冲区了,那么申请空闲缓冲区的队列中的所有进程都被唤醒,全部(n)去争夺这个新的空闲缓冲区,于是(n-1)都加入到该缓冲区的等待队列
这样设计是可理解的,没有空闲缓冲区的时候,申请该资源的进程没有可以加入的队列(不知道加入到哪个缓冲区),现在专门用一个队列来让他们排队,同时也能阻塞他们了
linux下的五种进程状态
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define TASK_ZOMBIE 3
#define TASK_STOPPED 4
1.TASK_RUNNING:可运行状态,处于该状态的进程可以被调度执行而成为当前进程.
2.TASK_INTERRUPTIBLE:可中断睡眠状态,处于该状态的进程在所需资源有效时被唤醒,也可以通过信号或者定时中断唤醒.
3.TASK_UNINTERRUPTIBLE:不可中断睡眠状态,处于该状态的进程仅当所需资源有效时被唤醒.
4.TASK_ZOMBLE:僵尸状态,表示进程结束且释放资源.但其task_struct仍未释放.
5.TASK_STOPPED:暂停状态.处于该状态的进程通过其他进程的信号才能被唤醒
sched.c
sleep_on(struct task_struct **p)
作用:将当前执行该函数的进程即CURRENT插入到等待队列的队首并阻塞,其中p是等待某个资源的队列的队首的pcb的指针的指针
实现:
- 调用__sleep_on(p,TASK_UNINTERRUPTIBLE);
__sleep_on(struct task_struct **p, int state)
作用:将当前进程插入到等待进程队列的队首指针p(头插),并将队首指针指向当前进程
实现:
- 如果进程0尝试阻塞即if (current == &(init_task.task))则直接报错
- 将当前进程CURRENT插入到等待队列(千万注意!这里的队列其实是栈,只是我们很少说等待栈,反正就是后到的进程先出)的队首p即tmp = *p; *p = current; current->state = state; 这三行代码隐含了一个等待队列(而不是显式),实现十分巧妙,因为当前进程CURRENT执行__sleep_on这种内核函数会专门有自己的内核栈来保存临时变量,因此tmp被保存在CURRENT的内核栈中,于是CURRENT通过tmp能够找到等待队列中的前一个等待进程,此时队首指针p指向当前进程(其中p永远指向队首进程),然后将当前进程状态设置为阻塞态
- 打开中断即汇编sti指令
- 调度其他进程运行即schedule(),这时同样需要该资源的新进程就可以开始执行__sleep_on函数(通常,参考),经历多轮时钟中断和调度后,阻塞事件完成或资源空闲了(会主动调用释放解锁了,比如读写块到缓冲区函数ll_rw_block底层在一开始上锁,当且仅当读写完成才解锁),当等待队列的队首进程被唤醒即wake_up后(唤醒前也是卡在schedule()),继续向下执行,令队首进程的下一个等待进程作为队首即*p = tmp,并且将新的队首进程唤醒即tmp->state=0,依次进行下去,即旧队首唤醒新队首,最后整个等待队列都被唤醒重新一起争夺资源(资源一旦空闲,所有等待进程被唤醒)
wake_up(struct task_struct **p)
作用:将传入的进程p唤醒
实现:
- 将传入的进程p的状态修改为就绪态即(**p).state=0;
super.c
超级块全局数组super_block super_block[NR_SUPER]
 设备号为0==空闲超级块槽
设备号为0==空闲超级块槽
get_super(int dev)
返回值: super_block *
作用:从超级块全局数组中获取设备号对应设备的超级块
实现:遍历超级块全局数组,直到当前被遍历超级块的设备号与dev相等
put_super(int dev)
作用:释放(即清空、初始化)超级块全局数组中设备号所对应设备的超级块
实现:
- 对该超级块上锁
- 该超级块的设备号设置为0(作为空闲超级块槽的依据)
- 释放(brelse)i节点位图和逻辑块位图所占用的缓冲区块
- 解锁该超级块,并唤醒等待超级块全局数组空槽的进程
read_super(int dev)
返回值:super_block *
作用:找到超级块全局数组空槽并从该设备读取超级块到空槽中
实现:
- 遍历超级块全局数组(缓存)查找是否已经有此超级块,有则直接返回
- 遍历超级块全局数组找到dev==0的空槽
- 读取即bh = bread(dev,1)超级块并对超级块上锁
- 初始化空槽
- 释放该缓冲区块
- 根据刚才读取的超级块确定i节点位图和逻辑块位图
- 分别读取两个位图到超级块结构体中的s_imap数组和s_zmap数组(每次读一块并且将缓冲头地址赋给数组当前元素)
- 将i节点位图和逻辑块位图中第一个数据块设置为已被占用(不许用,为了后面方便)
- 解锁超级块
sys_umount(char * dev_name)
返回值:int
作用:根据设备名(即dev_name,准确说是全路径名)卸载指定设备。注意!对于设备文件,其inode的i_zone[0]是设备号
实现:
- 根据dev_name全路径名获取(namei)到该设备的inode
- 判断如果不是块设备则释放(iput)设备inode并返回错误
- 释放设备inode
- 判断如果设备号是根设备的则返回错误
- 判断如果读取超级块(get_super)失败或者设备未挂载(super_block->s_imount==0)则返回错误
- 判断如果挂载的节点的挂载数为0(super_block->s_imount->i_mount==0)则返回错误(你说你挂载在某个inode,但是这个inode根本就没有表明自己被挂载了)
namei(char * pathname)
返回值:inode *
作用:根据全路径名获取到该文件的inode
实现:
set_bit(bitnr,addr)
返回值:register int
作用:返回起始于addr内存段中的第bitnr位的值
实现:
register int __res __asm__("ax");
__asm__("bt %2,%3;setb %%al":
"=a" (__res):"a" (0),
"r" (bitnr),"m" (*(addr)));
__res;
内联汇编的输入。
"a"(0), eax = 0;
"r"(bitnr), 任意空闲寄存器(假设为ebx), ebx=bitnr;
"m"(*(addr)), 内存变量*(addr);
内联汇编语句。
bt %2, %3 -> bt ebx, *addr,
检测*addr的ebx位是否为1, 为1则eflag.CF=1, 否则eflag.CF=0;
setb %%al, al=CF;
内联汇编输出。
__res = eax。
__res作为set_bit(bitnr, addr)宏代表表达式的最终值。*/
mount_root()
作用:开始加载文件系统
实现:
- 初始化全局文件打开表的每个元素的引用数为0(file_table[i].f_count=0,文件每被open一次f_count加1)
- 初始化全局超级块数组
- 读取根设备的超级块(p=read_super(ROOT_DEV))
- 从根设备上读取第ROOT_INO个inode(mi=iget(ROOT_DEV,ROOT_INO),其中ROOT_INO==1即根inode)
- ????(mi->i_count += 3)
- p->s_isup = p->s_imount = mi(分别是当前文件系统的根inode以及挂载点的inode,比如现在有根文件系统,插入u盘后需要挂载到根文件系统中,因此此时u盘的超级块中的s_isup是u盘的根inode,s_imount是位于根文件系统的挂载点的inode)
- 将当前进程的当前工作目录和根目录均设置为根inode(current->pwd = mi;current->root = mi)
- 利用位图统计空闲inode数和空闲数据块数
free=0;
i=p->s_nzones;
/*p->s_nzones是当前文件系统的总数据块数
即图中的蓝色部分。
i是int类型,16位*/
while (-- i >= 0)
if (!set_bit(i&8191,p->s_zmap[i>>13]->b_data))
free++;
/*i是当前数据块的序号,8191的二进制是连续13个1,即i&8191取低13位即求出当前数据块在缓冲区块中的偏移,i>>13即求出当前数据块属于第几个缓冲区块,i>>13的值在0~8之间,因为i是16位*/
printk("%d/%d free blocks\n\r",free,p->s_nzones);
free=0;
i=p->s_ninodes+1;
while (-- i >= 0)
if (!set_bit(i&8191,p->s_imap[i>>13]->b_data))
free++;
printk("%d/%d free inodes\n\r",free,p->s_ninodes);
调用链:init.c->sys_setup->mount_root
inode.c
iget(int dev,int nr)
返回值:inode *
作用:从设备号为dev的设备上读取第nr个inode
实现:
_bmap(struct inode * inode,int block,int create)
返回值:int
作用:根据inode的i_data得到该文件逻辑块号为block的全局物理块号。create=1时,如果逻辑块block还未被分配全局物理块号,则按照分配算法分配给该逻辑块,将该逻辑块映射到物理块。create=0时即使未被分配也不管,直接返回初始值。
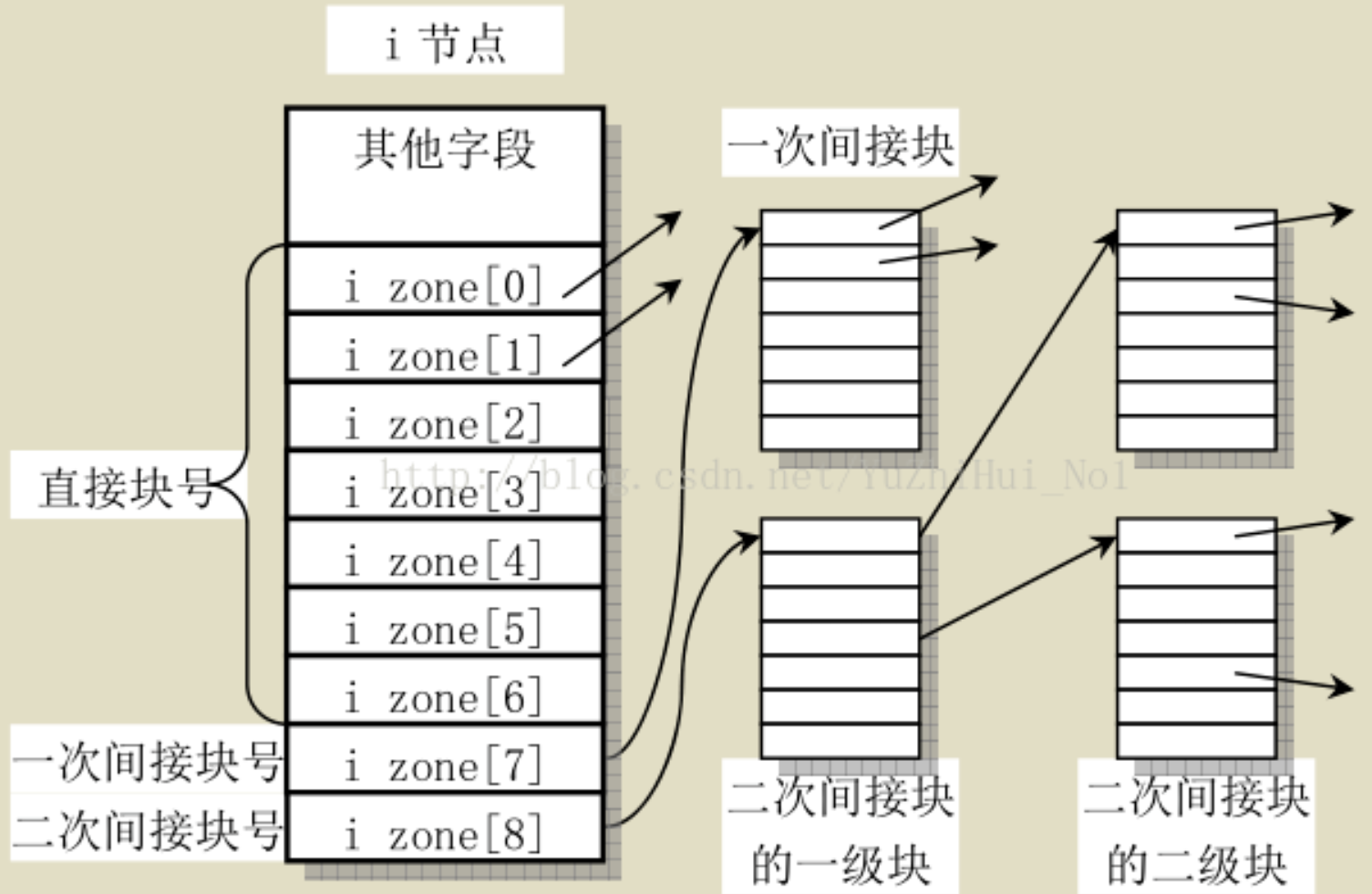
实现:
- 若block在直接寻址的范围内,则直接返回inode->i_data[block]
- 若block在一次寻址的范围内,则先读取一次间址块bh=bread(inode->i_dev,inode->i_data[7]),获取对应全局物理块号i = ((unsigned short *) (bh->b_data))[block];,然后释放缓冲区,最后返回块号i
- 同理若block在二次寻址的范围内,则需要读两次间址块最后返回块号
- 如果create=1且以上过程中发现逻辑块block没有对应的全局物理块号即初始值0(或-1???)则调用minix_new_block(int dev)通过分配算法分配块,然后inode设置为脏
get_empty_inode()
返回值:inode *
作用:从inode缓存表中找到空闲的inode节点并初始化
实现:
- 遍历inode_table,如果当前inode引用计数i_count==0,则符合最低条件(还不是最优),然后继续循环,只有当前inode引用计数i_count==0并且该文件未被修改过即i_dirt以及未被上锁即i_lock,则立即跳出循环,该inode为最优
- 如果找到的空闲inode符合最低条件,但该inode被修改过,则需要先把inode写回磁盘(write_inode(inode)->minix_write_inode(inode)),然后该inode才可以被使用
- 初始化得到的空闲inode即memset(inode,0,sizeof(*inode));
- 将inode引用计数设置为1即inode->i_count = 1;
namei.c—/fs/minix/namei.c
minix_mknod(struct inode * dir, const char * name, int len, int mode, int rdev)
返回值:int
作用:在minix文件系统下创建设备文件。
实现:
- 根据basename在dir中检查该设备文件是否已经存在bh = minix_find_entry(&dir,basename,namelen,&de),已存在则直接返回 文件已存在错误
- 在dir所在设备中找到一个空闲的inode即inode = minix_new_inode(dir->i_dev);,并将inode的idev初始化为所在目录inode的设备号即inode->i_dev = dev;
- 根据传入的mode初始化该inode即inode->i_mode = mode;
- 根据mode判断如果是设备文件(块设备文件或者字符设备文件)则用rdev初始化inode所代表的设备的设备号即inode->i_rdev = rdev;
- 将该inode设为脏即inode->i_dirt = 1;
- 在dir的目录文件中找到空闲目录项并将其目录项名设置name即bh = minix_add_entry(dir,name,len,&de),这里的传入的de被设置为空闲目录项的地址
- 将空闲目录项的inode编号设置为在2所找到的空闲inode即de->inode = inode->i_ino,并将该目录项所在缓冲区设脏即bh->b_dirt = 1;
minix_add_entry(struct inode * dir,const char * name, int namelen, struct minix_dir_entry ** res_dir)
返回值:buffer_head *
作用:在minix文件系统下,只把name加入目录文件dir的目录即minix_dir_entry数组,inode统一被初始化为0
实现:
- 先获取首个(直接索引)逻辑块的物理块号block = dir->i_data[0]
- 读入首个逻辑块即bh = bread(dir->i_dev,block)
- 开始遍历目录文件dir的目录(读入目录文件的内容即minix_dir_entry数组到缓冲区),直到de->inode==0即目录项空闲(如果遍历到最后一个目录项仍不空闲,则选择最后一个目录项的下一个目录项(且修改dir的文件大小和设脏,因为新增了目录项),并且如果目录项的数目刚好占用一个块,则申请一个新的物理块并建立好逻辑块与物理块的映射即block = minix_create_block(dir,i/DIR_ENTRIES_PER_BLOCK),然后读入该新物理块即
bh = bread(dir->i_dev,block)),则把name填入到de->name[]中且缓冲区设脏,minix文件系统对文件名长度进行了限制即MINIX_NAME_LEN=14,如果name的长度超出则截断,没超出则填充0即
for (i=0; i < MINIX_NAME_LEN ; i++)
de->name[i]=(i<namelen)?get_fs_byte(name+i):0; - 将新目录项de(是地址)赋值给res_dir即*res_dir = de;
- 返回空闲目录项所在缓冲区的头部bh
dir_namei(const char * pathname,int * namelen, const char ** name)
返回值:inode *
作用:获取pathname中最底层目录的inode,并且用户传入的name会被赋值为最底层的目录名或者文件名(如/a/b/c得到c)
实现:
- 调用get_dir()获取目录pathname的inode
- 循环遍历pathname,每遇到“/”就令name指向/的下一个字符的地址,最后会得到最底层的目录名(如/a/b/c得到c)
get_dir(const char * pathname)
返回值:inode *
作用:获取目录pathname最底层目录的inode。比如/var/log/httpd,将只返回 log/目录的inode,/var/log/httpd/则返回httpd/的目录
实现:
- 判断pathname第一个字符是否为/,是则代表pathname为绝对路径,令临时变量
inode = current->root,pathname++。否则
inode = current->pwd; - 目录引用数加1即inode->i_count++;
- 依次遍历pathname中的每一个目录,即依次获得两个/之间夹住的目录名,根据该名字thisname和当前父目录的inode有
bh = find_entry(&inode,thisname,namelen,&de)找到该子目录项de即dir_entry类型
释放高速缓冲区bh即brelse()以及inode节点iput()
根据de获得该子目录inode的编号即
inr = de->inode,又根据当前父目录获得设备号idev = inode->i_dev,于是得到该子目录inode即inode = iget(idev,inr),回到3
minix_find_entry(struct inode * dir,const char * name, int namelen, struct minix_dir_entry ** res_dir)
返回值:buffer_head *
作用:根据目录dir的inode找到其下名为name的目录项。其中res_dir存放该目录项,而返回值是该目录项所在高速缓冲区的头部。
实现:
- 根据entries =
(*dir)->i_size / (sizeof (struct minix_dir_entry));得到该目录下目录项的数目 - 先得到第一个逻辑块的对应物理块号
block = (*dir)->i_zone[0] - 读取第一个逻辑块bh = bread((*dir)->i_dev,block)
- 使数据块可以按目录项来遍历de = (struct minix_dir_entry *) bh->b_data;,此时的de是第一个目录项的地址
- 利用目录项的数目entries开始遍历第一个数据块的目录项,如果当前目录项de对应名字和name匹配即minix_match(namelen,name,de),则返回该目录项所在高速缓冲区的头部,以及将de赋值给res_dir。如果不匹配,则de++,并且如果de已经超出当前逻辑块,则根据当前已遍历的目录项数目i求得新的逻辑块号然后根据bmap得到该逻辑块号对应物理块号block = bmap(*dir,i/DIR_ENTRIES_PER_BLOCK),然后读入该物理块并且使数据块可以按目录项来遍历。
namei.c—/fs/namei.c
sys_mknod(const char * filename, int mode, int dev)
返回值:int
作用:可以基于任意文件系统创建设备文件(体现VFS)。与sys_creat(创建普通文件,底层调用的是sys_open)不同在于sys_mknod可以输入设备号参数即dev。
实现:
- 判断是否为超级用户suser(),不是则不执行直接返回
- 获取最底层目录的inode即
dir = dir_namei(filename,&namelen,&basename),
basename被赋值为最底层的目录名或者文件名(比如filename是/dev/usb,则dir是dev/目录的inode,basename是usb) - 判断dir的写权限,无则不执行直接返回
- 判断dir是否有mknod的函数指针即
if (!dir->i_op || !dir->i_op->mknod),无则不执行直接返回 - 调用dir的mknod函数(体现VFS)即dir->i_op->mknod(dir,basename,namelen,mode,dev);(假如磁盘是minix文件系统,那么dir->i_op->mknod就是minix_mknod)
bitmap.c—/fs/minix/bitmap.c
minix_new_block(int dev)
返回值:int
作用:从设备号为dev的设备中找到空闲的数据块并返回该块在整个设备的块号
实现:
- 从dev设备中获取超级块即sb = get_super(dev)
- 通过遍历dev设备的数据块位图,找到空闲的数据块即j=find_first_zero(bh->b_data)然后置为占用(且缓冲区设为脏)
- 获取空闲数据块在整个设备中的全局编号j += i*8192 + sb->s_firstdatazone-1;
- 读入该空闲数据块即bh=getblk(dev,j)
- 将缓冲区的空闲数据块清0即clear_block(bh->b_data),并将缓冲区设为脏
- 返回空闲数据块在整个设备中的全局编号j
minix_new_inode(int dev)
返回值:inode *
作用:在minix文件系统下,在磁盘找到空闲的inode并初始化
实现:
- 从inode缓冲表中获得一个空闲inode即inode=get_empty_inode()
- 根据参数dev即设备号初始化得到的inode的超级块指针即
inode->i_sb = get_super(dev) - 根据刚刚得到的超级块指针可以得到8个inode位图的缓冲区地址(minix文件系统的磁盘的inode位图和数据块位图均占用8个缓冲块即8M),依次遍历这8个缓冲区,对于每个缓冲区遍历每个位 直到找到第一个为0的位即find_first_zero(bh->b_data)相当于找到磁盘中空闲的inode
- 将刚刚在inode位图中找到的空闲位设置为1,即被占用
- 将缓冲区设置为脏使得刚刚在缓冲区的inode位图的空闲位设置为1能写回磁盘即bh->b_dirt = 1;
- 初始化该inode,inode设置为脏,inode的全局编号(即在磁盘的inode数组的第几个)根据3也可以确定下来,其中最重要的是将minix文件系统对inode的操作函数指针赋值给该inode,即inode->i_op = &minix_inode_operations;
inode.c
minix_write_inode(struct inode * inode)
返回值:inode *
作用:将传入的minix文件系统的inode标记为脏
实现:
- 找到传入的inode所在的物理磁盘块(
block =
2 +
inode->i_sb->s_imap_blocks + inode->i_sb->s_zmap_blocks +
(inode->i_ino-1)/
MINIX_INODES_PER_BLOCK;)
并且通过bh=bread(inode->i_dev,block)读入这个块,然后根据bh->data得到该minix_inode即(raw_inode =
((struct minix_inode *)bh->b_data) +
(inode->i_ino-1)%MINIX_INODES_PER_BLOCK;)
这里必须要先把inode所在块读入而不是直接写inode到磁盘,因为内存与磁盘的交互是缓冲块,只有inode这一小部分的内容(还不够一个块的大小)那直接写回就会丧失了其余部分 - 将传入的通用inode中的属性赋值给minix_inode的对应属性(由于raw_inode是bh->b_data的地址,所以raw_inode被赋值的时候缓冲区内容也被修改了)
- 如果传入的inode是设备文件的(块设备文件或者字符设备文件),则只需要赋值首个块号即raw_inode->i_zone[0] = inode->i_rdev;(inode有i_dev和i_rdev,对于普通文件的i_dev表明该文件所在磁盘的设备号,对于设备文件的i_rdev表明该设备的设备号)。否则(普通文件的inode)需要赋值每个索引块指明文件所在物理块的位置。
- 将缓冲区设置为脏即bh->b_dirt=1(原因如第2点),将inode设置为未修改即inode->i_dirt=0(因为已经为该inode修改完成)
minix_create_block(struct inode * inode, int block)
返回值:int
作用:在inode中获取第block个逻辑块的物理块,如果发现该逻辑块还没有被分配物理块,则通过遍历数据块位图找到空闲的物理块分配给该逻辑块
实现:
- 调用_bmap(inode,block,1);
buffer.c
wait_on_buffer(struct buffer_head * bh)
作用:令当前进程等待缓冲区资源。如果缓冲区无人占用则无需等待,否则将当前进程加入到该资源的等待队列并阻塞
实现:
- 关中断,确保执行2的时候只有一个进程访问资源的锁,否则一旦锁空闲,所有进程都不阻塞了
- 循环判断资源是否被上锁占用了,是则将当前进程加入到该资源的等待队列并阻塞即
while (bh->b_lock) sleep_on(&bh->b_wait); - 开中断
bread(int dev,int block)
返回值:buffer_head *
作用:
实现:
1.
2.
BADNESS宏定义
定义:BADNESS(bh) (((bh)->b_dirt<<1)+(bh)->b_lock)
返回值:char(但是数字)
作用:分配空闲缓冲区时衡量缓冲区的好坏(空闲)程度。同样没上锁的两个缓冲区,被修改过的那个是更坏的缓冲区(2)。同样没被修改过的两个缓冲区,上锁的那个是更坏的缓冲区(1)。既被上锁还被修改过则是最坏的缓冲区(3),既没被上锁也没被修改过则是最好的缓冲区(0)(b_dirt和b_lock的值只会为0或1)。
getblk(int dev,int block)
返回值:buffer_head *
作用:返回装有设备号为dev的设备中块号为block的内容的缓冲区
实现:
- 通过哈希值看指定块是否已存在即
bh = get_hash_table(dev,block),bh是最终要返回的缓冲区 - 循环遍历空闲缓冲区链表(双向链表)free_list,如果当前缓冲区的被引用数b_count>0,则说明缓冲区正在被使用(???那为什么还把它放进空闲缓冲区链表???),看下一个空闲缓冲区。如果当前缓冲区空闲且在此之前未找到空闲缓冲区即bh==NULL,或者当前缓冲区比已找到的空闲缓冲区bh好(BADNESS(tmp)<BADNESS(bh)),则令当前缓冲区作为已找到的空闲缓冲区即bh = tmp,如果当前缓冲区不仅比已找到的空闲缓冲区bh好而且是完全空闲即BADNESS(tmp)==0,则直接退出循环,否则一直遍历到表尾
- 如果遍历完后bh仍为空,说明没有空闲缓冲区或者所有缓冲区的引用数都>0,则当前进程阻塞等待即加入到空闲缓冲区资源的等待队列的队首sleep_on(&buffer_wait),直到被唤醒(有空闲缓冲区了),则再次回到2执行(goto语句)
- 到了这里说明已经找到空闲缓冲区了即bh!=NULL,
read_write.c
sys_write(unsigned int fd,char * buf,unsigned int count)
返回值:int
作用:
实现:
1.
2.
end
返回值:
作用:
实现:
1.
2.
结构体
struct inode_operations minix_inode_operations = {
minix_create,
minix_lookup,
minix_link,
minix_unlink,
minix_symlink,
minix_mkdir,
minix_rmdir,
minix_mknod,
minix_rename,
minix_readlink,
minix_open,
minix_release,
minix_follow_link
};
struct dir_entry {
unsigned short inode; //inode节点的编号
char name[NAME_LEN]; //文件名
};
struct buffer_head {
char * b_data; /* pointer to data block (1024 bytes) */
unsigned long b_blocknr; /* block number */
unsigned short b_dev; /* device (0 = free) */
unsigned char b_uptodate;
unsigned char b_dirt; /* 0-clean,1-dirty */
unsigned char b_count; /* users using this block */
unsigned char b_lock; /* 0 - ok, 1 -locked */
struct task_struct * b_wait;
struct buffer_head * b_prev;
struct buffer_head * b_next;
struct buffer_head * b_prev_free;
struct buffer_head * b_next_free;
};
struct inode {
dev_t i_dev;
ino_t i_ino;//在磁盘中的inode表排第几个
umode_t i_mode;
/*i_mode一共10位,第一位表明结点文件类型,后9位依次为:
i结点所有者、所属组成员、其他成员的权限
(权限有读写执行三种)*/
nlink_t i_nlink;
uid_t i_uid;
gid_t i_gid;
dev_t i_rdev;
off_t i_size;//文件大小(字节数)
time_t i_atime;
time_t i_mtime;
time_t i_ctime;
unsigned long i_data[16];
struct inode_operations * i_op;
struct super_block * i_sb;
struct task_struct * i_wait;
struct task_struct * i_wait2; /* for pipes */
unsigned short i_count;//i节点被使用的次数
unsigned char i_lock;
unsigned char i_dirt;
unsigned char i_pipe;
unsigned char i_mount;
unsigned char i_seek;
unsigned char i_update;
};
struct file {
unsigned short f_mode;
unsigned short f_flags;
unsigned short f_count;
struct inode * f_inode;
struct file_operations * f_op;
off_t f_pos;
};
struct super_block {
unsigned short s_ninodes;
unsigned short s_nzones;
unsigned short s_imap_blocks;
unsigned short s_zmap_blocks;
unsigned short s_firstdatazone;
unsigned short s_log_zone_size;
unsigned long s_max_size;
unsigned short s_magic;
/* These are only in memory */
struct buffer_head * s_imap[8];
struct buffer_head * s_zmap[8];
unsigned short s_dev;
struct inode * s_covered;
struct inode * s_mounted;
unsigned long s_time;
struct task_struct * s_wait;
unsigned char s_lock;
unsigned char s_rd_only;
unsigned char s_dirt;
};
struct file_operations {
int (*lseek) (struct inode *, struct file *, off_t, int);
int (*read) (struct inode *, struct file *, char *, int);
int (*write) (struct inode *, struct file *, char *, int);
};
struct inode_operations {
int (*create) (struct inode *,const char *,int,int,struct inode **);
int (*lookup) (struct inode *,const char *,int,struct inode **);
int (*link) (struct inode *,struct inode *,const char *,int);
int (*unlink) (struct inode *,const char *,int);
int (*symlink) (struct inode *,const char *,int,const char *);
int (*mkdir) (struct inode *,const char *,int,int);
int (*rmdir) (struct inode *,const char *,int);
int (*mknod) (struct inode *,const char *,int,int,int);
int (*rename) (struct inode *,const char *,int,struct inode *,const char *,int);
int (*readlink) (struct inode *,char *,int);
int (*open) (struct inode *, struct file *);
void (*release) (struct inode *, struct file *);
struct inode * (*follow_link) (struct inode *, struct inode *);
};
struct minix_inode {
unsigned short i_mode;
unsigned short i_uid;
unsigned long i_size;
unsigned long i_time;
unsigned char i_gid;
unsigned char i_nlinks;
unsigned short i_zone[9];
};
struct minix_super_block {
unsigned short s_ninodes;
unsigned short s_nzones;
unsigned short s_imap_blocks;
unsigned short s_zmap_blocks;
unsigned short s_firstdatazone;
unsigned short s_log_zone_size;
unsigned long s_max_size;
unsigned short s_magic;
};
struct minix_dir_entry {
unsigned short inode;
char name[MINIX_NAME_LEN];
};