StarGAN v2: Diverse Image Synthesis for Multiple Domainsp
github:https://github.com/clovaai/stargan-v2
1 模型架构
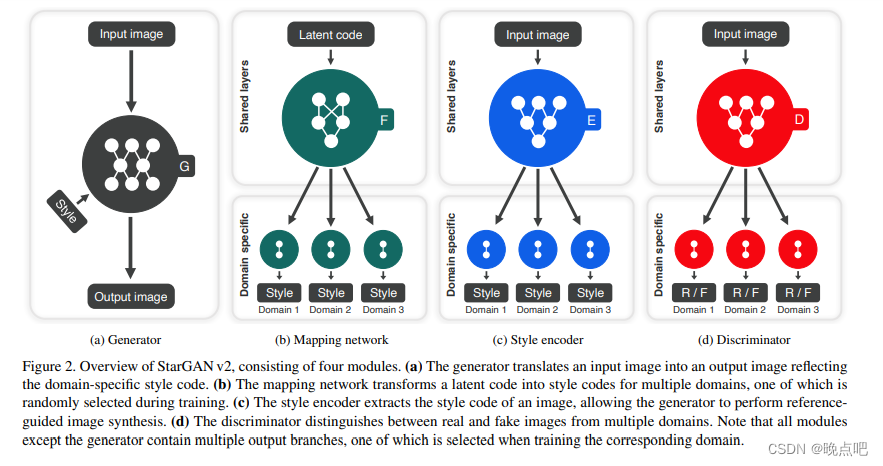
模型主要架构由四部分组成
①Generator、②Mapping network、③Style encoder、④Discriminator
-
Generator:G网络
生成模型G将输入图片x转换成 输出图片G(x,s),反映了一个领域的独有风格编码s。s是有Maping network F或者风格编码E生成。s被设计表征为领域y的风格。 -
Mapping network: F网络
给定一个隐变量z和一个领域y,mapping network F生成一个风格 s=F(z),F由一层MLP和多个输出分支组成,分支代表了领域的所有风格。通过随机采样不同的隐变量z,F能高效的学习各领域的风格表征。 -
Style encoder:E网络
给定图片X和相应的领域y,encoder E挖掘风格编码 s=E(x),E和上面的F类似。使用不同的参考图片,E可以产生不同风格的编码s。 -
Discriminator:D网络
判别器D是多任务判别器,由多个输出分支组成,每个分支Dy学习一个二分类,判断图片X是否是真实的y领域,或者由G生成的假图 G(x,s).
2 训练目标
2.1Adversarial objective.
对抗损失:
训练期间,随机采样隐变量z和领域y,通过F函数,生成风格编码s ,
风格编码:
s
ˉ
=
F
y
ˉ
(
z
)
风格编码: \bar s=F_{\bar y}(z)
风格编码:sˉ=Fyˉ(z)
生成网络G,将图片X和上面的风格编码S作为输入,生成图片:
生成图片:
G
(
x
,
s
ˉ
)
生成图片: G(x,\bar s)
生成图片:G(x,sˉ)
对抗损失函数为:
L
a
d
v
=
E
x
,
y
[
l
o
g
D
y
(
x
)
]
+
E
x
,
y
ˉ
,
z
[
l
o
g
(
1
−
D
y
ˉ
(
G
(
x
,
s
ˉ
)
)
)
]
(
1
)
L_{adv}=E_{x,y}[logD_y(x)]+E_{x,\bar y,z}[log(1-D_{\bar y}(G(x,\bar s)))] \qquad (1)
Ladv=Ex,y[logDy(x)]+Ex,yˉ,z[log(1−Dyˉ(G(x,sˉ)))](1)
D_y:是y领域的判别器
F: 是提供y领域的风格编码s
G:输入图片和风格编码s,生成新图片
2.2 Style reconstruction
风格重构损失
使得前后的风格距离最小
L
s
t
y
=
E
x
,
y
ˉ
,
z
[
∣
∣
s
ˉ
−
E
y
ˉ
(
G
(
x
,
s
ˉ
)
)
∣
∣
1
]
(
2
)
L_{sty}=E_{x,\bar y ,z}[||\bar s-E_{\bar y}(G(x,\bar s))||_1] \qquad (2)
Lsty=Ex,yˉ,z[∣∣sˉ−Eyˉ(G(x,sˉ))∣∣1](2)
E网络用来生成风格,上面有提到
(前面的E是求均值,后面的
E
y
ˉ
E_{\bar y}
Eyˉ是网络)
2.3 Style diversification
为了使生成器G产生更多风格图片,使得不同风格图片的距离尽可能大
L d s = E x , y ˉ , z 1 , z 2 [ ∣ ∣ G ( x , s ˉ 1 ) − G ( x , s ˉ 2 ) ∣ ∣ 1 ] ( 3 ) L_{ds}=E_{x,\bar y,z_1,z_2}[||G(x,\bar s_1)-G(x,\bar s_2)||_1]\qquad (3) Lds=Ex,yˉ,z1,z2[∣∣G(x,sˉ1)−G(x,sˉ2)∣∣1](3)
s ˉ 1 和 s ˉ 2 \bar s_1和\bar s_2 sˉ1和sˉ2是F在隐变量 z 1 和 z 2 条件下生成的 s ˉ i = F y ˉ ( z i ) f o r i ∈ 1 , 2 z_1和z_2条件下生成的 \bar s_i =F_{\bar y}(z_i) \quad for \quad i \in {1,2} z1和z2条件下生成的sˉi=Fyˉ(zi)fori∈1,2
2.4 cycle consistency loss
循环一致损失
使得经过变换后的X与之前的X距离最小
L
c
y
c
=
E
x
,
y
,
y
ˉ
,
z
[
∣
∣
x
−
G
(
G
(
x
,
s
ˉ
)
,
s
^
)
∣
∣
1
]
(
4
)
L_{cyc}=E_{x,y,\bar y,z}[||x-G(G(x,\bar s),\hat s)||_1] \qquad (4)
Lcyc=Ex,y,yˉ,z[∣∣x−G(G(x,sˉ),s^)∣∣1](4)
s ^ = E y ( x ) \hat s=E_y(x) s^=Ey(x)是E网络估计的风格code,y是原始的X的领域,使生成器G学会去保留原始的X的特征
2.5 full objective
将上面的损失函数求和,其中DS是最大化距离(所有用减号),其他是最小化
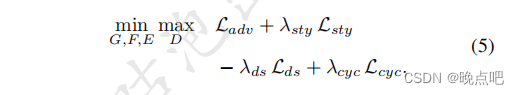


![新型智慧城市整体规划建设方案[67页PPT]](https://img-blog.csdnimg.cn/img_convert/b2bf82d46c13efd0567dbf35632cc807.jpeg)