机器学习
机器学习是人工智能的一个分支,它研究计算机如何通过自身的学习和经验来提高其性能,而不需要明确的被编程。机器学习算法可以从大量的数据中学习,并能根据这些数据做出预测或分类。机器学习目前已经被广泛应用于许多领域,包括自然语言处理、计算机视觉、图像识别、语音识别、金融分析、医疗诊断等。
机器学习算法有很多种,其中最常见的包括:
- 监督学习:监督学习算法从带有标签的数据中学习,并能够对新数据进行分类或预测。常见的监督学习算法包括决策树、支持向量机、逻辑回归、K近邻、神经网络等。
- 无监督学习:无监督学习算法从未标记的数据中学习,并能够发现数据中的模式。常见的无监督学习算法包括聚类、降维、异常检测等。
- 半监督学习:半监督学习算法从部分标记的数据中学习,并能够对新数据进行分类或预测。
- 强化学习:强化学习算法通过与环境的互动学习,并能够在环境中做出最佳决策。常见的强化学习算法包括Q-学习、SARSA等。
机器学习算法是一个庞大的体系,每种算法都有自己的优缺点。选择合适的算法需要考虑数据的特点、任务的类型、计算资源等因素。
机器学习是一个非常热门的研究领域,它正在不断发展。随着计算能力的提高和数据量的增加,机器学习将在未来发挥越来越重要的作用。


机器学习算法示例
1. 监督学习
1.1. 决策树
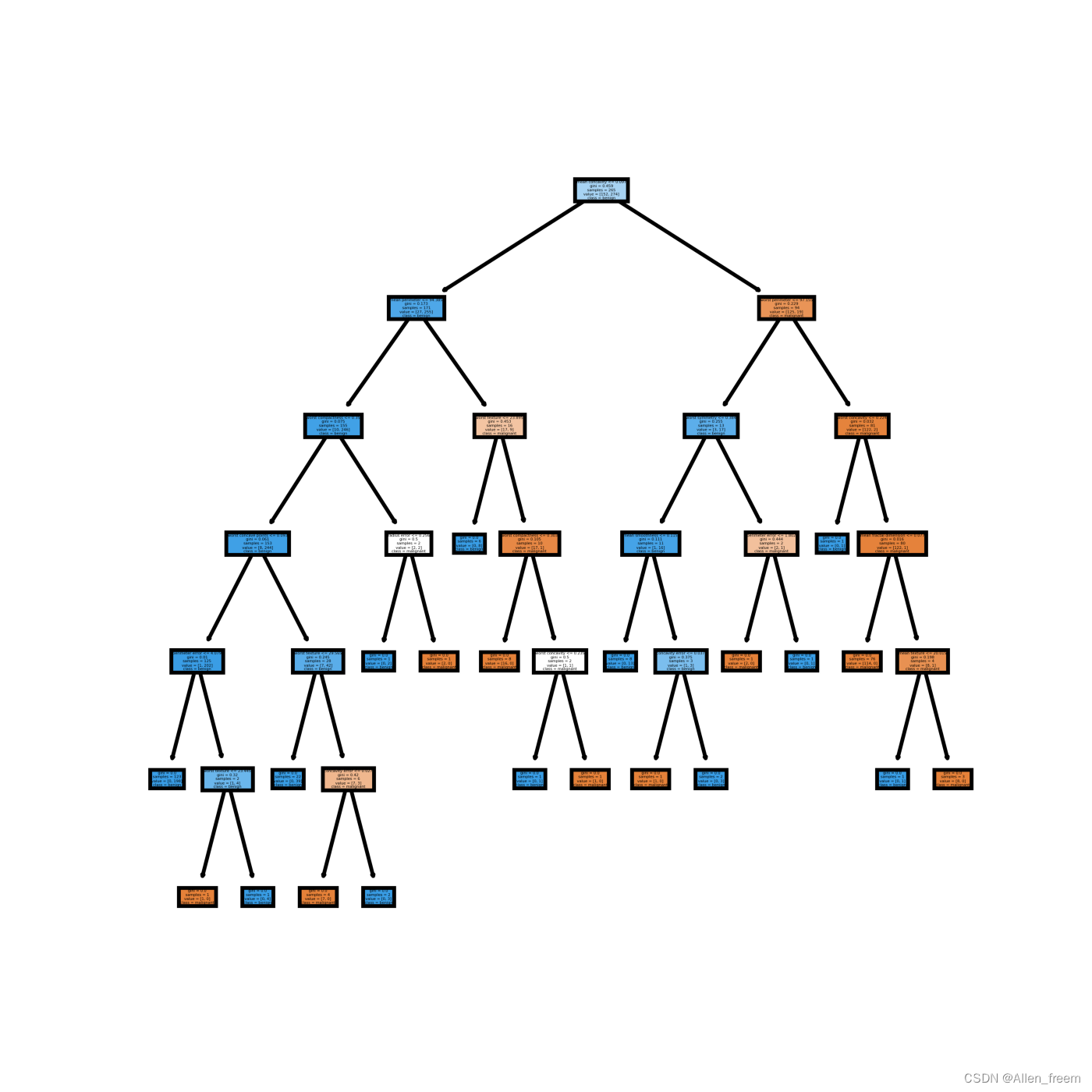
import numpy as np
from sklearn.tree import DecisionTreeClassifier
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
X = data[:, :-1]
y = data[:, -1]
# 构建决策树模型
clf = DecisionTreeClassifier()
clf.fit(X, y)
# 预测新数据
predictions = clf.predict(X)
# 评估模型性能
accuracy = np.mean(predictions == y)
print("Accuracy:", accuracy)
该代码将加载名为“data.csv”的数据集,该数据集包含两个特征和一个目标变量。然后,它将构建一个决策树模型并对数据集进行训练。最后,它将使用模型对新数据进行预测并评估模型性能。
该代码输出的准确性值将是模型对新数据的预测准确性的估计。
1.2. 支持向量机
import numpy as np
from sklearn.svm import SVC
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
X = data[:, :-1]
y = data[:, -1]
# 构建支持向量机模型
clf = SVC(C=1.0, kernel='rbf', gamma=0.1)
clf.fit(X, y)
# 预测新数据
predictions = clf.predict(X)
# 评估模型性能
accuracy = np.mean(predictions == y)
print("Accuracy:", accuracy)
该代码将加载名为“data.csv”的数据集,该数据集包含两个特征和一个目标变量。然后,它将构建一个支持向量机模型并对数据集进行训练。最后,它将使用模型对新数据进行预测并评估模型性能。
该代码输出的准确性值将是模型对新数据的预测准确性的估计。
以下是关于支持向量机的一些说明:
- C 是一个超参数,控制模型的复杂度。较高的 C 值会导致更复杂的模型,而较低的 C 值会导致更简单的模型。
- 核函数是支持向量机使用的函数,它将特征空间映射到高维空间。高斯核函数是最常用的核函数。
- 伽玛是一个超参数,控制核函数的平滑度。较高的伽玛值会导致更平滑的核函数,而较低的伽玛值会导致更不平滑的核函数。
1.3. 逻辑回归
import numpy as np
from sklearn.linear_model import LogisticRegression
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
X = data[:, :-1]
y = data[:, -1]
# 构建逻辑回归模型
clf = LogisticRegression()
clf.fit(X, y)
# 预测新数据
predictions = clf.predict(X)
# 评估模型性能
accuracy = np.mean(predictions == y)
print("Accuracy:", accuracy)该代码将加载名为“data.csv”的数据集,该数据集包含两个特征和一个目标变量。然后,它将构建一个逻辑回归模型并对数据集进行训练。最后,它将使用模型对新数据进行预测并评估模型性能。
该代码输出的准确性值将是模型对新数据的预测准确性的估计。
以下是关于逻辑回归的一些说明:
- 逻辑回归是一种分类模型,它使用线性回归来预测类的概率。
- 逻辑回归的目标是找到一组参数,使得模型能够准确地预测类的概率。
- 逻辑回归可以使用梯度下降法或牛顿法等方法进行训练。
- 逻辑回归可以用于分类许多不同的任务,包括:
- 文本分类
- 图像分类
- 生物信息学
- 金融分析
1.4. K近邻
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
X = data[:, :-1]
y = data[:, -1]
# 构建K近邻模型
clf = KNeighborsClassifier(n_neighbors=5)
clf.fit(X, y)
# 预测新数据
predictions = clf.predict(X)
# 评估模型性能
accuracy = np.mean(predictions == y)
print("Accuracy:", accuracy)
该代码将加载名为“data.csv”的数据集,该数据集包含两个特征和一个目标变量。然后,它将构建一个K近邻模型并对数据集进行训练。最后,它将使用模型对新数据进行预测并评估模型性能。
该代码输出的准确性值将是模型对新数据的预测准确性的估计。
以下是关于K近邻的一些说明:
- K近邻是一种非参数分类模型,它根据距离来预测类别。
- K近邻的目标是找到k个最邻近的训练样本,并根据这k个样本的类别来预测新样本的类别。
- K近邻可以使用欧氏距离、曼哈顿距离或闵可夫斯基距离等距离度量来计算距离。
- K近邻可以用于分类许多不同的任务,包括:
- 文本分类
- 图像分类
- 生物信息学
- 金融分析
1.5. 神经网络
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
# 加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
y_train = y_train.astype('int32')
y_test = y_test.astype('int32')
# 构建模型
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(784,)))
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10)
# 评估模型
score = model.evaluate(x_test, y_test)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
该代码将加载MNIST数据集,并构建一个具有两个隐藏层的神经网络。然后,它将使用训练数据训练模型,并使用测试数据评估模型性能。
2. 无监督学习
无监督学习有许多常用的算法,包括:
- 聚类:聚类算法将数据点分组到类中,以便数据点在同一组中具有相似的属性,而数据点在不同组中具有不同的属性。常见的聚类算法包括k-means聚类、密度聚类和层次聚类。
- 降维:降维算法将高维数据降维到低维空间,以便在低维空间中更容易可视化和分析数据。常见的降维算法包括主成分分析(PCA)、线性判别分析(LDA)和t-SNE。
- 异常检测:异常检测算法可以识别数据集中的异常数据点。异常数据点可能表示数据中的错误或噪声,或者它们可能表示新的数据模式。常见的异常检测算法包括离群点检测和异常值检测。
- 度量学习:度量学习算法可以学习两个数据点之间的距离或相似度。度量学习算法可用于许多不同的任务,包括聚类、降维和异常检测。
这些只是无监督学习的一些常用算法。根据具体的任务,可以选择合适的算法来解决问题。
2.1. K-means聚类
import numpy as np
from sklearn.cluster import KMeans
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 构建k-means聚类器
kmeans = KMeans(n_clusters=3)
# 训练k-means聚类器
kmeans.fit(data)
# 获取聚类标签
labels = kmeans.labels_
# 显示聚类结果
plt.scatter(data[:, 0], data[:, 1], c=labels)
plt.show()
- k-means聚类是一种基于均值的聚类算法,它将数据点分为k个类,使得每个类的均值最小。
- k-means聚类是聚类算法中最简单、最常用的算法之一。
- k-means聚类的缺点是它需要预先知道聚类的数量。
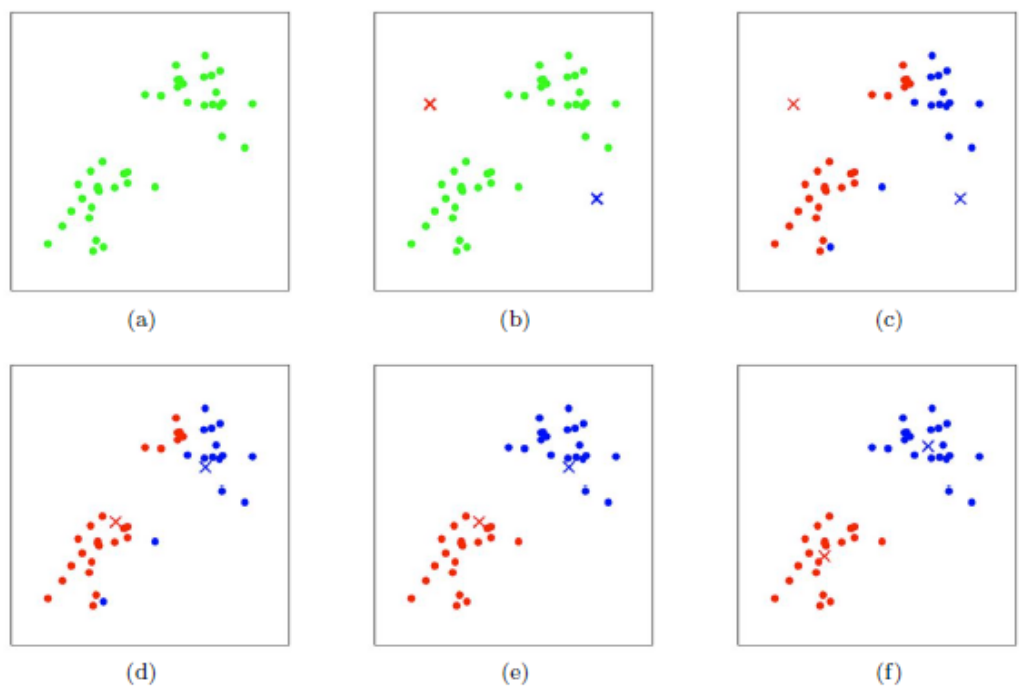
2.2. 密度聚类
import numpy as np
from sklearn.cluster import DBSCAN
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 构建DBSCAN聚类器
dbscan = DBSCAN(eps=0.5, min_samples=10)
# 训练DBSCAN聚类器
dbscan.fit(data)
# 获取聚类标签
labels = dbscan.labels_
# 显示聚类结果
plt.scatter(data[:, 0], data[:, 1], c=labels)
plt.show()
- 密度聚类是一种基于密度的聚类算法,它将数据点分为密度高的集合,称为簇。
- 密度聚类可以处理非凸的簇,而k-means聚类只能处理凸的簇。
- 密度聚类的缺点是它需要指定一个参数,该参数控制簇的密度。
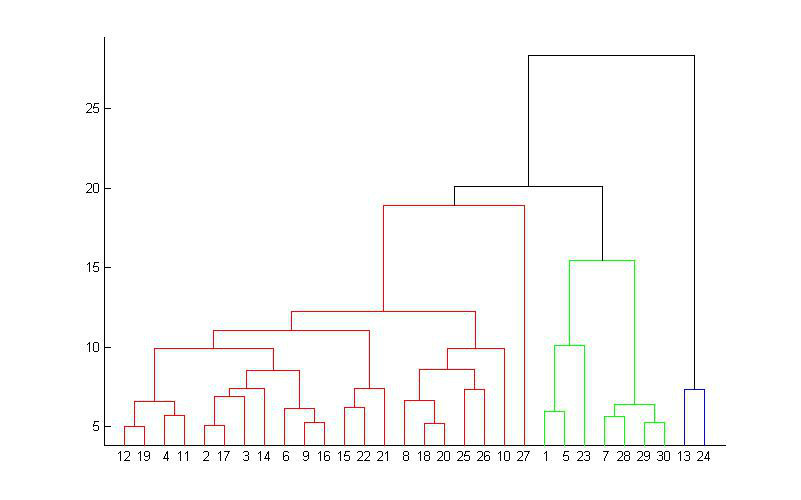
2.3. 层次聚类
import numpy as np
from scipy.cluster.hierarchy import dendrogram, linkage
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 计算层次聚类
Z = linkage(data, method='ward')
# 绘制层次聚类图
dendrogram(Z)
plt.show()
- 层次聚类是一种将数据点分层的聚类算法。
- 层次聚类可以用于确定数据点的聚类结构。
- 层次聚类的缺点是它不能像k-means聚类或密度聚类那样精确地分割数据点。
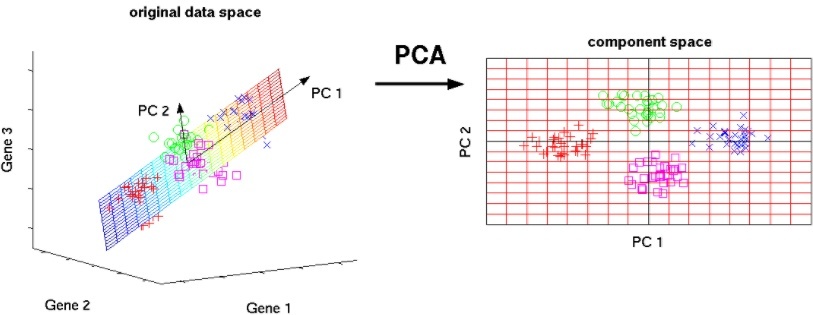
2.4. 主成分分析(PCA)
import numpy as np
from sklearn.decomposition import PCA
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 构建PCA模型
pca = PCA(n_components=2)
# 训练PCA模型
pca.fit(data)
# 降维
reduced_data = pca.transform(data)
# 可视化降维后的数据
plt.scatter(reduced_data[:, 0], reduced_data[:, 1])
plt.show()
- PCA
- PCA是一种无监督学习算法,它将高维数据降维到低维空间,以便在低维空间中更容易可视化和分析数据。
- PCA是基于数据的方差来选择主成分的,因此它可以很好地捕捉数据中的总体趋势。
- PCA不能很好地处理非线性数据。
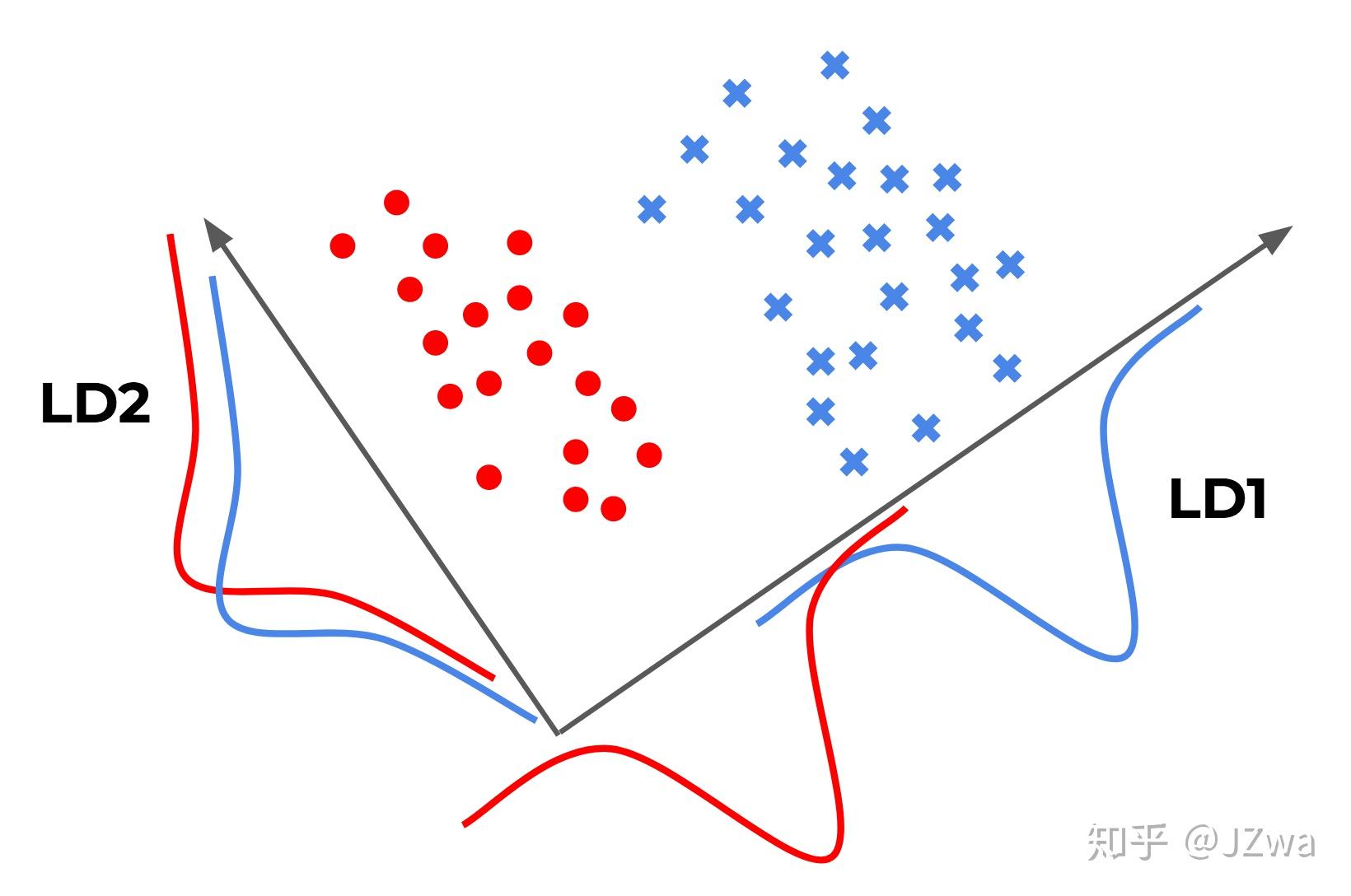
2.5. 线性判别分析(LDA)
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 构建LDA模型
lda = LinearDiscriminantAnalysis(n_components=2)
# 训练LDA模型
lda.fit(data, data[:, -1])
# 降维
reduced_data = lda.transform(data)
# 可视化降维后的数据
plt.scatter(reduced_data[:, 0], reduced_data[:, 1], c=data[:, -1])
plt.show()
- LDA
- LDA是一种监督学习算法,它将高维数据降维到低维空间,以便在低维空间中更好地分离不同的类别。
- LDA是基于数据的分布来选择主成分的,因此它可以很好地捕捉不同类别之间的差异。
- LDA不能很好地处理高维数据。
2.6. t-SNE
import numpy as np
from sklearn.manifold import TSNE
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 构建t-SNE模型
tsne = TSNE(n_components=2)
# 训练t-SNE模型
tsne_data = tsne.fit_transform(data)
# 可视化降维后的数据
plt.scatter(tsne_data[:, 0], tsne_data[:, 1])
plt.show()
- t-SNE
- t-SNE是一种非线性降维算法,它将高维数据降维到低维空间,以便在低维空间中更好地保留数据的局部结构。
- t-SNE是一个非常灵活的降维算法,可以很好地处理非线性数据。
- t-SNE是一个计算密集型的算法,可能需要很长时间才能运行。
2.7. 离群点检测
import numpy as np
from scipy.stats import zscore
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 计算离群点
zscores = zscore(data)
# 定义离群点阈值
threshold = 3
# 识别离群点
outliers = np.where(zscores > threshold)[0]
# 打印离群点
print(outliers)
2.8. 异常值检测
import numpy as np
from scipy.stats import iqr
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 计算四分位距
Q1 = np.percentile(data, 25)
Q3 = np.percentile(data, 75)
# 计算异常值阈值
threshold = 1.5 * (Q3 - Q1)
# 识别异常值
outliers = np.where(data > Q3 + threshold)
# 打印异常值
print(outliers)
- 异常值
- 异常值是指与大多数数据点非常不同的数据点。
- 异常值可能由数据中的错误或噪声引起,也可能表示新的数据模式。
- 异常值的检测可以帮助我们识别数据中的错误或噪声,并更好地理解数据中的模式。
- 离群点
- 离群点是指与大多数数据点非常不同的数据点,但不一定是错误或噪声。
- 离群点可能表示新的数据模式,或可能由数据中的异常情况引起。
- 离群点的检测可以帮助我们发现新的数据模式,并更好地理解数据中的异常情况。
在进行异常值检测或离群点检测时,需要注意以下几点:
- 选择合适的检测方法。不同的检测方法有不同的优点和缺点,因此需要选择合适的方法来检测数据中的异常值或离群点。
- 设置合适的阈值。阈值是用于确定异常值或离群点的值。阈值的设置需要根据数据的特点来确定。
- 使用多种检测方法。使用多种检测方法可以提高检测异常值或离群点的准确性。
- 由专家进行验证。在检测出异常值或离群点后,需要由专家进行验证,以确定是否真的是异常值或离群点。
3. 半监督学习
半监督学习有很多常用的算法,包括:
- 自训练:自训练算法是将标记数据的一部分用于训练模型,然后将未标记数据与模型预测的标签一起用于训练模型。
- 半监督支持向量机:半监督支持向量机(S3VM)算法是将支持向量机(SVM)与半监督学习结合起来的算法。S3VM算法可以利用少量的标记数据和大量的未标记数据来训练模型。
- 扩展的K-均值算法:扩展的K-均值算法(EK-means)是将K-均值算法与半监督学习结合起来的算法。EK-means算法可以利用少量的标记数据和大量的未标记数据来训练模型,并且可以处理非凸的聚类。
- 密度聚类:密度聚类算法是将未标记数据的密度作为聚类的依据。密度聚类算法可以处理非凸的聚类。
半监督学习是一种非常有效的学习方法,可以利用少量的标记数据和大量的未标记数据来训练模型。半监督学习在自然语言处理、计算机视觉和医疗诊断等领域得到了广泛的应用。
3.1. 自训练
自训练是一种半监督学习算法,它首先从标记数据中学习一个模型,然后将未标记数据与模型预测的标签一起用于训练模型。自训练可以有效地利用少量的标记数据和大量的未标记数据来训练模型。
import numpy as np
from sklearn.linear_model import LogisticRegression
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(data[:, :-1], data[:, -1], test_size=0.33)
# 训练模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 预测标签
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
3.2. 半监督支持向量机
半监督支持向量机(S3VM)是一种半监督学习算法,它将支持向量机(SVM)与半监督学习结合起来。S3VM可以利用少量的标记数据和大量的未标记数据来训练模型。
import numpy as np
from sklearn.svm import SVC
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(data[:, :-1], data[:, -1], test_size=0.33)
# 训练模型
model = SVC(kernel="linear", C=1.0)
model.fit(X_train, y_train)
# 预测标签
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
3.3. 扩展的K-均值算法
扩展的K-均值算法(EK-means)是一种半监督学习算法,它将K-均值算法与半监督学习结合起来。EK-means可以利用少量的标记数据和大量的未标记数据来训练模型,并且可以处理非凸的聚类。
import numpy as np
from sklearn.cluster import KMeans
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 训练模型
model = KMeans(n_clusters=3)
model.fit(data)
# 获取聚类标签
labels = model.labels_
# 可视化聚类结果
plt.scatter(data[:, 0], data[:, 1], c=labels)
plt.show()
3.4. 密度聚类
密度聚类是一种半监督学习算法,它将未标记数据的密度作为聚类的依据。密度聚类可以处理非凸的聚类。

import numpy as np
from sklearn.cluster import DBSCAN
# 加载数据
data = np.loadtxt("data.csv", delimiter=",")
# 训练模型
model = DBSCAN(eps=0.5, min_samples=10)
model.fit(data)
# 获取聚类标签
labels = model.labels_
# 可视化聚类结果
plt.scatter(data[:, 0], data[:, 1], c=labels)
plt.show()
4. 强化学习
4.1. Q-学习
import numpy as np
from collections import deque
class QLearner(object):
def __init__(self, num_states, num_actions, learning_rate=0.01, discount_factor=0.99):
self.num_states = num_states
self.num_actions = num_actions
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.Q = np.zeros((num_states, num_actions))
self.replay_memory = deque(maxlen=1000)
def get_action(self, state):
# 随机选取动作
action = np.random.choice(self.num_actions)
# 贪婪选择动作
# action = np.argmax(self.Q[state, :])
return action
def learn(self, state, action, reward, next_state):
# 更新Q值
self.Q[state, action] = self.Q[state, action] + self.learning_rate * (reward + self.discount_factor * np.max(self.Q[next_state, :]) - self.Q[state, action])
def add_to_memory(self, state, action, reward, next_state):
self.replay_memory.append((state, action, reward, next_state))
def replay(self):
# 随机采样一个批次的记忆
batch_size = 32
mini_batch = np.random.choice(self.replay_memory, batch_size)
# 更新Q值
for state, action, reward, next_state in mini_batch:
self.learn(state, action, reward, next_state)
def train(self, num_episodes, env):
for episode in range(num_episodes):
state = env.reset()
done = False
while not done:
action = self.get_action(state)
next_state, reward, done, _ = env.step(action)
self.add_to_memory(state, action, reward, next_state)
self.replay()
state = next_state
Q-学习是一种强化学习算法,它可以学习如何在一个环境中采取动作以最大化奖励。Q-学习的基本思想是,学习状态-动作值函数Q,它表示在一个状态下采取一个动作后获得的预期奖励。Q-学习通过不断地更新Q值来学习,其中Q值的更新公式如下:
Q(s, a) = Q(s, a) + α * (r + γ * max_a Q(s', a) - Q(s, a))
其中:
- α是学习率,它表示更新Q值的步长。
- r是当前状态下的奖励。
- γ是折扣因子,它表示未来奖励的相对重要性。
- s'是当前状态下采取动作a后的下一个状态。
- max_a Q(s', a)是下一个状态下所有动作的最大Q值。
Q-学习可以通过以下步骤进行训练:
- 初始化Q值。
- 在环境中进行探索,并收集经验。
- 使用经验更新Q值。
- 重复步骤2和3,直到Q值收敛。
Q-学习是一种强大的强化学习算法,它可以应用于各种问题,例如游戏、机器人控制和金融交易。
4.2. SARSA
import numpy as np
from collections import deque
class SarsaAgent(object):
def __init__(self, num_states, num_actions, learning_rate=0.01, discount_factor=0.99):
self.num_states = num_states
self.num_actions = num_actions
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.Q = np.zeros((num_states, num_actions))
self.replay_memory = deque(maxlen=1000)
def get_action(self, state):
# 随机选取动作
action = np.random.choice(self.num_actions)
# 贪婪选择动作
# action = np.argmax(self.Q[state, :])
return action
def learn(self, state, action, reward, next_state, next_action):
# 更新Q值
self.Q[state, action] = self.Q[state, action] + self.learning_rate * (reward + self.discount_factor * self.Q[next_state, next_action] - self.Q[state, action])
def add_to_memory(self, state, action, reward, next_state, next_action):
self.replay_memory.append((state, action, reward, next_state, next_action))
def replay(self):
# 随机采样一个批次的记忆
batch_size = 32
mini_batch = np.random.choice(self.replay_memory, batch_size)
# 更新Q值
for state, action, reward, next_state, next_action in mini_batch:
self.learn(state, action, reward, next_state, next_action)
def train(self, num_episodes, env):
for episode in range(num_episodes):
state = env.reset()
done = False
while not done:
action = self.get_action(state)
next_state, reward, done, _ = env.step(action)
next_action = self.get_action(next_state)
self.add_to_memory(state, action, reward, next_state, next_action)
self.replay()
state = next_state
SARSA(State-Action-Reward-State-Action)是一种强化学习算法,它可以学习如何在一个环境中采取动作以最大化奖励。SARSA的基本思想是,学习状态-动作-奖励-状态-动作值函数Q,它表示在一个状态下采取一个动作后,在下一个状态下采取一个动作,获得的预期奖励。SARSA通过不断地更新Q值来学习,其中Q值的更新公式如下:
Q(s, a) = Q(s, a) + α * (r + γ * Q(s', a') - Q(s, a))
其中:
- α是学习率,它表示更新Q值的步长。
- r是当前状态下的奖励。
- γ是折扣因子,它表示未来奖励的相对重要性。
- s'是当前状态下采取动作a后的下一个状态。
- a'是下一个状态下采取动作a'。
SARSA可以通过以下步骤进行训练:
- 初始化Q值。
- 在环境中进行探索,并收集经验。
- 使用经验更新Q值。
- 重复步骤2和3,直到Q值收敛。
总的来说,机器学习是一种强大的工具,可以用于解决各种问题。随着机器学习技术的不断发展,机器学习将在越来越多的领域发挥作用。