需要源码请点赞关注收藏后评论区留言私信~~
一、流计算概述
在传统的数据处理流程中总是先收集数据,然后将数据放到 DB中。当人们需要的 时候通过DB对数据做query,得到答案或进行相关的处理。这样看起来虽然非常合理,采用类似于 MapReduce方式的离线处理并不能很好地解决问题,结果却不理想,尤其是对一些实时搜索应用环境中的某些具体问题,这就引出了一种新的数据计算结构--流计算方式
流计算可以很好地对大规模流动数据在不断变化的运动过程中实时地 进行分析,捕捉到可能有用的信息,并把结果发送到下一计算节点
流计算包括早期的IBM System S,当前比较流行的流式计算框架Storm、Kafka
二、流计算与批处理系统对比
流计算侧重于实时计算方面,而批处理系统侧重于离线数据处理方面,一个追求的是低延迟,另外一个追求的是高吞吐量,处理的数据也不同,流计算处理的数据经常不断变化,而离线处理的数据是静态数据,输出形式也不同,总体来讲,两者的区别体现在以下几点
系统的输入包括两类数据,即实时的流式数据和静态的离线数据
系统的输出也包括流式数据和离线数据
业务的计算结果输出方式是通过两个条件决定的
三、Storm流计算系统
Storm 是一个 Twitter开源的分布式、高容错的实时计算系统
Storm 经常用于实时分析、在线机器学习、持续计算 、分布式远程调用和ETL等领域
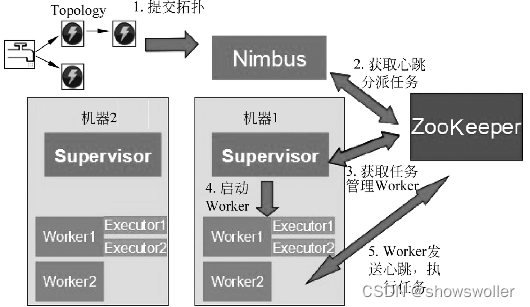
Storm主要分为 Nimbus 和 Supervisor两种组件
下图是是Storm集群架构
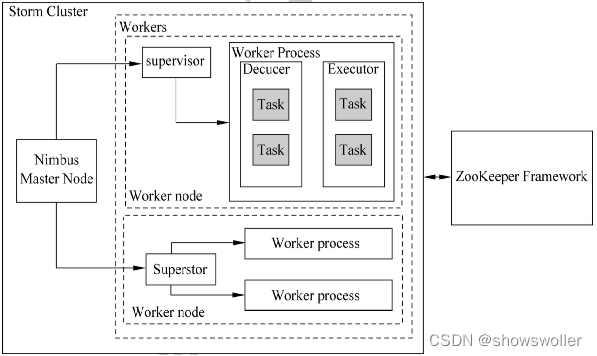
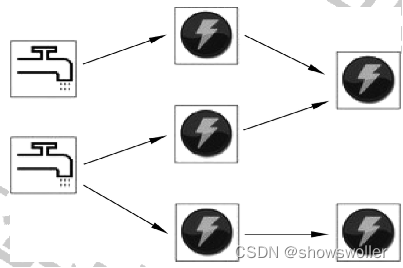
Storm中每个实时计算任务表示称一个topology
四、Samza流计算系统
Apache Samza是一个分布式流处理框架
它使用 Apache Kafka用于消息发送,采 用 Apache Hadoop YARN 来提供容错、处理器隔离、安全性和资源管理,专用于实时数据的处理
Samza由以下3层构成
数据流层(A streaming layer)
执行层(An execution layer)
处理层(A progressing layer)
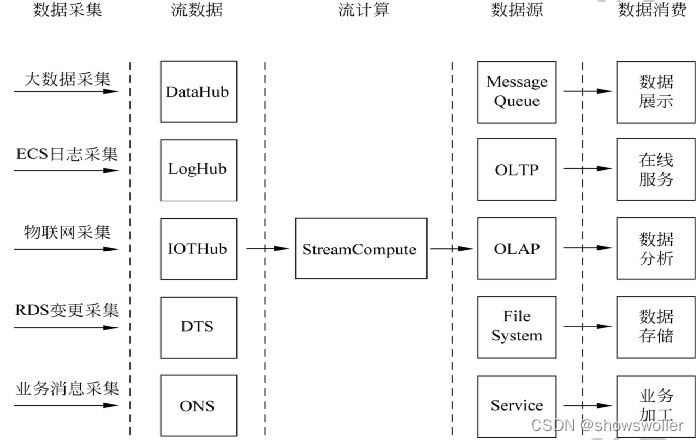
五、阿里云流计算
Aliyun Stream Compute(阿里云流计算 )是运行在阿里云平台上的流式大数据分析平台,给用户提供在云上进行流式数据实时化分析的工具
阿里云流计算提供类标准的StreamSQL语义协助用户简单、轻松地完成流式计算逻辑的处理
六、集群日志文件的实时分析
目前分布式系统在各大生产 系统中广泛使用,监控这些分布式系统产生的日志,判断集群运行是否正常,采用流计算框架实时分析分布式系统产生的日志
以分析HDFS集群运行状态来简单说明流式计算框架的使用。当 NameNode 出现故障的时候需要及时报警,从而最大程度地减少损失
利用Flink做简单的日志文件单词统计分析,分析一个时间段内 NameNode产 生的单词统计
运行效果如下
可以根据Flink的Web界面查看SocketTextStream任务,找到对应的Flink文本统计计算节点

代码如下
package alibook.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.FileSystem.WriteMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* This example shows an implementation of WordCount with data from a text
* socket. To run the example make sure that the service providing the text data
* is already up and running.
* <p>
* To start an example socket text stream on your local machine run netcat from
* a command line: <code>nc -lk 9999</code>, where the parameter specifies the
* port number.
* </p>
* <p>
* Usage:
* <code>SocketTextStreamWordCount <hostname> <port> <result path></code>
* </p>
* <p>
* This example shows how to:
* <ul>
* <li>use StreamExecutionEnvironment.socketTextStream
* <li>write a simple Flink program,
* <li>write and use user-defined functions.
* </ul>
*
*/
public class SocketTextStream {
public static void main(String[] args) throws Exception {
if (!parseParameters(args)) {
return;
}
// set up the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment();
// get input data
DataStream<String> text = env.socketTextStream(hostName, port, '\n', 0);
DataStream<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.keyBy(0)
.sum(1);
if (fileOutput) {
counts.writeAsText(outputPath, WriteMode.NO_OVERWRITE);
} else {
counts.print();
}
// execute program
env.execute("WordCount from SocketTextStream Example");
}
// *************************************************************************
// UTIL METHODS
// *************************************************************************
private static boolean fileOutput = false;
private static String hostName;
private static int port;
private static String outputPath;
private static boolean parseParameters(String[] args) {
// parse input arguments
if (args.length == 3) {
fileOutput = true;
hostName = args[0];
port = Integer.valueOf(args[1]);
outputPath = args[2];
} else if (args.length == 2) {
hostName = args[0];
port = Integer.valueOf(args[1]);
} else {
System.err.println("Usage: SocketTextStreamWordCount <hostname> <port> [<output path>]");
return false;
}
return true;
}
/**
* Implements the string tokenizer that splits sentences into words as a
* user-defined FlatMapFunction. The function takes a line (String) and
* splits it into multiple pairs in the form of "(word,1)" ({@code Tuple2<String,
* Integer>}).
*/
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String, Integer>> out)
throws Exception {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}创作不易 觉得有帮助请点赞关注收藏~~~