安装目录以及各个版本
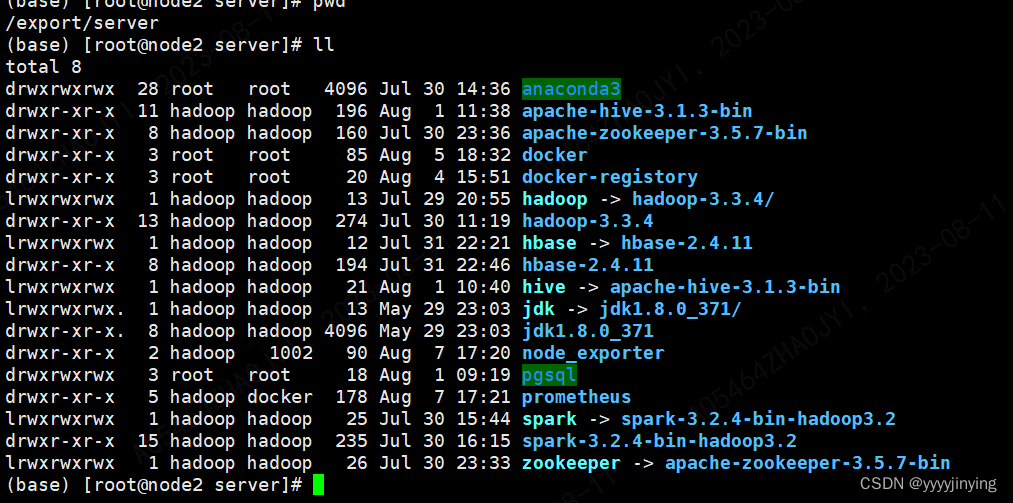
大数据安装版本
| 软件 | 版本 | 备注 |
|---|---|---|
| hadoop | hadoop-3.3.4 | hdfs基础 |
| spark | spark-3.2.4-bin-hadoop3.2 | 计算框架 |
| zookeeper | apache-zookeeper-3.5.7-bin | 分布式服务器 |
| hbase | hbase-2.4.11 | 列式存储 |
| hive | apache-hive-3.1.3-bin | 数仓元数据 |
启动服务
su - hadoop
-- 启动hadoop和spark
exec-hadoop.sh start
exec-hadoop.sh stop
-- 启动数据库
systemctl start docker // pgsql hive
-- 启动hive
nohup hive --service metastore >> /export/server/hive/logs/metastore.log 2>&1 &
-- 启动hbase
/export/server/hbase/bin/start-hbase.sh
cd /export/server/hbase && bin/stop-hbase.sh
本地虚拟机快照记录

查看系统
lsb_release -a
cat /etc/redhat-release
修改主机名
hostnamectl set-hostname <新主机名>
/etc/hostname
两台服务器的主机名
hostname
node1
node2
node3
安装docker
参考安装:
https://docs.docker.com/engine/install/centos/#installation-methods
开机启动
systemctl enable docker.service
systemctl is-enabled docker.service
安装docker compose
https://github.com/docker/compose/releases/tag/v2.17.2

mv docker-compose-linux-x86_64 /usr/local/bin/docker-compose
chmod +x docker-compose
docker-compose version
安装python
参考:https://blog.csdn.net/jinying_51eqhappy/article/details/131956003
创建用户hadoop
adduser hadoop
passwd hadoop
安装hadoop
hadoop的配置文件
cd /export/server/hadoop/etc/hadoop
mkdir -p /export/server/hadoop/logs
mkdir -p /export/server/hadoop/tmpdata
配置workers
vim workers
node1
node2
node3
配置hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export HADOOP_PID_DIR=/home/hadoop/tmp
export HADOOP_SECURE_PID_DIR=/home/hadoop/tmp
配置core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node2:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/hadoop/tmpdata</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
配置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>node2:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9868</value>
</property>
</configuration>
hadoop-env.sh
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export HADOOP_PID_DIR=/home/hadoop/tmp
export HADOOP_SECURE_PID_DIR=/home/hadoop/tmp
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
mapred-env.sh
export JAVA_HOME=/export/server/jdk
yarn-env.sh
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
配置mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>Execution framework set to Hadoop YARN.</description>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node2:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node2:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MAPREDUCE home设置为HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MAPREDUCE HOME 设置为HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>mAPREDUCE HOME 设置为HADOOP_HOME</description>
</property>
</configuration>
配置yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
全局环境配置/etc/profile
vim /etc/profile
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/export/server/hadoop
export PYSPARK_PYTHON=/export/server/anaconda3/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/export/server/spark
export HBASE_HOME=/export/server/hbase
export HIVE_HOME=/export/server/hive
export PATH=$PATH:$HADOOP_HOME/bin:$PYSPARK_PYTHON
export PATH=$PATH:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin
同步node1,node2,node3服务器配置
创建同步脚本xsync
mkdir -p /home/hadoop/bin && cd /home/hadoop/bin
vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Arguement
exit;
fi
#2. 遍历集群所有机器
for host in node1 node2 node3
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
添加执行权限
chmod +x xsync
同步Hadoop
cd /export/server
sudo /home/hadoop/bin/xsync hadoop
创建jps状态打印
vim /export/server/hadoop/sbin/jpsall.sh
#!/bin/bash
for host in node1 node2 node3
do
echo =============== $host ===============
ssh $host $JAVA_HOME/bin/jps
done
添加执行权限
chmod +x jpsall.sh
master服务初始化hadoop
hadoop namenode -format
配置hive
配置 /etc/profile 的hive同上;
授权代理hadoop用户,可以支持hive访问
cd hadoop/etc/hadoop
vim core-site.xml
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
同上
配置hive-env.sh
cd hive/conf
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
配置meata元素据库pgsql
vim hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:postgresql://node2:5432/hivedata?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.postgresql.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hiveuser</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node2</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node2:9083</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
初始化表
cd /export/server/hive/bin
./schematool -dbType postgres -initSchema
测试hive
mkdir -p /export/server/hive/logs
后台启动
>nohup hive --service metastore >> /bigdata/server/hive/logs/metastore.log 2>&1 &
>hive 交互式操作
配置spark
hadoop fs -mkdir /sparklog
/ect/profile配置同上;
配置works
node1
node2
node3
配置spark-env.sh
#!/usr/bin/env bash
JAVA_HOME=/export/server/jdk
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
export SPARK_MASTER_HOST=node2
export SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node2:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
配置 spark使用hive
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node2:9083</value>
</property>
</configuration>
启动服务
cd /export/hadoop/sbin
vim exec-hadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh node2 $HADOOP_HOME/sbin/start-dfs.sh
echo " --------------- 启动 yarn ---------------"
ssh node1 $HADOOP_HOME/sbin/start-yarn.sh
echo " --------------- 启动 historyserver ---------------"
ssh node2 $HADOOP_HOME/bin/mapred --daemon start historyserver
echo " --------------- 启动 spark ---------------"
ssh node2 $SPARK_HOME/sbin/start-all.sh
echo " --------------- 启动 spark 历史服务器 ---------------"
ssh node2 $SPARK_HOME/sbin/start-history-server.sh
# ssh node2 /export/server/zookeeper/bin/zk.sh start
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- stop historyserver ---------------"
ssh node2 $HADOOP_HOME/bin/mapred --daemon stop historyserver
echo " --------------- stop yarn ---------------"
ssh node1 $HADOOP_HOME/sbin/stop-yarn.sh
echo " --------------- stop hdfs ---------------"
ssh node2 $HADOOP_HOME/sbin/stop-dfs.sh
echo " --------------- stop spark ---------------"
ssh node2 $SPARK_HOME/sbin/stop-all.sh
echo " --------------- stop spark 历史服务器 ---------------"
ssh node2 $SPARK_HOME/sbin/stop-history-server.sh
# ssh node2 /export/server/zookeeper/bin/zk.sh stop
;;
*)
echo "Input Args Error..."
;;
esac
chmod +x exec-hadoop.sh
exec-hadoop.sh start
exec-hadoop.sh stop
spark on yarn
pyspark --master spark://ecs-qar1-0002:7077
pyspark --master yarn
sc.parallelize([1,2,3]).map(lambda x:x*10).collect()
yarn客户端模式
spark-submit --master yarn --deploy-mode client --driver-memory 512m --executor-memory 512m --num-executors 2 --total-executor-cores 2 /bigdata/server/spark/examples/src/main/python/pi.py 10
安装zoookeeper
参考:https://blog.csdn.net/jinying_51eqhappy/article/details/132013638
安装hbase
参考:https://blog.csdn.net/jinying_51eqhappy/article/details/132030894