CMU 15-445 -- Distributed OLTP Databases -20
- 引言
- Assumption
- Agenda
- Atomic Commit Protocols
- Two-Phase Commit (2PC)
- 2PC Success
- 2PC Abort
- 2PC Optimizations
- Fault Tolerant
- Paxos
- Multi-Paxos
- 2PC vs. Paxos
- Replication
- Replication Configuration
- Approach #1: Master-Replica
- Approach #2: Multi-Master
- K-Safety
- Propagation Scheme
- Propagation Timing
- Approach #1: Continuous
- Approach #2: On Commit
- Active vs. Passive
- Approach #1: Active-Active
- Approach #2: Active-Passive
- CAP
- Federated Databases
- 小结
引言
本系列为 CMU 15-445 Fall 2022 Database Systems 数据库系统 [卡内基梅隆] 课程重点知识点摘录。
上节课我们介绍了分布式事务的去中心化实现:
- 应用程序要发起一次事务时,先通过某种方式选择这个事务的 master node,并向它发送事务开始的请求:

- master node 同意后,应用程序向事务涉及的节点发送数据更新请求,此时每个节点都只是执行请求但尚未提交:
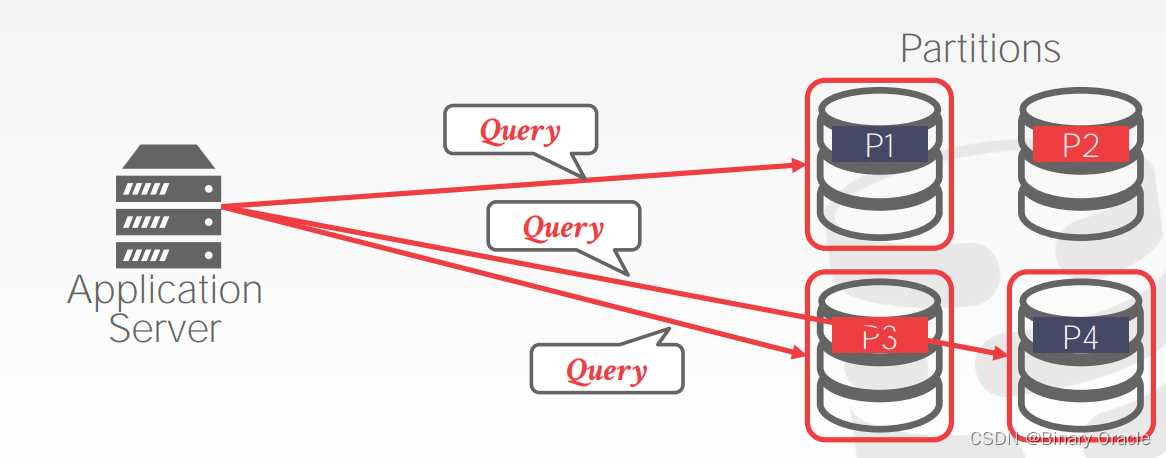
- app server 收到所有节点的响应后,向 master node 发送事务提交的请求,master node 再问其它节点是否可以安全提交。若是,则确保所有节点提交事务后由 master node 返回成功,若否,则确保所有节点回滚成功,同时由 master node 返回失败。:
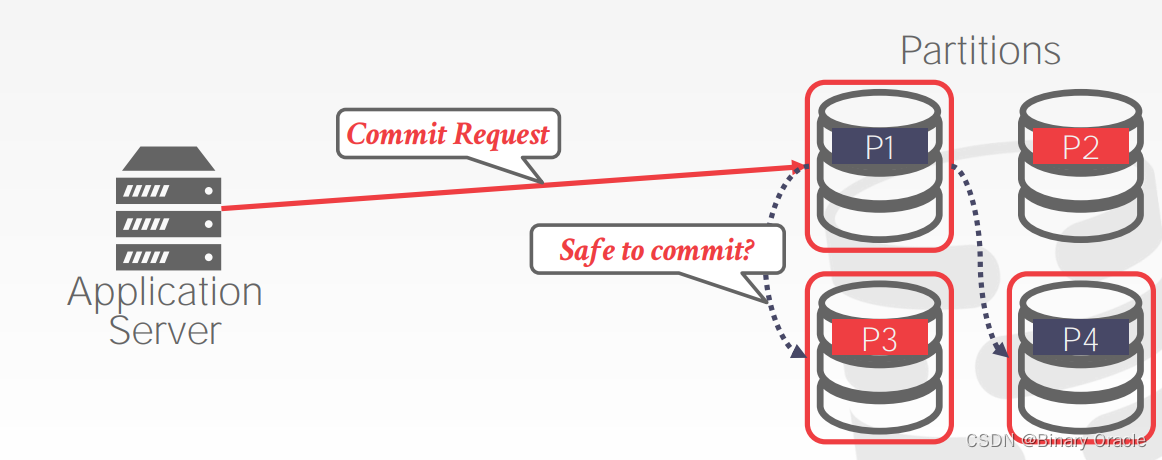
但上节课我们没有讨论如何确保所有节点都认同事务提交,所有节点在同意之后实际执行了提交。这里有很多细节需要考虑:
- 如果一个节点发生了故障怎么办?
- 如果这期间节点之间消息传递延迟了怎么办?
- 我们是否需要等待所有都节点都同意?如果集群较大等待时间就会由于短板效应而增加。
本节我们就来讨论一下这些问题。
Assumption
我们首先需要假设在分布式数据库中,所有节点都是好孩子,都受到严格的控制,不会耍坏心眼,让它提交就提交,让它回滚就回滚。如果我们不能信任其它节点,那我们将需要 Byzantine Fault Tolerant 协议来实现分布式事务。几乎所有的分布式数据库都符合我们的假设,除了区块链。
Agenda
- Atomic Commit Protocols
- Replication
- Consistency Issues (CAP)
- Federated Databases
Atomic Commit Protocols
常见的 Atomic Commit Protocols 包括:
- 2PC
- 3PC
- Paxos
- Raft
- ZAB (Apache Zookeeper)
- Viewstamped Replication
本课讨论 2PC 和 Paxos。
Two-Phase Commit (2PC)
2PC Success
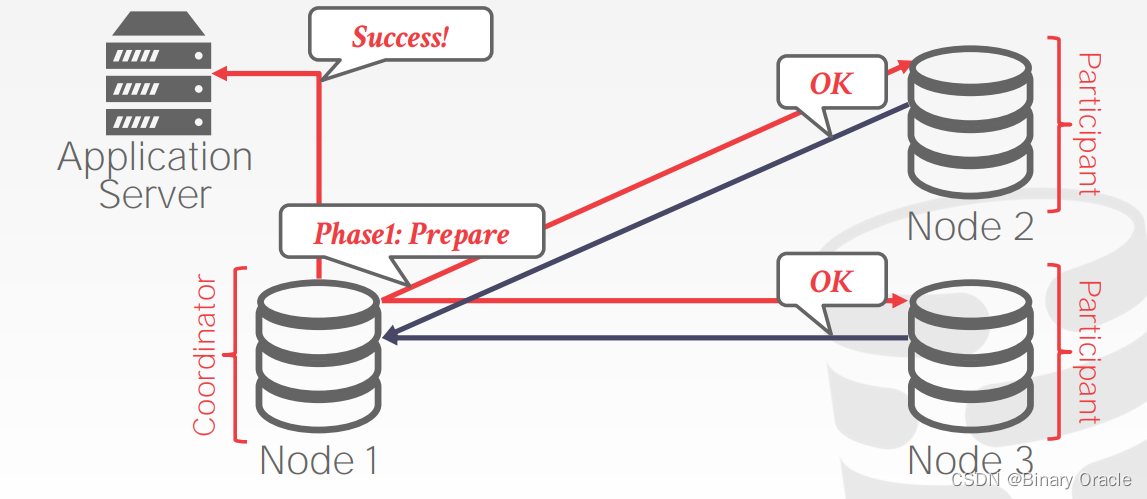
- 应用程序在发送事务提交请求到其选取的 master node/coordinator (下文称 coordinator) 后,进入 2PC 的第一阶段:准备阶段 (Prepare Phase)

- coordinator 向其它节点发送 prepare 请求,待所有节点回复 OK 后,进入第二阶段:提交阶段 (Commit Phase)
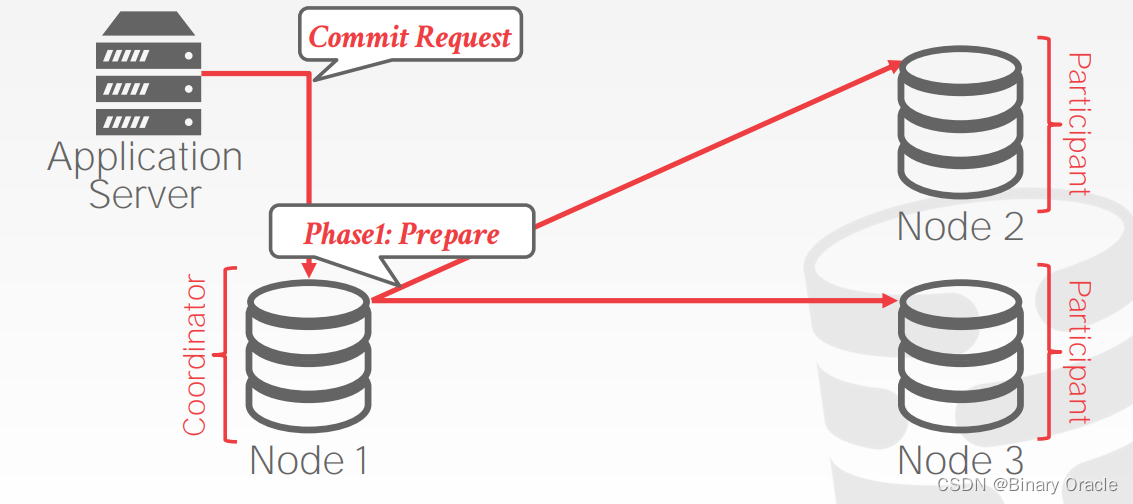

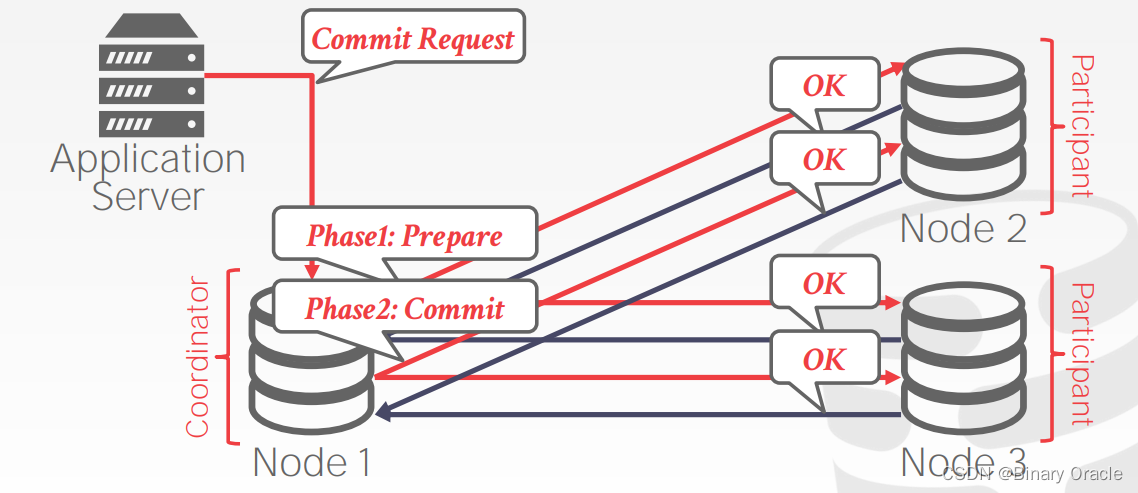
- coordinator 向其它节点发送 commit 请求:

- 待所有节点在本地提交,并返回 OK 后,coordinator 返回成功消息给应用程序

2PC Abort
- 在 Prepare 阶段,其它节点如果无法执行该事务,则返回 Abort 消息:
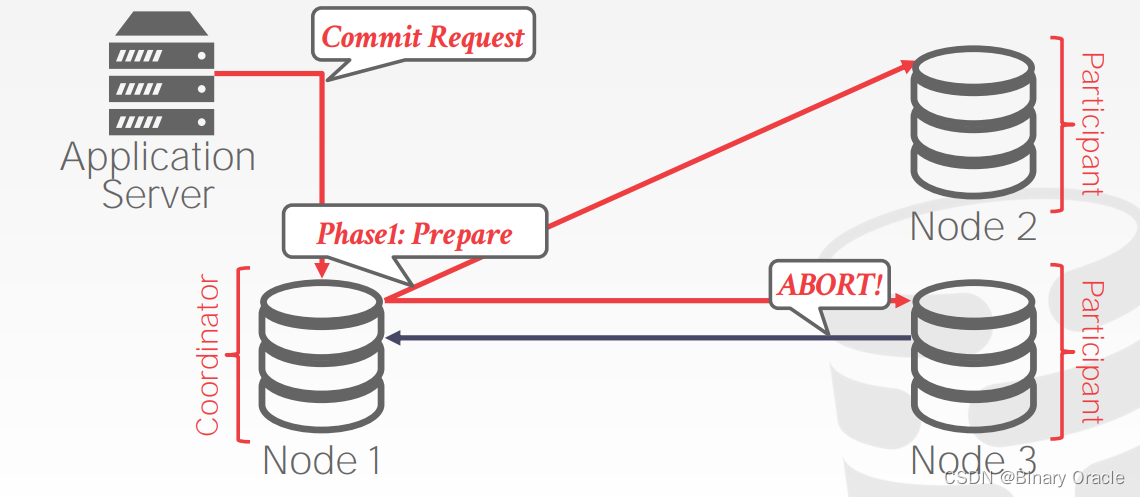
- 此时 coordinator 可以立即将事务中止的信息返回给应用程序,同时向所有节点发送事务中止请求
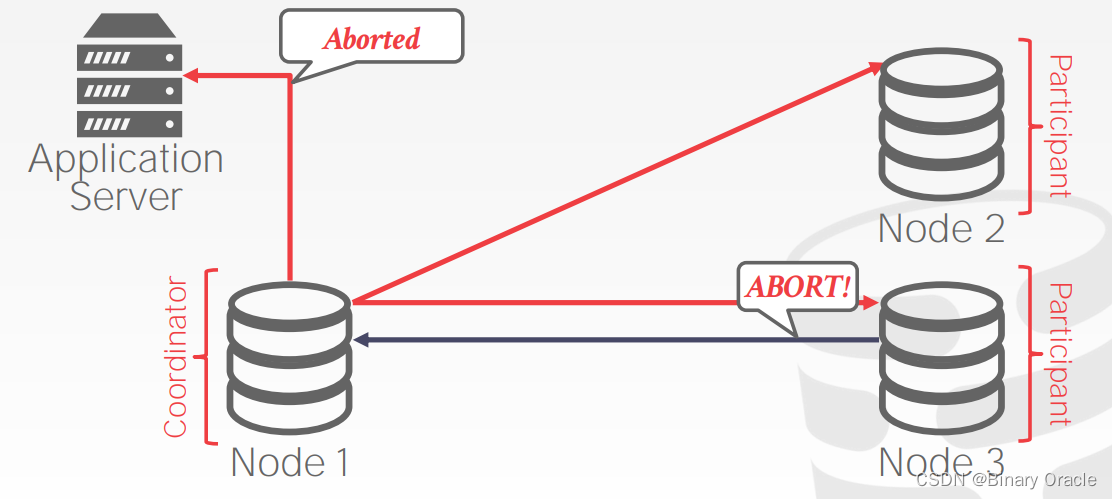
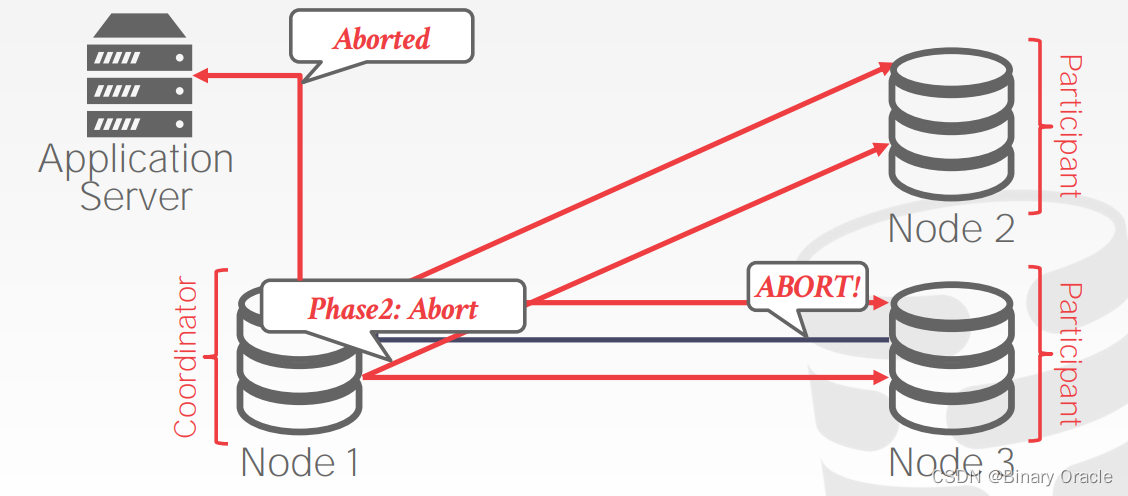
- coordinator 需要保证所有节点的事务全部回滚:

2PC Optimizations
2PC 有两个优化技巧:
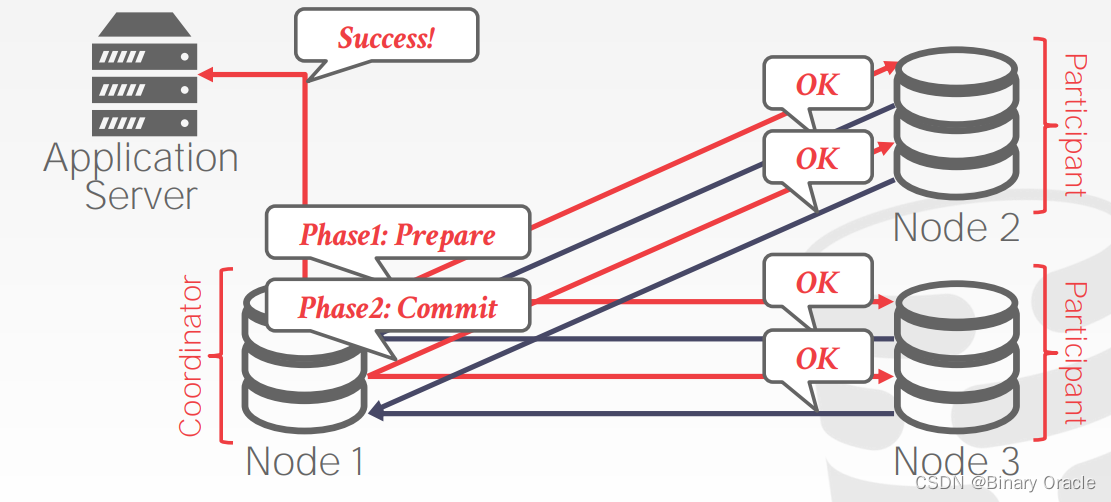
- Early Prepare Voting:假如你向远端节点发送的请求是最后一个 (尚未发送提交请求),远端节点就可以利用这个信息直接在最后一次响应后返回 Prepare 阶段的响应,即直接告诉 coordinator 事务是否可以提交。
- Early Acknowledgement After Prepare:实际上在准备阶段完成后,如果所有节点都已经回复 OK,即认为事务可以安全提交,此时 coordinator 可以直接回复应用程序事务提交已经成功。这符合 2PC 的语义,只要 Prepare Phase 通过,那么所有节点必须保证能够提交事务,Commit Phase 无论如何必须执行成功。


Fault Tolerant
在 2PC 的任何阶段都可能出现节点崩溃。如何容错是 2PC 需要解决的重要问题。首先,所有节点都会将自己在每个阶段所做的决定落盘,类似 WAL,然后才将这些决定发送给其它节点。这就保证了每个节点在发生故障恢复后,能知道自己曾经做过怎样的决定。在 coordinator 收到所有其它节点 Prepare 节点的 OK 响应后,且 coordinator 将事务可以进入 Commit 阶段的信息写入日志并落盘后,这个事务才真正被认为已经提交。
如果 coordinator 在 Commit Phase 开始之前发生故障,那么其实该事务相关的任何改动都未落盘,不会产生脏数据,coordinator 在故障恢复后可以继续之前的工作;如果 coordinator 在 Commit Phase 开始之后发生故障,其它节点需要等待 coordinator 恢复,或用其它方式确定新的 coordinator,接替之前的 coordinator 完成剩下的工作。
如果 participant 在 Commit Phase 之前发生故障,那么 coordinator 可以简单地利用超时机制来直接认为事务中止;如果在 Commit Phase 之后发生故障,那么 coordinator 需要通过不断重试,保证事务最终能够完成。
由于 2PC 中许多决定都依赖于所有节点的参与,可能会出现 live lock,影响事务的推进效率,于是就有了共识算法。
Paxos
关于Paxos算法通俗易懂理解,可以参考知乎这篇高赞帖子回答: 如何浅显易懂地解说 Paxos 的算法?
paxos 属于共识协议,coordinator 负责提交 commit 或 abort 指令,participants 投票决定这个指令是否应该执行。与 2PC 相比,paxos 只需要等待大多数 participants 同意,因此在时延上比 2PC 更有保障。
paxos 最早在 Leslie Lamport 的 The Part-Time Parliament 论文中提出,尽管这篇文章是 1998 年发表的,但早在 1992 年,他为了证明不存在这种拥有容错能力的共识算法,就发现了 Paxos。但由于他不听从论文审校人的建议修改,这篇论文就没有发表,若干年后,当人们开始尝试解决这个问题时,他才将这篇论文拿出来,声明自己早就已经解决了该问题。但这篇论文比较晦涩难懂,后来他在 2001 年又发表了一篇名为 Paxos Made Simple,仍然没有多少人能够看懂。直到 Google 在 2007 年发表了名为 Paxos Made Live - An Enginnering Perspective 的文章,才终于让更多人理解了其中的思想。
我们可以将 2PC 理解成是 Paxos 的一种特殊情况。接下来我们看一下 Paxos 的工作过程。在 Paxos 中,coordinator 被称为 proposer,participants 被称为 acceptors,如下图所示:
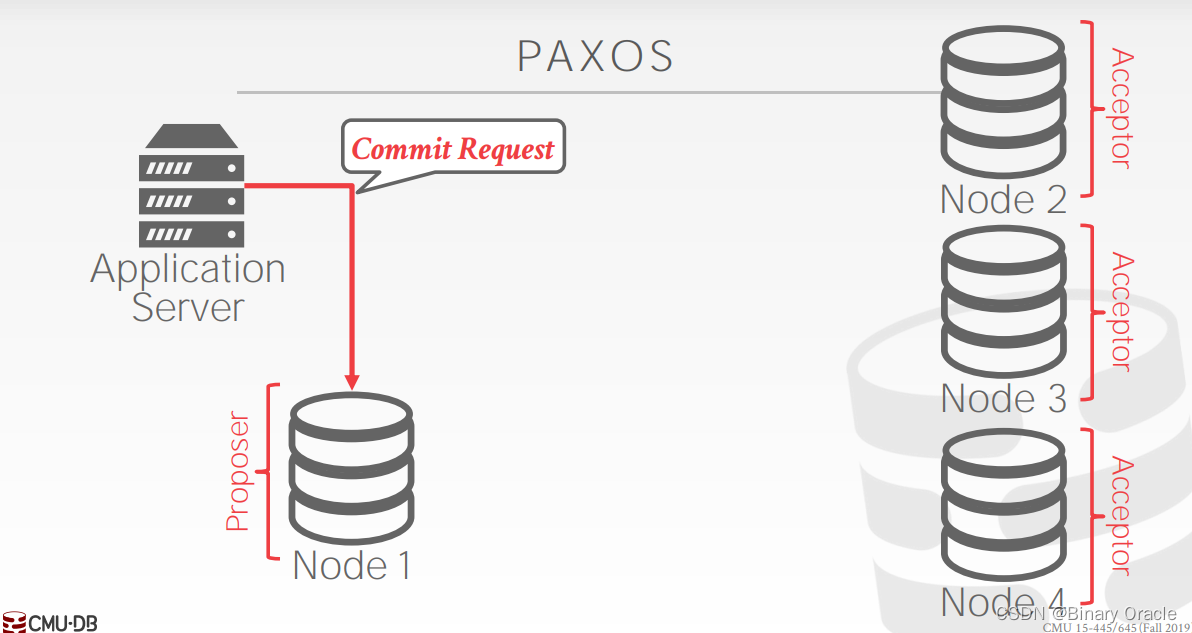
paxos 需要存在多数节点,因此我们这里有 3 个 acceptors。应用程序首先向 proposer 发起事务提交请求 , 然后 proposer 向所有节点发出 Proposal,类似 2PC 的 Prepare 阶段,但与 2PC 不同,节点回复 Agree 时无需保证事务肯定能执行完成:
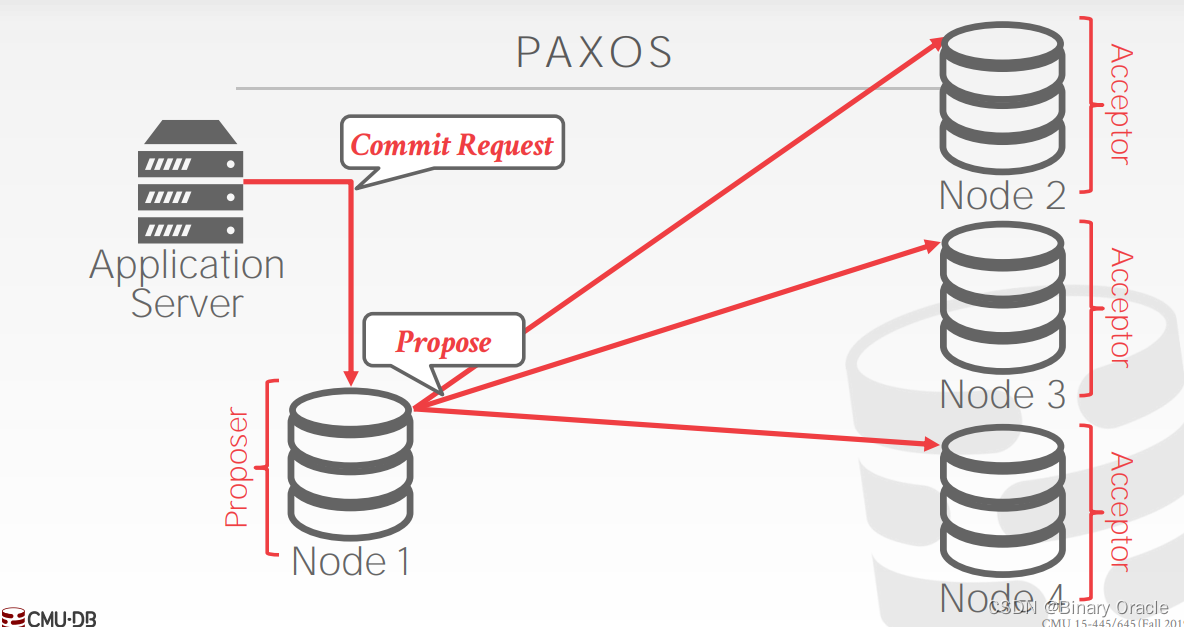
此外如果其中一个 acceptor (Node 3) 发生故障,proposer 依然获得了大多数节点的同意,不会阻碍 Paxos 协议的推进。获得多数节点同意后,proposer 就会继续向所有节点发送 Commit 请求:
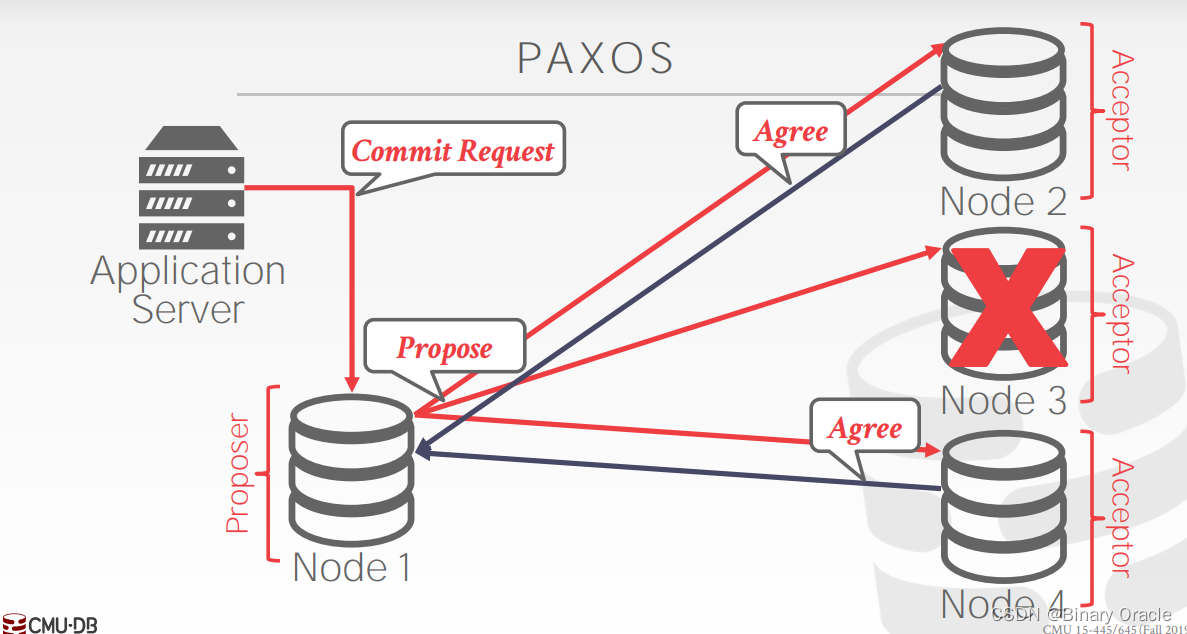
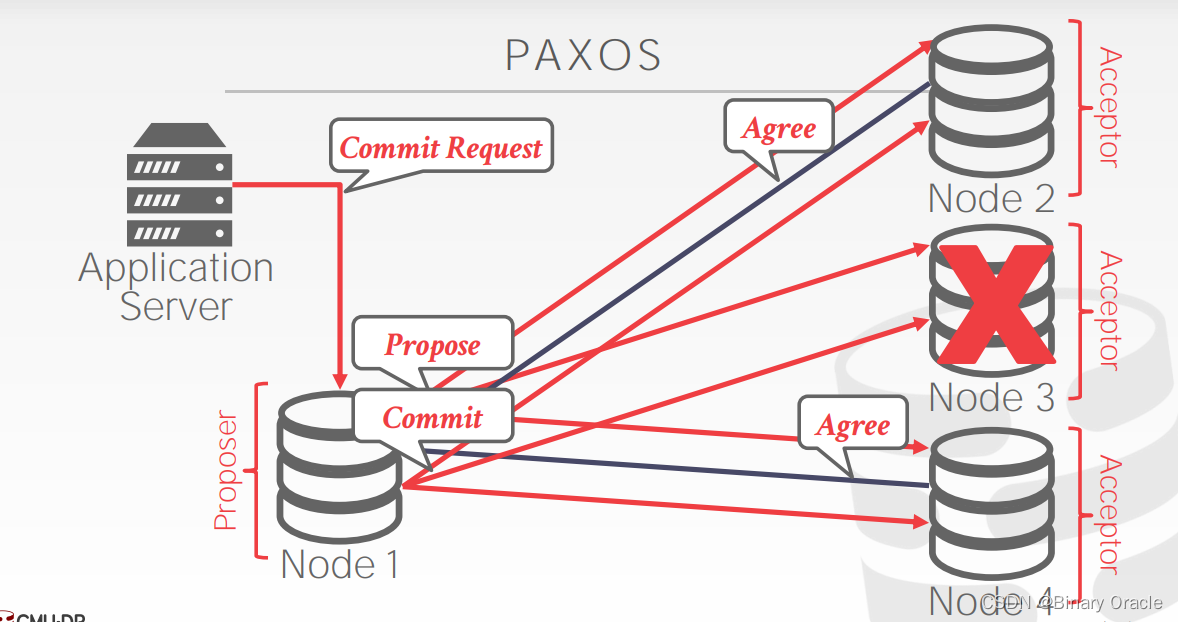
仅当多数节点回复 Accept 后 proposer 才能确定事务提交成功,回复给应用程序:


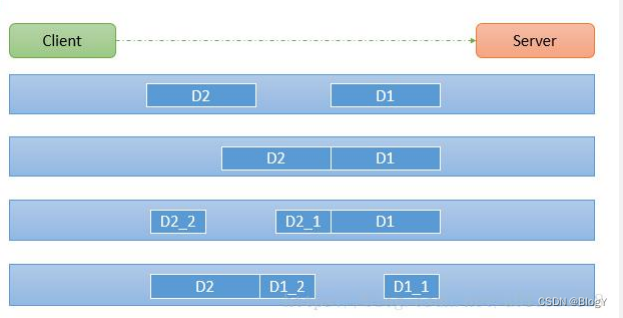
即使在 Commit 阶段,每个 acceptor 仍然可以拒绝请求。举例如下:
- 假设有两个 Proposer 同时存在,这是 proposer 1 提出逻辑时刻为 n 的 proposal,随后所有 acceptors 都回复 agree

- 随后 proposer 2 提出逻辑时刻为 n+1 的 proposal,接着 proposer 1 发起逻辑时刻为 n 的 commit 请求。由于 acceptors 收到了逻辑时刻更新的请求,因此它们拒绝 proposer 1 的请求
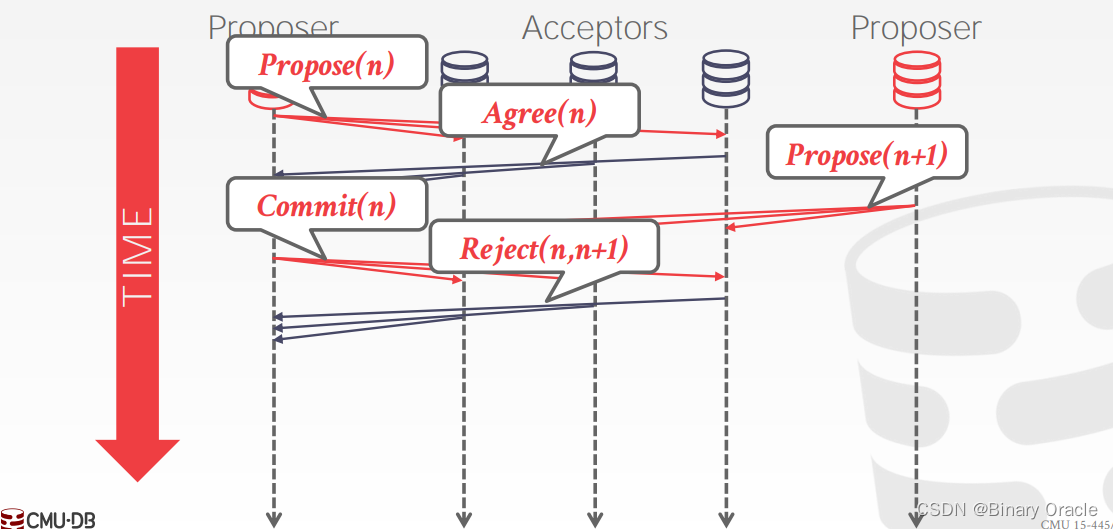
- 随后 proposer 2 完成剩下的协议步骤,成功提交事务
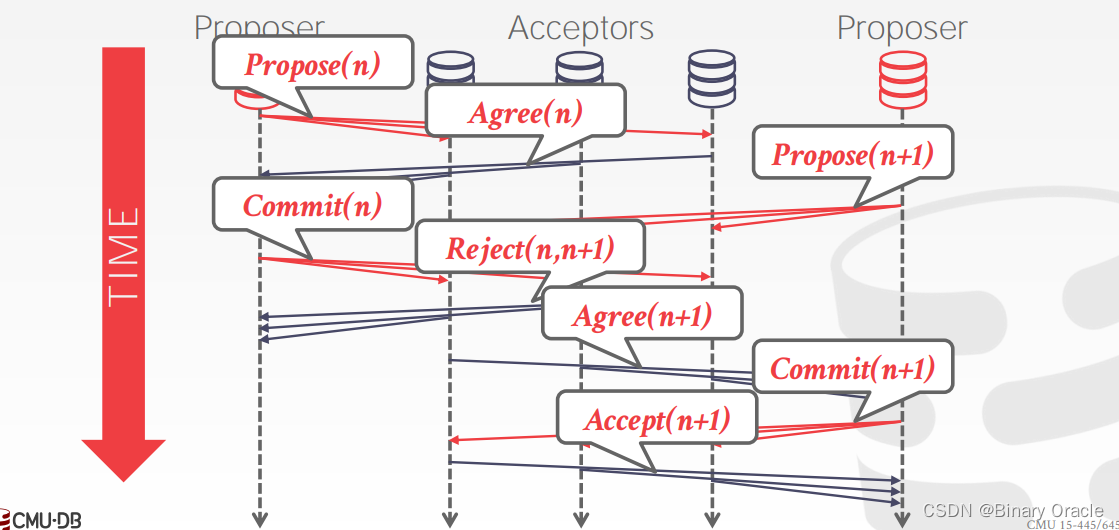
有没有可能出现两个 proposer 互相阻塞对方,导致 commit 永远不成功?这时就需要 Multi-Paxos。
Multi-Paxos
如果系统中总是有任意数量的 proposer,达成共识就可能变得比较困难,那么我们是不是可以先用一次 Paxos 协议选举出 Leader,确保整个系统中只有一个 proposer,然后在一段时间内,它在提交事务时就不需要 Propose 操作,直接进入 Commit 即可。这样就能大大提高 Paxos 达成共识的效率。到达一段时间后,proposer 的 Leader 身份失效,所有参与者重新选举。
你可能会问,每次选举的时候会不会出现互相阻塞的现象?如果在实践上我们用一些合理的优先和随机退后 (backoff) 机制,就可以减少阻塞的次数,概率上保证选举能够最终成功。
2PC vs. Paxos
目前绝大多数分布式数据库的各个节点一般部署距离较近、且网络连接质量较高,网络抖动和节点故障发生的概率比较低,因此它们多数采用 2PC 作为 Atomic Commit Protocol。2PC 的优点在于其网络通信成本低,在绝大多数情况下效率高,缺点在于如果出现 coordinator 故障,则会出现一定时间的阻塞。Paxos 的优点在于可以容忍少数节点发生故障,缺点在于通信成本较高。
Replication
分布式数据库还需要复制数据到冗余的节点上,提高数据库本身的可用性。在 Replication 的实现方案上,有以下 4 个核心的设计决定需要考虑:
- Replica Configuration
- Propagation Scheme
- Propagation Timing
- Update Method
Replication Configuration
该设计决定主要讨论的是如何设计复制节点之间的关系,如何分配读写流量。
Approach #1: Master-Replica
所有数据写操作都指向 master,master 更新本地数据后,将这些数据更新请求传播给其它复制节点 (无需使用 atomic commit protocol)。只读事务是否可以被允许在复制节点上执行取决于对一致性的要求,以及数据库本身实现的隔离级别。如果 master 节点崩溃,就利用共识算法选举出新的 master。
Approach #2: Multi-Master
不同节点可以同时成为 master,同时接受写事务请求。但复制节点之间需要通过 atomic commit protocol 来保证写入不同 master 的数据之间不存在冲突。
二者的对比如下图所示:
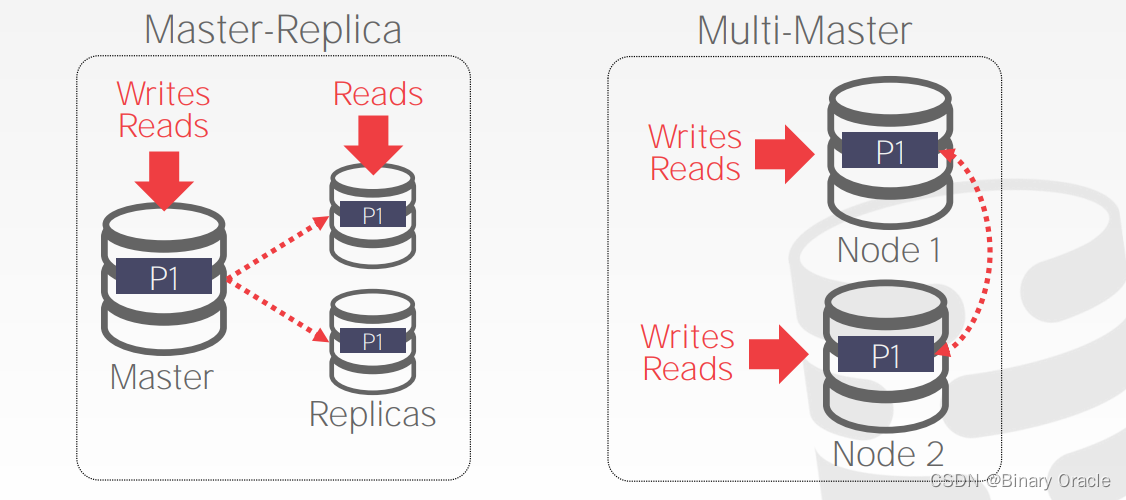
FackBook 最早采用的就是 Master-Replica 的配置,所有的写请求都被路由到唯一的 master 区域,然后再由 master 将数据传播到其它 replica 区域。因此用户在发朋友圈时,实际上其所在区域的数据库中可能还不存在他刚发的朋友圈,FackBook 通过在 cookie 中先保存用户刚发表的朋友圈,来制造数据已经写入的假象。后来 FB 将配置修改成 Multi-Master 的方案,并自行设计了不同 master 之间数据同步和解决冲突的方案。
K-Safety
K-safty 指的是同步复制节点 (In-sync Replica) 数量与复制数据库的容错性的关系。通常如果同步复制节点小于 K,数据库则不得不停下,直到同步复制节点的数量重新满足要求。K 的大小取决于你对数据丢失的容忍度。
Propagation Scheme
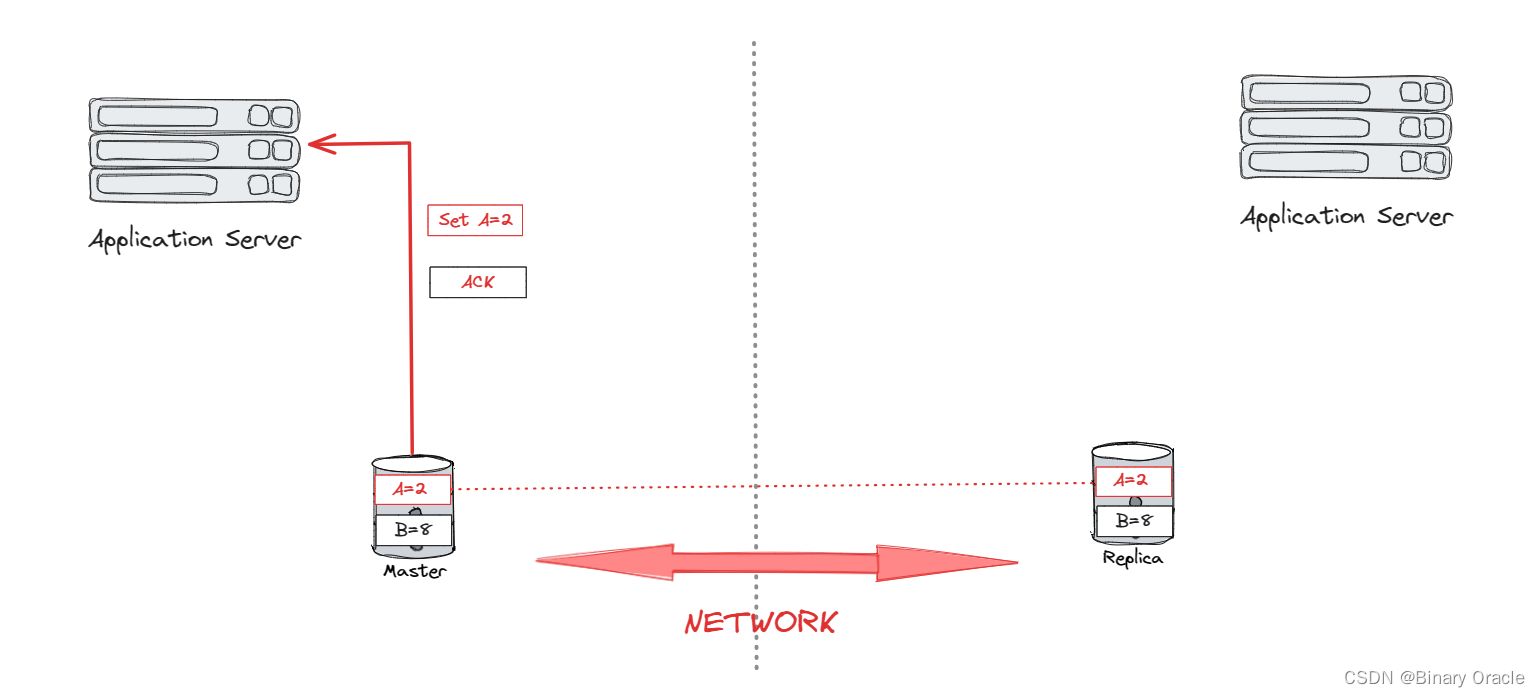
当一个事务在复制数据库上提交时,数据库需要决定事务是否应该等待数据改动被成功传播到其它节点后才向客户端发送 ack。显然,我们有两种 propagation schemes,同步和异步,二者分别对应强一致性和最终一致性。

这也是传统关系型数据库与 NoSQL 数据库之间的差异之一。传统关系型数据库强调一致性,主节点必须等待复制节点落盘后,才能告诉客户端数据修改成功;NoSQL 数据库为了性能不会等待复制节点落盘,而是在本地落盘后直接告诉客户端数据修改成功,同时异步将数据传播给复制节点。当然如果 NoSQL 数据库的主节点在还没来得及传播数据时永久故障,那么这条数据也将消失。
Propagation Timing
主节点什么时候开始将日志数据同步给复制节点?
Approach #1: Continuous
DBMS 在生成日志时就持续地将日志传播给复制节点,只要不出现问题,这种做法的效率更高。DBMS 还需要将事务提交或中止的信息也传播给复制节点,保证事务在复制节点也能统一提交或中止。缺点在于:如果事务最终中止,那么复制节点就做了无用功。
大部分数据库为了效率采用的都是这种方案。
Approach #2: On Commit
DBMS 只在一个事务彻底执行完成时才将日志传播给复制节点,这样如果事务中止,复制节点就什么事都不用做。缺点在于,由于需要等待事务结束时才同步数据,整体同步效率较低。
Active vs. Passive
主节点与复制节点执行事务的顺序。
Approach #1: Active-Active
事务同时在多个复制节点上独立执行,在执行结束时需要检查两边数据是否一致。
Approach #2: Active-Passive
事务先在一个复制节点上执行,然后将数据的变动传播给其它复制节点。
CAP
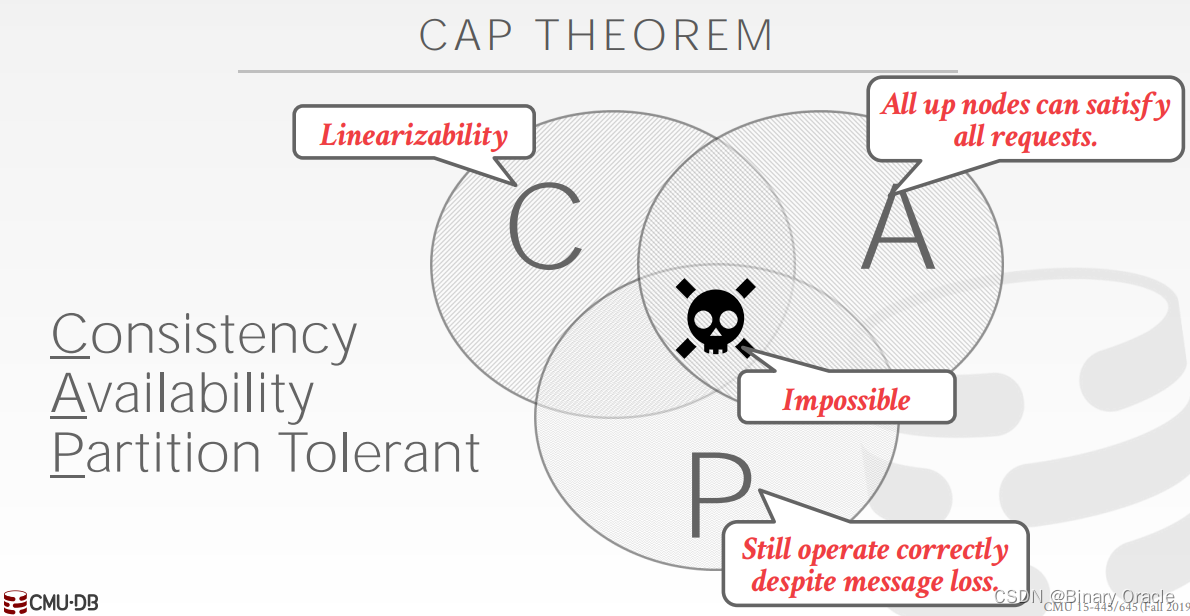
-
C : Consistent
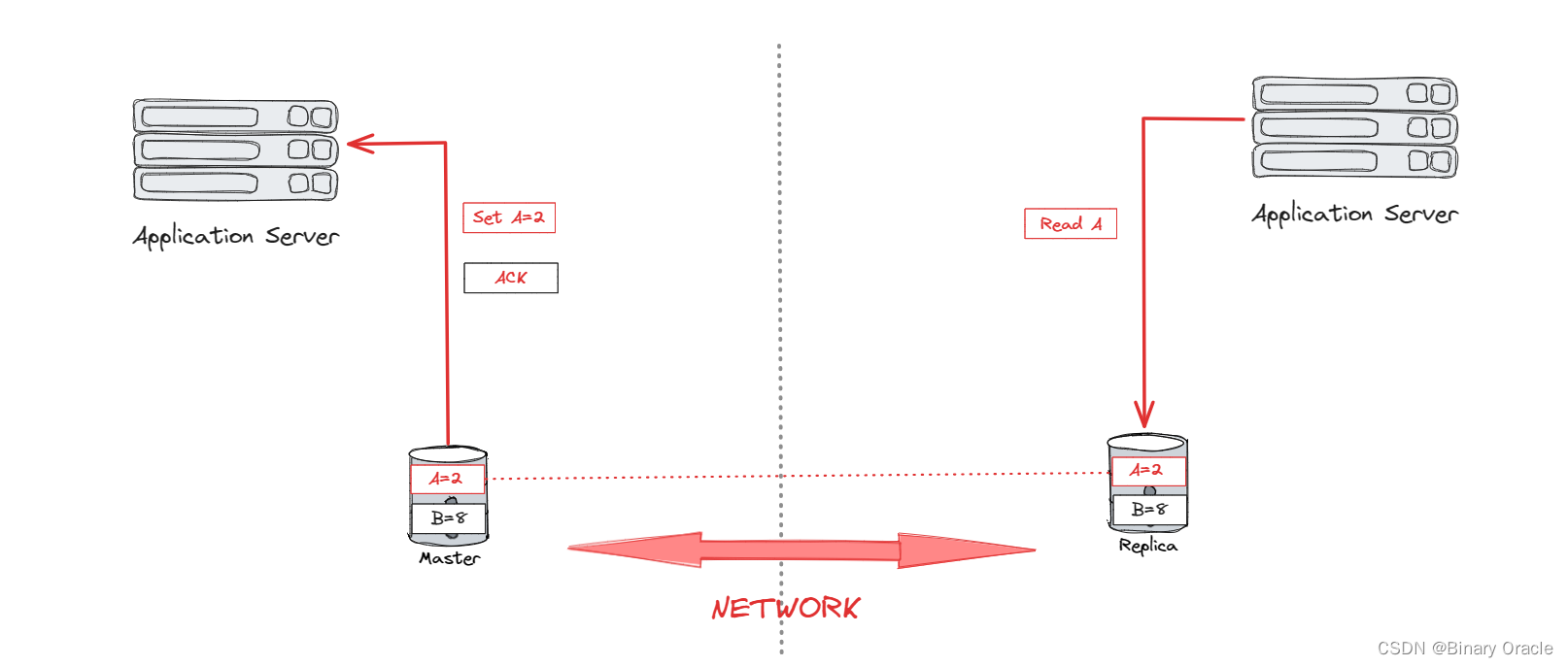
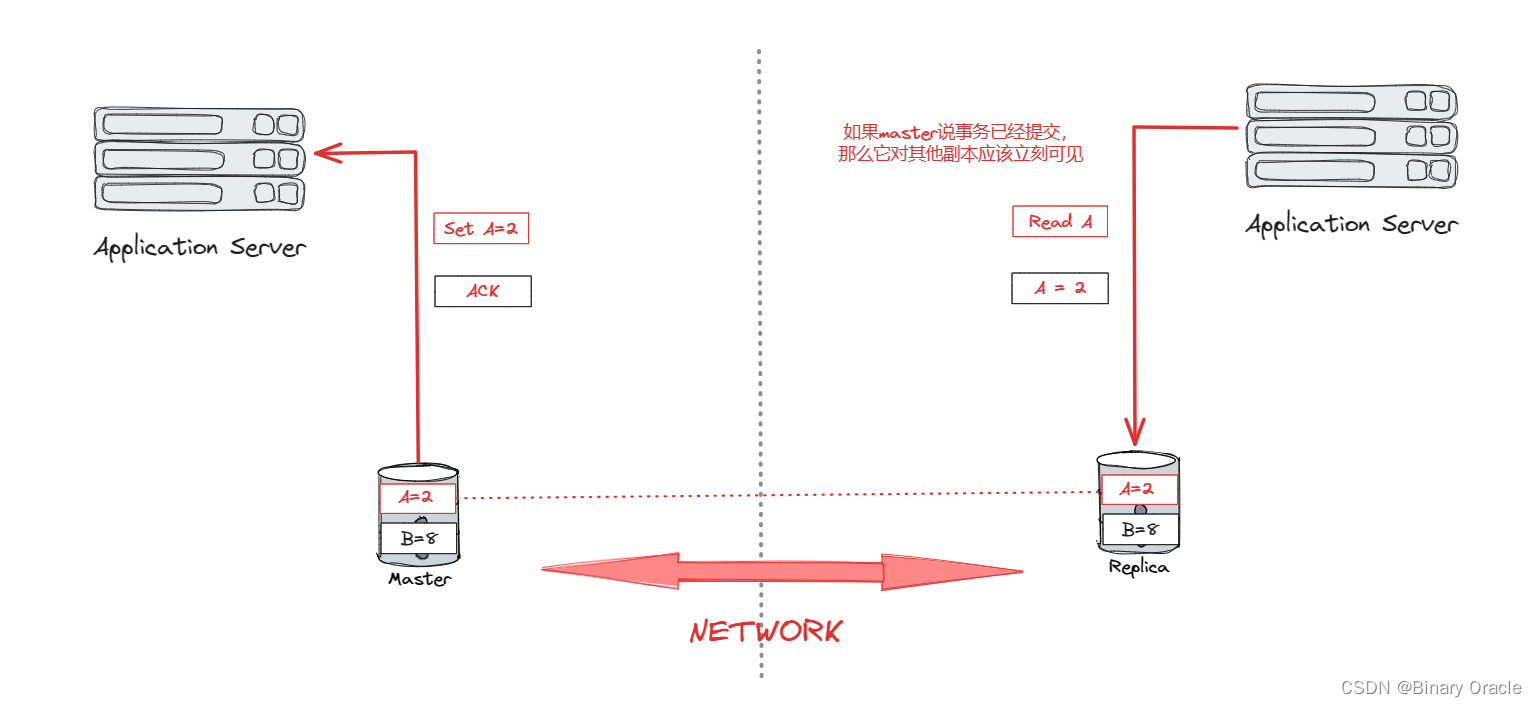
-
A : Always Available
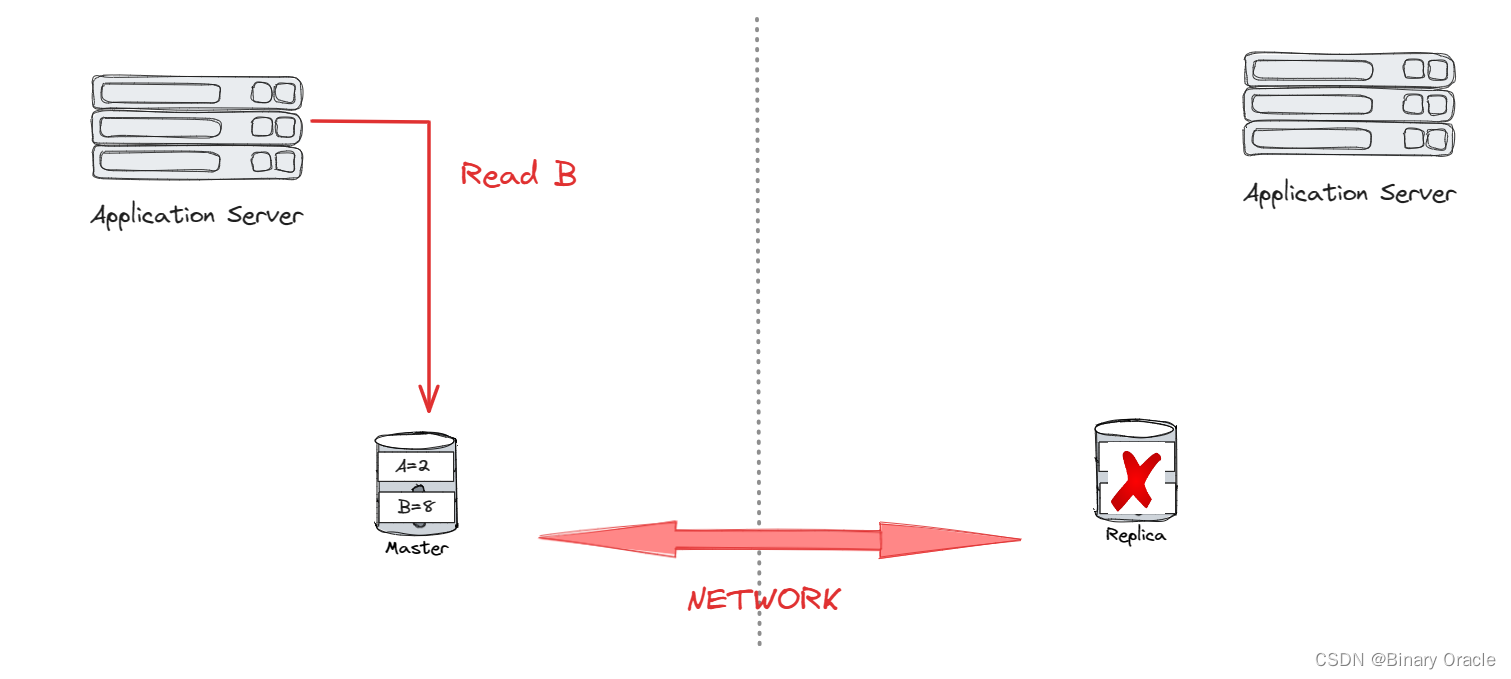
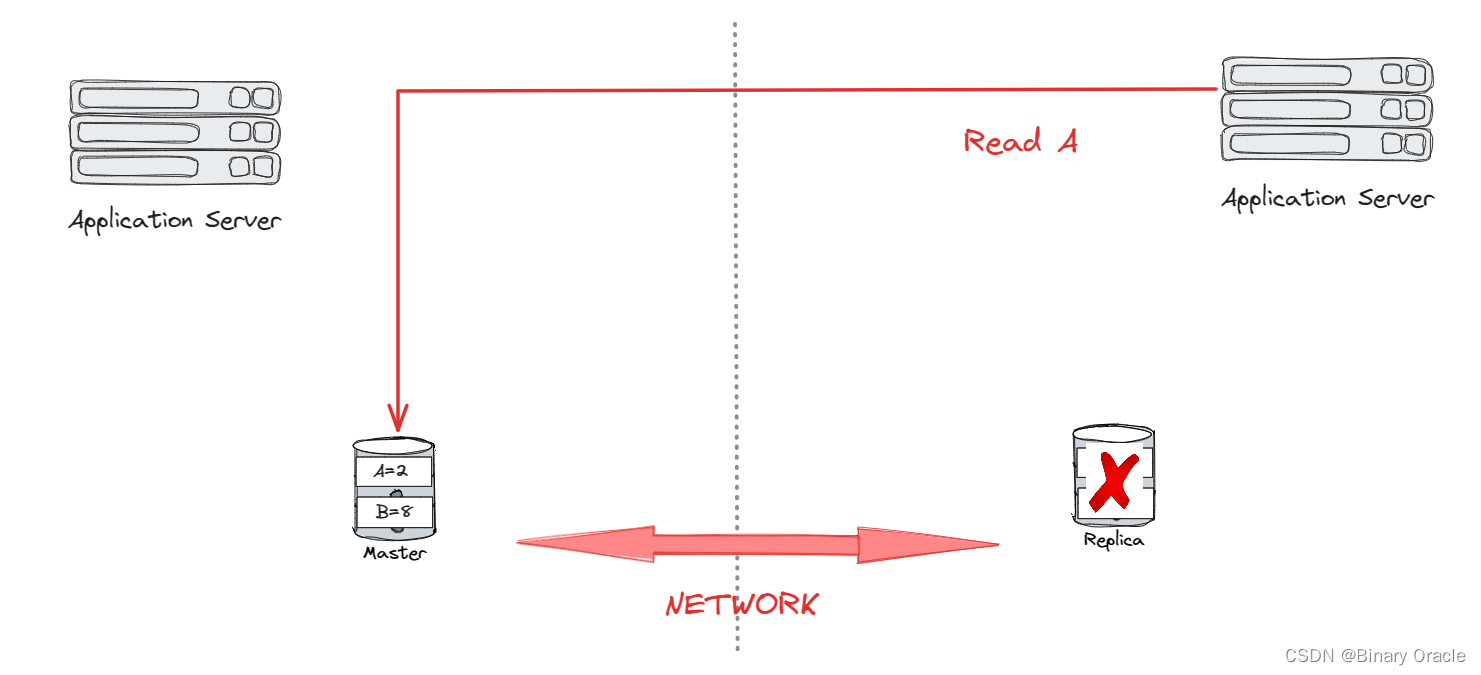
- P : Network Partition Tolerant


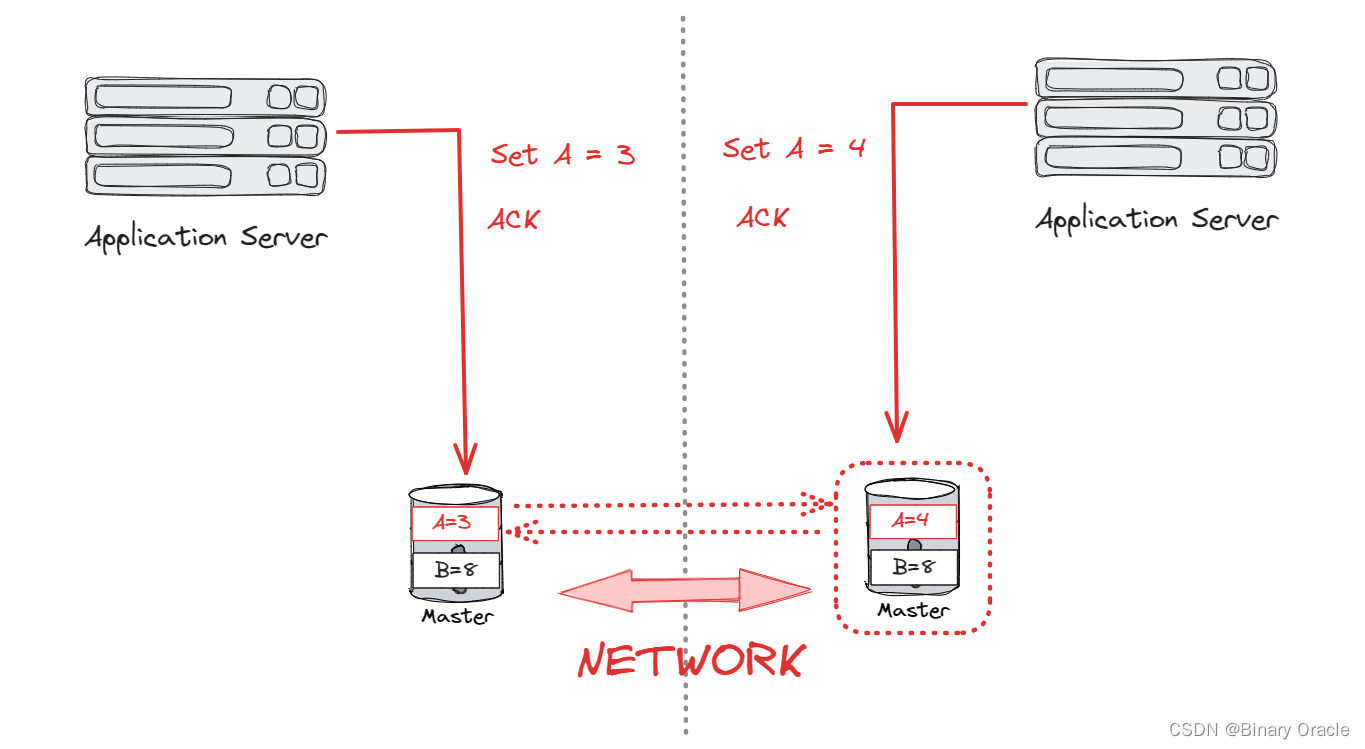
CAP中,通常 P 是给定的,即 network partition 是必然发生的,所有的分布式系统都必须做到 network partition tolerant,因此实际的分布式数据库只能在 consistency 和 availability 之间取舍。
面对故障,DBMS 如何处理决定了它们在 C 和 A 上的取舍。传统关系型数据库或 NewSQL 数据库通常会在多数节点发生故障时停止接受数据写请求;而 NoSQL 数据库会提供事后解冲突的机制,因此只要有部分节点还可用,他们的系统就可以继续运行。
Federated Databases
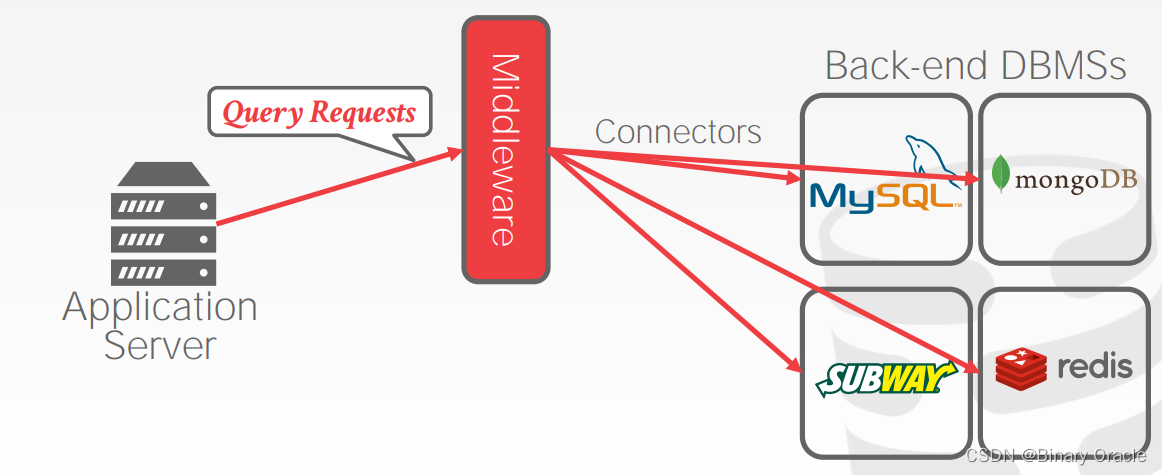
到现在为止,我们都假设我们的分布式系统中每个节点都运行着相同的 DBMS,但在实际生产中,通常公司内部可能运行着多种类型的 DBMS,如果我们能够在此之上抽象一层,对外暴露统一的数据读写接口也是一个不错的想法。这就是所谓的联邦数据库。
然而实际上这个很难,也从没有人把这种方案实现地很好。不同的数据模型、查询语句、系统限制,没有统一的查询优化方案,大量的数据复制,都使得这种方案比较难产。
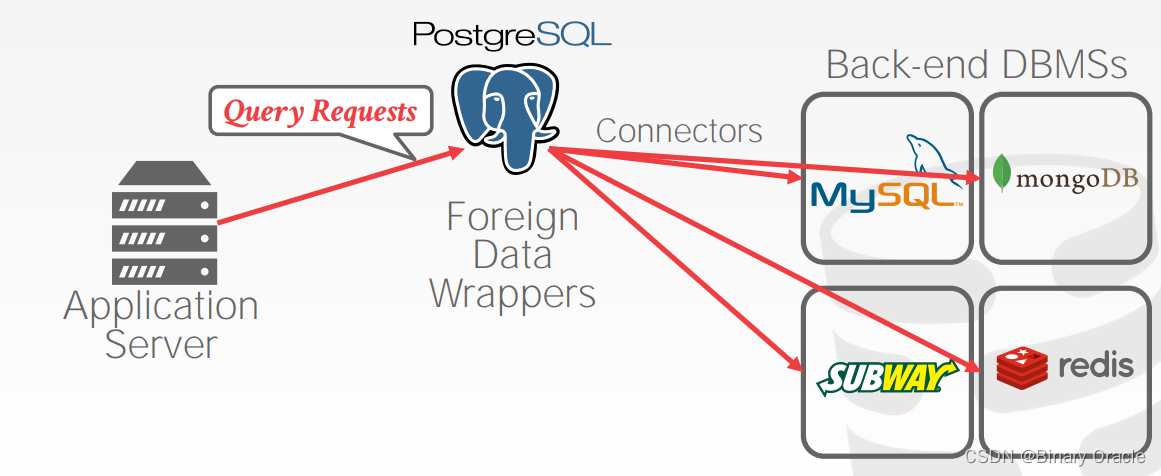
PostgreSQL 有 Foreign Data Wrappers 组件能提供这种方案,它能识别请求的类型并将其发送给相应的后端数据库:
小结
所有针对 Distributed OLTP 数据库的讨论都是基于节点友好的假设,只有区块链数据库假设节点是有恶意的。处理恶意节点问题需要使用不同的事务提交协议。
本节对应教材PDF
paxos协议相关论文:
- The Part-Time Parliament
- Paxos Made Simple
- Paxos Made Live