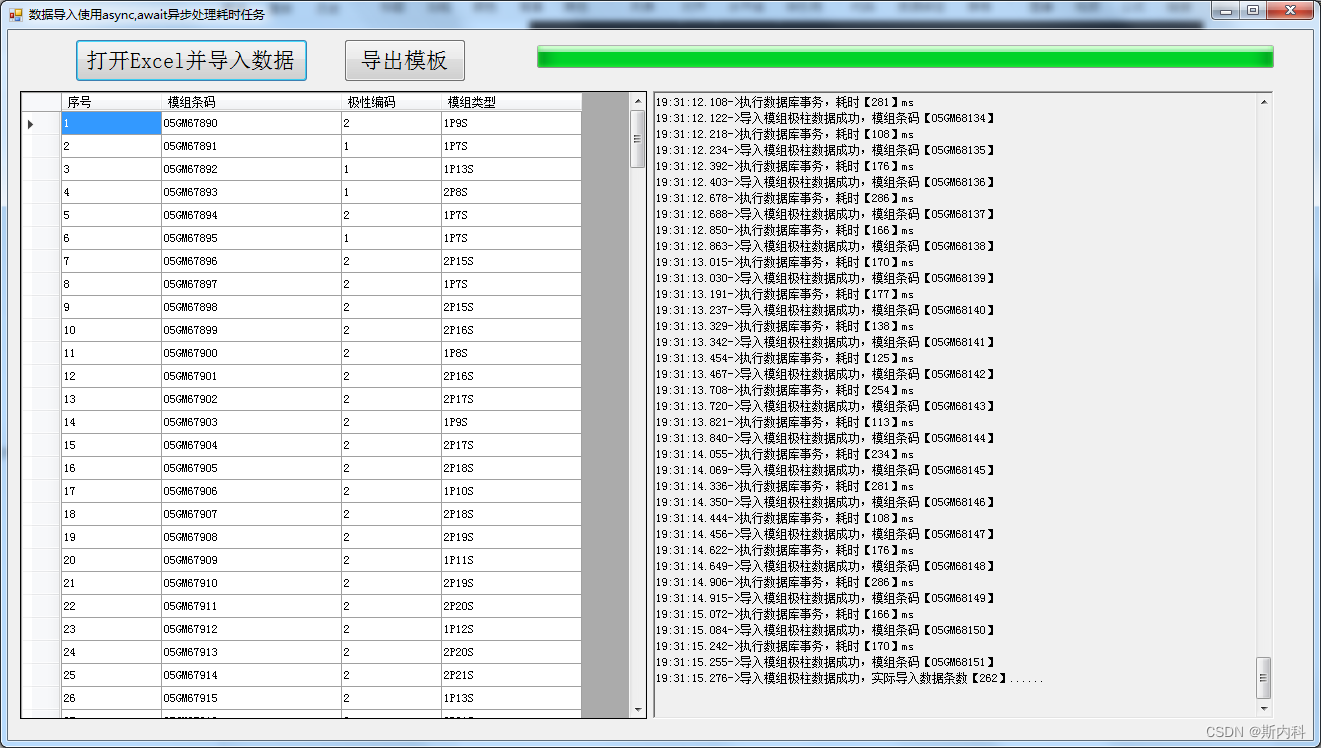
范式
关系
注意:根据阿里开发规范,不再设置数据库的外键,在应用层保证外键逻辑即可
数据库设计
1:1
1:n
设想学生-班级案例,若在班级中保存所有学生的主键,则表长不好预测,表的数据亢余。
所以是在多的一方保存一次1的一方的主键
m:n
在中间多添加一个“关系”实体。
在关系中存储双方的主键,并将组合的主键作为自己的主键(这样两条记录中保存的双方id不会同时相同)
转化成了两个一对多关系,其中关系是多个一方,保存双方的主键
orm
一对多
在1的一方定义一个列表,保存多个’n’的对象
在n的一方保存一个1的对象
“要能找到信息啊,要不然还得再去数据库查,麻烦”
查询的时候通常是需要所有信息的,单单在n的一方知道1的主键没啥用,,另外,即使用了复杂查询,也要有个能在内存中表示出1:n关系的对象来保存。分别取出1和n的n+1个对象,再在内存中读取键值判断关系不方便。
<mapper namespace="studentNamespace">
<resultMap type="zhongfucheng2.Student" id="studentMap">
<id property="id" column="sid"/>
<result property="name" column="sname"/>
</resultMap>
<!--查询选修的java学科有多少位学⽣-->
<!--由于我们只要查询学⽣的名字,⽽我们的实体studentMap可以封装学⽣的名字,那么我们返回
studentMap即可,并不需要再关联到学科表-->
<select id="findByGrade" parameterType="string" resultMap="studentMap">
select s.sname,s.sid from zhongfucheng.students s,zhongfucheng.grades g
WHERE s.sgid=g.gid and g.gname=#{name};
</select>
</mapper>
就是说光select学生表,把记录包装给grade的list里就行了。这个例子没有要查的学科表的信息
<select id="selectUsers" resultType="map">
上述语句只是简单地将所有的列映射到 HashMap 的键上,这由 resultType 属性指定。虽然在大部分情况下都够用,但是 HashMap 并不是一个很好的领域模型。你的程序更可能会使用 JavaBean 或 POJO(Plain Old Java Objects,普通老式 Java 对象)作为领域模型。MyBatis 对两者都提供了支持。看看下面这个 JavaBean:
高级结果映射
MyBatis 创建时的一个思想是:数据库不可能永远是你所想或所需的那个样子。 我们希望每个数据库都具备良好的第三范式或 BCNF 范式==?==,可惜它们并不都是那样。 如果能有一种数据库映射模式,完美适配所有的应用程序,那就太好了,但可惜也没有。 而 ResultMap 就是 MyBatis 对这个问题的答案。
result标签的extends:继承
举个例子,比如一对多,要左连接,因为分类一定要找到,无论有没有属性对应
为什么category7的也来了?难道是左连接,左边的数据查出来了,右边的没查出来也给个7?
但是不左连接,不带属性的直接就没有了,,
多对多前后端设计
多对多被拆成了两个一对多,到底是写一对多查询还是多对多查询呢?
如果关联表(如评论)需要单独页面列出来,就查关联表LIST,因为保存有另外两表的对象,所以另外俩也查出来了
ER图
关系:菱形
实体:矩形
属性:椭圆
- why自动生成的不一样?
对于主键等有不同的叫法(主码等),想知道了临时再查
ER图优化笔记
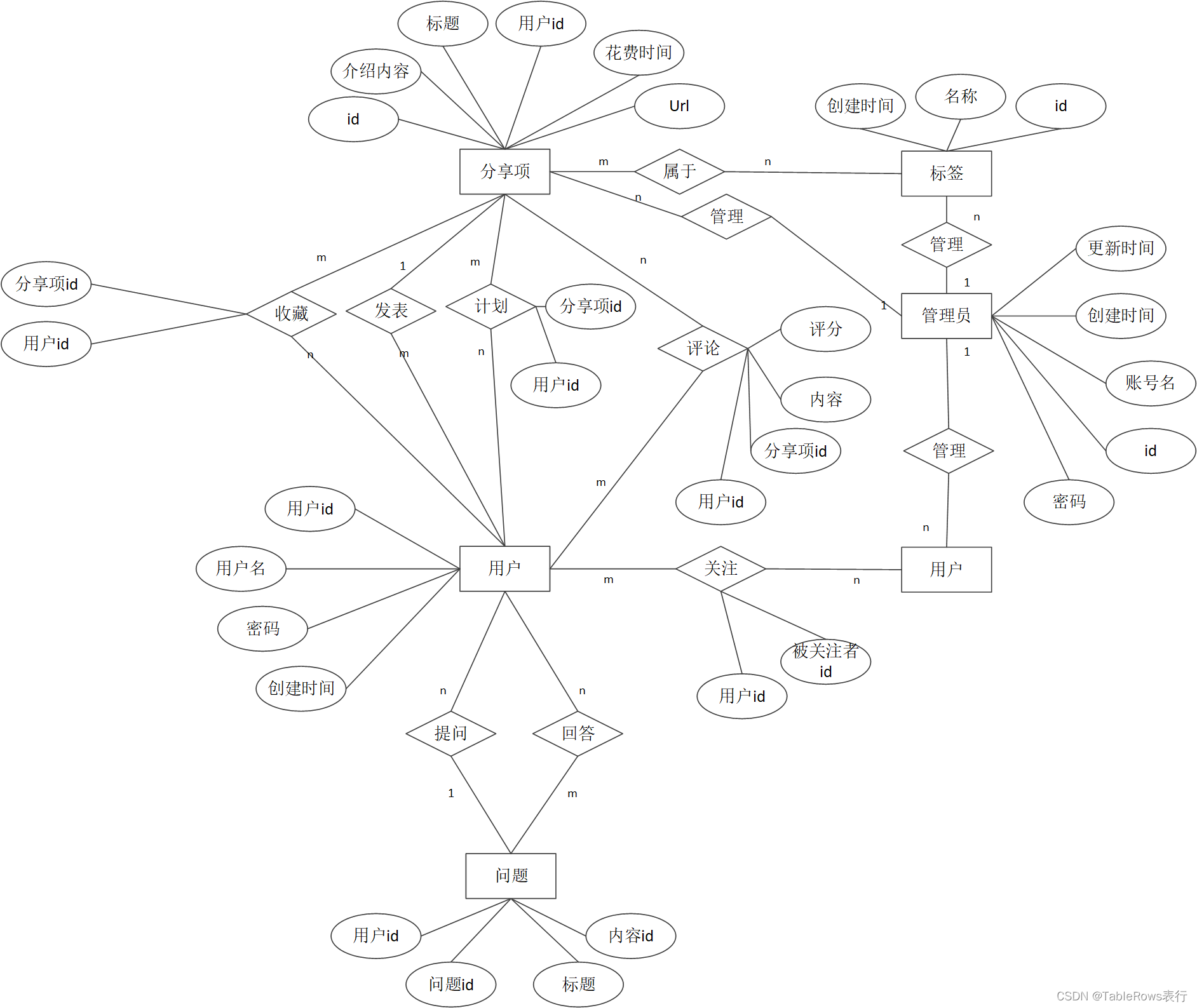
- 多对多关联表不需要在ER图写明双方主键。一对多也不用写另一方的主键。等到设计数据库时自己实现
- 关系类型(m,n)和属性不说明也可以不注明
- 用户和分享项之间的关系太多了,可以考虑把m:n关系拆成一个实体,变成两个m:1。毕竟实体可以是抽象的
主键设计
在微服务、数据库迁移等情景下,自增id可能会出现重复、参照完整性缺失等问题。
如果只是为了唯一id,可以使用雪花算法、uuid。
- uuid随机分布不好建立索引?
uuid缺点:
-
太长了,占空间,索引麻烦、没有可读性
-
为什么不重复?因为和硬件地址有关么?
mysql若设置为自增主键,主键值会不断增加,如果插入了比当前自增值大的主键,则会在最大值的基础上自增;
不论删除了主键值最大的记录,下一个自增的主键值还是在之前的最大值上自增;
如果改变表结构,先取消主键自增再设置主键自增,主键会从当前最大值开始自增;
和innonDB有关
连接
一次查询多表时需要连接。连接是讲多个表按条件生成一个连接表。然后在连接表上按查询条件查询。
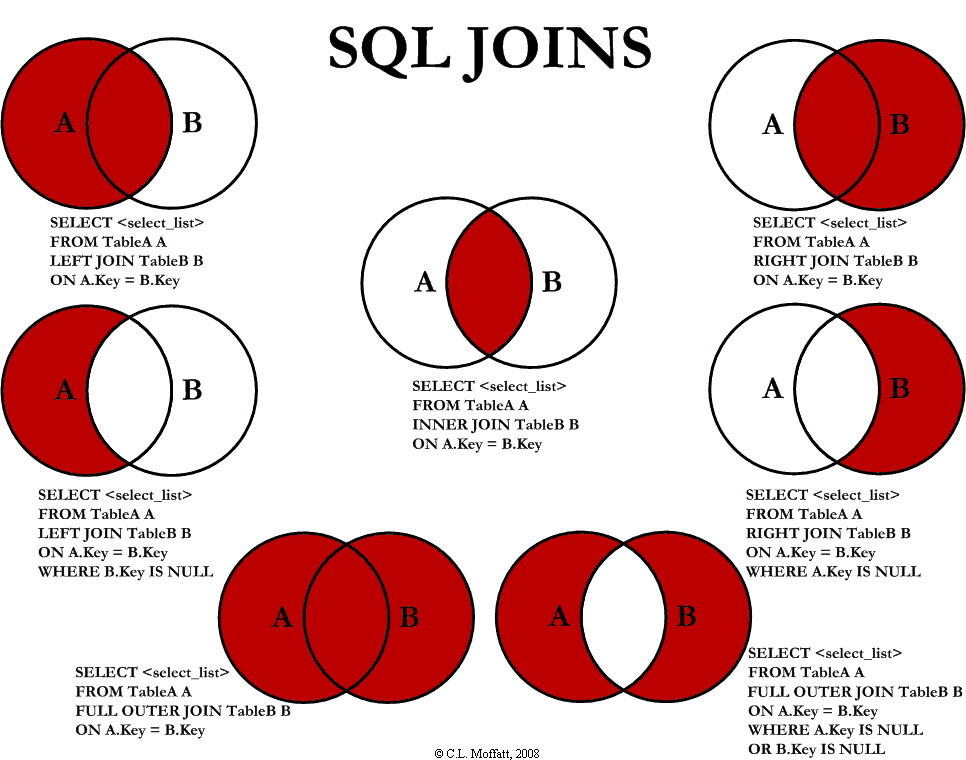
⼀)内连接(等值连接):查询客户姓名,订单编号,订单价格
select c.name,o.isbn,o.price
from customers c inner join orders o
where c.id = o.customers_id;
内连接(等值连接)只能查询出多张表中,连接字段相同的记录
⼆)外连接 outer join :按客户分组,查询每个客户的姓名和订单数
分为左外连接和右外连接
---------------------------------------------------
左外连接:
select c.name,count(o.isbn)
from customers c left outer join orders o
on c.id = o.customers_id
group by c.name;
---------------------------------------------------
右外连接:
select c.name,count(o.isbn)
from orders o right outer join customers c
on c.id = o.customers_id
group by c.name;
---------------------------------------------------
注意:外连接既能查询出多张表中,连接字段相同的记录;⼜能根据⼀⽅,将另⼀⽅不符合相同记录
强⾏查询出来
连接方式的选择
在一次mybatis报错中学到的,之前只会无脑左连接。
左连接时,生成的连接表会有全部的左表的数据;
内连接只有符合连接条件的记录(行);
如果需要左表的全部数据,比如首页列出所有数据,就需要左连接;
如果只是查询符合连接条件的某一个或几个,用内连接;
在Myabtis中,如果只返回一个数据,确查询到了多个,就会报错。
如果只查一个数据就要用内连接。如果返回左表所有内容,会导致报错。
话说左右换个位置不久没区别了。
多表查询时同名字段/别名作用
多表查询时多个表中相同名字的字段可能会覆盖。尽量在设计时不要有同名表存在同名字段。
如果真的这么设计了,可以在查询时用as给字段起别名,并且修改orm框架的关联映射,将列名改为别名
给要返回给应用层的取别名,Sql里可以用表名.列名区分。应用层因为关联映射写的时候没别名,不会区分。
脏数据
范式
sql语句笔记
查询最后一条记录
可以通过order by、desc来对查询到的数据排序,用limit选取其中的部分
阿里开发规范要求数据库设计记录的创建时间和修改时间。如果有创建时间就很好办
last_insert_id()函数:
仅适用于设置自增主键时。获取最后一次插入的主键值。
如果查询时需要筛选条件,那么最后一次插入的记录可能不是筛选条件内的最后一条记录
top
SELECT TOP 1 * FROM table_name
SELECT TOP 1 * FROM user order by id desc; # 降序排列
limit当id超过1000就不适用了吧 ??
mysql默认排序
MyISAM 表
MySQL Select 默认排序是按照物理存储顺序显示的(不进行额外排序)。也就是说SELECT * FROM tbl – 会产生“表扫描”。如果表没有删除、替换、更新操作,记录会显示为插入的顺序。
•InnoDB 表
同样的情况,会按主键的顺序排列。
似乎是按索引排序,如果select的字段中有索引列(比如主键),就会自动按主键升序排序
所以说,不要依赖mysql默认的排序
多表查询、左连接
一对多,双表查询要连接一次
多对多,三表查询要连接两次,各自与中间关联表相连
多表查询时,记得给重名字段起别名。
中间关系表的东西不用select东西了
<select id="selectForShareItemById" parameterType="String" resultMap="ForShareItemResult">
select s.id, s.title, s.descripe, s.time, s.url, s.create_time, s.update_time, s.status, s.user_id,
t.id as tid, t.tag_name
from for_share_item s
inner join for_item_tag it on s.id = it.item_id
inner join for_tag t on it.tag_id = t.id
where s.id = #{id}
</select>
分库分表
原理
即使SQL命中了索引,如果表的数据量超过一千万的话,查询也是会明显变慢的。这是因为索引一般是B+树结构,数据千万级别的话,B+树的高度会增高,每高一层就要多去硬盘查一此索引。
实践
Mybatis-plus分库分表
Sharding-JDBC
逻辑删除
逻辑删除与唯一索引问题:由于数据并未物理删除而知识改变了逻辑删除位,可能造成无法插入同样信息问题
此时要想同时解决防重(幂等性)问题,可以加入分布式锁(高并发下会影响性能)
方案:加一张防重表,在防重表中增加商品表的name和model字段作为唯一索引。
例如:
CREATE TABLE `product_unique` (
`id` bigint(20) NOT NULL COMMENT 'id',
`name` varchar(130) DEFAULT NULL COMMENT '名称',
`model` varchar(255) NOT NULL COMMENT '规格',
`user_id` bigint(20) unsigned NOT NULL COMMENT '创建用户id',
`user_name` varchar(30) NOT NULL COMMENT '创建用户名称',
`create_date` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `ux_name_model` (`name`,`model`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品防重表';
其中表中的id可以用商品表的id,表中的name和model就是商品表的name和model,不过在这张防重表中增加了这两个字段的唯一索引。
在添加商品数据之前,先添加防重表。如果添加成功,则说明可以正常添加商品,如果添加失败,则说明有重复数据。
防重表添加失败,后续的业务处理,要根据实际业务需求而定。
如果业务上允许添加一批商品时,发现有重复的,直接抛异常,则可以提示用户:系统检测到重复的商品,请刷新页面重试。
例如:
try {
transactionTemplate.execute((status) -> {
productUniqueMapper.batchInsert(productUniqueList);
productMapper.batchInsert(productList);
return Boolean.TRUE;
});
} catch(DuplicateKeyException e) {
throw new BusinessException("系统检测到重复的商品,请刷新页面重试");
}
在批量插入数据时,如果出现了重复数据,捕获DuplicateKeyException异常,转换成BusinessException这样运行时的业务异常。
- 好一手异常转换
还有一种业务场景,要求即使出现了重复的商品,也不抛异常,让业务流程也能够正常走下去。
例如:
try {
transactionTemplate.execute((status) -> {
productUniqueMapper.insert(productUnique);
productMapper.insert(product);
return Boolean.TRUE;
});
} catch(DuplicateKeyException e) {
product = productMapper.query(product);
}
在插入数据时,如果出现了重复数据,则捕获DuplicateKeyException,在catch代码块中再查询一次商品数据,将数据库已有的商品直接返回。
如果调用了同步添加商品的接口,这里非常关键的一点,是要返回已有数据的id,业务系统做后续操作,要拿这个id操作。
当然在执行execute之前,还是需要先查一下商品数据是否存在,如果已经存在,则直接返回已有数据,如果不存在,才执行execute方法。这一步千万不能少。
例如:
Product oldProduct = productMapper.query(product);
if(Objects.nonNull(oldProduct)) {
return oldProduct;
}
try {
transactionTemplate.execute((status) -> {
productUniqueMapper.insert(productUnique);
productMapper.insert(product);
return Boolean.TRUE;
});
} catch(DuplicateKeyException e) {
product = productMapper.query(product);
}
return product;
千万注意:防重表和添加商品的操作必须要在同一个事务中,否则会出问题。
顺便说一下,还需要对商品的删除功能做特殊处理一下,在逻辑删除商品表的同时,要物理删除防重表。用商品表id作为查询条件即可。
补充
(1)流水型数据
流水型数据是无状态的,多笔业务之间没有关联,每次业务过来的时候都会产生新的单据,比如交易流水、支付流水,只要能插入新单据就能完成业务,特点是后面的数据不依赖前面的数据,所有的数据按时间流水进入数据库。
(2)状态型数据
状态型数据是有状态的,多笔业务之间依赖于有状态的数据,而且要保证该数据的准确性,比如充值时必须要拿到原来的余额,才能支付成功。
(3)配置型数据
此类型数据数据量较小,而且结构简单,一般为静态数据,变化频率很低。
状态表
OLTP业务方向
能不拆就不拆读需求水平扩展
数据量为千万级,可能达到亿级或者更高
流水表
OLTP业务的历史记录
业务拆分,面向分布式存储设计
OLAP业务统计数据源
设计数据统计需求存储的分布式扩展
规范
记得看阿里巴巴
统一字符集,似乎字符集不同也可能导致多表查询时索引失效
MySQL数据库的事务隔离级别默认为RR(Repeatable-Read),建议初始化时统一设置为RC(Read-Committed),对于OLTP业务更适合。
(4)数据库中的表要合理规划,控制单表数据量,对于MySQL数据库来说,建议单表记录数控制在2000W以内。
(5)MySQL实例下,数据库、表数量尽可能少;数据库一般不超过50个,每个数据库下,数据表数量一般不超过500个(包括分区表)。