目录标题
- B-树的由来
- B-树的规则和原理
- B-树的插入分析
- B-树的插入实现
- 准备工作
- find函数
- insert
- 中序遍历
- B-树的性能测试
- B-树的删除
- B+树
- B+树的元素插入
- B*树的介绍
B-树的由来
在前面的学习过程中,我们见过很多搜索结构比比如说顺序查找,二分查找,搜索二叉树,平衡二叉树,哈希表,如果数据量不是很大能够一次性放在内存中的话上面的结构是没有问题的,如果要处理的数据非常多的话就得对上面的结构进行处理,比如说平衡二叉树,如果数据不是很多的话平衡二叉树的每个节点会存储两个数据,一个是用于比较和查找的关键字K,另外一个就是存储的数据V,如果存储的数据非常多并且每个数据占用的内存非常大的话那这里就得做出更改将存储的数据放到磁盘上,而数据V里面存储的就是对应数据在磁盘上的地址,通过K来对比数据找到目标数据之后就可以根据里面的地址对磁盘进行IO找到相应的数据并对其进行读取,那如果数据的个数非常的多并且关键字所占用的空间大小也很大,导致关键字也存不下去的话这里就又得进行修改,将关键字也存储到磁盘上,内存中每个节点就直接存储数据在磁盘上的地址,那么在查找数据并比较数据的时候就是先通过地址将关键字从磁盘中提取出来然后进行比较,但是这里就存在一个问题我们知道cpu是一个很快的东西,而对磁盘进行读写是一个很慢的过程,尽管通过平衡二叉树可以在log(n)的时间复杂度找到想要的数据,可是因为要对磁盘读取这里的速度也会变的很慢,具体有多慢呢?我们来看看《算法导论》里面的描述:

所以要想快速的在大量数据中找到指定数据,就得减少对磁盘的io次数,那么这个时候有小伙伴会想到哈希表好像可以减少io次数它的时间复杂度是o(1),那这里能不能使用哈希表呢?答案是不行,首先哈希表在面对一些特殊数据时可能会发生很严重的哈希冲突,其次哈希表在搜索数据的时候也不是一次就能够找到这里的o(1)指的是常数次,具体是多少次得看具体的实现,所以哈希表也不能胜任这项工作,那么为了解决这个问题就有了一个新的数据结构叫做B树,这里大家别搞混了啊不是这个B数。
B-树的规则和原理
平衡二叉树效率低的原因是因为要多次从磁盘中提取一个节点的数据进行比较,提取的次数最多为树的高度次,那么B树的思想就是保持搜索二叉树的特性降低树的高度,每次从磁盘中读取多个节点的数据进行比较,比较的方法跟搜索二叉树一样,通过数据的大小关系来做到一次比较排除多个数据,一棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
- 根节点至少有两个孩子。
- 每个分支节点都包含k-1个关键字和k个孩子,其中 ceil(m/2) ≤ k ≤ m ceil是向上取整函数
- 每个叶子节点都包含k-1个关键字,其中 ceil(m/2) ≤ k ≤ m
- 所有的叶子节点都在同一层。
- 每个节点中的关键字从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
- 每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An)其中,Ki(1≤i≤n)为关键字,且Ki<Ki+1(1≤i≤n-1)。Ai(0≤i≤n)为指向子树根结点的指针。且Ai所指子树所有结点中的关键字均小于Ki+1。n为结点中关键字的个数,满足ceil(m/2)-1≤n≤m-1。
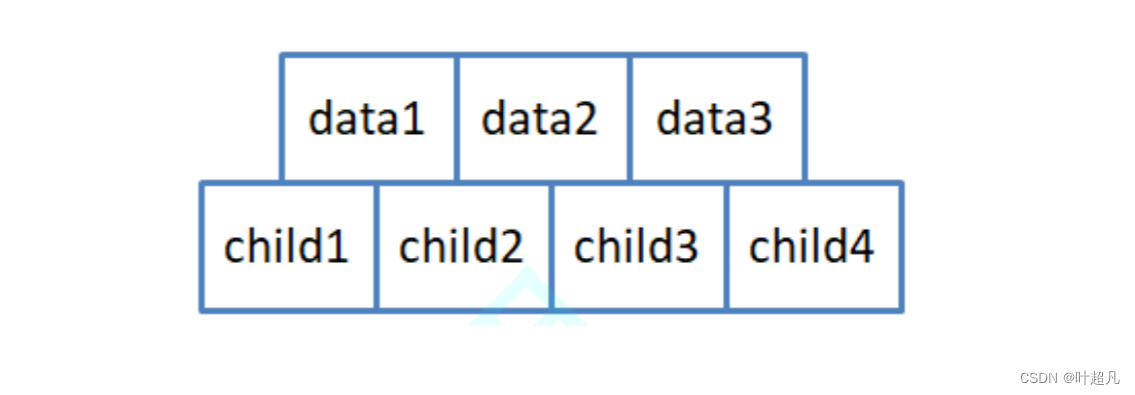
假设m的值等于3,那么通过规则二可以知道每个分支节点里面至少存在一个关键字和两个孩子,最多含有2个关键字和3个孩子,那么节点就长下面这样:

那么这里就有个问题当前节点能不能存储一个关键字和三个孩子呢?答案是不能的因为规则而规定了每个节点都包含k-1个关键字和k个孩子,也就是说不管分支节点的内部数据怎么样,该节点内孩子的数目一定是要比关键字的数目多一,那么这一点也恰好反应了规则一的内容我们知道根节点一定存在一个关键字,那么根据规则二便可以知道根节点一定存在两个孩子,这里大家要知道的一点:虽然我们上面画的关键字最多有两个孩子最多有三个,但是在实现的过程中我们为了方便节点的分裂我们会多加一个上去也就是说当M等于3时孩子最多有4个关键字最多有3个:
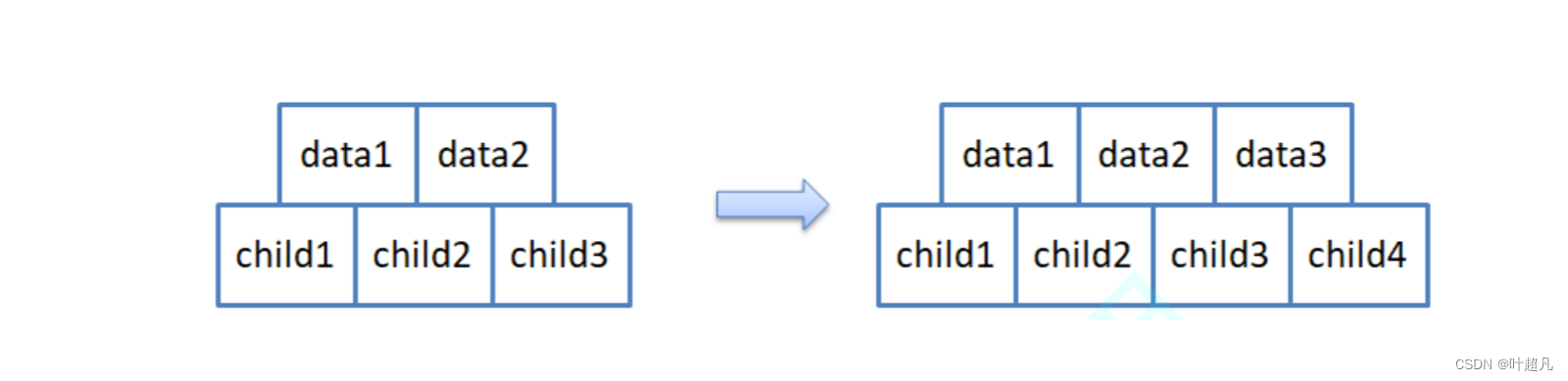
我们上面描述的是分支节点的内部情况,而对于叶子节点则是包含k-1个关键字,其中 ceil(m/2) ≤ k ≤ m,那么这就对应的是规则三,而规则四就是告诉我们所有的叶子节点都处于同一层,也就是说B树的每条路径的长度都是一样的,规则五和规则六可以放到一起来理解,节点里面的child表示一个指针,它指向的是一个子树,子树里面也存储着很多节点,而规则五和六就是告诉我们子树child1中节点的值一定比关键字data1要小,data1的值又比child2子树中的所有节点都要小,child2子树中的所有值都要比关键字data2,data2的值又比child3子树中的所有值要小,那么这就是每个节点中数据的规律,当我们要查找一个数据的时候就可以利用这个规律,比如说dest数据比data1要大,那么我们就知道它肯定不会在child1子树里面,如果它比data2要小的话那么它一定在child2里面,那么这个时候就可以用相同的规律在child2的根节点里面进行查找,那么这就是B树的规则和原理,接下来我们来B树是如何生成的。
B-树的插入分析
假设M的值等于3,那么这个B树里面就应该存储2个关键字和3个指针,但是为了方便后面节点的分裂这里就各添加一个元素:
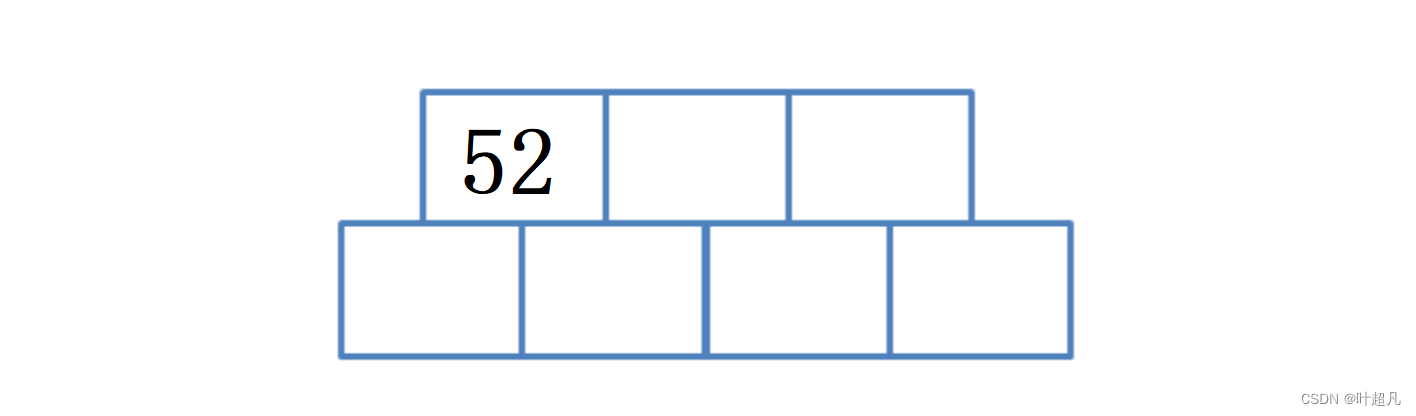
那么接下来就要往树里面插入以下数据:52 ,139, 75, 49, 145, 36,50,47,101,插入52时b树里面就只有一个节点所以B树里面也就不存在指向子树的指针,那么这里的图片就是这样:
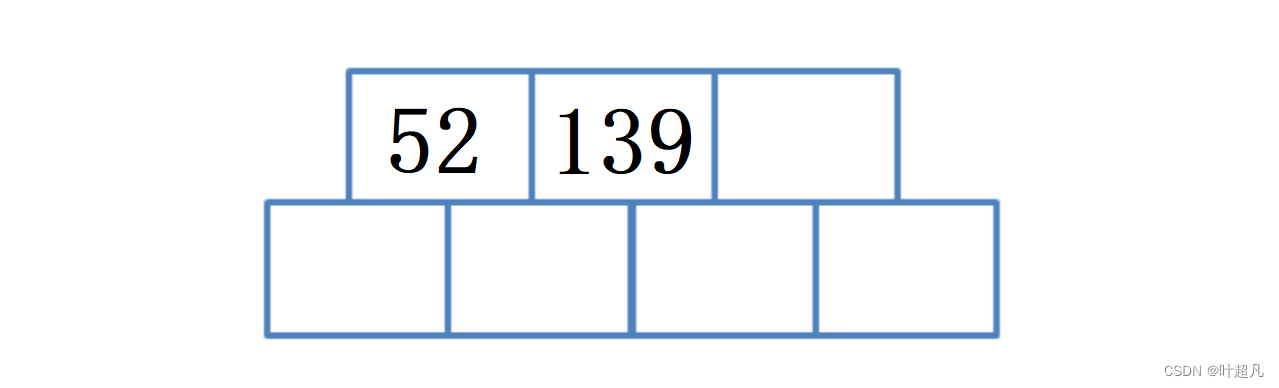
那么插入数据139时,该数据就会紧接着52的后面:
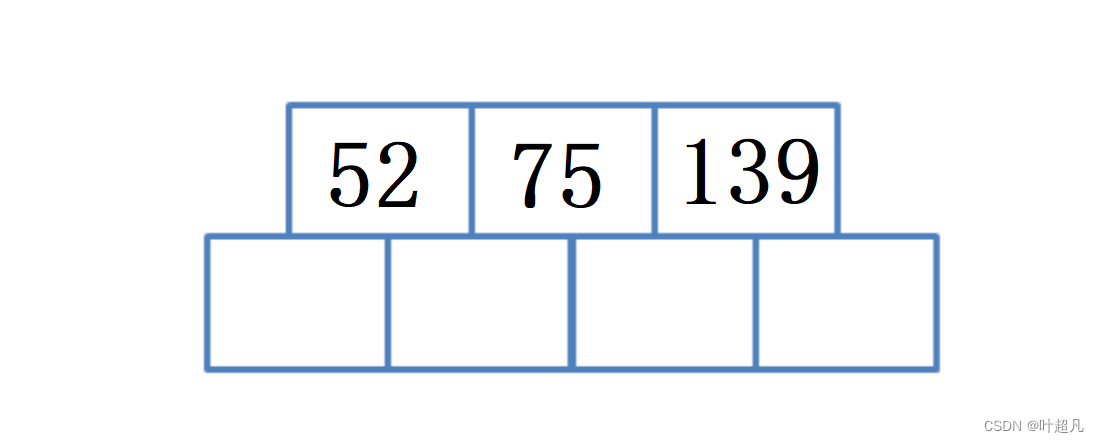
按照规则来说当前节点存储的关键字已经满了,但是为了方便后面的分裂这里还可以存储一个关键字,因为75比52大比139小,所以75就应该插入到中间位置,那么这里的图片如下:
当一个节点的空间用完时就得对这个节点进行分裂,分裂的方法是创建一个新节点出来,然后将已满的节点拷贝一半的数据到新节点里面这里拷贝的顺序是从右往左进行拷贝,那么这里存有三个节点所以就是将3/2个节点移动到另外一个节点里面,那么这里的图片如下:
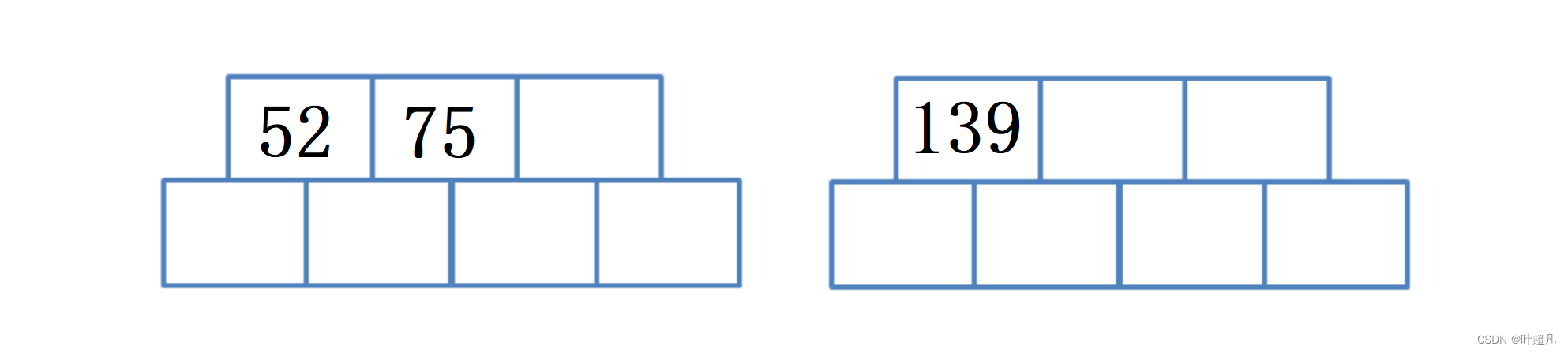
但是仅这里做的话无法将两个节点连接起来,所以这个时候再创建一个节点让这个节点作为B树的根,然后将老节点的最右边的数据(这里就是75)移动到根节点(父节点)里面,并且根节点(父节点)的第一个指针指向老节点,第二个指针指向新节点,那么这里的图片就变成下面这样:
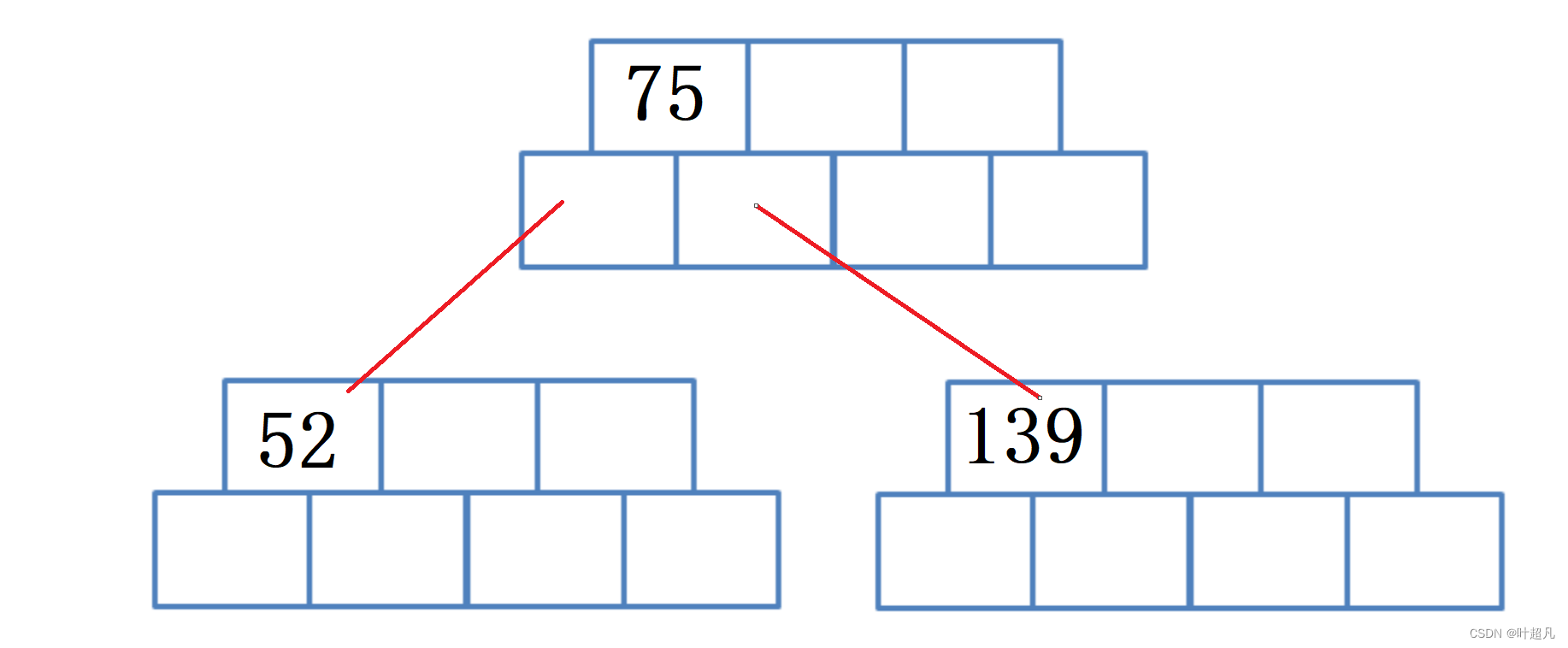
然后插入数据49,因为49比75小所以49应该在75左边的子树,又因为49比52要小所以49应该在52的前面:
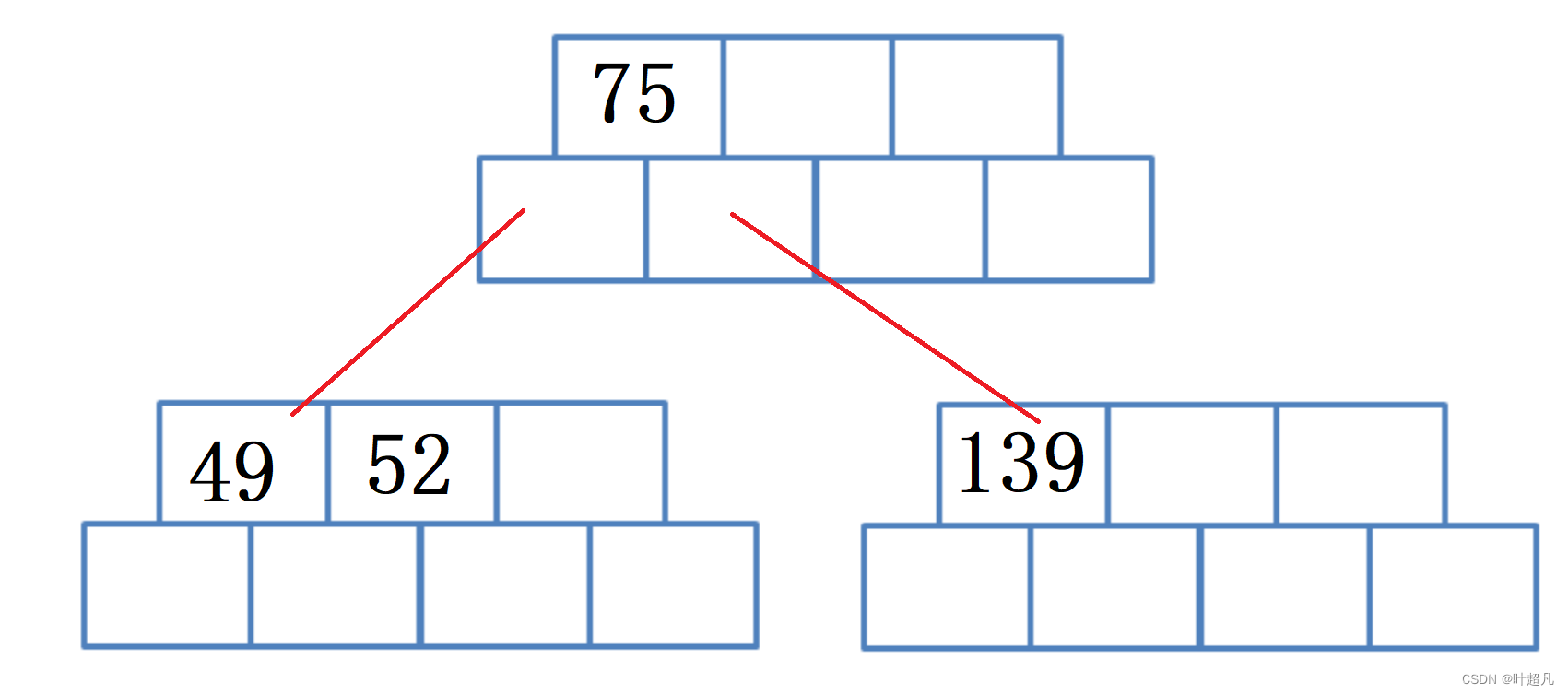
然后插入数据145,因为145比75要大所以他应该在75右边的子树,又因为145比139要大所以他应该在139的右边:
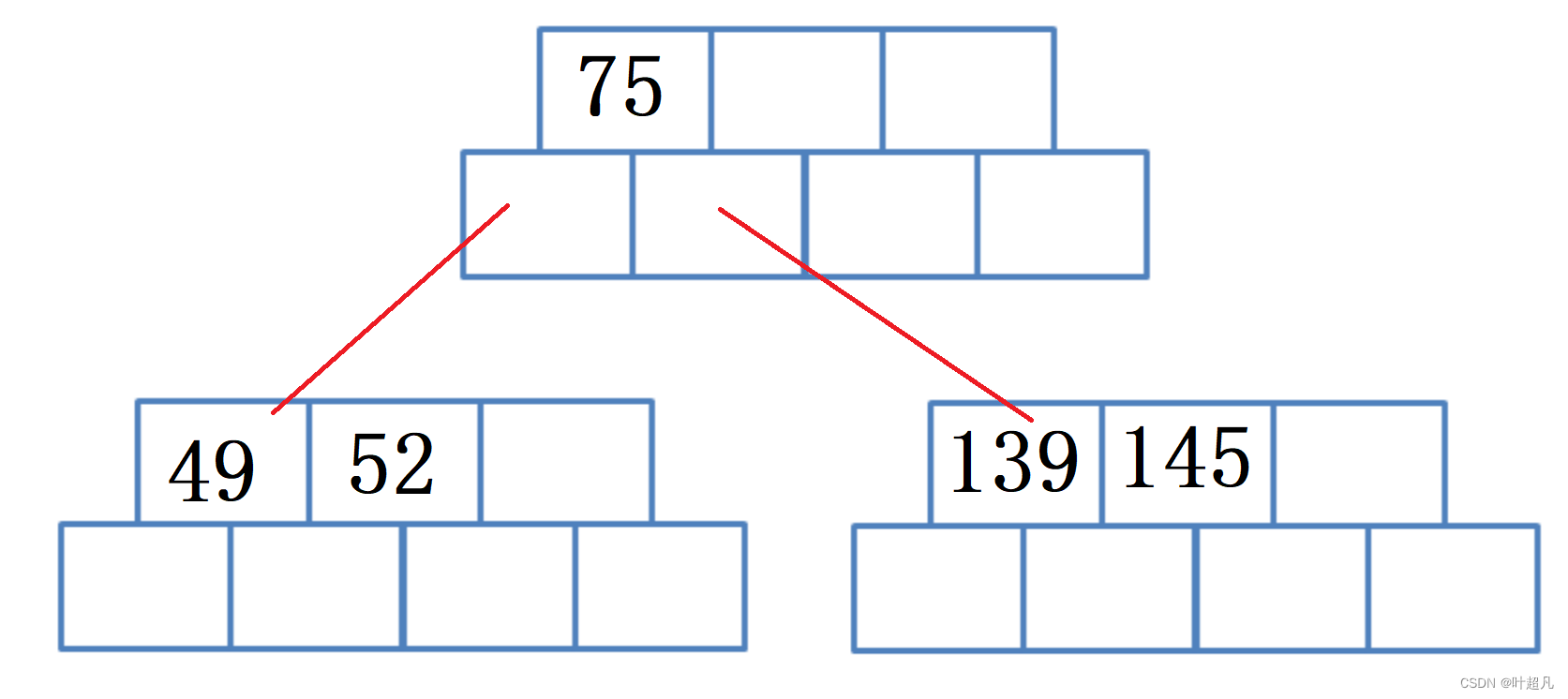
然后插入数据36,因为36比75要小所以他应该75左边的子树,又因为26比49要小所以他应该插入到49的左边:
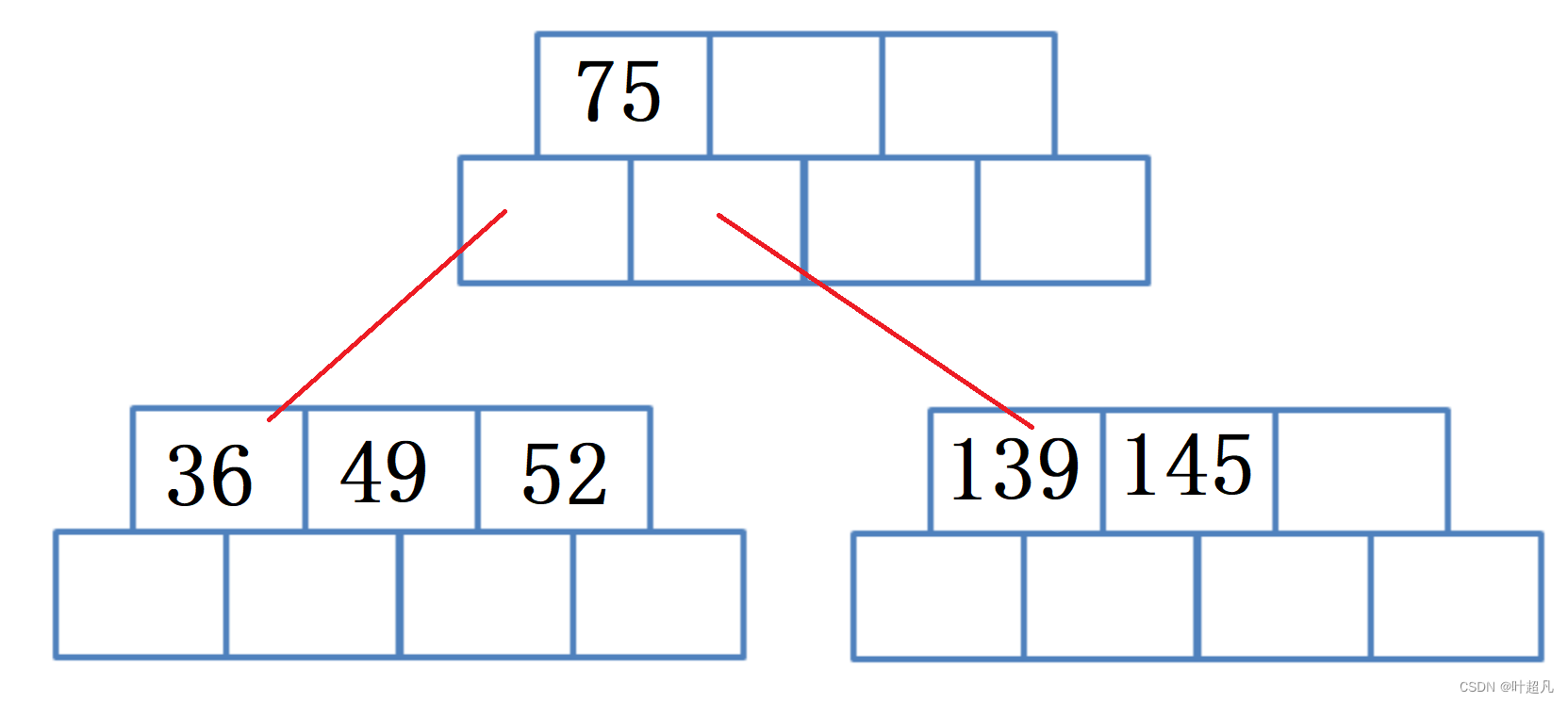
那么这个时候又出现一个吃饱了的节点,所以这个时候得对该节点进行分裂,创建一个新的节点将已满节点的一半数据(52)移动进来,然后让父节点的中的一个指针指向自己,但是这里有个问题:我们说每个节点中指针的数目一定比关键字的数目大一,如果按照上面的步骤做的话会导致指针的数目比关键字的数目大二就变成了下面这样:
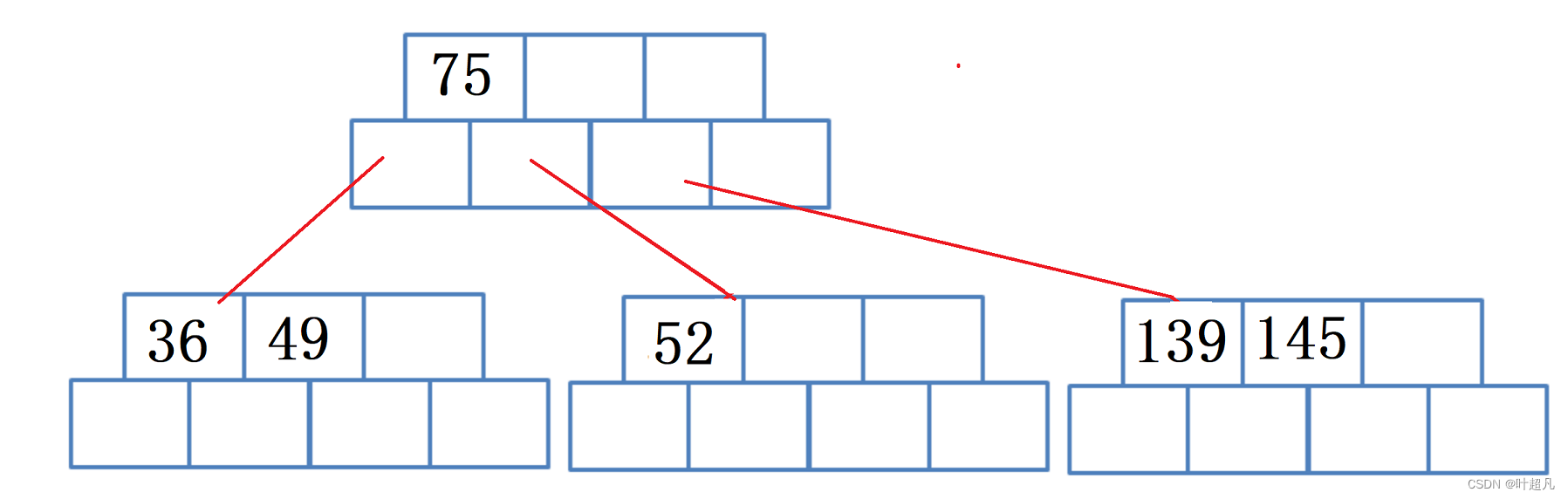
所以为了解决这个问题我们还得将老节点中最右边的数据移动到父节点里面,所以这里大家可以发现不管是创建根节点还是已经有了父节点,在节点分裂的时候都要将原来节点中的一个元素移动到父节点或根节点里面来保证关键字和指针的平衡,那么这里的图片如下:
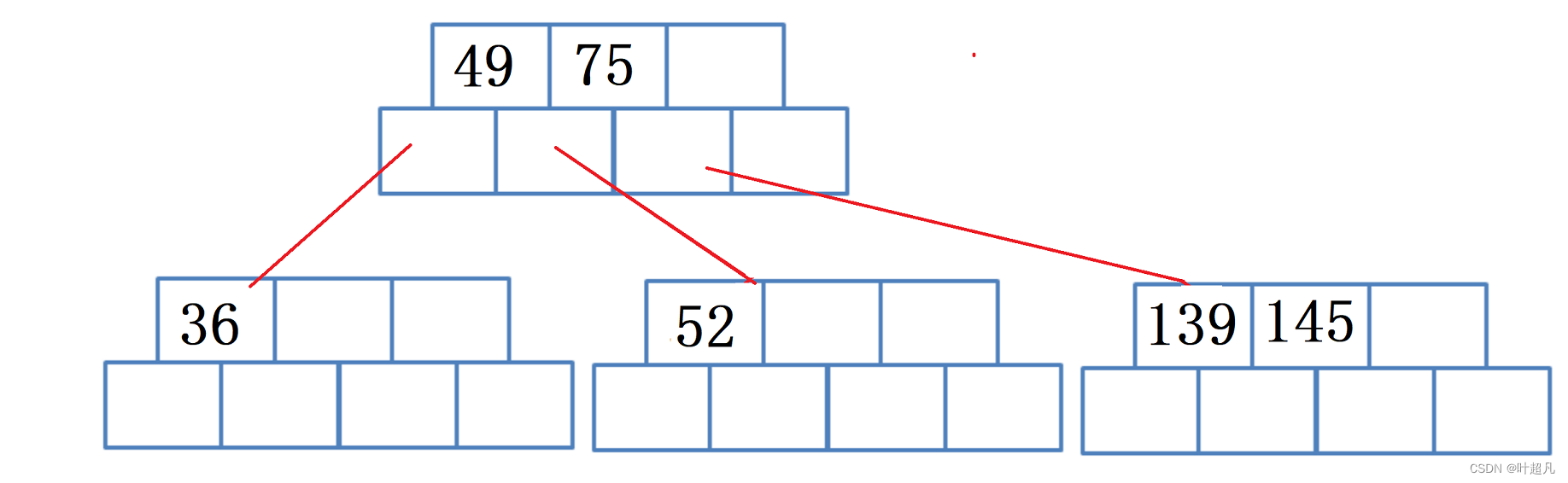
然后插入数据50,因为50比49大比75小所以50应该插入到49和75之间的子树:
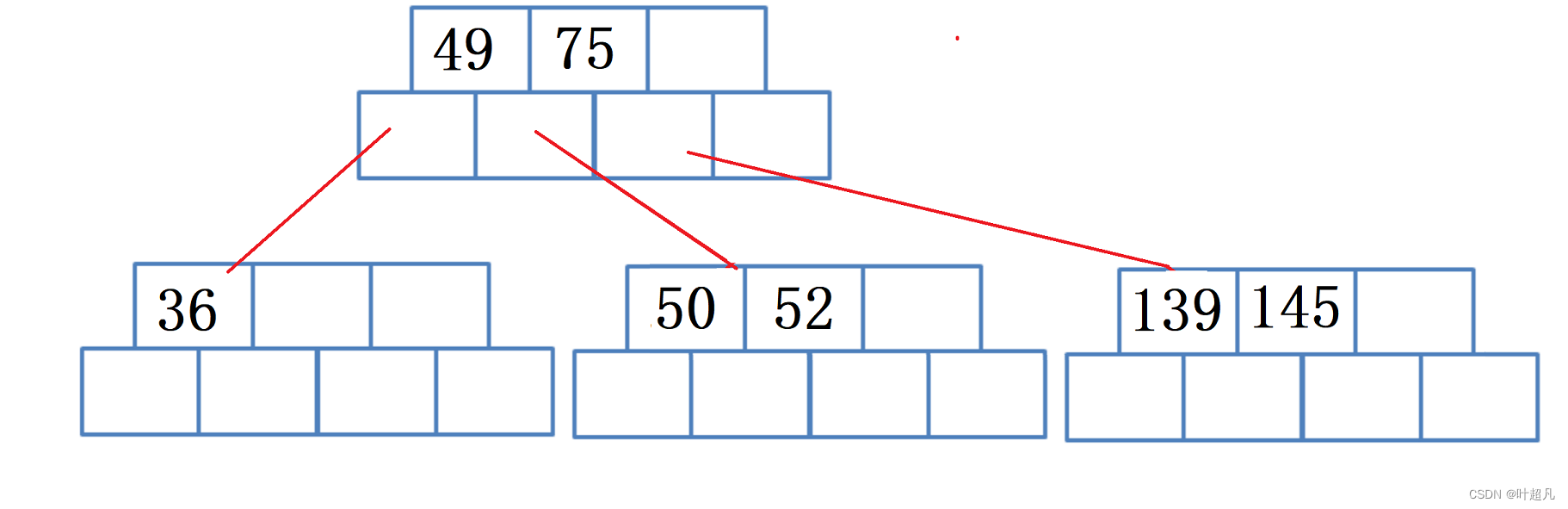
同样的道理插入47之后图片就变成了下面这样:
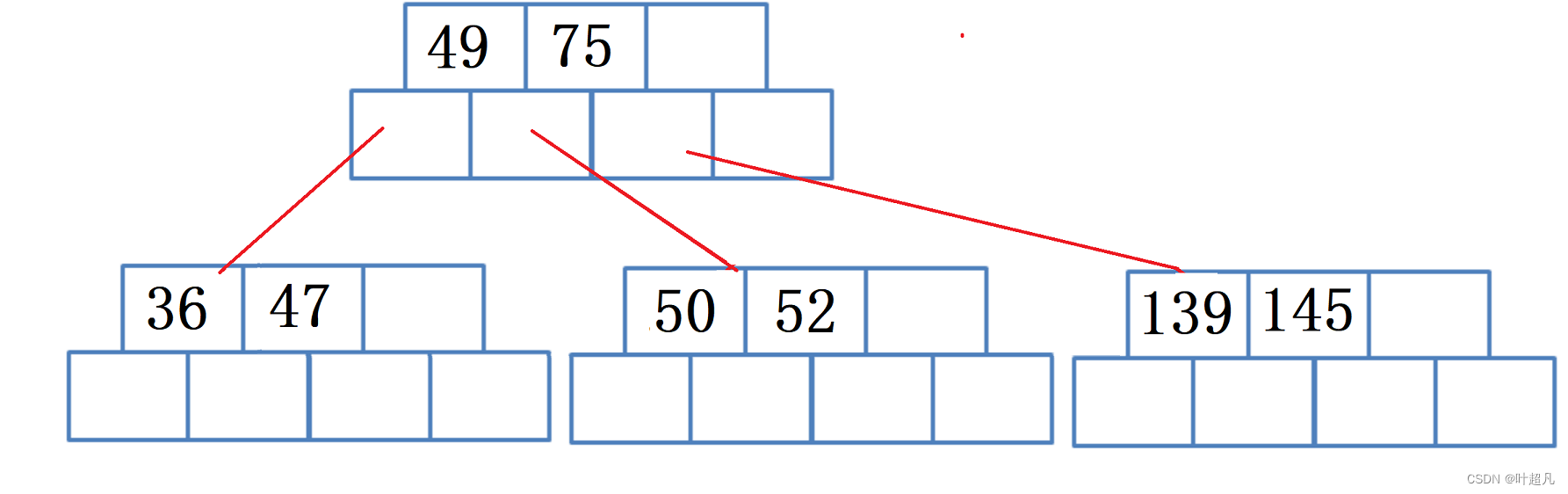
然后插入数据101图片就会变成下面这样:
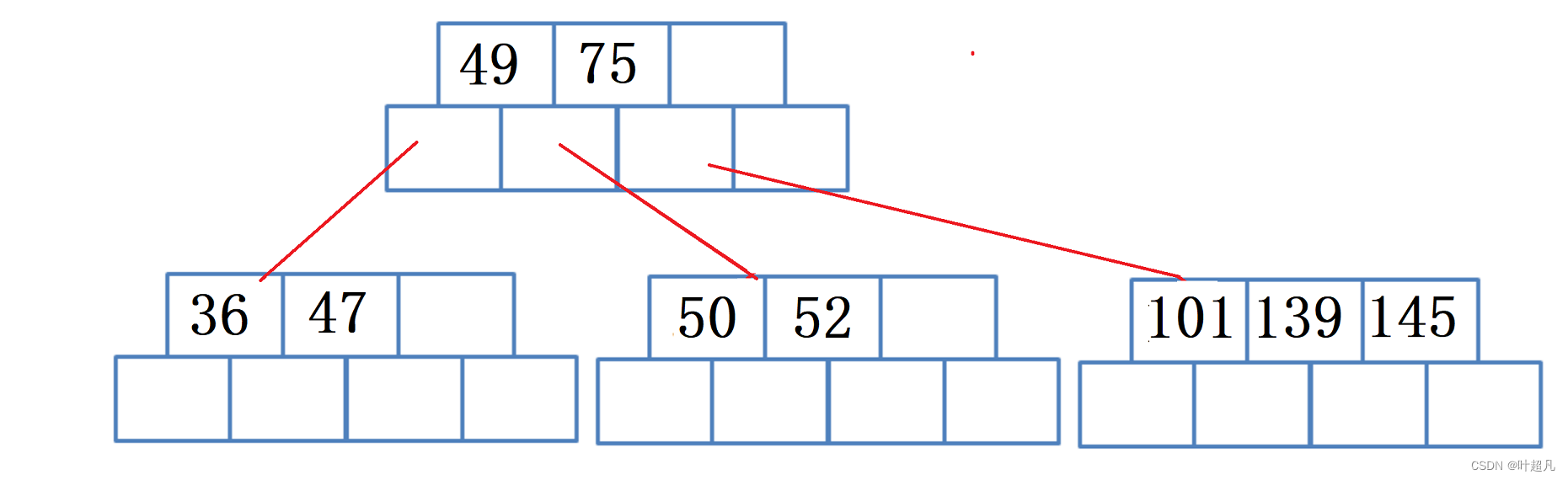
那么这里就又出现了一个吃饱了的节点,所以得再创建一个节点然后将已满节点的一半移动到新节点里面,然后将老节点中最右节点移动到父节点里面,那么这里的图片就变成下面这样:
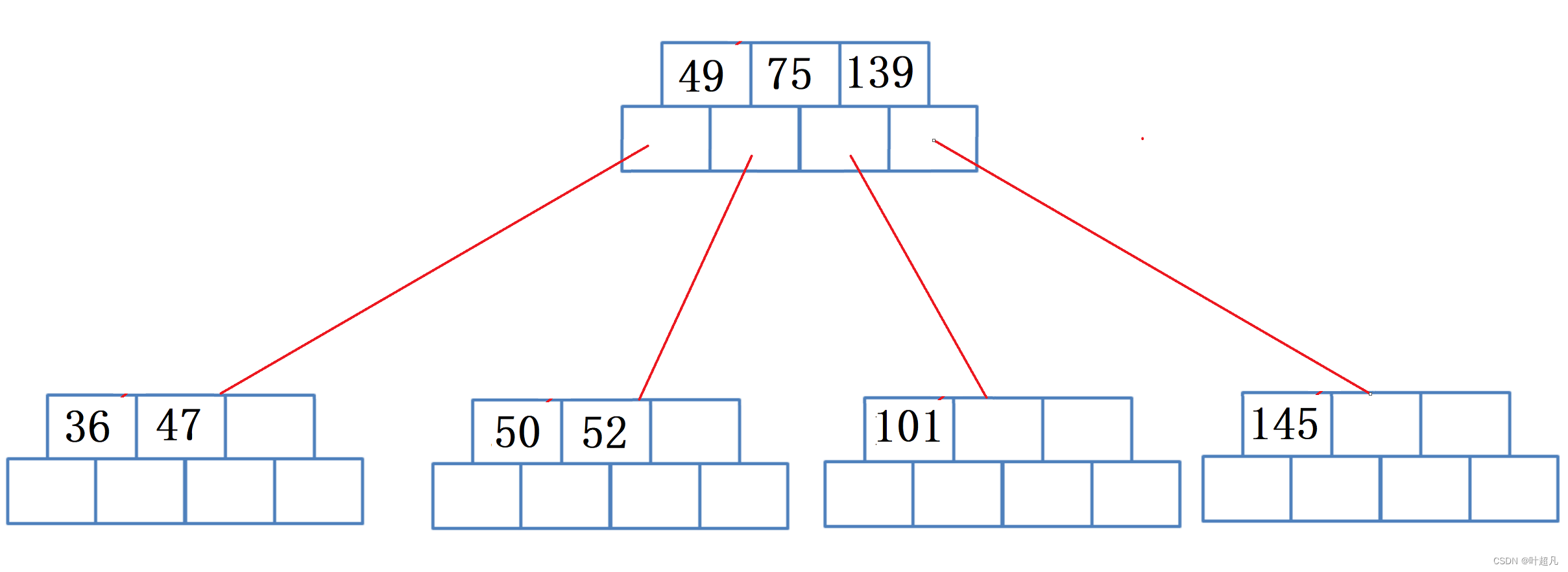
通过图片我们可以发现子节点进行分裂之后,父节点吃饱了所以在插入节点的过程中很可能会出现连续的分裂情况,那么这个时候还得进行分裂,因为这里是对根节点进行分裂,所以我们得创建两个节点,一个节点做根一个节点做原来根节点的兄弟,那么这里的图片如下:
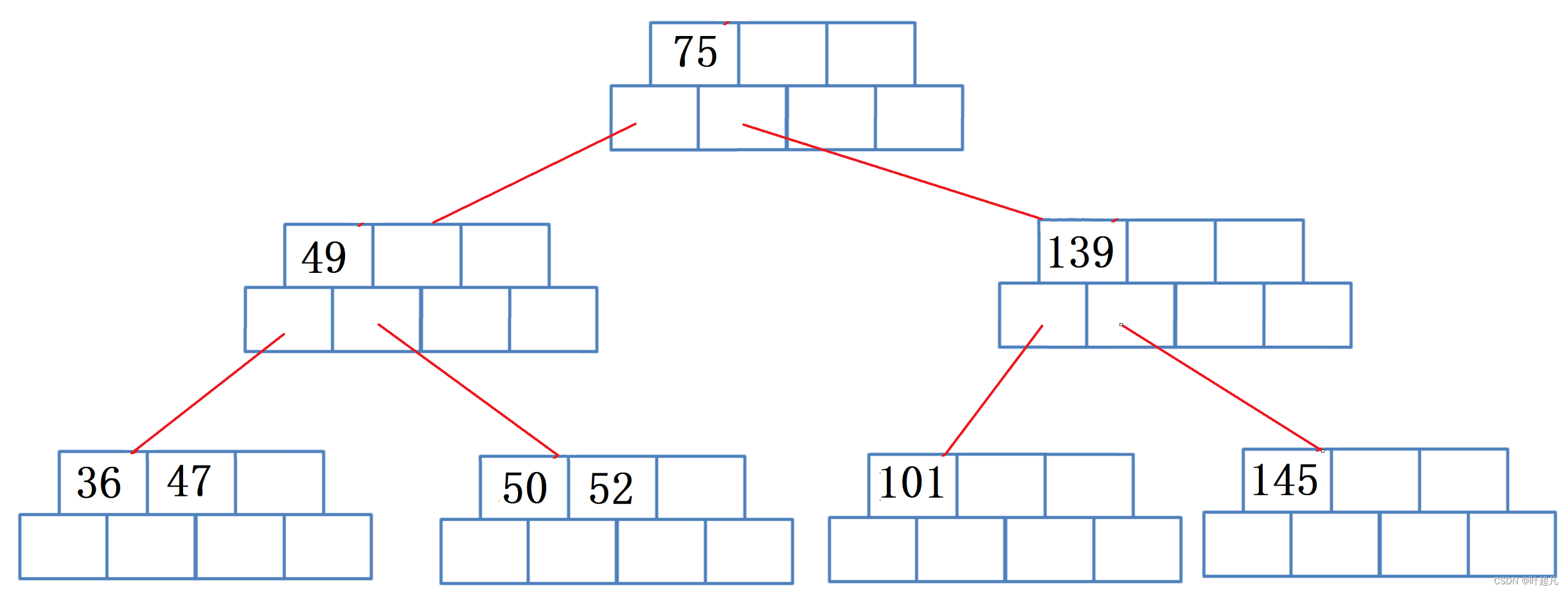
那么这就是节点插入的过程。这里有个细节大家要注意一下:创建兄弟节点之后要会将一半的关键字拷贝过去,但是拷贝的同时要将对应的指针也拷贝到兄弟节点里面,并且转移n个关键字就得转移n+1个指针,那么这就是节点插入的过程,接下来我们要模拟实现B树。
B-树的插入实现
准备工作
首先每个节点里面会存有很多的数据,那么这里我们就得创建一个类来描述每个节点并且这个类得是一个模板类,模板中存在两个参数一个参数用来表示关键字或者指针的类型,另外一个参数用来表示当前树的阶树
template<class K,size_t M>
struct TreeNode
{
};
节点中需要一个K类型的数组来关键字数组的大小为M,然后需要一个TreeNode类型的指针数组用来存储子树的地址数组的大小为M+1,因为节点满了之后需要对父节点插入数据,所以还需要一个指针用来指向当前节点的父节点,为了方便判断节点是否需要分裂这里就再创建一个变量用来记录当前节点的个数,那么构造函数里面就将指针数组全部初始化为nullptr,将K类型的数组全部初始化为K类型的默认构造,将计数变量初始化为0指向父节点的指针初始化为空,那么这里的代码如下:
struct BTreeNode
{
BTreeNode()
{
for (int i = 0; i < M; i++)
{
_keys[i] = K();
_subs[i] = nullptr;
}
_subs[M] = nullptr;
_parent = nullptr;
_n = 0;
}
BTreeNode* _parent;//指向父节点
K _keys[M];//存储关键字或者指针
BTreeNode* _subs[M + 1];//指向子树的指针数组
size_t _n;//记录当前节点的个数
};
然后可以创建一个B数类,这个类也是一个模板类并且模板的参数和节点的参数一样,在这个类里面就只有一个指向节点的指针,那么这里代码如下:
template<class K, size_t M>
class BTree
{
typedef BTreeNode<K, M> Node;
public:
private:
Node* _root=nullptr;
};
那么准备工作到这里就结束了,接下来我们要实现B树的查找函数。
find函数
find函数需要一个K类型的参数并且返回类不能只为bool,因为我们需要通过find函数来找到数据所在的地址并且还能够获取到数据,所以返回值的类型为pair类型并且pair的第一个参数表示节点的地址第二个参数用来表示节点中的第几个元素,那么这里函数声明就长这样:
pair<Node*, size_t> find(const K&)
通过之前的规律我们知道指针数组第i+1号元素指向的所有节点一定是比关键字数组中第i号元素大比i+1号元素小,所以我们就可以使用循环来进行比较,如果K的值比关键字数组第i号元素小的话就跳转到指针数组中的第i号元素那么这里我们就可以创建一个指针变量cur来进行跳转,因为根节点指针数组的每个元素都为空,所以当查找的元素不存在时cur指针一定会走向根节点并且值为空所以判断循环的条件就可以是cur的值
pair<Node*, size_t> find(const K& key)
{
Node* cur = _root;
while (cur)
{
}
return make_pair(cur, -1);
}
因为指针数组的数目比关键字数组多一个所以我们先创建一个变量用来记录找到元素的下标,创建while循环如果i的值比当前节点内部元素数目要少的话就执行循环,如果K的值比当前下标的元素要大的话就对i++,如果小的话就直接break结束循环,如果相等的话就直接返回当前的下标和节点的地址,循环结束之后我们就得到元素的小标然后对cur进行跳转即可,那么这里打代码如下:
pair<Node*, size_t> find(const K& key)
{
Node* cur = _root;
while (cur)
{
size_t i = 0;
while (i < cur->_n)
{
if (key < cur->_keys[i])
{
break;
}
else if (key > cur->_keys[i])
{
i++;
}
else
{
return make_pair(cur, i);
}
}
cur = cur->_subs[i];
}
return make_pair(cur, -1);
}
我们知道一个函数是可以在另外一个函数中使用的,我们知道往容器里面插入一个数据的时候一定得先找数据所在的地方,所以按道理来说我们应该可以在insert函数里面使用find函数,可是这里存在一个问题,当前容器是不支持插入相同数据的,而find函数在找不存在的容器时会返回空指针,所以这里就出现问题我们上面的实现导致find函数用不上,那么这里就可以做出一点改进,再创建一个parent指针用来记录查找指针的父节点,这样当节点存在就返回cur指针如果节点不存在就返回parent指针,这样在insert函数里面使用find函数我们就可以知道元素应该插入到哪个位置上,如果是判断节点是否存在的话我们依然可以通过pair的第二个元素进行判断,那么这里的代码如下:
pair<Node*, size_t> find(const K&)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
size_t i = 0;
while (i < cur->_n)
{
if (K < cur->_keys[i])
{
break;
}
else if (K > cur->_keys[i])
{
i++;
}
else
{
return make_pair(cur, i);
}
}
parent = cur;
cur = cur->_subs[i];
}
return make_pair(parent, -1);
}
insert
insert函数需要一个K类型的参数,因为插入的数据存在相同值所以该函数的返回类型为bool类型,如果出现相同值就返回false,如果插入成功就返回true:
bool insert(const K& key)
因为插入的树里面可能一个元素都没有所以在函数的开始得用if语句来进行一下判断,如果当前对象的root变量等于空的话就new一个Node然后让root指针指向这个节点,将节点的第一个关键字复制为key,最后将该节点的_n变量加一:
bool insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node;
_root->_keys[0] = key;
_root->_n++;
return true;
}
}
如果不为空的话就表明当前的树有元素,那么这个时候就可以创建一个pair类型的变量来接收find函数的返回值,如果变量的第二个参数为-1就表示当前的容器中存在相同值然后就直接返回false,如果第二个元素大于等于0就开始执行
bool insert(const K& key)
{
pair<Node*, K> ret = find(key);
if (ret.second >= 0)
{
return false;
}
else
{
//开始执行插入
}
}
ret变量里面记录了元素应该插入的节点,那么这个时候就可以创建一个for循环将插入位置往后的元素都向后挪动一个位置,这里大家要注意一下挪动关键字的同时还得挪动关键字对应的孩子指针,因为数据的挪动不仅仅出现在一个节点,在很多节点都会有所以将这个功能放到一个函数里面,在叶子节点里面挪动数据不需要连接孩子,但是在分支节点里面插入数据是因为下面的节点出现了分裂创建出来了新的节点从而往上面插入了数据,那么这个时候我们不仅得插入数据还得连接新创建的子节点和子节点的父节点,那么这个函数就得存在三个参数一个表示插入的关键字,一个表示关键字插入的节点,最后一个就表示关键字对应的子节点,那么这里的函数声明如下:
void InsertKey(Node* node, const K& key, Node* child)
//node表达当前存在的节点,key表示插入的关键字,child表示关键字对应的孩子节点
然后在函数里面就先通过for循环找到节点要插入的位置,在查找的过程中顺便移动元素那么这里我们就从后往先进行查找,首先创建一个创建一个变量n记录当前节点的最后一个元素的位置,然后创建while在循环里面将元素进行挪动循环执行的条件就是n的值大于等于0,在循环里面添加一个if语句进行判断,如果当前位置的元素大于key就对n的值减一,如果当前元素的值小于key就直接使用break来结束循环:
void InsertKey(Node* node, const K& key, Node* child)
//node表达当前存在的节点,key表示插入的关键字,child表示关键字对应的孩子节点
{
int n = node->_n-1;
while (n>=0)
{
if (key < node->_keys[n])
{
node->_keys[n + 1] = node->_keys[n];
node->_subs[n + 2] = node->_subs[n + 1];//注意这里的元素多一个
--n;
}
else
{
break;
}
}
}
循环结束之后我们就知道当前元素应该插入的位置,又因为元素已经挪动好了我们直接插入元素就可以,插入完元素之后我们还得关注一下参数中的孩子节点,因为叶子节点没有孩子所以他传递过来的参数为空指针,所以父子节点连接的时候还得进行判断,如果孩子节点不为空就让孩子节点指向父节点,最后对节点中的n进行++那么这里的代码如下:
void InsertKey(Node* node, const K& key, Node* child)
//node表达当前存在的节点,key表示插入的关键字,child表示关键字对应的孩子节点
{
int n = node->_n-1;
while (n>=0)
{
if (key < node->_keys[n])
{
node->_keys[n + 1] = node->_key[n];
node->_subs[n + 2] = node->_keys[n + 1];//注意这里的元素多一个
--n;
}
else
{
break;
}
}
node->_keys[n + 1] = key;
node->_subs[n + 2] = child;//父节点找到孩子
if (child != nullptr)
{
child->_parent = node;
}
node->_n++;
}
实现完插入函数之后我们再回到insert函数,因为插入一个节点可能会导致当前节点发生分裂从往父节点里面也插入节点,所以在完成插入之前先创建insertkey函数所需要的三个变量以方便函数的插入,又因为插入节点是一个循环的过程,所以接下来我们还得创建一个循环来完成插入,如果插入元素之后当前节点不是满的话就直接break,如果满了还得做一些操作:
bool insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node;
_root->_keys[0] = key;
_root->_n++;
return true;
}
pair<Node*, K> ret = find(key);
if (ret.second >= 0)
{
return false;
}
else
{
//开始执行插入
Node* parent = ret.first;
K newKey = key;
Node* child = nullptr;
while (1)
{
InsertKey(parent, newKey, child);
if (parent->_n != M)
{
//当前节点没有满就直接退出
break;
}
else
{
//当前的节点已经满了得分裂
}
}
}
}
如果相等的话就表明当前节点已经满了这个时候就得创建一个兄弟节点然后将一半的数据赋值给兄弟节点,这里的数据包括关键字和孩子指针,并且赋值完了之后还得将原始数据进行覆盖:
else
{
//当前的节点已经满了得分裂
size_t mid = M / 2;
// 分裂一半[mid+1, M-1]给兄弟
Node* brother = new Node;
size_t j = 0;
size_t i = mid + 1;
for (; i <= M - 1; i++)
{
brother->_keys[j] = parent->_keys[i];
brother->_subs[j] = parent->_subs[i];
//赋值完之后得对原始数据进行重置
parent->_keys[i] = K();
parent->_subs[i] = nullptr;
j++;
}
}
但是这么做存在一个问题关键字和孩子指针都赋值给了兄弟节点但是这些孩子节点的父节点却依然指向原来的节点,所以在复制的同时还得修改一下孩子节点的父节点的指向,并且因为叶子结点的存在孩子节点可能为空,所以在改变指向的时候得进行一下判断判断,循环结束之后我们还得修改再进行一次赋值因为孩子数组的元素个树比关键字数组多一个所以还得进行一次修改,然后修改两个节点内部的计数变量那么这里的代码如下:
else
{
//当前的节点已经满了得分裂
size_t mid = M / 2;
// 分裂一半[mid+1, M-1]给兄弟
Node* brother = new Node;
size_t j = 0;
size_t i = mid + 1;
for (; i <= M - 1; i++)
{
brother->_keys[j] = parent->_keys[i];
brother->_subs[j] = parent->_subs[i];
if (parent->_subs[i] != nullptr)
{
parent->_subs[i]->_parent = brother;
}
//赋值完之后得对原始数据进行重置
parent->_keys[i] = K();
parent->_subs[i] = nullptr;
j++;
}
//指针数组多一个
brother->_subs[j] = parent->_subs[i];
if (parent->_subs[i] != nullptr)
{
parent->_subs[i]->_parent = brother;
}
parent->_subs[i] = nullptr;
brother->_n = j;
parent->_n -= (brother->_n + 1);
//这里多减一个是因为还要往父亲移动
}
兄弟节点搞定之后就来处理父亲节点,首先创建变量midkey记录要插入父亲节点的关键字然后将原始数据清除,因为往父节点插入数据存在两个情况一个是父节点不存在也就是根节点发生分裂,另外一种就是父节点存在,这两种情况处理起来是不一样的,所以这里得添加一个if语句进行判断,对于父节点不存在的节点这里就再创建一个节点将该节点的关键字数组的第一个元素赋值为midkey,然后将指针数组的第一个元素指向原来节点,将第二个元素指向兄弟节点,并将兄弟节点和原来的根节点的父亲指针指向新创建的节点,最后修改节点内部计数变量,那么这里的代码如下:
else
{
//当前的节点已经满了得分裂
size_t mid = M / 2;
// 分裂一半[mid+1, M-1]给兄弟
Node* brother = new Node;
size_t j = 0;
size_t i = mid + 1;
for (; i <=M - 1; i++)
{
brother->_keys[j] = parent->_keys[i];
brother->_subs[j] = parent->_subs[i];
if (parent->_subs[i] != nullptr)
{
parent->_subs[i]->_parent = brother;
}
//赋值完之后得对原始数据进行重置
parent->_keys[i] = K();
parent->_subs[i] = nullptr;
j++;
}
//指针数组多一个
brother->_subs[j] = parent->_subs[i];
if (parent->_subs[i] != nullptr)
{
parent->_subs[i]->_parent = brother;
}
parent->_subs[i] = nullptr;
brother->_n = j;
parent->_n -= (brother->_n + 1);
//这里多减一个是因为还要往父亲移动
K midkey = parent->_keys[mid];
parent->_keys[mid] = K();
if (parent->_parent == nullptr)
{
_root = new Node;
_root->_keys[0] = midkey;
_root->_subs[0] = parent;
_root->_subs[1] = brother;
_root->_n = 1;
parent->_parent = _root;
brother->_parent = _root;
}
else
{
}
}
如果不是根节点这里就要进行转换,转换成为在父节点里面插入变量midkey,那么这里就只用改变parent和child和newKey的值就行,那么这里的代码如下:
bool insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node;
_root->_keys[0] = key;
_root->_n++;
return true;
}
pair<Node*, K> ret = find(key);
if (ret.second >= 0)
{
return false;
}
else
{
//开始执行插入
Node* parent = ret.first;
K newKey = key;
Node* child = nullptr;
while (1)
{
InsertKey(parent, newKey, child);
if (parent->_n != M)
{
//当前节点没有满就直接退出
break;
}
else
{
//当前的节点已经满了得分裂
size_t mid = M / 2;
// 分裂一半[mid+1, M-1]给兄弟
Node* brother = new Node;
size_t j = 0;
size_t i = mid + 1;
for (; i <= M - 1; i++)
{
brother->_keys[j] = parent->_keys[i];
brother->_subs[j] = parent->_subs[i];
if (parent->_subs[i] != nullptr)
{
parent->_subs[i]->_parent = brother;
}
//赋值完之后得对原始数据进行重置
parent->_keys[i] = K();
parent->_subs[i] = nullptr;
j++;
}
//指针数组多一个
brother->_subs[j] = parent->_subs[i];
if (parent->_subs[i] != nullptr)
{
parent->_subs[i]->_parent = brother;
}
parent->_subs[i] = nullptr;
brother->_n = j;
parent->_n -= (brother->_n + 1);
//这里多减一个是因为还要往父亲移动
K midkey = parent->_keys[mid];
parent->_keys[mid] = K();
if (parent->_parent == nullptr)
{
_root = new Node;
_root->_keys[0] = midkey;
_root->_subs[0] = parent;
_root->_subs[1] = brother;
_root->_n = 1;
parent->_parent = _root;
brother->_parent = _root;
break;
}
else
{
//通过循环转换成为往父节点里面进行插入
child = brother;
parent = parent->_parent;
newKey = midkey;
}
}
}
}
return true;
}
中序遍历
二叉树有中序遍历那么同样的道理B树也有中序遍历,中序遍历的顺序是左子树根节点右子树,首先用户拿不到根节点的值,所所以这里采用嵌套调用的方式来实现遍历:
void _InOrder(Node * cur)
{
}
void InOrder()
{
_InOrder(_root);
}
然后在_InOrder函数里面就先判断一下cur是否为空,如果为空的话就直接返回,然后就创建一个for循环不停的遍历每个节点的孩子,循环的第一步就是跳转到对应的孩子,然后就打印对应位置的关键字的值,等关键字数组遍历完成之后再跳转到最右边的子树,那么这里代码如下:
void _InOrder(Node * cur)
{
if (cur == nullptr)
return;
// 左 根 左 根 ... 右
size_t i = 0;
for (; i < cur->_n; ++i)
{
_InOrder(cur->_subs[i]); // 左子树
cout << cur->_keys[i] << " "; // 根
}
_InOrder(cur->_subs[i]); // 最后的那个右子树
}
有了上面的代码之后就可以对其进行测试,测试的代码如下:
nt main()
{
BTree<int, 3> BTree;
BTree.insert(52);
BTree.insert(139);
BTree.insert(75);
BTree.insert(49);
BTree.insert(145);
BTree.insert(36);
BTree.insert(50);
BTree.insert(47);
BTree.insert(101);
BTree.InOrder();
return 0;
}
代码的运行结果如下:
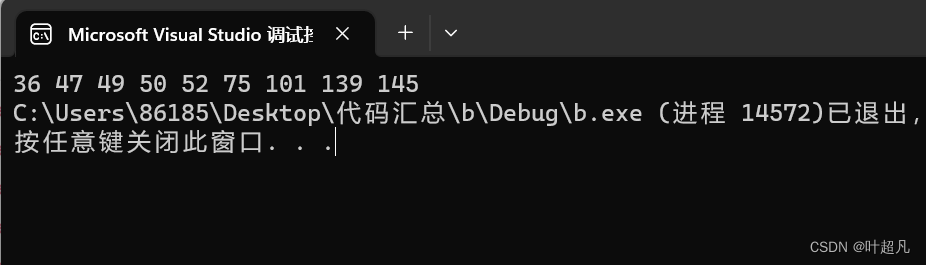
符合我们的预期。
B-树的性能测试
在项目中一般将M的值设置为1024,那么假设每个节点都是满的,那么根节点中会存储1023个数据和1024个子树,然后在第二层就存在1024个节点每个节点又有1023个关键字和1024个孩子,所以第二层存储的节点个数就是1024*1023,第二层的孩子指针就是1024*1024,那么第三层存储的节点个数就是1024*1024*1023,孩子指针的个数就是1024*1024*1024,所以第四层存储的关键字个数就是1024*1024*1024*1023,将每一层存储的节点个数加起来就是一个非常大的数字1023+1024*1023+1024*1024*1023+1024*1024*1024*1023,存储这么对数据但是在查找数据的时候最坏也只用对磁盘进行4次Io,上面是最好的情况那么最坏情况就是每个节点都只存储一半的数据这里粗略进行计算,第一层节点就只有一个数据和两个孩子,第二个层就有两个节点每个节点里面存储512个关键字和孩子,所以第三层就有1024个节点每个节点里面存储512个关键字和512个孩子,第四层就有1024*512个节点,每个节点存储512个关键字所以第四层就存储1024*512*512个关键字,所以当一个B树最坏情况装的就是1+2*512+2*512*512+2*512*512*512节点,可以看到及时最坏情况下b树也能够存储大量的数据,那么这就是B-树的性能。
B-树的删除
假设当前树的内容如下:
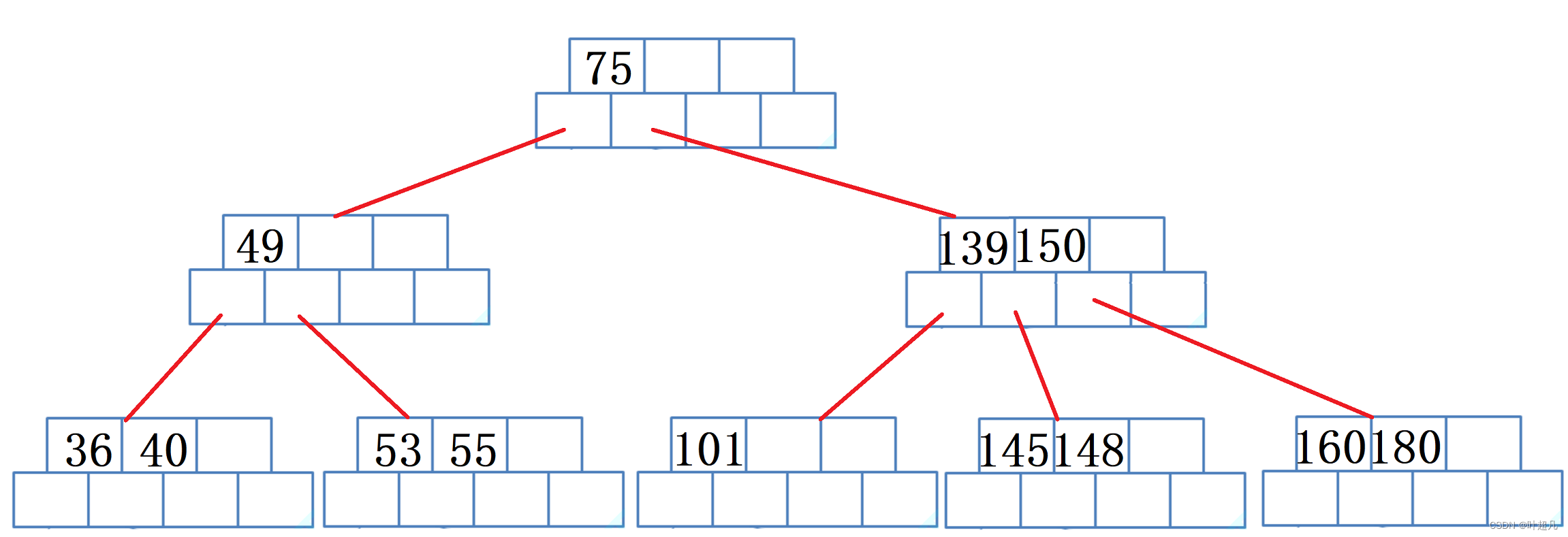
如果我们要删除36,那么这里就是直接删除并将40移动到36的位置
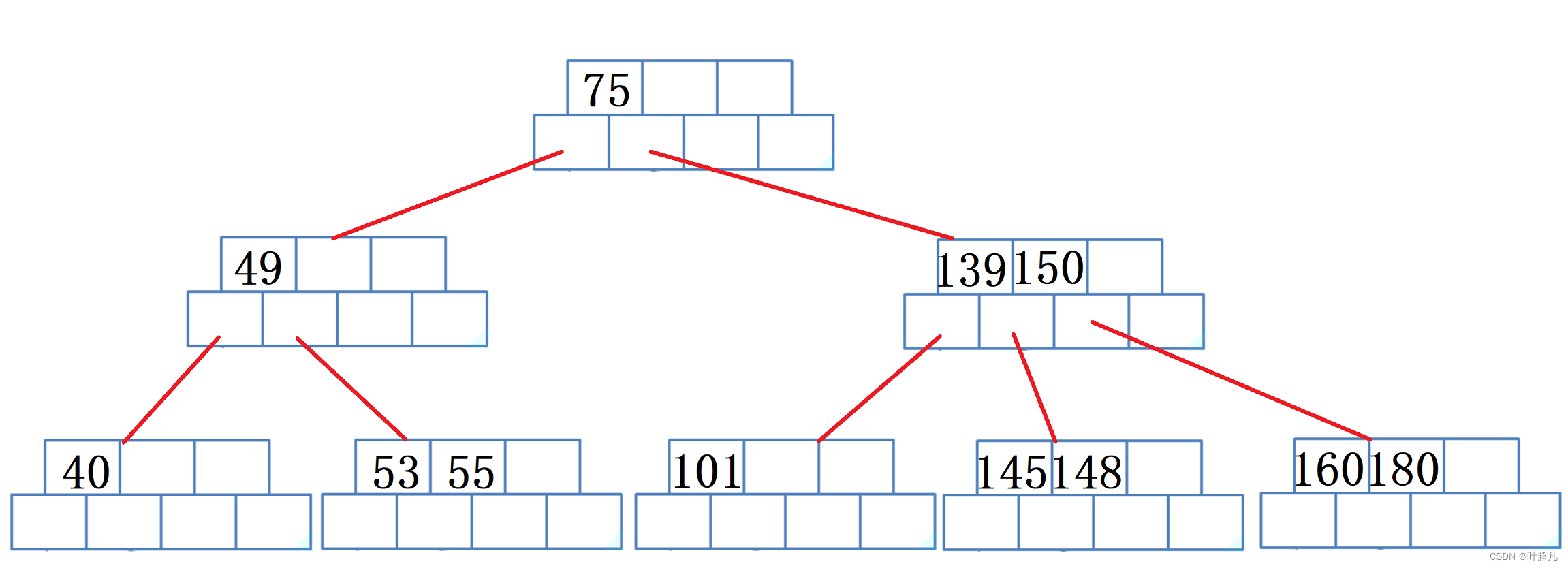
当删除一个元素时,如果当前节点里面的元素数量小于m/2 -1的话则优先找父亲借,然后父亲再兄弟节点节,所以这里先把49放到40的位置上:
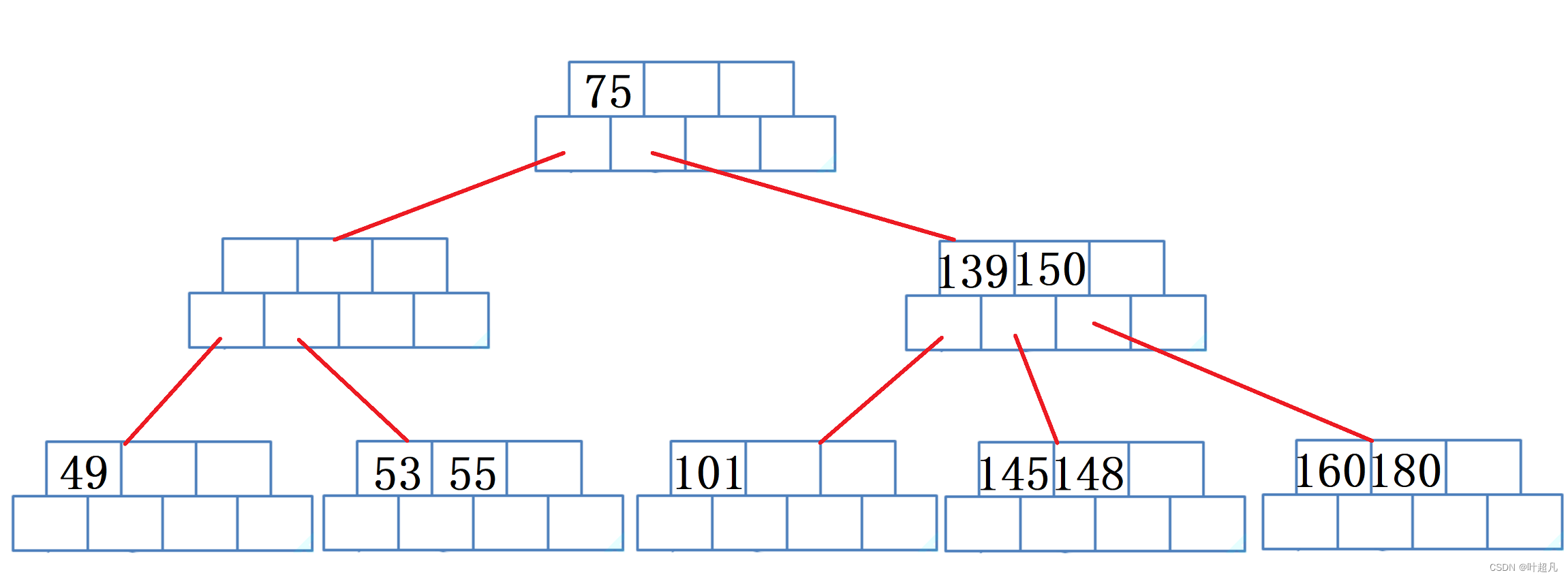
然后再从兄弟那里找一个最小的元素放到父亲节点里面,所以图片就变成下面这样:
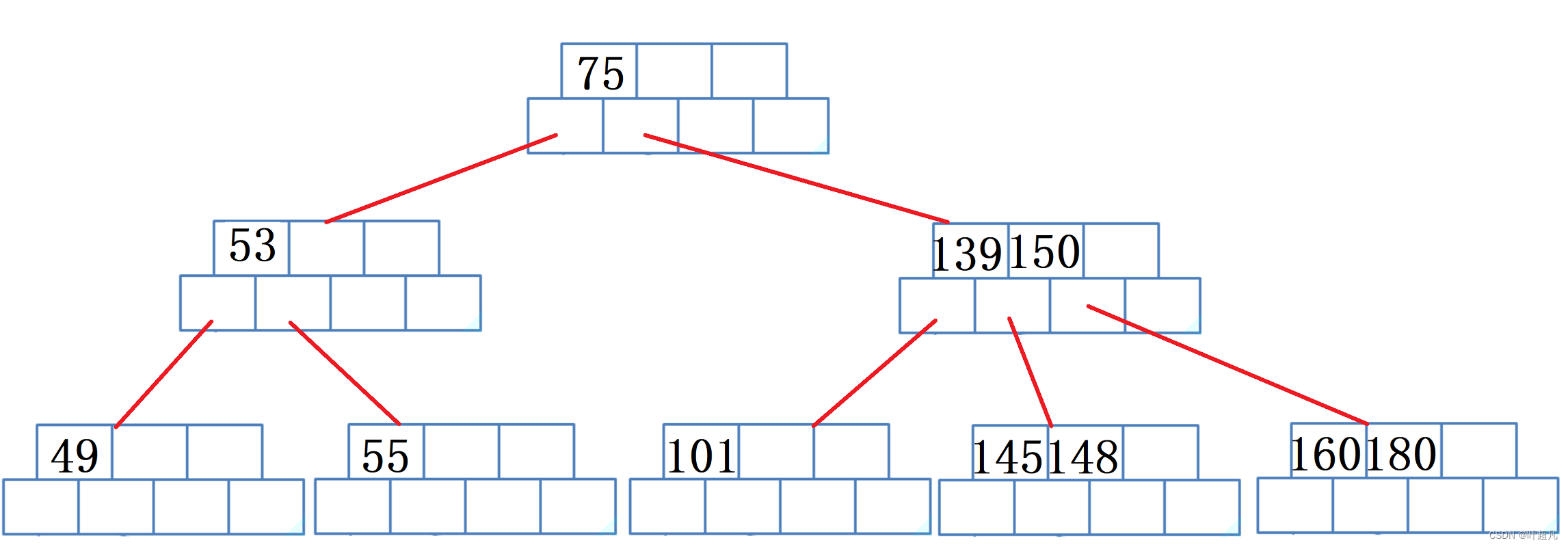
如果再删除49的话同样也是找付父亲借父亲找兄弟借,可是这里就存在一个问题兄弟借不到了,那么这时父亲就得找他的父亲借,所以先把53放到49的位置,然后把75放到53的位置,但是因为55比75要小那么这个时候就将55和75换一个位置,所以图片就变成下面这样:
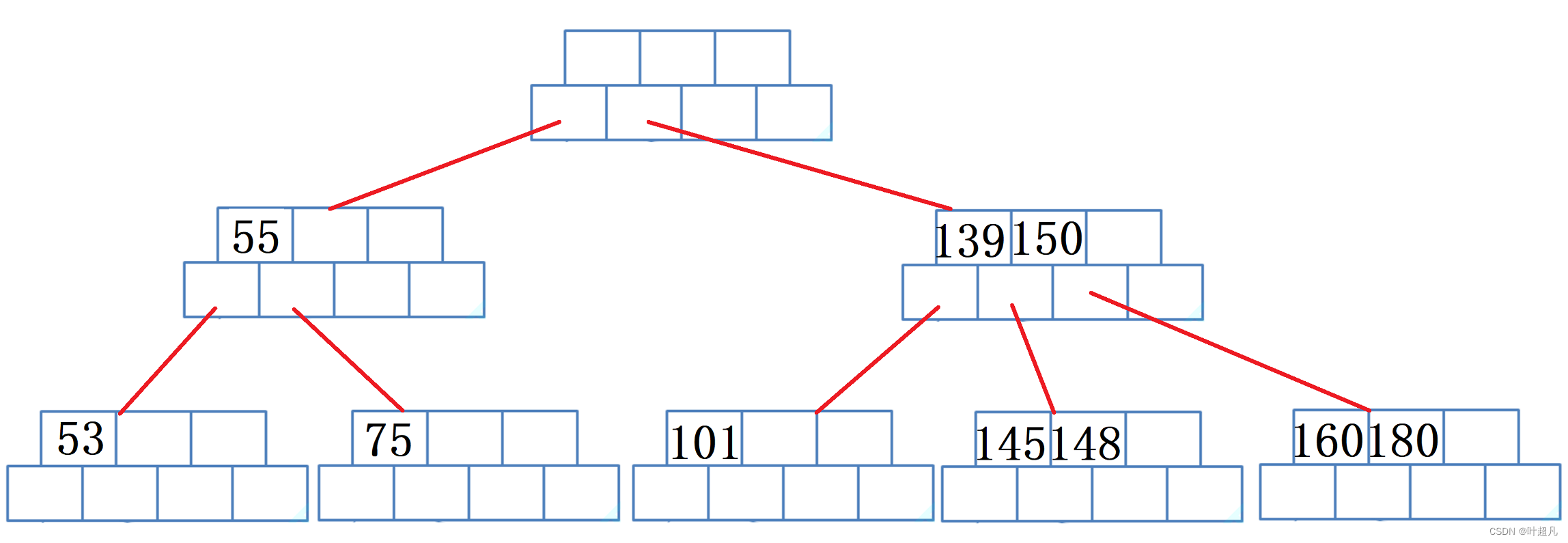
然后父亲的父亲就找父亲的兄弟借,也就是将139放到原来75的位置,可是这时候父亲的兄弟就变的不符合规则了,那么这个时候他就会找他的孩子借,第一个孩子借不了就找第二个孩子借,所以145来到139的位置148来到145的位置,那么这里的图片如下:
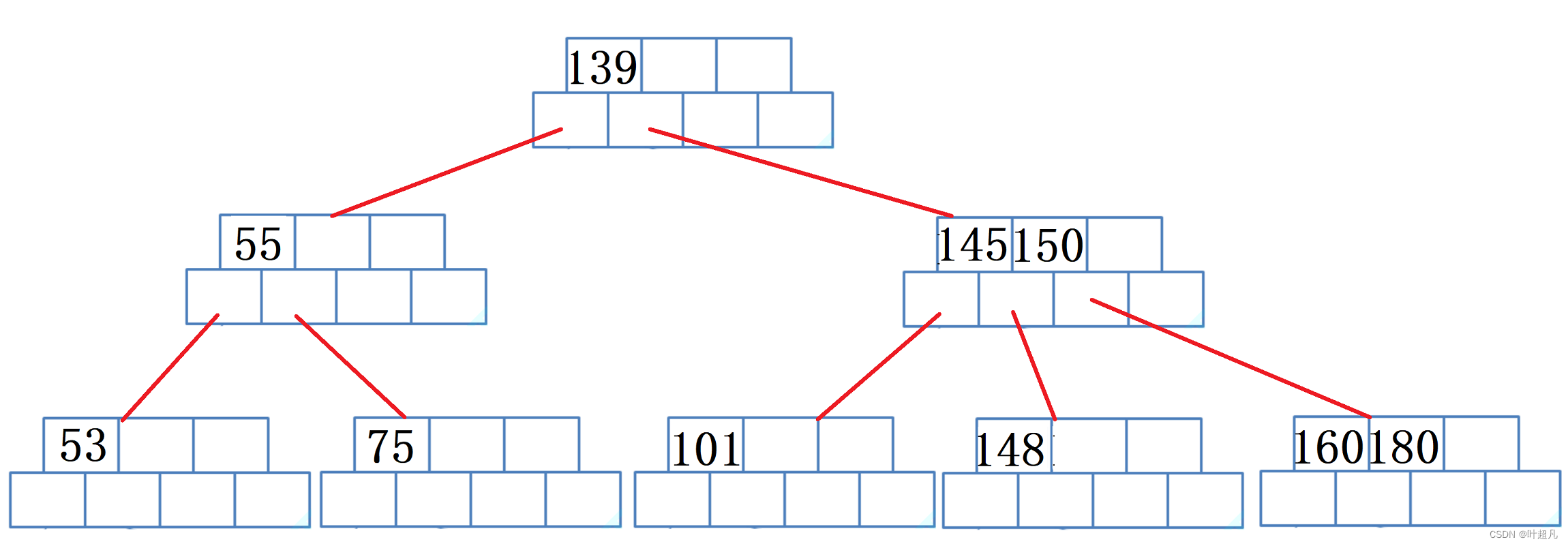
然后再删除150这个时候就得将150放到145的位置上然后将160提到上面来:
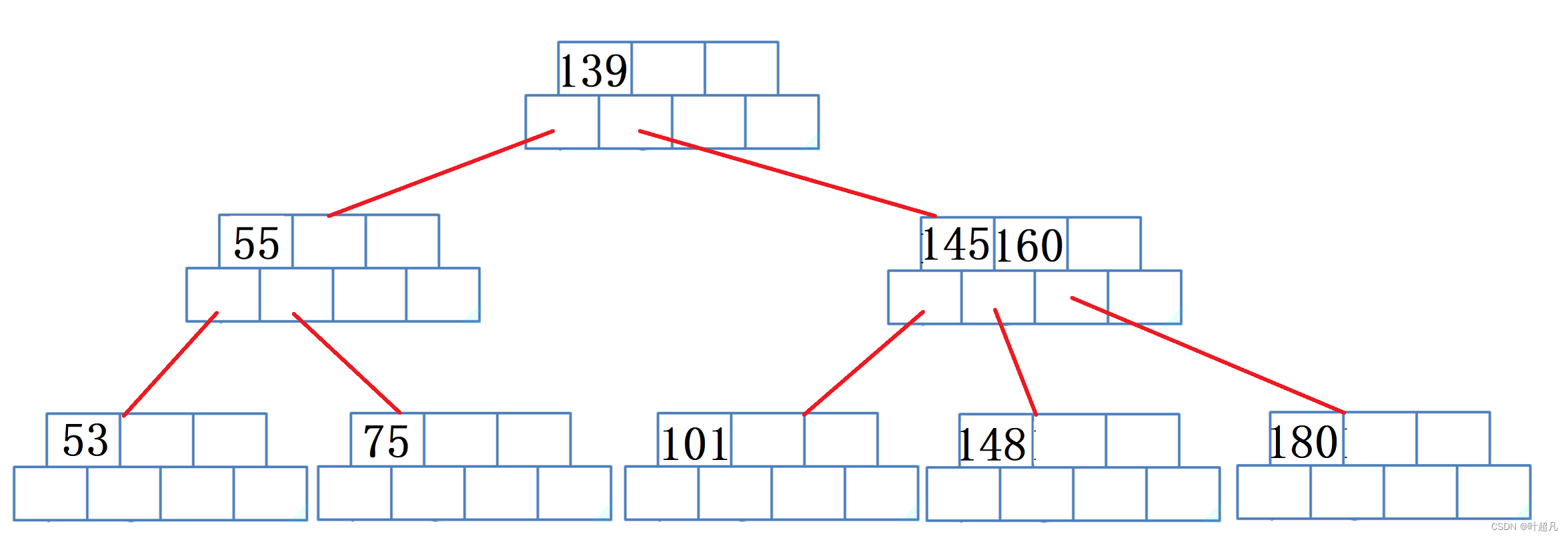
然后再删除节点180因为当前节点的元素个数小于m/2-1并且他向父亲和兄弟也借不到元素,所以这个时候就得进行合并将180所在的节点删除然后将160放到148所在的节点
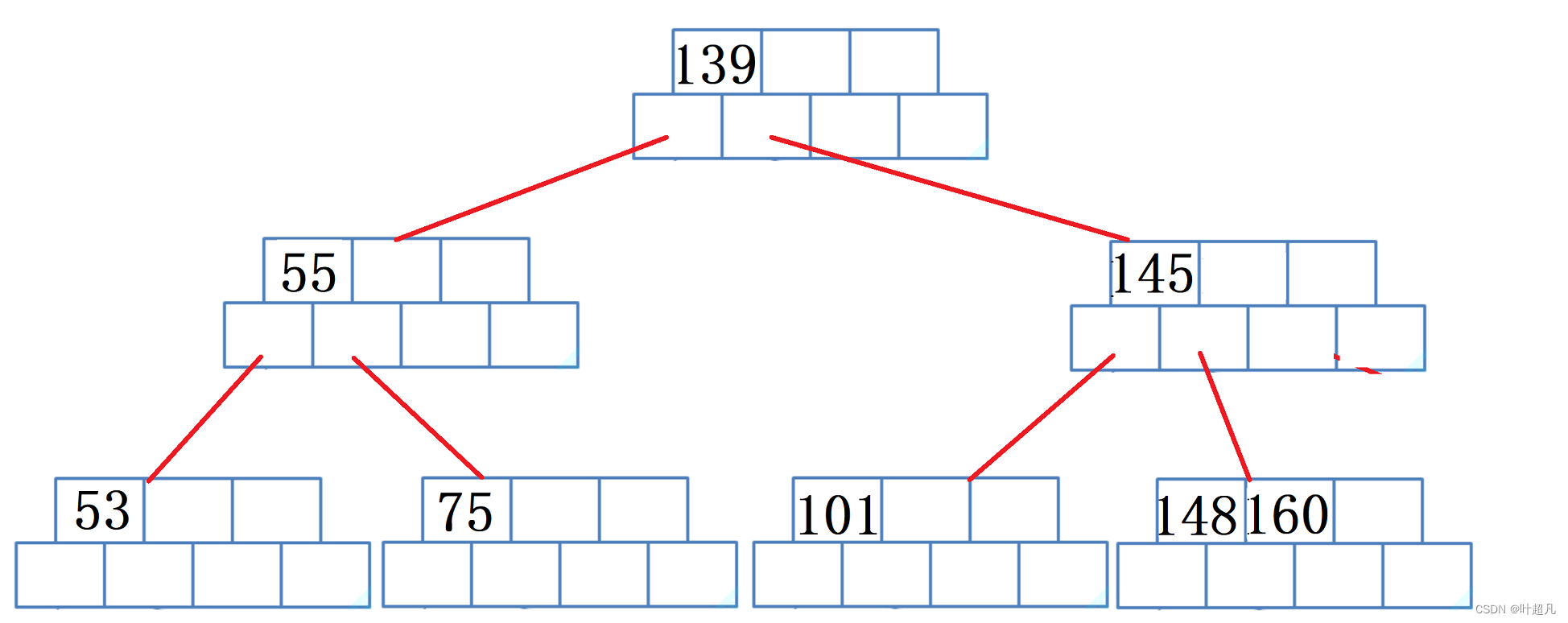
再删除节点160没有任何问题:
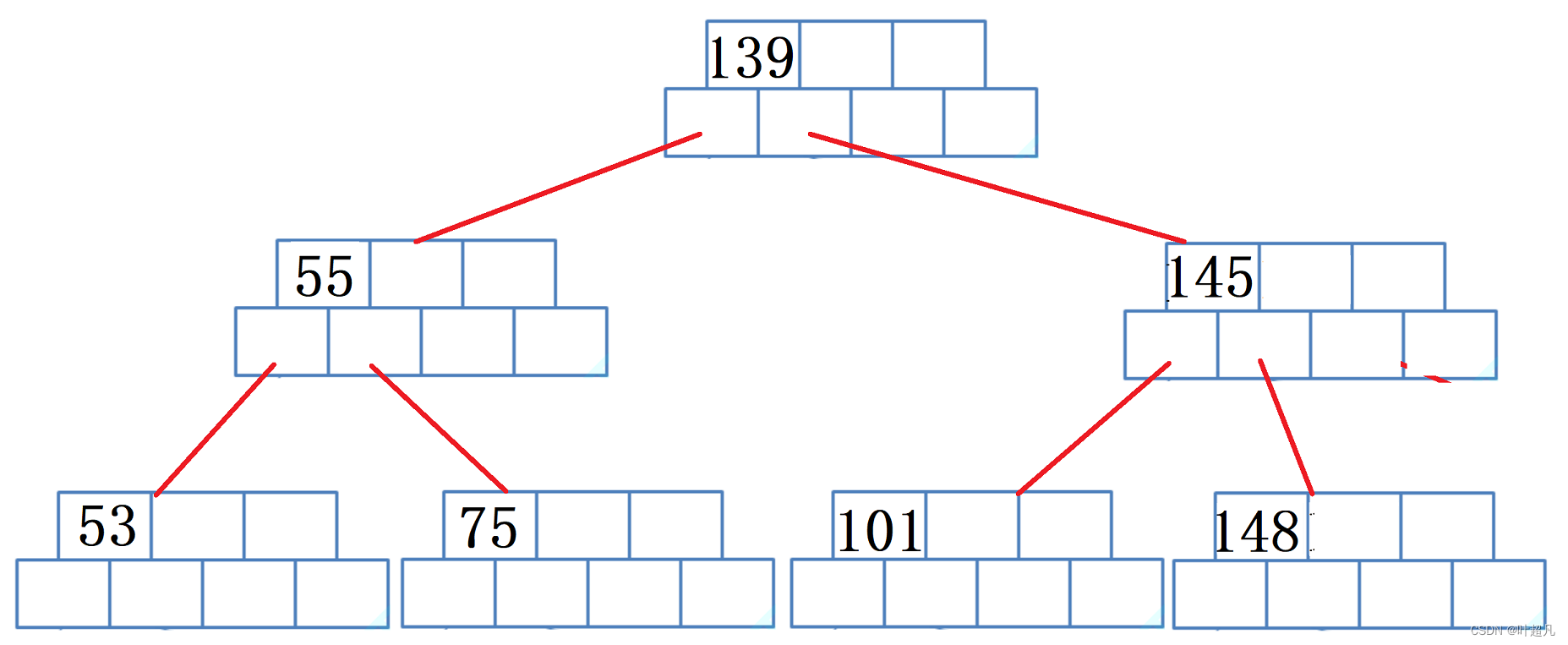
再删除节点145因为当前节点数量不够了并且无法向其他节点借时就得进行合并,这里就是将139和55进行合并,将101和148进行合并:
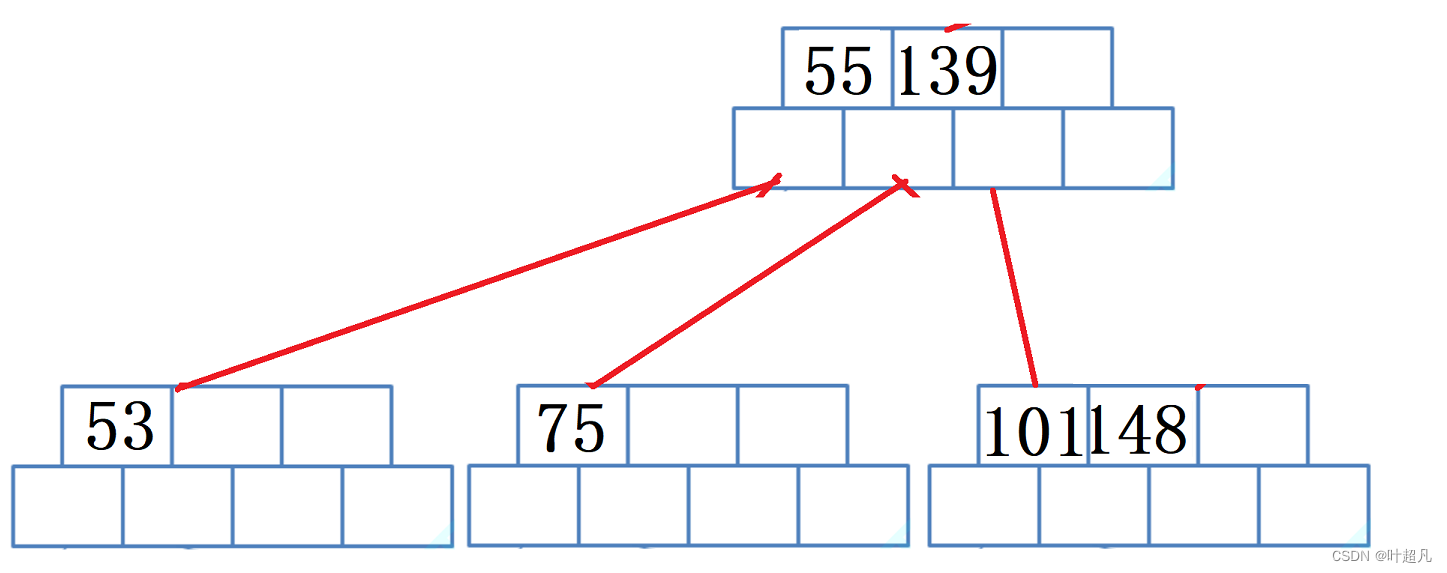
那么这就是大致的删除规则反正就是很复杂很难这里我们就不实现了大家了解即可。
B+树
B+树是B树的变形,是在B树基础上优化的多路平衡搜索树,B+树的规则跟B树基本类似,但是又在B树的基础上做了以下几点改进优化:
- 分支节点的子树指针与关键字个数相同。
- 分支节点的子树指针p[i]指向关键字值大小在[k[i],k[i+1])区间之间,这就说明B+树取消了最左边的那个子树
- 所有叶子节点增加一个链接指针链接在一起
- 所有关键字及其映射数据都在叶子节点出现。
那么将其规划一下就可以得到下面的图片:
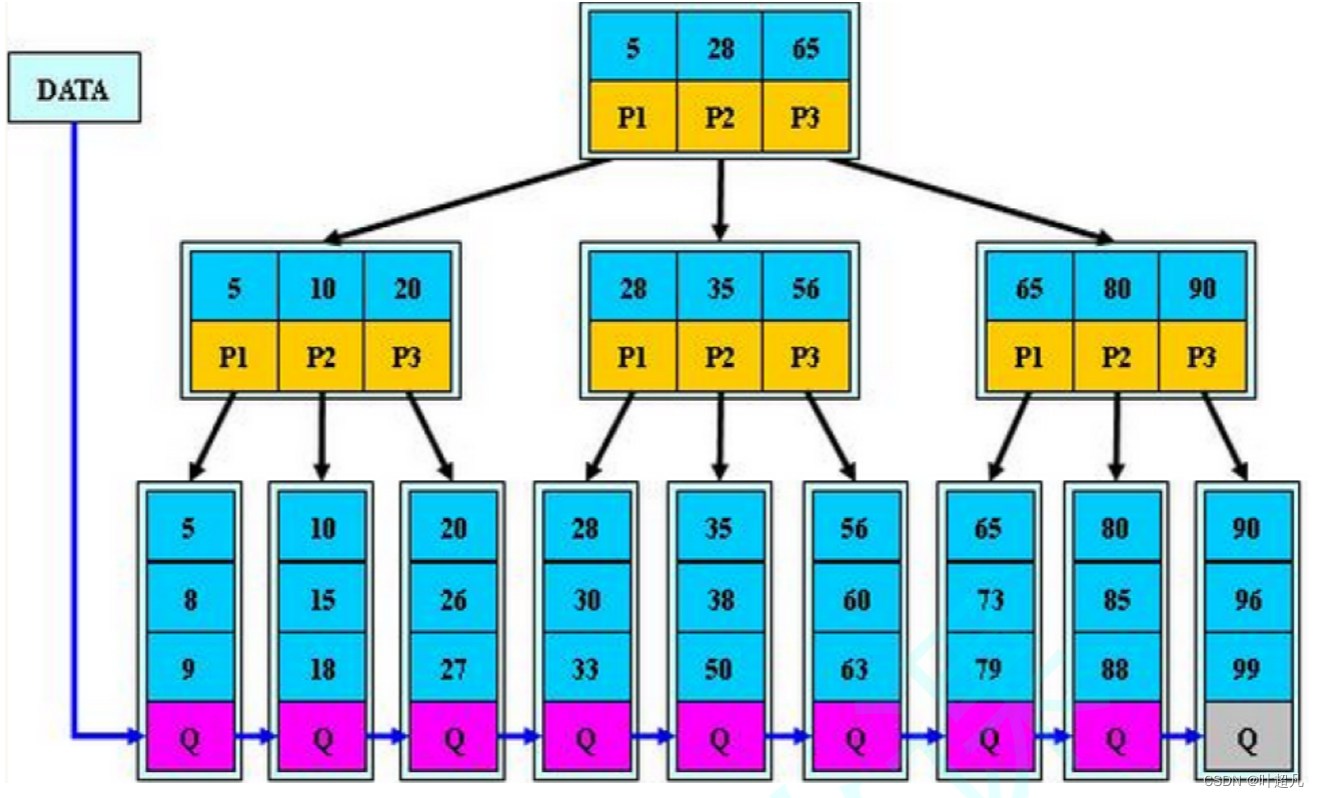
所有的叶子节点增加一个链接指针链接在一起,那么这时想要遍历树中的每个元素时就可以直接通过叶子节点中的指针进行遍历,不需要像B-树一样从头开始遍历,通过上面的图片大家也可以看到分支节点和叶子节点中存在重复的值,那么分支节点里面存的值是叶子节点最小值的索引,也就是说通过分支节点里面的值我们就可以知道他的子节点中的最小值是多少,那么通过这个索引我们在查找元素的时候就很简单,假如说查找元素4,因为根节点的第一个元素的值为5,而4比5还小这就说明当前树中没有5,如果我们要查找元素60那么根节点中存在三个值5 28 65,因为60比28要大但是比65要小所以60只可能出现在28的子树里面,28指向的分支节点总又存储了三个值分别为28 35 56,因为60比56要大并且后面没有元素了,所以就存储在56对应的叶子节点,然后遍历叶子结点的内容即可,那么这就是B+树的内部构造接下来我们来看B+树的插入。
B+树的元素插入
B+树的每个节点都含有两块内容一个用来存储索引一个用来存储值,假设M的值为3插入的第一个元素为53图片就是下面这样:
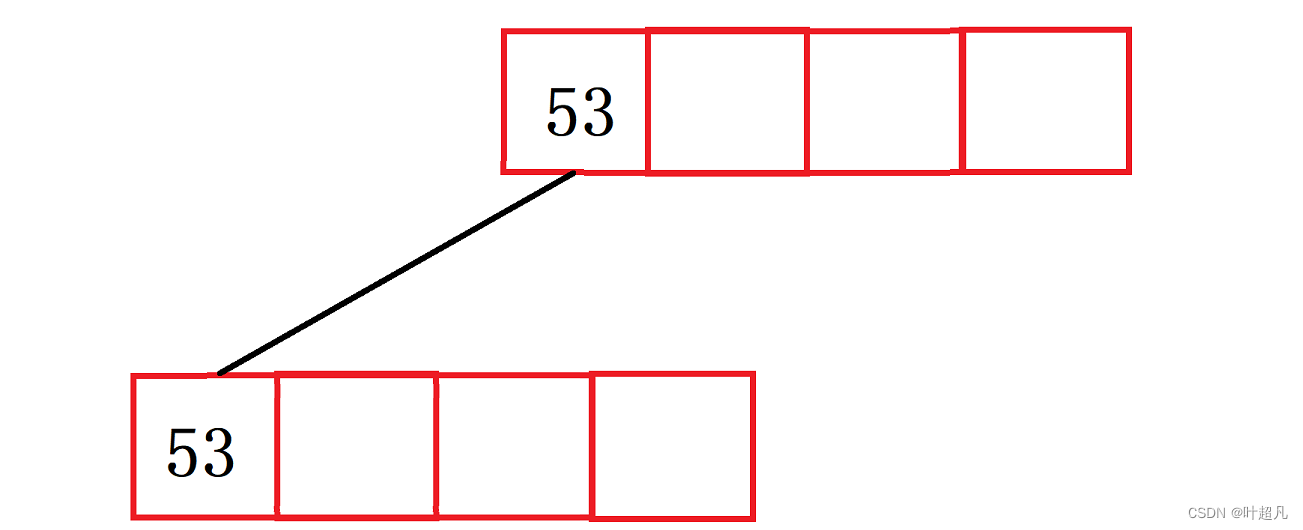
上面的方块用来存储子节点的索引,下面的方块用来存储值,然后再插入数据139和75图片就变成了下面这样:
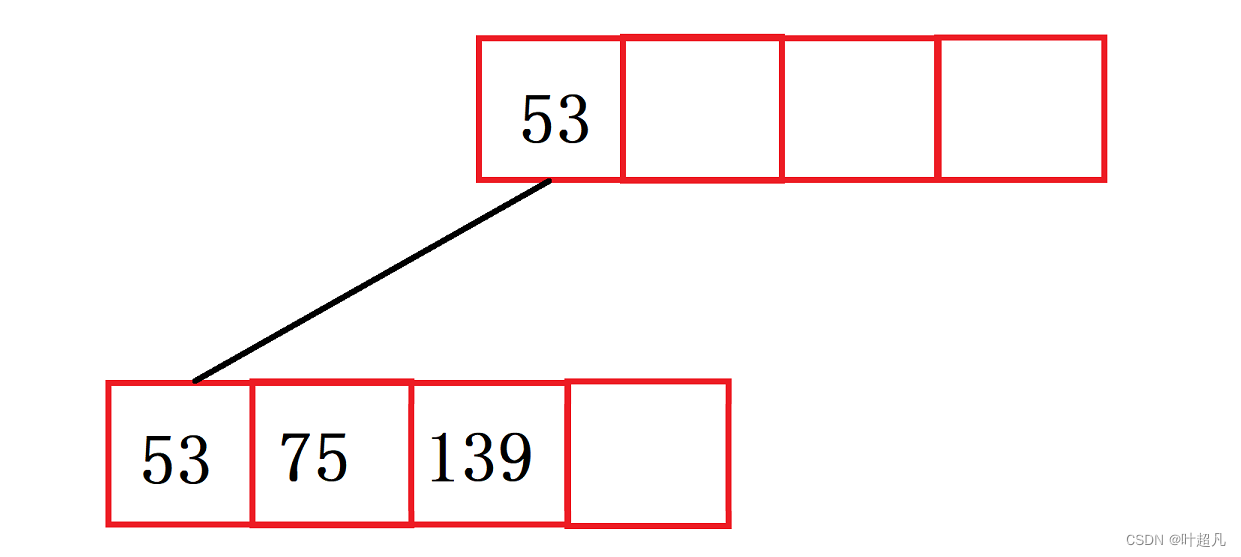
再插入数据49,因为49比53要小所以插入数据的同时还得修改索引的值:
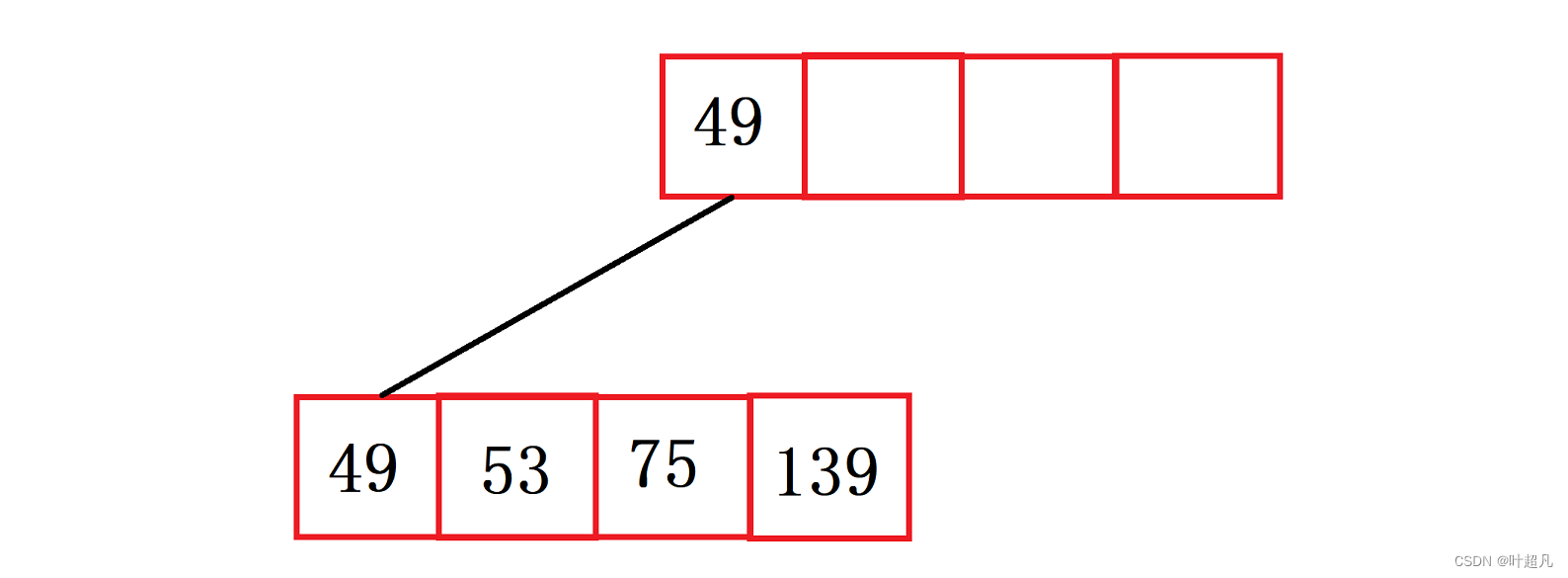
并且当前的节点已经填满了所以这个时候就得进行分裂创建一个新的节点并将原来节点的一半分裂出去然后往索引里面添加值,那么这里的图片就变成下面这样
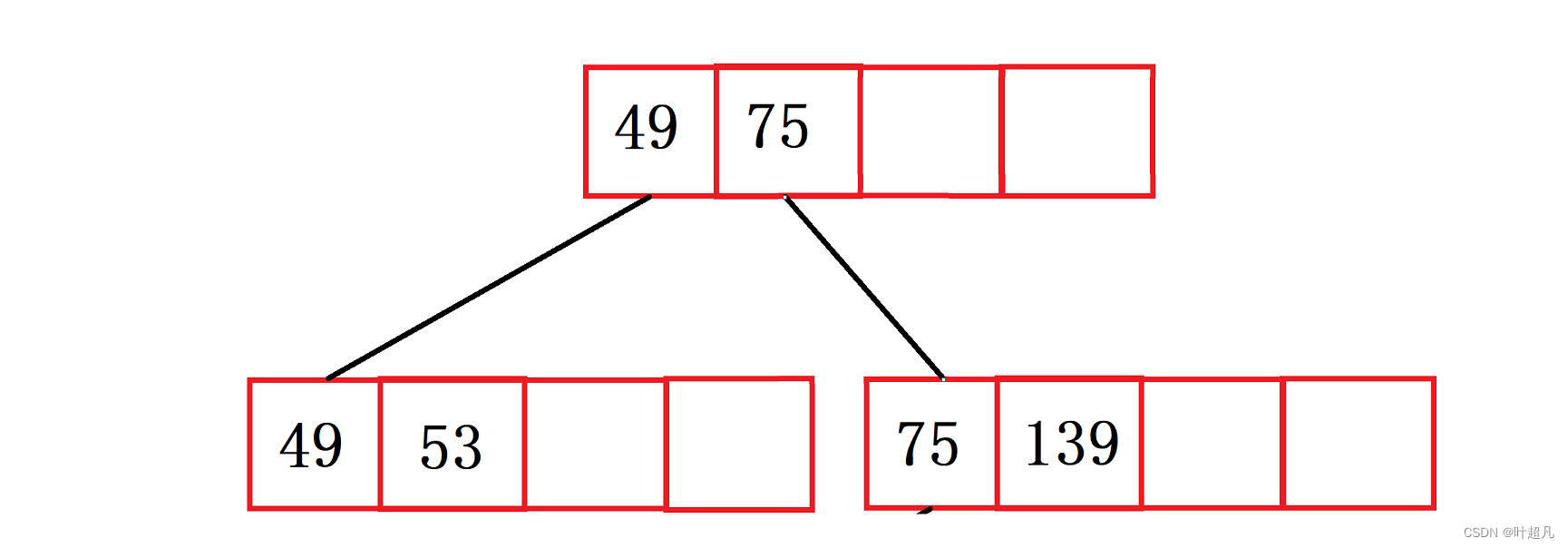
然后插入元素145 36图片就变成下面这样:
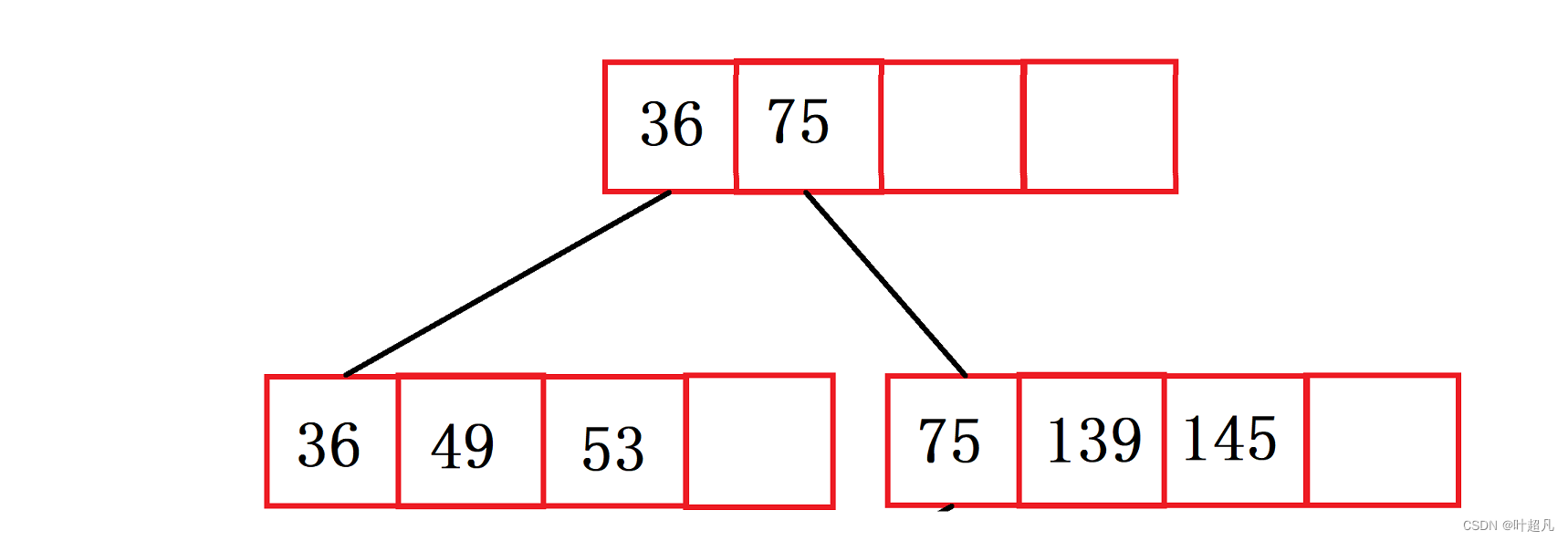
再插入元素101
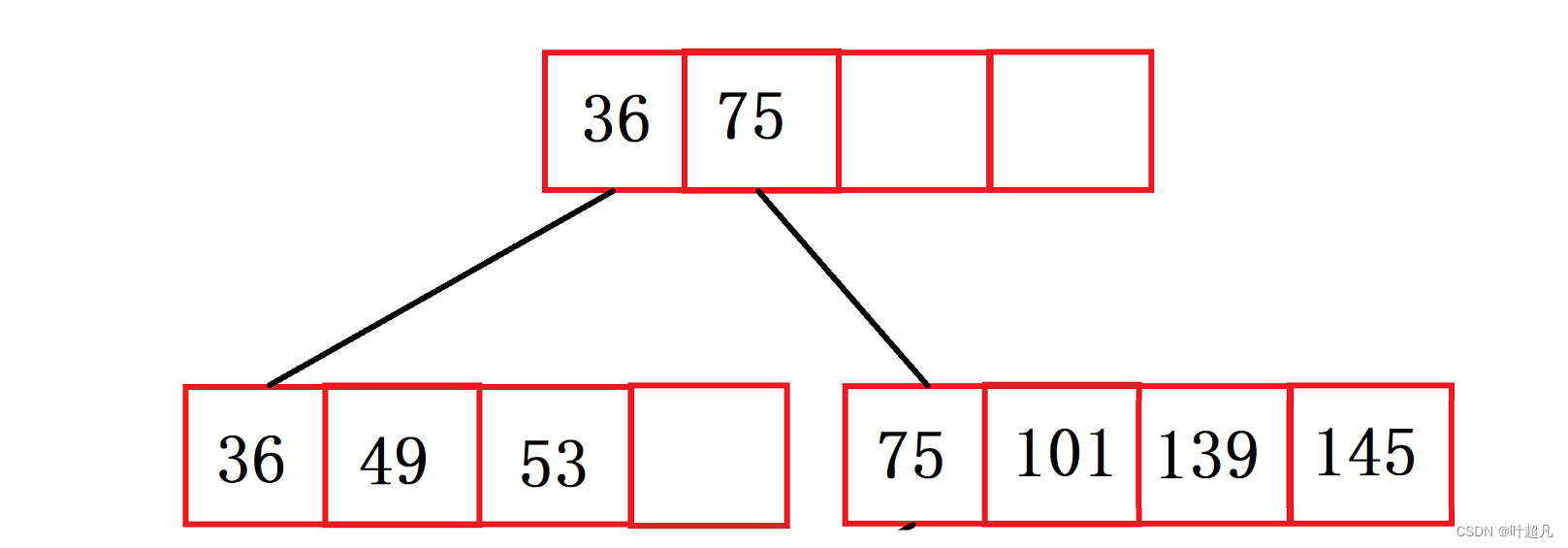
节点满了就需要对其进行分裂:
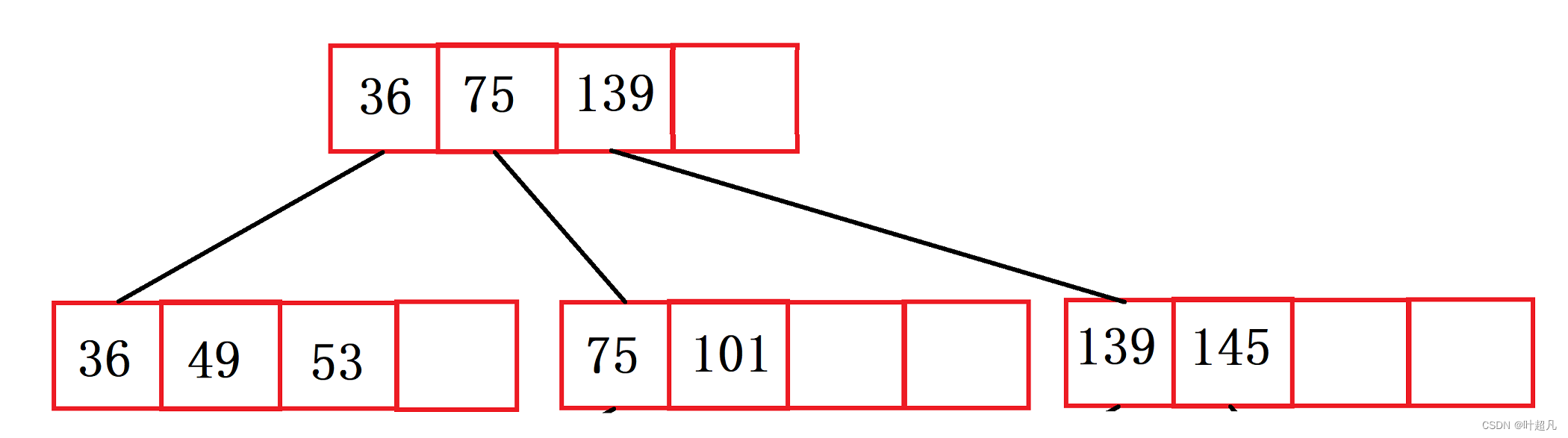
然后再插入150和155,那么这个时候图片就变成了下面这样:
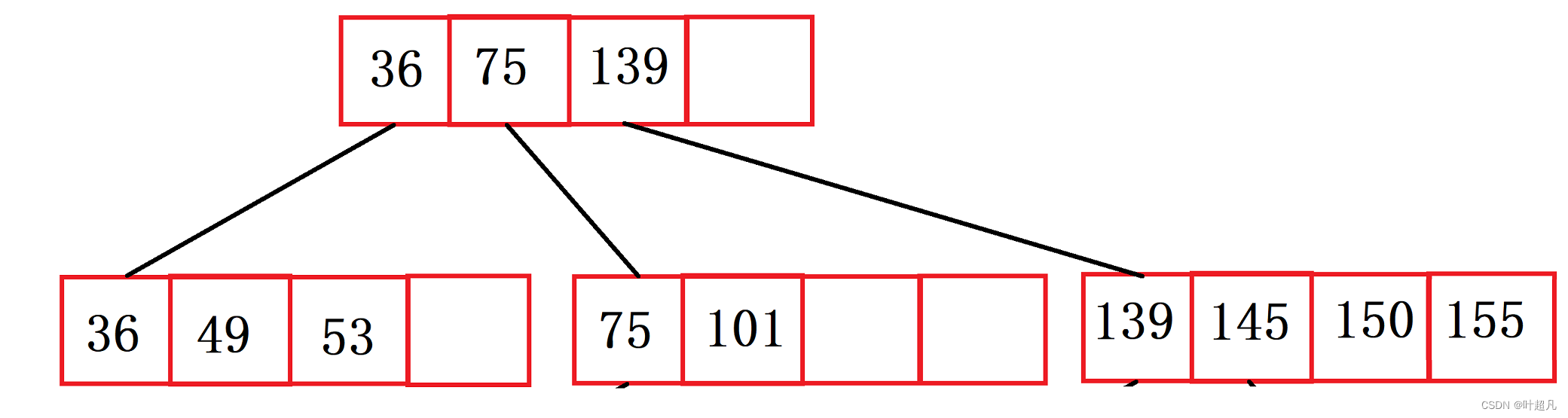
然后对节点进行分裂往父节点里面插入索引:
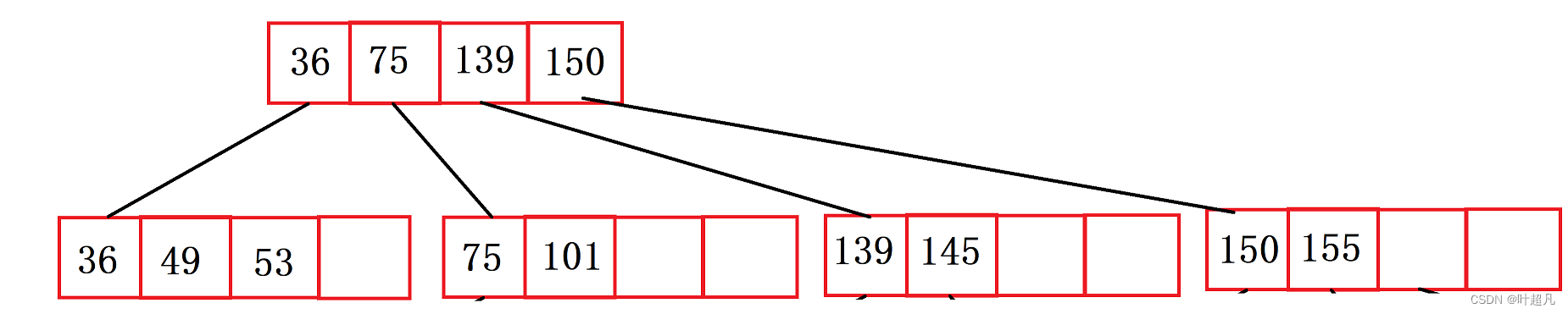
这时父节点也满了,那么这个时候也得对这个节点进行分裂
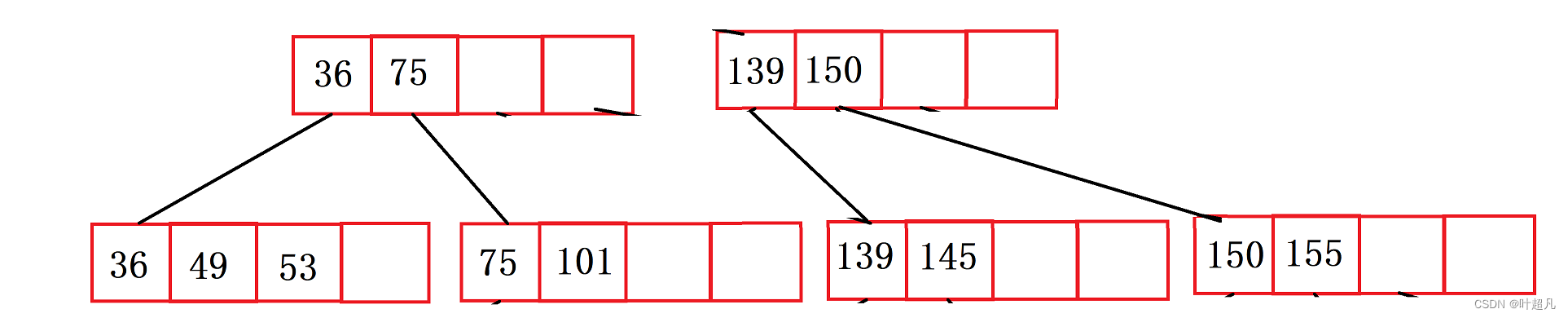
但是这个时候就没有了根节点,所以还得创建一个根节点用来指向两个分支节点:
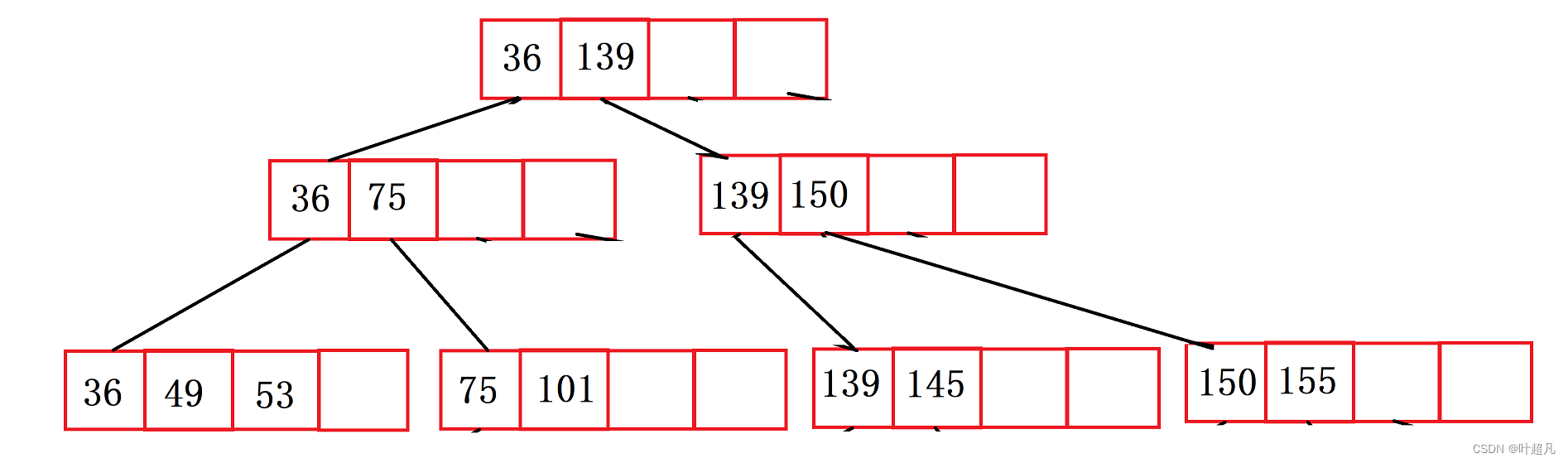
那么这就是B+树的插入过程,大家理解了就行无需模拟实现。
B*树的介绍
B树是B+树的变形,在B+树的非根和非叶子节点再增加指向兄弟节点的指针
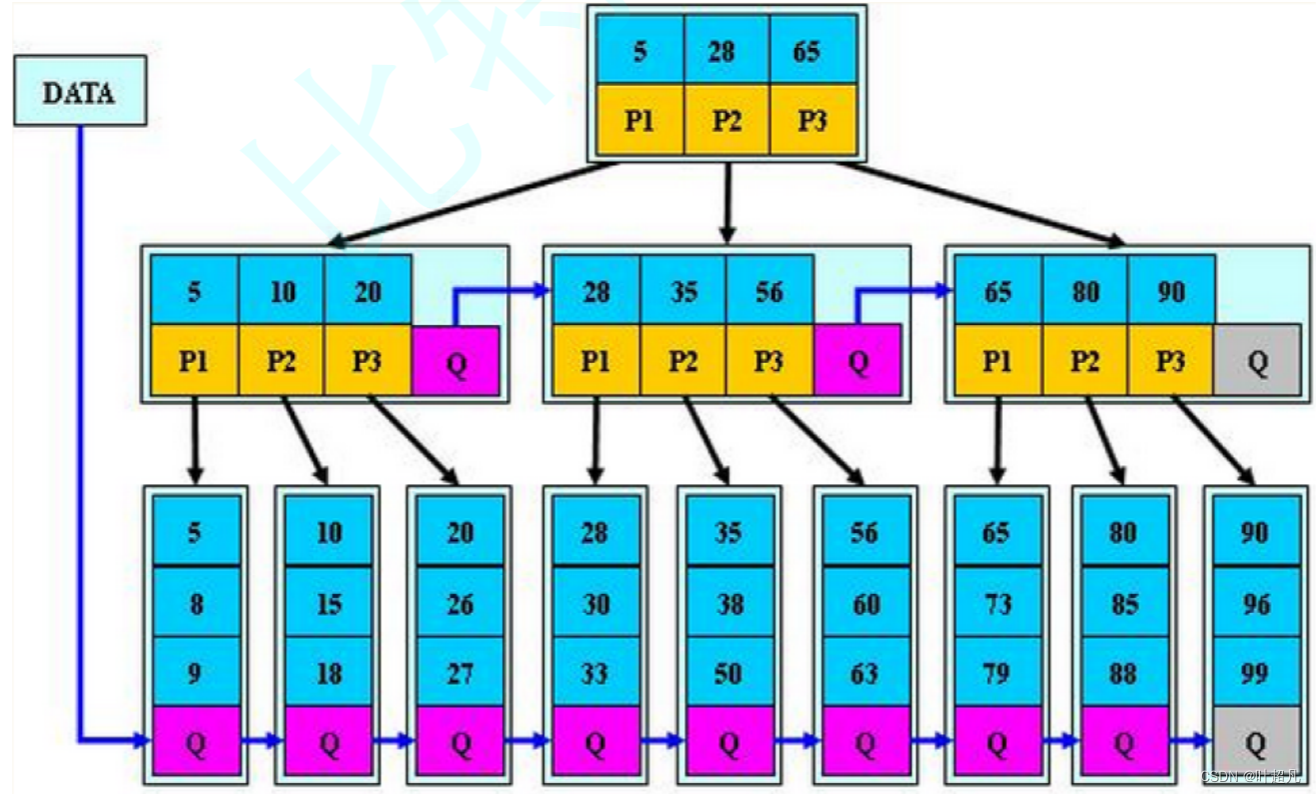
B树跟B+树的结构差不多就是在每个分支节点中也添加了一个指针用来指向同层的分支节点,然后B*树在分裂的时候与B+树有所不同:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。所以,B*树分配新结点的概率比B+树要低,空间使用率更高。通过以上介绍,大致将B树,B+树,B*树总结如下:
B树:有序数组+平衡多叉树;B+树:有序数组链表+平衡多叉树;B*树:一棵更丰满的,空间利用率更高的B+树。