🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
什么是机器学习?
传统编程的局限性
从编程到学习
什么是 TensorFlow?
使用张量流
在 Python 中安装 TensorFlow
在 PyCharm 中使用 TensorFlow
在 Google Colab 中使用 TensorFlow
机器学习入门
看看网络学到了什么
概括
在创建人工智能 (AI) 时,机器学习 (ML) 和深度学习是一个很好的起点。然而,刚开始使用时,很容易被各种选项和所有新术语弄得不知所措。本书旨在为程序员揭开神秘面纱,带您通过编写代码来实现机器学习和深度学习的概念;以及构建行为更像人类的模型,包括计算机视觉、自然语言处理 (NLP) 等场景。因此,它们成为一种合成的或人工智能的形式。
但是当我们提到机器学习时,这个现象到底是什么?让我们快速浏览一下,并在我们继续之前从程序员的角度考虑它。之后,本章将向您展示如何安装交易工具,从 TensorFlow 本身到您可以对 TensorFlow 模型进行编码和调试的环境。
什么是机器学习?
前我们了解了 ML 的来龙去脉,让我们考虑一下它是如何从传统编程演变而来的。我们将从检查什么是传统编程开始,然后考虑它受限的情况。然后我们将看到 ML 如何发展以处理这些情况,并因此开辟了实施新场景的新机会,解锁了许多人工智能的概念。
传统编程涉及我们编写以编程语言表达的规则,这些规则作用于数据并给我们答案。这几乎适用于任何可以用代码编程的地方。
例如,考虑一款像流行的 Breakout 这样的游戏。代码决定了球的运动、比分以及比赛输赢的各种条件。想一想球从砖块上弹回的场景,如图1-1所示。

图 1-1。在 Breakout 游戏中编写代码
在这里,球的运动可以由它的dx和dy属性决定。当它撞到一块砖时,砖被移开,球的速度增加并改变方向。该代码作用于有关游戏情况的数据。
或者,考虑一个金融服务场景。您拥有有关公司股票的数据,例如其当前价格和当前收益。您可以使用图 1-2中的代码计算一个有价值的比率,称为 P/E(价格除以收益)。
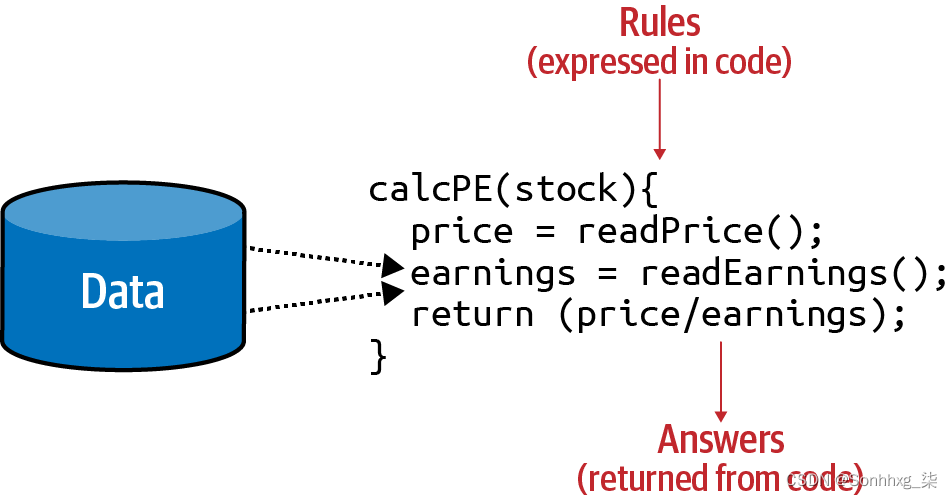
图 1-2。金融服务场景中的代码
您的代码读取价格,读取收益,并返回前者除以后者的值。
如果我试图将像这样的传统编程总结成一张图,它可能看起来像图 1-3。

图 1-3。传统编程的高级视图
如您所见,您拥有以编程语言表达的规则。这些规则作用于数据,结果就是答案。
传统编程的局限性
这图 1-3中的模型从一开始就是开发的支柱。但它有一个固有的局限性:即只有可以实现的场景才是您可以推导出规则的场景。其他场景呢?通常,由于代码太复杂,它们无法开发。只是不可能编写代码来处理它们。
例如,考虑活动检测。可以检测我们活动的健身监测器是最近的一项创新,不仅是因为廉价和小型硬件的可用性,还因为处理检测的算法以前不可行。让我们探讨一下原因。
图 1-4显示了一个简单的步行活动检测算法。可以考虑人的速度。如果它小于特定值,我们可以确定他们可能正在行走。

图 1-4。活动检测算法
鉴于我们的数据是速度,我们可以扩展它来检测它们是否正在运行(图 1-5)。

图 1-5。扩展运行算法
如您所见,根据速度,我们可能会说如果它小于某个特定值(例如 4 mph),则该人正在行走,否则他们正在跑步。它仍然有效。
现在假设我们想将其扩展到另一种流行的健身活动,骑自行车。该算法可能如图 1-6所示。

图 1-6。扩展骑自行车的算法
我知道这很天真,因为它只是检测速度——例如,有些人跑得比其他人快,而且你下坡跑的速度可能比骑车上坡快。但总的来说,它仍然有效。但是,如果我们想实现另一个场景,比如打高尔夫球(图 1-7),会发生什么情况?

图 1-7。我们如何编写高尔夫算法?
我们现在被困住了。我们如何确定某人正在使用这种方法打高尔夫球?这个人可能会走一会儿,停下来,做一些活动,再走一会儿,停下来,等等。但是我们怎么知道这是高尔夫呢?
我们使用传统规则检测此活动的能力遇到了瓶颈。但也许有更好的方法。
进入机器学习。
从编程到学习
让我们回顾一下我们用来演示什么是传统编程的图表(图 1-8)。在这里,我们有规则作用于数据并给我们答案。在我们的活动检测场景中,数据是人移动的速度;由此我们可以编写规则来检测他们的活动,无论是步行、骑自行车还是跑步。我们在打高尔夫球时碰壁了,因为我们无法想出规则来确定这项活动是什么样子的。

图 1-8。传统编程流程
但是如果我们在这个图表上翻转轴会发生什么?不是我们想出规则,如果我们想出答案,并且连同数据有一种方法可以弄清楚规则可能是什么,那会怎样?
图 1-9显示了它的样子。我们可以考虑这个高级图表来定义机器学习。

图 1-9。改变坐标轴以获得机器学习
那么这意味着什么呢?好吧,现在不是我们试图弄清楚规则是什么,而是我们获得了大量关于我们场景的数据,我们标记这些数据,然后计算机可以找出使一个数据匹配特定标签的规则是什么,并且另一条数据匹配不同的标签。
这将如何用于我们的活动检测场景?好吧,我们可以查看所有为我们提供有关此人数据的传感器。如果他们有一个可检测心率、位置、速度等信息的可穿戴设备——如果我们在他们进行不同的活动时收集了大量此类数据的实例——我们最终会得到这样的数据: “这就是走路的样子”,“这就是跑步的样子”,等等(图 1-10)。

图 1-10。从编码到 ML:收集和标记数据
现在我们作为程序员的工作从弄清楚规则转变为确定活动,再到编写将数据与标签相匹配的代码。如果我们能做到这一点,那么我们就可以扩展我们可以用代码实现的场景。机器学习是一种使我们能够做到这一点的技术,但为了开始,我们需要一个框架——这就是 TensorFlow 发挥作用的地方。在下一节中,我们将了解它是什么以及如何安装它,然后在本章后面您将编写您的第一个代码来学习两个值之间的模式,就像在前面的场景中一样。这是一个简单的“Hello World”场景,但它具有在极其复杂的场景中使用的相同基础代码模式。
这人工智能领域广阔而抽象,涵盖了让计算机像人类一样思考和行动的一切。人类采取新行为的方式之一是通过实例学习。因此,机器学习学科可以被认为是人工智能发展的入口。通过它,机器可以学习像人一样看东西(计算机视觉领域),像人一样阅读文本(自然语言处理)等等。我们将使用 TensorFlow 框架在本书中介绍机器学习的基础知识。
什么是 TensorFlow?
张量流是一个用于创建和使用机器学习模型的开源平台。它实现了机器学习所需的许多常见算法和模式,使您无需学习所有底层数学和逻辑,并使您能够专注于您的场景。它面向所有人,从爱好者到专业开发人员,再到推动人工智能发展的研究人员。重要的是,它还支持将模型部署到网络、云、移动和嵌入式系统。我们将在本书中涵盖这些场景中的每一个。
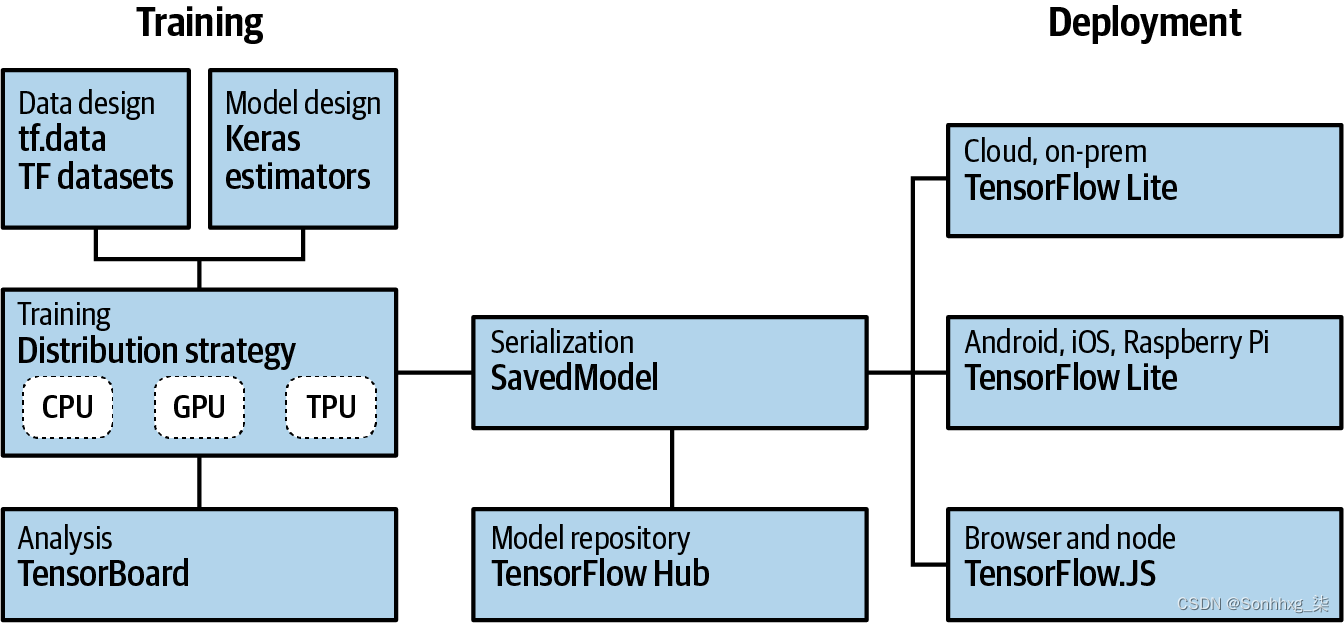
图 1-11。TensorFlow 高层架构
这创建机器学习模型的过程称为 训练。这是计算机使用一组算法来了解输入以及它们之间的区别的地方。因此,例如,如果你想让计算机识别猫和狗,你可以使用两者的大量图片来创建模型,计算机将使用该模型来尝试弄清楚是什么让猫成为猫,以及什么使狗成为狗。一旦模型被训练,让它识别或分类未来输入的过程称为 推理。
因此对于培训模型,有几件事你需要支持。首先是一组用于设计模型本身的 API。和TensorFlow 有三种主要方法可以做到这一点:您可以手动编写所有代码,找出计算机如何学习的逻辑,然后在代码中实现(不推荐);你可以使用内置的 estimators,它们是您可以自定义的已经实现的神经网络;或者你可以使用Keras,一种高级 API,可让您在代码中封装常见的机器学习范例。本书将主要关注在创建模型时使用 Keras API。
训练模型的方法有很多种。在大多数情况下,您可能只使用单个芯片,无论是中央处理器 (CPU)、图形处理器 (GPU) 还是称为 张量处理单元(TPU)。在更高级的工作和研究环境中,可以使用跨多个芯片的并行训练,采用 训练跨越多个芯片的分布策略。TensorFlow 也支持这一点。
这任何模型的生命线都是它的数据。如前所述,如果您想创建一个可以识别猫狗的模型,则需要使用大量猫狗示例对其进行训练。但是您如何管理这些示例呢?随着时间的推移,您会发现这通常涉及比创建模型本身更多的编码。TensorFlow 附带 API 以尝试简化此过程,称为张量流数据服务。对于学习,它们包括许多预处理的数据集,您可以使用一行代码。它们还为您提供处理原始数据的工具,使其更易于使用。
超过创建模型时,您还需要能够将它们交到人们可以使用的地方。为此,TensorFlow 包含用于服务的API ,您可以在其中通过 HTTP 连接为云或 Web 用户提供模型推理。对于在移动或嵌入式系统上运行的模型,有TensorFlow Lite,它提供了用于在 Android 和 iOS 以及基于 Linux 的嵌入式系统(例如 Raspberry Pi)上进行模型推理的工具。一个TensorFlow Lite 的分支,称为 TensorFlow Lite Micro (TFLM),也通过称为TinyML。最后,如果你想为你的浏览器或 Node.js 用户提供模型,TensorFlow.js 提供了以这种方式训练和执行模型的能力。
接下来,我将向您展示如何安装 TensorFlow,以便您可以开始使用它创建和使用 ML 模型。
使用张量流
在本节中,我们将介绍安装和使用 TensorFlow 的三种主要方式。我们将从如何使用命令行将其安装到您的开发者盒子开始。然后,我们将探索使用流行的 PyCharm IDE(集成开发环境)来安装 TensorFlow。最后,我们将了解 Google Colab 以及如何使用它在浏览器中通过基于云的后端访问 TensorFlow 代码。
在 Python 中安装 TensorFlow
张量流支持使用多种语言创建模型,包括Python、Swift、Java等。在本书中,我们将专注于使用 Python,由于它对数学模型的广泛支持,它实际上是机器学习的语言。如果您还没有,我强烈建议您访问Python以启动并运行它,并访问 learnpython.org以学习 Python 语言语法。
使用 Python 有多种安装框架的方法,但 TensorFlow 团队支持的默认方法是pip.
因此,在您的 Python 环境中,安装 TensorFlow 就像使用一样简单:
pip install tensorflow请注意,从 2.1 版本开始,这将默认安装 GPU 版本的 TensorFlow。在此之前,它使用的是 CPU 版本。因此,在安装之前,请确保您拥有受支持的 GPU 及其所有必需的驱动程序。有关详细信息,请访问TensorFlow。
如果您没有所需的 GPU 或驱动程序,您仍然可以在任何 Linux、PC 或 Mac 上安装 TensorFlow 的 CPU 版本:
pip install tensorflow-cpu启动并运行后,您可以使用以下代码测试您的 TensorFlow 版本:
import tensorflow as tf
print(tf.__version__)您应该会看到如图 1-12所示的输出。这将打印当前运行的 TensorFlow 版本——在这里您可以看到已安装版本 2.0.0。

图 1-12。在 Python 中运行 TensorFlow
在 PyCharm 中使用 TensorFlow
例如,在图 1-13中,我有一个名为example1的新项目,我指定我将使用 Conda 创建一个新环境。当我创建项目时,我将拥有一个干净的新虚拟 Python 环境,我可以在其中安装我想要的任何版本的 TensorFlow。
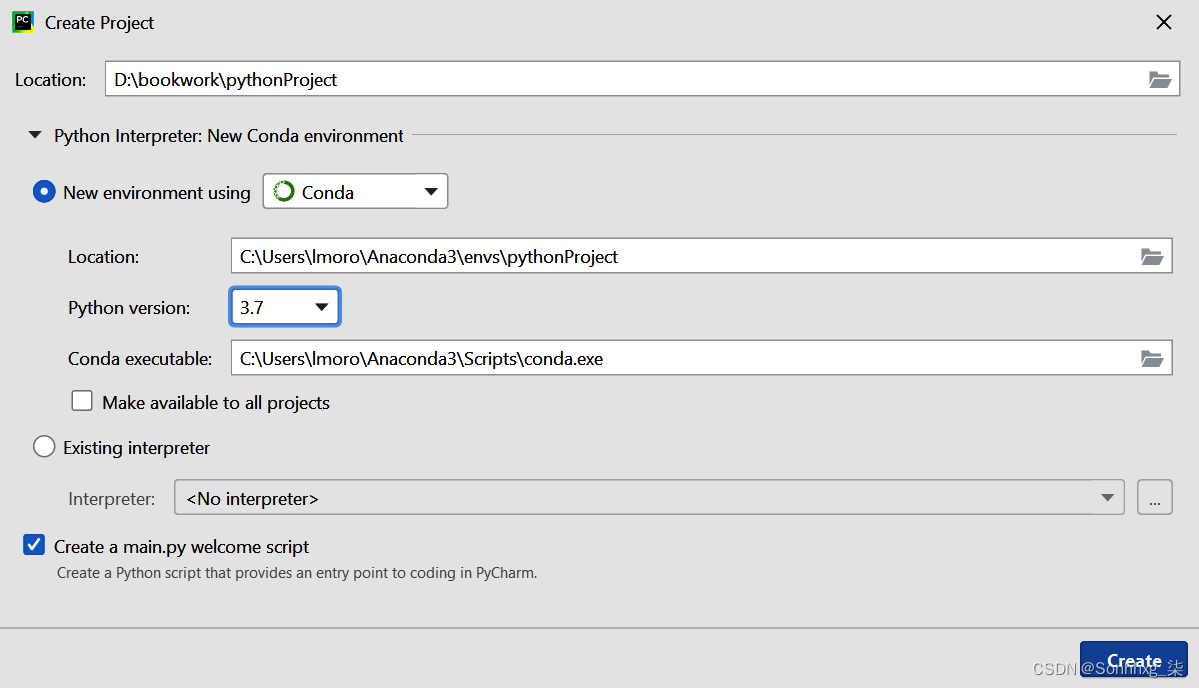
图 1-13。使用 PyCharm 创建新的虚拟环境
创建项目后,您可以打开“文件”→“设置”对话框,然后从左侧菜单中选择“项目: <您的项目名称> ”条目。然后您将看到更改项目解释器和项目结构设置的选项。选择 Project Interpreter 链接,您将看到正在使用的解释器,以及安装在该虚拟环境中的包列表(图 1-14)。
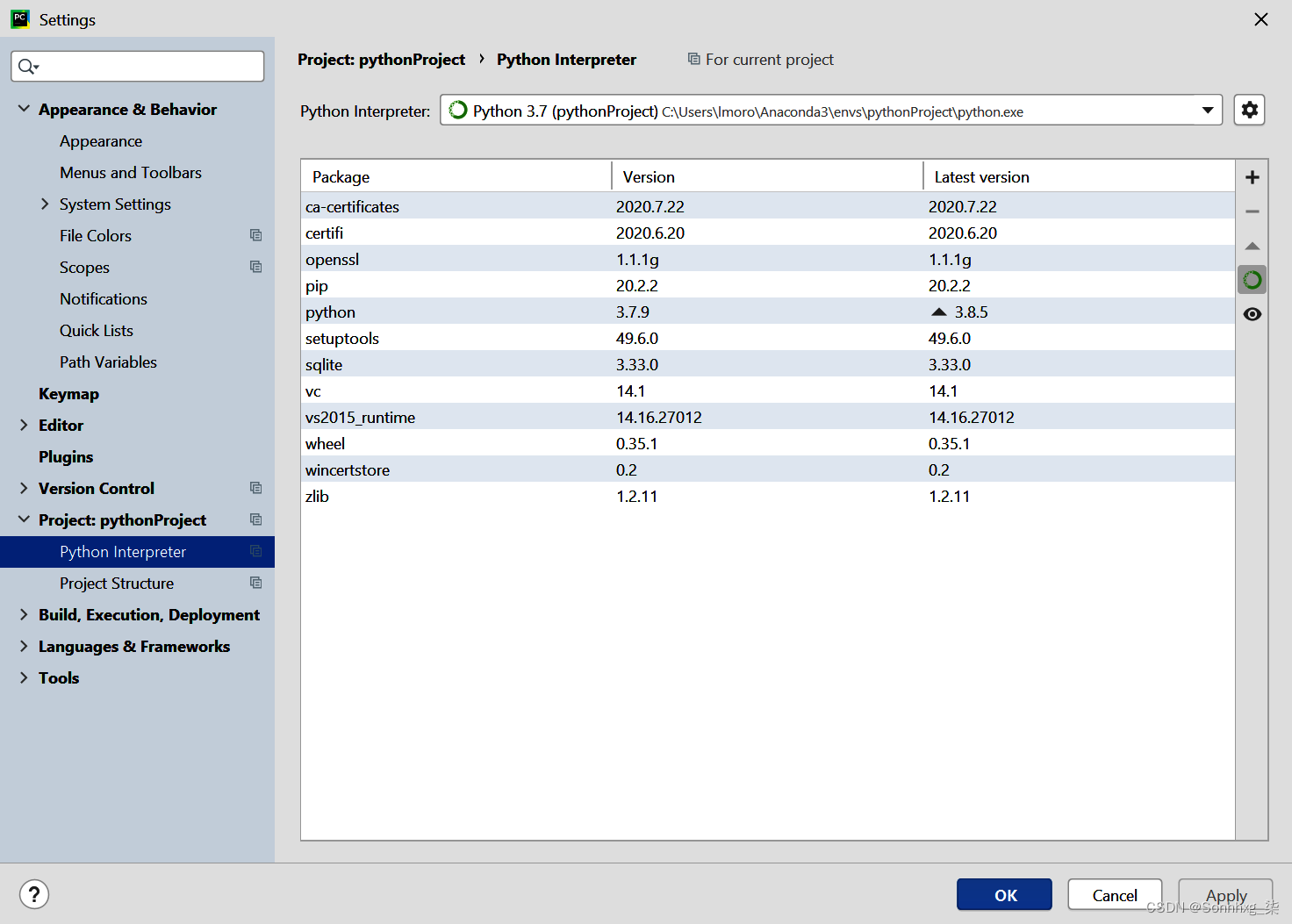
图 1-14。将包添加到虚拟环境
单击右侧的 + 按钮,将打开一个对话框,显示当前可用的包。在搜索框中键入“tensorflow”,您将看到名称中带有“tensorflow”的所有可用包(图 1-15)。

图 1-15。使用 PyCharm 安装 TensorFlow
一旦您选择了 TensorFlow 或您想要安装的任何其他包,然后单击“安装包”按钮,PyCharm 将完成剩下的工作。
安装 TensorFlow 后,您现在可以使用 Python 编写和调试 TensorFlow 代码。
在 Google Colab 中使用 TensorFlow
当你访问 Colab 网站时,你可以选择打开以前的 Colabs 或开始一个新的笔记本,如图1-16所示。
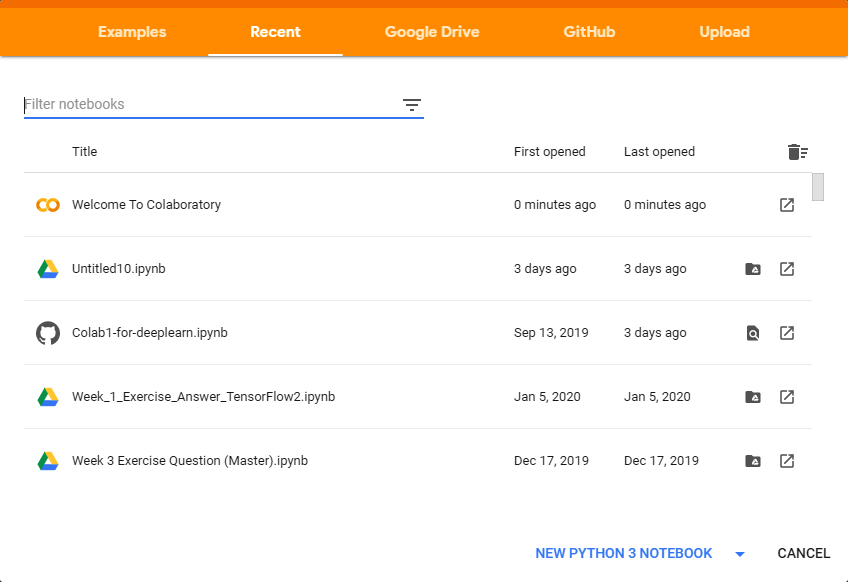
图 1-16。开始使用 Google Colab
单击 New Python 3 Notebook 链接将打开编辑器,您可以在其中添加代码或文本窗格(图 1-17)。您可以通过单击窗格左侧的“播放”按钮(箭头)来执行代码。
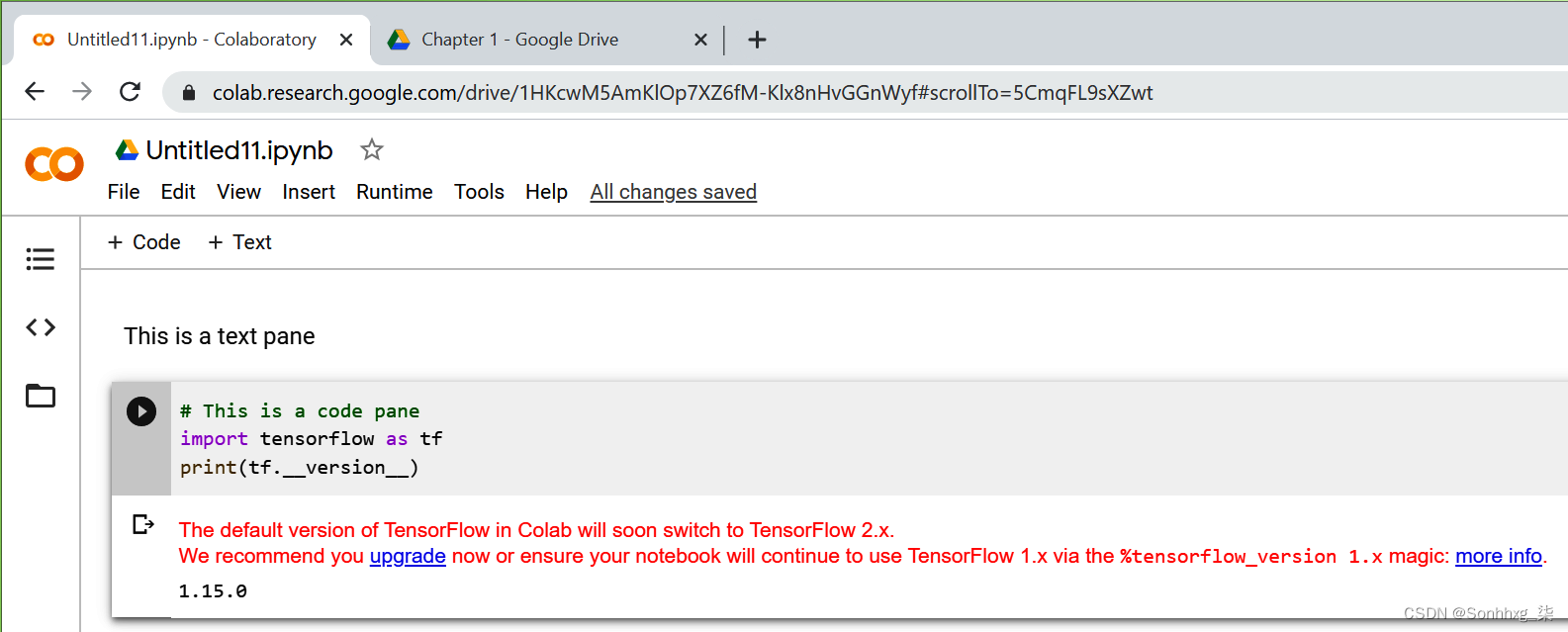
图 1-17。在 Colab 中运行 TensorFlow 代码
检查 TensorFlow 版本始终是个好主意,如此处所示,以确保您运行的是正确的版本。Colab 的内置 TensorFlow 通常会比最新版本落后一两个版本。如果是这种情况,您可以pip install通过简单地使用如下代码块来更新它,如前所示:
!pip install tensorflow==2.1.0运行此命令后,您在 Colab 中的当前环境将使用所需版本的 TensorFlow。
机器学习入门
作为我们在本章前面看到,机器学习范式是您拥有数据、数据被标记的范式,您想要找出将数据与标签匹配的规则。在代码中显示这一点的最简单的可能场景如下。考虑这两组数字:
X = –1, 0, 1, 2, 3, 4
Y = –3, –1, 1, 3, 5, 7X 和 Y 值之间存在某种关系(例如,如果 X 为 –1,则 Y 为 –3,如果 X 为 3,则 Y 为 5,依此类推)。你能看见它吗?
几秒钟后,您可能会看到这里的模式是 Y = 2X – 1。您是怎么得到的?不同的人以不同的方式计算出来,但我通常听到这样的观察结果,即 X 在其序列中增加 1,而 Y 增加 2;因此,Y = 2X +/- 某物。然后他们查看何时 X = 0 并看到 Y = –1,因此他们认为答案可能是 Y = 2X – 1。接下来他们查看其他值并看到这个假设“成立”,答案是Y = 2X – 1。
这与机器学习过程非常相似。让我们看一下您可以编写的一些 TensorFlow 代码,让神经网络为您解决这个问题。
这是完整代码,使用 TensorFlow Keras API。如果它还没有意义,请不要担心;我们将逐行通过它:
import tensorflow as tf
import numpy as np
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([Dense(units=1, input_shape=[1])])
model.compile(optimizer='sgd', loss='mean_squared_error')
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
model.fit(xs, ys, epochs=500)
print(model.predict([10.0]))让我们从第一行开始。你可能听说过神经网络,你可能见过用相互连接的神经元层来解释它们的图表,有点像图 1-18。
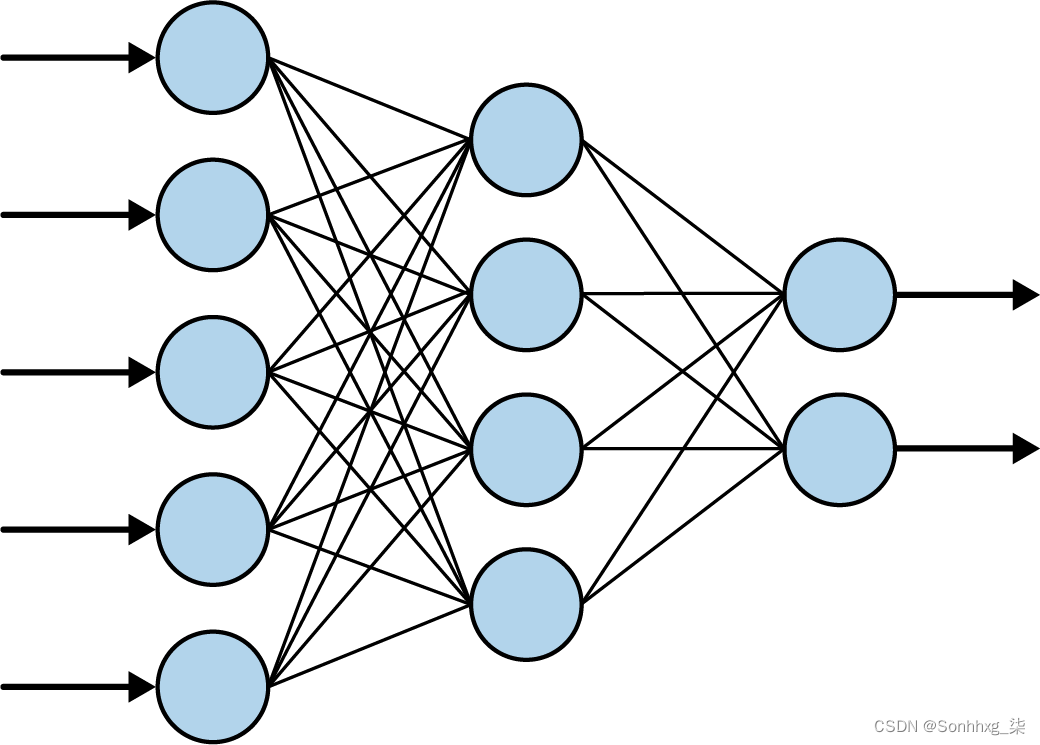
图 1-18。一个典型的神经网络
什么时候你看到这样的神经网络,将每个“圆圈”视为一个神经元,将圆圈的每一列视为一个层。因此,在图 1-18中,有三层:第一层有五个神经元,第二层有四个,第三层有两个。
如果我们回顾我们的代码并只看第一行,我们会发现我们正在定义最简单的神经网络。只有一层,它只包含一个神经元:
model = Sequential([Dense(units=1, input_shape=[1])])什么时候使用 TensorFlow,您可以使用Sequential. 在 中Sequential,您可以指定每一层的外观。我们里面只有一行Sequential,所以我们只有一层。
然后,您可以使用 API 定义层的外观keras.layers。有很多不同的层类型,但这里我们使用一个Dense层。“稠密”表示一组完全(或密集)连接的神经元,这就是您在图 1-18中看到的,其中每个神经元都连接到下一层中的每个神经元。它是最常见的层类型形式。我们的Dense层已经units=1指定,所以我们在整个神经网络中只有一个密集层和一个神经元。最后,当您指定神经网络中的第一层(在本例中,它是我们唯一的层)时,您必须告诉它输入数据的形状是什么。在这种情况下,我们的输入数据是我们的 X,它只是一个值,所以我们指定这是它的形状。
下一行才是真正有趣的地方。我们再来看一下:
model.compile(optimizer='sgd', loss='mean_squared_error')如果您以前做过任何有关机器学习的事情,您可能已经看到它涉及很多数学。如果你多年没有学过微积分,它可能看起来像是一个入门障碍。这是数学的用武之地——它是机器学习的核心。
在像这样的场景,计算机不知道X 和 Y 之间的关系是什么。所以它会做出猜测。例如,它猜测 Y = 10X + 10。然后它需要衡量该猜测的好坏。那是损失函数的工作。
它已经知道 X 为 –1、0、1、2、3 和 4 时的答案,因此损失函数可以将这些与猜测关系的答案进行比较。如果它猜测 Y = 10X + 10,那么当 X 为 –1 时,Y 将为 0。正确答案为 –3,所以有点偏差。但是当 X 为 4 时,猜测的答案是 50,而正确的答案是 7。这真是相去甚远。
武装的有了这些知识,计算机就可以做出另一个猜测。这是工作的 优化器。这是使用重微积分的地方,但使用 TensorFlow,可以对您隐藏。您只需选择合适的优化器以用于不同的场景。在在这种情况下,我们选择了一个称为sgd,它代表随机梯度下降——一个复杂的数学函数,当给定值、先前的猜测以及计算该猜测的错误(或损失)的结果时,它可以生成另一个。随着时间的推移,它的工作是最小化损失,并通过这样做使猜测的公式越来越接近正确答案。
接下来,我们只需将我们的数字格式化为各层期望的数据格式。在 Python 中,有一个库叫做TensorFlow 可以使用的 Numpy,这里我们将我们的数字放入一个 Numpy 数组中,以便于处理它们:
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)这 学习过程将开始于 model.fit命令,像这样:
model.fit(xs, ys, epochs=500)您可以将其理解为“将 X 与 Y 相匹配,并尝试 500 次。” 因此,在第一次尝试时,计算机会猜测其中的关系(例如 Y = 10X + 10),并衡量该猜测的好坏。然后它将这些结果提供给优化器,优化器将生成另一个猜测。然后将重复此过程,其逻辑是损失(或错误)会随着时间的推移而下降,结果“猜测”会越来越好。
图 1-19显示了这个在 Colab notebook 中运行的屏幕截图。看一下随时间变化的损失值。

图 1-19。训练神经网络
我们可以看到,在前 10 个时期内,损失从 3.2868 变为 0.9682。也就是说,仅经过 10 次尝试,网络的性能就比最初的猜测好三倍。然后看看第 500 个纪元发生了什么(图 1-20)。

图 1-20。训练神经网络——最后五个时期
我们现在可以看到损失是 2.61 × 10 -5。损失变得如此之小,以至于模型几乎可以看出数字之间的关系是 Y = 2X – 1。机器已经了解了它们之间的模式。
我们的最后一行代码然后使用经过训练的模型得到如下预测:
print(model.predict([10.0]))笔记
期限 预测通常在处理 ML 模型时使用。不过,不要将其视为展望未来!使用这个术语是因为我们要处理一定程度的不确定性。回想一下我们之前谈到的活动检测场景。当这个人以一定的速度移动时,她很可能是在走路。同样,当模型了解两件事之间的模式时,它会告诉我们答案可能是什么。换句话说,它是在预测答案。(稍后您还将了解 inference,模型从众多答案中选择一个,并推断它选择了正确的答案。)
当我们要求模型在 X 为 10 时预测 Y 时,您认为答案会是什么?您可能会立即想到 19,但这是不正确的。它会选择一个非常接近19 的值。这有几个原因。首先,我们的损失不是 0。它仍然是一个非常小的数额,所以我们应该预料到任何预测的答案都会有很小的偏差。其次,神经网络仅使用少量数据进行训练——在本例中仅使用六对 (X,Y) 值。
这模型中只有一个神经元,该神经元学习权重和偏差,因此 Y = WX + B。这看起来与我们想要的关系 Y = 2X – 1 完全一样,我们希望它学习W = 2 和 B = –1。鉴于该模型仅针对六项数据进行了训练,因此永远不能期望答案恰好是这些值,而是非常接近它们的值。
自己运行代码,看看会得到什么。我运行它时得到 18.977888,但您的答案可能略有不同,因为当神经网络首次初始化时有一个随机元素:您的初始猜测将与我的和第三方的略有不同。
看看网络学到了什么
这显然是一个非常简单的场景,我们在线性关系中匹配 Xs 和 Ys。正如上一节所述,神经元具有它们学习的权重和偏差参数,这使得单个神经元可以很好地学习这样的关系:即,当 Y = 2X – 1 时,权重为 2,偏差为 –1。和在 TensorFlow 中,我们实际上可以查看学习到的权重和偏差,只需对我们的代码进行简单更改,如下所示:
import tensorflow as tf
import numpy as np
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
l0 = Dense(units=1, input_shape=[1])
model = Sequential([l0])
model.compile(optimizer='sgd', loss='mean_squared_error')
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
model.fit(xs, ys, epochs=500)
print(model.predict([10.0]))
print("Here is what I learned: {}".format(l0.get_weights()))不同的是,我创建了一个变量来l0保存Dense图层。然后,在网络完成学习后,我可以打印出该层学习的值(或权重)。
在我的例子中,输出如下:
Here is what I learned: [array([[1.9967953]], dtype=float32),
array([-0.9900647], dtype=float32)]因此,学习到的 X 和 Y 之间的关系是 Y = 1.9967953X – 0.9900647。
这非常接近我们的预期 (Y = 2X – 1),我们可以说它更接近现实,因为我们假设该关系将适用于其他值。
概括
这就是您的第一个机器学习“Hello World”。您可能会认为,对于像确定两个值之间的线性关系这样简单的事情来说,这似乎有点矫枉过正。你是对的。但最酷的是,我们在这里创建的代码模式与用于更复杂场景的模式相同。您将从第 2 章开始看到这些内容,我们将在其中探索一些基本的计算机视觉技术——机器将学习“查看”图片中的模式,并识别其中的内容。



![[附源码]计算机毕业设计动漫电影网站Springboot程序](https://img-blog.csdnimg.cn/8a81c84706074b319fee1ea8b1119f99.png)