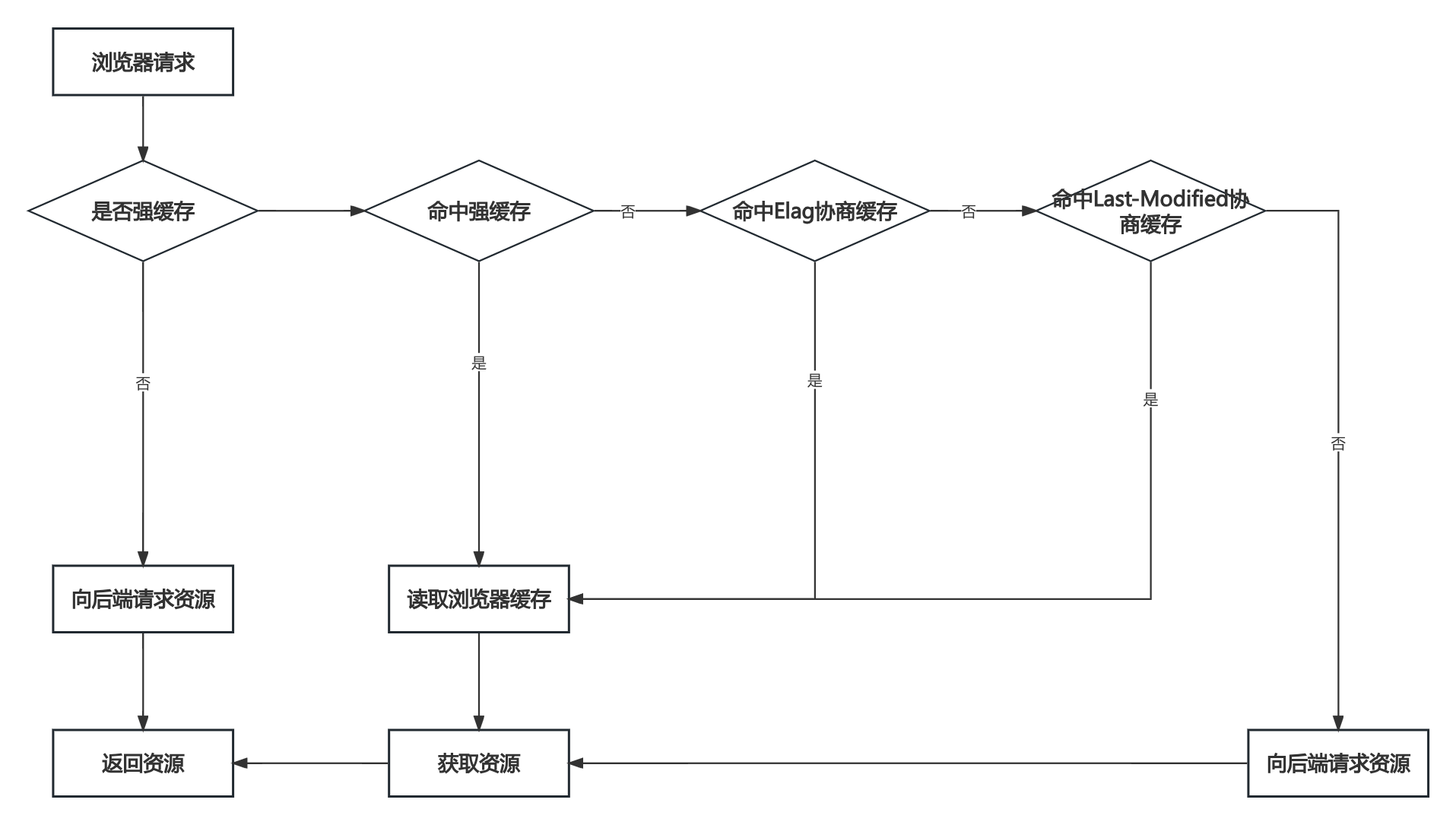
七、事务transaction
1、引入
场景:学工部整个部门解散了,该部门及部门下的员工都需要删除了。
-
操作:
-- 删除学工部 delete from dept where id = 1; -- 删除成功 -- 删除学工部的员工 delete from emp where dept_id = 1; -- 删除失败(操作过程中出现错误:造成删除没有成功) -
问题:如果删除部门成功了,而删除该部门的员工时失败了,此时就造成了数据的不一致。
要解决上述的问题,就需要通过数据库中的事务来解决。
2、基本介绍

DML: 添加插入删除
【⭐】简而言之:事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
当执行事务操作时,mysql会在表上加锁,防止其他用户改表的数据
3、事务操作语句
MYSQL中有两种方式进行事务的操作:
- 自动提交事务:即执行一条sql语句提交一次事务。(默认MySQL的事务是自动提交)
- 手动提交事务:先开启,再提交
事务操作有关的语句:


【⭐】注意commit之前,是其他会话看不到。假如事务T1在commit之前改了数据,它在commit之前也可以查询到自己修改的数据(只是T2 T3…看不到)
手动提交事务使用步骤:
- 第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务
- 第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务
【练习】
-- 事务的一个重要的概念和具体操作
-- 演示
-- 1. 创建一张测试表
CREATE TABLE t27
( id INT,
`name` VARCHAR(32));
-- 2. 开始事务
START TRANSACTION
-- 3. 设置保存点
SAVEPOINT a
-- 执行dml 操作
INSERT INTO t27 VALUES(100, 'tom');
SELECT * FROM t27;
SAVEPOINT b
-- 执行dml操作
INSERT INTO t27 VALUES(200, 'jack');
-- 回退到 b
ROLLBACK TO b --从SAVEPOINT b语句开始重新往下执行
-- 继续回退 a
ROLLBACK TO a
-- 如果这样, 表示直接回退到事务开始的状态.
ROLLBACK
COMMIT
4、细节

5、事务的隔离级别


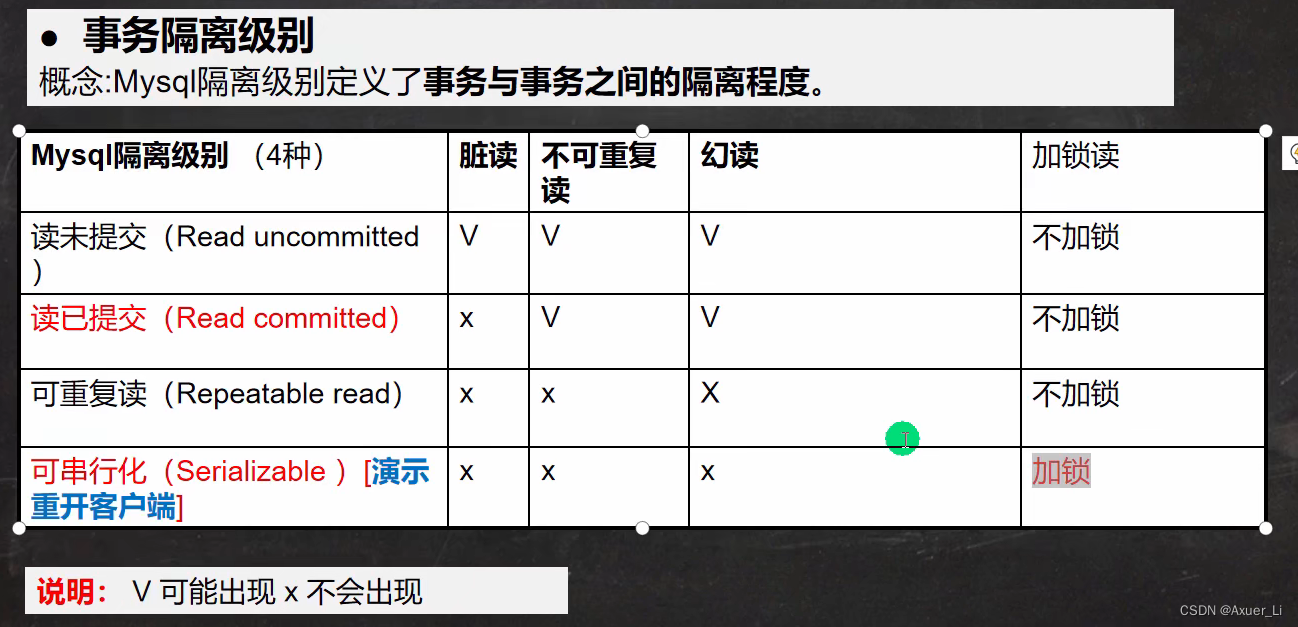
⭐【未提交---脏读 修改删除---不可重复读 插入--幻读】
假设目前有两个事务,事务T1和事务T2
-
事务T1修改了一个数据,还没有commit,T2此时读取数据库数据,获得了T1修改后的数据—>脏读
-
事务T1修改或删除数据后,并且commit,T2此时读取数据库数据,获得了T1修改或删除后的数据,但T2还没有完成自己的commit操作,也就是被其他事务影响了 —> 不可重复读
-
事务T1插入新数据后,并且commit,T2此时读取数据库数据,获得了T1插入后的数据,但T2还没有完成自己的commit操作,也就是被其他事务影响了 —> 幻读
脏读核心是读到了未提交的数据,
不可重复读核心是T2事务读到了它登陆进数据库之后的数据(按理来说它只能得到登陆进去之前的数据)
6、隔离级别案例

-- 演示mysql的事务隔离级别
-- 1. 开了两个mysql的控制台
-- 2. 查看当前mysql的隔离级别
SELECT @@tx_isolation;
-- mysql> SELECT @@tx_isolation;
-- +-----------------+
-- | @@tx_isolation |
-- +-----------------+
-- | REPEATABLE-READ |
-- +-----------------+
-- 3.把其中一个控制台的隔离级别设置 Read uncommitted
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
-- 4. 两个控制台都启动事务start trasaction;
-- 5. 两个控制台都选择数据库use db05
-- 6. 创建表
CREATE TABLE `account`(
id INT,
`name` VARCHAR(32),
money INT);
-- 查看当前会话隔离级别
SELECT @@tx_isolation
-- 查看系统当前隔离级别
SELECT @@global.tx_isolation
-- 设置当前会话隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
-- 设置系统当前隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL [你设置的级别]
7、事务的四大特性
面试题:事务有哪些特性?
原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
事务的四大特性简称为:ACID
-
原子性(Atomicity) :原子性是指事务包装的一组sql是一个不可分割的工作单元,事务中的操作要么全部成功,要么全部失败。
-
一致性(Consistency):一个事务完成之后数据都必须处于一致性状态。
如果事务成功的完成,那么数据库的所有变化将生效。
如果事务执行出现错误,那么数据库的所有变化将会被回滚(撤销),返回到原始状态。
- 隔离性(Isolation):多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
一个事务的成功或者失败对于其他的事务是没有影响。
- 持久性(Durability):一个事务一旦被提交或回滚,它对数据库的改变将是永久性的,哪怕数据库发生异常,重启之后数据亦然存在。
八、索引
1、基本介绍
索引(index):是帮助数据库高效获取数据的数据结构 。
- 简单来讲,就是使用索引可以提高查询的效率。
2、索引的结构
没用索引前,是全表查询,一条条查,效率极低
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。
我们平常所说的索引,如果没有特别指明,都是指默认的 B+Tree 结构组织的索引。
在没有了解B+Tree结构前,我们先回顾下之前所学习的树结构:
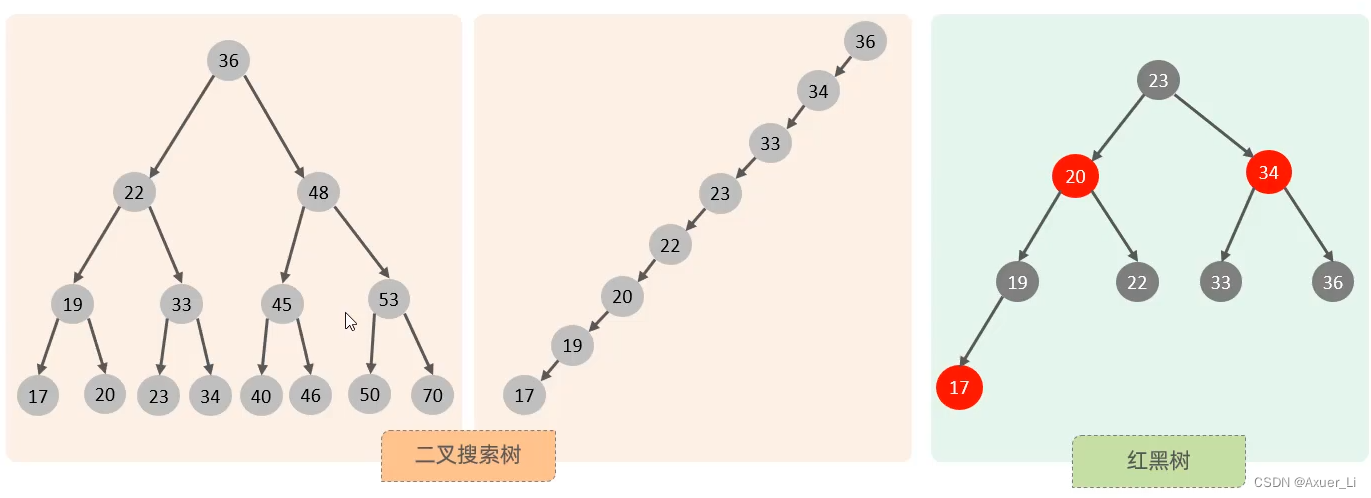
思考:采用二叉搜索树或者是红黑树来作为索引的结构有什么问题?
答案:
最大的问题就是在数据量大的情况下,树的层级比较深,会影响检索速度。因为不管是二叉搜索数还是红黑数,一个节点下面只能有两个子节点。此时在数据量大的情况下,就会造成数的高度比较高,树的高度一旦高了,检索速度就会降低。
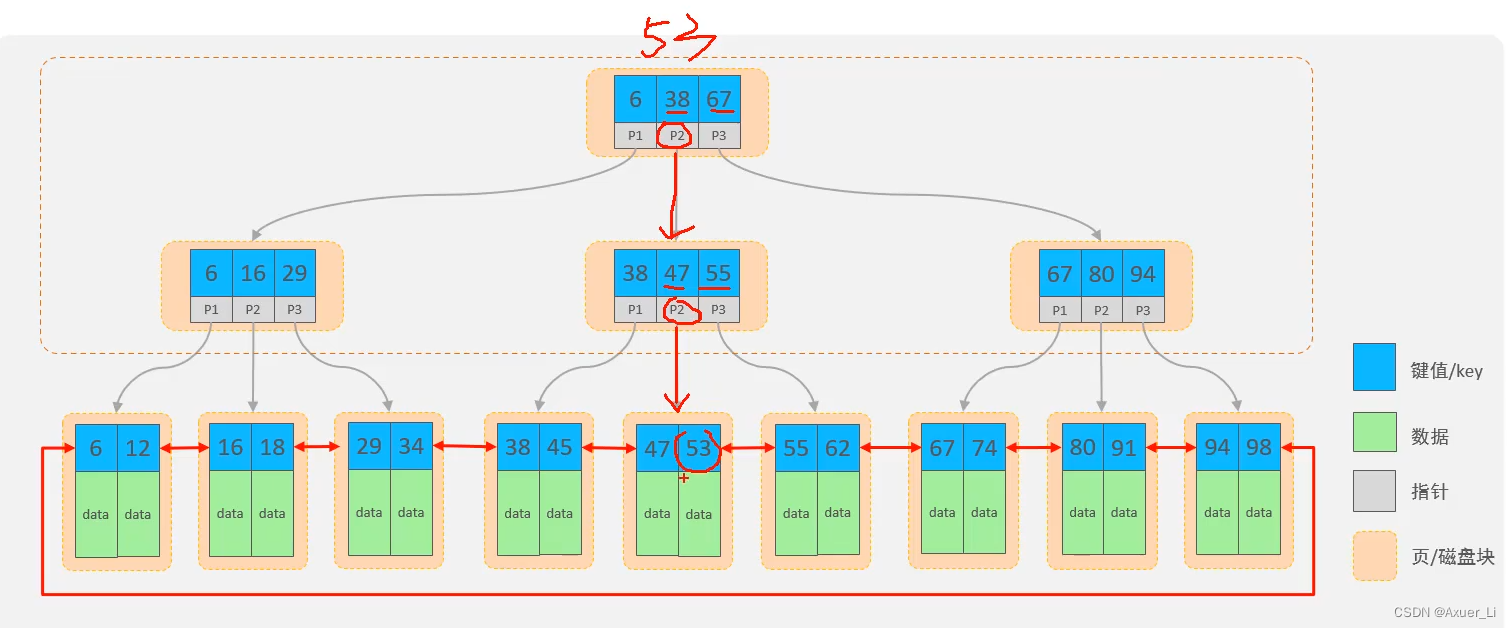

拓展:
非叶子节点都是由key+指针域组成的,一个key占8字节,一个指针占6字节,而一个节点总共容量是16KB,那么可以计算出一个节点可以存储的元素个数:16*1024字节 / (8+6)=1170个元素。
- 查看mysql索引节点大小:show global status like ‘innodb_page_size’; – 节点大小:16384
当根节点中可以存储1170个元素,那么根据每个元素的地址值又会找到下面的子节点,每个子节点也会存储1170个元素,那么第二层即第二次IO的时候就会找到数据大概是:1170*1170=135W。也就是说B+Tree数据结构中只需要经历两次磁盘IO就可以找到135W条数据。
对于第二层每个元素有指针,那么会找到第三层,第三层由key+数据组成,假设key+数据总大小是1KB,而每个节点一共能存储16KB,所以一个第三层一个节点大概可以存储16个元素(即16条记录)。那么结合第二层每个元素通过指针域找到第三层的节点,第二层一共是135W个元素,那么第三层总元素大小就是:135W*16结果就是2000W+的元素个数。
结合上述分析B+Tree有如下优点:
- 千万条数据,B+Tree可以控制在小于等于3的高度
- 所有的数据都存储在叶子节点上,并且底层已经实现了按照索引进行排序,还可以支持范围查询,叶子节点是一个双向链表,支持从小到大或者从大到小查找
3、索引的优缺点
优点:
- 提高数据查询的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
缺点:
- 索引会占用存储空间。
- 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率(因为也维护了索引数据结构)。
但其实影响不大,因为项目中绝大部分都是select,其他操作占少部分
4、索引的类型

主键索引和唯一索引是不重复的
普通索引可以重复:比如名字可以重复,但是想给名字加索引,所以用普通索引
5、索引语法

标准索引名:idx_表名_建立索引的字段名
如:idx_emp_name
-- 为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);
-- 查询 tb_emp表的索引信息
show index in tb_emp;
-- 删除 tb_emp 表中name字段的索引
drop index idx_emp_name on tb_emp;
【⭐】注意:在建表时,MySQL会自动给主键和唯一字段建立索引(而且主键索引性能最高)

其他方式创建、查询、删除索引
-- 演示mysql的索引的使用
-- 创建索引
CREATE TABLE t25 (
id INT ,
`name` VARCHAR(32));
-- 查询表是否有索引
SHOW INDEXES FROM t25;
-- 添加索引
-- 添加唯一索引
CREATE UNIQUE INDEX id_index ON t25 (id);
-- 添加普通索引方式1
CREATE INDEX id_index ON t25 (id);
-- 如何选择
-- 1. 如果某列的值,是不会重复的,则优先考虑使用unique索引, 否则使用普通索引
-- 添加普通索引方式2
ALTER TABLE t25 ADD INDEX id_index (id)
-- 添加主键索引
CREATE TABLE t26 (
id INT ,
`name` VARCHAR(32));
ALTER TABLE t26 ADD PRIMARY KEY (id)
SHOW INDEX FROM t25
-- 删除索引
DROP INDEX id_index ON t25
-- 删除主键索引
ALTER TABLE t26 DROP PRIMARY KEY
-- 修改索引 , 先删除,在添加新的索引
-- 查询索引
-- 1. 方式
SHOW INDEX FROM t25
-- 2. 方式
SHOW INDEXES FROM t25
-- 3. 方式
SHOW KEYS FROM t25
-- 4 方式
DESC t25
6、什么时候适合创建索引

九、引擎
1、基本介绍
【表类型由存储引擎决定】

2、主要存储引擎/表类型特点
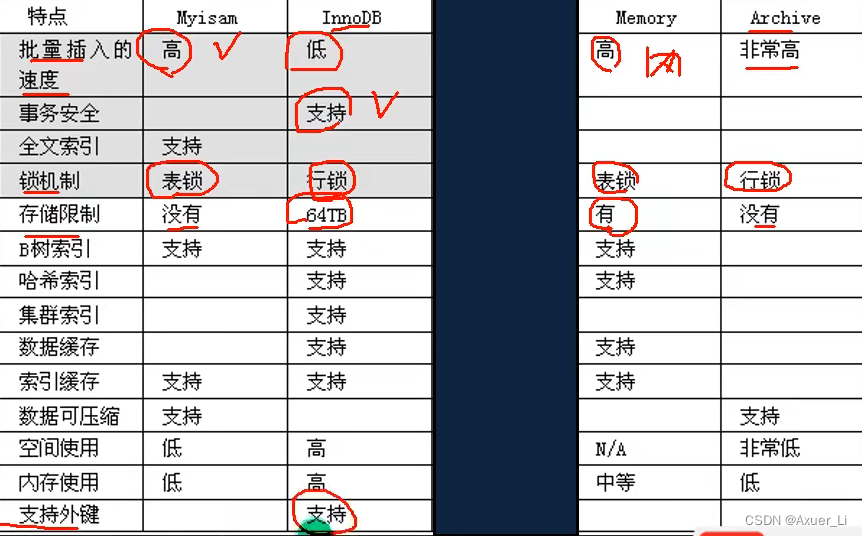
3、 MyISAM、InnoDB、MEMORY引擎区别

4、三种存储引擎使用案例
-- 表类型和存储引擎
-- 查看所有的存储引擎
SHOW ENGINES
-- innodb 存储引擎,是前面使用过.
-- 1. 支持事务 2. 支持外键 3. 支持行级锁
-- myisam 存储引擎
CREATE TABLE table28 (
id INT,
`name` VARCHAR(32)) ENGINE MYISAM
-- 1. 添加速度快 2. 不支持外键和事务 3. 支持表级锁
START TRANSACTION;
SAVEPOINT t1
INSERT INTO t28 VALUES(1, 'jack');
SELECT * FROM t28;
ROLLBACK TO t1 --有问题,不支持事务
-- memory 存储引擎
-- 1. 数据存储在内存中[关闭了Mysql服务,数据丢失, 但是表结构还在]
-- 2. 执行速度很快(没有IO读写) 3. 默认支持索引(hash表)
CREATE TABLE t29 (
id INT,
`name` VARCHAR(32)) ENGINE MEMORY
DESC t29
INSERT INTO t29
VALUES(1,'tom'), (2,'jack'), (3, 'hsp');
SELECT * FROM t29
-- 指令修改存储引擎
ALTER TABLE `t29` ENGINE = INNODB
4、如何选择表的存储引擎

使用MEMORY进行优化

想要获取某个id的登录状态,直接查询内存中的user_state表即可
用户登录状态发生改变,也是将数据写入内存的user_state表中
下一次重启MySQL服务时,所有修改的信息被销毁–》但无所谓,因为随着用户的状态变化还会重新写入user_state表中,状态也不是特别重要的信息
十、视图
1、基本概念
只希望某个用户查询得到数据表中的一部分信息 --> 需要创建一张虚拟表,这张虚拟表就是视图

2、视图和基表关系的示意图

3、基本使用


-- 创建视图
create or replace view stu_v_1 as select id,name from student where id <= 10;
-- 查询视图
show create view stu_v_1;
select * from stu_v_1;
select * from stu_v_1 where id < 3;
-- 修改视图
create or replace view stu_v_1 as select id,name,no from student where id <= 10;
alter view stu_v_1 as select id,name from student where id <= 10;
-- 删除视图
drop view if exists stu_v_1;
4、细节讨论

5、检查选项
1)引入
指定的条件为 id<=10, id为17的数据,是不符合条件的,所以没有查
询出来,但是这条数据确实是已经成功的插入到了基表中。
如果我们定义视图时,如果指定了条件,然后我们在插入、修改、删除数据时,是否可以做到必须满足
条件才能操作,否则不能够操作呢? 答案是可以的,这就需要借助于视图的检查选项了。
2)基本介绍
当使用WITH CHECK OPTION子句创建视图时,MySQL会通过视图检查正在更改的每个行,例如 插
入,更新,删除,以使其符合视图的定义。 MySQL允许基于另一个视图创建视图,它还会检查依赖视
图中的规则以保持一致性。为了确定检查的范围,mysql提供了两个选项: CASCADED 和 LOCAL
,默认值为 CASCADED 。
-- 1.创建语句添加WITH CHECK OPTION
CREATE VIEW stu_v_1
AS SELECT id,name
FROM student
WHERE id<=20
WITH LOCAL CHECK OPTION;
-- 2. 执行插入、更新、删除时会检查是否符合id<=20
INSERT INTO stu_v_1
VALUES(30,'Tom'); -- 报错,因为id>20
3)CASECASED
级联。
不仅仅检查自己,还要检查基于的视图
比如,v2视图是基于v1视图的,如果在v2视图创建的时候指定了检查选项为 cascaded,但是v1视图
创建时未指定检查选项。 则在执行检查时,不仅会检查v2,还会级联检查v2的依赖视图v1。
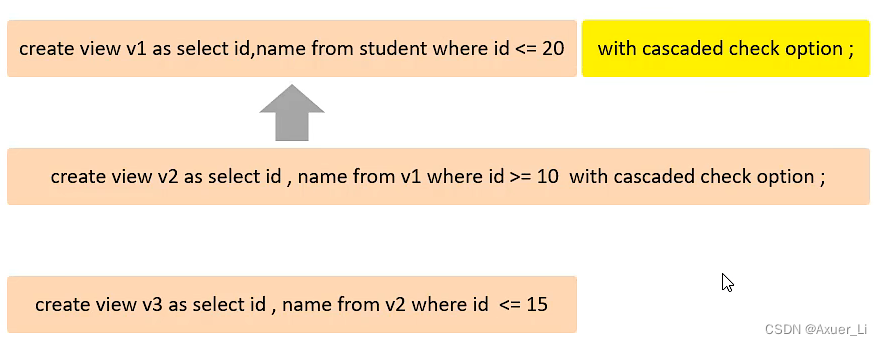
-- 1. 创建完v2后通过v2插入数据
CREATE VIEW v1
AS SELECT id,name
FROM student
WHERE id<=20;
CREATE VIEW v2
AS SELECT id,name
FROM v1
WHERE id>=10;
WITH CASECADED CHECK OPTION;
-- 1.1 执行插入操作时
-- ① 检查id是不是大于等于10
-- ② 检查id是不是小于等于20
INSERT INTO v2
VALUES(28,"Tom"); -- 插入失败,因为在检查v1视图时不满足条件
INSERT INTO v2
VALUES(17,"Tom"); -- 插入成功
-- 2. 创建完v3后通过v3插入数据
CREATE VIEW v3
AS SELECT id,name
FROM v2
WHERE id<=15;
-- 1.2 执行插入操作时
-- ① 由于没有添加with check option,所以不会检查id是否<=15
-- ② 但是会看它依赖的视图(以及所有依赖的依赖),是否有with check option,如果有,就要检查相应条件
-- ③ 所有检查完毕都没有报错,才插入成功,否则报错
INSERT INTO v2
VALUES(18,"Tom"); -- 不会在v3检查,但会在v2和v1中检查。
-- 结果:在源表中插入成功,但由于不满足v3条件,所以不会在v3中显示出来
INSERT INTO v2
VALUES(11,"Tom"); -- 插入成功,在v3中会显示
INSERT INTO v2
VALUES(22,"Tom"); -- 插入失败
4)LOCAL
本地。
只检查自己
比如,v2视图是基于v1视图的,如果在v2视图创建的时候指定了检查选项为 local ,但是v1视图创
建时未指定检查选项。 则在执行检查时,知会检查v2,不会检查v2的关联视图v1
CREATE VIEW v4
AS SELECT id,name
FROM student
WHERE id<=15;
CREATE VIEW v5
AS SELECT id,name
FROM v4
WHERE id>=10;
WITH LOCAL CHECK OPTION;
-- 1.1 执行插入操作时
-- ① 检查id是不是大于等于10
-- ② 看依赖视图(以及依赖的依赖)是否包含检查选项,如果有,则检查
-- ③ 检查都通过,则插入成功
INSERT INTO v2
VALUES(7,"Tom"); -- 插入失败,id<10
INSERT INTO v2
VALUES(16,"Tom"); -- 插入成功,不检查v4,因为v4没有检查选项。会在源表中插入这个数据,只不过在v4中不显示
CREATE VIEW v6
AS SELECT id,name
FROM v5
WHERE id<20;
INSERT INTO v2
VALUES(9,"Tom"); -- 插入失败,id<10
INSERT INTO v2
VALUES(22,"Tom"); -- 插入成功,不会在v4和v6中显示
6、视图更新
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系(即视图中的数据必须在表数据中存在,是最原始的数据)。如果视图包含以下任何一
项,则该视图不可更新:
A. 聚合函数或窗口函数(SUM()、 MIN()、 MAX()、 COUNT()等)
B. DISTINCT
C. GROUP BY
D. HAVING
E. UNION 或者 UNION ALL
例子
create view stu_v_count as select count(*) from student; //视图中得到单行单列的数据,但这个count(*)本身不存在,不是一对一
insert into stu_v_count values(10); -- 报错
7、视图的作用
-
简单
视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。 -
安全
数据库可以授权,但不能授权到数据库特定行和特定的列上。通过视图用户只能查询和修改他们所能见到的数据 -
数据独立
视图可帮助用户屏蔽真实表结构变化带来的影响。可以烧做很多改动,就升级数据表。比如源表gender字段修改为了sex字段,那么我们只需要把视图定义时的gender改为sex,并取一个别名sex,以避免业务开发时需要大幅修改代码的情况
-
高性能
关系数据库的数据常常会分表存储,如果想建立这些表之间的关系,就会使用到连接JOIN,但这样不仅麻烦效率也比较低。但如果用视图将相关的表和字段组合在一起,只筛选出对关系有用的信息,就可以避免使用JOIN查询数据。
8、视图课堂练习

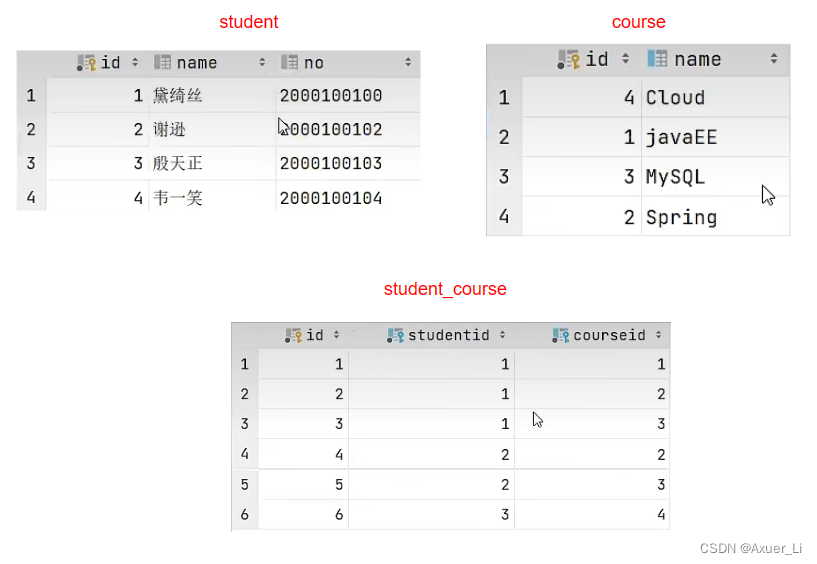
-- 1
CREATE VIEW tb_user_view
AS SELECT id,name,profssion,age,gender,status,createtime
FROM tb_user;
-- 2
CREATE VIEW tb_stu_couse_view
AS SELECT s.name student_name,s.no student_no,c.name student_course
FROM student s,student_course sc,course c
WHERE s.id = sc.studentid AND sc.courseid = c.id
SELECT * FROM tb_stu_course_view; -- 用视图简化多表联查的操作,相当于用视图封装了多表联查,在后续业务中,只需要对视图进行操作即可
十一、MySQL管理
1、Mysql用户
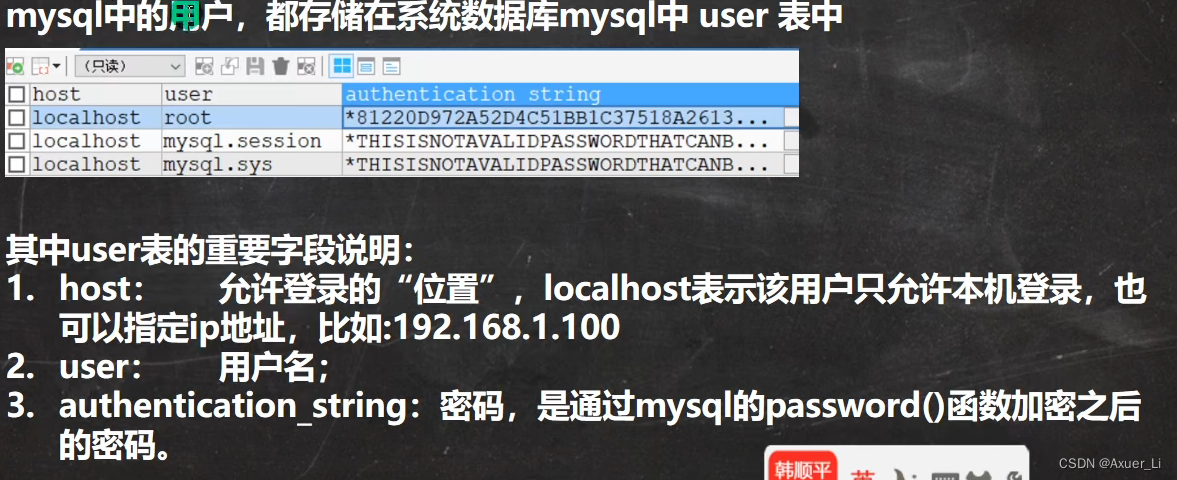
2、创建/删除用户

登录位置时ip位置
-- 1. 创建新的用户
-- 解读 (1) 'hsp_edu'@'localhost' 表示用户的完整信息
-- (2)'hsp_edu' 是用户名 'localhost' 是登录的IP
-- (3) 123456 密码, 但是注意 存放到 mysql.user表时,是password('123456') 加密后的密码
-- *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
CREATE USER 'hsp_edu'@'localhost' IDENTIFIED BY '123456'
-- 查询
SELECT `host`, `user`, authentication_string
FROM mysql.user
-- 2. 删除用户
DROP USER 'hsp_edu'@'localhost'
3、不同数据库用户,操作的库和表不相同
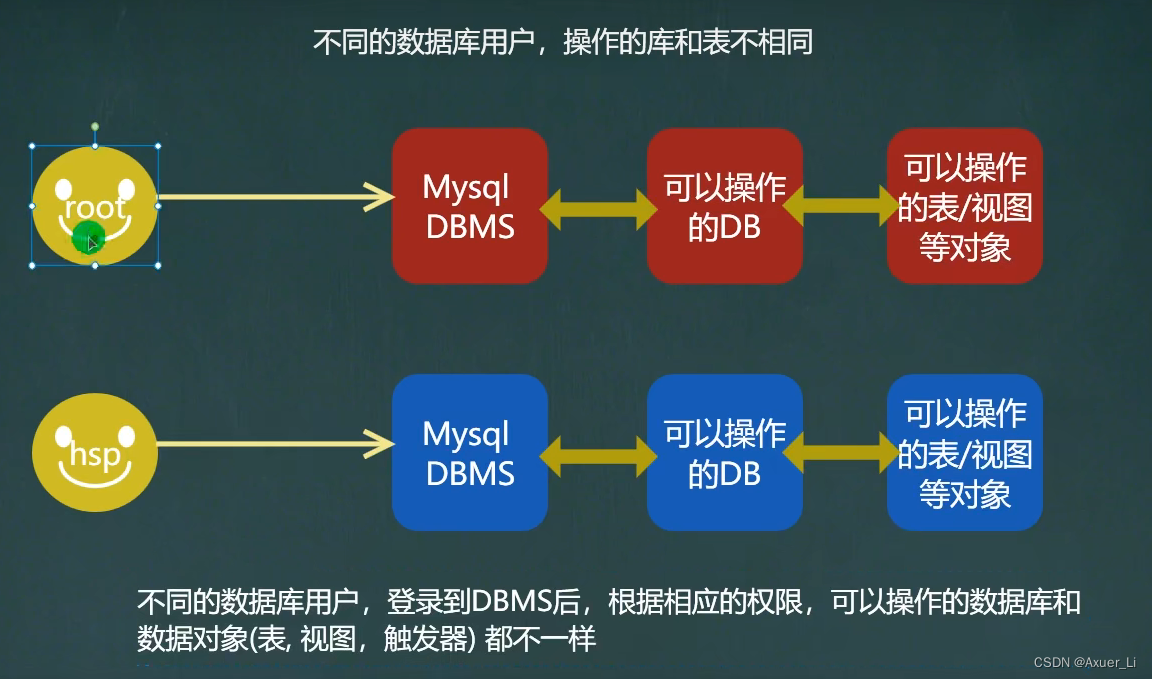
-- 3. 登录(连接)
-- 用datagrip等工具连接hsp_edu时,看到的数据库完全不一样
4、修改密码

-- 修改自己的密码,没问题(目前是hsp_edu用户在操作)
SET PASSWORD = PASSWORD('abcdef');
-- 修改其他人的密码,需要权限(这里修改root不成功)
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('123456');
-- root 用户修改 hsp_edu@localhost 密码, 是可以成功.
SET PASSWORD FOR 'hsp_edu'@'localhost' = PASSWORD('123456')
5、mysql中的权限
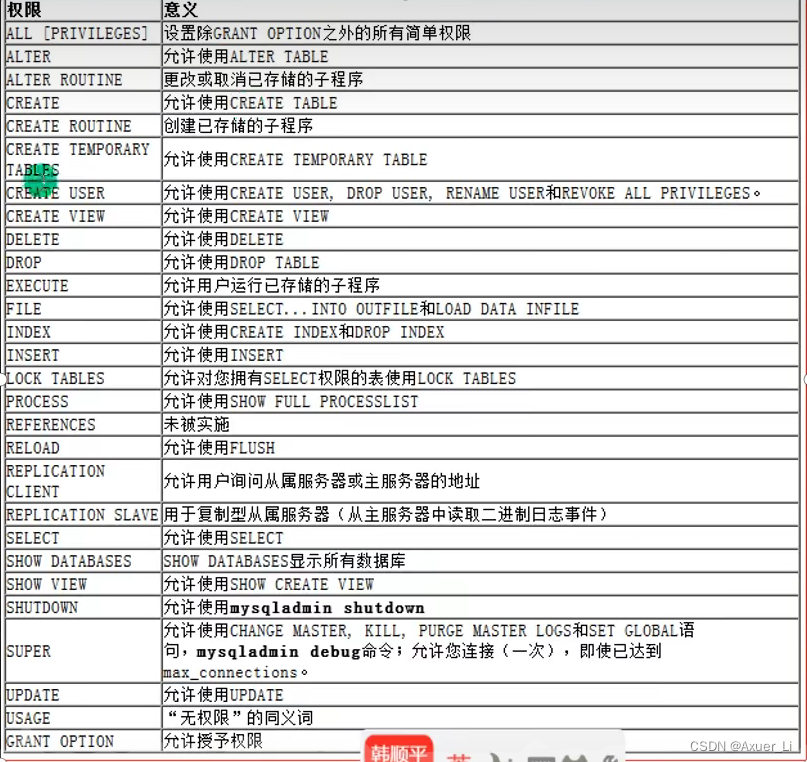
6、给用户授权
一般都是root用户给普通用户授权的。

7、回收用户授权

8、权限生效指令
MySQL5.7之后基本都是系统自动生效

9、用户管理练习

-- 演示 用户权限的管理
-- 创建用户 shunping 密码 123 , 从本地登录
CREATE USER 'shunping'@'localhost' IDENTIFIED BY '123'
-- 使用root 用户创建 testdb ,表 news
CREATE DATABASE testdb
CREATE TABLE news (
id INT ,
content VARCHAR(32));
-- 添加一条测试数据
INSERT INTO news VALUES(100, '北京新闻');
SELECT * FROM news;
-- 给 shunping 分配查看 news 表和 添加news的权限
GRANT SELECT , INSERT
ON testdb.news
TO 'shunping'@'localhost'
-- 可以增加update权限
GRANT UPDATE
ON testdb.news
TO 'shunping'@'localhost'
-- 修改 shunping的密码为 abc
SET PASSWORD FOR 'shunping'@'localhost' = PASSWORD('abc');
-- 回收 shunping 用户在 testdb.news 表的所有权限
REVOKE SELECT , UPDATE, INSERT ON testdb.news FROM 'shunping'@'localhost'
REVOKE ALL ON testdb.news FROM 'shunping'@'localhost'
-- 删除 shunping
DROP USER 'shunping'@'localhost'
10、细节

-- 说明 用户管理的细节
-- 在创建用户的时候,如果不指定Host, 则为% , %表示表示所有IP都有连接权限
-- create user xxx;
CREATE USER jack
SELECT `host`, `user` FROM mysql.user
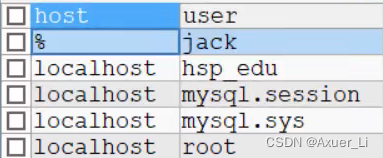
-- 你也可以这样指定
-- create user 'xxx'@'192.168.1.%' 表示 xxx用户在 192.168.1.*的ip可以登录mysql
CREATE USER 'smith'@'192.168.1.%'
-- 在删除用户的时候,如果 host 不是 %, 需要明确指定 '用户'@'host值'
DROP USER jack -- 默认就是 DROP USER 'jack'@'%'
DROP USER 'smith'@'192.168.1.%'
十二、章作业
【1】

别名如果带空格,必须用’'或者""括起来
D答案会这么分析:Annual是sal*12 的别名,还要查找一个新列Salary

“order by 3” 的意思是按照SELECT语句中第三个列进行排序。这个语法相当于将第三个列名替换成数字 1,以代表第三个列。 “order by 3” 和 “order by 第三列列名” 是等价的。
由于这里SELECT没有第三列,所以C答案是错的
【2】

-- 9
-- 提示:LAST_DAY(日期),可以返回该日期所在月份的最后一天
SELECT *
FROM emp
WHERE hiredate = DATE_SUB(LAST_DAY(hiredate),INTERVAL 3 DAY);
-- 或者
SELECT *
FROM emp
WHERE DAY(DATE_ADD(hiredate , INTERVAL 4 DAY)) = 1;
-- 10
SELECT *
FROM emp
WHERE DATE_ADD(hiredate, INTERVAL 12 YEAR) < NOW();
-- 11
SELECT CONCAT(LCASE(SUBSTRING(ename,1,1)) , SUBSTRING(ename,2)) AS new_name
FROM emp
-- 12
SELECT ename
FROM emp
WHERE ename LIKE "_____"; -- 5个_
-- 或者
SELECT ename
FROM emp
WHERE LENGTH(ename) = 5;
【3】



-- 13
SELECT *
FROM emp
WHERE ename NOT LIKE '%R%'; -- %是任意字符,也就是说0个字符也可以,所以R在首尾也会被检测到
-- 21
SELECT ename , FLOOR(sal / 30)
FROM emp;
-- 23
SELECT ename , DATEDIFF(entrydate , now())
FROM emp;
-- 24
SELECT ename
FROM emp
WHERE ename LIKE 'A';
-- 25
SELECT ename , FROM_DAYS(DATEDIFF(NOW() , entrydate)) AS '工作年月日'
FROM emp;
-- 或者(这么算不准确)
SELECT ename , FLOOR(DATEDIFF(NOW() , entrydate) / 365) AS '工作年' ,
FLOOR(DATEDIFF(NOW() , entrydate) % 365 / 31) AS '工作月',
DATEDIFF(NOW() , entrydate) % 31) AS '工作日'
FROM emp;
【4】

-- 1
SELECT dept.name,count(*) AS '员工数'
FROM emp,dept
WHERE emp.dept_id = dept.id
GROUP BY emp.dept_id;
-- 或者
SELECT dept.name,tmp.c AS '员工数'
FROM dept,(SELECT dept_id , COUNT(*) AS c
FROM emp
GROUP BY dept_id) tmp
WHERE dept.id = tmp.dept_id;
-- 2
SELECT *
FROM emp
WHERE sal > (
SELECT sal
FROM emp
WHERE ename = 'SMITH');
-- 3
SELECT employee.name, manager.name, employee.entrydate , manager.entrydate
FROM emp employee , emp manager
WHERE employee.mgr = manager.id
AND emp.entrydate > manager.entrydate;
-- 4
SELECT dept.name , emp.*
FROM dept
LEFT JOIN emp
ON dept.id = emp.dept_id; --注意是ON不是WHERE
-- 5
SELECT e.ename,d.name
FROM emp e,dept d
WHERE e.job = "CLERK"
AND e.dept_id = d.id;
-- 6
SELECT job,MIN(sal)
FROM emp
GROUP BY job
HAVING MIN(sal) > 1500;
-- 7
SELECT ename
FROM emp
WHERE dept_id = (
SELECT id
FROM dept
WHERE name = "SALES");
-- 8
-- 下面报错,聚合函数不能单独用在WHERE语句里,一般用在HAVING和SELECT里
SELECT *
FROM emp
WHERE sal > AVG(sal);
-- 正确写法
SELECT *
FROM emp
WHERE sal > (
SELECT AVG(sal)
FROM emp);
【5】

-- 13
-- IFNULL(a,b):如果a为空,则把b的值赋给a
SELECT tb_dept.id,tb_dept.name,IFNULL(tmp.count,0)
FROM tb_dept
LEFT JOIN(SELECT dept_id, COUNT(*) AS count
FROM tb_emp
GROUP BY dept_id) tmp
ON tb_dept.id = tmp.dept_id
ORDER BY tb_dept.id;
【6】
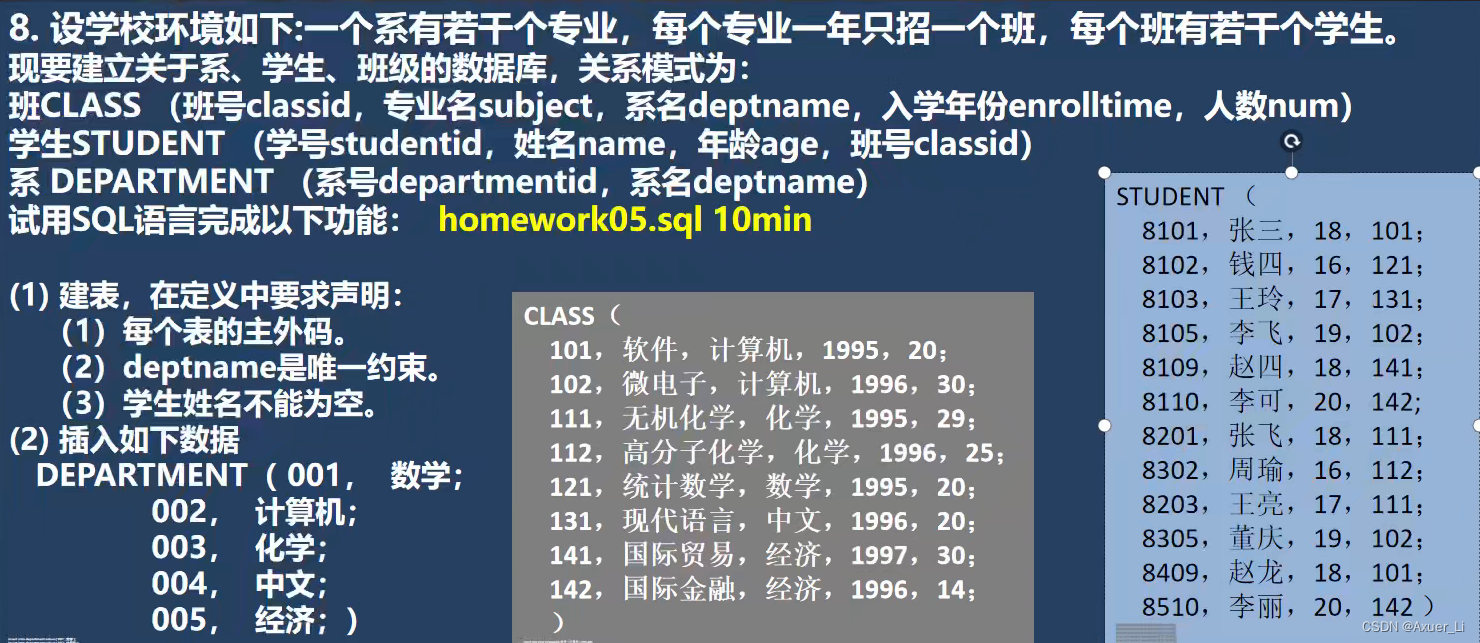

-- 3.3
SELECT departmentid , tmp.deptname,tmp.c AS "系人数"
FROM department,(SELECT deptname,SUM(num) AS c
FROM class
GROUP BY deptname
HAVING SUM(num) >= 30) tmp
WHERE department.departmentname = tmp.deptname;
-- 5
START TRANSACTION;
-- 张三所在的班级人数-1
UPDATE class SET NUM = NUM - 1
WHERE classid = (
SELECT classid
FROM student
WHERE name = '张三'
);
-- 删除张三
DELETE FROM student
WHERE name = '张三';
-- 提交事务
COMMIT;