引言
最近,我进行了一次网上搜索,以寻找DevOps的概述,尽管有大量的DevOps工具和实践,但我无法找到一个综合的概述。因此,我开始了对DevOps生态系统和最佳实践的梳理,以创建一个整体视图,方便后续研究实践
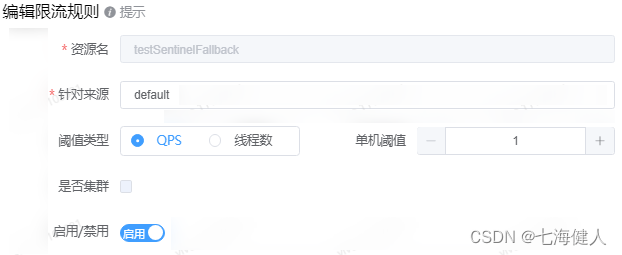
CI(持续集成)
这个图表的CI部分包括以下组件:

•代码仓库:在图表中,我使用了GitLab作为源代码控制和代码仓库,因为它在仓库管理方面具有用户友好的界面。它允许以分层方式创建组和子组,有效地控制团队结构。•构建工具:图表中也使用了GitLab作为构建工具。它提供了广泛的功能,用于编写代码管道,并支持模板化。•自动化测试:虽然有许多端到端测试框架可用,但目前在社区中最流行的是Cypress。对于自动化安全测试,您还可以使用GitLab,它提供了全面的工具集,供您使用。•构件库:为了存储Docker镜像或Helm图表,我集成了Harbor作为构建库。尽管有基于云的选项,但在空隙环境中使用诸如Harbor之类的工具是必需的。您可以参考我另一篇文章,比较了用于存储Docker镜像的Harbor和Nexus:
我将CD存储库与源代码存储库分开,因为需要多个环境来为多个客户提供服务。然而,如果您的每个产品没有多个环境,您可以将它们合并到一个存储库中。

基础设施即代码:为了创建基础设施(VM)和平台(Kubernetes),使用像Terraform这样的工具是必不可少的,它可以轻松创建。虽然还有其他选择,比如Ansible或Puppet,但这些工具不支持声明性格式。我强烈建议使用Terraform和GitLab来存储您的IAC状态。
部署服务:我将GitLab作为部署服务,用于存储每个应用程序的环境配置文件。您可以在GitLab内创建一个Git存储库,存储您的配置文件,并定义一个管道,以将Helm图表部署到Kubernetes集群。虽然还有其他选择,比如Spinnaker,但我发现它相当复杂,具有许多可能对您的用例不必要的功能。
CM(持续监控)
CM(持续监控)部分包括以下组件和关系:

度量服务器:在图表中,我使用Prometheus作为度量服务器,用于收集和存储来自应用程序、平台和基础设施的度量。
日志服务器:我使用了社区中广受欢迎的ELK堆栈(Elasticsearch + Logstash + Kibana)来收集和存储日志。它提供了广泛的功能,可以根据收集的日志增强分析仪表板。
跟踪服务器:对于跟踪服务器,我选择了Jaeger。虽然还有另一个选项Zipkin,但我个人推荐Jaeger,因为它是一个较新的项目,拥有更大的社区。如果您想了解如何从应用程序发送跟踪到Jaeger,可以查看我关于这个主题的另一篇文章:
基础设施监控:有许多可用于基础设施监控的工具,每个工具都有其自己的优缺点。然而,我选择了Zabbix,因为它是一个具有全面监控能力的开源项目。它是一个基于代理的工具,虽然还有一些无代理的替代方案。一些公司选择使用SolarWinds作为替代方案。
自动缩放器:
Keda项目专门设计用于基于Kubernetes中不同指标的Pod自动缩放。它支持各种类型的应用程序,并从中收集指标以便于自动缩放。此外,还有其他工具可用于根据Prometheus收集的指标自动缩放基础设施和平台资源(如VM数量或Kubernetes工作节点)。
警报管理器:警报管理器工具应能够从不同系统收集和去重警报。Alertmanager是Prometheus开源团队开发的一个工具,可以接收来自各种监控工具(如Prometheus、Zabbix和Elasticsearch)的警报。它能够根据预定义的规则和配置对这些警报进行分组、去重和过滤。此外,它还支持各种通知机制,可以将警报发送给支持团队,包括电子邮件、PagerDuty、Slack和其他自定义集成。
结论
总体而言,如下所示:

这些系统共同工作,以确保生产环境的可靠性和弹性。CI + CD + CM的组合促进了不同团队之间更好的协作。如果您正在遵循敏捷方法,开发团队可以处理CI部分,运维团队可以处理CD部分,监控团队可以处理CM部分。这些团队合作,以确保服务的可靠性。
希望这些整理对你有点帮助~

![[LeetCode - Python] 11.乘最多水的容器(Medium);26. 删除有序数组中的重复项(Easy)](https://img-blog.csdnimg.cn/d8583aed89c74b628cfa1e67253e2e79.png)