Reinforcement Learning with Code 【Code 4. DQN】
This note records how the author begin to learn RL. Both theoretical understanding and code practice are presented. Many material are referenced such as ZhaoShiyu’s Mathematical Foundation of Reinforcement Learning.
The code refers to Mofan’s reinforcement learning course and Hands on Reinforcement Learning.
文章目录
- Reinforcement Learning with Code 【Code 4. DQN】
- 1. Theoretical Basis
- 2. Gym Env
- 3. Implement DQN
- 4. Reference
1. Theoretical Basis
Readers can get some insight understanding from (Chapter 8. Value Function Approximation), which is omitted here.
这里还是简要介绍一下DQN的思想,就是用一个神经网络来近似值函数(value function),根据Q-learning的思想,我们已经使用
r
+
γ
max
a
q
(
s
,
a
,
w
)
r+\gamma\max_a q(s,a,w)
r+γmaxaq(s,a,w)来近似了真值,当我们使用神经网络来近似值函数时,我们用符号
q
^
\hat{q}
q^来表示对q-value的近似。
则我们需要优化的目标函数是
min
w
J
(
w
)
=
E
[
(
R
+
γ
max
a
∈
A
(
S
′
)
q
^
(
S
′
,
a
,
w
)
−
q
^
(
S
,
A
,
w
)
)
2
]
{\min_w J(w) = \mathbb{E} \Big[ \Big( R+\gamma \max_{a\in\mathcal{A}(S^\prime)} \hat{q}(S^\prime, a, w) - \hat{q}(S,A,w) \Big)^2 \Big]}
wminJ(w)=E[(R+γa∈A(S′)maxq^(S′,a,w)−q^(S,A,w))2]
详细的解释见下图,或则见(Chapter 8. Value Function Approximation)。

这里涉及到了两个技巧,第一个就是Experience replay,第二个技巧是Two Networks。
-
Experience replay: 主要是需要维护一个经验池,在一般的有监督学习中,假设训练数据是独立同分布的,我们每次训练神经网络的时候从训练数据中随机采样一个或若干个数据来进行梯度下降,随着学习的不断进行,每一个训练数据会被使用多次。在原来的 Q-learning 算法中,每一个数据只会用来更新一次值。为了更好地将 Q-learning 和深度神经网络结合,DQN 算法采用了经验回放(experience replay)方法,具体做法为维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中,训练 Q 网络的时候再从回放缓冲区中随机采样若干数据来进行训练。这么做可以起到以下两个作用。
-
使样本满足独立假设。在 MDP 中交互采样得到的数据本身不满足独立假设,因为这一时刻的状态和上一时刻的状态有关。非独立同分布的数据对训练神经网络有很大的影响,会使神经网络拟合到最近训练的数据上。采用经验回放可以打破样本之间的相关性,让其满足独立假设。
-
提高样本效率。每一个样本可以被使用多次,十分适合深度神经网络的梯度学习。
-
-
Two Networks: DQN算法的最终更新目标是让 q ^ ( s , a , w ) \hat{q}(s,a,w) q^(s,a,w)逼近 r + γ max a q ^ ( s , a , w ) r+\gamma\max_a\hat{q}(s,a,w) r+γmaxaq^(s,a,w),由于 TD 误差目标本身就包含神经网络的输出,因此在更新网络参数的同时目标也在不断地改变,这非常容易造成神经网络训练的不稳定性。为了解决这一问题,DQN 便使用了目标网络(target network)的思想:既然训练过程中 Q 网络的不断更新会导致目标不断发生改变,不如暂时先将 TD 目标中的 Q 网络固定住。为了实现这一思想,我们需要利用两套 Q 网络。
- 原来的训练网络 q ^ ( s , a , w ) \hat{q}(s,a,w) q^(s,a,w),用于计算原来的损失函数 q ^ ( S , A , w ) \hat{q}(S,A,w) q^(S,A,w)中的项,并且使用正常梯度下降方法来进行更新。
- 目标网络的参数用
w
T
w^T
wT来表示,训练网络参数用
w
w
w来表示,目标网络参数
w
T
w^T
wT用于计算原先损失函数中的项。如果两套网络的参数随时保持一致,则仍为原先不够稳定的算法。为了让更新目标更稳定,目标网络并不会每一步都更新。具体而言,目标网络使用训练网络的一套较旧的参数,训练网络
q
^
(
s
,
a
,
w
)
\hat{q}(s,a,w)
q^(s,a,w)在训练中的每一步都会更新,而目标网络的参数每隔
C
C
C步才会与训练网络
w
w
w同步一次,即
w
T
←
w
w^T\leftarrow w
wT←w。这样做使得目标网络相对于训练网络更加稳定。而训练网络按照一下方式进行更新
w t + 1 = w t + α t [ r t + 1 + γ max a ∈ A ( s t + 1 ) q ^ ( s t + 1 , a , w T ) − q ^ ( s t , a t , w ) ] ∇ w q ^ ( s t , a t , w ) \textcolor{red}{w_{t+1} = w_{t} + \alpha_t \Big[ r_{t+1} + \gamma \max_{a\in\mathcal{A}(s_{t+1})} \hat{q}(s_{t+1},a,w_T) - \hat{q}(s_t,a_t,w) \Big] \nabla_w \hat{q}(s_t,a_t,w)} wt+1=wt+αt[rt+1+γa∈A(st+1)maxq^(st+1,a,wT)−q^(st,at,w)]∇wq^(st,at,w)
2. Gym Env
本文使用gym库中的CartPole-v1作为智能体的交互环境,其目的是左右移动小车,让小车上的木棍能够尽可能保持竖直。所以动作空间为离散值,只有向左 and 向右。但状态空间是连续的,则这种情况下不能使用tabular的表示方式。CartPole-v1的action_space和state_space的设置如下,详见gym官网
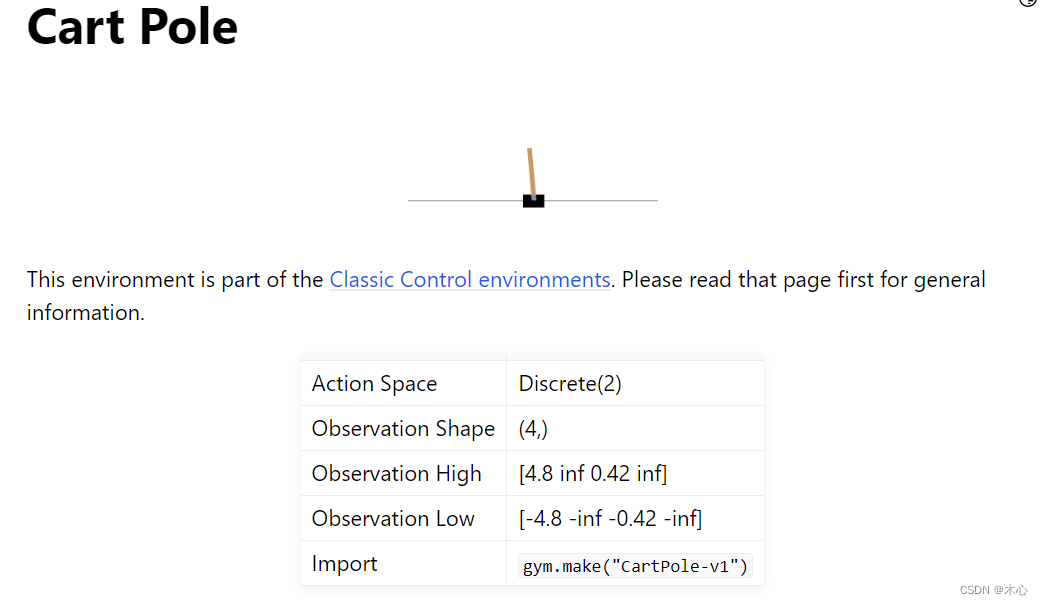
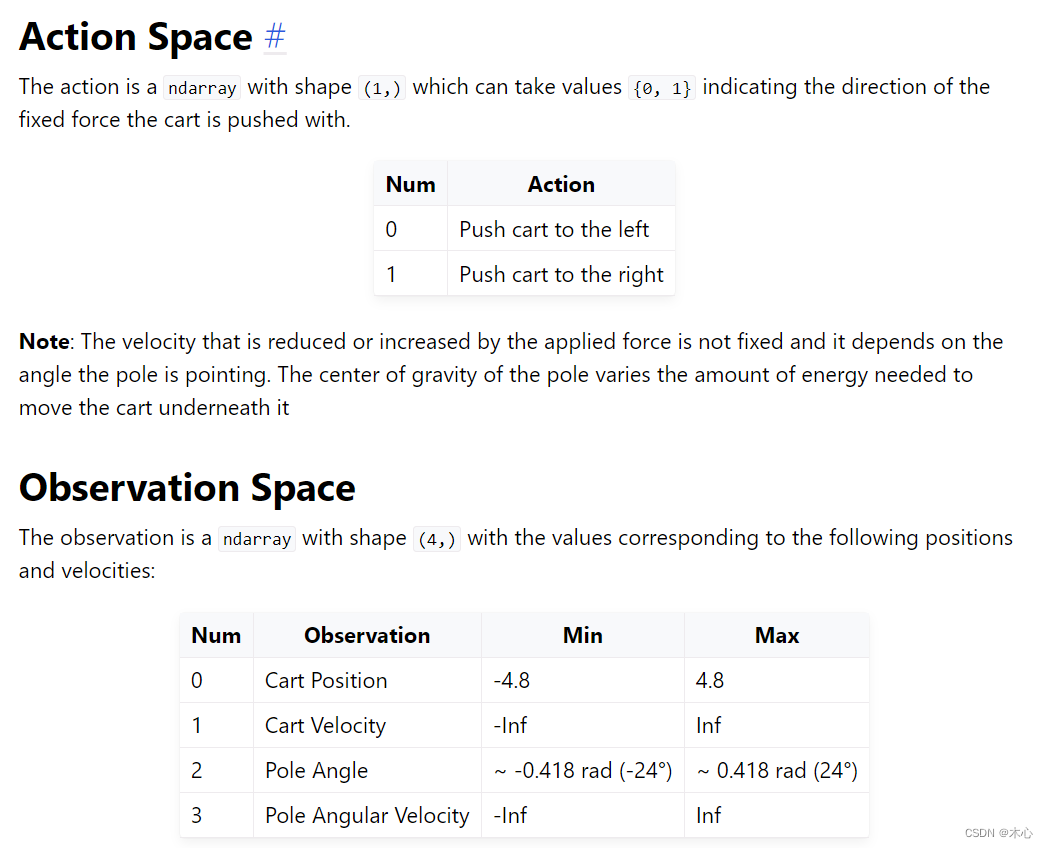
这个环境下,动作空间是离散的二维,状态空间是连续的4维,分别表示小车的位置,小车的速度,杆的角度,杆的角速度。
3. Implement DQN
rl_utils.py中实现了经验回放池。
import random
import numpy as np
import collections
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity) # 使用collection中的队列数据结构作为容器
def add(self, state, action, reward, next_state, done): #add experience
# buffer中的每个experience都是以tuple的形式存在
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size): # sample batch_size item
transition = random.sample(self.buffer, batch_size)
states, actions, rewards, next_states, dones = zip(*transition)
return np.array(states), actions, rewards, np.array(next_states), dones
def size(self): # 获得buffer的维护长度
return len(self.buffer)
RL_brain.py中搭建了值函数,并且实现了DQN算法
from rl_utils import ReplayBuffer
import numpy as np
import torch
import torch.nn.functional as F
class QNet(torch.nn.Module):
# 仅包含一层隐藏层的Q value function
def __init__(self, state_dim, hidden_dim, action_dim):
super(QNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
class DQN():
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate,
gamma, epsilon, target_update, device):
self.action_dim = action_dim
self.q_net = QNet(state_dim, hidden_dim, action_dim).to(device) # behavior net将计算转移到cuda上
self.target_q_net = QNet(state_dim, hidden_dim, action_dim).to(device) # target net
self.optimizer = torch.optim.Adam(self.q_net.parameters(), lr=learning_rate)
self.target_update = target_update # 目标网络更新频率
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-greedy
self.count = 0 # record update times
self.device = device # device
def choose_action(self, state): # epsilon-greedy
# state is a list [x1, x2, x3, x4]
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim) # 产生[0,action_dim)的随机数作为action
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax(dim=1).item()
return action
def learn(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions'], dtype=torch.int64).view(-1,1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1,1).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1,1).to(self.device)
q_values = self.q_net(states).gather(dim=1, index=actions)
max_next_q_values = self.target_q_net(next_states).max(dim=1)[0].view(-1,1)
q_target = rewards + self.gamma * max_next_q_values * (1 - dones) # TD target
dqn_loss = torch.mean(F.mse_loss(q_target, q_values)) # 均方误差损失函数
self.optimizer.zero_grad()
dqn_loss.backward()
self.optimizer.step()
# 一定周期后更新target network参数
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(
self.q_net.state_dict())
self.count += 1
if __name__ == "__main__":
# test
qnet = QNet(4, 10, 2)
print(qnet)
run_dqn.py中实现了主函数即强化学习主循环,设置了超参数,并且绘制return曲线
from rl_utils import ReplayBuffer, moving_average
from RL_brain import DQN, QNet
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
import random
import gym
import torch
# super parameters
lr = 2e-3
num_episodes = 500
hidden_dim = 128 # number of hidden layers
gamma = 0.98 # discounted rate
epsilon = 0.01 # epsilon-greedy
target_update = 10 # per step to update target network
buffer_size = 10000 # maximum size of replay buffer
minimal_size = 500 # minimum size of replay buffer
batch_size = 64
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
render = False # render to screen
env_name = 'CartPole-v1'
if render:
env = gym.make(id=env_name, render_mode='human')
else:
env = gym.make(id=env_name)
# env.seed(0)
random.seed(0)
np.random.seed(0)
torch.manual_seed(0)
replaybuffer = ReplayBuffer(capacity=buffer_size)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon, target_update, device)
return_list = []
for i in range(10):
with tqdm(total = int(num_episodes/10), desc='Iteration %d'%i) as pbar:
for i_episode in range(int(num_episodes/10)):
episode_return = 0
state, _ = env.reset() # initial state
done = False
while not done:
if render:
env.render()
action = agent.choose_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
replaybuffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
if replaybuffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replaybuffer.sample(batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'rewards': b_r,
'next_states': b_ns,
'dones': b_d
}
agent.learn(transition_dict)
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
env.close()
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()
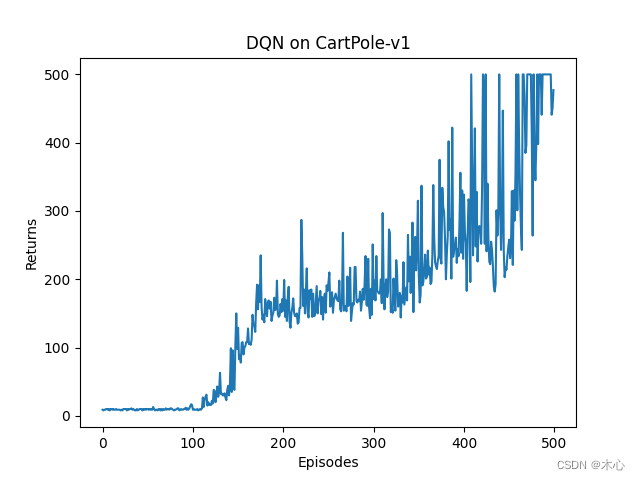
最终学习曲线如图所示
4. Reference
赵世钰老师的课程
莫烦ReinforcementLearning course
Chapter 8. Value Function Approximation
Hands on RL