HPRNet: Hierarchical Point Regression for Whole-Body Human Pose Estimation解析
- 摘要
- 1. 简介
- 2. Related Work
- 2.1 Human Body Pose Estimation
- 2.2 Whole-body Pose Estimation
- 3. Model
- 3.1 全身关键点的层次回归
- 3.2 足部关键点回归
- 3.3 网络架构
- 3.4 目标函数
- PCH and BKH > Focal Loss (热图检测)
- PCC > L1 Loss(误差补偿)
- BKO/HKO/FKO > L1 Loss (关键点回归)
- PB/FB > L1 Loss (Box的长和宽回归)
- 总Loss
- 4. 实验
- 4.1 数据集
- 4.2 实验结果
论文链接:HPRNet: Hierarchical Point Regression for Whole-Body Human Pose Estimation
论文代码:https://github.com/nerminsamet/HPRNet
论文出处:Image and Vision Computing,2021
论文单位:Middle East Technical University, Ankara, Turkey
摘要
- 在本文中,我们提出了一种新的自下而上的单阶段全身姿态估计方法,我们称之为“层次点回归(hierarchical point regression)”,简称HPRNet。
- 在标准身体姿势估计中,估计人体上约17个主要关节的位置。
- 不同的是,在全身姿势估计中,也会估计细粒度关键点的位置(面部68个,每只手21个,每只脚3个),这就产生了一个需要解决的尺度方差问题。
- 为了处理不同身体部位之间的尺度差异,我们建立了身体部位的分层点表示(hierarchical point representation),并对它们进行联合回归。
- 每个部分(例如面部)的细粒度关键点的相对位置参考该部分的中心进行回归,其位置本身相对于人的中心进行估计。
- 此外,与现有的两阶段方法不同,我们的方法在恒定的时间内预测全身姿势,而不依赖于图像中的人数。
- 在COCO WholeBody dataset上,HPRNet在所有全身部位(即身体、脚、脸和手)的关键点检测上显著优于之前所有自下而上的方法。它在面部(75.4 AP)和手部(50.4 AP)关键点检测方面也取得了最先进的结果。
1. 简介
- 人体姿态估计是一项具有挑战性的计算机视觉任务,其目的是在图像和视频中定位人体关键点。
- 人体姿态估计在动作识别、人体网格恢复、增强/虚拟现实、动画和游戏等视觉任务和应用中发挥着重要作用。
- 与标准人体姿态估计任务不同,全身姿态估计的目标是检测除标准人体关键点外的面部、手和脚关键点。
- 这个问题的挑战是全身不同部位之间的极端尺度差异或不平衡。 例如,相对于肘部、膝盖和臀部等标准身体关键点,面部和手部关键点的相对较小的尺度使得面部和手部关键点的精确定位更加困难。由于这种尺度方差问题,直接应用现有的人体姿态估计方法不能得到令人满意的结果。
- 尽管在过去的几十年里,人体姿态估计已经得到了很好的研究,但由于缺乏大规模的完整注释的全身关键点数据集,对全身姿态估计任务的探索还不够充分。
- 之前的几种方法分别在不同的人脸、手和身体数据集上训练多个深度网络,并在推理时将它们集成在一起。 这些方法受到数据集偏差、光照、姿态和尺度变化以及复杂的训练和推理管道等问题的影响。
- 最近,为了解决缺少基准的问题,引入了一种新的全身姿势估计数据集,称为COCO WholeBody。COCO WholeBody扩展了COCO关键点数据集,进一步标注了脸、手和脚关键点。
- 除标准外,还从COCO关键点数据集中提取了17个人体关键点,68个面部标志,42个手部关键点
6个脚部的关键点,如图1。
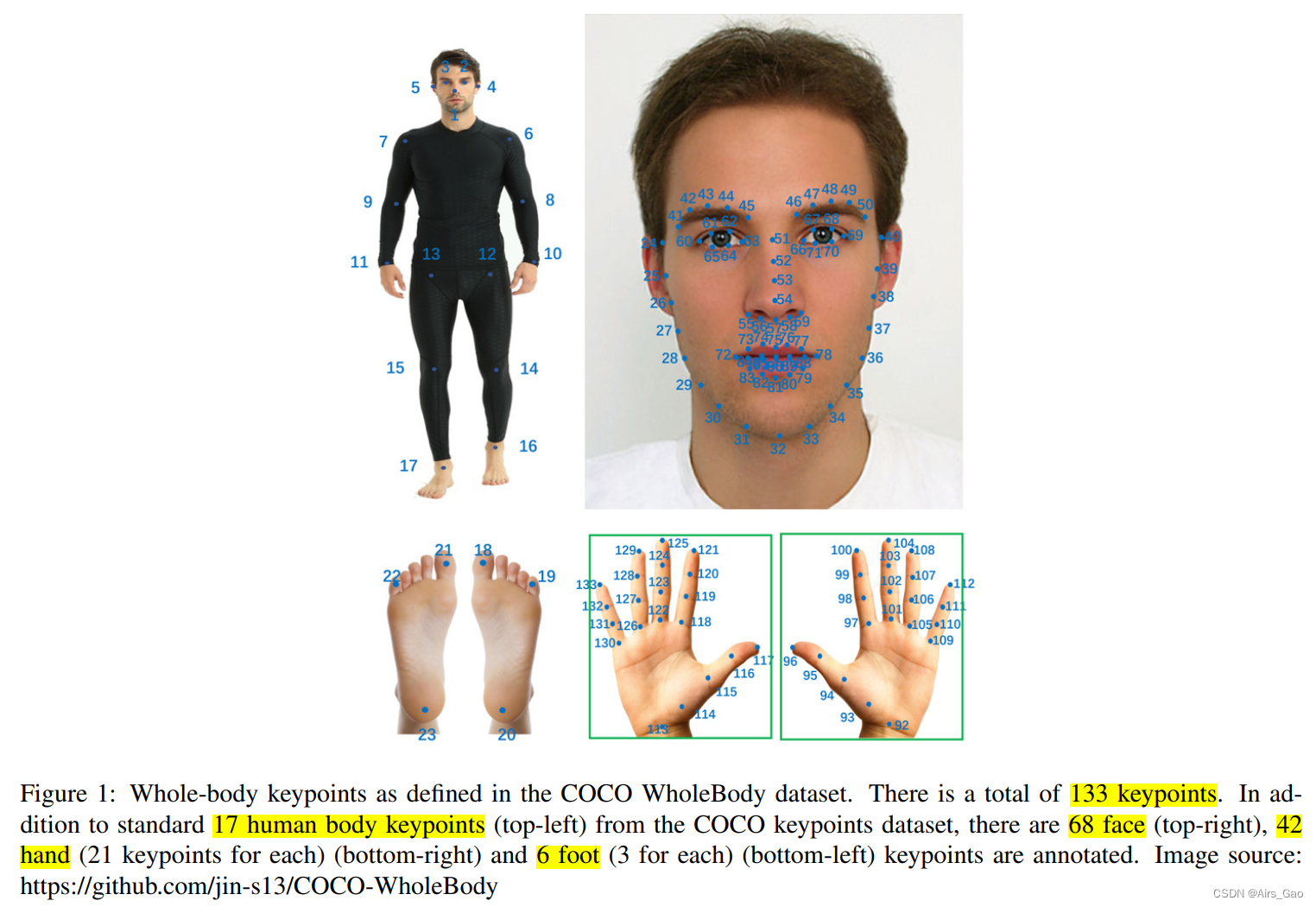
- 除了这些133个全身关键点标注,数据集也有脸部和手部的边界框标注,从对应部位的极端关键点自动计算。
- 他们还提出了一个强有力的基线,叫做ZoomNet,开创了技术的先河。ZoomNet是一种基于人体姿态估计模型HRNet的自顶向下的两阶段方法。
- 给定一张图像,ZoomNet首先使用FasterRCNN人检测器检测人实例,然后使用CNN模型预测17个身体和6个脚关键点。随后,为了克服全身部位之间的尺度差异,ZoomNet将检测到的手和脸区域进行裁剪,并使用seperate CNNs将其转换为更高的分辨率,进一步进行人脸和手部关键点估计。
- 人体姿态估计和全身姿态估计主要有两种方法:自下而上和自上而下。
- 自下而上的方法直接检测人体关键点,然后对它们进行分组,得到给定图像中每个人的最终姿势。
- 自上而下的方法(如ZoomNet)首先检测和提取人物实例,然后分别对每个实例应用姿态估计。
- 分组阶段的自下而上方法比对每个人实例重复姿态估计更有效。
- 因此,自顶向下的方法会随着人数的增加而减慢。
- 然而,与自下而上的方法相比,自上而下的方法获得了更好的精度。
- 在本文中,我们提出了一种新的自下而上的方法,HPRNet,它通过分层回归关键点来显式处理全身姿态估计的层次性。
- 为此,除了估计标准的身体关键点外,我们还定义了相对较小的身体部位(如脸和手)的边界框中心,并与人实例中心偏移(图3)。
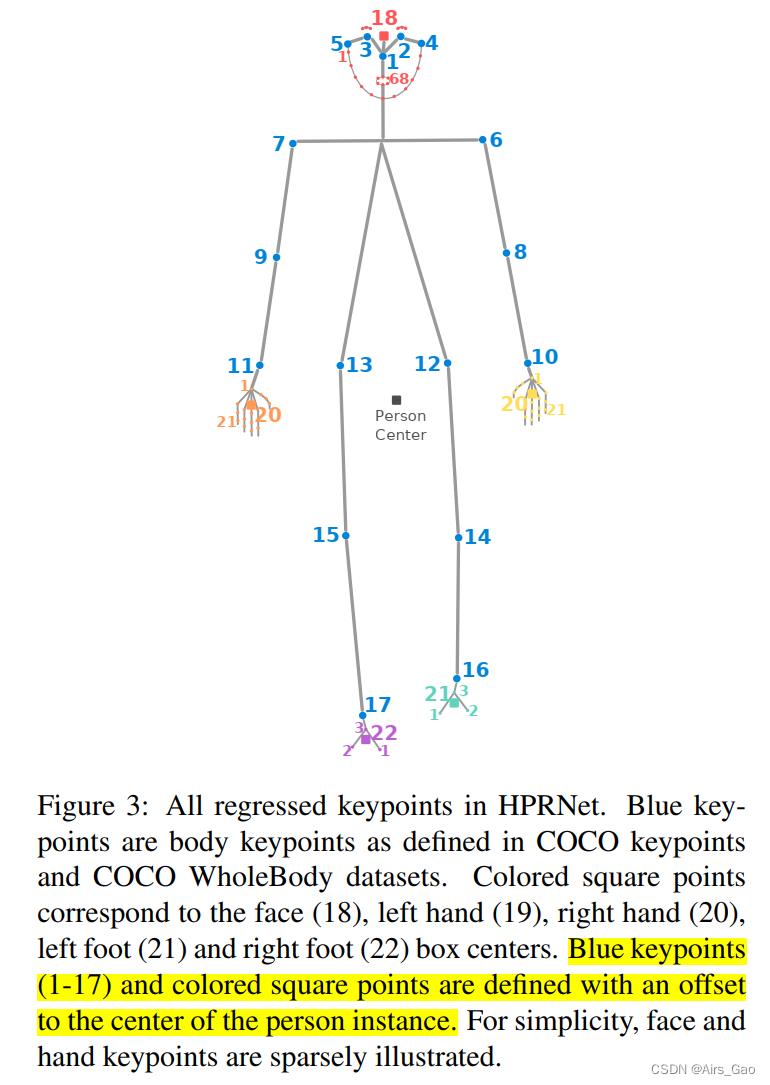
- 同时,我们构建另一个层次的回归,其中我们定义每个手和脸关键点与其对应的手脸边界框中心的偏移量。
- 我们共同训练每个层次的回归层次,并根据它们定义的中心点回归所有的全身关键点。
- 这种分层自下向上的方法有两个好处:
(1)首先,自然处理不同身体部位之间的尺度差异,因为每个部位内的相对距离在一个相似的范围内,每个部位类型由一个单独的子网络处理。
(2)第二,作为自下而上的方法,HPRNet的推理速度受输入图像中人数的影响最小。这与自上而下的方法(如ZoomNet)形成对比,后者在人员实例较多的情况下显著减慢速度(包含1人的图像65.7毫秒,而包含10人的图像668.2毫秒)。 - 我们的方法是基于中心点的自下而上的目标检测方法。 这些方法可以很容易地扩展到关键点估计任务。
- 我们在COCO WholeBody数据集上通过消融实验和与SOTA)比较验证了我们方法的有效性。我们的方法明显优于所有自下而上的方法。它在人脸和手部关键点的检测上也优于SOTA自上而下的方法ZoomNet,同时明显快于ZoomNet。
- 我们在本文中的主要贡献是提出了一种单阶段、自下而上的方法,以缩小自下而上和自上而下方法之间的性能差距。与自上而下的方法相比,我们的方法几乎是恒定时间运行的,独立于输入图像中的人数。
2. Related Work
2.1 Human Body Pose Estimation
- 我们可以将目前的多人姿态估计方法分为两种: 自下而上和自上而下。
- 在自下而上的方法中,给定图像,首先检测body关键点,不知道人物实例的数量或位置,也不知道这些关键点属于哪个人物实例。随后,将检测到的关键点分组并分配给人员实例。
- 最近,基于中心的目标检测方法已经扩展到人体姿态估计。这些方法表示与人框中心的偏移值的关键点,并在训练期间直接回归它们。为了提高关键点的定位,他们还像其他自下而上的方法一样估计每个关键点的热图。在推理中,使用中心偏移量,他们将关键点分组并分配给人物实例。 由于自下而上的方法可以同时检测所有人的关键点,因此速度很快。
- 自上而下的方法首先检测输入图像中的人物实例。通常,他们使用现成的对象检测器(例如FasterRCNN)来获取人bounding box。接下来,自顶向下方法估计每个裁剪的人物框的单个人物姿势。通过裁剪和调整每个人员框的大小,自上而下方法的优点是可以放大每个人员的详细信息。因此,自上而下的方法更能处理规模差异问题。因此,最先进的结果是通过自上而下的方法获得的,自上而下和自下而上的方法之间存在精度差距。
- 然而,由于姿态估计模型是为每个人实例运行的,因此自上而下方法的平均速度往往较慢,即随着图像中人物数量的增加,它们的速度会明显变慢。
- 有人可能会认为,在全身姿势估计数据集(即:COCO WholeBody)可能是一种全身姿势估计的解决方案。然而,正如在COCO WholeBody数据集论文中所述,由于全身部位之间的大尺度差异,应用这些方法直接导致精度不理想。
2.2 Whole-body Pose Estimation
- 全身姿态估计需要准确定位身体、面部、手和脚上的关键点。
- 在面部对齐、面部landmark检测、手部姿态估计、手部跟踪和足部关键点检测等主题下,对每个身体部位的关键点检测都进行了很好的独立研究。
- 然而,由于缺乏大规模的标注数据集,关于全身姿态估计的研究并不多。
- 在COCO WholeBody数据集发布之前,OpenPose尝试检测全身关键点。为此,OpenPose集成了5个单独训练的模型,分别是human body pose estimation, hand detection, face detection, hand pose estimation 和 face pose estimation 。
- 由于这些多模型,OpenPose的训练和推理是复杂和昂贵的。我们的端到端可训练的单一网络消除了这些缺点。
- 建立全身姿势估计基准的第一步是发布COCO WholeBody数据集。
- 他们还提出了一个强大的、两阶段的、自上而下的模型来对COCO WholeBody数据集进行全身姿势估计。首先使用FasterRCNN[45]在图像中获得候选人物框。接下来,使用一个称为ZoomNet的单一网络,对人体框进行全身关键点检测。
- ZoomNet由4个子CNN网络组成:
(1)首先,FeatureNet对输入的人物框进行处理,并在两个尺度上提取共享特征。
(2)接下来,使用来自FeatureNet的功能,BodyNet检测身体和脚的关键点。BodyNet还负责面部和手部边界框角点的预测,粗略提取面部和手部区域。
(3)然后,将裁剪好的脸部和手部边界框输入FaceHead和HandHead网络,检测脸部和手部的关键点。 - 他们使用HRNet-W32网络用于BodyNet, HRNetV2pW18网络用于FaceHead和HandHead网络.
- 尽管自下而上的方法很快,但它们不够健壮,无法处理整个身体部位的尺度差异。
- 我们假设用到精心选择的位置的偏移值来表示每个关键点可以处理尺度方差。在此基础上,我们扩展了基于中心的人体姿态估计方法,通过引入关键点的层次回归进行全身姿态估计。
- 我们还表明,对小尺度全身部位(即脸和手)的关键点进行分层回归比裁剪和放大更有效。
3. Model
- HPRNet是一种学习回归全身关键点的单阶段端到端可训练网络。
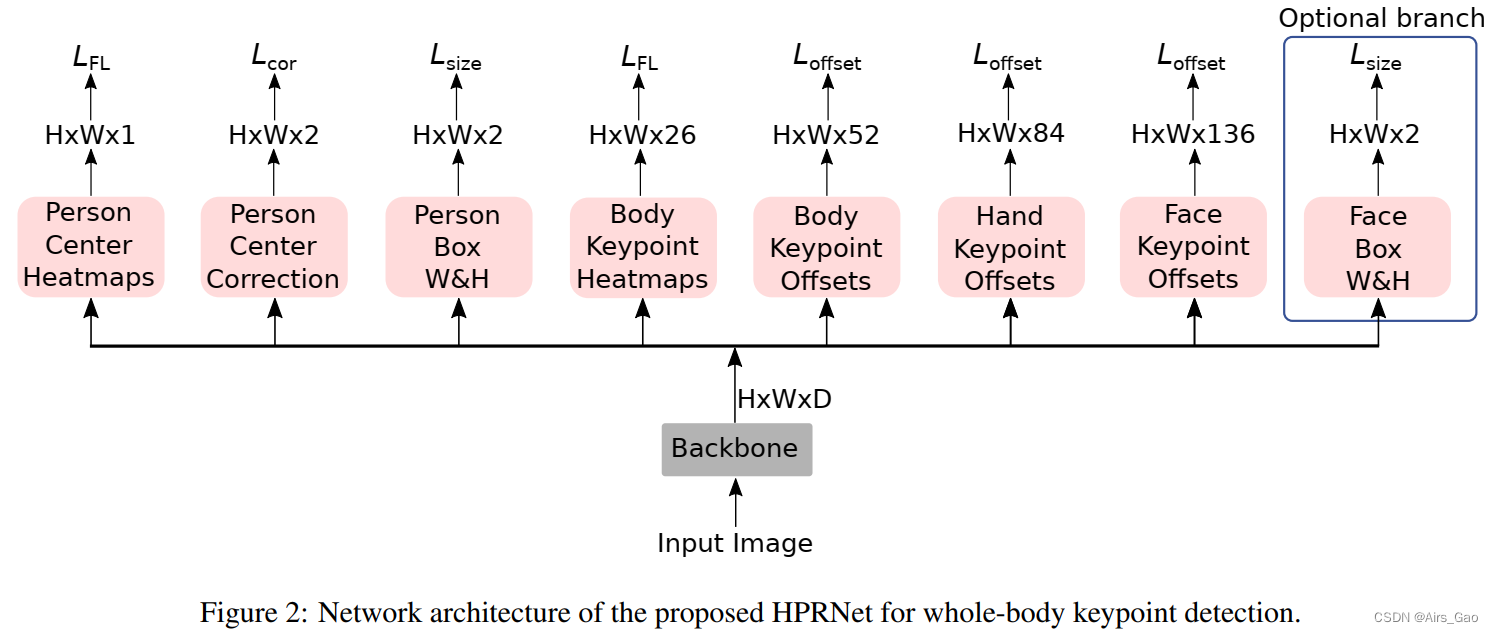
- 在HPRNet中,输入图像首先通过骨干网络,骨干网络的输出被馈送到8个独立的分支,即:Person Center Heatmap, Person Center Correction, Person W & H, Body Keypoint Offsets, Body Keypoint Heatmaps, Hand Keypoint Offsets, Face Keypoint Offsets
,Face Box W & H. - HPRNet的网络构架如图2所示。
3.1 全身关键点的层次回归
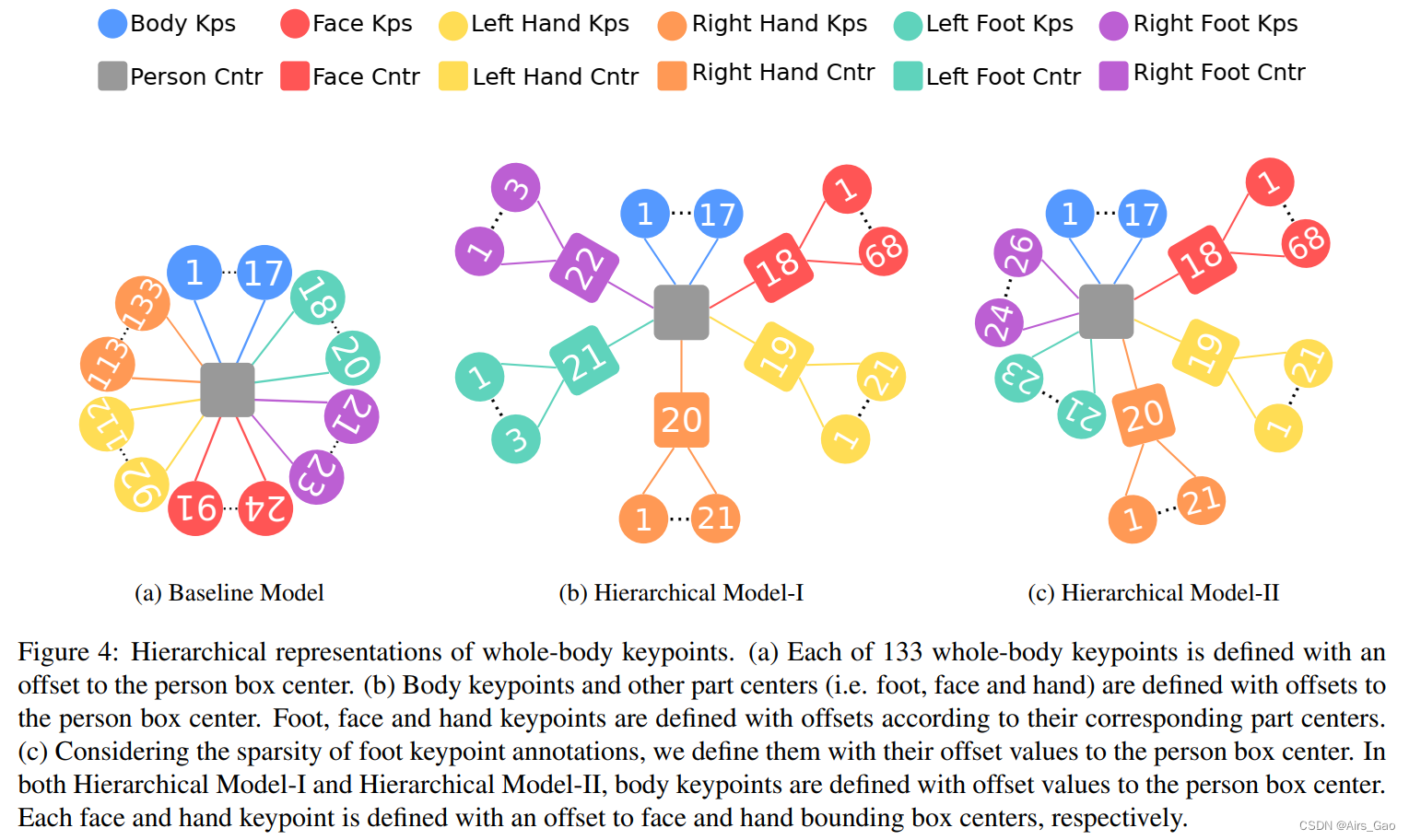
- 在HPRNet中,我们构建了一种分层回归机制,其中我们定义了每个全身关键点与人物框上特定点的相对位置(即偏移量)。
- 我们表示身体上的(标准)17个关键点中的每一个都与人物边界框的中心偏移。
- 不像身体,脸和手和脚都是小部位。在此基础上,我们用相对于人体部位中心的位置定义每个部位,如下所示:
(1)68个面关键点中的每一个都用面边界框中心的偏移量来定义;
(2)21个左手关键点中的每一个都用左手边界框中心的偏移量来定义;
(3)21个右手关键点中的每一个都用与右手边界框中心的偏移量来定义;
(4)3个左脚关键点中的每一个都用左脚边界框中心的偏移量来定义;
(5)3个右脚关键点中的每一个都用右脚边界框中心的偏移量来定义;
人脸、手和脚的边界框自动从groundtruth关键点注释中提取。 - 我们将脸部、左手、右手、左脚和右脚的边界框中心视为身体部分的关键点,并使用与人框中心的偏移值定义每个关键点(图3)。
- 在推理中,在检测到输入图像中的所有关键点后,我们将它们分组并分配给人物实例。为了实现这一点,我们从CenterNet中Person Center Heatmap分支的输出中获得预测的人员中心。
- 接下来,我们获得Body Keypoint Offsets分支输出的预测人中心位置的偏移值。之后,我们将这些偏移量添加到人物中心,以获得
regressed身体关键点位置。 - 同时,我们从Body Keypoint Heatmaps分支的输出热图中提取
detectedbody关键点。 - 最后一步,我们根据L2距离对
detected和regressed关键点进行匹配,只取预测人物边界框内的关键点。 - 接下来,我们对脸和手的关键点(以及脚的关键点,如果我们使用 Hierarchical Model-1)(如图4 b)进行分组。
- 我们从Body Keypoint Heatmaps分支的输出中得到预测的人体部位中心。
- 然后,我们在Hand Keypoint offset和Face Keypoint offset分支输出对应的预测部位中心位置上收集偏移值。
- 最后,我们将这些偏移量添加到部位中心,以获得脸和手的关键点。
3.2 足部关键点回归
- 理想情况下,COCO WholeBody数据集中每个标记的脚部分应该有3个关键点注释。然而,超过20%的注释脚缺少注释 (例如,它们有一个或两个关键点注释,而不是三个)。
- 这些缺失的注释对HPRNet提出了挑战,因为我们自动从标注的极值点提取足中心。
- 在缺少足部关键点的情况下,得到的足部中心点不可靠。
- 为了处理这个问题,我们将脚关键点视为身体关键点,如图4c所示,并通过它们与人物边界框中心的偏移量来表示它们。
3.3 网络架构
- 给定大小为4H × 4W × 3的输入图像,骨干网络输出大小为H × W × D的特征图。
- 主干的输出被馈送到以下后续分支。
- 每个分支有一个带有1 × 1滤波器的卷积层,之后是一个ReLU层和另一个带有1 × 1滤波器的卷积层。
- (1)Person Center Heatmap 分支输出H × W大小的张量,用于人中心点预测。
- (2)Person Center Correction分支为中心位置在空间轴上的局部偏移预测H × W × 2大小的张量。这些偏移量有助于恢复由于网络下采样操作而丢失的中心点精度。
- (3)Person Box W & H分支为每个Person实例中心输出H × W × 2大小的宽度和高度张量。
- (4)Body Keypoint Offsets 分支预测26个关键点(17个身体关键点+ 6个脚关键点+脸框中心+左手框中心+右手框中心)到person Box中心横跨x和y轴的偏移量。
- (5)Body Keypoint Heatmaps 分支为26个关键点输出H × W × 26大小的热图张量。
- (6)Hand Keypoint offset 分支输出H × W × 84大小的张量,其偏移值在21个左手关键点和左手框中心之间; 以及21个右手关键点与右手框在空间轴上的中心之间的偏移值。
- (7)Face Keypoint Offsets 分支输出H × W × 136大小的张量,其偏移值在68个面部关键点和面框中心之间跨越空间轴。
- (8)Face Box W & H 分支为每个面输出宽度和高度为 H × W × 2 大小的张量。这是一个可选的分支。
3.4 目标函数
PCH and BKH > Focal Loss (热图检测)
- 为优化 Person Center Heatmap(PCH)和 Body Keypoint Heatmap(BKH)分支,我们使用先前工作中改进的 focal loss。focal loss (FL)如式1所示。
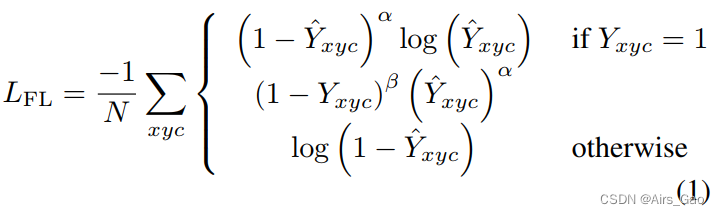
- I∈R4W×4H×3是我们的输入图像。
- 在HPRNet中,由于降采样操作,每个分支的空间输出大小减小了4倍,从而得到 W ×H。
- 因此,Y∈[0,1]W×H×C是人中心和关键点的ground truth热图。
- C 对应类别数量和关键点类型。例如,在Person Center Heatmap分支,我们只有人类,因此C = 1。
- Y^ ∈[0,1]W×H×C是分支输出的预测热图,其中 Y^x,y,c = 1 表示人中心或关键点出现在位置(x,y)为c类。
- 在以下所有方程中,N 为图像 I 中ground truth人中心或关键点的总数。
- α和β为 focal loss 参数,设为α = 2, β = 4(参照CenterNet)。
PCC > L1 Loss(误差补偿)
- 为了补偿由于网络下采样操作导致的人中心点的离散化误差,我们根据类似于自下而上的目标检测器的 L1 loss 来优化 Person Center Correction。
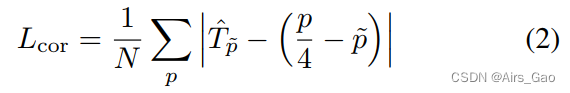
- T^ ∈ RW×H×2是网络预测的局部偏移量,用于恢复人中心点的丢失精度。
- p ∈ R2是 ground truth 的关键点;p~ = [p/4] 为低分辨率下对应的 ground truth 关键点位置。
BKO/HKO/FKO > L1 Loss (关键点回归)
- 我们优化Body Keypoint Offset,Hand Keypoint Offset和Face Keypoint Offset偏移分支使用 L1 loss。
- 关键点回归的一般公式如式3所示。
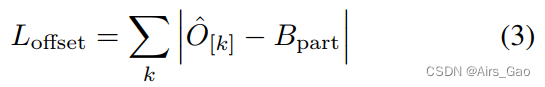
- 式中,O^ ∈ RH×W×k×2为特定全身部位(即身体、面部、手) 关键点 k 的回归输出。
- Bpart 是该部分边界框的真实中心。
PB/FB > L1 Loss (Box的长和宽回归)
- 最后,对于Person Box H & W和Face Box H & W分支,我们使用 L1 loss 并将其缩放0.1(参照CenterNet)。
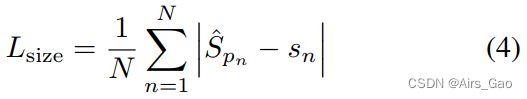
- Sn = (w,h)是每个对象(或面部) n 的宽度和高度值,S^ ∈ RW×H×2是预测的宽度和高度值。
总Loss
- 我们将所有分支机构的损失加起来,得出总体损失如下:

4. 实验
4.1 数据集
COCO WholeBody dataset
4.2 实验结果









![智慧水利整体解决方案[43页PPT]](https://img-blog.csdnimg.cn/img_convert/fac9d85bb599af888c0454fe96fa7ff1.jpeg)