1.字符串是怎么实现不可变的,不可变类,字符串不可变的好处
(1)保存字符串的数组被 final 修饰且为私有的,并且String 类没有提供/暴露修改这个字符串的方法。
(2)String 类被 final 修饰导致其不能被继承,进而避免了子类破坏 String 不可变。
(3)不可变类是指这个类的实例一旦创建完成后,就不能改变其成员变量值
String类的设计符合上面总结的不变类型的设计原则。虽然String对象将value设置为final,并且还通过各种机制保证其成员变量不可改变。但是还是可以通过反射机制改变其值。
不可变类提供了线程安全的特性,但同时也带来了对象创建的开销,每更改一个属性都是重新创建一个新的对象。JDK内部也提供了很多不可变类如Integer、Double、String等。String的不可变特性主要为了满足常量池、线程安全、类加载的需求。合理使用不可变类可以带来极大的好处
(4)字符串不可变的好处
1.多线程安全修改安全
2.便于实现字符串常量池
2.如何实现String的equal方法:
1、首先是和自己比;
2、被比较的对象是否是String类型的;
3、再看它的长度是否相等;
4、比较它里面的每一个字符串;
扩展:
String里边的equals方法是比较两个字符串对象的内容是否是相等的;
Object里边的equals方法是比较两个对象的内存地址是否是一致的,如果一致,即意味着这两个对象在内存中其实是一个对象,则返回true,否则返回false;
注意,当我们写代码的时候,每当要重写Object的该equals方法时,通常都需要重写hashCode方法(也是Object类中的),以保证相等的对象必须具有相等的哈希码。
3.hash冲突的解决方法:
1.拉链法(hashMap)
2.线性探测
4.向线程池提交任务的过程,核心线程与非核心线程的区别,为什么不建议Exectors创建线程池
创建线程池的方法常用的有两中,一种是new ThreadPoolExecutor配置7种参数,一种是Executors类,四种封装好的线程池类型(定长,单线程,可缓存支持灵活回收的线程池,支持周期执行任务的线程池)
Exector弊端
1.定长,单线程的允许的请求队列Integer.MAX_VALUE,可以堆积大量请求,从而导致OOM
2.可缓存,支持周期的允许的创建的线程Integer.MAX_VALUE.,会堆积大量线程,从而导致OOM
如果当前运行的线程数小于核心线程数,那么就会新建一个线程来执行任务。如果当前运行的线程数等于或大于核心线程数,但是小于最大线程数,那么就把该任务放入到任务队列里等待执行。如果向任务队列投放任务失败(任务队列已经满了),但是当前运行的线程数是小于最大线程数的,就新建一个线程来执行任务。如果当前运行的线程数已经等同于最大线程数了,新建线程将会使当前运行的线程超出最大线程数,那么当前任务会被拒绝,饱和策略会调用RejectedExecutionHandler.rejectedExecution()方法。
非核心线程与核心线程:
核心线程只是一个叫法, 核心线程与非核心线程的区别是:
创建核心线程时会携带一个任务, 而非核心线程没有
如果核心线程执行完第一个任务, 线程池内线程无区别
线程池是期望达到 corePoolSize 的并发状态, 不关心最先添加到线程池的核心线程是否会被销毁
5.在线程池添加任务,如何避免被多个线程调用
6.线程数如何设值,超线程,虚拟线程,虚拟线程如何保证不进行上下文切换
7.fokjoinpool
8.线程上下文切换,用户态与核心态
用户态,在应用程序中运行,代码没有对硬件的直接控制权限,不能使用硬件资源,
内存态,可以直接操作硬件资源,例如代码没有对硬件的直接控制权限
9.分布式锁解决什么问题,几种实现方式,mysql如何实现分布式锁
多进程并发问题解决:多个进程之间所有线程可见的区域实现这个互斥量
- ①基于DB实现
- ②基于Redis实现(连锁,redission(可重入,重试,超时释放))
- ③基于Zookeeper实现
基于数据库:
在数据库中创建一张lock表,表中设置方法名、线程ID等字段。并为方法名字段建立唯一索引,当线程执行某个方法需要获取锁时,就以这个方法名作为数据向表中插入,如果插入成功代表获取锁成功,如果插入失败,代表有其他线程已经在此之前持有锁了,当前线程可以阻塞等待或直接返回。同时,也可以基于表中的线程ID字段为锁重入提供支持。当然,当持有锁的线程业务逻辑执行完成后,应当删除对应的数据行,以此达到释放锁的目的。(删 失败问题:加过期时间+守护线程续命)
因为是基于数据库实现的,所以获取锁、释放锁等操作都要涉及到数据落盘、删盘等磁盘IO操作,性能方面值得考虑。同时也对于超时失效机制很难提供支持,在实现过程中也会出现很多其他问题,为了确保解决各类问题,实现的方式也会越发复杂。
Redission:
可重入:利用hash结构记录线程id和可重入次数
可重试:利用信号量,发布订阅
超时续约:利用watchdog,每隔一段时间,重制超时时间(释放锁的过程,同时关闭watchdog)
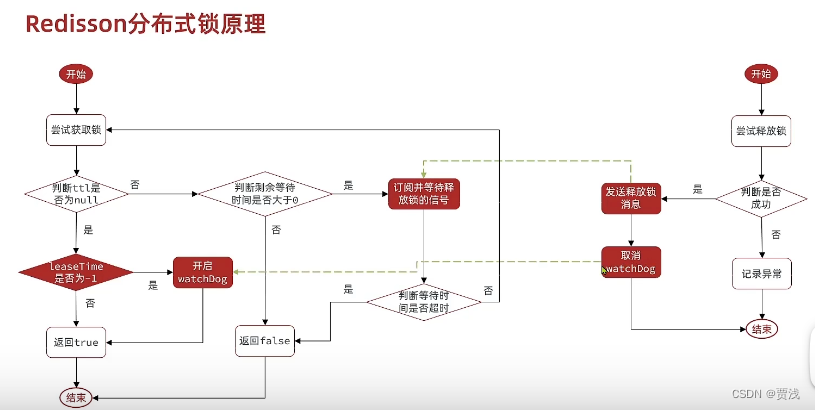
Redis数据不是实时同步的,主机写入成功后会立即返回,存在主从架构锁失效问题。
Zookeeper数据是实时同步的,主机写入后需一半节点以上写入成功才会返回。
所以如果你的项目追求高性能,可以放弃一定的稳定性,那么推荐使用Redis实现。比如电商、线上教育等类型的项目。
但如果你的项目追求高稳定,愿意牺牲一部分性能换取稳定性,那么推荐使用Zookeeper实现。比如金融、银行、政府等类型的项目。
10.行锁锁的是什么
11.回表,减少回表的优化
索引下推:
没有:索引的过滤条件在mysql serve层执行。
有之后:下推到存储引擎,基于索引进行过滤筛选 减少回表策略
12.一个sql语句如何判断走没走覆盖索引
13.Ping的原理
14.40亿qq号10位只有1G内存(bitmap)
15springboot自动装配
16.spring事务失效
17.CAS的底层怎么实现
为什么在硬件上原子性
CAS缺陷
cas如何对多个对象使用
cas是在硬件层面实现的一个比较并交换的动作,在Java中是通过umsafe类对象实现的,提供了几个cas操作的api。cas本质上就是cpu的一个原子指令,在inter x86中的指令为compxchg,在执行该指令时,会对cpu总线加锁,保证在访问该共享资源时 得排队等待。所以实现了原子性也就是不可分割的特性,底层也是加锁的形式,不过是从操作系统的层面说的。
18.1.7与1.8hashmap区别
19.死链底层
20.父类加载器和子类加载器在代码上是什么关系
组合关系来复用父加载器的代码
21.如何破坏双亲
自定义加载器的话,需要继承 ClassLoader 。如果我们不想打破双亲委派模型,就重写 ClassLoader 类中的 findClass() 方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。但是,如果想打破双亲委派模型则需要重写 loadClass() 方法。
Java提供了很多核心接口的定义,这些接口被称为SPI接口,同时为了方便加载第三方的实现类,SPI提供了一种动态的服务发现机制(约定),只要第三方在编写实现类时,在工程内新建一个META-INF/services/目录并在该目录下创建一个与服务接口名称同名的文件,那么在程序启动的时候,就会根据约定去找到所有符合规范的实现类,然后交给线程上下文类加载器进行加载处理。
22.B树和B+树区别
从MYSQL:
1.单点查询:
B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。
2.插入与删除效率
B+ 树的插入和删除效率更高。
3.范围查询
B+ 树所有叶子节点间还有一个链表进行连接,这种设计对范围查找非常有帮助