文章目录
- 前言
- 1. 剑指 Offer : 复杂链表(带随机指针)的复制
- 1.1 思路分析(利用map搞)
- 1.2 AC代码
- 2. 前K个高频单词
- 2.1 思路1+AC代码
- 2.2 思路2+AC代码
- 2.3 思路3+AC代码
- 3. 两个数组的交集
- 3.1 思路分析
- 3.2 AC代码
前言
上一篇文章我们学习了map和set的使用,那学习了map和set之后,有些题目用它们做起来还是很爽的。
1. 剑指 Offer : 复杂链表(带随机指针)的复制
题目链接: link

如果大家看过我之前初阶数据结构的博客的话会发现这道题我们其实是讲过的,不过当时我们使用C语言搞的,说实话C语言实现起来还是挺麻烦的。
大家可以看一下之前这篇文章:
链接: 【初阶数据结构】——剑指 Offer : 复杂链表(带随机指针)的复制
1.1 思路分析(利用map搞)
我们再来一起回顾下之前C语言的做法
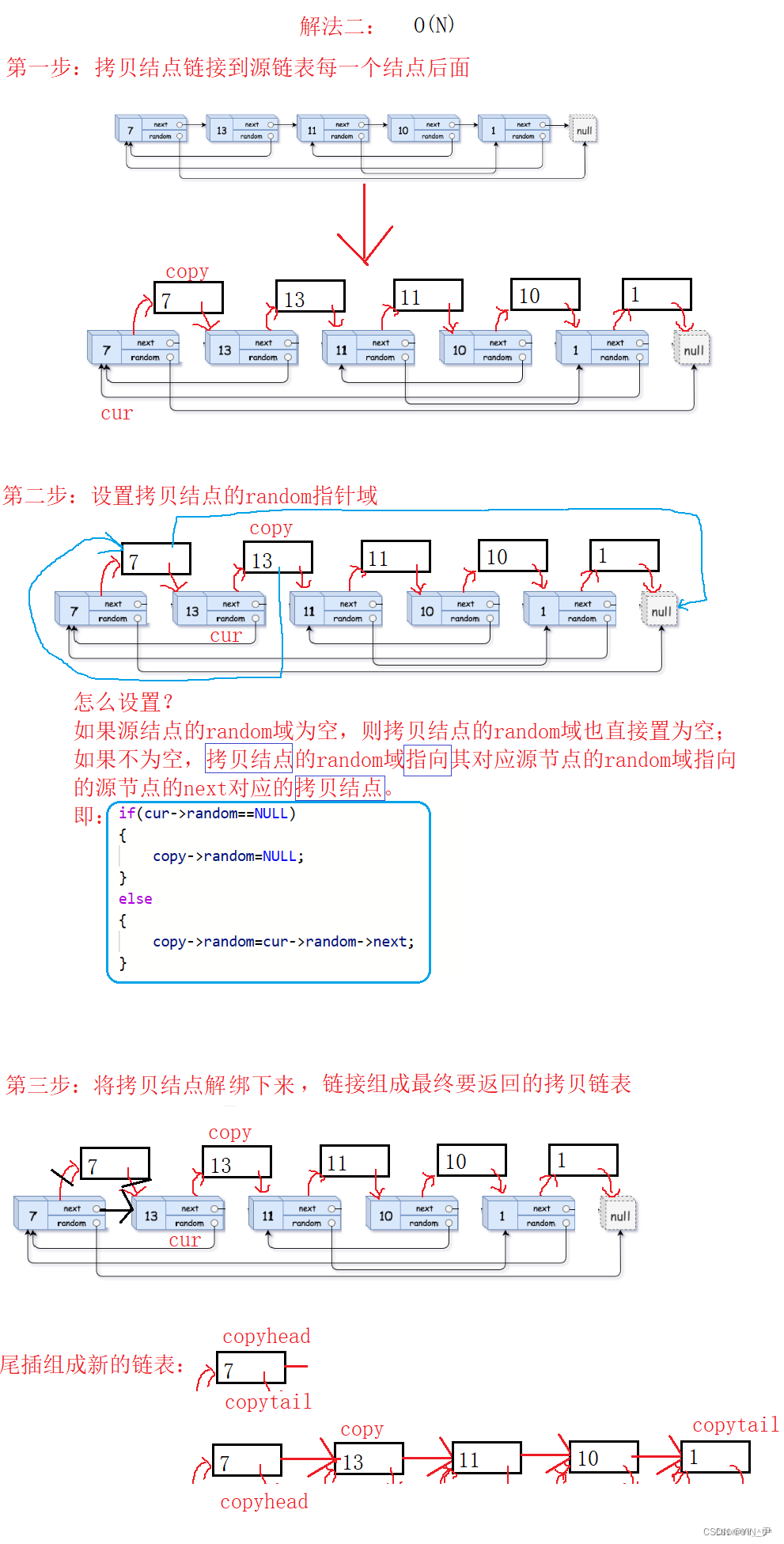
大家思考我们为什么要拷贝原链表的结点一个个链接到原链表结点的后面?
其实就建立了原链表结点与拷贝链表每个结点的一种映射关系,方便我们设置拷贝结点的random域。
那我们现在C++有了map,搞这个是不是很简单啊:
怎么做呢?
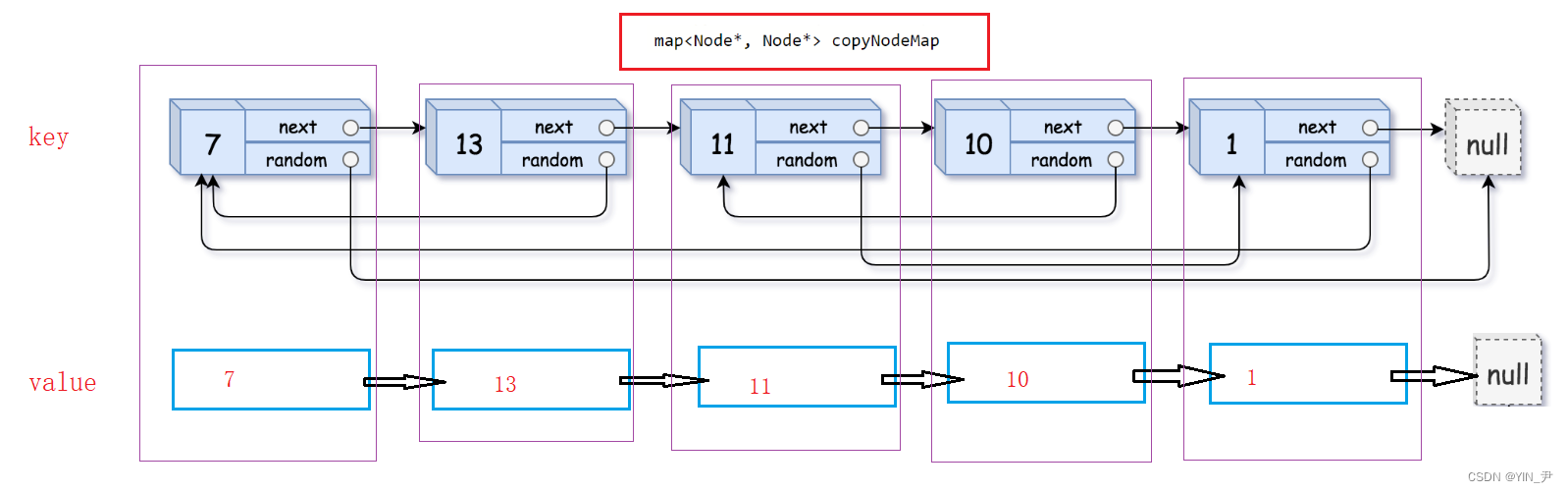
首先我们定义一个map,然后遍历原链表,依次拷贝结点,在map中建立源节点与拷贝结点的映射,并链接拷贝链表
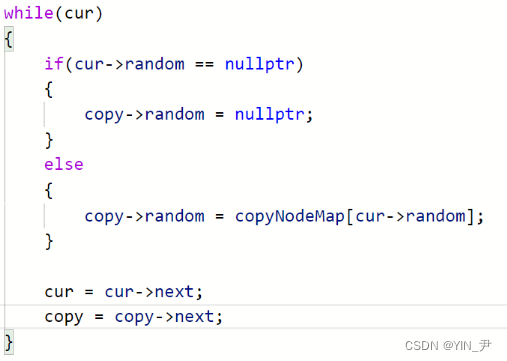
然后,再遍历原链表设置拷贝结点的random域:
如果源节点的random指向空,那么拷贝结点random也指向空;如果源节点不指向空,那拷贝结点就指向map中对应源节点的random指向的结点对应的拷贝结点
1.2 AC代码
来写一下代码

class Solution {
public:
Node* copyRandomList(Node* head) {
map<Node*,Node*> m;
Node* cur=head;
Node* copyhead=nullptr, *copytail=nullptr;
while(cur)
{
Node* copyNode=new Node(cur->val);
m[cur]=copyNode;
if(copytail==nullptr)
{
copyhead=copytail=copyNode;
}
else
{
copytail->next=copyNode;
copytail=copytail->next;
}
cur=cur->next;
}
cur=head;
while(cur)
{
if(cur->random==nullptr)
{
m[cur]->random=nullptr;
}
else
{
m[cur]->random=m[cur->random];
}
cur=cur->next;
}
return copyhead;
}
};
2. 前K个高频单词
题目链接: link

给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
大家思考一下这道题怎么做?
2.1 思路1+AC代码
我们来分析一下:
那首先我们是不是应该对列表里面每个单词出现的次数做一个统计啊,然后要返回前k个出现次数最多的单词,那这是不是就是一个TOP-K问题啊。
那这道题其实比较需要注意的地方是如果有不同的单词出现相同的次数, 这些相同次数的单词要按字典顺序 排序。
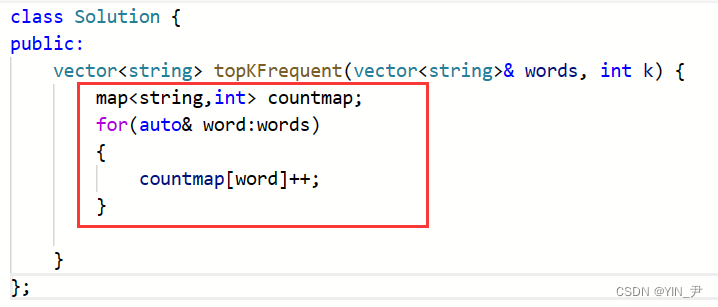
那第一步我们可以先统计一下单词出现的次数
那现在统计次数对我们来说是不是很简单啊,直接用map就行了嘛,这不跟我们演示的那个统计水果出现次数的一样嘛。
那然后我们是不是要取到出现次数最多的前k个单词啊
那提到TOP-K的话,大家可能最先想到的就是用优先级队列去搞,这当然是一种方法,但是这里我们不打算讲这中解法。
那大家想一想还有没有其它方法?
🆗,我们是不是可以按照次数对所有单词进行一个排序啊,排个降序,然后前K个单词不就是要返回的结果嘛。
诶!那我们的map不是会“自动排序”(当然本质是因为中序遍历使得有序)嘛,是的,但是它是按照key的大小进行排(插入的时候比较的是key的大小)的,而我们统计出来的次数是不是放到value里面了。
但是我们想要的排序是按照次数排的,所以不行。
那要排序的话:
库里面不是有一个排序算法sort可以排嘛。
但是,我们的map不能用sort。
因为sort要求传入的迭代器必须是随机迭代器
而我们map的迭代器是双向迭代器
所以不行。


那怎么办呢?
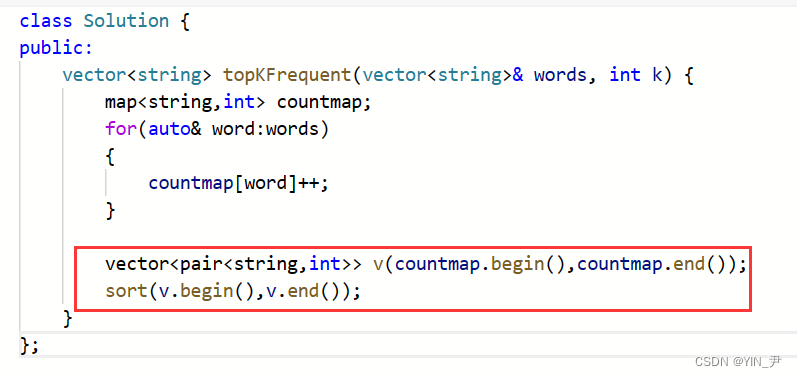
🆗,我们可以把map里面的元素拷贝到vector里面再用sort排序。
但是呢,现在我们的vector里面存的是pair。
pair呢虽然也支持比较大小
它重载了这些比较运算符,但是大家看它的比较规则是我们想要的吗?
比如小于
它比较的时候是先看两个的first满不满足小于,不满足再去看second是否满足小于。
但是我们要按照次数比,即second比,另外sort默认还是升序,我们这里取TOP-K的话搞成降序比较好。
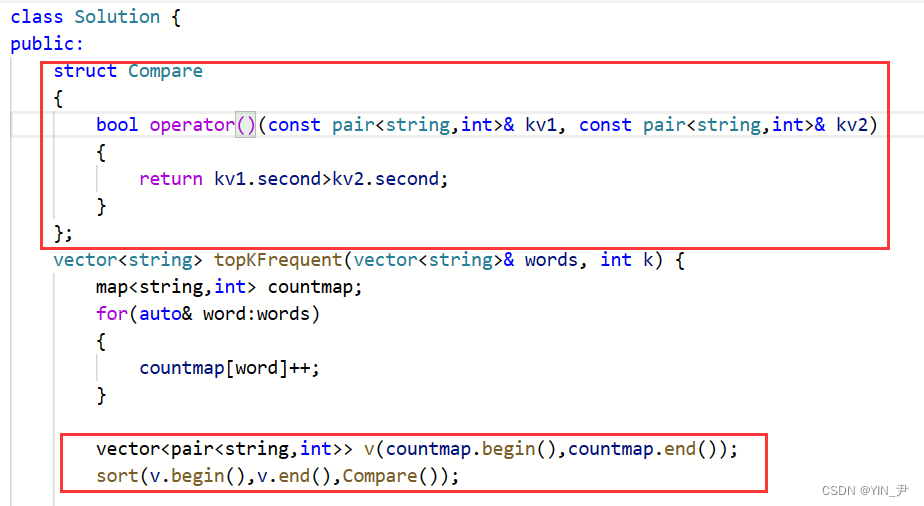
那既然不行,我们就可以自己写一个比较的仿函数(也可以写成函数传函数指针),因为sort是可以由我们自己指定比较方式的
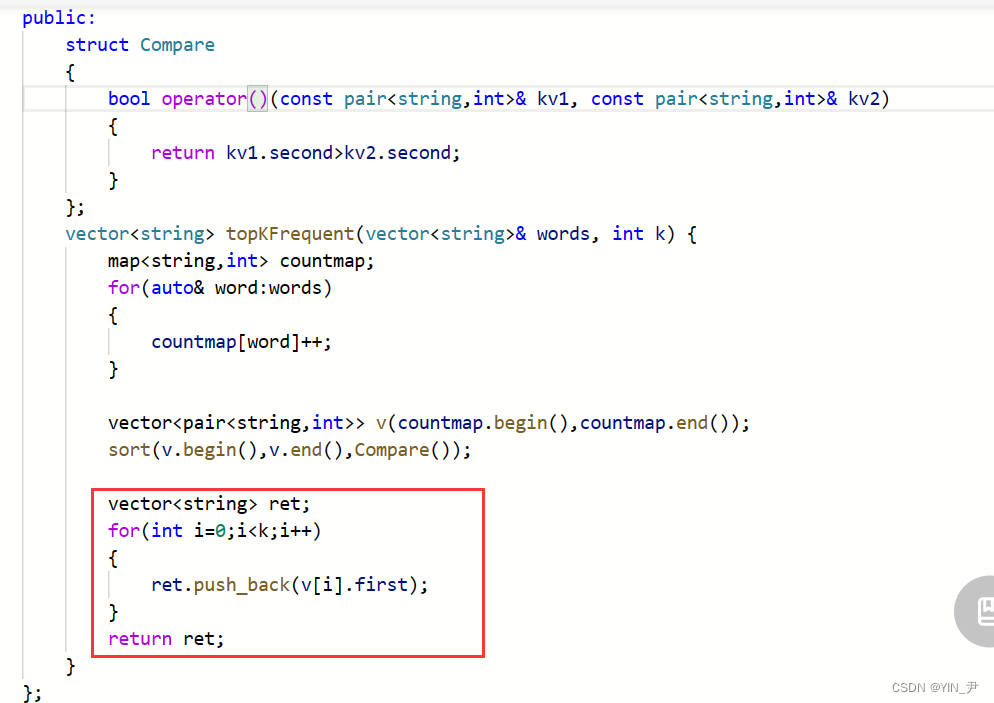
那排好序的话我们取到前k个不就好了嘛(注意最终返回只要单词)
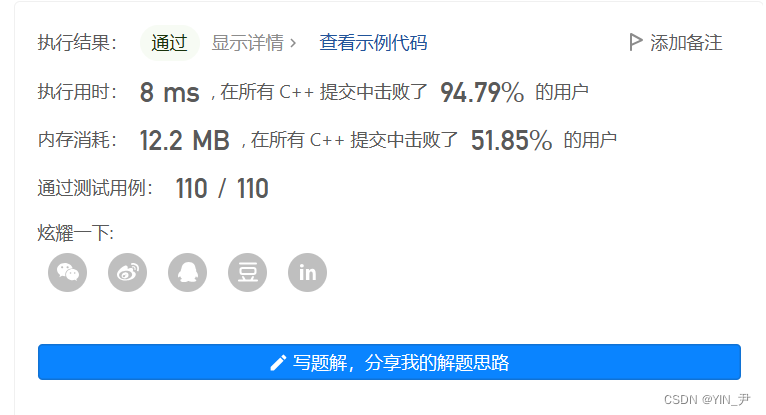
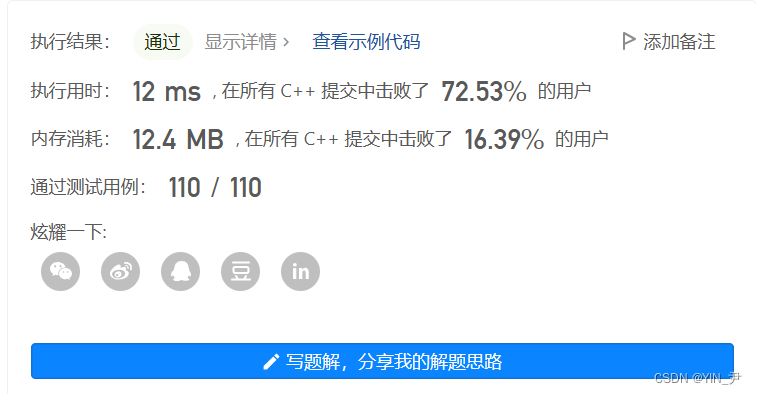
我们提交一下
🆗,只通过了一部分的测试用例


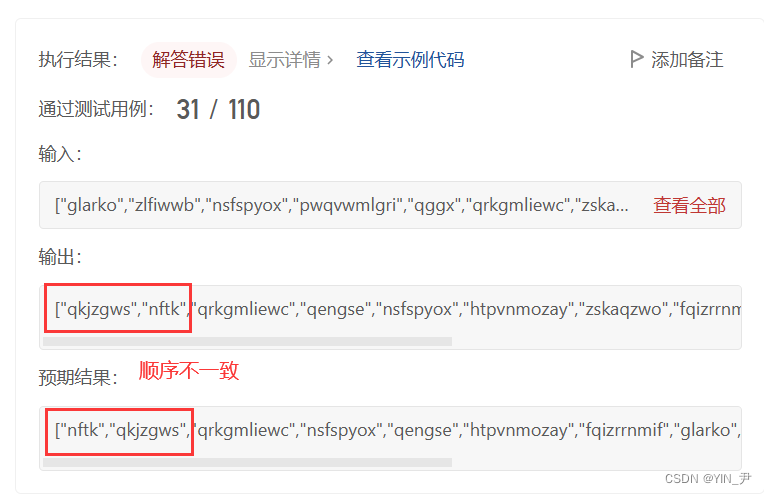
怎么回事呢?
大家还记不记得上面我们说了这道题特别要注意的就是题目要求如果有不同的单词出现相同的次数, 这些相同次数的单词要按字典顺序 排序。
我们放到map里面统计好次数,这时候虽然不是按次数进行排序,是按照key即first排序的嘛。
但是first不就是单词嘛,所以我们放到map里面之后单词的前后顺序其实就是按照字典顺序排好了。
我们后面的排序只需要按照次数再排一下就好了。
但是:
这是不是涉及到排序算是否稳定啊。
因为有可能有次数相同的单词,本来没按次数排之前它们的前后顺序是正确的(是按字典顺序的),但是如果按次数排序的时候,排序算法不稳定,是不是会导致这些次数相同的单词的前后顺序发生改变啊。
那这样得到的结果就不对了。
而我们刚才用的啥?
sort,底层是快排,不稳定,所以有些测试用例才没通过。
那我们怎么办?
🆗,那其实除了sort,算法库里面还提供了一个稳定的算法——stable_sort
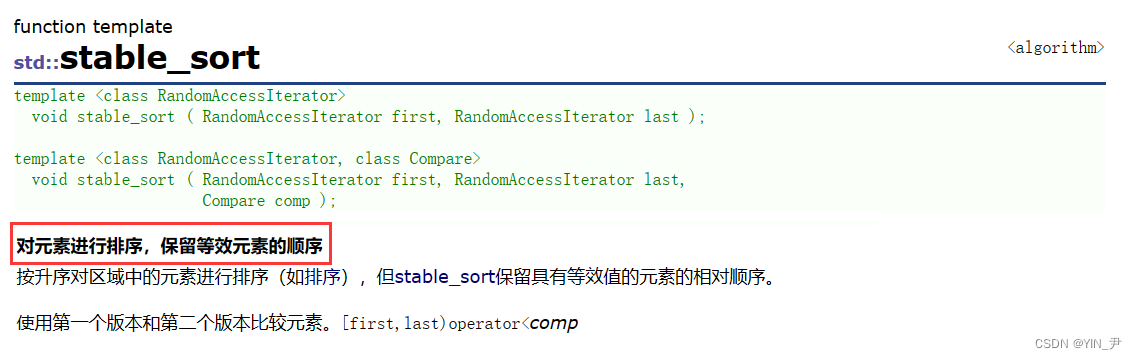
所以:
把sort换成stable_sort就行了
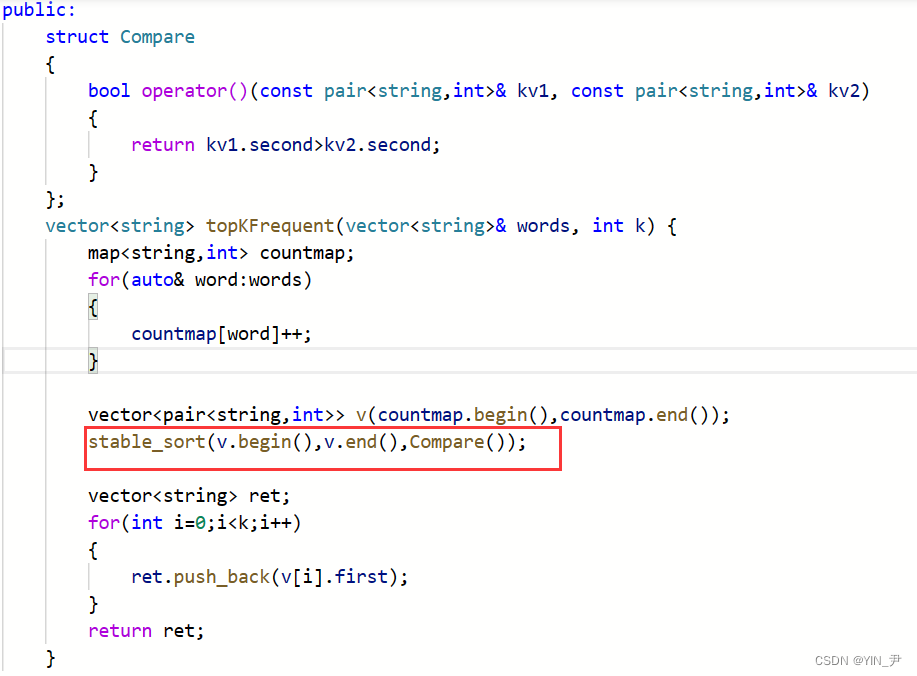
class Solution {
public:
struct Compare
{
bool operator()(const pair<string,int>& kv1, const pair<string,int>& kv2)
{
return kv1.second>kv2.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> countmap;
for(auto& word:words)
{
countmap[word]++;
}
vector<pair<string,int>> v(countmap.begin(),countmap.end());
stable_sort(v.begin(),v.end(),Compare());
vector<string> ret;
for(int i=0;i<k;i++)
{
ret.push_back(v[i].first);
}
return ret;
}
};
2.2 思路2+AC代码
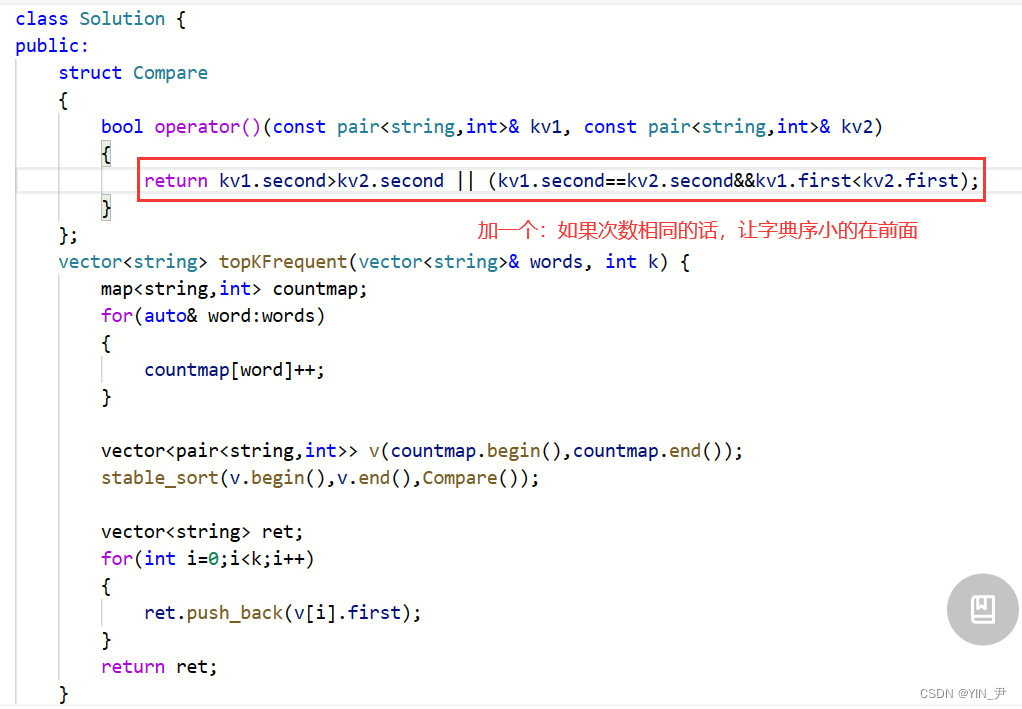
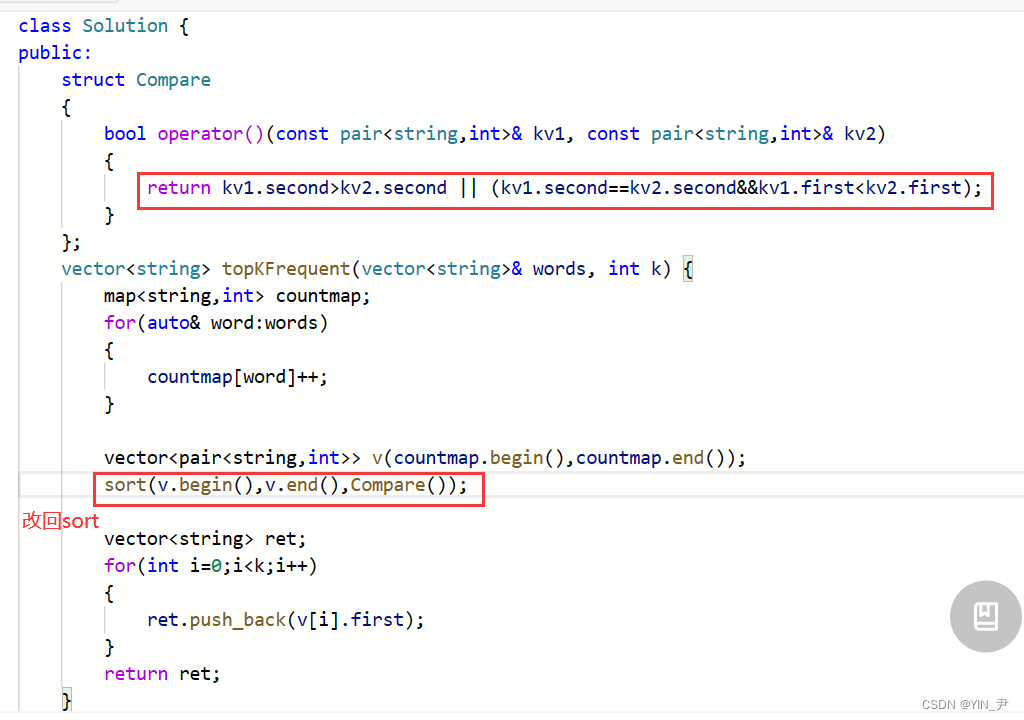
当然了,我们也不是必须用stable_sort才行。
既然sort不稳定,那我们可以让它变稳定:
在我们写的那个控制比较方式的仿函数里面加一个限制条件就行了
class Solution {
public:
struct Compare
{
bool operator()(const pair<string,int>& kv1, const pair<string,int>& kv2)
{
return kv1.second>kv2.second || (kv1.second==kv2.second&&kv1.first<kv2.first);
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> countmap;
for(auto& word:words)
{
countmap[word]++;
}
vector<pair<string,int>> v(countmap.begin(),countmap.end());
sort(v.begin(),v.end(),Compare());
vector<string> ret;
for(int i=0;i<k;i++)
{
ret.push_back(v[i].first);
}
return ret;
}
};
2.3 思路3+AC代码
那其实不用sort,我们也有办法搞:
我们可以用利用set排序。
怎么做呢?
前面我们统计好次数不是放到一个map里面了,那我们可以把它再放到一个set里面,那肯定要把整个pair放进去。
但是这样的话,sort默认的排序肯定是不行的,默认是升序,我们这里搞成降序的话比较好拿到前K个次数最多的单词。
另外,我们排序的时候要按次数比较,但是次数相同的时候要保证字典顺序小的在前面。
所以我们还是要自己写一个仿函数:
当然这个用我们上面写的那个就可以,因为也是存的pair,比较规则一样。
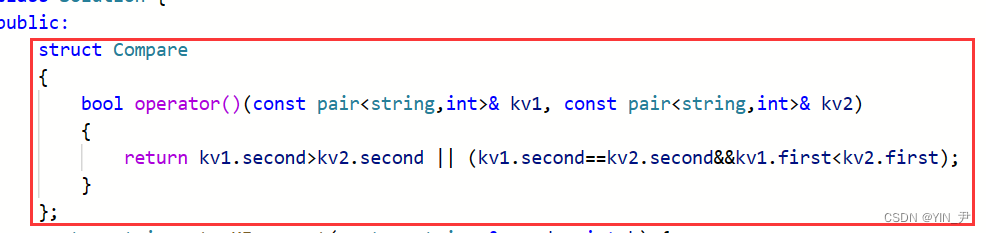
那然后我们把map里面的内容放到set里面,把前K个获取到就行了
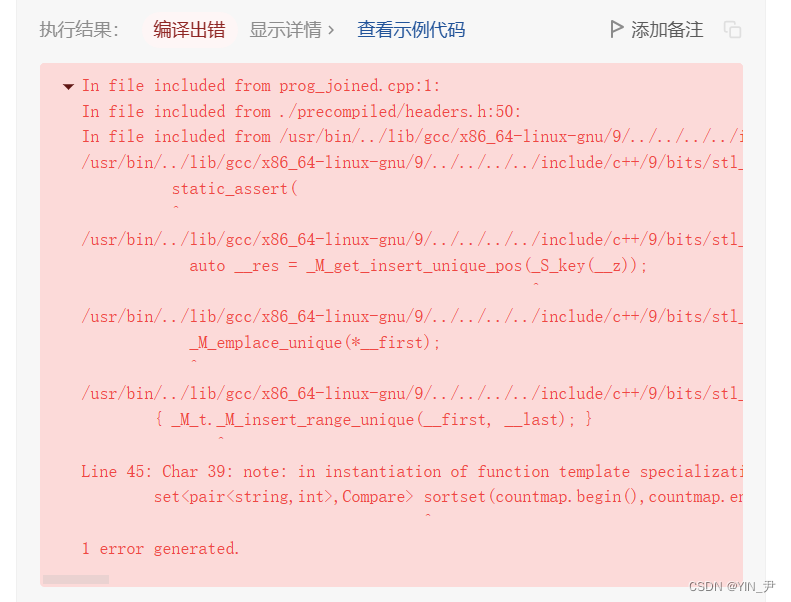
但是提交这里报了一个很奇怪的错。
怎么回事呢?
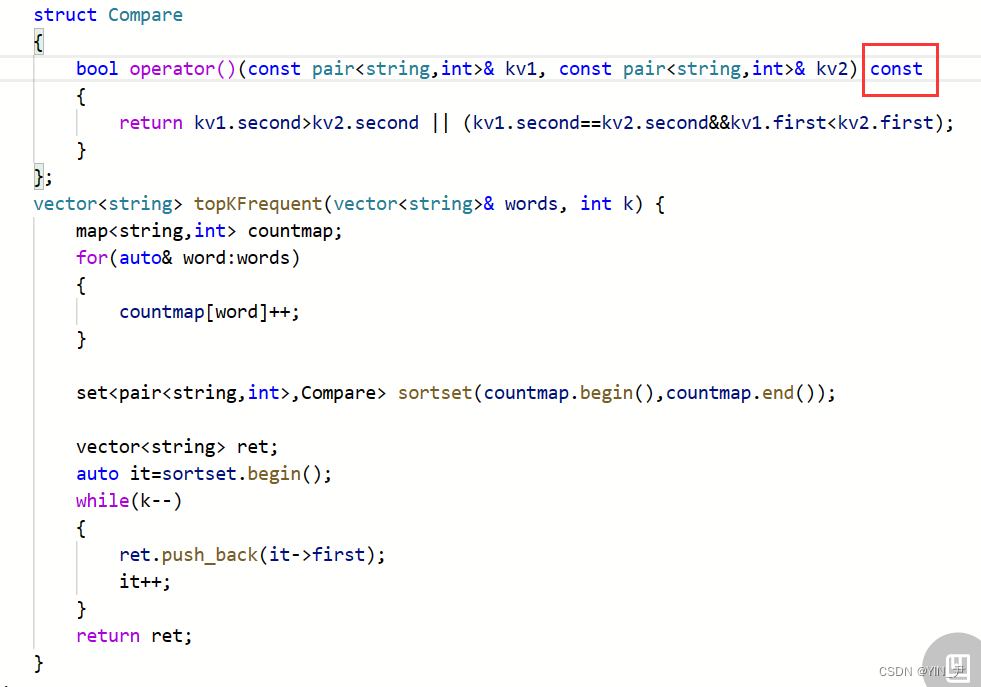
🆗,注意我们写了这个仿函数,有时候他测试的时候会用const对象调用,所以以后写仿函数最后把const加上
就好了。
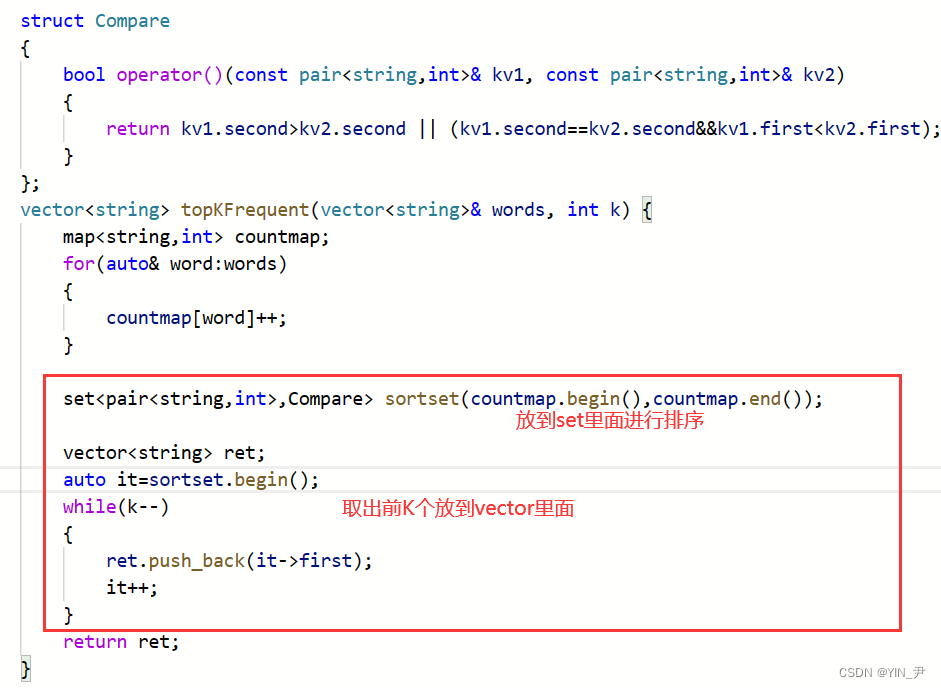
最后,大家想一下为什么我们这里用set(multiset也可以)而不用multimap(map的话有相同次数会去重)呢?
multimap不是也会排序吗?
🆗,因为用multimap的话他排序的时候控制的仿函数是按照key进行比较的
而我们要按次数比较,次数是value。

3. 两个数组的交集
题目链接: link

给我们两个数组,要求我们返回它们的交集,交集中每个元素必须是唯一的。
3.1 思路分析
这个题怎么做呢?
第一步,我们相对两个数组进行排序加去重(因为最终输出结果中元素要唯一,排序的话有助于我们后面找)。
那排序的话我们可以用sort,然后去重其实库里面也有去重算法——unique

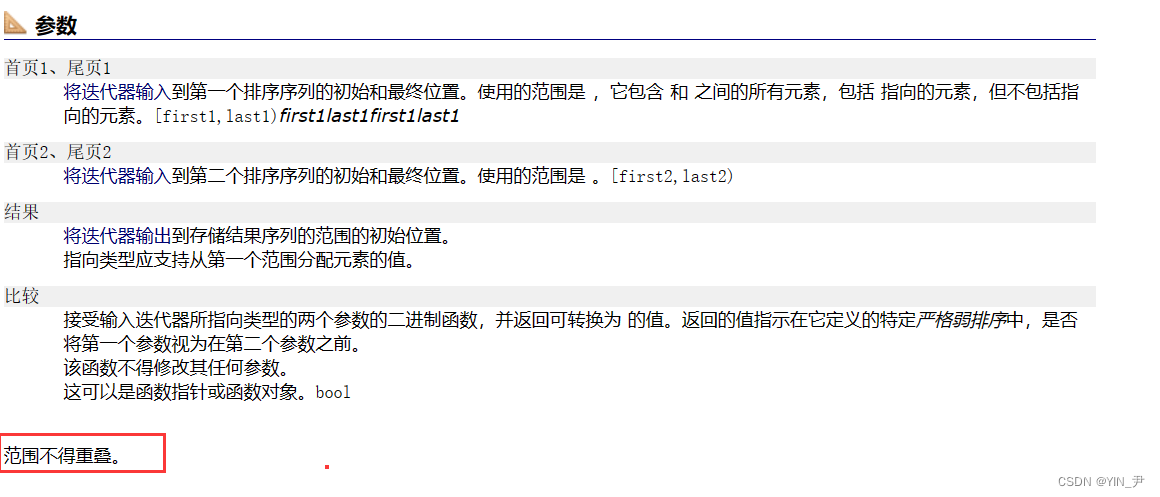
但是,我们有必要有这两个吗?
我们直接一个set就搞定了
然后呢,其实算法库里面也是有求这些集合的算法的。
但是我们不建议大家这样写,题目就是想让我们自己设计算法呢。


那怎么求交集?
其实很简单
我们现在不是已经对两个数组进排序去重了嘛。
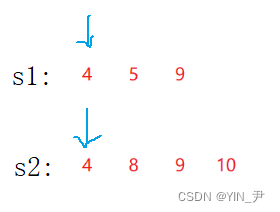
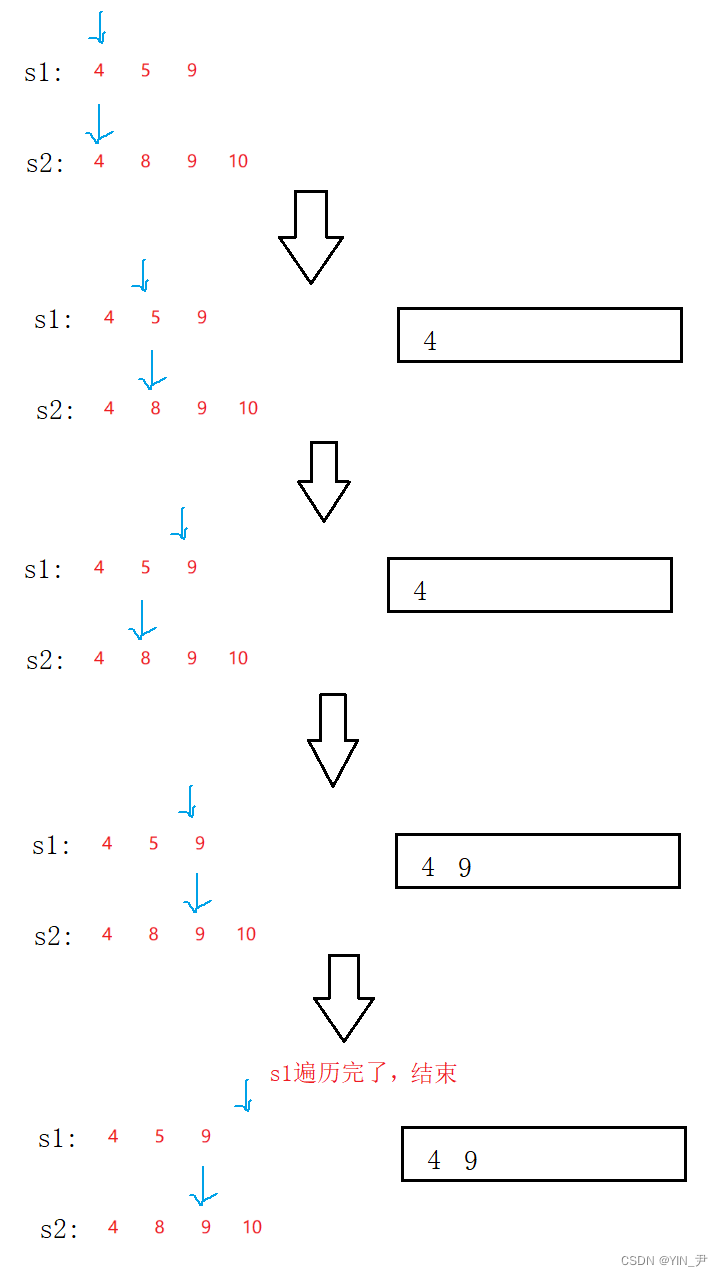
假设现在是这个样子
怎么求它们两个的交集呢?
很简单,双指针去遍历
两个元素相同,就是交集,同时++;
不相同,小的++;
有一个遍历完就结束

3.2 AC代码
来写一下代码
class Solution {
public:
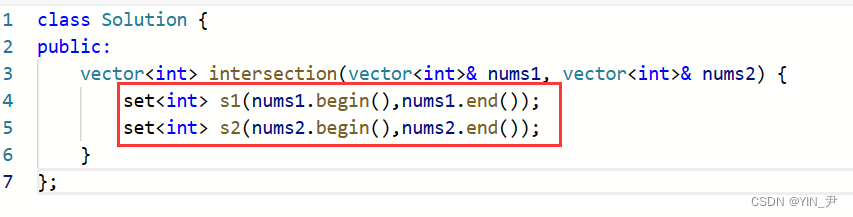
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
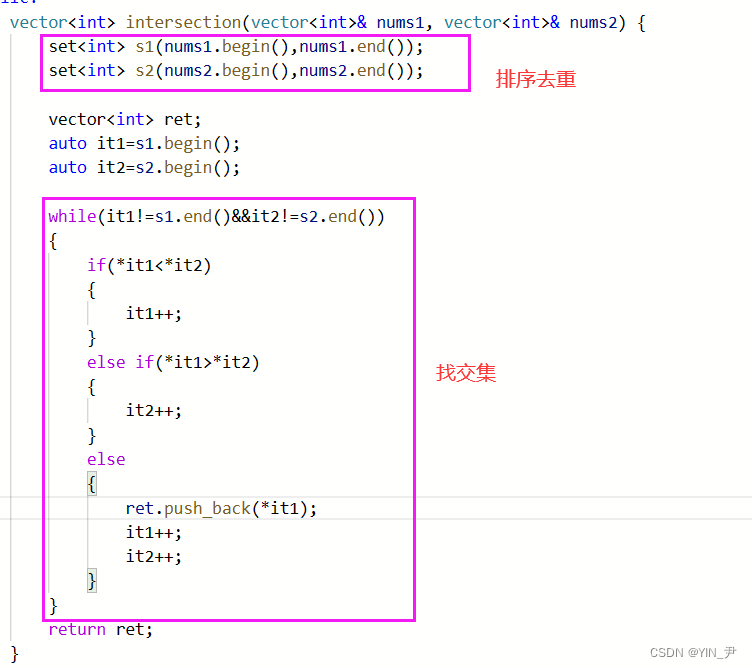
set<int> s1(nums1.begin(),nums1.end());
set<int> s2(nums2.begin(),nums2.end());
vector<int> ret;
auto it1=s1.begin();
auto it2=s2.begin();
while(it1!=s1.end()&&it2!=s2.end())
{
if(*it1<*it2)
{
it1++;
}
else if(*it1>*it2)
{
it2++;
}
else
{
ret.push_back(*it1);
it1++;
it2++;
}
}
return ret;
}
};