面试怕问到缓存穿透?看这篇就够了!
缓存穿透
缓存穿透指的是请求的数据在数据库和缓存中都不存在,这样缓存永远都不会生效,这些请求就会直接打到数据库中。
就比方说,你去查询一个商户,带着id为负数的参数去请求,那么这个东西肯定是查不到的,那么redis这层对于数据库的保护伞就永远起不到作用了。如果说有人不怀好意,并发的去请求这个东西,很容易造成数据库挂掉。
那么为了应对 这些不怀好意的人,我们怎么去预防呢?
-
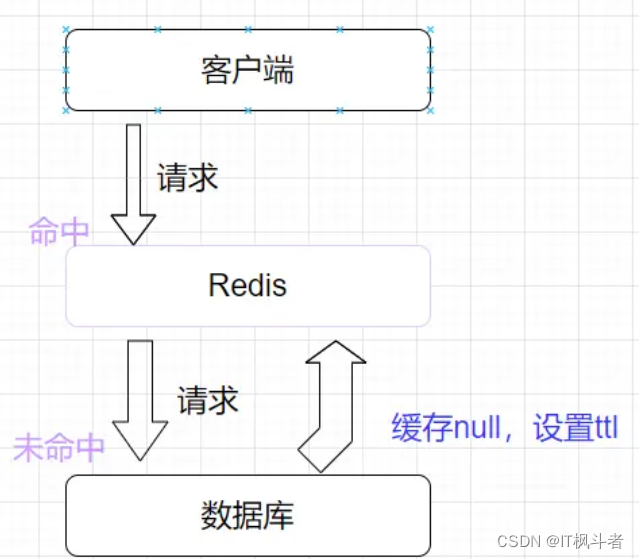
方案一:缓存空对象
-
我们可以对于这个糟糕的请求,如果第一次数据库,redis都没有查询到(未命中),那么我们那就在redis给他去缓存一个空的对象。这样第二次这个糟糕的请求打过来的时候,redis就把刚刚缓存的空对象返回,这样保护伞的作用也就生效了!
优点:实现简单
缺点:1. 造成额外内存消耗,缓存了很多垃圾 2. 存在短期的不一致
有同学可能会好奇,为什么会造成短期的不一致呢?因为,当我们把一个查不到的东西设置成null的时候,redis成为了保护伞,但是如果在此时,我们讲这个查不到的数据给它赋值了,外面的请求如果再想查到,是不是这个时候的redis不再是保护伞,而是一个厚障壁了?
针对这两个缺点,我们可以通过设置ttl(过期时间)来缓解。
针对第一个缺点,如果redis中的数据设置为null,那么我们就给他的ttl设置的短一点,这样内存就会定期清理了
针对第二个缺点,我们同样可以设置短一点的ttl,这样也许2-3min后,我们就又可以访问到数据库了。或者如果我们新增一条数据到数据库,这时候redis不是变成了厚障壁了嘛,那么,我们在新增的同时。把原来为null的那个防御数据删掉,更新成新的数据,也就是说,在新增数据库的同时,更新缓存!这样是不是也能解决数据不一致的问题呢?
-
方案二:布隆过滤
-
看到这张图,我们会发现,有个叫布隆过滤器的东西,它有什么作用呢?
原来他会知道所有数据库里面的数据,如果没有该数据,那么布隆过滤器会将它直接打回。
那么有同学会很好奇,布隆过滤器怎么这么牛,那它岂不是要求存储空间很大?
原来布隆过滤器,会将数据库里面的数据转化成二进制编码,用0 1的方式来告诉请求方它存不存在,这样其实占据的空间是很小的。这种存在与否是概率上的统计,如果布隆过滤器告诉你,它不存在,那么它一定不存在,那如果它告诉你存在,但其实它不一定存在。
说到这里,有同学又会疑惑了,既然它有概率无法拦截恶意请求,那么是不是还是有概率被缓存穿透?
没错,是这样的。没有哪种方案是绝对可靠的,我们需要放到实际的业务场景里仔细分析。
好的,接下来,我们来总结下布隆过滤器的优缺点:
-
优点:内存占用少,没有多余的key
-
缺点:实现起来相对复杂,并且存在误判可能
-
实战
下面我们将进入一个场景,来实战我们缓存穿透的解决策略。
我们新建了一个表,插入了14条数据
如果说此时我们访问id为999的话,肯定是缓存穿透的,下面我们来写缓存穿透的代码
@Override
public Result queryById(Long id) {
if(id == null || id < 0){
return Result.fail("商户为空");
}
String key = SHOP_CACHE_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
if(StrUtil.isNotBlank(shopJson)){
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
if(shopJson != null){
return Result.fail("别攻击我啦");
}
Shop shop = getById(id);
if(shop == null){
stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
return Result.fail("未查询到店铺信息");
}
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);
}如果这个时候我们访问 id 为 999的商品信息,我们redis中肯定查不到,就会去查数据库,数据库也查不到,我们就设置redis中该id的value为null,过期时间设置的短一些,节省内存空间,然后第二次再访问,redis就会起到保护伞的作用啦,不会到数据库。
我们来测试一下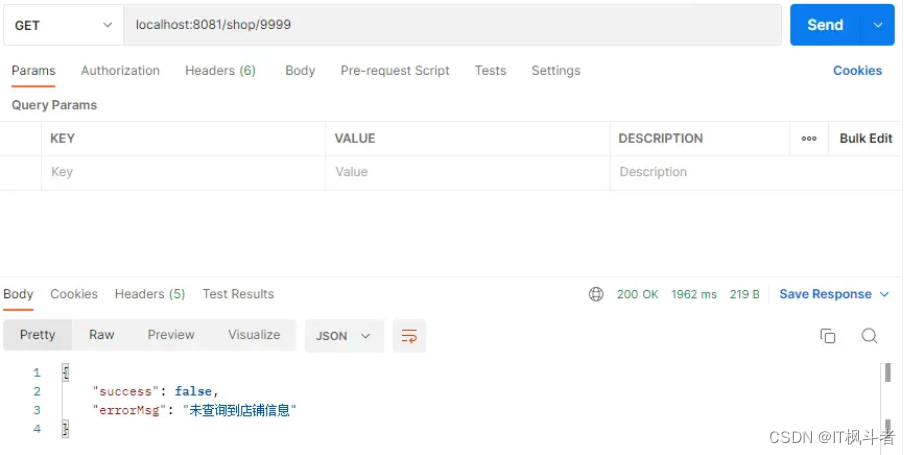
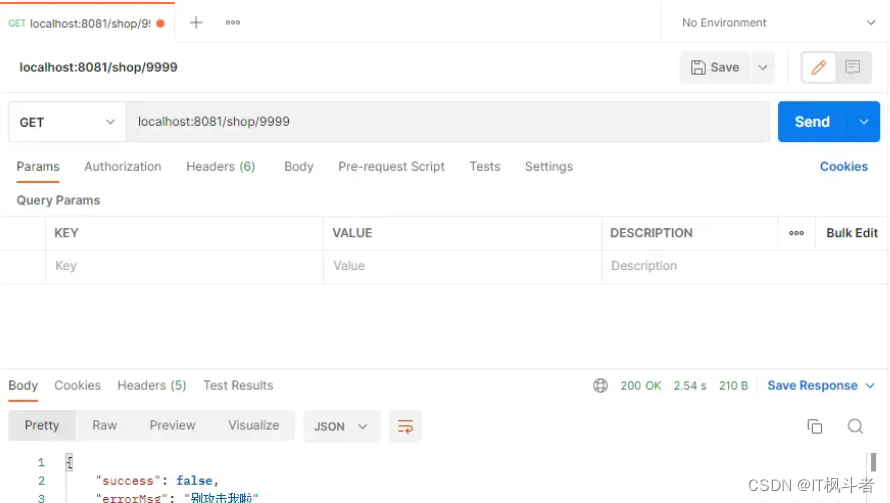
成功!redis向你发送了警告,你别攻击我了!!
防止缓存穿透解决方案总结
-
缓存null值,就是我们之前实践的方式。
-
布隆过滤
-
增强id的复杂度,比如说,限定某个长度,尾缀限定,如果不满足,就直接不进入方法,避免猜测id规律
-
做好数据的基础格式校验
-
加强用户权限的校验,比如说,不登录就不能去访问某一个接口
-
做好热点参数的限流










![[附源码]Python计算机毕业设计SSM基于大数据的超市进销存预警系统(程序+LW)](https://img-blog.csdnimg.cn/c217ab38160e45d68abf762203cc6a8a.png)
