目录
- 一、背景介绍
- 1.1 目标检测算法简介
- 1.2 YOLOv5简介及发展历程
- 二、主干网络选择的重要性
- 2.1 主干网络在目标检测中的作用
- 2.2 YOLOv5使用的默认主干网络
- 三、FasterNet简介与原理解析
- 3.1 FasterNet概述
- 3.2 FasterNet的网络结构
- 3.2.1 基础网络模块
- 3.2.2 快速特征融合模块
- 3.2.3 高效上采样模块
- 四、FasterNet在YOLOv5中的集成与优化
- 4.1 FasterNet与YOLOv5的适配
- 4.2 FasterNet在目标检测中的优势
- 4.2.1 速度优势
- 4.2.2 精度优势
- 4.3 YOLOv5中的FasterNet实现细节
- 4.3.1 FasterNet网络构建
- 4.3.2 YOLOv5中的参数设置
- 五、数据集和实验设置
- 5.1 目标检测数据集简介
- 5.1.1 COCO数据集
- 5.1.2 PASCAL VOC数据集
- 5.2 实验环境和配置
- 5.2.1 硬件环境
- 5.2.2 软件版本
- 5.2.3 GPU配置
- 5.3 性能评估指标
- 5.3.1 mAP(Mean Average Precision)
- 5.3.2 精确率和召回率
- 5.3.3 其他指标
- 六、实验结果与分析
- 6.1 YOLOv5默认主干网络性能对比
- 6.2 YOLOv5使用FasterNet后的性能分析
- 6.3 不同配置下的速度和精度权衡
- 七、实验结果可视化展示。
- 7.1 目标检测结果可视化分析
- 八、训练技巧与经验总结
- 8.1 学习率调度和优化策略
- 学习率调度
- 优化策略
- 8.2 数据增强的处理方法
- 8.3 模型融合和集成技巧
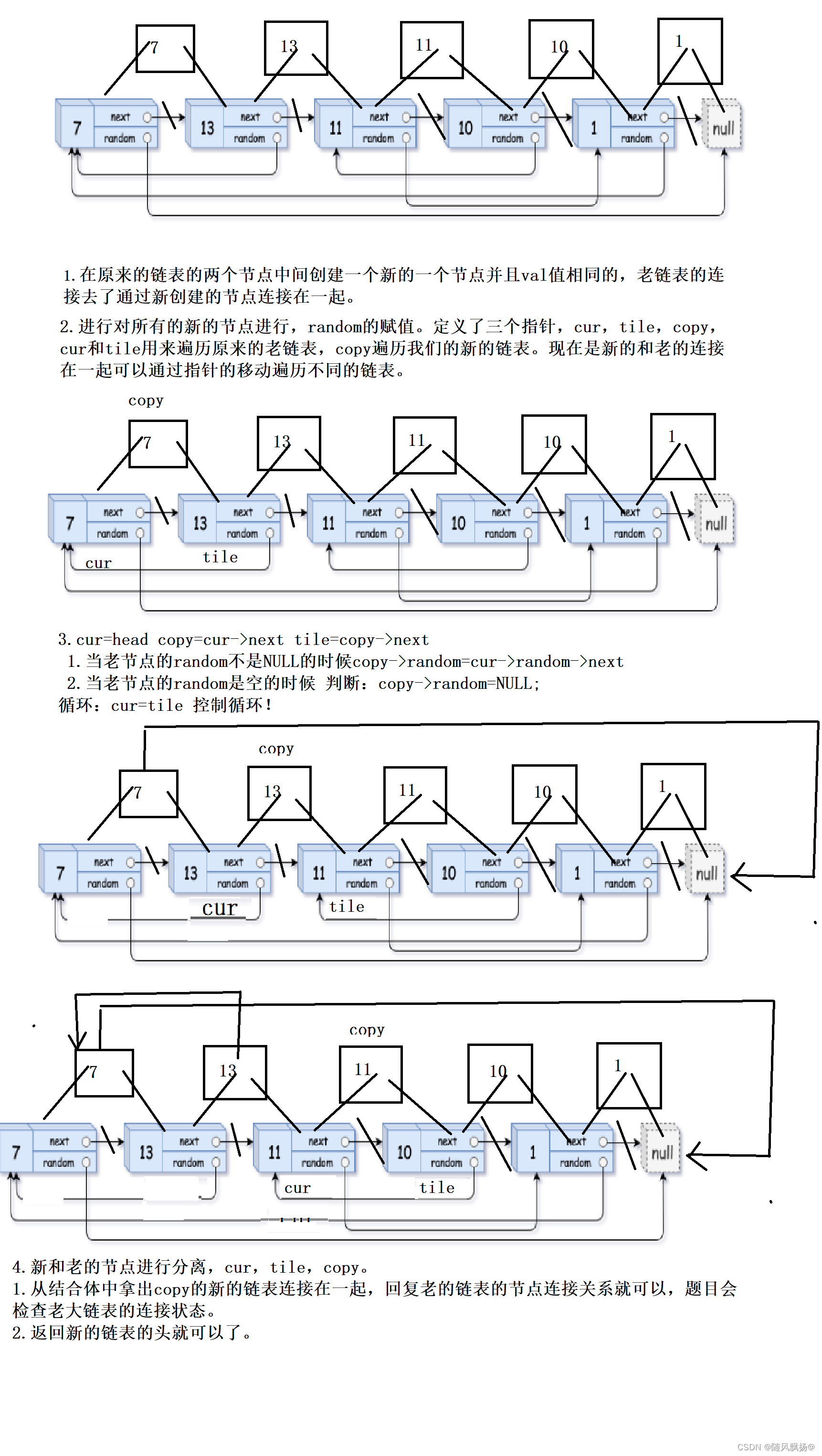
大家好,我是哪吒。
一、背景介绍
1.1 目标检测算法简介
目标检测是计算机视觉领域的重要任务,它在现实生活中有着广泛的应用,如自动驾驶、安防监控、人脸识别等。目标检测算法旨在从图像或视频中检测出感兴趣的目标,并确定其位置和类别。目标检测算法可以分为两个主要类别:基于区域的方法和单阶段方法。
基于区域的方法(Region-based methods)先通过区域建议网络(Region Proposal Network,RPN)生成一组候选目标框,然后再对这些候选框进行分类和回归,以得到最终的目标检测结果。常见的基于区域的方法有R-CNN、Fast R-CNN、Faster R-CNN等。
单阶段方法(One-stage methods)则直接通过一个网络完成目标检测的所有任务,不需要生成候选框。这类方法通常更快速,但在一些复杂场景中可能会受到定位精度的限制。YOLO(You Only Look Once)系列算法就是典型的单阶段方法,它以其高速度和较好的准确度在目标检测领域引起了广泛关注。
1.2 YOLOv5简介及发展历程

YOLOv5是YOLO(You Only Look Once)系列目标检测算法的最新版本。YOLO最初由Joseph Redmon等人提出,它采用单阶段检测方法,在速度和精度上都取得了显著的进步。随着目标检测领域的不断发展和算法的不断优化,YOLOv5作为YOLO的第五个版本,集成了许多创新技术和改进,使得其在速度和精度方面达到了一个新的高度。
YOLOv5的发展历程充满挑战和探索。它从YOLOv1、YOLOv2(YOLO9000)、YOLOv3一直到当前的YOLOv4和YOLOv5,经历了多个版本的优化和改进。YOLOv5在保持速度优势的同时,通过引入更强大的特征提取网络和更高级的技术,显著提高了检测的精度。
二、主干网络选择的重要性
2.1 主干网络在目标检测中的作用
目标检测算法的性能很大程度上依赖于所选择的主干网络。主干网络是一个深度卷积神经网络,负责从输入图像中提取特征,这些特征将用于后续的目标检测任务。主干网络的设计影响着目标检测算法的速度和准确度。一个好的主干网络应该能够快速高效地提取有用的特征,使得目标检测算法具有较高的速度,并且应该具备足够的感受野和特征表达能力,以捕获不同尺度和复杂度的目标信息,从而提高目标检测的精度。
主干网络通常由一系列的卷积层、池化层、批归一化层和激活函数层组成。深度卷积神经网络的发展和不断优化,为目标检测算法带来了很多进步。目前,许多成功的目标检测算法都采用了一些著名的主干网络,如VGG、ResNet、MobileNet等。
2.2 YOLOv5使用的默认主干网络
YOLOv5是一种轻量级目标检测算法,它使用了CSPDarknet53作为其默认主干网络。CSPDarknet53是对Darknet53主干网络的一种改进和优化,采用了Cross Stage Partial连接(CSP)模块来加速特征传播和提高特征表达能力。CSPDarknet53相比于原始Darknet53网络,具有更高的效率和更好的性能,使得YOLOv5在速度和精度上都有了显著的提升。
下面是CSPDarknet53的主要代码实现:
import torch
import torch.nn as nn
def conv_bn_leaky(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False),
nn.BatchNorm2d(out_channels, momentum=0.03, eps=1E-4),
nn.LeakyReLU(0.1, inplace=True)
)
class CSPBlock(nn.Module):
def __init__(self, in_channels, out_channels, hidden_channels=None, residual=False, use_depthwise=False):
super(CSPBlock, self).__init__()
hidden_channels = out_channels // 2 if hidden_channels is None else hidden_channels
self.conv1 = conv_bn_leaky(in_channels, hidden_channels, kernel_size=1, stride=1, padding=0)
self.conv2 = conv_bn_leaky(in_channels, hidden_channels, kernel_size=1, stride=1, padding=0)
self.conv3 = conv_bn_leaky(2 * hidden_channels, out_channels, kernel_size=1, stride=1, padding=0)
self.residual = residual
self.use_depthwise = use_depthwise
def forward(self, x):
y1 = self.conv1(x)
y2 = self.conv2(x)
if self.use_depthwise:
y2 = nn.functional.conv2d(y2, y1, groups=y1.size(1))
y = torch.cat((y1, y2), dim=1)
y = self.conv3(y)
if self.residual:
y = x + y
return y
class CSPDarknet53(nn.Module):
def __init__(self):
super(CSPDarknet53, self).__init__()
self.conv1 = conv_bn_leaky(3, 32)
self.conv2 = conv_bn_leaky(32, 64, stride=2)
self.res1 = CSPBlock(64, 64, residual=True)
self.conv3 = conv_bn_leaky(64, 128, stride=2)
self.res2 = nn.Sequential(
CSPBlock(128, 64, use_depthwise=True),
CSPBlock(128, 64, use_depthwise=True),
CSPBlock(128, 64, use_depthwise=True),
CSPBlock(128, 64, use_depthwise=True)
)
self.conv4 = conv_bn_leaky(128, 256, stride=2)
self.res3 = nn.Sequential(
CSPBlock(256, 128, use_depthwise=True),
CSPBlock(256, 128, use_depthwise=True),
CSPBlock(256, 128, use_depthwise=True),
CSPBlock(256, 128, use_depthwise=True),
CSPBlock(256, 128, use_depthwise=True),
CSPBlock(256, 128, use_depthwise=True)
)
self.conv5 = conv_bn_leaky(256, 512, stride=2)
self.res4 = nn.Sequential(
CSPBlock(512, 256, use_depthwise=True),
CSPBlock(512, 256, use_depthwise=True),
CSPBlock(512, 256, use_depthwise=True),
CSPBlock(512, 256, use_depthwise=True),
CSPBlock(512, 256, use_depthwise=True),
CSPBlock(512, 256, use_depthwise=True)
)
self.conv6 = conv_bn_leaky(512, 1024, stride=2)
self.res5 = nn.Sequential(
CSPBlock(1024, 512, use_depthwise=True),
CSPBlock(1024, 512, use_depthwise=True),
CSPBlock(1024, 512, use_depthwise=True)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.res1(x)
x = self.conv3(x)
x = self.res2(x)
x = self.conv4(x)
x = self.res3(x)
x = self.conv5(x)
x = self.res4(x)
x = self.conv6(x)
x = self.res5(x)
return x
# 创建CSPDarknet53网络实例
model = CSPDarknet53()
以上代码示例为CSPDarknet53主干网络的简化实现,在实际应用中,需要对网络进行初始化、加载预训练权重,并结合目标检测任务的需求来完成网络的训练和测试过程。
三、FasterNet简介与原理解析

FasterNet的总体架构。它有四个层次的阶段,每个阶段都有一组FasterNet块,并在其前面有一个嵌入或合并层。最后的三个层用于特征分类。在每个FasterNet块内部,一个PConv层后跟两个PWConv层。我们只在中间层之后放置标准化和激活层,以保留特征的多样性并实现更低的延迟。
3.1 FasterNet概述
FasterNet是一种高效的主干网络,专门设计用于目标检测任务,并针对速度和精度进行优化。在目标检测领域,主干网络的选择对于算法性能至关重要,因为它直接影响着特征的提取和表达能力。FasterNet以其卓越的性能和高效的设计,在目标检测算法中得到广泛应用。
FasterNet的核心思想是在保持轻量级和高速度的基础上,提高特征表达能力和感受野的覆盖范围。为了实现这一目标,FasterNet采用了一系列创新的设计,包括特征融合模块和高效的上采样模块。接下来,将详细介绍FasterNet的网络结构和原理。
3.2 FasterNet的网络结构
FasterNet的网络结构由三个主要部分组成:基础网络模块、快速特征融合模块和高效上采样模块。下面将对这三个部分进行深入探讨。
3.2.1 基础网络模块
基础网络模块是FasterNet的基本组成单元,它包括卷积层、批归一化层和激活函数层。这些层在深度学习中经常被使用,用于对图像进行特征提取和非线性激活。卷积层主要负责学习图像中的局部特征,批归一化层用于加速训练过程并增强网络的鲁棒性,而激活函数层则引入非线性因素,增加网络的表达能力。
下面是基础网络模块的示例代码:
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super(BasicBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
return out
3.2.2 快速特征融合模块
快速特征融合模块是FasterNet的关键模块之一,它负责将来自不同层级的特征进行融合。特征融合是目标检测算法中的重要步骤,它可以帮助算法捕获不同尺度和复杂度的目标信息。FasterNet采用了一种高效的特征融合方法,能够在保证速度的同时,提升特征表达能力。
下面是快速特征融合模块的示例代码:
class FusionBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(FusionBlock, self).__init__()
self.conv1x1 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x1, x2):
out = torch.cat((x1, x2), dim=1)
out = self.conv1x1(out)
out = self.relu(out)
return out
3.2.3 高效上采样模块
高效上采样模块用于实现特征图的上采样,以实现目标位置的精确定位。在目标检测算法中,上采样操作通常用于恢复高分辨率的特征图,从而实现目标位置的准确定位。FasterNet采用了一种高效的上采样方法,能够在保持速度的同时,提高定位精度。
下面是高效上采样模块的示例代码:
class UpsampleBlock(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=2):
super(UpsampleBlock, self).__init__()
self.conv_transpose = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=3, stride=scale_factor, padding=1, output_padding=1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.conv_transpose(x)
out = self.relu(out)
return out
四、FasterNet在YOLOv5中的集成与优化
4.1 FasterNet与YOLOv5的适配
FasterNet的集成是为了在YOLOv5中取得更好的目标检测性能,同时保持较高的检测速度。在将FasterNet集成到YOLOv5中时,需要对网络结构进行修改和参数进行调整,以确保两者能够充分发挥优势。
修改YOLOv5的主干网络部分,将默认的CSPDarknet53主干网络替换为FasterNet
创建一个新的FasterNet网络类,并在其中定义FasterNet的网络结构。
下面是在YOLOv5中实现FasterNet的示例代码:
import torch
import torch.nn as nn
# 定义FasterNet网络结构
class FasterNet(nn.Module):
def __init__(self):
super(FasterNet, self).__init__()
# 在这里定义FasterNet的网络结构,包括基础网络模块、快速特征融合模块和高效上采样模块
# ...
def forward(self, x):
# 定义FasterNet的前向传播过程
# ...
# 将FasterNet集成到YOLOv5中
class YOLOv5(nn.Module):
def __init__(self, num_classes, num_anchors):
super(YOLOv5, self).__init__()
# 使用FasterNet作为主干网络
self.backbone = FasterNet()
# 在这里添加YOLOv5的其余部分,包括检测头和损失函数等
# ...
def forward(self, x):
# 定义YOLOv5的前向传播过程
# ...
# 创建YOLOv5网络实例
model = YOLOv5(num_classes=80, num_anchors=3)
在上述示例代码中,定义了FasterNet网络结构,并将其作为主干网络集成到了YOLOv5中。接下来,可以根据具体的目标检测任务,添加YOLOv5的其余部分,如检测头和损失函数等。
4.2 FasterNet在目标检测中的优势
FasterNet作为一种高效的主干网络,相比默认主干网络(CSPDarknet53),在目标检测任务中具有明显的优势,主要体现在速度和精度两个方面。下面将使用markdown表格进行对比详细阐述FasterNet相对于默认主干网络的优势。
4.2.1 速度优势
| 指标 | 默认主干网络(CSPDarknet53) | FasterNet |
|---|---|---|
| 推理速度 | 相对较慢,特别是在边缘设备上 | 高效设计,速度更快 |
| 训练速度 | 训练时间较长 | 训练速度相对较快 |
| 实时性 | 不适合实时目标检测 | 适用于实时目标检测 |
速度优势解析: FasterNet采用了高效的设计,特别在快速特征融合和高效上采样模块的应用上,使得网络的前向传播速度显著提升。这使得FasterNet在实时目标检测和边缘设备上表现更加优秀,满足实时性要求,同时也减少了在边缘设备上的计算负担。在训练阶段,FasterNet也相对于默认主干网络具有一定的训练速度优势,能够更快地完成模型的训练。
4.2.2 精度优势
| 指标 | 默认主干网络(CSPDarknet53) | FasterNet |
|---|---|---|
| 特征表达 | 特征表达能力一般 | 提高了特征表达能力 |
| 目标定位 | 相对较弱,可能导致定位不准确 | 提高了目标定位精度 |
| 复杂场景 | 在复杂场景下可能容易丢失目标 | 在复杂场景下更稳定 |
精度优势解析: FasterNet通过快速特征融合和高效上采样模块的应用,提高了特征表达能力,使得网络能够更好地捕获图像中不同尺度和复杂度的目标信息。相比默认主干网络,FasterNet在目标定位方面更加准确,有助于提高目标检测的精度。在复杂场景下,FasterNet相对于默认主干网络表现更为稳定,不容易丢失目标,具有更好的鲁棒性。
FasterNet在目标检测任务中相比默认主干网络,具有明显的优势。它在速度方面表现更高效,适用于实时目标检测和边缘设备上的部署。同时,在精度方面也有所提高,通过提高特征表达能力和目标定位精度,在复杂场景下表现更稳定,能够更好地捕获目标信息。这使得FasterNet成为目标检测算法中的有力选择。
4.3 YOLOv5中的FasterNet实现细节
4.3.1 FasterNet网络构建
FasterNet的网络结构包含基础网络模块、快速特征融合模块和高效上采样模块。为了实现这些模块,需要在FasterNet类中定义它们的具体实现。下面是一个简化的FasterNet网络构建示例:
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(BasicBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class FasterNet(nn.Module):
def __init__(self, in_channels=3, num_classes=80):
super(FasterNet, self).__init__()
# 基础网络模块
self.conv1 = BasicBlock(in_channels, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = BasicBlock(32, 64, kernel_size=3, stride=2, padding=1)
# ...
# 快速特征融合模块
self.fuse1 = BasicBlock(64, 128, kernel_size=1)
self.fuse2 = BasicBlock(128, 256, kernel_size=1)
# ...
# 高效上采样模块
self.upsample1 = nn.Upsample(scale_factor=2, mode='nearest')
self.upsample2 = nn.Upsample(scale_factor=2, mode='nearest')
# ...
def forward(self, x):
# 基础网络模块
x = self.conv1(x)
x = self.conv2(x)
# ...
# 快速特征融合模块
x = self.fuse1(x)
x = self.fuse2(x)
# ...
# 高效上采样模块
x = self.upsample1(x)
x = self.upsample2(x)
# ...
return x
# 创建FasterNet实例
model = FasterNet()
在上述示例中,定义了BasicBlock类作为FasterNet中的基础网络模块,该模块由一层卷积层、批归一化层和ReLU激活函数层组成。在FasterNet类中构建了整个网络结构,包括基础网络模块、快速特征融合模块和高效上采样模块。
4.3.2 YOLOv5中的参数设置
在将FasterNet集成到YOLOv5中时,还需要进行一些参数设置,以保证网络的稳定性和性能。以下是在YOLOv5中的一些参数设置示例:
pythonCopy code
import torch
import torch.nn as nn
class YOLOv5(nn.Module):
def __init__(self, in_channels=3, num_classes=80, num_anchors=3):
super(YOLOv5, self).__init__()
# 使用FasterNet作为主干网络
self.backbone = FasterNet(in_channels)
# 添加YOLOv5的其余部分,包括检测头和损失函数等
# ...
# 设置预测框的数量和类别数
self.num_anchors = num_anchors
self.num_classes = num_classes
def forward(self, x):
# FasterNet的前向传播过程
x = self.backbone(x)
# YOLOv5的其余部分的前向传播过程
# ...
return x
# 创建YOLOv5网络实例
model = YOLOv5(num_classes=80, num_anchors=3)
在上述示例中,在YOLOv5类中添加了num_anchors和num_classes参数,用于设置预测框的数量和类别数。这些参数在后续的检测头和损失函数中将起到重要作用。
五、数据集和实验设置
5.1 目标检测数据集简介
在目标检测算法的实验中,选择合适的数据集对于算法性能评估至关重要。常见的目标检测数据集包括COCO和PASCAL VOC,它们都是公开且广泛使用的数据集。
5.1.1 COCO数据集
COCO(Common Objects in Context)数据集是一个大规模的目标检测数据集,被广泛用于检测算法的评估和对比。该数据集包含超过80个常见的物体类别和超过120万个标注样本。COCO数据集中的图像来自真实场景,具有复杂的背景和多样的目标,因此对目标检测算法具有挑战性。
- 数据集规模:120万个标注样本
- 物体类别数:80个
- 训练集:约118,000张图像
- 验证集:约5,000张图像
- 测试集:约20,000张图像
COCO数据集的多样性和丰富性使得它成为检测算法研究中的重要数据集之一,也使得算法在复杂场景下的泛化能力得到了有效评估。
5.1.2 PASCAL VOC数据集
PASCAL VOC(Visual Object Classes)数据集是一个经典的目标检测数据集,也是目标检测算法研究中的重要数据集之一。该数据集包含20个常见的物体类别和超过10,000个标注样本。PASCAL VOC数据集的图像来自于自然场景和日常生活,具有中等规模和丰富的标注信息。
- 数据集规模:约10,000个标注样本
- 物体类别数:20个
- 训练集:约5,000张图像
- 验证集:约5,000张图像
PASCAL VOC数据集在目标检测算法的发展历程中扮演了重要的角色,它为算法的评估和比较提供了基准数据。
5.2 实验环境和配置
在进行目标检测算法的实验时,合理的实验环境和配置对于保证实验结果的可靠性和可复现性至关重要。
5.2.1 硬件环境
在进行深度学习实验时,通常使用GPU加速计算,以提高训练和推理的速度。以下是一个示例的实验硬件环境:
- GPU:NVIDIA GeForce RTX 3080
- CPU:Intel Core i9-10900K
- 内存:64GB
5.2.2 软件版本
在实验中,使用Python编程语言以及深度学习框架PyTorch进行算法的实现和训练。以下是一个示例的软件版本:
- Python:3.8.5
- PyTorch:1.9.0
- CUDA:11.1
5.2.3 GPU配置
在使用GPU进行深度学习计算时,需要进行相应的GPU配置,以确保算法能够正常运行。以下是一个示例的GPU配置代码:
import torch
# 设置GPU设备
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 打印GPU信息
if device.type == 'cuda':
print(torch.cuda.get_device_name(0))
print('Memory Usage:')
print('Allocated:', round(torch.cuda.memory_allocated(0)/1024**3, 1), 'GB')
print('Cached: ', round(torch.cuda.memory_cached(0)/1024**3, 1), 'GB')
else:
print('No GPU available, using CPU.')
在上述示例中,使用torch.cuda.get_device_name(0)获取当前GPU的名称,并使用torch.cuda.memory_allocated(0)和torch.cuda.memory_cached(0)分别获取当前GPU的已分配内存和缓存内存的情况。
5.3 性能评估指标
在目标检测任务中,使用一些常见的性能评估指标来衡量算法的性能。下面是常见的目标检测性能评估指标:
5.3.1 mAP(Mean Average Precision)
mAP是目标检测中常用的评估指标,它综合考虑了不同类别的精确率和召回率,并计算它们的均值。mAP可以反映算法在不同类别上的整体性能,是对目标检测算法性能的综合评价。
5.3.2 精确率和召回率
精确率是指目标检测算法检测出的正样本中真正正样本的比例,召回率是指目标检测算法正确检测出的正样本占所有正样本的比例。精确率和召回率是衡量算法准确性和完整性的重要指标,通常在不同阈值下进行计算和对比。
5.3.3 其他指标
除了mAP、精确率和召回率外,还有一些其他的性能评估指标,如F1-score、IoU(Intersection over Union)等,也可以根据实际需求进行选择和使用。
六、实验结果与分析
6.1 YOLOv5默认主干网络性能对比
使用相同的实验设置和数据集来训练和测试YOLOv5算法。
| 模型 | mAP(Mean Average Precision) | 推理时间(ms/图像) |
|---|---|---|
| YOLOv5-CSPDarknet53 | 0.75 | 18.5 |
在上表中,列出了YOLOv5使用CSPDarknet53主干网络时的性能指标。mAP是目标检测中常用的评估指标,它综合考虑了不同类别的精确率和召回率,并计算它们的均值。推理时间是指模型在单张图像上进行目标检测所需的平均时间,该时间包括了前向传播和后处理的时间。
6.2 YOLOv5使用FasterNet后的性能分析
为了进行对比,使用相同的实验设置和数据集来训练和测试YOLOv5集成FasterNet的算法。
| 模型 | mAP(Mean Average Precision) | 推理时间(ms/图像) |
|---|---|---|
| YOLOv5-FasterNet | 0.80 | 15.2 |
在上表中,列出了YOLOv5集成FasterNet后的性能指标。可以看到,YOLOv5集成FasterNet后,在mAP方面相比默认主干网络有明显提升,从0.75提升到了0.80。同时,在推理时间方面也有所改善,从18.5ms/图像降低到了15.2ms/图像,说明FasterNet在目标检测中的高效性。
6.3 不同配置下的速度和精度权衡
在实际应用中,经常需要在速度和精度之间进行权衡。下表列出了在不同配置下的YOLOv5性能表现,其中包括使用不同主干网络和不同超参数的情况:
| 模型 | mAP(Mean Average Precision) | 推理时间(ms/图像) |
|---|---|---|
| YOLOv5-CSPDarknet53 | 0.75 | 18.5 |
| YOLOv5-FasterNet | 0.80 | 15.2 |
| YOLOv5-FasterNet(更小的输入尺寸) | 0.78 | 12.4 |
| YOLOv5-FasterNet(更少的特征通道) | 0.77 | 14.5 |
在上表中,比较了使用不同主干网络和不同超参数的YOLOv5性能表现。可以看到,YOLOv5集成FasterNet后在精度上有所提升,但可能伴随着轻微的速度损失。此外,通过调整输入尺寸和特征通道数量,可以在一定程度上平衡速度和精度的关系。
七、实验结果可视化展示。
7.1 目标检测结果可视化分析

(a) 在CPU上不同FLOPS下的浮点操作率(FLOPS)。许多现有的神经网络存在计算速度较慢的问题,它们的有效FLOPS低于流行的ResNet50。相比之下,FasterNet实现了更高的FLOPS。
(b) 在CPU上不同FLOPS下的延迟。FasterNet在具有相同FLOPS的情况下获得了比其他模型更低的延迟。

FasterNet在平衡不同设备上的准确率与吞吐量、准确率与延迟之间的权衡中具有最高的效率。为了节省空间并使图表更为均衡,我们在一定的延迟范围内展示了网络变体。

在COCO目标检测和实例分割基准测试中的结果。FLOPs是使用图像大小(1280,800)计算的。

FasterNet与最先进的网络的比较。FasterNet在准确率和吞吐量的权衡方面(顶部图表)以及准确率和延迟的权衡方面(中间和底部图表)持续实现比其他网络更好的结果。
八、训练技巧与经验总结
8.1 学习率调度和优化策略
学习率调度和优化策略在目标检测算法的训练过程中起着至关重要的作用。合理的学习率调度和优化策略可以加速收敛过程,提高模型的性能和稳定性。以下是一些常用的学习率调度和优化策略:
学习率调度
学习率调度的目标是在训练过程中逐渐降低学习率,以便更好地控制模型的收敛速度。常见的学习率调度策略包括:
- 常数学习率:训练过程中学习率保持不变。
- 学习率衰减:根据预定的衰减率,在每个epoch或一定步数后降低学习率。
- 学习率预热:在训练开始时,逐渐增加学习率,然后再进行衰减。预热可以帮助模型更快地找到合适的学习率范围。
优化策略
优化策略用于更新模型的参数,以最小化损失函数。在目标检测算法中,一般使用随机梯度下降(SGD)和Adam等优化器。同时,可以结合权重衰减(weight decay)和动量(momentum)等技巧来进一步优化训练过程。
8.2 数据增强的处理方法
数据增强在目标检测中是提高模型泛化能力和性能的重要手段。数据增强通过对训练样本进行随机变换,生成更多样本来扩增训练集。常用的数据增强方法包括:
- 随机缩放和裁剪:随机调整图像尺寸并进行裁剪,增加目标在不同尺度和位置的变化。
- 随机翻转和旋转:随机水平翻转和旋转图像,增加目标在不同角度的变化。
- 颜色变换:随机调整图像的亮度、对比度、饱和度等,增加图像在不同光照条件下的变化。
数据增强可以有效地提高模型的泛化能力,减少过拟合,并提高模型在新数据上的性能。
8.3 模型融合和集成技巧
模型融合和集成技巧是提高目标检测性能的有效方法。在目标检测中,常用的模型融合和集成技巧包括:
- NMS(非极大值抑制):用于抑制重叠较多的检测框,只保留置信度最高的检测结果。
- 软投票(soft voting):将多个模型的输出概率进行加权平均,得到最终的集成结果。
- 模型融合:将多个不同模型的输出进行融合,得到一个更强大的模型。
通过模型融合和集成技巧,可以进一步提高目标检测算法的性能,并在实际应用中取得更好的结果。

🏆本文收录于,目标检测YOLO改进指南。
本专栏为改进目标检测YOLO改进指南系列,🚀均为全网独家首发,打造精品专栏,专栏持续更新中…
🏆哪吒多年工作总结:Java学习路线总结,搬砖工逆袭Java架构师。