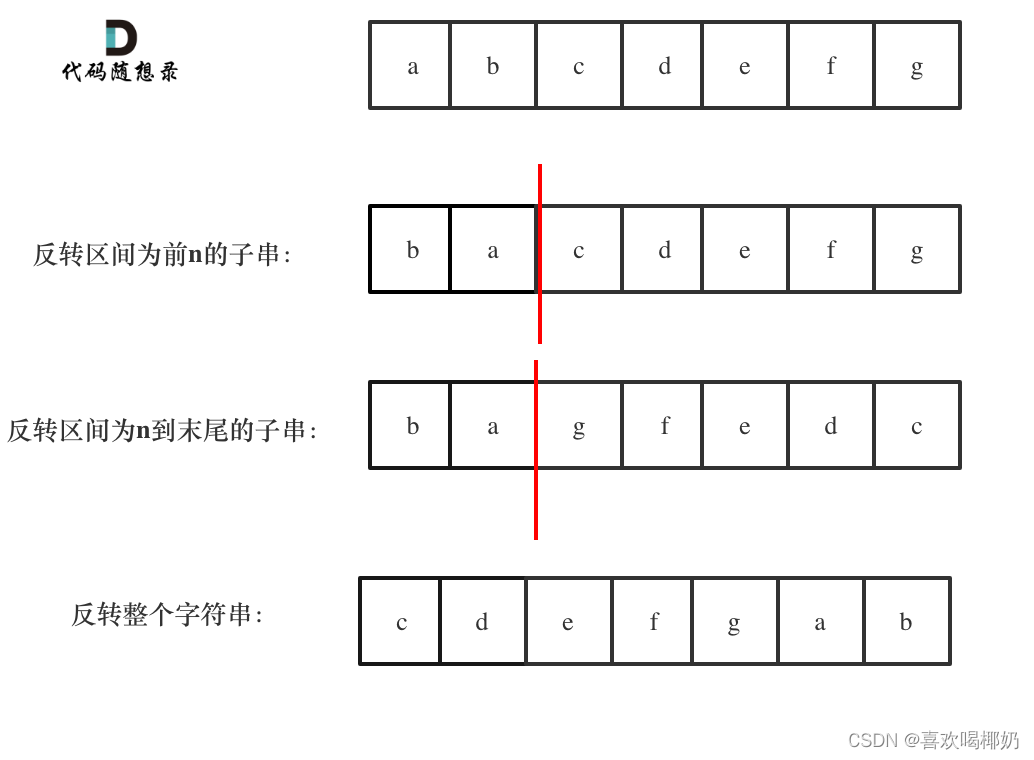
目录
1 Inpaint Anything介绍
1.1 为什么我们需要Inpaint Anything
1.2 Inpaint Anything工作原理
1.3 Inpaint Anything的功能是什么
1.4 Segment Anything模型(SAM)
1.5 Inpaint Anything
1.5.1 移除任何物体
1.5.2 填充任意内容
1.5.3 替换任意内容
1.5.4 实践
1.6 实验总结
2 Inpaint Anything部署与运行
2.1 conda环境准备
2.2 运行环境安装
2.3 模型下载
3 Inpaint Anything运行效果展示
3.1 Remove Anything
3.2 Fill Anything
3.3 Replace Anything
3.5 Remove Anything Video
4 总结
1 Inpaint Anything介绍
通过一键点击标记选定对象,即可实现移除指定对象、填补指定对象、替换一切场景,涵盖了包括目标移除、目标填充、背景替换等在内的多种典型图像修补应用场景。
现代图像修复系统在掩膜选择和填充孔洞方面经常遇到困难。基于Segment-Anything模型(SAM),作者首次尝试了无需掩膜的图像修复,并提出了一种名为"Inpaint Anything(IA)"的新范式,即"点击和填充"。
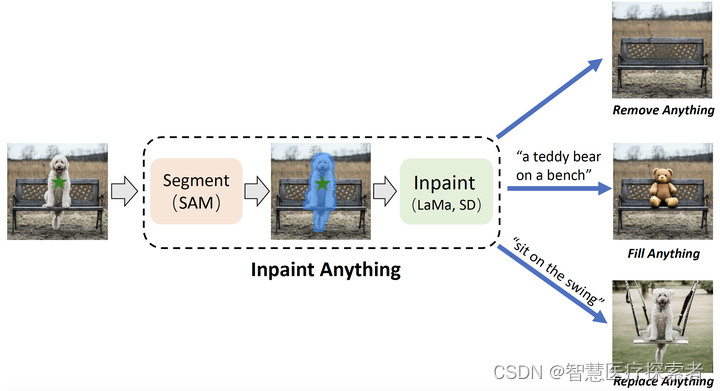
IA的核心思想是结合不同模型的优势,构建一个非常强大且用户友好的流程来解决修复相关的问题。IA支持三个主要功能:
- 移除任何物体:用户可以点击一个物体,IA将移除它并用上下文平滑填补"空洞";
- 填充任何内容:在移除某些物体后,用户可以提供基于文本的提示给IA,然后它将通过驱动稳定扩散(Stable Diffusion)[11]等AIGC模型来填充空洞与相应的生成内容;
- 替换任何背景:借助IA,用户可以选择保留点击选择的物体并用新生成的场景替换其余背景。
论文:https://arxiv.org/pdf/2304.06790.pdf
代码:https://github.com/geekyutao/Inpaint-Anything
1.1 为什么我们需要Inpaint Anything
- 最先进的图像修复方法,如LaMa 、Repaint、MAT、ZITS等,在修复大区域和处理复杂重复结构方面取得了巨大进展。它们可以成功地对高分辨率图像进行修复,并且通常可以很好地推广到其他图像。然而,它们通常需要每个掩膜的精细注释,这对于训练和推断是必不可少的。
- Segment Anything Model (SAM)是一个强大的分割基础模型,可以根据输入提示(如点或框)生成高质量的对象遮罩,并且可以为图像中的所有对象生成全面准确的遮罩。然而,它们的遮罩分割预测尚未充分探索。
- 此外,现有的修复方法只能使用上下文来填充已移除的区域。AIGC模型为创作开辟了新的机会,这有潜力满足大量需求,并帮助人们生成所需的内容。
- 因此,通过结合SAM、最先进的图像修复器LaMa和AI生成的内容(AIGC)模型的优势,我们提供了一个强大且用户友好的流程,用于解决更多通用的与修复相关的问题,例如对象移除、新内容填充和背景替换。
1.2 Inpaint Anything工作原理
Inpaint Anything结合了 SAM、图像修补模型(例如 LaMa)和 AIGC 模型(例如 Stable Diffusion)等视觉基础模型。
- SAM(Segment Anything Model)可以通过点或框等输入提示生成高质量的对象分割区域,实现指定目标的分割。
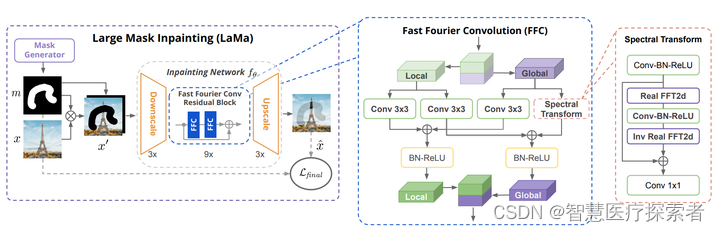
- 图像修补模型LaMa,则能够在高分辨率图像的情况下,随意删除图像中的各种元素。模型的主要架构如下图所示。包含一个mask的黑白图,一张原始图像。将掩码图覆盖图像后输入Inpainting网络中,先是降采样到低分辨率,再经过几个快速傅里叶卷积FFC残差块,最后输出上采样,生成了一张高分辨的修复图像。
- AIGC模型Stable Diffusion,则只要简单的输入一段文本,Stable Diffusion 就可以迅速将其转换为图像。
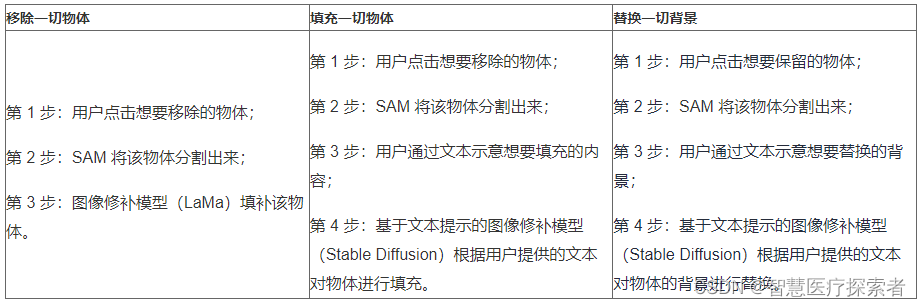
将三个模型结合到一起,我们可以做出很多的功能。本文就实现了在图片/视频中移除一切物体、在图片中填充一切物体和在图片中替换一切背景这三种功能,其具体实现步骤如下:
1.3 Inpaint Anything的功能是什么
- 使用SAM + SOTA修复器移除任意对象: 通过IA,用户可以通过简单地点击对象来轻松地从界面中删除特定对象。此外,IA还提供了一个选项,让用户可以使用上下文数据填充生成的"空洞"。针对此需求,我们结合了SAM和一些最先进的修复器(如LaMa)的优势。通过腐蚀和膨胀的手动细化,由SAM生成的掩膜预测作为修复模型的输入,为要擦除和填充的对象区域提供清晰的指示。
- 使用SAM + AIGC模型填充或替换任意内容:
(1) 在移除对象后,IA提供了两种选项来填充生成的"空洞",即使用上下文数据或"新内容"。具体而言,我们利用类似Stable Diffusion [11]的强大AI生成内容(AIGC)模型通过文本提示来生成新对象。例如,用户可以使用"dog"这个词或者"一只可爱的狗,坐在长凳上"这样的句子来生成一只新的狗来填充空洞。
(2) 此外,用户还可以选择在保留点击选择的对象的同时,用新生成的场景替换剩余的背景。IA支持多种方式来提示AIGC模型,例如使用不同的图像作为视觉提示或使用简短的标题作为文本提示。例如,用户可以保留图像中的狗,但将原来的室内背景替换为室外背景。

1.4 Segment Anything模型(SAM)
Segment Anything是一种基于大型视觉语料库(SA-1B)训练的基于ViT的CV模型。SAM在各种场景中展示了有前景的分割能力,以及基础模型在计算机视觉领域的巨大潜力。这是通往视觉人工通用智能的开创性一步,SAM曾被誉为"CV版ChatGPT"。
- SOTA修复器:图像修复作为一个不适定的逆问题,在计算机视觉和图像处理领域得到了广泛的研究。其目标是用具有视觉合理结构和纹理的内容替换损坏图像的缺失区域。在Inpaint Anything(IA)中,作者调研了一种简单的单阶段方法LaMa 用于基于掩膜的修复,该方法通过结合快速傅立叶卷积(FFC)、感知损失和激进的训练掩膜生成策略,在生成重复性视觉结构方面表现出色。
- AIGC模型:ChatGPT和其他生成AI(GAI)技术都属于人工智能生成内容(AIGC)的范畴,涉及通过AI模型创建数字内容,例如图像、音乐和自然语言。它被视为一种新型的内容创作方式,并在各种内容生成方面展现了最先进的性能。在我们的IA工作中,作者直接使用强大的AIGC模型Stable Diffusion,基于文本提示来在空洞中生成所需的内容。
1.5 Inpaint Anything
作者提出的Inpaint Anything (IA)的原理是将现成的基础模型组合起来,以解决广泛的图像修复问题。通过组合各种基础模型的优势,IA能够生成高质量的修复图像。具体而言,我们的IA包括三种方案,即Remove Anything、Fill Anything和Replace Anything,分别用于移除、填充和替换任意内容。
1.5.1 移除任何物体
Remove Anything专注于通过允许用户从图像中消除任何物体来解决物体移除问题,同时确保生成的图像在视觉上仍然合理。
Remove Anything由三个步骤组成:点击、分割和移除。
- 在第一步中,用户通过点击选择他们想要从图像中移除的物体。
- 接下来,使用基础分割模型,如Segment Anything ,根据点击位置自动分割物体并创建遮罩。
- 最后,使用先进的修复模型,如LaMa [13],使用遮罩来填补被移除物体留下的空洞。
由于图像中不再存在该物体,修复模型会用背景信息填充空洞。
需要注意的是,在整个过程中,用户只需要点击他们想要从图像中移除的物体。
1.5.2 填充任意内容
Fill Anything允许用户将图像中的任何物体填充为他们想要的任何内容。
该工具包括四个步骤:点击、分割、文本提示和生成。
- Fill Anything的前两个步骤与Remove Anything相同。
- 在第三步中,用户输入指示他们想要用什么内容填充物体空洞的文本提示。
- 最后,采用强大的AIGC模型,如Stable Diffusion [11],基于文本提示修复模型在空洞中生成所需的内容。
1.5.3 替换任意内容
Replace Anything能够将任何物体替换为任何背景。Replace Anything的过程与Fill Anything类似,但在这种情况下,提示AIGC模型生成与指定物体外部相一致的背景。
1.5.4 实践
将基础模型组合解决任务可能会遇到不兼容或不适合的问题。我们应该考虑中间处理,以实现模型和任务之间更好的协调。在本研究中,针对图像修复场景,我们总结了一些良好的组合实践如下:
- 膨胀操作的重要性。
我们观察到SAM的分割结果(即物体遮罩)可能包含不连续和非平滑的边界,或者物体区域内部存在空洞。这些问题对于有效地移除或填充物体构成了挑战。因此,我们使用膨胀操作来优化遮罩。此外,对于填充物体,大遮罩为AIGC模型提供更大的创作空间,有利于与用户意图的"对齐"。因此,在Fill Anything中采用了大的膨胀操作。
- 保真度的重要性。
大多数最先进的AIGC模型(如Stable Diffusion)需要图像具有固定的分辨率,通常为512×512。简单地将图像调整到这个分辨率可能会导致保真度的降低,从而对最终的修复结果产生不利影响。因此,采取保留原始图像质量的措施是必要的,例如使用裁剪技术或在调整大小时保持图像的宽高比。
- 提示的重要性。
我们的研究表明,文本提示对AIGC模型有重要影响。然而,我们观察到在文本提示修复场景中,简单的提示(例如"长凳上的玩具熊"或"墙上的毕加索画作")通常能产生满意的结果。相比之下,更长、更复杂的提示可能会产生令人印象深刻的结果,但它们往往不太用户友好。

1.6 实验总结
作者在Inpaint Anything中对Remove Anything、Fill Anything和Replace Anything进行了评估,分别在移除对象、填充对象和替换背景的三种情况下进行。作者从COCO数据集、LaMa测试集和手机拍摄的照片中收集了测试图像。实验结果表明,所提出的Inpaint Anything具有通用性和鲁棒性,能够有效地对具有多样内容、分辨率和宽高比的图像进行修复。
2 Inpaint Anything部署与运行
2.1 conda环境准备
conda环境准备详见:annoconda
2.2 运行环境安装
git clone https://github.com/geekyutao/Inpaint-Anything
cd Inpaint-Anything
conda create -n ia python=3.9
conda activate ia
pip install torchvision==0.15.2
pip install torchaudio==2.0.2
pip install -e segment_anything
pip install -r lama/requirements.txt
pip install diffusers==0.16.1
pip install transformers==4.30.2
pip install accelerate==0.19.0
pip install scipy==1.11.1
pip install safetensors==0.3.1
pip install numpy==1.23.5
pip install jpeg4py==0.1.42.3 模型下载
(1)Remove Anything模型
创建模型存储目录:
mkdir -p pretrained_models/big-lamaSAM模型下载:SAM地址
Lama模型地址:Lama地址
从以上模型地址下载模型文件,下载完成后:
SAM模型文件移动到pretrained_models目录下,
Lama模型文件移动到pretrained_models/big-lama
完成后命令行显示如下:
[root@localhost Inpaint-Anything]# ll pretrained_models/
总用量 2504448
drwxr-xr-x 3 root root 51 8月 4 18:13 big-lama
-rw-r--r-- 1 root root 2564550879 8月 4 15:32 sam_vit_h_4b8939.pth
[root@localhost Inpaint-Anything]# ll pretrained_models/big-lama/
总用量 4
-rw-r--r-- 1 root root 3947 8月 4 15:28 config.yaml
drwxr-xr-x 2 root root 31 8月 4 15:28 models(2)Fill Anything模型
mkdir -p stabilityai/stable-diffusion-2-inpainting模型下载地址:huggingface地址,下载完成后,存放到上面的目录中
(3)Remove Anything Video模型
模型下载地址:sttn模型, sttn模型文件移动到pretrained_models目录下,
mkdir -p pytracking/pretrain模型下载地址:osTrack模型,下载完成后,存放到上面的目录中
3 Inpaint Anything运行效果展示
3.1 Remove Anything
(1)通过指定坐标点移除物体
python remove_anything.py \
--input_img ./example/remove-anything/dog.jpg \
--coords_type key_in \
--point_coords 200 450 \
--point_labels 1 \
--dilate_kernel_size 15 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth \
--lama_config ./lama/configs/prediction/default.yaml \
--lama_ckpt ./pretrained_models/big-lama运行成功后,结果存放在result目录下。




(2)通过点击移除物体
python remove_anything.py \
--input_img ./example/remove-anything/dog.jpg \
--coords_type click \
--point_coords 200 450 \
--point_labels 1 \
--dilate_kernel_size 15 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth \
--lama_config ./lama/configs/prediction/default.yaml \
--lama_ckpt ./pretrained_models/big-lama此中方式需要有显示器展示和操作
3.2 Fill Anything
通过指定坐标点和Prompt填充物体
python fill_anything.py \
--input_img ./example/fill-anything/sample1.png \
--coords_type key_in \
--point_coords 750 500 \
--point_labels 1 \
--text_prompt "a teddy bear on a bench" \
--dilate_kernel_size 50 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pthText prompt: "a teddy bear on a bench"





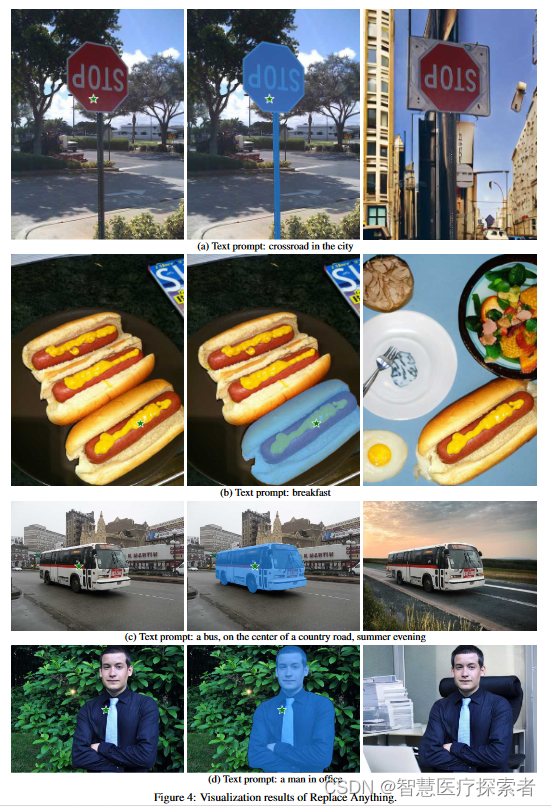
3.3 Replace Anything
通过指定坐标点和Prompt替换物体
python replace_anything.py \
--input_img ./example/replace-anything/dog.png \
--coords_type key_in \
--point_coords 750 500 \
--point_labels 1 \
--text_prompt "sit on the swing" \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pthText prompt: "a man in office"





3.5 Remove Anything Video
python remove_anything_video.py \
--input_video ./example/video/paragliding/original_video.mp4 \
--coords_type key_in \
--point_coords 652 162 \
--point_labels 1 \
--dilate_kernel_size 15 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth \
--lama_config lama/configs/prediction/default.yaml \
--lama_ckpt ./pretrained_models/big-lama \
--tracker_ckpt vitb_384_mae_ce_32x4_ep300 \
--vi_ckpt ./pretrained_models/sttn.pth \
--mask_idx 2 \
--fps 25以下案例都是视频文件的移除展示:



4 总结
Inpaint Anything (IA)是一款多功能工具,结合了Remove Anything、Fill Anything和Replace Anything的功能。基于分割模型、SOTA修复模型和AIGC模型,IA能够实现无需遮罩的图像修复,并支持用户友好的操作方式,即“点击删除,提示填充”。
此外,IA可以处理各种不同的高质量输入图像,包括任意宽高比和2K分辨率。这个项目充分利用现有的大规模AI模型的强大能力,并展示了“可组合AI”的潜力。在未来,Inpaint Anything (IA)将进一步开发,以支持更多的实用功能,如细粒度图像抠像、编辑等,并将其应用于更多现实应用中。