层次遍历简介
广度优先在面试里出现的频率非常高,整体属于简单题。而广度优先遍历又叫做层次遍历,基本过程如下:
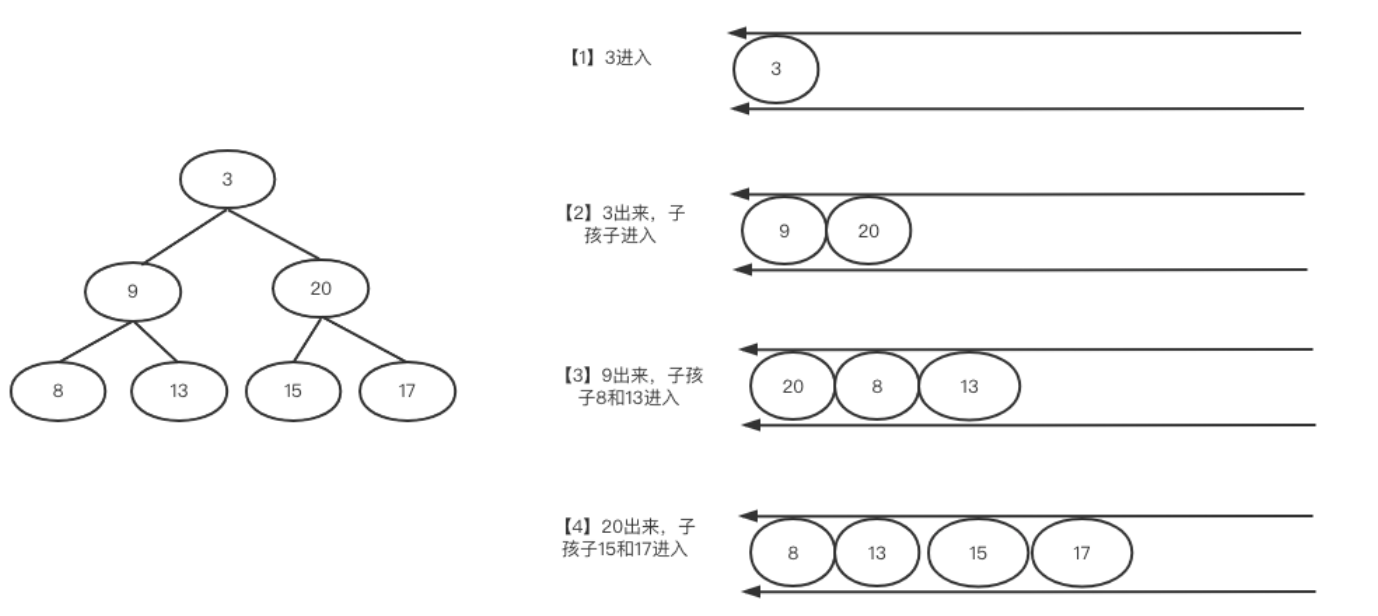
层次遍历就是从根节点开始,先访问根节点下面一层全部元素,再访问之后的层次,类似金字塔一样,逐层访问。我们可以看到上面例子就是从左到右一层一层遍历二叉树,先访问3,之后访问1的左右孩子9和10,之后分别访问9和20的左右孩子[4,5]和[6,7] ,最后得到结果[3,9,20,8,13,15,7]
这里需要关注的问题是:将遍历过的元素的左右孩子保存起来。例如:访问9时,其左右孩子8和13应该先保存一下,直到处理20之后才会处理。使用队列就是一个比较好的方法。
以上图为例,过程如下
- 先将3入队(使用链表实现的队列)
- 然后3出队,接着将3的左右孩子9和10 保存在队列中
- 然后9 出队,将9的左右孩子8和13入队
- 接着20出队,将15和7入队
- 最后8 13 15 7 分别出队,此时都是叶子节点了,没有入队的元素了。
拓展
如果能将树的每层次分开了,是否可以整点新花样?
首先,能否将每层的元素顺序给反转一下呢?
能否奇数行不变,只将偶数行反转呢?
能否将输出层次从低到root逐层输出呢?
再来,既然能拿到每一层的元素了,能否找到当前层最大的元素? 最小的元素? 最右的元素(右视图)? 最左的元素(左视图) ? 整个层的平均值?
而以上问题就是经典的层次遍历题。
题号如下
102.二又树的层序遍历
107.二又树的层次遍历lIl
199.二又树的右视图
637.二又树的层平均值
429.N又树的前序遍历
515.在每个树行中找最大值
116.填充每个节点的下一个右侧节点指针
117.填充每个节点的下一个右侧节点指针Il
103 锯齿层序遍历
基本的层序遍历与变换
题目
遍历并输出全部元素,二叉树示例如下:
* 3 * / \ * 9 20 * / \ * 15 7
代码实现思路
先访问根节点,然后将其左右孩子放到队列里,接着继续出队列;出来的元素,将其左右孩子放入队列中,直到队列为空了才退出来。
代码实现
节点代码
public TreeNode{
public int data;
public TreeNode left;
public TreeNode right;
public TreeNode(int data){
this.data = data;
}
}实现代码
public List<Integer> simpleLevelTraverse(TreeNode root){
// 创建一个数组实现的集合接收遍历后的结果
List<Integer> res = new ArrayList<>();
// 如果该树是一颗空树,返回空的集合
if(root == null){
return res;
}
// 使用链表当做队列,用于存储树的节点
// 从尾插入,从头删除
LinkedList<TreeNode> queue = new LinkedList<>();
// 将根节点放入队列中,然后不断遍历根节点
queue.add(root);
// 有多少元素就遍历多少次
while(queue.size() > 0){
// remove():获取并移除此队列的头(第一个元素)
TreeNode t = queue.remove();
// 使用集合搜集遍历后的节点数据部分
res.add(t.data);
// 如果该节点有左节点(不为空),则将其加入队列中,用于下次遍历
if(t.left != null){
queue.add(t.left);
}
// 如果该节点有右节点(不为空),则将其加入队列中,用于下次遍历
if(t.right != null){
queue.add(t.right);
}
}
// 返回遍历后的结果
return res;
}根据树的结构可以看到,一个节点在一层访问之后,其子孩子都是在下一层按照FIFO的顺序处理的,因此,队列就相当于一个缓冲区。这题是逐层自左向右执行的,如果将每层的元素分开打印,便有了另一种题目。
二叉树的层序遍历(每层元素分开打印)
题目
给你一个二叉树,请你返回其按照程序遍历得到的节点值。(即逐层从左到右遍历)
示例
* 二叉树:[3,9,20,null,null,15,7]
* 3
* / \
* 9 20
* / \
* 15 7
* 返回后程序遍历结果
* [
* [3],
* [9,20],
* [15,7]
* ]
解析
此题依旧可以使用队列存储每一层的节点。但题目要求逐层节点打印,那就需要考虑某一层是否访问完。针对这个问题,可以使用一个变量size标记一下某一层的元素个数,只要出队列一个节点,就将size的值减1,减到0,说明该层元素访问完了(当然,也可以从0开始遍历,遍历到size个的时候(i < size)就说明这一层的节点都访问过了),然后重新将size标记为下一层节点的个数,继续执行(因此,size需要在循环中创建)。
对于结果集,可以看作外层一个集合(用于存储层数),里面一层集合(用于存储每一层的节点值)
代码实现
public List<List<Integer>> getEveryLevelNodeFromTop(TreeNode root){
List<List<Integer>> res = new ArrayList<List<Integer>>>();
if(root == null){
return res;
}
LinkedList<TreeNode> queue = new LinkedList<>();
queue.add(root);
while(queue.size()>0){
List<Integer> temp = new ArrayList<>();
int size = queue.size();
for(int i = 0 ; i < size ; i++){
TreeNode t = queue.remove();
temp.add(t.data);
if(t.left != null){
queue.add(t.left);
}
if(t.right != null){
queue.add(t.right);
}
}
res.add(temp);
}
return res;
}重要性
上面的代码是整个算法体系的核心算法之一,与链表反转、二分查找属于同一个级别!
层序遍历(自底向上)
题目
给定一个二叉树,返回其节点值自底向上的层序遍历。(即:按从叶子节点所在层到根节点所在的层,逐层自左向右遍历)
* 3 * / \ * 9 20 * / \ * 15 7
示例
[
[15,7],
[9,20],
[3]
]
分析
如果要求从上到下输出每一层的节点值,做法是很直观的。在遍历完一层节点之后,将存储该层节点值的列表添加到结果列表的尾部。这道题要求从下到上输出每一层的节点值,只要对上述操作稍作修改即可在遍历完一层节点之后,将存储该层节点值的列表添加到结果列表的头部。
为了降低在结果列表的头部添加一层节点值的列表的时间复杂度,结果列表可以使用链表的结构,在链表头部添加一层节点值的列表的时间复杂度是 O(1)。在 Java 中,由于我们需要返回的 List 是一个接口,这里可以使用链表实现。
代码实现
public List<List<Integer>> getEveryNodeFromBottom(TreeNode root){
List<List<Integer>> res = new LinkedList<List<Integer>>();
if(root == null){
return res;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(! queue.isEmpty()){
List<Integer> temp = new ArrayList<>();
int size = queue.size();
for(int i = 0 ; i < size ; i++){
TreeNode t = queue.pull();
temp.add(t.data);
TreeNode left = t.left , right = t.right;
if(left != null){
queue.offer(left);
}
if(right != null){
queue.offer(right);
}
}
// 栈结构:将先进入结果集的集合放入后面
res.add(0,temp);
}
return res;
}二叉树的锯齿形遍历
题目
给定一个二叉树,返回其节点值的锯齿形层序遍历(即:先从左往右,再从右往左进行下一层遍历。以此类推,层与层之间交替执行)
* 3 * / \ * 9 20 * / \ * 15 7
示例
[
[3],
[20,9],
[15,7]
]
分析
这个题与之前的区别只是最后输出的要求有所变化,要求我们按层数的奇偶来决定每一层的输出顺序如果当前层数是偶数,从左至右输出当前层的节点值,否则,从右至左输出当前层的节点值。为了满足题目要求的返回值为[先从左往右,再从右往左]交替输出的锯齿形,可以利用[双端队列,的数据结构来维护当前层节点值输出的顺序。双端队列是一个可以在队列任意一端插入元素的队列。在广度优先搜索遍历当前层节点拓展下一层节点的时候我们仍然从左往右按顺序拓展,但是对当前层节点的存储我们维护一个变量 isOrderLeft 记录是从左至右还是从右至左的:
如果从左至右,我们每次将被遍历到的元素插入至双端队列的末尾。
从右至左,我们每次将被遍历到的元素插入至双端队列的头部。
代码实现
/**
* 给定一个二叉树,返回其节点值的锯齿形层序遍历(即:先从左往右,再从右往左进行下一层遍历。以此类推,层与层之间交替执行)
* @param root 树的根节点
* @return 交替执行的遍历结果
*/
public List<List<Integer>> levelOrderBetweenLeftAndRight(TreeNode root){
LinkedList<List<Integer>> res = new LinkedList<List<Integer>>();
if (root == null){
return res;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
boolean isOrderLeft = true;
while (!queue.isEmpty()){
Deque<Integer> levelLeft = new LinkedList<Integer>();
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode curNode = queue.remove();
if (isOrderLeft){
levelLeft.offerLast(curNode.data);
}else {
levelLeft.offerFirst(curNode.data);
}
if (curNode.left != null){
queue.add(curNode.left);
}
if (curNode.right != null) {
queue.add(curNode.right);
}
}
res.add(new LinkedList<>(levelLeft));
isOrderLeft = !isOrderLeft;
}
return res;
}层次遍历(N叉树)
题目
给定一个 N 又树,返回其节点值的层序遍历。 (即从左到右,逐层遍历)树的序列化输入是用层序遍历,每组子节点都由 null 值分隔 (参见示例)。
示例
输入: root = [1,null,3,2,4,nu11,5,6](表述树的元素是这个序列)
输出: [[1],[3,2,4],[5,6]]
代码实现
N叉树代码
class MutilTreeNode {
public int data ;
public List<MutilTreeNode> children;
}实现
public List<List<Integer>> nLevelOrder(MutilTreeNode root){
ArrayList<List<Integer>> res = new ArrayList<>();
Deque<MutilTreeNode> deque = new LinkedList<>();
if (root != null){
//Java中的java.util.LinkedList.addLast()方法用于在LinkedList的末尾插入特定元素。
deque.addLast(root);
}
while (! deque.isEmpty()){
ArrayList<Integer> nd = new ArrayList<>();
ArrayDeque<MutilTreeNode> next = new ArrayDeque<>();
while (! deque.isEmpty()){
MutilTreeNode cur = deque.pollFirst();
nd.add(cur.data);
for (MutilTreeNode child : cur.children) {
if (child != null){
next.add(child);
}
}
deque = next;
res.add(nd);
}
}
return res;
}