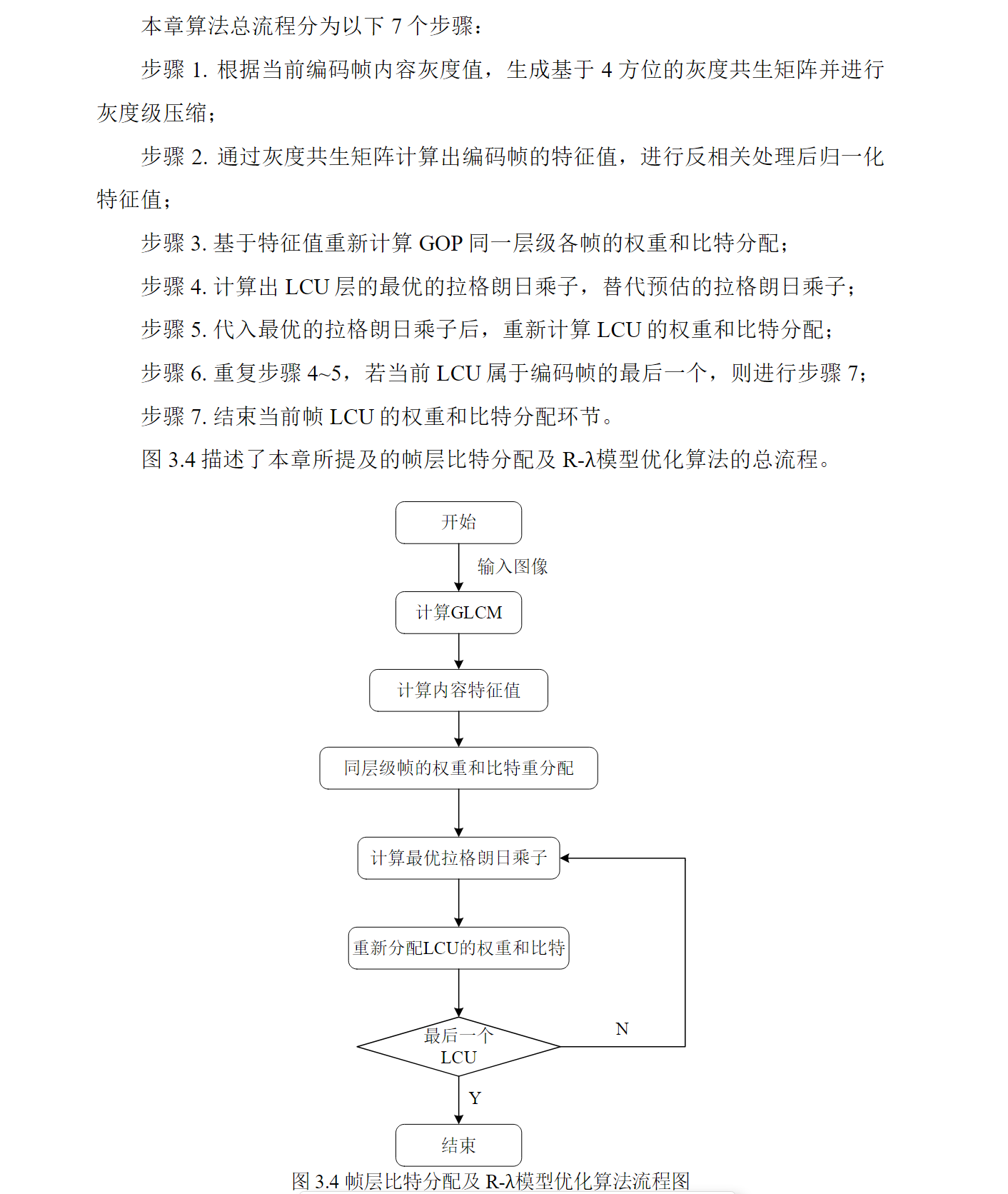
参考Linux 下Coredump分析与配置
在做项目的时候,很容易遇到“段错误(核心已转储)”的问题。如果是语法错误还可以很快排查出来问题,但是碰到coredump就没办法直接找到问题,可以通过设置core文件来查找问题,直接定位到出问题的行号,十分方便。
什么是coredump
Core是内存的意思,当程序运行过程中检测到异常程序异常退出的时候,系统就会把程序当前的内存状况存储在一个core文件中,叫做coredumoed也就是信息转储,操作系统检测到当前进程异常时将通过信号的方式通知目标进程相应的错误信息比如我遇到的问题就是SIGSEGV信号(进程进行了一次无效的内存引用,不正确的内存处理)
配置core
- 在跟目录下面建立一个储存coredump文件的文件夹(最好是在根目录下面,不然有可能之后会有权限不够的问题)
mkdir /corefile
- 设置产生coredump文件的大小
- 首先使用ulimit -a查看,core file是0的话这个时候就没有办法写core文件,所以要先设置大小
- 早corefile文件中输入
ulimit -c unlimited,设置大小之后最好不要关闭当前窗口,不然打开新窗口的时候core文件大小可能又变成0了 - 执行以下两条命令:
echo "1" > /proc/sys/kernel/core_uses_pid //将1写入到该文件里
echo "/corefile/core-%e-%p-%t" > /proc/sys/kernel/core_pattern
- 修改配置文件
vim /etc/profile
添加ulimit -S -c unlimited > /dev/null 2>&1
执行命令使其生效
source /etc/profile
- 机器重启的时候清空corefile
因为coredump文件很大会占用硬盘,所以在配置文件/etc/rc.local中最后面添加命令rm -rf /corefile/*,机器重启的时候清空这个文件夹 - 再执行以下两条命令
echo "1" > /proc/sys/kernel/core_uses_pid
echo "/corefile/core-%e-%p-%t" > /proc/sys/kernel/core_pattern
测试
- 在编译程序或者项目的时候,一定要加上-g,不然之后通过gdb查看问题的时候不会显示出错的地方的行号
- 运行程序,出现“段错误核心已转储”,然后去corefile文件,命令行输入
ll,出现如下结果

- 运行gdb阅读core文件
gdb 程序路径 对应的coredump文件
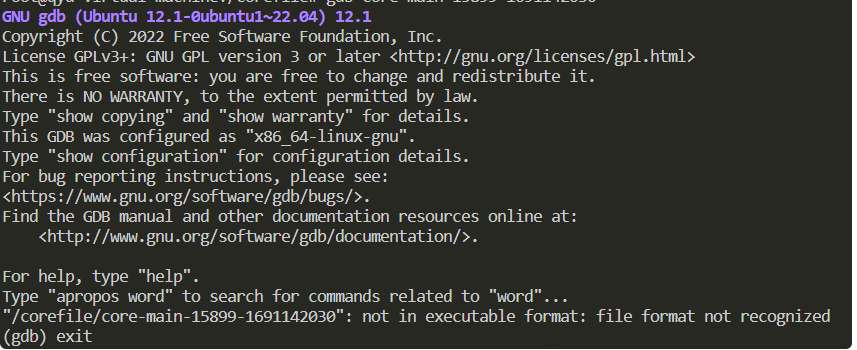
- 如果命令输入不正确就会显示如下图
gdb运行的时候没有输入这个程序路径:
编译的时候没有加参数-g:

- gdb运行成功:会显示出问题的行号,通过bt或者where看到函数调用栈情况
经过问题排查,发现我是因为错误使用内存,所以编写代码的时候要注意细节,如果出现问题要擅长通过gdb调试、core文件排查、解决问题。
![SSM(Vue3+ElementPlus+Axios+SSM前后端分离)--搭建Vue 前端工程[一]](https://img-blog.csdnimg.cn/img_convert/43e0cc595418c536362a57e2dd1fc6bd.png)