前置问题
关于分布式,可能是系统、网络等问题我最终还是取消掉了,下面这些尝试使用分布式时报的错姑且记录一下。。。
##############################
module ‘distutils’ has no attribute ‘version’
pip install setuptools==59.5.0
No module named ‘_distutils_hack’
安装setuptools时可能会提示这么一句,那就打开提示中的\lib\site-packages\distutils-precedence.pth,在“import os;”后面加个回车即可
缺包wandb einops
安就完了,奥利给
ValueError: Error initializing torch.distributed using env:// rendezvous: environment variable *** expected, but not set
之前跑gaitedge时也出过这种问题,好像是关于分布式的配置,当时用的小破笔记本所以这些关于多线程的全部取消掉了
os.environ['RANK'] = '0'
os.environ['WORLD_SIZE'] = '2'# =torch.cuda.device_count()
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '35632'
RuntimeError: Distributed package doesn’t have NCCL built in
好像是因为win不支持NCCL
所以还是参考之前的做法替换一下
torch.distributed.init_process_group("gloo")
#############################
首先对比一下yaml配置
因为输入是pkl文件,所以和gaitgl对比
1.学习率
gaitgl是经典的1e-4,而MetaGait是3.5e-4
2.scheduler
#gaitgl
scheduler_cfg:
gamma: 0.1
milestones:
- 70000
scheduler: MultiStepLR
#metagait
scheduler_cfg:
gamma: 0.1
milestones:
- 80000
- 100000
scheduler: warmup
warmup_iters: 10000
warmup_factor: 0.01
具体调用时
self.scheduler = WarmupMultiStepLR(optimizer=self.optimizer, milestones=cfgs['scheduler_cfg']['milestones'], warmup_iters=cfgs['scheduler_cfg']['warmup_iters'], warmup_factor=cfgs['scheduler_cfg']['warmup_factor'])
MultiStepLR其实就是每逢70000这样一个milestones,当前学习率就要乘以gamma
而WarmupMultiStepLR通过 _get_warmup_factor_at_iter 函数计算预热因子
if iter >= warmup_iters: #10000
return 1.0
if method == "constant":
return warmup_factor #0.01
elif method == "linear": #没给,那就是默认的Linear
alpha = iter / warmup_iters
return warmup_factor * (1 - alpha) + alpha
else:
raise ValueError("Unknown warmup method: {}".format(method))
warmup factor
=
warmup factor
×
(
1
−
i
t
e
r
warmup iters
)
+
i
t
e
r
warmup iters
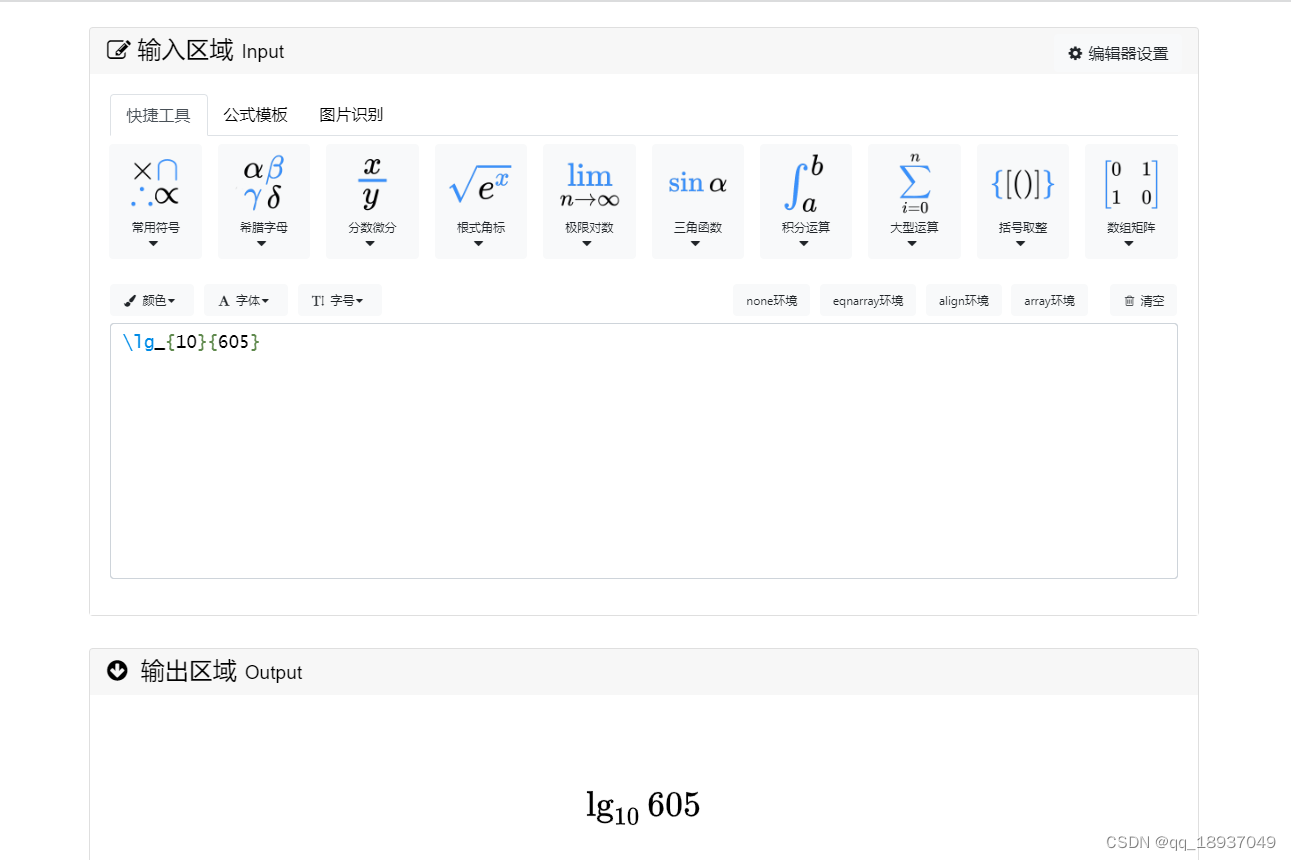
\text{warmup factor}=\text{warmup factor}×(1−\frac{iter}{\text{warmup iters}})+\frac{iter}{\text{warmup iters}}
warmup factor=warmup factor×(1−warmup itersiter)+warmup itersiter
然后根据阶段性的milestones和gamma计算实际学习率。
[base_lr * warmup_factor * self.gamma ** bisect_right(self.milestones, self.last_epoch)
for base_lr in self.base_lrs]
lr multi step = base lr × warmup factor × g a m m a bisect right ( m i l e s t o n e s , last epoch ) \text{lr multi step}=\text{base lr}\times \text{warmup factor}\times gamma^{\text{bisect right}(milestones,\text{last epoch})} lr multi step=base lr×warmup factor×gammabisect right(milestones,last epoch)
bisect_right用于在有序序列中找到某个值应该插入的位置,同时保持序列的有序性。具体来说,bisect_right返回一个索引,该索引是在有序序列中查找插入某个元素后,保持有序状态的最右侧位置。
在给定有序序列 a 中,bisect_right(a, x) 将找到元素 x在序列中应该插入的位置,并返回一个索引,以确保插入后序列仍然保持有序。如果 x 已经存在于序列中,该函数将返回在最右侧出现的位置。
例如,考虑以下代码:
from bisect import bisect_right a = [1, 3, 5, 7, 9] x = 6 index = bisect_right(a, x) print(f"Index to insert {x}: {index}")在这个例子中,x 的值是 6,而有序序列 a 是 [1, 3, 5, 7, 9]。bisect_right(a, x) 将返回值 3,因为将元素 6 插入到位置 3 后,序列仍然保持有序。所以,这个函数在这里返回的索引是插入位置的索引。
在你提供的代码中,bisect_right 的使用是为了找到阶段性里程碑(milestones)列表中最接近 last_epoch 的值的位置,从而确定应该应用哪个学习率衰减因子。
——ChatGPT
3.学习轮次起码120000,gaitgl是经典的80000
开始debug
一、首先类似地通过dataset取数据
例如首先读取的是data_list(5, 64, 64)的uint8的pkl(这里5是对应的总帧数,例如下一个就是108了),seq_info['037', 'bg-02', '018', ['datasets/CASIA-B-pkl\\037\\bg-02\\018\\018.pkl']]
(因为突然有些懵逼这个只有5帧的id是怎么在后面整出来30帧的,所以再研究一下sampler)
训练
'sampler': {
'batch_shuffle': True,
'batch_size': [8, 8],
'frames_num_fixed': 30,
'frames_num_max': 50,
'frames_num_min': 25,
'sample_type': 'fixed_ordered',
'type': 'TripletSampler',
'frames_skip_num': 0}
测试
{'batch_size': 1,
'sample_type': 'all_ordered',
'type': 'InferenceSampler'}
二、接着预处理inputs
# TripletSampler.__iter__
while True:
sample_indices = []
pid_list = sync_random_sample_list(
self.dataset.label_set, self.batch_size[0])
# 从训练的总74类id中取出8类id作为当前batch
for pid in pid_list:
indices = self.dataset.indices_dict[pid]
indices = sync_random_sample_list(
indices, k=self.batch_size[1])
sample_indices += indices
# 遍历每一个ID
# 从id对应的样本索引(包括10种属性、11种角度的pkl,
# 所以基本上都是110个pkl
# 有的不够是因为他有些视角下原本没有帧样本,被跳过去了)
# 中取出8个作为当前batch
if self.batch_shuffle:
sample_indices = sync_random_sample_list(
sample_indices, len(sample_indices))
total_batch_size = self.batch_size[0] * self.batch_size[1]
total_size = int(math.ceil(total_batch_size /
self.world_size)) * self.world_size
sample_indices += sample_indices[:(
total_batch_size - len(sample_indices))]
sample_indices = sample_indices[self.rank:total_size:self.world_size]
yield sample_indices
# CollateFn.__call__
batch_size = len(batch)
# 此时的batch是bs个tuple组成的list(也就对应之前的bs=64个pkl)
# tuple第二项是id、属性、角度、[pkl路径]
# tuple第一项是(_, 64, 64)的numpy
# 其中_就表示原本这个视角下有多少帧的图像
feature_num = len(batch[0][0])
# 有注释说这里就是单纯的1,除非后续兼容了二值图或者骨架建模什么的
seqs_batch, labs_batch, typs_batch, vies_batch = [], [], [], []
for bt in batch:
seqs_batch.append(bt[0])
labs_batch.append(self.label_set.index(bt[1][0]))
typs_batch.append(bt[1][1])
vies_batch.append(bt[1][2])
global count
count = 0
def sample_frames(seqs):
global count
sampled_fras = [[] for i in range(feature_num)]
seq_len = len(seqs[0])
indices = list(range(seq_len))
if self.sampler in ['fixed', 'unfixed']:
if self.sampler == 'fixed':
frames_num = self.frames_num_fixed
else:
frames_num = random.choice(
list(range(self.frames_num_min, self.frames_num_max+1)))
if self.ordered:
fs_n = frames_num + self.frames_skip_num
# 30
if seq_len < fs_n:
# 例如前面质疑过的只有5帧的这一个样本
it = math.ceil(fs_n / seq_len)
# 通过进一让扩充后的帧序列绰绰有余
# 扩充其实就有点像重复寻址,不过是让索引拷贝了几份
# 但是其实顺序取帧主要不就是要学习这个人有时序的动作步态
# 这里重复的头接上一周期的尾
# 这样的衔接不就会造成错误的步态时序吗
# 不如直接当做噪声去除
seq_len = seq_len * it
indices = indices * it
start = random.choice(list(range(0, seq_len - fs_n + 1)))
# 随机选取一个起始点
# 保证从这开始往后能够取到30帧
end = start + fs_n
idx_lst = list(range(seq_len))
idx_lst = idx_lst[start:end]
idx_lst = sorted(np.random.choice(
idx_lst, frames_num, replace=False))
# 为什么前面已经通过start:end]截取到了30帧,这里却还要随机选取?
# 大概是因为前面其实还涉及到一个self.frames_skip_num
# 使得选取帧之间还会有些跳帧
# 不过不是均匀跳帧,只是多了一些备选帧罢了
# 这里就相当于一个shuffle吧,然后再排回原来的顺序
indices = [indices[i] for i in idx_lst]
else:
replace = seq_len < frames_num
if seq_len == 0:
get_msg_mgr().log_debug('Find no frames in the sequence %s-%s-%s.'
% (str(labs_batch[count]), str(typs_batch[count]), str(vies_batch[count])))
count += 1
indices = np.random.choice(
indices, frames_num, replace=replace)
for i in range(feature_num):
for j in indices[:self.frames_all_limit] if self.frames_all_limit > -1 and len(indices) > self.frames_all_limit else indices:
sampled_fras[i].append(seqs[i][j])
return sampled_fras
# 存储成为[30个(60,60)的numpy]
# f: feature_num
# b: batch_size
# p: batch_size_per_gpu
# g: gpus_num
fras_batch = [sample_frames(seqs) for seqs in seqs_batch] # [b, f]
# [64个[30个(60,60)的numpy]]
batch = [fras_batch, labs_batch, typs_batch, vies_batch, None]
if self.sampler == "fixed":
fras_batch = [[np.asarray(fras_batch[i][j]) for i in range(batch_size)]
for j in range(feature_num)] # [f, b]
# 相当于把第二维那个对应feature_num=1的维度转置到最外面
else:
seqL_batch = [[len(fras_batch[i][0])
for i in range(batch_size)]] # [1, p]
def my_cat(k): return np.concatenate(
[fras_batch[i][k] for i in range(batch_size)], 0)
fras_batch = [[my_cat(k)] for k in range(feature_num)] # [f, g]
batch[-1] = np.asarray(seqL_batch)
batch[0] = fras_batch
return batch
# 然后再反压,就很奇怪的多余
取到64个(8类,每类8个),对应inputs[0]是64个(30, 64, 64)->seq;inputs[1]是64个id->lab;inputs[2]是64个属性类型->typ;inputs[3]是64个角度->vie;inputs[4]是None->seqL
三、输入网络
ipts-》[torch.Size([64, 30, 64, 44])]
labs
typs
vies
seqL
把ipts反压成sils-》torch.Size([64, 1, 30, 64, 44])
MetaGait(
####### gaitgl有的部分 #########
(conv3d): Sequential(
(0): BasicConv3d(
(conv3d): Conv3d(1, 32, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
)
(1): LeakyReLU(negative_slope=0.01, inplace=True)
)
(LTA): Sequential(
(0): BasicConv3d(
(conv3d): Conv3d(32, 32, kernel_size=(3, 1, 1), stride=(3, 1, 1), bias=False)
)
(1): LeakyReLU(negative_slope=0.01, inplace=True)
)
(GLConvA0): GLConv(
(global_conv3d): BasicConv3d(
(conv3d): Conv3d(32, 64, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
)
(local_conv3d): BasicConv3d(
(conv3d): Conv3d(32, 64, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
)
)
(MaxPool0): MaxPool3d(kernel_size=(1, 2, 2), stride=(1, 2, 2), padding=0, dilation=1, ceil_mode=False)
(GLConvA1): GLConv(
(global_conv3d): BasicConv3d(
(conv3d): Conv3d(64, 128, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
)
(local_conv3d): BasicConv3d(
(conv3d): Conv3d(64, 128, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
)
)
(GLConvB2): GLConv(
(global_conv3d): BasicConv3d(
(conv3d): Conv3d(128, 128, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
)
(local_conv3d): BasicConv3d(
(conv3d): Conv3d(128, 128, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
)
)
###############################
此时有outs-》torch.Size([64, 128, 10, 64, 22])
(eca): LocalAttention(
(avg_pool): AdaptiveAvgPool3d(output_size=(1, 1, 1))#自适应降维到给定尺寸
得到weight-》torch.Size([64, 128, 1, 1, 1])
(dynamic_conv): MHN(输入weight
先mean(dim=[2,3,4], keepdim=True),但效果其实相当于没处理
(reduce): Conv3d(128, 16, kernel_size=(1, 1, 1), stride=(1, 1, 1))
得到x_gap-》torch.Size([64, 16, 1, 1, 1])
(wn_fc1): Conv3d(16, 6, kernel_size=(1, 1, 1), stride=(1, 1, 1))
得到x_w-》torch.Size([64, 6, 1, 1, 1]),做sigmoid
(wn_fc2): Conv3d(6, 384, kernel_size=(1, 1, 1), stride=(1, 1, 1), groups=6, bias=False)
得到x_w-》torch.Size([64, 384, 1, 1, 1])
(conv3d_sample_by_sample):
如果weight的bs为1(也就是test):
先把x_w给view成(3,128,1,1,1)
out=F.conv3d(weight,weight=x_w,stride=(1,1,1),padding=(0,0,0),groups=1)#groups对应分组卷积
否则:
先把weight给view成(1,-1,weight.shape[2], weight.shape[3],weight.shape[4])也即torch.Size([1, 8192, 1, 1, 1])
把x_w给view成(bs*3,128,1,1,1)也即torch.Size([192, 128, 1, 1, 1])
out=F.conv3d(weight,weight=x_w,stride=(1,1,1),padding=(0,0,0),groups=1*bs)
得到weight-》torch.Size([1, 192, 1, 1, 1])再view成torch.Size([64,3, 1, 1, 1])
)
(avg_pool): AdaptiveAvgPool3d(output_size=(1, 1, 1))#自适应降维到给定尺寸
再对x做一次后经过压缩,再做einops.rearrange得到y-》torch.Size([64,1, 128])#这个爱因斯坦函数其实就相当于transpose、view或permute吧
(conv1): Conv1d(1, 1, kernel_size=(1,), stride=(1,), bias=False)
输入y得到y1-》torch.Size([64,1, 128])
(conv3): Conv1d(1, 1, kernel_size=(3,), stride=(1,), padding=(1,), bias=False)
输入y得到y3-》torch.Size([64,1, 128])
(conv5): Conv1d(1, 1, kernel_size=(5,), stride=(1,), padding=(2,), bias=False)
输入y得到y5-》torch.Size([64,1, 128])
三个分别einops.rearrange再反压得到torch.Size([64, 128, 1, 1, 1])
(sigmoid): Sigmoid()分别
对weight的第1维正好分三份有weight1~weight3
计算x * y1 * weight1 + x * y5 * weight2 + x * y3 * weight3返回outs1->torch.Size([64, 128, 10, 64, 22])
)
(se): SELayer(
还是输入outs-》torch.Size([64, 128, 10, 64, 22])
(avg_pool): AdaptiveAvgPool3d(output_size=(1, 1, 1))
再压缩得到y->torch.Size([64, 128])
(fc): Sequential(
(0): Linear(in_features=128, out_features=128, bias=False)
(1): LeakyReLU(negative_slope=0.01, inplace=True)
(2): Linear(in_features=128, out_features=128, bias=False)
(3): Sigmoid()
)再反压得到torch.Size([64, 128, 1, 1, 1])
)返回outs2=outs*y-》torch.Size([64, 128, 10, 64, 22])
outs = outs1 + outs2
(TP): PackSequenceWrapper()
# 参数和gaitgl不太一样
#MetaGait:
#outs = self.TP(outs, dim=2, seq_dim=2, seqL=seqL)[0]
#gaitgl:
#outs = self.TP(outs, seqL=seqL, options={"dim": 2})[0]
# 不过看本质应该都是一样的最大池化,维度也都是2
得到outs-》torch.Size([64, 128, 64, 22])
(HPP): GeMHPP()
得到outs-》torch.Size([64, 128, 64])
随后又与gaitgl不同的是
经过permute得到得到outs-》torch.Size([64, 64, 128])
(Head0): SeparateFCs()
其实就是单独乘一个权重矩阵
得到gait-》torch.Size([64, 64, 128])
再次与gaitgl不同的是
gait被permute成torch.Size([64, 128, 64])后直接执行bn和head1
(Bn): SyncBatchNorm(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
得到bnft后再permute成torch.Size([64, 64, 128])后直接给head1
(Head1): SeparateFCs()
得到logi-》torch.Size([64, 64, 74])
最后写进retval的bnft被permute成torch.Size([64, 64, 128])
#原本输入给head1的是2,0,1
#这里是0,2,1
logi也1,0,2permute成torch.Size([64, 64, 74])
#也就是前两维的64调换顺序
)
training_feat:
triplet:
embeddings: torch.Size([64, 64, 128])
labels: torch.Size([64])
softmax:
logits: torch.Size([64, 64, 74])
labels: torch.Size([64])
visual_summary:
image/sils: torch.Size([1920, 1, 64, 44])
inference_feat:
embeddings: torch.Size([64, 64, 128])
输出结构和gaitgl一致
局部依赖
MHN
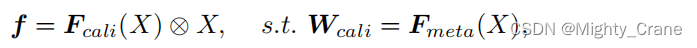
本质就是构造一个映射Fmeta使得通过当前输入得到 Fcali的权重Wcali
于是代码中有eca中的avg_pool对输入x得到一个m
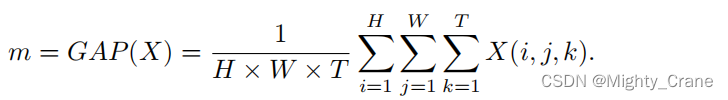
随后两次卷积(wn_fc)得到Wcali(不过代码中m还经过了一次名为reduce的卷积。也没有经历两次leakyrelu,而是一次sigmoid)
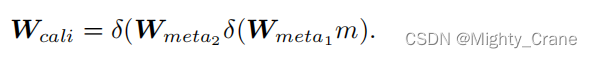
最后再直接F.conv3d得到flocal
MTA
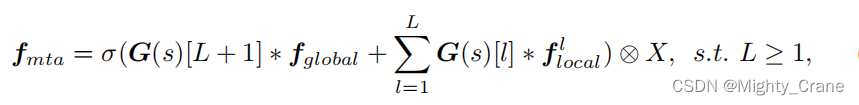
论文里是整体和局部一起的,代码里是分开的,其实就是
F
c
a
l
i
(
X
)
⨂
X
F_{cali}(X)\bigotimes X
Fcali(X)⨂X
这里局部的代码就是1、3、5三种尺度的门控卷积经过sigmoid得到对应的y,应该是对应公式里的G
局部依赖
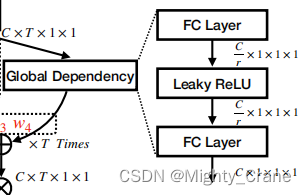
也就对应代码SE中的avg_pool后接两层FC,这里倒是有一层leakyrelu,最后还有一层sigmoid应该是对应上面MTA总公式里那个。最后的x*y也满足了全局这一部分的
F
c
a
l
i
(
X
)
⨂
X
F_{cali}(X)\bigotimes X
Fcali(X)⨂X
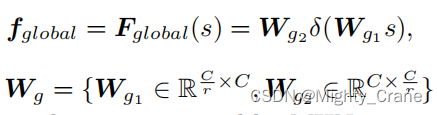
(不过论文里说Wg这俩也都是MHN自适应参数化得到的?代码里就是简单的模式化Linear啊。而且最后整体也没有最后的门控权重G,直接就和局部的结果求和了)
MTP
最后的加权池化,代码里其实就是和gaitgl一致的,没看出有什么并行分支,还是串行的最大池化TP、GeM广义平均池化(甚至不愿意加一个GAP)
看issue里说这应该不是完整的代码,所以whatever吧