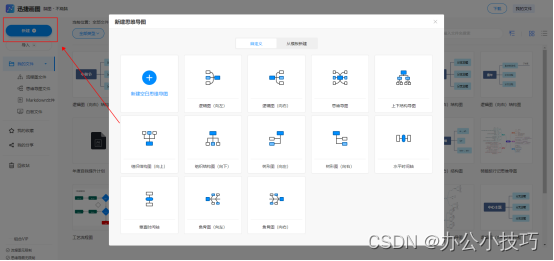
关于 ARTS 的释义 ——
每周完成一个 ARTS:
● Algorithm: 每周至少做一个 LeetCode 的算法题
●Review: 阅读并点评至少一篇英文技术文章
● Tips: 学习至少一个技术技巧
● Share: 分享一篇有观点和思考的技术文章
深度学习
- 深度学习
- 概念
- 崛起
- 框架

主页传送门:📀 传送
深度学习
概念
深度学习是机器学习领域的一个分支,它是一种基于人工神经网络的学习方法,旨在让计算机模仿人类大脑的神经
结构和学习方式,从大量数据中学习并提取高层次的抽象特征,从而实现对复杂问题的解决和预测。
深度学习中的"深度"指的是神经网络的层数,通常包含多个隐藏层。这些隐藏层会逐层处理输入数据,并通过权重和
偏置的调整来学习特征的表示。每一层的输出作为下一层的输入,这样多层堆叠在一起的结构使得神经网络可以学习更加复杂的
特征和模式。
深度学习在图像识别、自然语言处理、语音识别等领域取得了显著的成就,它广泛应用于计算机视觉、自然语言处
理、推荐系统、智能机器人等领域。深度学习的成功离不开大规模数据集的支持和计算能力的提升,特别是GPU和TPU等加速硬
件的应用,使得深度学习模型的训练变得更加高效。
崛起
从 2006 年开始至今,在这一时期研究者逐渐掌握了训练深层神经网络的方法,使得神经网络重新崛起.
[Hinton et al., 2006] 通过逐层预训练来学习一个深度信念网络, 并将其权重作为一个多层前馈神经网络的初始化权重,再用反向
传播算法进行精调.这种“预训练 + 精调”的方式可以有效地解决深度神经网络难以训练的问题.随着深度神经网络在语音识别
[Hinton et al., 2012]和图像分类[Krizhevsky et al.,2012]等任务上的巨大成功,以神经网络为基础的深度学习迅速崛起.近年来,
随着大规模并行计算以及 GPU 设备的普及,计算机的计算能力得以大幅提高.此外,可供机器学习的数据规模也越来越大.在
强大的计算能力和海量的数据规模支持下,计算机已经可以端到端地训练一个大规模神经网络,不再需要借助预训练的方式.各
大科技公司都投入巨资研究深度学习,神经网络迎来第三次高潮
框架
在深度学习中,一般通过误差反向传播算法来进行参数学习.采用手工方式来计算梯度再写代码实现的方式会非常低效,并且容易出错.此外,深度学习模型需要的计算机资源比较多,一般需要在CPU 和 GPU 之间不断进行切换,开发难度也比较大.因此,一些支持自动梯度计算、无缝CPU和GPU切换等功能的深度学习框架就应运而生.
比较有代表性的框架包括:Theano、Caffe、TensorFlow、Pytorch、飞桨(PaddlePaddle)、Chainer和MXNet等
- TensorFlow:由 Google 公司开发的深度学习框架,可以在任意具备CPU或者GPU的设备上运行.TensorFlow的计算过程使用数据流图来表示.TensorFlow 的名字来源于其计算过程中的操作对象为多维数组,即张量(Tensor).TensorFlow 1.0版本采用静态计算图,2.0 版本之后也支持动态计算图(在大规模分布式训练和部署方面优于其他)
- PyTorch:由 Facebook、NVIDIA、Twitter 等公司开发维护的深度学习框架,其前身为 Lua 语言的 Torch3.PyTorch 也是基于动态计算图的框架,在需要动态改变神经网络结构的任务中有着明显的优势.(对于初学者来说,PyTorch是一个非常友好和易于上手的深度学习框架)
- Theano:由蒙特利尔大学的 Python 工具包, 用来高效地定义、优化和计算张量数据的数学表达式.Theano 可以透明地使用 GPU 和高效的符号微分(PS:Theano 项目目前已停止维护.)
- Caffe:由加州大学伯克利分校开发的针对卷积神经网络的计算框架,主要用于计算机视觉.Caffe 用 C++ 和 Python 实现,但可以通过配置文件来实现所要的网络结构,不需要编码.
- 飞桨(PaddlePaddle):由百度开发的一个高效和可扩展的深度学习框架,同时支持动态图和静态图.飞桨提供强大的深度学习并行技术,可以同时支持稠密参数和稀疏参数场景的超大规模深度学习并行训练,支持千亿规模参数和数百个节点的高效并行训练.
- MindSpore5:由华为开发的一种适用于端边云场景的新型深度学习训练/推理框架.MindSpore为Ascend AI处理器提供原生支持,以及软硬件协同优化.
- Chainer6:一个最早采用动态计算图的深度学习框架,其核心开发团队为来自日本的一家机器学习创业公司 Preferred Networks.和 Tensorflow、Theano、Caffe 等框架使用的静态计算图相比,动态计算图可以在运行时动态地构建计算图,因此非常适合进行一些复杂的决策或推理任务.
- MXNet7:由亚马逊、华盛顿大学和卡内基·梅隆大学等开发维护的深度学习框架.MXNet支持混合使用符号和命令式编程来最大化效率和生产率,并可以有效地扩展到多个GPU和多台机器.
在这些基础框架之上,还有一些建立在这些框架之上的高度模块化的神经网络库,使得构建一个神经网络模型就像搭积木一样容易.其中比较有名的模块化神经网络框架有:
1)基于 TensorFlow 和 Theano 的 Keras(目前,Keras 已经被集成到TensorFlow 2.0版本中.)
2)基于 Theano的Lasagne;
3)面向图结构数据的DGL1
想了解更全面的深度学习框架可以参考wikipedia

如果喜欢的话,欢迎 🤞关注 👍点赞 💬评论 🤝收藏 🙌一起讨论 你的支持就是我✍️创作的动力! 💞💞💞