生信麻瓜的 ChatGPT 4.0 初体验
偷个懒,用ChatGPT 帮我写段生物信息代码
代码看不懂?ChatGPT 帮你解释,详细到爆!
如果 ChatGPT 给出的的代码不太完善,如何请他一步步改好?
全球最佳的人工智能系统可以通过难度较大的考试,写出有人类感染力的文章,还能和人类一样流畅地聊天,以至于很多人无法辨别它们的输出是否为人类所写。那么,它们不能做什么呢?解决简单的视觉逻辑谜题。
据研究人员在2023年5月发布的报告称,通过一系列排列在屏幕上的鲜艳彩色方块的测试,大多数人可以发现其中的连接模式。然而,ChatGPT和搜索引擎Bing的AI系统GPT-4在其中一个模式的谜题中仅答对了三分之一,而在另一个模式中仅有3%的正确率[1]。
逻辑谜题的研究团队旨在为评估AI系统的能力提供更好的基准,并帮助解决大型语言模型(LLM)如GPT-4所面临的难题。从某种程度上测试时,它们轻松通过了曾被视为机器智能的重要里程碑式的任务。但从另一种测试方式来看,它们似乎不那么出色,展现出明显的盲点和对抽象概念无法进行推理的局限。
“人工智能领域的人们正在努力解决如何评估这些系统的问题,”新墨西哥州圣达菲研究所计算机科学家Melanie Mitchell表示,她的团队创建了这些逻辑谜题。
到目前为止,人工智能系统在ConceptARC测试上还无法达到人类水平的表现。这个逻辑谜题要求解决者在观察多维度展示的抽象概念基础上,展示格网模式在解决者看到后会如何变化。以下是基于相同抽象概念的两个样本任务。你能解决它们吗?

**看看你都答对了吗?**

过去两三年中,大型语言模型(LLM)在多项任务的能力上远远超过了之前的人工智能系统。它们的工作原理是,在给定输入文本时,根据它们在数十亿条在线句子中训练出的单词之间的统计相关性生成合理的下一个单词。对于建立在LLMs上的聊天机器人来说,还有一个额外的因素:人类培训师提供了广泛的反馈来调整机器人的响应。
令人惊讶的是,这种基于自动补全算法是从海量人类语言的数据中训练得出,其功能应用广泛。其他AI系统可能在某一项任务上击败LLMs,但它们必须根据特定问题相关的数据进行训练,并且不能从一项任务推广到另一项任务。
两派系研究人员对LLMs内部工作机制持不同看法,哈佛大学认知科学家Tomer Ullman表示,其中一些研究人员认为LLMs的成就是基于一种推理或理解的算法。然而其他研究人员(包括他自己和Mitchell等研究人员)则持谨慎态度。
Ullman说:“争论双方都是非常优秀的人才。” 之所以出现分歧,是因为没有确凿的证据支持任何一种观点。Ullman补充说:“没有仪器可以向某物发出“滴滴声-是的,有智能”。
来自讨论双方的研究人员表示,像逻辑谜题这样揭示人类和人工智能系统能力差异的测试是朝着正确方向迈出的一步。这些基准还可以帮助揭示当今机器学习系统的局限性,并梳理人类智能的要素, 纽约大学的认知计算科学家Brenden Lake说道。
关于如何最好地测试LLMs以及这些测试所显示的内容的研究也有着实际意义。如果LLMs将被应用在现实世界的领域——从医学到法律——了解其能力的局限性是非常重要的,Mitchell说道,“我们必须了解它们能做什么和不能做什么,以便我们知道如何安全地使用它们。”
图灵测试过时了?
长期以来,最著名的机器智能测试是图灵测试,由英国数学家和计算领域的杰出人物Alan Turing在 1950 年提出,当时计算机还处于起步阶段。图灵提出了一个名为模拟游戏的评估方法[2]。评估中,人类考官与隐藏的计算机和一个看不见的人进行简短的、基于文本的对话。考官能否可靠地判断出哪台是电脑?这是一个相当于“机器能思考吗?”的问题,图灵建议道。
Mitchell提到,图灵并未指出该测试场景的具体细节,因此没有确切的标题可以回溯。“这并非是一个能在机器上运行的字面测试——它更像是一个思想实验,”谷歌的软件工程师François Chollet说,他常驻华盛顿州西雅图。
但是,利用语言来测试机器是否能够思考的想法依然存在。几十年来,商人和慈善家Hugh Loebner资助了一年一度的图灵测试活动,即勒布纳奖(Loebner Prize)。人类考官与机器和人进行基于文本的对话,并试图猜测哪个是哪个。但计算机科学家Rob Wortham说,由于Loebner已经去世,用于策划图灵测试的会议经费已用完,因此,年度会议在2019年之后便停止了。Rob Wortham是英国人工智能和行为模拟研究学会的联合主任,该学会从2014年开始代表Loebner主办比赛。他说,LLM现在很有可能在这样的比赛中愚弄人类;巧合的是,这些测试活动在LLM兴起前不久就结束了。
其他研究人员一致认为,GPT-4 和其他 LLM 可能会通过图灵测试的流行概念,甚至可以在简短的对话中愚弄很多人。2023年5月,以色列特拉维夫AI21 Labs公司的研究人员报告说,超过150万人玩过基于图灵测试的网络游戏。玩家被分配聊天两分钟,要么是另一个玩家,要么是表现得像人的LLM驱动的机器人。只有60%的玩家能正确识别机器人,研究人员指出,这个概率堪比偶然事件[3]。
然而,熟悉LLM的研究人员可能仍然可以赢得这种游戏。Chollet说,他发现通过利用系统的已知弱点很容易判断出LLM。“如果你让我处于这样一种境地,你问我,'我现在在和LLM聊天吗?我一定能告诉你,“Chollet说。
他说,关键是让LLM脱离舒适区。他建议用利用不同场景的数据来训练LLM。在许多情况下,LLM通过提取最有可能与其训练数据中的原始问题相关的单词来作答,而不是通过给出适用新场景的正确答案。
然而,Chollet和其他人对使用以欺骗为中心的测试作为计算机科学的目标持怀疑态度。“这一切都是为了欺骗评审团,”Chollet说。该测试激励聊天机器人开发人员让人工智能达成欺骗,而不是开发有用或有趣的功能。
基准测试的危险
研究人员通常使用旨在评估特定能力(如语言能力、常识推理和数学能力)性能的基准来评估人工智能系统,并非采用图灵测试。越来越多的团队开始转向为人类设计的学术和专业考试。
2023年3月发布GPT-4时,位于加利福尼亚州旧金山的 OpenAI公司在一系列为机器设计的基准测试上测试了它的性能,包括阅读理解、数学和编码。GPT-4在大多数方面都取得了优异成绩[4].该公司还为 GPT-4 设置了大约 30 项考试,包括:为美国高中生设计的各种特定学科测试,称为大学先修课程;评估美国医生临床知识现状的考试;以及美国研究生学习选拔过程中使用的标准测试GRE。OpenAI 报告称,在构成美国许多州律师资格认证流程部分的统一律师考试中,GPT-4 的分数位于前 10% (参见“AI 系统性能 — 选定结果”)。
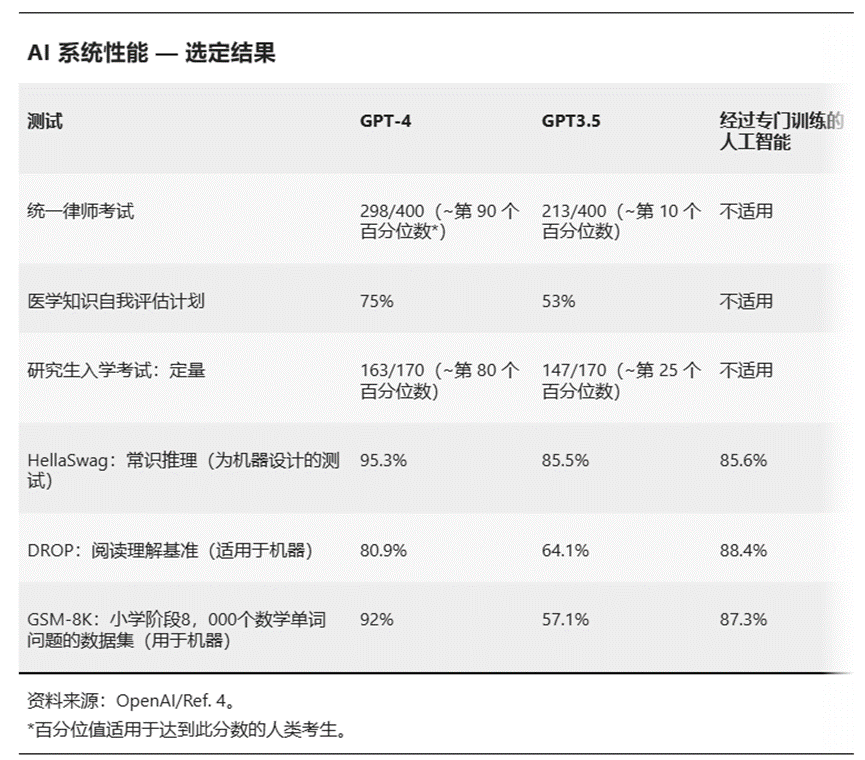
“很多语言模型都可以在这些基准测试上做得很好,” Mitchell说。“但通常,结论不是他们在这些一般能力上超过了人类,而是基准是有限的。”研究人员提到的一个挑战是,这些模型是在大量的文本上进行训练的,以至于他们已经在训练数据中看到类似的问题,因此实际上可能正在寻找答案。这类问题称为污染。
OpenAI表示,通过在问题和训练数据中寻找类似的单词字符串来进一步测试。去除类似字符串之前和之后测试LLM,其性能几乎无差异,这表明成功不能主要归因于污染。然而,一些研究人员质疑这项测试是否足够严格。
纽约大学的语言技术科学家Sam Bowman也在旧金山的人工智能公司Anthropic工作,他告诫不要将GPT-4的能力视为仅仅是记忆的结果。他说,污染“使结果有点复杂,但我认为它并没有真正改变大局”。
研究人员还指出,LLM在考试问题上的成功是不稳定的,可能无法转化为在现实世界中获得正确示例所需的强大能力。Mitchell说,稍微变换考试题目LLM可能就会失败。例如,她从工商管理硕士生考试题中抽去了一道,ChatGPT已经通过了,然后她稍微改写了一下。能回答这个问题的人就能回答改写后的问题。然而,ChatGPT没有通过。
在解释基准的含义方面存在更深层次的问题。对于一个人来说,这些考试的高分将可靠地表明普通智力水平(它指的是在一系列任务中表现良好并适应不同环境的能力)。也就是说,通常可以假设在考试中取得好成绩的人在其他认知测试中表现良好。但对于LLM来说,情况并非如此,Mitchell说;其工作方式与人非常不同。“以人类的思维方式进行推断并不总是适用于人工智能系统,”她说。
这可能是因为LLM只是从语言中学习;并未与物质世界相结合,他们就不会像人那样体验语言与物体、属性和感觉的联系。“很明显,他们理解单词的方式与人类不同,”Lake说。在他看来,LLM目前证明“如果没有真正的理解,你可以拥有非常流利的语言”。
另一方面,LLM还具有人类不具备的能力,例如能够知道人类曾经写过的几乎每个单词之间的联系。Mitchell说,这可能允许模型通过依赖语言或其他指标的怪癖来解决问题,而不必推广到更广泛的性能。
OpenAI的研究员Nick Ryder也认为,一项测试的表现可能不会像获得相同分数的人那样普遍化。“我认为人们不应该看对人类和大型语言模型的评估报告,并得出任何程度的等效性,”他说。OpenAI分数“并不意味着对类似人类的能力或类似人类的推理的陈述。它旨在说明模型在该任务上的表现”。
研究人员还比通过传统的机器基准测试和人工检查对LLM进行更广泛地探索。2023年3月,华盛顿州雷德蒙德Microsoft研究公司的Sébastien Bubeck和他的同事发表在预印本上的论文引起了很大的风波。论文题为“通用人工智能的火花:GPT-4的早期实验(Sparks of Artificial General Intelligence: Early experiments with GPT-4)”[5]。使用GPT-4的早期版本,他们记录了一系列令人惊讶的功能 - 其中许多与语言没有直接或明显的联系。一个值得注意的壮举是,它通过了心理学家的心理测试(心理测试可预测和推理他人的精神状态)。“鉴于GPT-4功能的广度和深度,我们认为它可以合理地被视为通用人工智能(AGI)系统的早期(但仍然不完整)版本,”他们写道。
尽管如此,正如Bubeck向Nature杂志澄清的那样,“GPT-4当然不会像人一样思考,对于它所展示的任何能力,它都会以自己的方式实现它”。
Mitchell说,虽然具有挑衅性,但该报告并没有系统的探讨LLM的能力。“这更像是人类学,”她说。Ullman说,要确信机器有心智理论,需要看到与类似人类的心智理论相对应的潜在认知过程的证据,而不仅仅是机器可以输出与人相同的答案。
人工智能研究人员说,为了找出LLM的优势和劣势,需要进行更广泛和严格的审计。色彩缤纷的逻辑谜题可能是一个候选者。
新的谜题
2019年,在LLMs(大型语言模型)走红之前,Chollet在网上发布了一种他创造的新型逻辑测试,名为“抽象和推理语料库”(ARC)[6]。求解者需要查看一个由方块构成的网格的多个视觉演示,观察网格是如何变换到另一种模式,并通过指示下一个网格将如何变换来展示他们掌握了网格变换的基本规律。“它旨在测试你对未曾见过的事物的适应能力,”Chollet说,并认为这是智能的本质。
ARC捕捉了“人类智能的特征”,Lake说,即从日常知识中进行抽象,并将其应用于以前未遇到的问题。
2020年,Chollet组织了一场机器人ARC竞赛,当时LLMs尚未获得广泛关注。获胜的机器人是一个专门训练用于解决类似ARC任务的AI系统,但与LLMs不同,它没有普遍应用的能力;它只正确解决了21%的问题。相比之下,人类解决ARC问题的正确率为80%[7]。几个研究团队现在已经使用ARC来测试LLMs的能力,但没有一项测验接近人类的表现。
Mitchell及其同事制作了一组新的谜题——ConceptARC,灵感来自ARC,但有两个关键的不同之处[1]。ConceptARC测试更为简单:Mitchell的团队希望确保基准测试不会错过机器智能的进展(即使进展很小)。另一个不同是,团队选择了特定的概念进行测试,然后为每个概念创建了一系列的谜题,这些谜题是概念的变体。
例如,为了测试“相同性”概念,一个谜题要求求解者保留具有相同形状的对象的模式;另一个谜题要求保留与同一轴线对齐的对象。这样做的目的是减少AI系统在未掌握概念的情况下通过测试的可能性(参见“击败机器的抽象思维测试”)。
性能不佳意味着什么
研究人员将ConceptARC任务分别提供给GPT-4和400名在线参与者。人类在所有概念组中的平均得分为 91%(在其中一个概念组上为97%);GPT-4在其中一个组上得分为33%,在其余所有组上得分不到30%。
Mitchell表示:“我们展示了机器仍然无法接近人类水平。”“令人惊讶的是,尽管它从未接受过这方面的训练却能解决其中一些问题”她补充说。
该团队还测试了Chollet竞赛中的领先机器人,这些机器人并非像LLMs那样具有通用能力,而是专门设计用于解决视觉谜题(如ARC)。总体而言,它们表现比GPT-4要好,但比人类差,最佳得分为77%,但在大多数类别中得分小于60%[1]。
Bowman表示,GPT-4在ConceptARC测试中表现的很艰难并不意味着它缺乏抽象推理的潜在能力。他表示,ConceptARC对GPT-4来说并不公平,因为它是一个视觉测试,而LLM的公开版本只能接受文本输入,因此研究人员将用代表图像的数字数组输入给GPT-4(例如,空白像素可能为0,而彩色方块可能是一个数字)。相比之下,人类参与者只需看到图像即可。“我们是在将一个仅限于语言的系统与具有高度发达的视觉系统的人类进行比较,”Mitchell说。“因此,这种比较不公平。”
OpenAI已经创建了GPT-4的“多模态”版本,可以接受图像作为输入。Mitchell和她的团队正等待该版本公开,以便测试ConceptARC,尽管她认为多模态GPT-4的表现也不会好到哪里去。“我不认为这些系统具有与人类相同的抽象概念和推理能力,”她说。
剑桥麻省理工学院的计算认知科学家Sam Acquaviva对此表示赞同。“我会感到震惊,”他说。他指出,另一个研究团队已经对GPT-4进行了1D-ARC的基准测试,其中抽象模式限于单行而不是网格[8]。他说,这应该能够消除一些不公平。Acquaviva表示,尽管GPT-4的表现有所改善,但并不足以表明LLM能可靠地掌握潜在规则并进行推理。
推理论证
Bowman指出,与其他实验结果汇总在一起表明,LLM至少已经获得了对抽象概念进行推理的基本能力。在一项示例中,哈佛大学的计算机科学家Kenneth Li和他的同事使用了数字版本的棋盘游戏Othello(两名玩家通过将黑白棋子在8×8网格上进行竞争),测试LLM是否依赖于语言的记忆表面统计数据来生成文本,或者他们是否可能像人们一样构建世界的内部表征。
当他们通过提供玩家的招数列表来训练LLM时,它变得非常擅长为下一步的有效性提供准确的建议。研究人员认为,他们有证据表明LLM一直在跟踪棋盘的状态,并且基于棋盘状态来提出下一步落子何处,而不仅仅是提供文本建议。
Bowman承认,LLM的推理能力总体上是“参差不齐”的,而且比人更有限 - 但他说它们是存在的,并且似乎随着模型大小而改善,这表明未来的LLM会更好。“这些系统绝对没有我们想要的那么可靠或通用,而且可能有一些特定的抽象推理技能仍然完全失败,”他说。“但我认为基本能力是有的。
Bowman、Mitchell和其他人一致认为,测试LLM的抽象推理能力和其他智力迹象的最佳方法仍然是一个开放性的、悬而未决的问题。加利福尼亚州帕洛阿尔托斯坦福大学的认知科学家Michael Frank并不认为会出现一种单一的、包罗万象的测试会成为图灵测试的继任者。“没有卢比孔河,不是只有一个标准,”他说。相反,他认为研究人员需要进行大量测试来量化各种系统的优势和劣势。“这些代理很棒,但它们在很多很多方面都有突破,系统地探测它们绝对至关重要,”他说。
Wortham为任何试图理解AI系统的人提供建议——避免他所谓的拟人化的诅咒。“我们将任何看似能证明智慧的东西拟人化,”他说。
“这是一种诅咒,因为除了使用人类模型之外,我们无法想到以任何方式显示以目标为导向的行为,”他说。“我们正在想象它这样做的原因是因为它像我们一样思考。
参考文献:
[1]. Moskvichev, A., Odouard, V. V. & Mitchell, M. Preprint at https://arxiv.org/abs/2305.07141 (2023).
[2]. Turing, A. M. Mind LIX, 433–460 (1950).
[3]. Jannai, D., Meron, A., Lenz, B., Levine, Y. & Shoham, Y. Preprint at https://arxiv.org/abs/2305.20010 (2023).
[4]. OpenAI. Preprint at https://arxiv.org/abs/2303.08774 (2023).
[5]. Bubeck, S. et al. Preprint at https://arxiv.org/abs/2303.12712 (2023).
[6]. Chollet, F. Preprint at https://arxiv.org/abs/1911.01547 (2019).
[7]. Johnson, A., Vong, W. K., Lake, B. M. & Gureckis, T. M. Preprint at https://arxiv.org/abs/2103.05823 (2021).
[8]. Xu, Y., Li, W., Vaezipoor, P., Sanner. S. & Khalil, E. B. Preprint at https://arxiv.org/abs/2305.18354 (2023).
[9]. Li, K. et al. Proc. Eleventh Int. Conf. Learn. Represent. https://openreview.net/forum?id=DeG07_TcZvT (2023).
阅读原文内容:
https://doi.org/10.1038/d41586-023-02361-7
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




























机器学习