文章目录
- 张量
- 张量在深度学习领域的定义
- 张量的基本属性
- 使用PyTorch
- 安装PyTorch
- 查看安装版本
- 创建张量
- 常用函数
- 四种创建张量的方式和区别
- 四则运算
张量
张量在深度学习领域的定义
张量(tensor)是多维数组,目的是把向量、矩阵推向更高的维度。
有n维度就叫做n维张量

其实在实际中,并不需要过分的关注张量的定义,只需要明白张量是多维数组就行。
张量的基本属性
主要有三个属性:秩、轴、形状
- 秩:主要告诉我们是张量的维度,其实就是告诉我们是几维向量,通过多少个索引就可以访问到元素。
- 轴:在张量中,轴是指张量的一个维度。当处理多维数据时,每个维度都可以被称为一个轴。通常,第一个轴称为0轴(或轴0),第二个轴称为1轴(或轴1),以此类推。
- 形状:形状是指张量在每个轴上的维度大小。它是一个由整数组成的元组,表示张量沿着每个轴的大小。
关于这些后面的例子中会提到
使用PyTorch

安装PyTorch
PyTorch官网:https://pytorch.org/
根据自己的需求和电脑的硬件情况进行选择,复制下方的pip命令安装即可
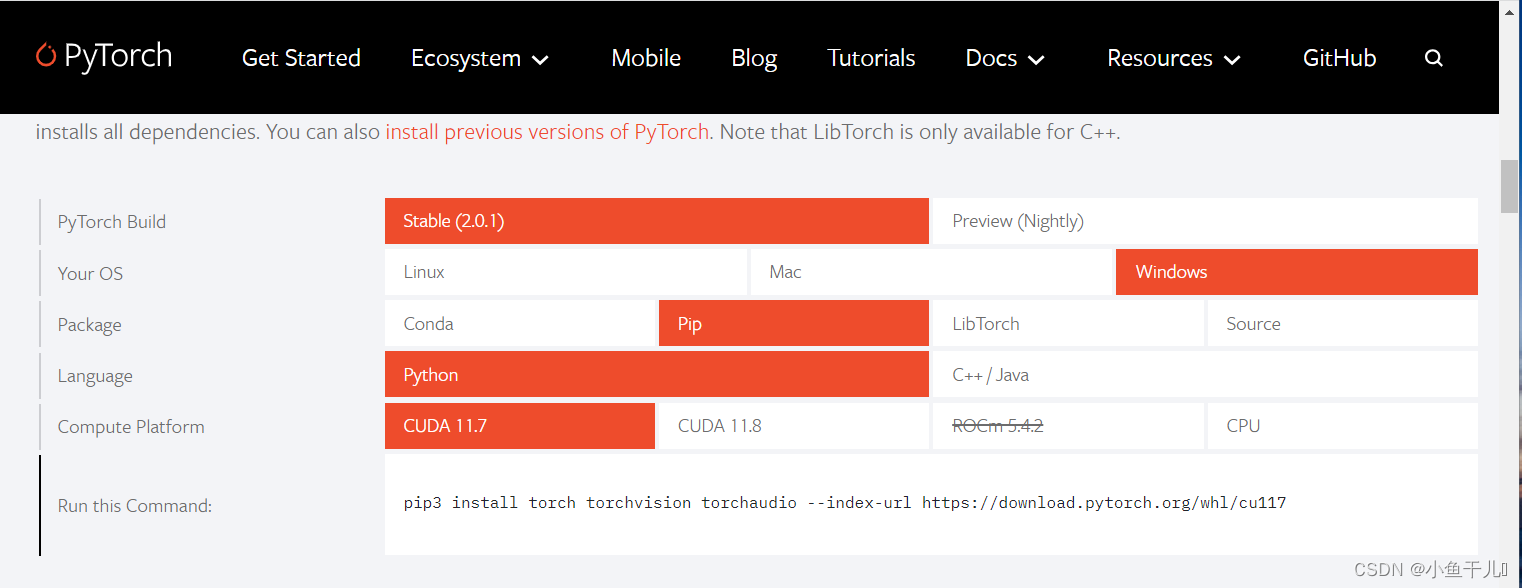
安装GPU版本的不需要再额外安装CUDA,现在的安装PyTorch会自带安装CUDA。
查看安装版本
print(torch.__version__) # 2.0.1+cpu 版本号
print(torch.cuda.is_available()) # False # 没有GPU,如果有则返回True
创建张量
默认创建的张量是在CPU下创建
import torch
# tensor 张量
t = torch.tensor([1,2,3]) # tensor([1, 2, 3])
print(t)
将张量转移到GPU下
# 使用gpu
t = t.cuda() # tensor([1, 2, 3], device='cuda:0')
print(t)
直接在GPU下创建张量
t = torch.tensor([1, 2, 3]).to('cuda') # tensor([1, 2, 3], device='cuda:0')
常用函数
import torch
# 创建一个二维张量
t = torch.tensor([
[1,2,3],
[4,5,6],
[7,8,9]
])
# 输出张量
print(t)
查看数据类型
print(type(t))
输出张量的形状
# 同样也可以理解为每一个轴的长度
print(t.shape)
# 两种方式返回内容一样
print(t.size())
改变形状
# 改变后形状要个原张量里面包含的元素数量一样多。
new_t = t.reshape((1,9))
print(new_t)
我们在使用改变形状的时候,在以前需要指定每一个轴的大小,这样还需要自己计算,比较麻烦,我们可以通过将其中一个参数设置为-1,让reshape自动计算其实际值
t.reshape(1,-1) # 会根据t元素的个数和其他指定的参数自动计算-1代表的实际值
统计张量中元素的个数
# prod() 用于计算张量中所有元素的乘积
# item() 取出张量的值
print(torch.tensor(t.shape).prod().item()) # 思路:根据将所有轴的长度相乘,得出的结果就是元素的个数
print(t.numel()) # 直接返回元素的个数
压缩张量/解压缩张量
通常指的是对张量进行降维操作和恢复原始形状的操作
torch.squeeze() 压缩
torch.unsqueeze() 解压缩
print(t.reshape(1,12))
# tensor([[1., 1., 1., 1., 2., 2., 2., 2., 3., 3., 3., 3.]])
print(t.reshape(1,12).shape)
# torch.Size([1, 12])
# 压缩张量
# 通过结构我们可以看看出,压缩张量,去除张量中维度大小为1的维度,从而降低张量的维度。如果在调用时不指定维度,则会去除所有大小为1的维度。这对于减少张量的冗余维度很有用。
print(t.reshape(1,12).squeeze())
# tensor([1., 1., 1., 1., 2., 2., 2., 2., 3., 3., 3., 3.])
print(t.reshape(1,12).squeeze().shape)
# torch.Size([12])
# 解压缩张量
print(t.reshape(1,12).squeeze().unsqueeze(dim=0))
# tensor([[1., 1., 1., 1., 2., 2., 2., 2., 3., 3., 3., 3.]])
print(t.reshape(1,12).squeeze().unsqueeze(dim=0).shape)
# torch.Size([1, 12])
四种创建张量的方式和区别
data = np.array([1,2,3])
-
方式1 Tensor()类构造器函数
t1 = torch.Tensor(data)会自动将整数转成小数 -
方式2 tensor工厂函数
t2 = torch.tensor(data)会根据输入的数据类型自动推断张量的数据类型 -
方式3 as_tensor工厂函数
t3 = torch.as_tensor(data) -
方式4 from_numpy工厂函数
t4 = torch.from_numpy(data)
四种方式的区别:
前两种方式会生成一份新的数据,后两种是和原数据共享,numpy和torch之间切换非常快,数据共享,两者之间保存统一的内存指向
举例
# 修改data原数据
data[0] = 0
data[1] = 0
data[2] = 0
方式一和方式二生成的张量中的数据没有发生改变
# 张量中的数据没有发生改变
print(t1) # tensor([1., 2., 3.])
print(t2) # tensor([1, 2, 3], dtype=torch.int32)
方式三和方式四生成的张量中的数据随着np.array的数据发生改变
# 张量中的数据随着np.array的数据发生改变-
print(t3) # tensor([0, 0, 0], dtype=torch.int32)
print(t4) # tensor([0, 0, 0], dtype=torch.int32)
注:在刚开始学习时,将重心放在逻辑和代码的正确性上,不需要太关注性能
拼接操作
t1 = torch.tensor([
[1, 2],
[3, 4]
])
t2 = torch.tensor([
[5, 6],
[7, 8]
])
使用cat函数进行拼接
# dim 根据指定轴进行拼接
t1_2 = torch.cat((t1,t2),dim=0)
print(t1_2)
# 两种拼接方式,张量秩不发生改变
t1_2 = torch.cat((t1,t2),dim=1)
print(t1_2)
合并张量
使用stack将张量合并成更高维的张量
t1 = torch.tensor([
[1,1,1,1],
[1,1,1,1],
[1,1,1,1],
[1,1,1,1]
])
t2 = torch.tensor([
[2,2,2,2],
[2,2,2,2],
[2,2,2,2],
[2,2,2,2]
])
t3 = torch.tensor([
[3,3,3,3],
[3,3,3,3],
[3,3,3,3],
[3,3,3,3]
])
# 使用stack将张量合并成更高维的张量
t = torch.stack((t1,t2,t3))
print(t)
print(t.shape)
# torch.Size([3, 4, 4])
拉伸张量
将多维的张量拉伸到一维,主要有两个方式,reshape、flatten
print(t.reshape(-1))
print(t.flatten())
# 另外还有两个参数可选
# start_dim(可选):指定展平的起始维度。默认为0,表示从第0维开始展平。
# end_dim(可选):指定展平的结束维度。默认为-1,表示展平到最后一维。
四则运算
张量的四则运算和numpy中ndarray的运算一致,都使用了广播机制
张量和常量的四则运算
t1 = torch.tensor([[1,2,3,4],[5,6,7,8]])
print(t1+1)
print(t1.add(1))
# 减法
print(t1-1)
print(t1.sub(1))
# 乘法
print(t1*1)
print(t1.mul(1))
# 除法
print(t1/1)
print(t1.div(1))
张量之间的四则运算
当两个张量形状相同或可广播时,可以直接进行四则运算。如果张量形状不匹配,PyTorch会尝试自动进行广播操作,使得张量能够进行元素级别的四则运算。
import torch
# 创建两个示例张量
tensor1 = torch.tensor([[1, 2], [3, 4]])
tensor2 = torch.tensor([[5, 6], [7, 8]])
# 加法
add_result = tensor1 + tensor2
print(add_result) # Output: tensor([[ 6, 8],
# [10, 12]])
# 减法
subtract_result = tensor1 - tensor2
print(subtract_result) # Output: tensor([[-4, -4],
# [-4, -4]])
# 乘法
multiply_result = tensor1 * tensor2
print(multiply_result) # Output: tensor([[ 5, 12],
# [21, 32]])
# 除法
divide_result = tensor1 / tensor2
print(divide_result) # Output: tensor([[0.2000, 0.3333],
# [0.4286, 0.5000]])
需要注意的是,张量之间的四则运算是逐元素的,即对应位置的元素进行运算。此外,还要注意确保参与四则运算的张量形状是兼容的,或者能够进行广播操作,否则会引发运算错误。
广播机制的原理
当执行算术运算时,如果两个数组的形状不完全相同,但是符合一定的规则,那么广播机制会自动对其中一个或两个数组进行扩展,使得它们的形状能够匹配,从而实现逐元素的运算。
广播机制的优点
广播机制的好处在于,它允许我们在不创建额外副本的情况下执行运算,从而节省内存和提高运算效率。同时,它也使得我们可以更方便地处理不同形状的数据,例如在神经网络中处理批量数据或处理多维特征数据时
矩阵的乘法和除法 二维张量的点乘
矩阵乘法使用torch.matmul()函数或者@运算符,而矩阵除法则使用逆矩阵(或者伪逆矩阵)来实现。
矩阵乘法
import torch
# 创建两个示例矩阵
matrix1 = torch.tensor([[1, 2], [3, 4]])
matrix2 = torch.tensor([[5, 6], [7, 8]])
# 矩阵乘法
result = torch.matmul(matrix1, matrix2)
print(result) # Output: tensor([[19, 22],
# [43, 50]])
# 或使用 @ 运算符
result = matrix1 @ matrix2
print(result) # Output: tensor([[19, 22],
# [43, 50]])
# 这样也可以用
matrix1.matmul(matrix2)
矩阵除法
在线性代数中,通常没有直接的矩阵除法运算,而是使用逆矩阵(inverse matrix)或者伪逆矩阵(pseudoinverse matrix)来实现矩阵除法。在PyTorch中,可以使用torch.inverse()函数来计算逆矩阵,从而实现矩阵除法。
import torch
# 创建两个示例矩阵
matrix1 = torch.tensor([[1, 2], [3, 4]])
matrix2 = torch.tensor([[5, 6], [7, 8]])
# 计算矩阵2的逆矩阵
inverse_matrix2 = torch.inverse(matrix2)
# 矩阵除法,等价于 matrix1 @ inverse_matrix2
result = torch.matmul(matrix1, inverse_matrix2)
print(result) # Output: tensor([[-4.0000, 4.0000],
# [ 6.5000, -3.5000]])
参考:https://deeplizard.com/learn/video/gZmobeGL0Yg