文章目录
- 2.PySpark——RDD编程入门
- 2.1 程序执行入口SparkContext对象
- 2.2 RDD的创建
- 2.2.1 并行化创建
- 2.2.2 获取RDD分区数
- 2.2.3 读取文件创建
- 2.3 RDD算子
- 2.4 常用Transformation算子
- 2.4.1 map算子
- 2.4.2 flatMap算子
- 2.4.3 reduceByKey算子
- 2.4.4 WordCount回顾
- 2.4.5 groupBy算子
- 2.4.6 Filter算子
- 2.4.7 distinct算子
- 2.4.8 union算子
- 2.4.9 join算子
- 2.4.10 intersection 算子
- 2.4.11 glom算子
- 2.4.12 groupByKey算子
- 2.4.13 sortBy算子
- 2.4.14 sortByKey
- 2.4.15 综合案例
- 2.4.16 将案例提交到yarn运行
- 2.5 常用Action算子
- 2.5.1 countByKey算子
- 2.5.2 collect算子
- 2.5.3 reduce算子
- 2.5.4 fold算子
- 2.5.5 first算子
- 2.5.6 take算子
- 2.5.7 top算子
- 2.5.8 count算子
- 2.5.9 takeSample算子
- 2.5.10 takeOrdered
- 2.5.11 foreach算子
- 2.5.12 saveAsTextFile
- 2.5.13 注意点
- 2.6 分区操作算子
- 2.6.1 mapPartitions算子
- 2.6.2 foreachPartition算子
- 2.6.3 partitionBy算子
- 2.6.4 repartition算子
- 2.6.5 coalesce算子
- 2.6.6 mapValues算子
- 2.6.7 join算子
- 2.7 面试题
- 2.8 总结
- 3.RDD的持久化
- 3.1 RDD的数据是过程数据
- 3.2 RDD的缓存
- 3.2.1 缓存
- 3.2.2 缓存特点
- 3.2.3 缓存是如何保存的
- 3.3 RDD的CheckPoint
- 3.3.1 RDD CheckPoint
- 3.3.2 CheckPoint是如何保存数据的
- 3.3.3 缓存和CheckPoint的对比
- 3.3.4 代码
- 3.3.5 注意
- 3.3.6 总结
- 4.Spark案例练习
- 4.1 搜索引擎日志分析案例
- 4.2 提交到集群运行
- 4.3 作业
2.PySpark——RDD编程入门
2.1 程序执行入口SparkContext对象
Spark RDD 编程的程序入口对象是SparkContext对象(不论何种编程语言)
只有构建出SparkContext, 基于它才能执行后续的API调用和计算
本质上, SparkContext对编程来说, 主要功能就是创建第一个RDD出来
代码演示:
# coding:utf8
# 导入Spark相关包
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 构建SparkConf对象
conf = SparkConf().setAppName ("helloSpark").setMaster("local[*]")
# 构建SparkContext执行环境入口对象
sc = SparkContext(conf=conf)
master的种类:
- local:local[N]:表示以N核CPU执行,local[*]:给予local进程 所有CPU核心的使用权
- standlone:spark://node1:7077
- yarn 模式
2.2 RDD的创建
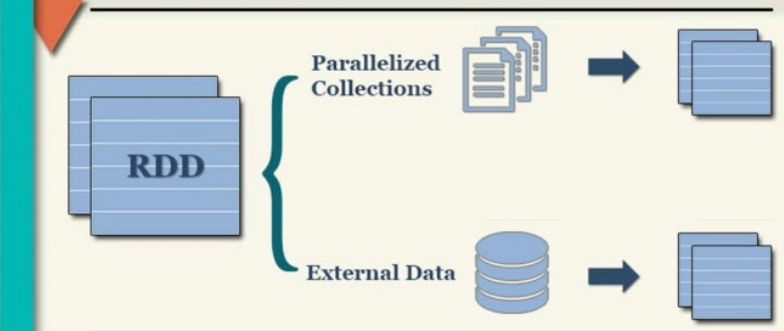
RDD的创建主要有2种方式:
• 通过并行化集合创建 ( 本地对象 转 分布式RDD )
• 读取外部数据源 ( 读取文件 )
2.2.1 并行化创建
概念:并行化创建,是指将本地集合转向分布式RDD,这一步就是分布式的开端:本地转分布式
API:
rdd = spakcontext.parallelize(参数1,参数2)
参数1 集合对象即可,比如list
参数2 分区数
完整代码:
# coding:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':
# 0. 构建Spark执行环境
conf = SparkConf().setAppName("create rdd").setMaster("local[*]")
sc = SparkContext(conf=conf)
# sc 对象的parallelize方法,可以将本地集合转换成RDD返回给你
data = [1,2,3,4,5,6,7,8,9]
rdd = sc.parallelize(data,numSlices=3)
print(rdd.collect())
执行结果:
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Process finished with exit code 0
2.2.2 获取RDD分区数
getNumPartitions API :获取RDD分区数量,返回值是Int数字
用法:rdd.getNumPartitions()
例如,基于上述代码设置了3为分区数,调用以下代码
print(rdd.getNumPartitions())
则会输出结果:3
完整案例代码:01_create_parallelize.py
# coding:utf8
# 导入Spark相关包
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 0. 初始化执行环境 构建SparkContext对象,本地集合--> 分布式对象(RDD)
conf = SparkConf().setAppName ("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 演示通过并行化集合的方式去创建RDD
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9])
# parallelize方法,没有给定分区数,默认分区数是多少? 根据CPU核心来定
print("默认分区数:", rdd.getNumPartitions())
rdd = sc.parallelize([1, 2, 3], 3)
print("分区数:", rdd.getNumPartitions())
# collect方法,是将RDD(分布式对象)中每个分区的数据,都发送到Driver中,形成一个Python List对象
# collect:分布式 转--> 本地集合
print("rdd的内容是:", rdd.collect())
print(type(rdd.collect()))
输出结果:
默认分区数: 8
分区数: 3
rdd的内容是: [1, 2, 3]
<class 'list'>
2.2.3 读取文件创建
textFileAPI
这个API可以读取本地数据,也可以读取hdfs数据
使用方法 :
sparkcontext.textFile(参数1,参数2)
参数1,必填,文件路径 支持本地文件 支持HDFS 也支持一些比如S3协议
参数2 可选,表示最小分区数量
注意:参数2 话语权不足,spark有自己的判断,在它允许的范围内,参数2有效果,超出spark允许的范围,参数2失效
案例代码:02_create_textFile.py
# coding : utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("02_create_textFile").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 通过textFile API 读取数据
# 读取本地文件数据
file_rdd1 = sc.textFile("../data/input/words.txt")
print("默认读取分区数:", file_rdd1.getNumPartitions())
print("file_rdd1 内容:", file_rdd1.collect())
#
# # 加最小分区数的测试
file_rdd2 = sc.textFile("../data/input/words.txt",3)
file_rdd3 = sc.textFile("../data/input/words.txt",100)
print("file_rdd2 分区数:", file_rdd2.getNumPartitions())
print("file_rdd3 分区数:", file_rdd3.getNumPartitions())
# 读取hdfs文件数据测试
hdfs_rdd = sc.textFile("hdfs://Tnode1:8020/input/words.txt")
print("hdfs_rdd 分区数:", hdfs_rdd.getNumPartitions())
print("hdfs_rdd 内容:", hdfs_rdd.collect())
输出结果:
默认读取分区数: 2
file_rdd1 内容: ['hello spark', 'hello hadoop', 'hello flink']
file_rdd2 内容: 4
file_rdd3 内容: 38
hdfs_rdd 分区: 2
hdfs_rdd 内容: ['hello spark', 'hello hadoop', 'hello flink']
wholeTextFile 读取文件的API,有个适用场景:适合读取一堆小文件
这个API是小文件读取专用
用法:
sparkcontext.textFile(参数1,参数2)
# 参数1,必填,文件路径 支持本地文件 支持HDFS 也支持一些比如S3协议
# 参数2 可选,表示最小分区数量
# 注意:参数2 话语权不足,spark有自己的判断,在它允许的范围内,参数2有效果,超出spark允许的范围,参数2失效
这个API偏向于少量分区读取数据
因为,这个API表明了自己是小文件读取专用,那么文件的数据很小、分区很多,
导致shuffle的几率更高,所以尽量少分区读取数据
案例代码:03_create_wholeTextFile.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 读取小文件文件夹
rdd = sc.wholeTextFiles("../data/input/tiny_files")
print(rdd.collect())
print(rdd.map(lambda x: x[1]).collect())
输出结果:
[('file:/tmp/pycharm_project_937/PySpark01/data/input/tiny_files/1.txt', 'hello spark\r\nhello hadoop\r\nhello flink'), ('file:/tmp/pycharm_project_937/PySpark01/data/input/tiny_files/2.txt', 'hello spark\r\nhello hadoop\r\nhello flink'), ('file:/tmp/pycharm_project_937/PySpark01/data/input/tiny_files/3.txt', 'hello spark\r\nhello hadoop\r\nhello flink'), ('file:/tmp/pycharm_project_937/PySpark01/data/input/tiny_files/4.txt', 'hello spark\r\nhello hadoop\r\nhello flink'), ('file:/tmp/pycharm_project_937/PySpark01/data/input/tiny_files/5.txt', 'hello spark\r\nhello hadoop\r\nhello flink')]
['hello spark\r\nhello hadoop\r\nhello flink', 'hello spark\r\nhello hadoop\r\nhello flink', 'hello spark\r\nhello hadoop\r\nhello flink', 'hello spark\r\nhello hadoop\r\nhello flink', 'hello spark\r\nhello hadoop\r\nhello flink']
2.3 RDD算子
算子是什么?
算子:分布式集合对象上的API称之为算子
方法、函数:本地对象的API,叫做方法、函数
算子:分布式对象的API,叫做算子
算子分类
RDD的算子 分成2类
- Transformation:转换算子
- Action:动作(行动)算子
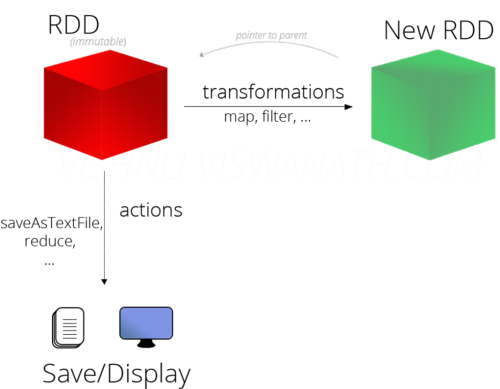
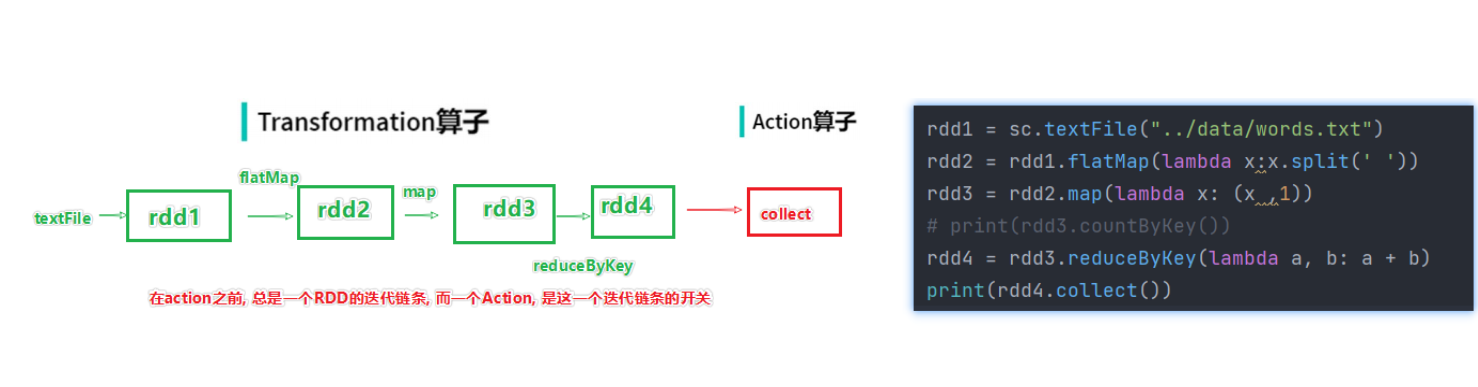
Transformation 算子:
定义:RDD的算子,返回值任然是一个RDD的,称之为转换算子
特性:这类算子lazy 懒加载的,如果没有action算子,Transformation算子是不工作的
Action算子
定义:返回值不是rdd的就是action算子
对于这两类算子来说,
Transformation算子,相当于在构建执行计划,action是一个指令让这个执行计划开始工作。如果没有
action,Transformation算子之间的迭代关系,就是一个没有通电的流水线,只有
action到来,这个数据处理的流水线才开始工作
2.4 常用Transformation算子
2.4.1 map算子
演示代码:04_operators_map.py
# coding:utf8
from pyspark import SparkConf, SparkContext
def addNum(data):
return data * 10
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 4)
rdd2 = rdd1.map(lambda x: x * 10)
rdd3 = rdd1.map(addNum)
result = rdd2.collect()
print(result)
print(rdd3.collect())
输出结果:
[10, 20, 30, 40, 50, 60, 70, 80, 90]
[10, 20, 30, 40, 50, 60, 70, 80, 90]
对于传入参数的lambda表达式
传入方法作为传参的时候,可以选择
- 定义方法,传入其方法名
- 使用lambda 匿名方法的方式
一般,如果方法体可以一行写完,用lambda方便。
如果方法体复杂,就直接定义方法更方便
2.4.2 flatMap算子
功能:对rdd执行map操作,然后进行解除嵌套操作
解除嵌套:

演示代码:05_operators_flatMap.py
# coding:utf8
from pyspark import SparkConf, SparkContext
def addNum(data):
return data * 10
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize(["hadoop spark hadoop", "spark hadoop hadoop", "hadoop flink spark"])
# 得到所有的单词,组成rdd,flatMap的传入参数和map一致,就是给map逻辑用的,解除嵌套无需逻辑(传参)
rdd2 = rdd1.flatMap(lambda line: line.split(" "))
print(rdd2.collect())
输出结果:
['hadoop', 'spark', 'hadoop', 'spark', 'hadoop', 'hadoop', 'hadoop', 'flink', 'spark']
注意:flatMap只适合用于有“嵌套”的rdd,直接用于没有嵌套的rdd会报错
2.4.3 reduceByKey算子
功能:针对KV型的RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作。
用法:
rdd.reduceByKey(func)
# func:(V,V) ——>V
# 接收2个传入参数(类型要一致),返回一个返回值,类型和传入要求一致。
reduceByKey的聚合逻辑是:
比如,有[1,2,3,4,5],然后聚合函数是:lambda a,b: a+ b
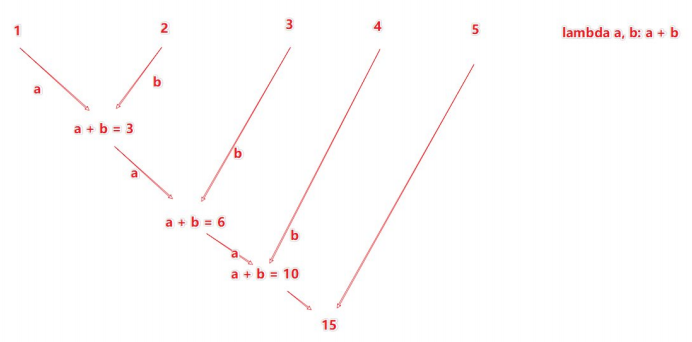
注意:reduceByKey中接收的函数,只负责聚合,不理会分组
分组是自动
byKey来分组的。
代码演示:06_operators_reduceByKey.py
# coding:utf8
from pyspark import SparkConf, SparkContext
def addNum(data):
return data * 10
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('a', 1)])
rdd2 = sc.parallelize([('a', 1), ('a', 11), ('b', 3), ('b', 1), ('a', 5)])
rdd3 = sc.parallelize([('a', 1), ('a', 11), ('b', 3), ('b', 1), ('a', 5)])
rdd = rdd.reduceByKey(lambda a, b: a + b)
rdd2 = rdd2.map(lambda x: (x[0], x[1] * 10))
# 只操作value的算子
rdd3 = rdd3.mapValues(lambda value: value * 10)
# recudeByKey 对相同key的数据执行聚合相加
print(rdd.collect())
print(rdd2.collect())
print(rdd3.collect())
输出结果:
[('a', 3), ('b', 2)]
[('a', 10), ('a', 110), ('b', 30), ('b', 10), ('a', 50)]
[('a', 10), ('a', 110), ('b', 30), ('b', 10), ('a', 50)]
2.4.4 WordCount回顾
代码演示:07_wordcount_example.py
# coding:utf8
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
# 构建SparkConf对象
conf = SparkConf().setAppName("test").setMaster("local[*]")
# 构建SparkContext执行环境入口对象
sc = SparkContext(conf=conf)
# 1.读取文件获取数据 构建RDD
file_rdd = sc.textFile(r"../data/input/words.txt")
# 2. 通过flatMap API取出所有的单词
word_rdd = file_rdd.flatMap(lambda x: x.split(" "))
# 3.将单词转换成元组,key是单词,value是1
word_with_one_rdd = word_rdd.map(lambda word:(word,1))
# 4. 用reduceByKey 对单词进行分组并进行value的聚合
result_rdd = word_with_one_rdd.reduceByKey(lambda a,b:a+b)
# 5. 通过collect算子,将rdd的数据收集到Driver中,打印输出
print(result_rdd.collect())
输出结果:
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
2.4.5 groupBy算子
功能:将rdd的数据进行分组
语法:
rdd.groupBy(func)
# func 函数
# func:(T)——>k
# 函数要求传入一个参数,返回一个返回值,类型无所谓
# 这个函数是 拿到你返回值后,将所有相同返回值的放入一个组中
# 分组完成后,每一个组是一个二元元组,key就是返回值,所有同组的数据放入一个迭代器对象中作为value
代码演示:08_oprators_groupBy.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)])
# 通过groupBy对数据进行分组
# groupBy传入的函数的意思是:通过这个函数,确定按照谁来分组(返回谁即可)
# 分组规则和SQL是一致的,也就是相同的在一个组(Hash分组)
result = rdd.groupBy(lambda t: t[0])
print(result.collect())
print("hello")
print(result.map(lambda t: (t[0], list(t[1]))).collect())
输出结果:
[('a', <pyspark.resultiterable.ResultIterable object at 0x7f85fa80eca0>), ('b', <pyspark.resultiterable.ResultIterable object at 0x7f85fa80ebb0>)]
hello
[('a', [('a', 1), ('a', 1)]), ('b', [('b', 1), ('b', 1), ('b', 1)])]
2.4.6 Filter算子
功能:过滤,把想要的数据进行保留
语法:
rdd.filter(func)
# func:(T)——>bool 传入1个随意类型参数进来,返回值必须是True or False
返回值是True的数据被保留,False的数据被丢弃
代码演示:09_operators_filter.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6])
# 通过Filter算子,过滤奇数,filter 只返回true的值
result = rdd.filter(lambda x: x % 2 == 1)
print(result.collect())
输出结果:
[1, 3, 5]
2.4.7 distinct算子
功能:对RDD数据进行去重,返回新的RDD
语法:
rdd.distinct(参数1)
# 参数1,去重分区数量,一般不用传
演示代码:10_operators_distinct.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 1, 1, 2, 2, 2, 3, 3, 3])
# distinct 进行RDD数据去重操作
print(rdd.distinct().collect())
rdd2 = sc.parallelize([('a', 1), ('a', 1), ('a', 3)])
print(rdd2.distinct().collect())
输出结果:
[1, 2, 3]
[('a', 3), ('a', 1)]
2.4.8 union算子
功能:2个rdd合并成1个rdd返回
用法:rdd.union(other_rdd)
注意:只合并,不会去重
代码演示:11_operators_union.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1, 1, 3, 3])
rdd2 = sc.parallelize(["a","b","a"])
rdd3 = rdd1.union(rdd2)
print(rdd3.collect())
print(rdd3.distinct().collect())
"""
1. 可以看到union算子是不会去重的
2. RDD的类型不同也是可以合并的
"""
输出结果:
[1, 1, 3, 3, 'a', 'b', 'a']
[1, 3, 'b', 'a']
2.4.9 join算子
功能:对两个RDD执行JOIN操作(可实现SQL的内、外连接)
注意:join算子只能用于二元元组
语法:
rdd.join(other_rdd) #内连接
rdd.leftOuterJoin(other_rdd) # 左外
rdd.rightOuterJoin(other_rdd) # 右外
代码演示:12_operators_join.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([(1001, "张三"), (1002, '李四'), (1003, '王五'), (1004, '赵六')])
rdd2 = sc.parallelize([(1001, "销售部"), (1002, '科技部')])
# 通过join算子来进行rdd之间的关联
# 对于join算子来说 关联条件 按照二元元组的key来进行关联
# 内连接
print(rdd1.join(rdd2).collect())
# 左外连接
print(rdd1.leftOuterJoin(rdd2).collect())
# 右外连接
print(rdd1.rightOuterJoin(rdd2).collect())
输出结果:
[(1001, ('张三', '销售部')), (1002, ('李四', '科技部'))]
[(1001, ('张三', '销售部')), (1002, ('李四', '科技部')), (1003, ('王五', None)), (1004, ('赵六', None))]
[(1001, ('张三', '销售部')), (1002, ('李四', '科技部'))]
2.4.10 intersection 算子
功能:求2个rdd的交集,返回一个新rdd
用法:rdd.intersection(other_rdd)
代码演示:13_operators_intersection.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([('a',1),('a',3)])
rdd2 = sc.parallelize([('a',1),('b',3)])
# 通过intersection算子求RDD之间的交集,将交集取出,返回新RDD
rdd3 = rdd1.intersection(rdd2)
print(rdd3.collect())
输出结果:
[('a', 1)]
2.4.11 glom算子
功能:将RDD的数据,加上嵌套,这个嵌套按照分区来进行
比如RDD数据[1,2,3,4,5]有两个分区
那么,被glom后,数据变成:[[1,2,3],[4,5]]
使用方法:rdd.glom()
代码演示:14_operators_glom.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],2)
rdd2 = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
print(rdd.glom().collect())
print(rdd.glom().flatMap(lambda x:x).collect()) # 用flatMap解嵌套
print(rdd2.glom().collect())
输出结果:
[[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[[1], [2], [3], [4, 5], [6], [7], [8], [9, 10]]
2.4.12 groupByKey算子
功能:针对KV型RDD,自动按照key分组
用法:rdd.groupByKey() 自动按照key分组
代码演示:15_operators_groupByKey.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a', 1), ('a', 1), ('a', 1,), ('b', 1), ('b', 1)])
rdd2 = rdd.groupByKey()
print(rdd2.map(lambda x:(x[0],list(x[1]))).collect())
输出结果:
[('a', [1, 1, 1]), ('b', [1, 1])]
2.4.13 sortBy算子
功能:对RDD数据进行排序,基于你指定的排序依据
语法:
rdd.sortBy(func,ascending=False,numPartitions=1)
# func:(T)——>U:告知按照rdd中的哪个数据进行排序,比如lambda x:x[1] 表示按照rdd中的第二列元素进行排序
# ascending = True升序;False 降序
# numPartition:用多少分区来排序
注意:如果要全局有序,排序分区数请设置为1,因为生产环境下,分区数大于1,很可能只得到局部有序的结果
代码演示:16_operators_sortBy.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('g', 3), ('c', 1), ('b', 2,), ('a', 9), ('h', 10), ('i', 4), ('l', 26,), ('o', 1), ('d', 7)])
# 使用sortBy对rdd进行排序
# 参数1 函数,表示的是,告诉spark按照数据的哪个列进行排序
# 参数2 bool,True表示升序,False表示降序
# 参数3 分区数设置
"""注意:如果要全局有序,排序分区数请设置为1,因为生产环境下,分区数大于1,很可能只得到局部有序的结果"""
rdd2 = rdd.sortBy(lambda x:x[1],ascending=True,numPartitions=3)
rdd3 = rdd.sortBy(lambda x:x[0],ascending=True,numPartitions=8)
print(rdd2.collect())
print(rdd3.collect())
输出结果:
[('c', 1), ('o', 1), ('b', 2), ('g', 3), ('i', 4), ('d', 7), ('a', 9), ('h', 10), ('l', 26)]
[('a', 9), ('b', 2), ('c', 1), ('d', 7), ('g', 3), ('h', 10), ('i', 4), ('l', 26), ('o', 1)]
2.4.14 sortByKey
功能:针对KV型RDD,按照key进行排序
语法:
sortByKey(ascending=True,numPartitions=None,keyfunc=<function RDD,<lambda>>)
- ascending:升序或降序,True升序,False降序,默认是升序
- numPartitions:按照几个分区进行排序,如果全局有序,设置为1
- keyfunc:在排序前对key进行处理,语法是:(k)——>U,一个参数传入,返回一个值
代码演示:17_operators_sortByKey.py
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('g', 3), ('A', 1), ('B', 2,), ('A', 9), ('h', 10), ('i', 4), ('l', 26,), ('o', 1), ('d', 7)])
# 调用了忽略大小写的函数
print(rdd.sortByKey(ascending=True, numPartitions=1, keyfunc=lambda key: str(key).lower()).collect())
输出结果:
[('A', 1), ('A', 9), ('B', 2), ('d', 7), ('g', 3), ('h', 10), ('i', 4), ('l', 26), ('o', 1)]
2.4.15 综合案例

代码演示:18_operators_demo.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 读取数据文件
file_rdd = sc.textFile("../data/input/order.text")
# 进行rdd数据的split 按照|符号进行,得到一个json数据
jsons_rdd = file_rdd.flatMap(lambda line: line.split("|"))
# 通过python内置的json库,完成json字符串到字典对象的转换
dict_rdd = jsons_rdd.map(lambda json_str: json.loads(json_str))
# 过滤数据,只保留北京的数据
beijing_rdd = dict_rdd.filter(lambda d: d['areaName'] == '北京')
# 组合北京和商品类型形成的字符串
category_rdd = beijing_rdd.map(lambda x: x['areaName'] + '_' + x['category'])
# 对结果集进行去重操作
result_rdd = category_rdd.distinct()
# 输出
print(result_rdd.collect())
输出结果:
['北京_平板电脑', '北京_家具', '北京_书籍', '北京_食品', '北京_服饰', '北京_手机', '北京_家电', '北京_电脑']
2.4.16 将案例提交到yarn运行
改动1:加入环境变量,让pycharm运行yarn的时候,知道hadoop的配置在哪,可以去读取yarn的信息
import os
from defs_19 import city_with_category
# 导入自己写的函数时,把文件夹设置为SourceRoot就不会报错了
os.environ['HADOOP_CONF_DIR']= "/export/server/hadoop/etc/hadoop"
改动2:在集群上运行,本地文件就不可以用了,需要用hdfs文件
# 在集群中运行,我们需要用HDFS路径,不能用本地路径
file_rdd = sc.textFile("hdfs://Tnode1:8020/input/order.text")
改动3:
"""
如果提交到集群运行,除了主代码以外,还依赖了其它的代码文件
需要设置一个参数,来告知spark,还有依赖文件要同步上传到集群中
参数叫做:spark.submit.pyFiles
参数的值可以是单个.py文件,也可以是.zip压缩包(有多个依赖文件的时候可以用zip压缩后上传)
"""
conf.set("spark.submit.pyFiles","defs_19.py")
完整代码:19_operators_runOnYarn.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
import os
from defs_19 import city_with_category
# 导入自己写的函数时,把文件夹设置为SourceRoot就不会报错了
os.environ['HADOOP_CONF_DIR']= "/export/server/hadoop/etc/hadoop"
if __name__ == '__main__':
# 提交到yarn集群,master设置为yarn
conf = SparkConf().setAppName("SparkDemo01").setMaster("yarn")
"""
如果提交到集群运行,除了主代码以外,还依赖了其它的代码文件
需要设置一个参数,来告知spark,还有依赖文件要同步上传到集群中
参数叫做:spark.submit.pyFiles
参数的值可以是单个.py文件,也可以是.zip压缩包(有多个依赖文件的时候可以用zip压缩后上传)
"""
conf.set("spark.submit.pyFiles","defs_19.py")
sc = SparkContext(conf=conf)
# 在集群中运行,我们需要用HDFS路径,不能用本地路径
file_rdd = sc.textFile("hdfs://Tnode1:8020/input/order.text")
# 进行rdd数据的split 按照|符号进行,得到一个json数据
jsons_rdd = file_rdd.flatMap(lambda line: line.split("|"))
# 通过python内置的json库,完成json字符串到字典对象的转换
dict_rdd = jsons_rdd.map(lambda json_str: json.loads(json_str))
# 过滤数据,只保留北京的数据
beijing_rdd = dict_rdd.filter(lambda d: d['areaName'] == '北京')
# 组合北京和商品类型形成的字符串
category_rdd = beijing_rdd.map(city_with_category)
# 对结果集进行去重操作
result_rdd = category_rdd.distinct()
# 输出
print(result_rdd.collect())
依赖代码:defs_19.py
# coding:utf8
def city_with_category(data):
return data['areaName'] + '_' +data['category']
输出结果:
['北京_书籍', '北京_食品', '北京_服饰', '北京_平板电脑', '北京_家具', '北京_手机', '北京_家电', '北京_电脑']
在服务器上通过spark-submit 提交到集群运行
# --py-files 可以帮你指定你依赖的其它python代码,支持.zip(一堆),也可以单个.py文件都行。
/export/server/spark/bin/spark-submit --master yarn --py-files ./defs.py ./main.py
服务器上程序运行结果:

注意,在服务器上跑时,需要把conf中的setMaster去掉
即conf = SparkConf().setAppName(“SparkDemo01”).setMaster(“yarn”)改为:
conf = SparkConf().setAppName(“SparkDemo01”)
2.5 常用Action算子
2.5.1 countByKey算子
功能:统计key出现的次数(一般适用于KV型的RDD)
代码演示:20_operators_countByKey.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.textFile("../data/input/words.txt")
rdd2 = rdd.flatMap(lambda x:x.split(" ")).map(lambda x: (x, 1))
# 通过countByKey来对key进行计数,这是一个Action算子
result = rdd2.countByKey()
print(result)
print(list(result))
print(result["hello"])
print(type(result))
输出结果:
defaultdict(<class 'int'>, {'hello': 3, 'spark': 1, 'hadoop': 1, 'flink': 1})
['hello', 'spark', 'hadoop', 'flink']
3
<class 'collections.defaultdict'>
2.5.2 collect算子
功能:将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象
用法:rdd.collect()
这个算子,是将RDD各个分区数据都拉取到Driver
注意的是,RDD是分布式对象,其数据量可以很大,
所以用这个算子之前要心知肚明地了解 结果数据集不会太大。
不然,会把Driver内存撑爆
2.5.3 reduce算子
功能:对RDD数据集按照你传入的逻辑进行聚合
语法:
rdd.reduce(func)
# func:(T,T)——>T
# 2参数传入1个返回值,返回值要和参数要求类型一致
代码演示:21_operators_reduce.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5])
print(rdd.reduce(lambda a, b: a + b))
输出结果:
15
2.5.4 fold算子
功能:和reduce一样,接收传入逻辑进行聚合,聚合是带有初始值的,
这个初始值聚合会作用在:
- 分区内聚合
- 分区间聚合
比如:[[1,2,3],[4,5,6],[7,8,9]]
数据量分布在3个分区
分区1: 1、2、3 聚合的时候带上10作为初始值得到16
分区3: 4、5、6 聚合的时候带上10作为初始值得到25
分区4: 7、8、9 聚合的时候带上10作为初始值得到34
3个分区的结果做聚合也带上初始值10,所以结果是10+16+25+34 = 85
代码演示:22_operators_fold.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
print(rdd.glom().collect())
print(rdd.fold(10, lambda a, b: a + b))
输出结果:
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
85
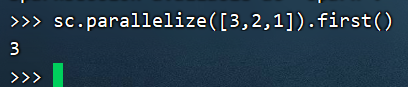
2.5.5 first算子
功能:取出RDD的第一个元素
用法
sc.parallelize([3,2,1]).first()
输出:3
2.5.6 take算子
功能:取RDD的前N个元素。组合成list返回给你
用法:
>>> sc.parallelize([3,2,1,4,5,6]).take(5)
[3, 2, 1, 4, 5]

2.5.7 top算子
功能:对RDD数据集进行降序排序,取前N个
用法:
>>> sc.parallelize([3,2,1,4,5,6]).top(3) # 表示取降序前3个
[6, 5, 4]

2.5.8 count算子
功能:计算RDD有多少条数据,返回值是一个数字
用法:
>>> sc.parallelize([3,2,1,4,5,6]).count()
6

2.5.9 takeSample算子
功能:随机抽样RDD的数据
用法:
takeSample(参数1:True or False,参数2:采样数,参数3:随机数种子)
- 参数1:True表示允许取同一个数据,False表示不允许取同一个数据,和数据内容无关,是否重复表示的是同一个位置的数据(有、无放回抽样)
- 参数2:抽样要几个
- 参数3:随机数种子,这个参数传入一个数字即可,随意给
随机数种子 数字可以随便传,如果传同一个数字 那么取出的结果是一致的。
一般参数3 我们不传,Spark会自动给与随机的种子。
代码演示:23_operators_takeSample.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 3, 5, 3, 1, 3, 2, 6, 7, 8, 6],1)
result = rdd.takeSample(False,5,1)
# 随机抽样可以抽出相同的数据,只是位置不同而已
# 随机数种子能让随机数不再继续发生变化
print(result)
输出结果:
[2, 7, 6, 6, 3]
注意:
随机抽样可以抽出相同的数据,只是位置不同而已
随机数种子能让随机数不再继续发生变化
2.5.10 takeOrdered
功能:对RDD进行排序取前N个
用法:
rdd.takeOrdered(参数1,参数2)
- 参数1 要几个数据
- 参数2 对排序的数据进行更改(不会更改数据本身,只是在排序的时候换个样子)
这个方法按照元素自然顺序升序排序,如果你想玩倒叙,需要参数2 来对排序的数据进行处理
代码演示:24_operators_takeOrdered.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 1)
print(rdd.takeOrdered(3))
print(rdd.takeOrdered(3,lambda x:-x))
输出结果:
[1, 2, 3]
[9, 7, 6]
2.5.11 foreach算子
功能:对RDD的每一个元素,执行你提供的逻辑的操作(和map一个思想),但是这个方法没有返回值
用法:
rdd.foreach(func)
# func:(T) ——> None
代码演示:25_operators_foreach.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 1)
rdd.foreach(lambda x: print(x * 10))
输出结果:
10
30
20
40
70
90
60
2.5.12 saveAsTextFile
功能:将RDD的数据写入文本文件中
支持本地写出,hdfs等文件系统
代码演示:
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,3,2,4,7,9,6],3)
rdd.saveAsTextFile("hdfs://Tnode1:8020/test/output/out1")
运行结果:
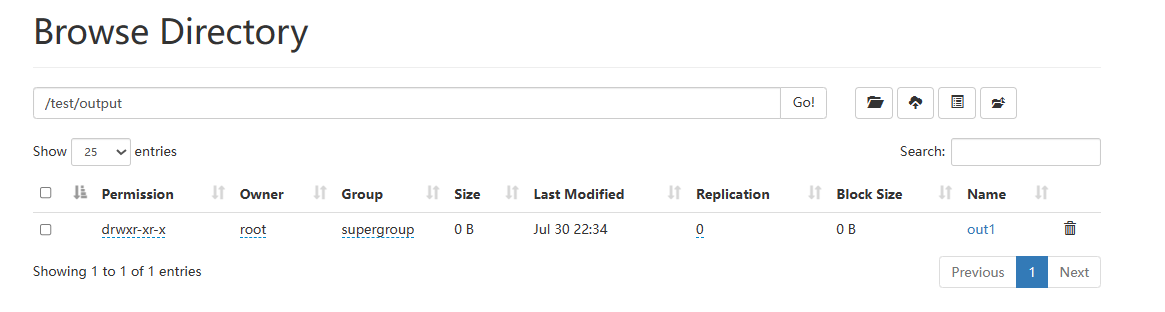
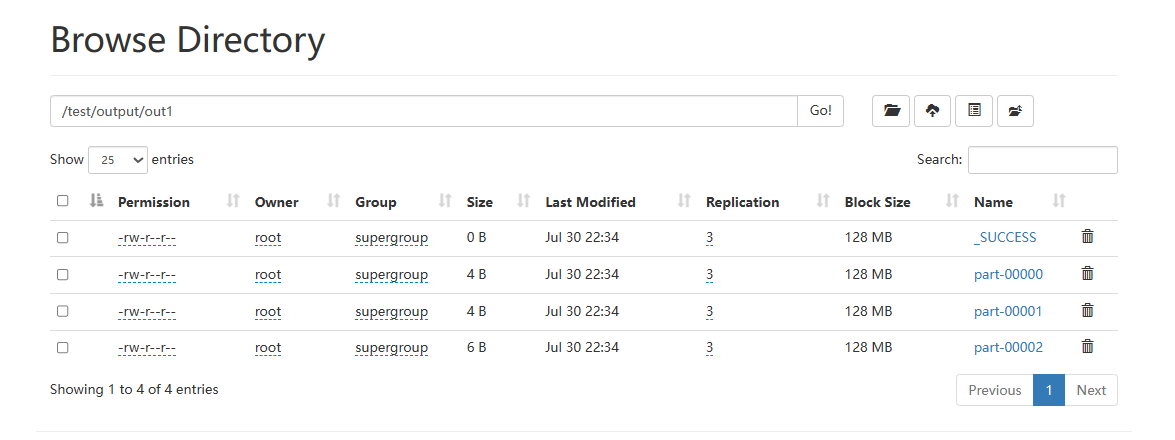
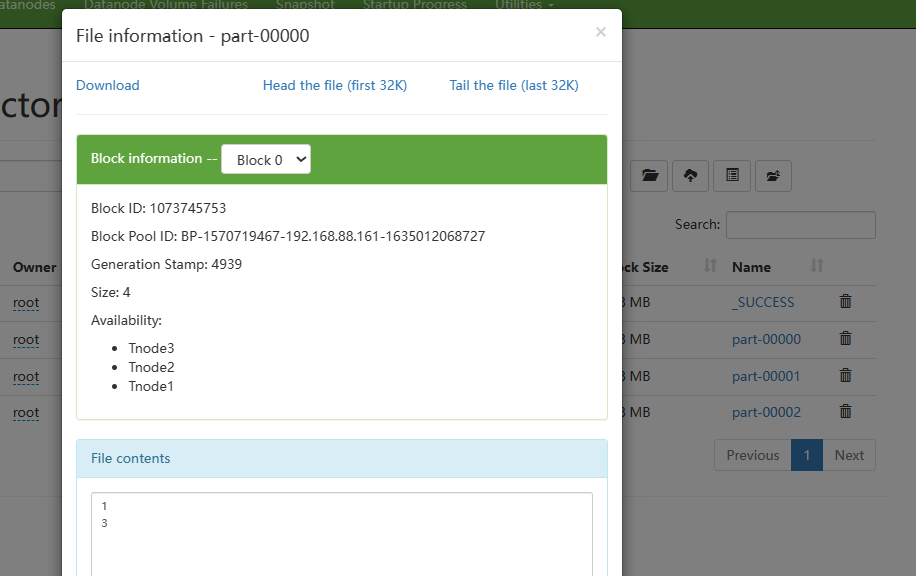
注意:保存文件API,是分布式执行的
这个API的执行数据是不经过driver的
如图,写出的时候,每个分区所在的Executor直接控制数据写出到目标文件系统中
所有才会一个分区产生一个结果文件

2.5.13 注意点
我们学习的action中:
- foreach
- saveAsTextFile
这两个算子是分区(Executor)直接执行的,跳过Driver,由分区所在的Executor直接执行
反之:其余的Action算子都会将结果发送至Driver
2.6 分区操作算子
2.6.1 mapPartitions算子
transformation算子
图解:
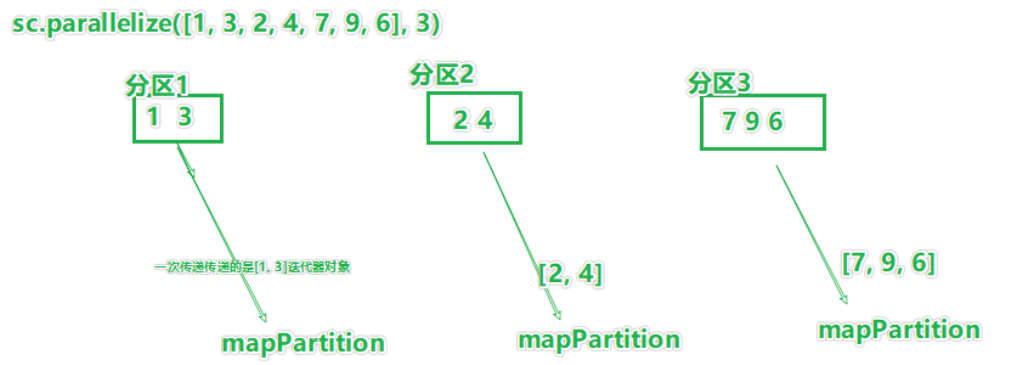
如图,mapPartition一次被传递的是一整个分区的数据
作为一个迭代器(一次性list)对象传入过来。
代码演示:27_operators_mapPartitions.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
import time
if __name__ == '__main__':
start_time = time.time()
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 效果和map一样,但是性能比map好,cpu计算没有省,但是网络IO少很多
rdd = sc.parallelize([1,3,2,4,7,9,6],3)
def process(iter):
result = []
for it in iter:
result.append(it*10)
return result
print(rdd.mapPartitions(process).collect())
# print(rdd.map(lambda x:x*10).collect())
end_time = time.time()
gap_time = (end_time - start_time)
gap_time = round(gap_time, 4) # 保留四位小数
print("执行本程序共耗时:" + str(gap_time) + "s")
输出结果:
[10, 30, 20, 40, 70, 90, 60]
执行本程序共耗时:8.0515s
注意:效果和map一样,但是性能比map好,cpu计算没有省,但是网络IO少很多
2.6.2 foreachPartition算子
Action算子
功能:和普通foreach一致,一次处理的是一整个分区数据
代码演示:28_operators_foreachPartitions.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,3,2,4,7,9,6],3)
def process(iter):
result = []
for it in iter:
result.append(it*10)
print(result)
rdd.foreachPartition(process)
输出结果:
[70, 90, 60]
[10, 30]
[20, 40]
foreachPartition 就是一个没有返回值的mapPartitions
2.6.3 partitionBy算子
transformation算子
功能:对RDD进行自定义分区操作
用法:
rdd.partitionBy(参数1,参数2)
- 参数1 重新分区后有几个分区
- 参数2 自定义分区规则,函数传入
参数2:(K)——>int
一个传入参数进来,类型无所谓,但是返回值一定是int类型,
将key传给这个函数,你自己写逻辑,决定返回一个分区编号
分区编号从0开始,不要超出分区数-1
代码演示:29_operators_partitionBy.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('hadoop', 1), ('spark', 1), ("hello", 1), ("flink", 1), ("hadoop", 1), ("spark", 1)])
# 使用partitionBy 自定义 分区
def process(k):
if 'hadoop' == k or 'hello' == k: return 0
if 'spark' == k: return 1
return 2
print(rdd.partitionBy(3, process).glom().collect())
输出结果:分区依次为0、1、2
[[('hadoop', 1), ('hello', 1), ('hadoop', 1)], [('spark', 1), ('spark', 1)], [('flink', 1)]]
分区号不要超标,你设置3个分区,分区号只能是0 1 2
设置5个分区 分区号只能是0 1 2 3 4
2.6.4 repartition算子
transformation算子
功能:对RDD的分区执行重新分区(仅数量)
用法:
rdd.repartition(N)
传入N 决定新的分区数
代码演示:30_operators_repartition_and_coalesce.py
# coding:utf8
import json
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5], 3)
# repartition 修改分区
print(rdd.repartition(1).getNumPartitions())
print(rdd.repartition(5).getNumPartitions())
# coalesce 修改分区
print(rdd.coalesce(1).getNumPartitions())
print(rdd.coalesce(5,shuffle=True).getNumPartitions())
输出结果:
1
5
1
5
注意:对分区的数量进行操作,一定要慎重
一般情况下,我们写spark代码除了要求全局排序设置为1个分区外,
多数时候,所有API中关于分区相关的代码我们都不太理会
因为,如果你改分区了
- 会影响并行计算(内存迭代的并行管道数量)
后面学- 分区如果增加,极大可能导致shuffle
2.6.5 coalesce算子
transformation算子
功能:对分区进行数量增减
用法:
rdd.coalesce(参数1,参数2)
- 参数1,分区数
- 参数2,True or False
True表示允许shuffle,也就是可以加分区
False表示不允许shuffle,也就是不能加分区,False是默认
代码见2.6.4
对比repartition,一般使用coalesce较多,因为加分区要写参数2
这样避免写repartition的时候手抖了加分区了
2.6.6 mapValues算子
Transformation算子
功能:针对二元元组RDD,对其内部的二元元组的Value执行map操作
语法:
rdd.mapValues(func)
# func: (V)——> U
# 注意,传入的参数,是二元元组的 value值
# 我们这个传入的方法,只对value进行处理
代码演示:
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("create rdd").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a', 1), ('a', 11), ('a', 6), ('b', 3), ('b', 5)])
# rdd.map(lambda x:(x[0],x[1]*10))
# 将二元元组的所有value都乘以10进行处理
print(rdd.mapValues(lambda x: x * 10).collect())
输出结果:
[('a', 10), ('a', 110), ('a', 60), ('b', 30), ('b', 50)]
2.6.7 join算子
Transformation算子
功能:对两个RDD执行join操作(可以实现SQL的内、外连接)
注意:join算子只能用于二元元组
代码见 2.4.9
2.7 面试题
groupByKey和reduceByKey的区别
在功能上的区别:
groupByKey仅仅只有分组功能而已reduceByKey除了有ByKey的分组功能外,还有reduce聚合功能,所以是一个分组+聚合一体化的算子
如果对数据执行分组+聚合,那么使用这2个算子的性能差别是很大的
reduceByKey的性能是远大于:groupByKey+聚合逻辑的
因为:
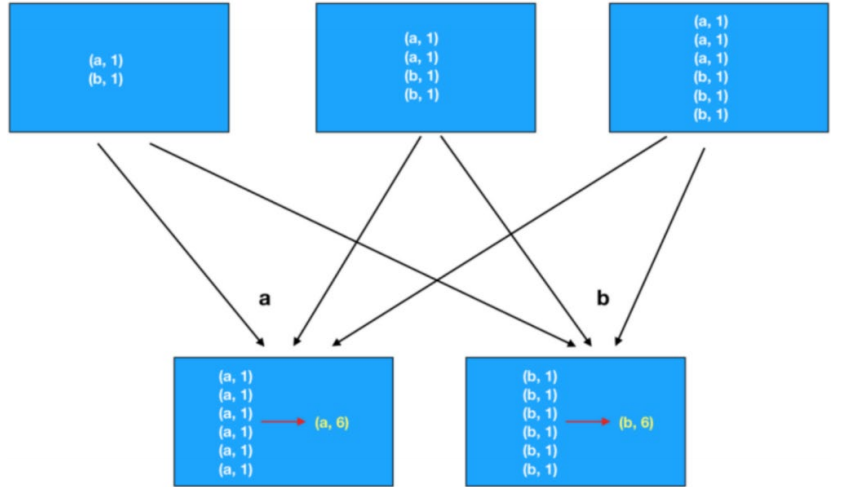
如图,这是groupByKey+聚合逻辑的执行流程。
因为,groupByKey只能分组,所以,执行上是先分组(shuffle)后聚合
再来看reduceByKey:

如图,reduceByKey由于自带聚合逻辑,所以可以完成:
- 先在分区内做预聚合
- 然后再走分组流程(shuffle)
- 分组后再做最终聚合
对于groupByKey,reduceByKey最大的提升在于,分组前进行了预聚合,那么在shuffle分组节点,被shuffle的数据可以极大地减少
这就极大地提升了性能
分组+聚合,首选
reduceByKey,数据越大,对groupByKey的优势就越高
2.8 总结
- RDD创建方式有哪几种方法?
通过并行化集合的方式(本地集合转分布式集合)
或者读取数据的方式创建(TextFile、WholeTextFile)
- RDD分区数如何查看?
通过getNumPartitions API查看,返回值Int
-
Transformation和Action的区别?
转换算子的返回值100%是RDD,而Action算子的返回值100%不是RDD转换算子是懒加载的,只有遇到Action才会执行,Action就是转换算子处理链条的开关。
-
哪两个Action算子的结果不经过Driver,直接输出?
foreach和saveAsTextFile 直接由Executor执行后输出,不会将结果发送到Driver上去
-
reduceByKey和groupByKey的区别?
reduceByKey自带聚合逻辑,groupByKey不带
如果做数据聚合reduceByKey的效率更好,因为可以先聚合后shuffle在最终聚合,传输的IO小
-
mapPartitions和foreachPartition的区别?
mapPartitions带有返回值 foreachPartition不带
-
对于分区操作有什么要注意的地方?
尽量不要增加分区,可能破坏内存迭代的计算管道
3.RDD的持久化
3.1 RDD的数据是过程数据
RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新的RDD生成,代表老RDD的消失。
RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了。
这个特性可以最大化地利用资源,老旧RDD没用了 就从内存中清理,给后续的计算腾出内存空间。
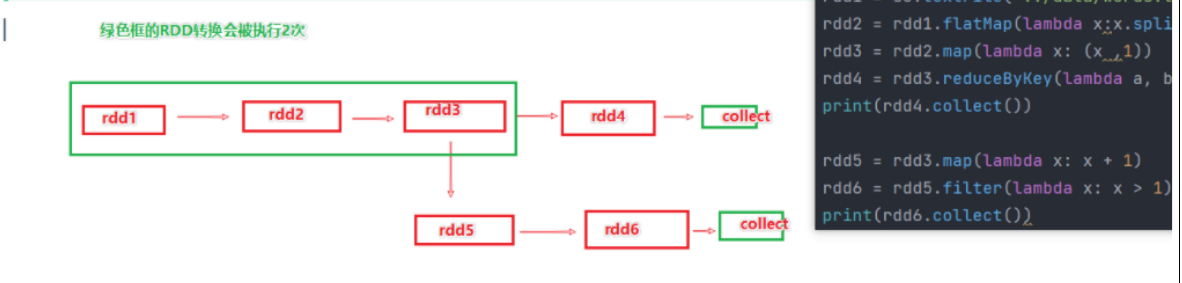
如上图,rdd3被2次使用,第一次使用之后,其实RDD3就不存在了。
第二次使用的时候,只能基于RDD的血缘关系,从RDD1重新执行,构建出来RDD3,供RDD5使用。
3.2 RDD的缓存
3.2.1 缓存
对于上述的场景,肯定要执行优化,优化就是:
RDD3如果不消失,那么RDD1——>RDD2——>RDD3这个链条就不会执行2次,或者更多次
RDD的缓存技术:Spark提供了缓存API,可以让我们通过调用APi,将指定的RDD数据保留在内存或者硬盘上
缓存的APi
# RDD3 被2次使用,可以加入缓存进行优化
rdd3.cache() # 缓存到内存中
rdd3.persist(StorageLevel.MEMORY_ONLY) # 仅内存缓存
rdd3.persist(StorageLevel.MEMORY_ONLY_2) # 仅内存缓存,2个副本
rdd3.persist(StorageLevel.DISK_ONLY) # 仅缓存硬盘上
rdd3.persist(StorageLevel.DISK_ONLY_2) # 仅缓存硬盘上,2个副本
rdd3.persist(StorageLevel.DISK_ONLY_3) # 仅缓存硬盘上,3个副本
rdd3.persist(StorageLevel.MEMORY_AND_DISK) # 先放内存,不够放硬盘
rdd3.persist(StorageLevel.MEMORY_AND_DISK_2) # 先放内存,不够放硬盘,2个副本
rdd3.persist(StorageLevel.OFF_HEAP) # 堆外内存(系统内存)
# 如上API,自行选择使用即可
# 一般建议使用rdd3.persist(StorageLevel.MEMORY_AND_DISK)
# 如果内存比较小的集群,建议使用rdd3.persist(StorageLevel.DISK_ONLY)或者就别用缓存了 用CheckPoint
# 主动清理缓存的API
rdd.unpersist()
3.2.2 缓存特点
- 缓存技术可以将过程RDD数据,持久化保存到内存或者硬盘上
- 但是,这个保存在设定上是认为不安全的。
缓存的数据在设计上是认为有丢失风险的。
所以,缓存有一个特点就是:其保留RDD之间的血缘(依赖)关系
一旦缓存丢失,可以基于血缘关系的记录,重新计算这个RDD的数据
缓存如何丢失:
- 在内存中的缓存是不安全的,比如断电、计算任务内存不足,把缓存清理给计算让路
- 硬盘中因为硬盘损坏也是可能丢失的。
代码演示:31_cache.py
# coding:utf8
from pyspark.storagelevel import StorageLevel
from pyspark import SparkConf, SparkContext
import time
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.textFile("../data/input/words.txt")
rdd2 = rdd1.flatMap(lambda x: x.split(" "))
rdd3 = rdd2.map(lambda x: (x, 1))
# 给rdd3加缓存
# rdd3.cache()
rdd3.persist(StorageLevel.MEMORY_AND_DISK_2) # 设置缓存级别
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
result = rdd4.collect()
print(result)
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x:sum(x))
print(rdd6.collect())
# 取消缓存
rdd3.unpersist()
time.sleep(10000000)
输出结果:
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
3.2.3 缓存是如何保存的
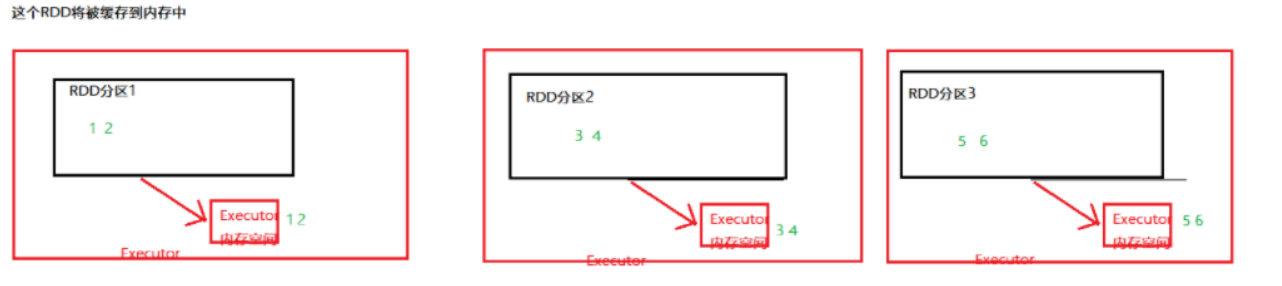
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U3Jp3aGK-1690941563363)(https://cdn.jsdelivr.net/gh/Sql88/BlogImg@main/img/%E7%BC%93%E5%AD%98%E6%98%AF%E5%A6%82%E4%BD%95%E4%BF%9D%E5%AD%98%E7%9A%842.png)]
如图,RDD是将自己分区的数据,每个分区自行将其数据保存在其所在的Executor内存和硬盘上。
这是分散存储
3.3 RDD的CheckPoint
3.3.1 RDD CheckPoint
CheckPoint技术,也是将RDD的数据,保存起来。
但是它仅支持硬盘存储
并且:
- 它被设计认为是安全的
- 不保留
血缘关系
3.3.2 CheckPoint是如何保存数据的
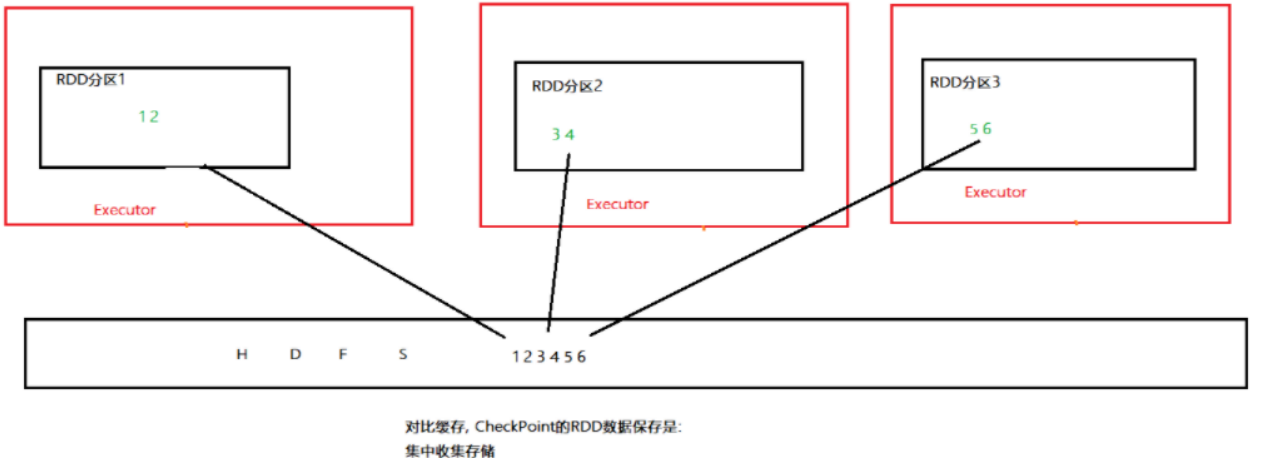
如图:CheckPoint存储RDD数据,是集中收集各个分区数据进行存储。而缓存是分散存储
3.3.3 缓存和CheckPoint的对比
- CheckPoint不管分区数量多少,风险是一样的,缓存分区越多,风险越高
- CheckPoint支持写入HDFS,缓存不行,HDFS是高可靠存储,CheckPoint被认为是安全的
- CheckPoint不支持内存,缓存可以,缓存如果写内存,性能比CheckPoint要好一些
- CheckPoint因为设计是安全的,所以不保留血缘关系,而缓存因为设计上认为不安全,所以保留
3.3.4 代码
# 设置CheckPoint第一件事情,选择CP的保存路径
# 如果是Local模式,可以支持本地文件系统,如果在集群运行,千万要用HDFS
sc.setCheckpointDir("hdfs://node1:8020/output/bj52ckp")
# 用的时候,直接调用checkPoint算子即可。
rdd.checkpoint()
完整代码演示:32_checkPoint.py
# coding:utf8
import json
from pyspark.storagelevel import StorageLevel
from pyspark import SparkConf, SparkContext
import time
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 1.告知spark,开启checkPoint功能
sc.setCheckpointDir("hdfs://Tnode1:8020/output/ckp")
rdd1 = sc.textFile("../data/input/words.txt")
rdd2 = rdd1.flatMap(lambda x: x.split(" "))
rdd3 = rdd2.map(lambda x: (x, 1))
# 调用checkPoint API 保存数据即可
rdd3.checkpoint()
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
result = rdd4.collect()
print(result)
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x:sum(x))
print(rdd6.collect())
# 取消缓存
rdd3.unpersist()
time.sleep(10000000)
输出结果:
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
3.3.5 注意
CheckPoint是一种重量级的使用,也就是RDD的重新计算成本很高的时候,我们采用CheckPoint比较合适。
或者数据量很大,用CheckPoint比较合适。
如果数据量小,或者RDD重新计算是非常快的,用CheckPoint没啥必要
Cache和CheckPoint两个API都不是Action类型
所以,想要它俩工作,必须在后面接上Action
接上Action的目的,是让RDD有数据,而不是为了CheckPoint和Cache工作。
3.3.6 总结
1.Cache和CheckPoint的区别
- Cache是轻量化保存RDD数据,可存储在内存和硬盘,是分散存储,设计上数据是不安全的(保留RDD血缘关系)
- CheckPoint是重量级保存RDD数据,是集中存储,只能存储在硬盘(HDFS)上,设计上是安全的(不保留RDD血缘关系)
2.Cache和CheckPoint的性能对比?
- Cache性能更好,因为是分散存储,各个Executor并行执行,效率高,可以保存到内存中(占内存),更快
- CheckPoint比较慢,因为是集中存储,涉及到网络IO,但是存储到HDFS上更加安全(多副本)
4.Spark案例练习
4.1 搜索引擎日志分析案例
数据格式:

需求:

- 用户搜索的关键词分析
- 用户和关键词组合分析
- 热门搜索时间段分析
案例实现代码:
# coding:utf8
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
import jieba
from operator import add
def context_jieba(data):
"""通过jieba分词工具 进行分词操作"""
seg = jieba.cut_for_search(data)
l = []
for word in seg:
l.append(word)
return l
def filter_words(data):
"""过滤不要的 谷、帮、客 湖"""
return data not in ['谷', '帮', '客', '湖']
def append_words(data):
"""修订某些关键词的内容"""
if data == '传智播': data = '传智播客'
if data == '院校': data = '院校帮'
if data == '博学': data = '博学谷'
if data == '数据': data = '数据湖'
return (data, 1)
def extract_user_and_word(data):
"""传入数据是 元组(1,我喜欢传智播客)"""
user_id = data[0]
content = data[1]
# 对content进行分词
words = context_jieba(content)
return_list = []
for word in words:
# 不要忘记过滤 \谷\帮\客\湖
if filter_words(word):
return_list.append((user_id + '_' + append_words(word)[0], 1))
return return_list
if __name__ == '__main__':
conf = SparkConf().setAppName("SparkDemo2")
sc = SparkContext(conf=conf)
# 1.读取文件
file_rdd = sc.textFile("hdfs://Tnode1/input/SogouQ.txt")
# 2. 对数据进行切分 \t
split_rdd = file_rdd.map(lambda x: x.split("\t"))
# 3. 因为要做多个需求,split_rdd 作为基础的rdd 会被多次使用
split_rdd.persist(StorageLevel.DISK_ONLY)
# TODO:需求1:用户搜索的关键‘词’分析
# 主要分析热点词
# 将所有的搜索内容取出
# print(split_rdd.takeSample(True, 3))
context_rdd = split_rdd.map(lambda x: x[2])
# 对搜索的内容进行分词分析
words_rdd = context_rdd.flatMap(context_jieba)
# print(words_rdd.collect())
# 异常的数据:
# 数据 湖 ——> 数据湖
# 院校 帮 ——> 院校帮
# 博学 谷 ——> 博学谷
# 传智播 客——> 传智播客
filtered_rdd = words_rdd.filter(filter_words)
# 将关键词转换:传智播 --> 传智播客
final_words_rdd = filtered_rdd.map(append_words)
# 对单词进行分组、聚合、排序 求出前五名
result1 = final_words_rdd.reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(5)
print("需求1结果:", result1)
# TODO:需求2:用户和关键词组合分析
# 1,我喜欢传智播客
# 1 + 我 1+喜欢 1+传智播客
user_content_rdd = split_rdd.map(lambda x: (x[1], x[2]))
# 对用户的搜索内容进行分词,分词后和用户ID再次组合
user_word_with_one_rdd = user_content_rdd.flatMap(extract_user_and_word)
# 对内容进行分组、聚合、排序、求前5
result2 = user_word_with_one_rdd.reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(5)
print("需求2结果:", result2)
# TODO:需求3:热门搜索时间段分析
# 取出来所有的时间
time_rdd = split_rdd.map(lambda x: x[0])
# 对时间进行处理,只保留小时精度即可
hour_with_one_rdd = time_rdd.map(lambda x: (x.split(":")[0], 1))
# 分组、聚合、排序
result3 = hour_with_one_rdd.reduceByKey(add). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
collect()
print("需求3结果:", result3)
输出结果:
需求1结果: [('scala', 2310), ('hadoop', 2268), ('博学谷', 2002), ('传智汇', 1918), ('itheima', 1680)]
需求2结果: [('6185822016522959_scala', 2016), ('41641664258866384_博学谷', 1372), ('44801909258572364_hadoop', 1260), ('7044693659960919_仓库', 1120), ('15984948747597305_传智汇', 1120)]
需求3结果: [('20', 3479), ('23', 3087), ('21', 2989), ('22', 2499), ('01', 1365)
4.2 提交到集群运行
# 普通提交
/export/server/spark/bin/spark-submit --master yarn SparkDemo2.py
# 压榨集群式提交
# 每个executor吃14g内存,8核cpu,总共3个executor
/export/server/spark/bin/spark-submit --master yarn --executor-memory 14g --executor-cores 8 --num-executors 3 ./SparkDemo2.py
输出结果:

要注意代码中:
- master部分删除
- 读取的文件路径改为hdfs才可以
4.3 作业

代码演示:
# coding:utf8
from pyspark import SparkContext, StorageLevel
from pyspark import SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("sparkHomeWork01").setMaster("local[*]")
sc = SparkContext(conf=conf)
file_rdd = sc.textFile("../../data/input/apache.log")
file_rdd.persist(StorageLevel.MEMORY_AND_DISK_2)
# 需求1:TODO:计算当前网站访问的PV(被访问次数)
visit_Num = file_rdd.count()
print("当前网站的被访问次数:", visit_Num) # 14
# 需求2:TODO:当前网站访问的用户数
userNum = file_rdd.distinct().count()
print("当前网站的访问用户数:", userNum) #
# 需求3:TODO:有哪些IP访问了本网站?
Ip_rdd1 = file_rdd.map(lambda x: x.split(" "))
Ip_rdd1.cache()
Ip_rdd2 = Ip_rdd1.map(lambda x: x[0]).distinct()
# print(IP_rdd2.collect())
print("有哪些IP访问了本网站:", Ip_rdd2.collect())
# 需求4 TODO:哪个页面访问量最高
page_rdd1 = Ip_rdd1.map(lambda x:x[-1])
page_rdd2 = page_rdd1.map(lambda x:(x,1))
page_rdd3 = page_rdd2.reduceByKey(lambda a,b:a+b)
# page = page_rdd3.sortBy(lambda x:x[1],ascending=False,numPartitions=1).take(1)
page = page_rdd3.takeOrdered(1,lambda x:-x[1])
page = page[0]
print(page)
print("访问量最高的页面是:",page[0],"共被访问:",page[1],"次")
输出结果:sparkHomeWork01.py
当前网站的被访问次数: 14
当前网站的访问用户数: 9
有哪些IP访问了本网站: ['83.149.9.216', '10.0.0.1', '86.149.9.216']
('/presentations/logstash-monitorama-2013/css/print/paper.css', 13)
访问量最高的页面是: /presentations/logstash-monitorama-2013/css/print/paper.css 共被访问: 13 次