引言
今天主要介绍百度退出的大模型开放领域对话模型PLATO的三篇论文,分别对应三个模型。
- PLATO
- 132M parameters
- 8M samples
- 问题:训练稳定性和效率
- PLATO-2
- 1.6B, 314M and 93M parameters
- 684M samples
- PLATO-XL
- 11B parameters
- 811M samples for en
- 1.2B sample for chs
效果最好的还是PLATO-XL,因为参数量大,同时训练的样本也多。前面两个模型都用了隐变量,但最后那个直接是一个语言模型。
预备知识
语言模型
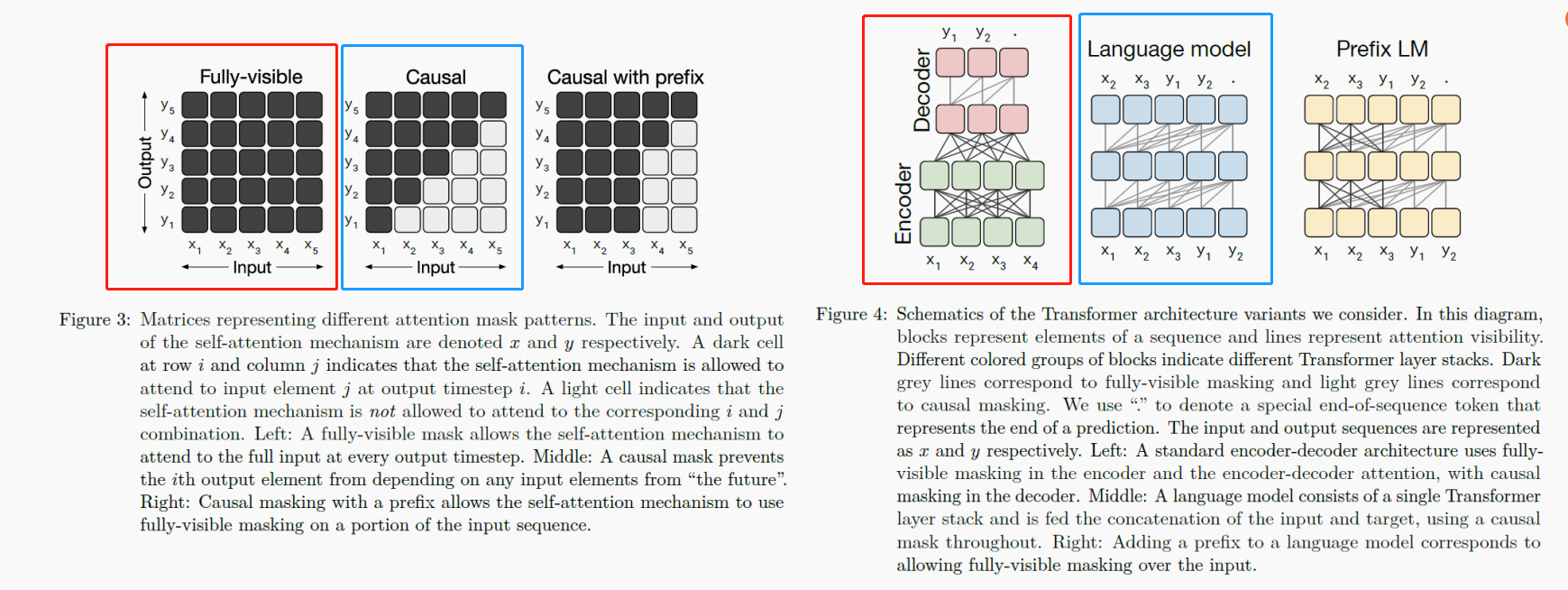
最早的Transformer是图右红框的形式,它对应一个标准的encoder-decoder架构,在encoder和encoder-decoder注意力上使用全可见的掩码;对于它的decoder来说,使用图左蓝框所示的掩码机制,只能看到目前为止的输入,也称为Causal。
有人提出了结合这两种掩码,输入由两部分组成,第一部分还是全可见的,第二部分用一个语言模型去学习。得到了图左第三种掩码方式,对应prefix languge modeling,如图右第三个所示。其中的黑线表示全可见的,灰线表示causal掩码。
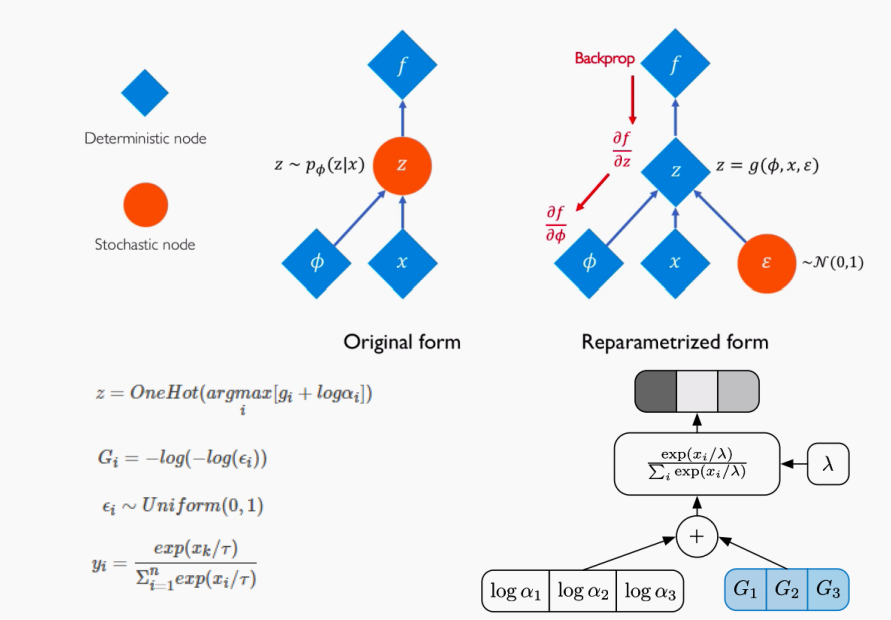
Gumbel-Softmax技巧
课程学习
课程学习(Curriculum Learning)是一种训练策略,模型人类的学习过程,让模型先从容易的样本开始学习,并逐渐进阶到复杂的样本和知识。

如果把所有的训练样本喂给模型,让模型去学习,可能得到右图最上面那条优化曲线,可以看到它有很多极值点,优化曲线非常不平坦。
此时如果说先喂给模型一些简单的样本,当模型学到一定知识之后,再把复杂的样本喂给模型学习。
上图左侧是一个图像识别任务,首先给模型少样的简单样本训练,此时得到的优化曲线如右边最下面那条所示,非常平滑,只有一个极值点,这样模型很容易学习。
然后再喂给模型更多的困难一点的样本,最后才是在整个训练集上学习。
可以用一个简单的模型来区分样本的难度。
PLATO
这是当时非常出名的一个模型,它引入了离散隐变量。
该模型考虑了对话上下文(context)、回复(response)和隐变量。这个隐变量代表context+response所属的领域。
由于没有这样的标签,它采用了无监督学习方法,在模型训练的过程中去学习这个隐变量。然后有一个超参数
K
K
K来指定有多少个隐变量,即多少种领域类别。
为什么要引入隐变量了,论文说因为语言模型在做生成任务时是一个单向模型。如果做判别任务时,一般使用masked LM,这是双向模型。然后作者认为由于单向模型看到的东西没有masked LM这种看到的多,所以效果没有后者好。引入隐变量尝试建模句子中的one-to-many关系。
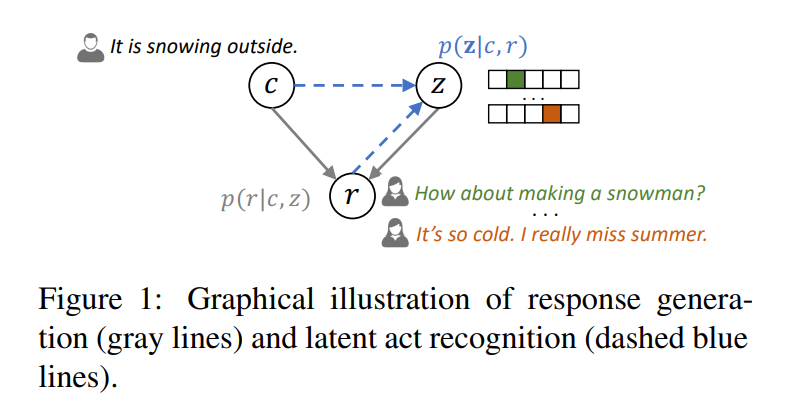
它的建模过程如上图所示,
c
c
c表示context,
r
r
r表示response,
z
z
z表示未知的隐变量,它通过one-hot来表示。
给定一个上下文 c c c和一个选择的隐变量 z z z,回复可以通过 p ( r ∣ c , z ) p(r|c,z) p(r∣c,z)来生成,如上图的灰线箭头所示;给定context和response对,底层的隐变量可以被估计为 p ( z ∣ c , r ) p(z|c,r) p(z∣c,r),如上图的蓝虚线。对应了这篇论文提出的两个任务:
- 回复生成
- 隐动作识别
架构
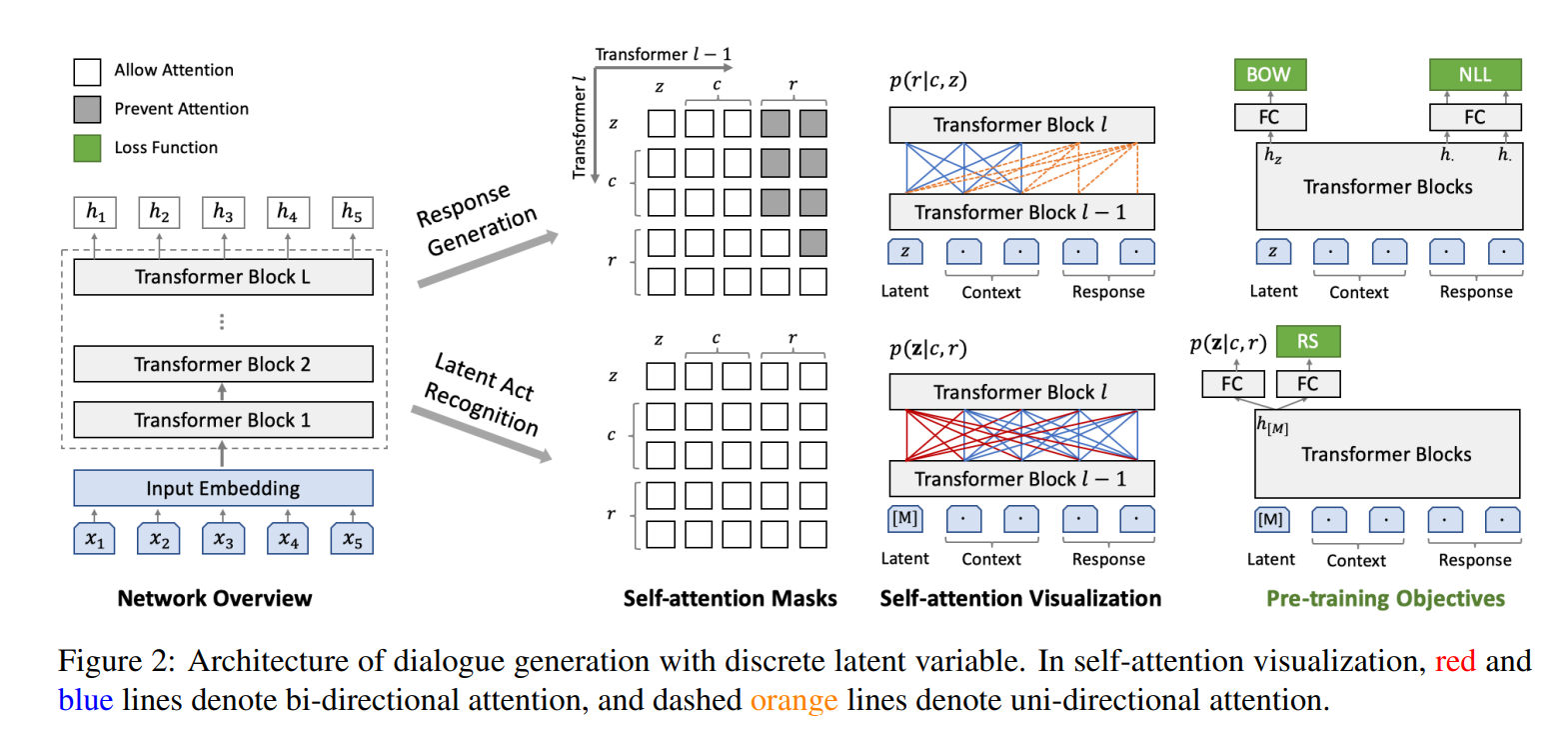
它的模型架构如上图所示。
首先也是基于Transformer (Block)。有两个任务分支,回复生成分支使用单向LM进行建模,然后给定了隐变量
z
z
z和context
c
c
c,想要去生成response
r
r
r。给输入加上了隐变量
z
z
z以和
r
<
t
r_{<t}
r<t去预测
r
t
r_t
rt。即
p
(
r
∣
c
,
z
)
=
∏
t
=
1
T
p
(
r
t
∣
c
,
z
,
r
<
t
)
p(r|c,z) = \prod_{t=1}^T p(r_t|c,z,r_{<t})
p(r∣c,z)=t=1∏Tp(rt∣c,z,r<t)
第二个任务,使用了双向LM建模,相当于用了BERT,所有的输入对模型都是可见的。给定了context和response和特定token [M]去预测所属的隐变量。相当于一个分类任务。
z
∼
p
(
z
∣
c
,
r
)
p
(
z
∣
c
,
r
)
=
softmax
(
W
1
h
[
M
]
+
b
1
)
∈
R
K
z ∼ p(\pmb z|c,r) \\ p(\pmb z|c,r) = \text{softmax}(W_1h_{[M]} + b_1) \in \Bbb R^K
z∼p(z∣c,r)p(z∣c,r)=softmax(W1h[M]+b1)∈RK
然后通过隐变量
z
z
z学到的双向LM,反哺第一个任务,因为这两个任务中的Transformer是参数共享的。作者通过这种方式解决上面提到的单向LM的问题。
输入表示
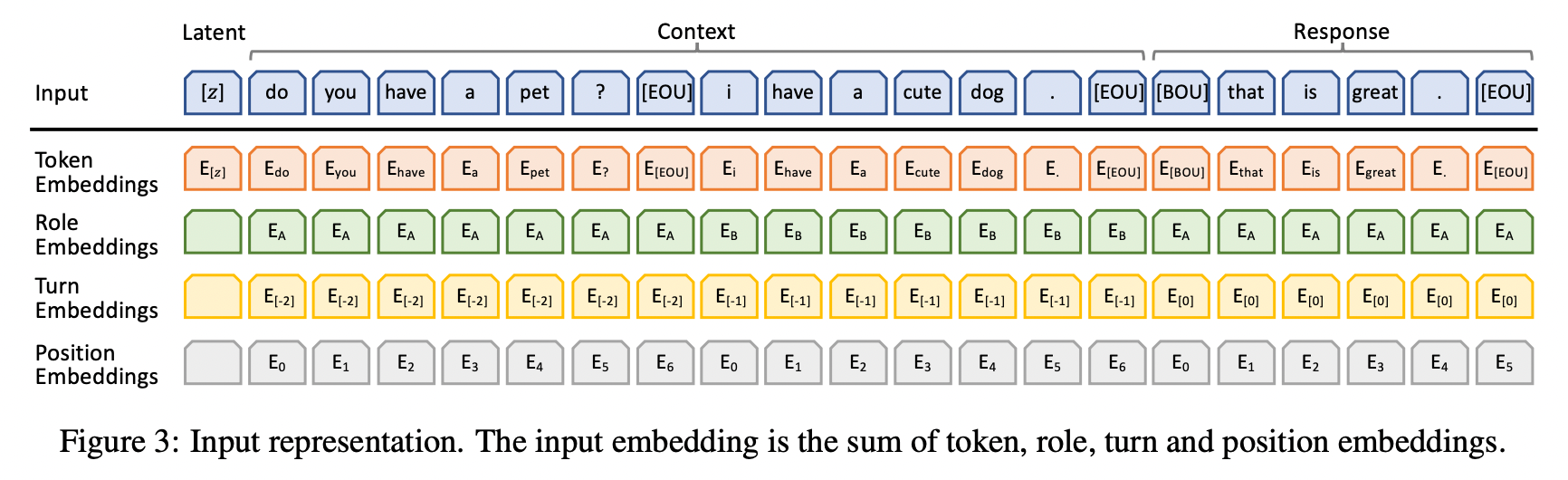
如上图所示,模型的嵌入包含了四部分:
- token
- special mask token
[M] - end-of-utterance
[EOU] - begin-of-utterance [
BOU] - latent E z ∈ R K × D E_z \in \Bbb R^{K \times D} Ez∈RK×D
- special mask token
- role
- turn
- position
有四种token,token 和 position 嵌入和Transformer模型一样。针对对话任务额外加了role和turn 嵌入。
role表示系统和用户的不同角色;turn表示多轮对话。
预训练目标
在对话生成预训练中有三个损失: 负对数似然(negative log-likelihood,NLL)、词袋(bag-of-words,BOW)以及回复选择(response select,RS)损失。
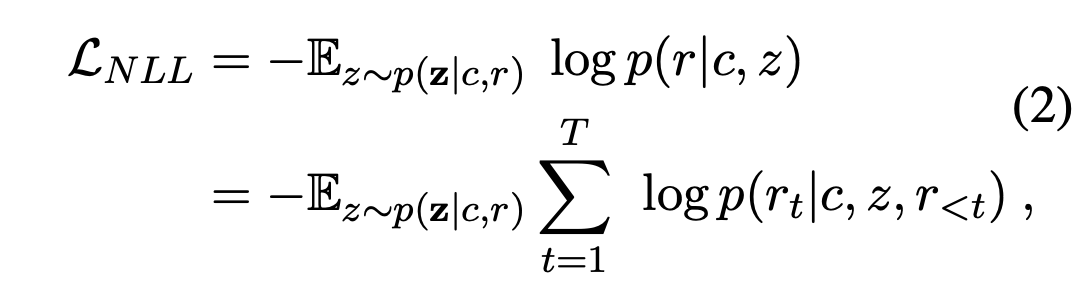
回复是基于因变量
z
z
z和上下文
c
c
c生成的。
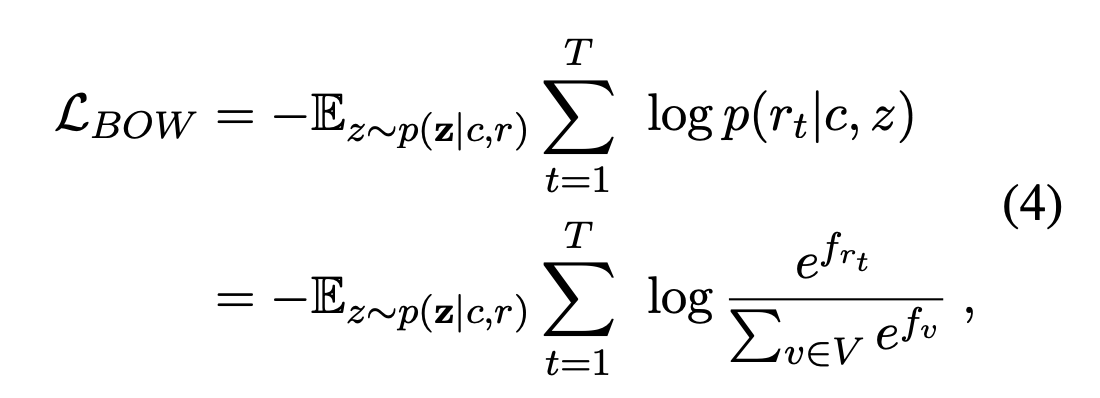
为了训练离散隐变量,引入了BOW损失。希望能学到全局信息。
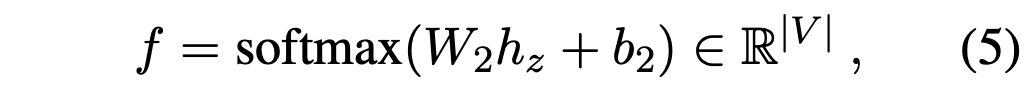
这里
V
V
V代表整个词典,函数
f
f
f尝试通过非回归的方式预测目标回复。这里
h
z
h_z
hz是隐变量的最终隐藏状态。
f
r
t
f_{r_t}
frt表示单词
r
t
r_t
rt的概率。
与NLL损失相比,BOW损失抛弃了单词的顺序信息,迫使隐变量去捕获目标回复的全局信息。
为了训练隐变量,还引入了回复选择损失。
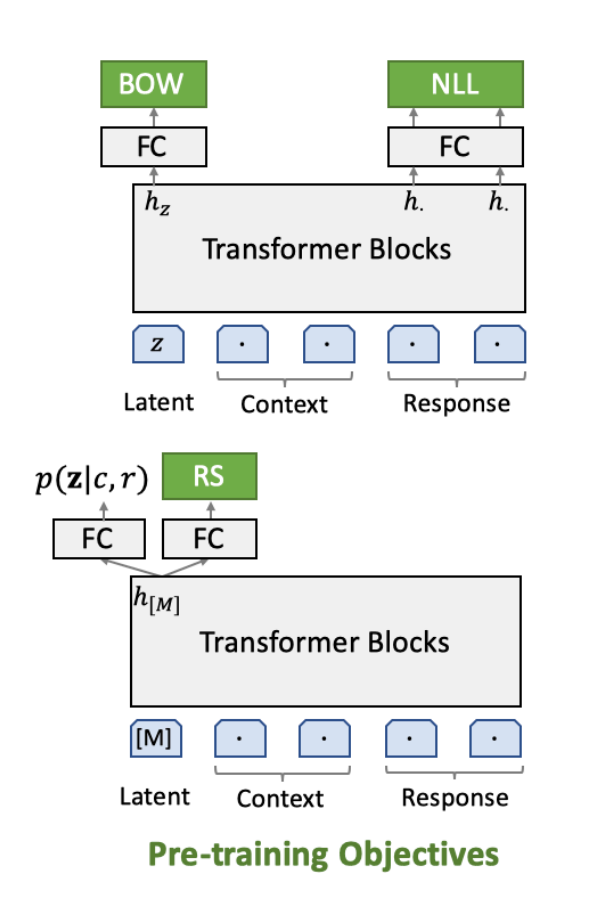
如上图所示,在Transformer Block自后分出了两个head,右边的FC用于RS任务。
回复选择主要用于区分回复是否与对话上下文相关,并且要与背景知识一致。同时它的得分可以被看成是连贯性的指标,帮助从候选回复中选择最连贯的那个。
回复选择是和latent act recognition的双向编码一起训练的。正样本是来自对话上下文以及对应的目标响应对
(
c
,
r
)
(c,r)
(c,r),它的标签
l
r
=
1
l_r=1
lr=1;负样本是随机从语料
(
c
,
r
−
)
(c,r^-)
(c,r−)中选择,标签为
l
r
−
=
0
l_{r^-}=0
lr−=0。
回复选择的二元交叉熵损失定义为:
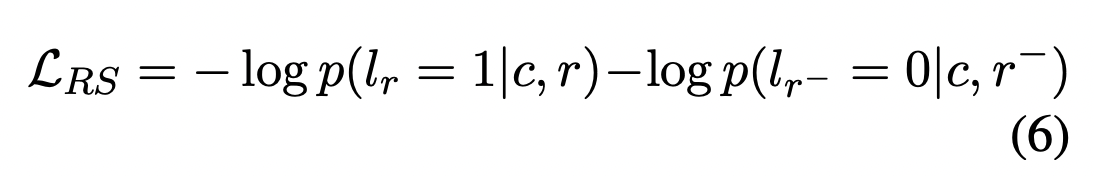
训练过程
- 隐动作识别(Latent Act Recognition)
- 给定上下文和目标回复对,估计后验概率 p ( z ∣ c , r ) p(\pmb z|c,r) p(z∣c,r)
- 随机选择 r − r^- r−并计算 L R S \mathcal{L}_{RS} LRS
- 回复选择
- 用采样的隐变量 z ∼ p ( z ∣ c , r ) z ∼ p(\pmb z|c,r) z∼p(z∣c,r)计算 L N L L \mathcal{L}_{NLL} LNLL和 L B O W \mathcal{L}_{BOW} LBOW
- 优化
- 累加这三个损失,用反向传播算法更新网络参数
微调和推理
- 候选回复选择
- 基于每个隐变量 z ∈ [ 1 , K ] z \in [1,K] z∈[1,K],生成对应的候选回复 r r r
- 回复选择
- 计算每个回复的 p ( l r = 1 ∣ c , r ) p(l_r=1|c,r) p(lr=1∣c,r),并选择值最大的作为最终的回复
这里由于不知道预测时隐变量是什么,所以暴力地选择了所有的隐变量,最终选择得分最高的回复。
PLATO-2
作者在训练PLATO-1的时候发现训练过程非常不稳定,并且效果低下。而PLATO-2的参数量更大,导致更加无法训练,因此引入了课程学习的概念。
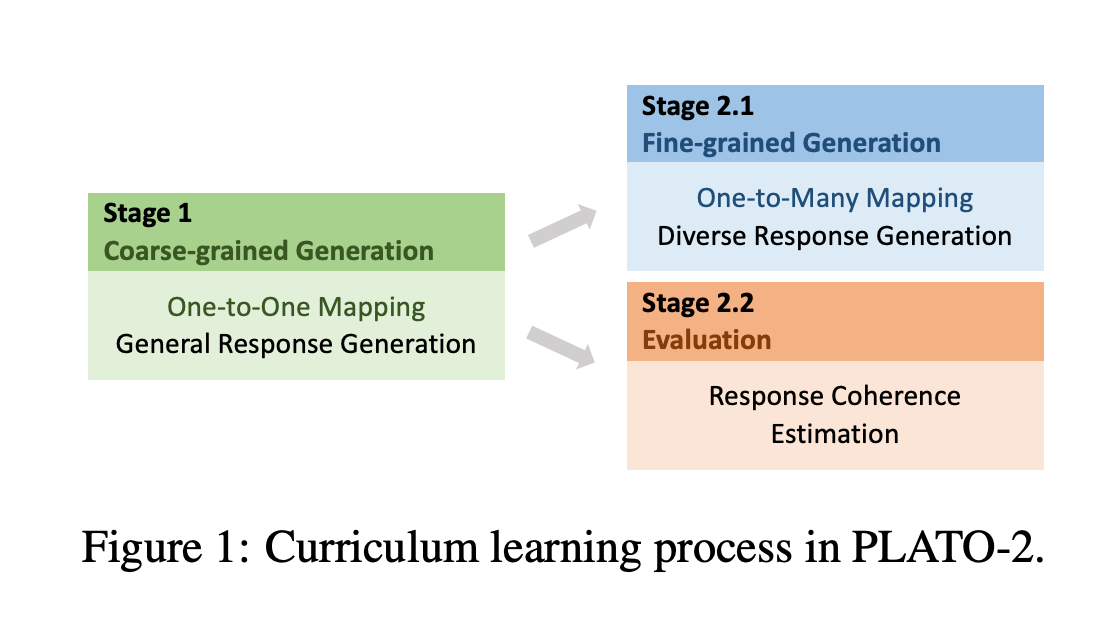
训练
既然PLATO-1的模型很难训练,那么在训练PLATO-2的时候,阶段一先训练一个简单的模型,得到一个相对较好的模型后,在阶段二的时候再进行充分训练。
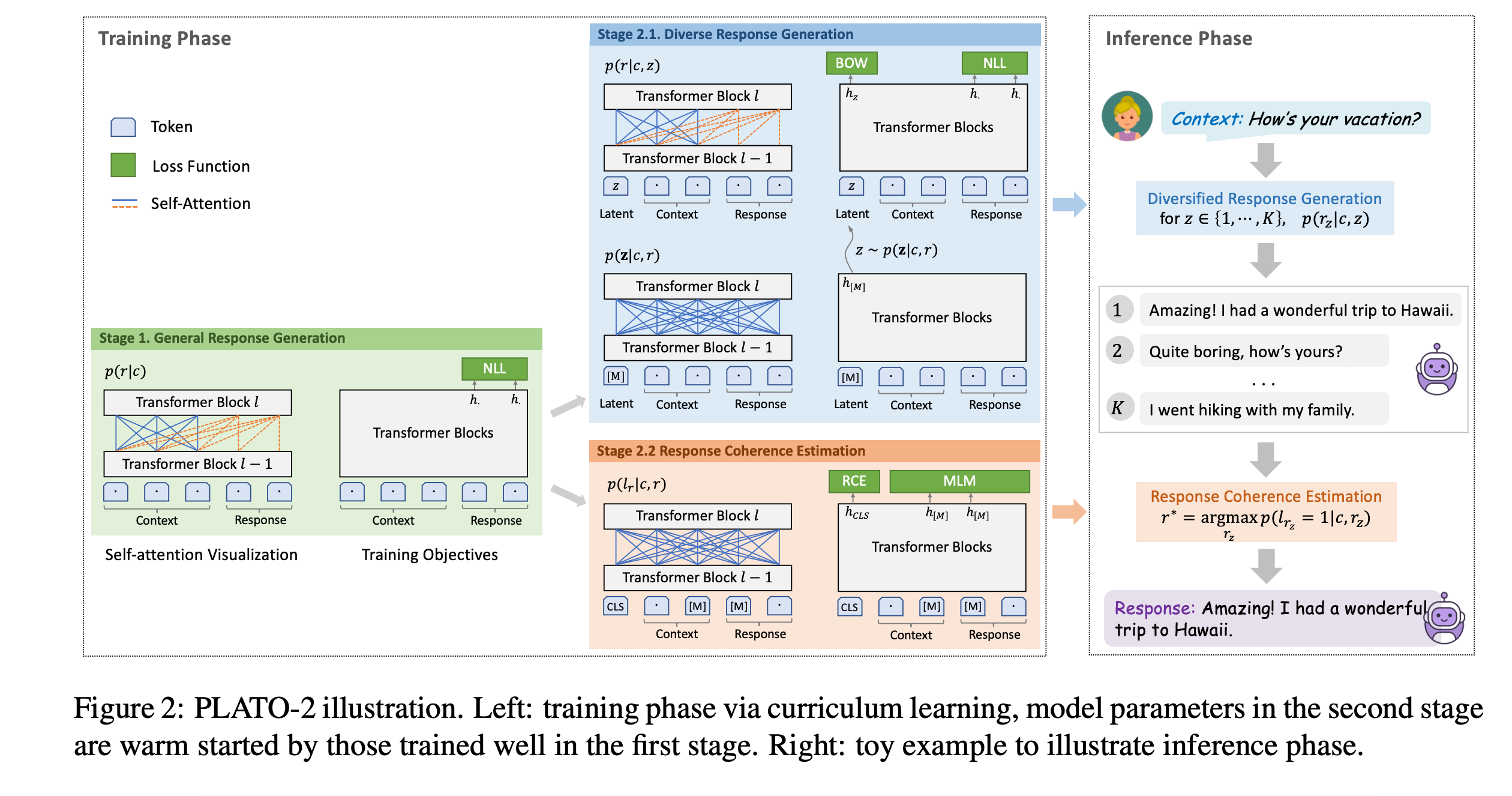
PLATO-2的图示如上。
一个输入对应一个输出是one-to-one;一个context对应多个合法的回复是one-to-many。
左边绿色的是一个Transformer,代表阶段一。右边橙色和蓝色代表阶段二的两个任务。
阶段一是就是一个简单的one-to-one映射模型,一个粗粒度的生成模型在不同的对话上下文中进行训练。该模型尝试捕获多元回复的模式,在推理时有时会生成通用和无聊的回复。
尽管有这些问题,该粗粒度的模型仍然在学习回复生成通用概念时表现的很高效。
阶段二基于阶段一的模型训练一个细粒度的生成模型和一个评估模型。细粒度读生成模型通过隐变量来学习多元回复生成的one-to-many映射关系。为了选择最合适的回复,一个评估模型被训练来评估该对话上下文和回复之间的连贯性。
在回复连贯性评估时加入了类似BERT的掩码语言模型任务,同时RS改名为RCE。
阶段一是粗粒度的one-to-one映射训练,给定上下文生成回复。
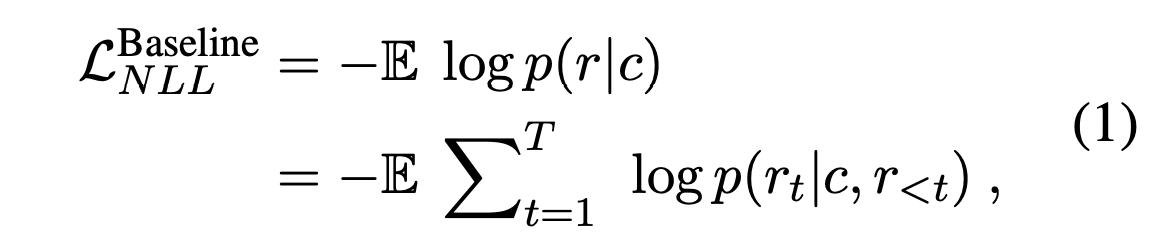
阶段二第一部分 是一个细粒度的one-to-many(微调)训练,包含两个损失:
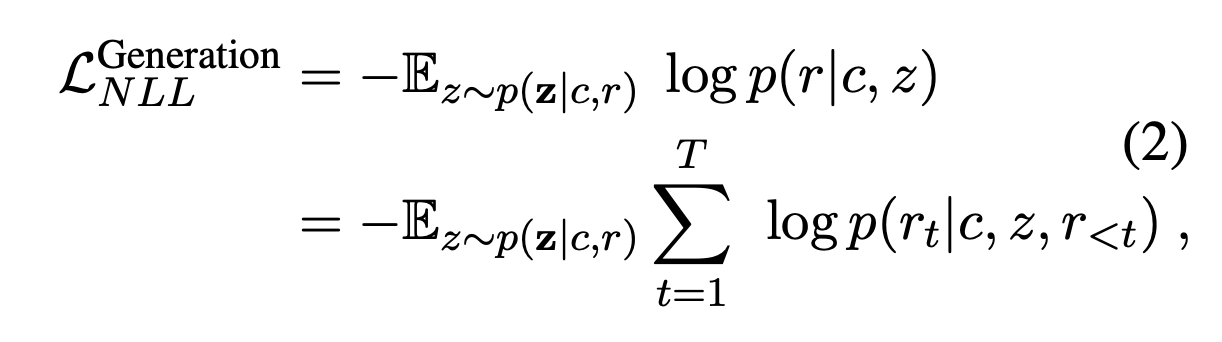
给定同一个上下文,输入不同的隐变量可以得到多个回复,就是one-to-many。
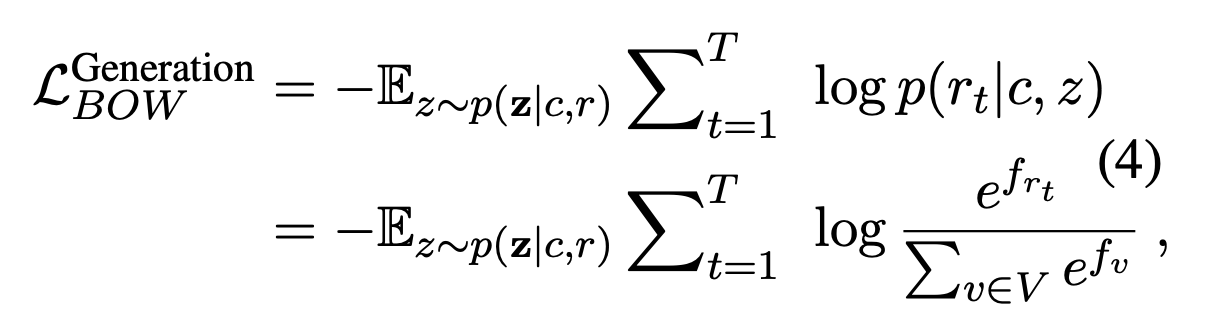
也有BOW损失,和PLATO-1类似。
阶段二第二部分对RS任务进行了改进,由回复选择(response select,RS)变成了回复连贯评估(response coherence estimation,RCE)。
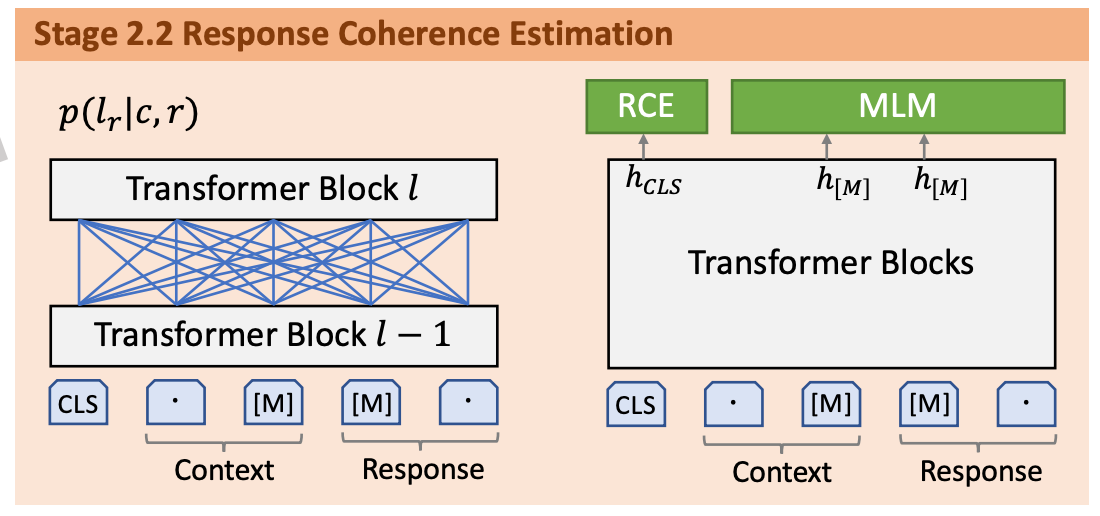
通过为隐变量分配不同的值,细粒度的生成模型能产生多个高质量且多样化的响应。为了从这些候选响应中选择最合适的,一个直接的方式是通过
p
(
z
∣
c
)
p
(
r
∣
c
,
z
)
p(z|c)p(r|c,z)
p(z∣c)p(r∣c,z)的值对它们进行排序。然而,先验非分布
p
(
z
∣
c
)
p(\pmb z|c)
p(z∣c)是很难评估。因此,这里选择另一种途经去训练和评估模型,即评估回复和给定对话上下文之间的连贯性。回复连贯性评估的损失定义为:
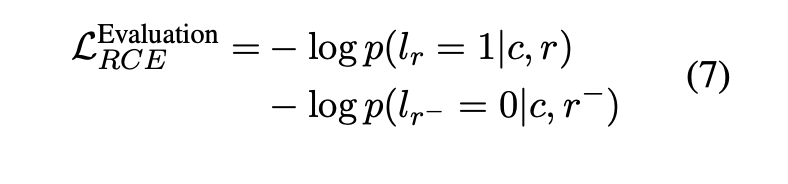
同时加入了masked langugae model任务:
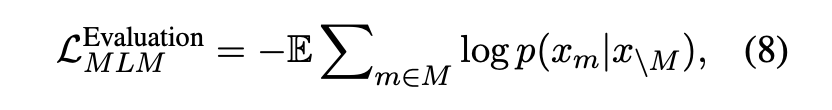
即随机mask掉一些token,需要还原被mask掉的token。
最终的损失就是它们两加起来。
推理
推理和PLATO-1基本一致,对于开放域对话,第二阶段的推理如下:
- 多样化候选回复生成
- 基于每个隐变量 z ∈ { 1 , ⋯ , K } z \in \{1,\cdots ,K\} z∈{1,⋯,K},它对应的候选回复 r z r_z rz通过细粒度生成模型 p ( r z ∣ c , z ) p(r_z|c,z) p(rz∣c,z)产生。
- 回复连贯评估
- 评估模型会进行排序并选择最大连贯值的回复 r ∗ = arg max r z p ( l r z = 1 ∣ c , r z ) r^*=\arg\max _{r_z} p(l_{r_z}=1|c,r_z) r∗=argmaxrzp(lrz=1∣c,rz)。
PLATO-XL
PLATO-XL是这一系列效果最好、参数量最大且思想最简单的。
它有11B(110亿)的参数量,同时在中文和英文对话中训练。
模型
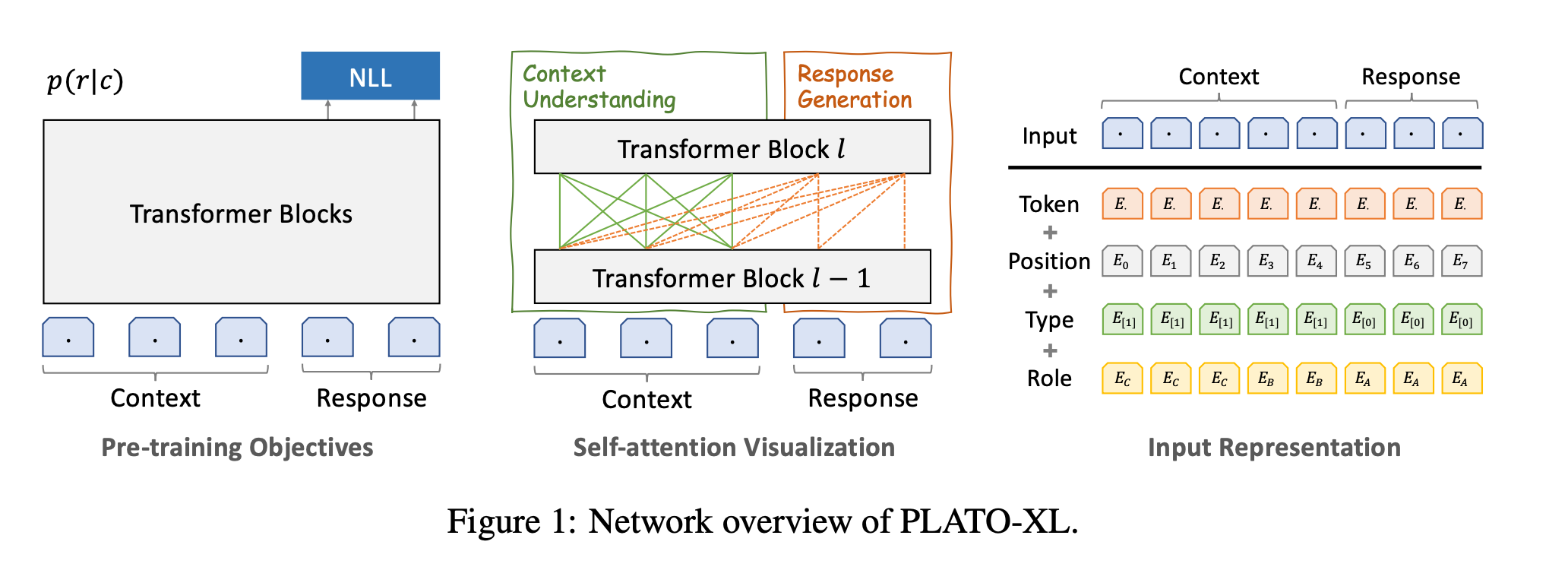
在PLATO-XL中,预训练目标只是最小化最大似然损失:
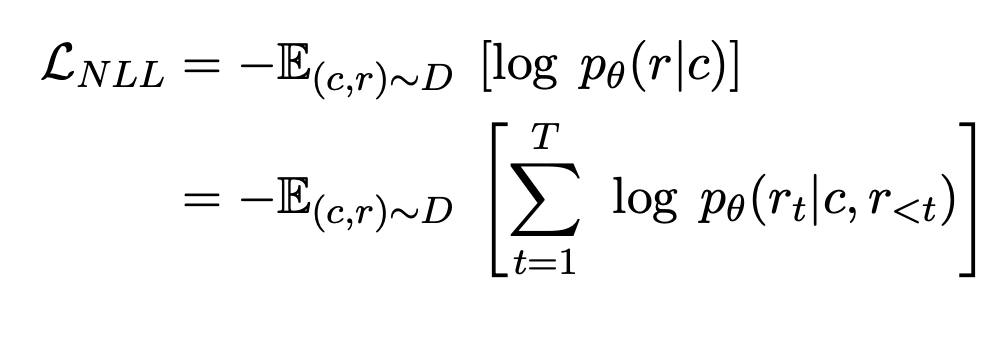
抛弃了前两个版本中的隐变量。
相比PLATO-1中,在输入表示上把turn 嵌入换成了type嵌入;role嵌入可以表示多人对话(群聊)。
role变成了多人,type表示提问/回复。
Multi-Party Aware Pre-training

什么叫multi-party呢?由于数据是从论坛中得到的,而论坛中的一个贴子可能有多个人去回复。而对于每个人的回复,还有可能有多个人去继续提问/回复。所以它是一个树形结构,这种结构就是multi-party。
参考
- 贪心学院课程
- Unified Language Model Pre-training for Natural Language Understanding and Generation
- CATEGORICAL REPARAMETERIZATION WITH GUMBEL-SOFTMAX
- A Survey on Curriculum Learning
- PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable
- PLATO-2: Towards Building an Open-Domain Chatbot via Curriculum Learning
- PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation