系列实验
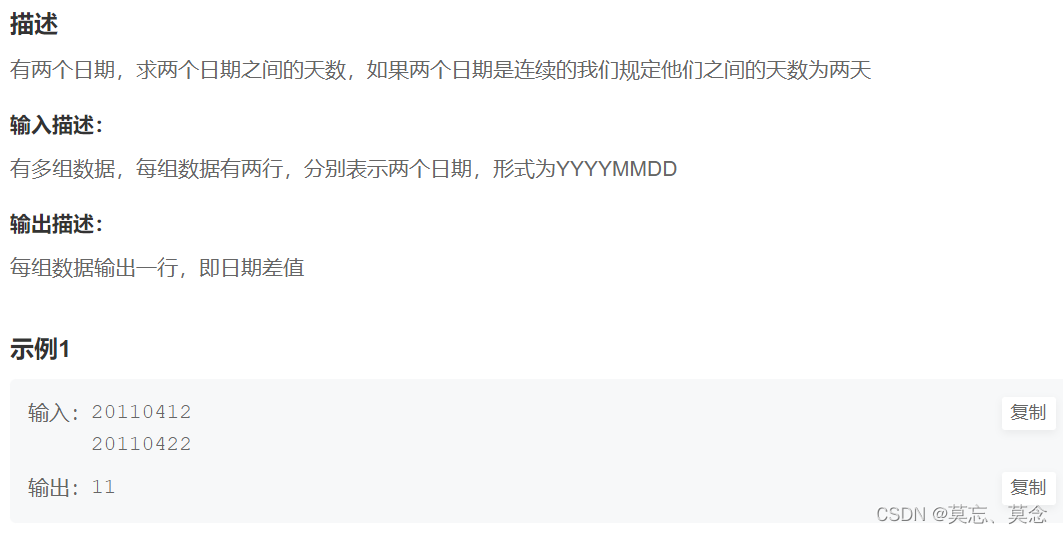
深度学习实践——卷积神经网络实践:裂缝识别
深度学习实践——循环神经网络实践
深度学习实践——模型部署优化实践
深度学习实践——模型推理优化练习
深度学习实践——模型推理优化练习
- 模型推理优化练习
- 架构设计练习
- 知识蒸馏练习
- 模型剪枝练习
- 参数量化练习
- 算式检测模型压缩优化
- 未优化前模型的大小与速度
- 算式检测模型剪枝
- 算式检测模型量化
- 算式识别模型压缩优化
- 实验结论
源码地址: https://pan.baidu.com/s/1PuWZF2DkG0-F5pQLMIkTcQ?pwd=c24s
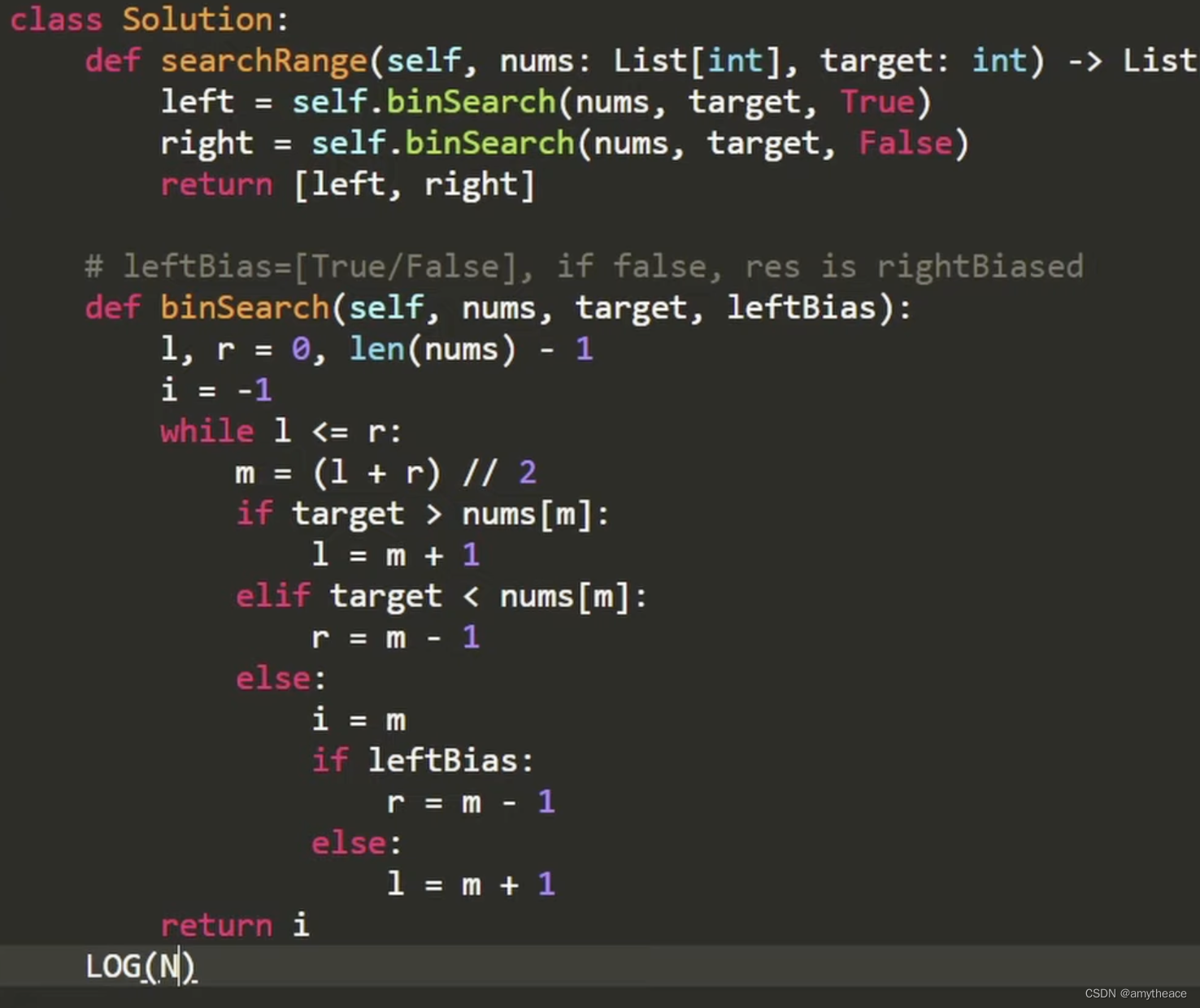
模型推理优化练习
架构设计练习
通过代码修改,探索StudentNet中各参数对模型参数量的影响。
架构设计上的优化压缩,主要是通过减少神经网络的参数量来进行。在这里可以通过增减通道数,对通道数进行剪枝来对模型进行压缩优化。在网站所给的源码中,模型提供了两个参数对通道进行调整,首先是base参数,此参数直接用于定义初始的神经元的通道数。其次是width_mult,此参数是剪枝控制因子,为1时表示不剪枝。剪枝后通道数=剪枝前通道数*width_mult。
根据对参数的理解可以知道,base越小那么模型压缩得越小,同样width_mult越小也会压缩得越小。下面通过修改代码来验证假想。
-
默认参数输出
首先输出默认值的神经网络层与对于的参数大小:
主要代码如下,完整代码见于
架构设计练习.pymodel_default = StudentNet() model_default.eval() summary(model_default.to('cuda:0'), input_size=(3, 128, 128))上面代码对应的输出结果如下,
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 16, 128, 128] 448 BatchNorm2d-2 [-1, 16, 128, 128] 32 ReLU6-3 [-1, 16, 128, 128] 0 MaxPool2d-4 [-1, 16, 64, 64] 0 Conv2d-5 [-1, 16, 64, 64] 160 BatchNorm2d-6 [-1, 16, 64, 64] 32 ReLU6-7 [-1, 16, 64, 64] 0 Conv2d-8 [-1, 32, 64, 64] 544 MaxPool2d-9 [-1, 32, 32, 32] 0 Conv2d-10 [-1, 32, 32, 32] 320 BatchNorm2d-11 [-1, 32, 32, 32] 64 ReLU6-12 [-1, 32, 32, 32] 0 Conv2d-13 [-1, 64, 32, 32] 2,112 MaxPool2d-14 [-1, 64, 16, 16] 0 Conv2d-15 [-1, 64, 16, 16] 640 BatchNorm2d-16 [-1, 64, 16, 16] 128 ReLU6-17 [-1, 64, 16, 16] 0 Conv2d-18 [-1, 128, 16, 16] 8,320 MaxPool2d-19 [-1, 128, 8, 8] 0 Conv2d-20 [-1, 128, 8, 8] 1,280 BatchNorm2d-21 [-1, 128, 8, 8] 256 ReLU6-22 [-1, 128, 8, 8] 0 Conv2d-23 [-1, 256, 8, 8] 33,024 Conv2d-24 [-1, 256, 8, 8] 2,560 BatchNorm2d-25 [-1, 256, 8, 8] 512 ReLU6-26 [-1, 256, 8, 8] 0 Conv2d-27 [-1, 256, 8, 8] 65,792 Conv2d-28 [-1, 256, 8, 8] 2,560 BatchNorm2d-29 [-1, 256, 8, 8] 512 ReLU6-30 [-1, 256, 8, 8] 0 Conv2d-31 [-1, 256, 8, 8] 65,792 Conv2d-32 [-1, 256, 8, 8] 2,560 BatchNorm2d-33 [-1, 256, 8, 8] 512 ReLU6-34 [-1, 256, 8, 8] 0 Conv2d-35 [-1, 256, 8, 8] 65,792 AdaptiveAvgPool2d-36 [-1, 256, 1, 1] 0 Linear-37 [-1, 11] 2,827 ================================================================ Total params: 256,779 Trainable params: 256,779 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.19 Forward/backward pass size (MB): 13.13 Params size (MB): 0.98 Estimated Total Size (MB): 14.29 ---------------------------------------------------------------- -
降低base值的结果
model_base12 = StudentNet(base=12) model_base12.eval() summary(model_base12.to('cuda:0'), input_size=(3, 128, 128))其结果如下:
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 12, 128, 128] 336 BatchNorm2d-2 [-1, 12, 128, 128] 24 ReLU6-3 [-1, 12, 128, 128] 0 MaxPool2d-4 [-1, 12, 64, 64] 0 Conv2d-5 [-1, 12, 64, 64] 120 BatchNorm2d-6 [-1, 12, 64, 64] 24 ReLU6-7 [-1, 12, 64, 64] 0 Conv2d-8 [-1, 24, 64, 64] 312 MaxPool2d-9 [-1, 24, 32, 32] 0 Conv2d-10 [-1, 24, 32, 32] 240 BatchNorm2d-11 [-1, 24, 32, 32] 48 ReLU6-12 [-1, 24, 32, 32] 0 Conv2d-13 [-1, 48, 32, 32] 1,200 MaxPool2d-14 [-1, 48, 16, 16] 0 Conv2d-15 [-1, 48, 16, 16] 480 BatchNorm2d-16 [-1, 48, 16, 16] 96 ReLU6-17 [-1, 48, 16, 16] 0 Conv2d-18 [-1, 96, 16, 16] 4,704 MaxPool2d-19 [-1, 96, 8, 8] 0 Conv2d-20 [-1, 96, 8, 8] 960 BatchNorm2d-21 [-1, 96, 8, 8] 192 ReLU6-22 [-1, 96, 8, 8] 0 Conv2d-23 [-1, 192, 8, 8] 18,624 Conv2d-24 [-1, 192, 8, 8] 1,920 BatchNorm2d-25 [-1, 192, 8, 8] 384 ReLU6-26 [-1, 192, 8, 8] 0 Conv2d-27 [-1, 192, 8, 8] 37,056 Conv2d-28 [-1, 192, 8, 8] 1,920 BatchNorm2d-29 [-1, 192, 8, 8] 384 ReLU6-30 [-1, 192, 8, 8] 0 Conv2d-31 [-1, 192, 8, 8] 37,056 Conv2d-32 [-1, 192, 8, 8] 1,920 BatchNorm2d-33 [-1, 192, 8, 8] 384 ReLU6-34 [-1, 192, 8, 8] 0 Conv2d-35 [-1, 192, 8, 8] 37,056 AdaptiveAvgPool2d-36 [-1, 192, 1, 1] 0 Linear-37 [-1, 11] 2,123 ================================================================ Total params: 147,563 Trainable params: 147,563 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.19 Forward/backward pass size (MB): 9.85 Params size (MB): 0.56 Estimated Total Size (MB): 10.60 ----------------------------------------------------------------可以看到与默认值相比,网络层的变量数减少了,网络层发送了变化,对模型进行了压缩。再依次减少base值,以模型为因变量base值为自变量可绘制下图。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5yJ5K1o0-1690719177660)(D:\学习资料\大三上\大三上资料\大三上资料\深度学习实践\作业\实验\实验5\文档记录.assets\image-20221203181501324.png)]](https://img-blog.csdnimg.cn/313d2fb2f1b34bf98c07eccc12d0d45a.png)
可知模型的大小与base值基本成正比关系。
-
降低width_mult值的结果
model_mul0_8 = StudentNet(width_mult=0.8) model_mul0_8.eval() summary(model_mul0_8.to('cuda:0'), input_size=(3, 128, 128))其结果如下:
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 16, 128, 128] 448 BatchNorm2d-2 [-1, 16, 128, 128] 32 ReLU6-3 [-1, 16, 128, 128] 0 MaxPool2d-4 [-1, 16, 64, 64] 0 Conv2d-5 [-1, 16, 64, 64] 160 BatchNorm2d-6 [-1, 16, 64, 64] 32 ReLU6-7 [-1, 16, 64, 64] 0 Conv2d-8 [-1, 32, 64, 64] 544 MaxPool2d-9 [-1, 32, 32, 32] 0 Conv2d-10 [-1, 32, 32, 32] 320 BatchNorm2d-11 [-1, 32, 32, 32] 64 ReLU6-12 [-1, 32, 32, 32] 0 Conv2d-13 [-1, 64, 32, 32] 2,112 MaxPool2d-14 [-1, 64, 16, 16] 0 Conv2d-15 [-1, 64, 16, 16] 640 BatchNorm2d-16 [-1, 64, 16, 16] 128 ReLU6-17 [-1, 64, 16, 16] 0 Conv2d-18 [-1, 102, 16, 16] 6,630 MaxPool2d-19 [-1, 102, 8, 8] 0 Conv2d-20 [-1, 102, 8, 8] 1,020 BatchNorm2d-21 [-1, 102, 8, 8] 204 ReLU6-22 [-1, 102, 8, 8] 0 Conv2d-23 [-1, 204, 8, 8] 21,012 Conv2d-24 [-1, 204, 8, 8] 2,040 BatchNorm2d-25 [-1, 204, 8, 8] 408 ReLU6-26 [-1, 204, 8, 8] 0 Conv2d-27 [-1, 204, 8, 8] 41,820 Conv2d-28 [-1, 204, 8, 8] 2,040 BatchNorm2d-29 [-1, 204, 8, 8] 408 ReLU6-30 [-1, 204, 8, 8] 0 Conv2d-31 [-1, 204, 8, 8] 41,820 Conv2d-32 [-1, 204, 8, 8] 2,040 BatchNorm2d-33 [-1, 204, 8, 8] 408 ReLU6-34 [-1, 204, 8, 8] 0 Conv2d-35 [-1, 256, 8, 8] 52,480 AdaptiveAvgPool2d-36 [-1, 256, 1, 1] 0 Linear-37 [-1, 11] 2,827 ================================================================ Total params: 179,637 Trainable params: 179,637 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.19 Forward/backward pass size (MB): 12.72 Params size (MB): 0.69 Estimated Total Size (MB): 13.59 ----------------------------------------------------------------![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-54YtLAKD-1690719177661)(D:\学习资料\大三上\大三上资料\大三上资料\深度学习实践\作业\实验\实验5\文档记录.assets\image-20221203182537114.png)]](https://img-blog.csdnimg.cn/7f6e0692ec5644ad8da087d0c8030156.png)
可知模型的大小与width_mul值基本成正比例关系,但是相对于base值其压缩的范围有限。
知识蒸馏练习
从案例中可以看出蒸馏后的student模型相比预训练的teacher模型,在性能上下降很多。请分析原因,并探索进一步提升student模型性能的方法。.
原因:
从网站的案例中可知,学生网络已经训练了很多轮次,理论上应该与教师网络的准确度相似,但是从结果可知还是差了很多。学生网络与教师网络有两大区别,其中之一是教师网路已经进行了充分训练,而学生网络一开始并未进行训练;其二是学生网络与教师网络的结构并不一致。
对于第一个不同,可以通过知识蒸馏的方法进行充分训练而消除,而第二个则不能。于是其性能不如教师网络的很大一个原因应该是其网络结构。于是打印教师网络和学生网络的结构进行对比,通过如下代码(具体代码见知识蒸馏.py)进行打印。
teacher_net = models.resnet18(pretrained=False, num_classes=11)
teacher_net.load_state_dict(torch.load(f'./teacher_resnet18.bin'))
student_net = StudentNet(base=16)
print("teacher Net")
summary(teacher_net.to('cuda:0'), input_size=(3, 128, 128))
print("\n\n\nstudent Net")
summary(student_net.to('cuda:0'), input_size=(3, 128, 128))
-
教师网络
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 64, 64, 64] 9,408 BatchNorm2d-2 [-1, 64, 64, 64] 128 ReLU-3 [-1, 64, 64, 64] 0 MaxPool2d-4 [-1, 64, 32, 32] 0 Conv2d-5 [-1, 64, 32, 32] 36,864 BatchNorm2d-6 [-1, 64, 32, 32] 128 ReLU-7 [-1, 64, 32, 32] 0 Conv2d-8 [-1, 64, 32, 32] 36,864 BatchNorm2d-9 [-1, 64, 32, 32] 128 ReLU-10 [-1, 64, 32, 32] 0 BasicBlock-11 [-1, 64, 32, 32] 0 Conv2d-12 [-1, 64, 32, 32] 36,864 BatchNorm2d-13 [-1, 64, 32, 32] 128 ReLU-14 [-1, 64, 32, 32] 0 Conv2d-15 [-1, 64, 32, 32] 36,864 BatchNorm2d-16 [-1, 64, 32, 32] 128 ReLU-17 [-1, 64, 32, 32] 0 BasicBlock-18 [-1, 64, 32, 32] 0 Conv2d-19 [-1, 128, 16, 16] 73,728 BatchNorm2d-20 [-1, 128, 16, 16] 256 ReLU-21 [-1, 128, 16, 16] 0 Conv2d-22 [-1, 128, 16, 16] 147,456 BatchNorm2d-23 [-1, 128, 16, 16] 256 Conv2d-24 [-1, 128, 16, 16] 8,192 BatchNorm2d-25 [-1, 128, 16, 16] 256 ReLU-26 [-1, 128, 16, 16] 0 BasicBlock-27 [-1, 128, 16, 16] 0 Conv2d-28 [-1, 128, 16, 16] 147,456 BatchNorm2d-29 [-1, 128, 16, 16] 256 ReLU-30 [-1, 128, 16, 16] 0 Conv2d-31 [-1, 128, 16, 16] 147,456 BatchNorm2d-32 [-1, 128, 16, 16] 256 ReLU-33 [-1, 128, 16, 16] 0 BasicBlock-34 [-1, 128, 16, 16] 0 Conv2d-35 [-1, 256, 8, 8] 294,912 BatchNorm2d-36 [-1, 256, 8, 8] 512 ReLU-37 [-1, 256, 8, 8] 0 Conv2d-38 [-1, 256, 8, 8] 589,824 BatchNorm2d-39 [-1, 256, 8, 8] 512 Conv2d-40 [-1, 256, 8, 8] 32,768 BatchNorm2d-41 [-1, 256, 8, 8] 512 ReLU-42 [-1, 256, 8, 8] 0 BasicBlock-43 [-1, 256, 8, 8] 0 Conv2d-44 [-1, 256, 8, 8] 589,824 BatchNorm2d-45 [-1, 256, 8, 8] 512 ReLU-46 [-1, 256, 8, 8] 0 Conv2d-47 [-1, 256, 8, 8] 589,824 BatchNorm2d-48 [-1, 256, 8, 8] 512 ReLU-49 [-1, 256, 8, 8] 0 BasicBlock-50 [-1, 256, 8, 8] 0 Conv2d-51 [-1, 512, 4, 4] 1,179,648 BatchNorm2d-52 [-1, 512, 4, 4] 1,024 ReLU-53 [-1, 512, 4, 4] 0 Conv2d-54 [-1, 512, 4, 4] 2,359,296 BatchNorm2d-55 [-1, 512, 4, 4] 1,024 Conv2d-56 [-1, 512, 4, 4] 131,072 BatchNorm2d-57 [-1, 512, 4, 4] 1,024 ReLU-58 [-1, 512, 4, 4] 0 BasicBlock-59 [-1, 512, 4, 4] 0 Conv2d-60 [-1, 512, 4, 4] 2,359,296 BatchNorm2d-61 [-1, 512, 4, 4] 1,024 ReLU-62 [-1, 512, 4, 4] 0 Conv2d-63 [-1, 512, 4, 4] 2,359,296 BatchNorm2d-64 [-1, 512, 4, 4] 1,024 ReLU-65 [-1, 512, 4, 4] 0 BasicBlock-66 [-1, 512, 4, 4] 0 AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0 Linear-68 [-1, 11] 5,643 ================================================================ Total params: 11,182,155 Trainable params: 11,182,155 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.19 Forward/backward pass size (MB): 20.50 Params size (MB): 42.66 Estimated Total Size (MB): 63.35 ---------------------------------------------------------------- -
学生网络
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 16, 128, 128] 448 BatchNorm2d-2 [-1, 16, 128, 128] 32 ReLU6-3 [-1, 16, 128, 128] 0 MaxPool2d-4 [-1, 16, 64, 64] 0 Conv2d-5 [-1, 16, 64, 64] 160 BatchNorm2d-6 [-1, 16, 64, 64] 32 ReLU6-7 [-1, 16, 64, 64] 0 Conv2d-8 [-1, 32, 64, 64] 544 MaxPool2d-9 [-1, 32, 32, 32] 0 Conv2d-10 [-1, 32, 32, 32] 320 BatchNorm2d-11 [-1, 32, 32, 32] 64 ReLU6-12 [-1, 32, 32, 32] 0 Conv2d-13 [-1, 64, 32, 32] 2,112 MaxPool2d-14 [-1, 64, 16, 16] 0 Conv2d-15 [-1, 64, 16, 16] 640 BatchNorm2d-16 [-1, 64, 16, 16] 128 ReLU6-17 [-1, 64, 16, 16] 0 Conv2d-18 [-1, 128, 16, 16] 8,320 MaxPool2d-19 [-1, 128, 8, 8] 0 Conv2d-20 [-1, 128, 8, 8] 1,280 BatchNorm2d-21 [-1, 128, 8, 8] 256 ReLU6-22 [-1, 128, 8, 8] 0 Conv2d-23 [-1, 256, 8, 8] 33,024 Conv2d-24 [-1, 256, 8, 8] 2,560 BatchNorm2d-25 [-1, 256, 8, 8] 512 ReLU6-26 [-1, 256, 8, 8] 0 Conv2d-27 [-1, 256, 8, 8] 65,792 Conv2d-28 [-1, 256, 8, 8] 2,560 BatchNorm2d-29 [-1, 256, 8, 8] 512 ReLU6-30 [-1, 256, 8, 8] 0 Conv2d-31 [-1, 256, 8, 8] 65,792 Conv2d-32 [-1, 256, 8, 8] 2,560 BatchNorm2d-33 [-1, 256, 8, 8] 512 ReLU6-34 [-1, 256, 8, 8] 0 Conv2d-35 [-1, 256, 8, 8] 65,792 AdaptiveAvgPool2d-36 [-1, 256, 1, 1] 0 Linear-37 [-1, 11] 2,827 ================================================================ Total params: 256,779 Trainable params: 256,779 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.19 Forward/backward pass size (MB): 13.13 Params size (MB): 0.98 Estimated Total Size (MB): 14.29 ----------------------------------------------------------------从上面的两个输出结果可知,学生网络相较于教师网络是比较小的,教师网络总共有11,182,155个参数,而学生网络只有256,779个。而我们知道模型的变量越多其拟合效果应当是越好的,那么可知教师网络明显多于学生网络,所以必然其准确率也比学生网络的高。
提升student模型性能的方法
- 对于学生模型的提升,从上面的原因分析可知。如果可以修改网络结构,则可以从网络结构方面提升。
- 其次可以寻找更强大的教师模型进行知识蒸馏以达到更高的准确率。
- 还可以通过增大数据集的方法,进行更高强度的训练。
- 通过调整参数以寻找更好的结果。
模型剪枝练习
类型单Module裁剪中的示例,对conv1的bias进行L1unstructured方法裁剪。
对于bias的剪枝,相对于weight只需要改变指定值即可,裁剪的代码基本于网站上的一致,只改变了下面的部分(具体代码见模型剪枝1.py):
module = model.conv1
print(module.bias)
prune.l1_unstructured(module,name="bias",amount=0.3)
print(module.bias)
对上面代码进行运行后可得,
Parameter containing:
tensor([-0.2817, -0.0636, 0.0237, 0.2616, -0.3117, -0.0650], device='cuda:0',
requires_grad=True)
tensor([-0.2817, -0.0000, 0.0000, 0.2616, -0.3117, -0.0650], device='cuda:0j',
grad_fn=<MulBackward0>)
可见除了第2第3个数变为0给剪掉外,其他的均未变。
在实战案例中,batchsize对裁剪性能是否有影响?其他超参数呢?
对裁剪的参数逐个进行调整进行如下实验,相关代码见模型剪枝2.py
-
batchsize的影响
首先将数据集变小,然后修改batchsize分别为24、48、72对比其输出的剪枝结果。具体代码可见
模型剪枝2.py。得到的结果如下:修建后网络的结果:
- batchsize为72时的模型预估大小为52.85MB
- batchsize为48时的模型预估大小为52.85MB
- batchsize为24时的模型预估大小为52.85MB
可以发现batchsize对剪枝的效果是没有影响的。
-
prune_rate的影响
将prune_rate分为0.75、0.85、0.95进行实验
修建后网络的结果:
- prune_rate为0.75时的模型预估大小为48.90MB
- prune_rate为0.85时的模型预估大小为50.61MB
- prune_rate为0.95时的模型预估大小为52.85MB
可以发现当prune_rate越小时对应的剪枝压缩效果也越好。
-
prune_count的影响
将prune_count分为1、2、3进行实验
修建后网络的结果:
- prune_count为1时的模型预估大小为53.74MB
- prune_count为2时的模型预估大小为53.29MB
- prune_count为3时的模型预估大小为52.85MB
可以发现当prune_count越小时对应的剪枝压缩效果越差。
参数量化练习
查阅PyTorch的参考文档,实践其他量化方法,并做性能对比分析。
在查阅完Pytorch文档后,发现pytorch提供一个名为Eager Mode Quantization的API 用于量化。此API提供了3中量化模式,在此我使用了其动态量化与静态量化的功能对模型进行了量化。下面我将分别利用此API对学生网络模型进行量化。
动态模型量化
根据官方文档可知,动态量化是比较简单的一种量化,只需要指定模型、需要量化的层、量化类型即可。而动态量化一般只对线性层和LSTM层起作用,对于卷积层是不起作用的。而student_net是卷积层比较多,所以初步估计动态量化的效果不佳。下面为代码实现部分详细代码见动态量化.py。下面只展示未在网站上显示过的代码片段:
-
加载模型
student_net_fp32 = StudentNet(base=16) device = "cpu" student_net_fp32.load_state_dict(torch.load(f'./student_custom_small.bin')) print('Model Loaded') -
模型动态量化
student_net_int8 = torch.quantization.quantize_dynamic( student_net_fp32, {torch.nn.Linear}, dtype=torch.qint8) -
验证集加载以及模型时间效率评估
valid_dataloader = data_load() student_net_fp32.eval() student_net_int8.eval() fp32_st = time.time() valid_loss_fp32 = run_test_epoch(valid_dataloader, student_net_fp32) fp32_time = time.time() - fp32_st int8_st = time.time() valid_loss_int8 = run_test_epoch(valid_dataloader, student_net_int8) int8_time = time.time() - int8_st print("valid_loss_fp32:",valid_loss_fp32,",time:",fp32_time) print("valid_loss_int8:",valid_loss_int8,",time:",int8_time) -
模型大小比较(代码参考于:https://github.com/pytorch/tutorials/blob/master/recipes_source/recipes/dynamic_quantization.py)
def print_size_of_model(model, label=""): torch.save(model.state_dict(), "temp.p") size=os.path.getsize("temp.p") print("model: ",label,' \t','Size (KB):', size/1e3) os.remove('temp.p') return size # 模型大小比较 f=print_size_of_model(student_net_fp32,"fp32") q=print_size_of_model(student_net_int8,"int8") print("{0:.2f} times smaller".format(f/q))
最后的运行结果如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G8F9ZSAd-1690719177662)(D:\学习资料\大三上\大三上资料\大三上资料\深度学习实践\作业\实验\实验5\文档记录.assets\image-20221205203524451.png)]](https://img-blog.csdnimg.cn/17c18f29c3be493c81d305addf4444b0.png)
可以看到动态量化的效果并不是很好,在推理时间方面,int类型的甚至大于fp32原型的,量化后的结果差于量化前的。而其准确率两者基本一致,对于最后模型的大小,量化后的模型基本完全没有优势,量化后的模型大小未1045KB而量化前的是1053KB,相距不大。
静态模型量化
静态模型量化相对于动态量化会复杂一点,相对于动态量化而言,它们都是把网络的权重参数转从float32转换为int8。然而他们间也有很大的不同点,那就是静态量化需要把训练集或者和训练集分布类似的数据喂给模型,然后通过每个op输入的分布特点来计算activation的量化参数。静态量化更适合于卷积神经网络,而实验中所用到的student_net就是卷积神经网络,所以静态量化在此上面应该会有较好效果,下面为代码实现部分详细代码见静态量化.py。代码内容主要与动态量化的一致,以下主要展示量化的代码:
valid_dataloader = data_load()
student_net_fp32.eval()
student_net_fp32.qconfig = torch.quantization.get_default_qconfig('fbgemm')
student_net_fp32_prepared = torch.quantization.prepare(student_net_fp32)
# 先读取部分数据用于定位
for batch_data in tqdm(valid_dataloader):
# 获取数据
inputs, hard_labels = batch_data
# 只是做validation的话,就不用计算梯度
with torch.no_grad():
student_net_fp32_prepared(inputs.to(device))
student_net_int8 = torch.quantization.convert(student_net_fp32_prepared)
除了定义量化的方法外,其网络结构也需要添加内容。需要在初始化时定义量化方法与逆量化方法,内容如下:
class StudentNet(nn.Module):
def __init__(self, base=16, width_mult=1):
super(StudentNet, self).__init__()
multiplier = [1, 2, 4, 8, 16, 16, 16, 16]
bandwidth = [base * m for m in multiplier] # 每层输出的channel数量
for i in range(3, 7): # 对3/4/5/6层进行剪枝
bandwidth[i] = int(bandwidth[i] * width_mult)
self.cnn = nn.Sequential(...)
# 直接将CNN的输出映射到11维作为最终输出
self.fc = nn.Sequential(
nn.Linear(bandwidth[7], 11)
)
self.quant = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.cnn(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
x = self.dequant(x)
return x
最后对验证集进行推理,得到一下的结果,
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DKCYM2ge-1690719177663)(D:\学习资料\大三上\大三上资料\大三上资料\深度学习实践\作业\实验\实验5\文档记录.assets\image-20221205214118224.png)]](https://img-blog.csdnimg.cn/77adc2424a364cfaab20b08ecd99a78f.png)
可见量化后的准确率明显偏低,与未量化前相差了两倍,但是量化后在运行时间方面是略优于未量化前的。而量化后最大的成果是其模型大小相对于未量化小了接近3倍。虽然模型大小小了3倍,但是其正确率实在太低,而不能有效使用,正确率方面的问题可能与网络结构有一定的联系。
算式检测模型压缩优化
算式检测模型是通过yolo训练得到的,它是基于yolov5s模型作为预训练模型得到的。而训练得到的结果,发现还有很多优化的地方,例如可以通过剪枝、量化等方式压缩模型的大小以节省存储空间,同时也可以通过此加快训练速度。而在这些压缩过程中虽然模型的精度会降低但是相对于存储空间的减少与推理数度的提升,其价值仍然很大。下面将对模型剪枝和量化两个方面对算式识别模型就行压缩优化以达到更好的效果。
未优化前模型的大小与速度
此算式识别模型是预先进行了训练的,最后得到了equation.pt的权重文件,先通过yolo自带的val.py文件查看模型对验证集的推理效果。进入yolov5文件夹后,输入下面的指令进行评估:
python val.py --weights ../equation.pt --data equation.yaml --img 640
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WKuRkJHP-1690719177664)(D:\学习资料\大三上\大三上资料\大三上资料\深度学习实践\作业\实验\实验5\文档记录.assets\image-20221206164134924.png)]](https://img-blog.csdnimg.cn/49c2dda7b444485c814f530da4988b84.png)
可以看到其精确率、召回率、mAP50分别未0.997、0.999、0.994,而其预处理时间为1.8ms每张照片、推理为227.9ms每张。
算式检测模型剪枝
-
yolo提供的剪枝方法
根据yolo的说明文档(https://github.com/ultralytics/yolov5/issues/304),在
val.py中插入模型剪枝语句以达到简单剪枝的效果。需要在yolo源文件下的,
val.py的第156行中添加如下的代码。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O4bqErDW-1690719177665)(D:\学习资料\大三上\大三上资料\大三上资料\深度学习实践\作业\实验\实验5\文档记录.assets\image-20221206184209672.png)]](https://img-blog.csdnimg.cn/1e901d842a4e4fa79152631f3bf94efe.png)
# prune from utils.torch_utils import prune prune(model, 0.3)此代码经过搜索发现,其实yolo内部有提供剪枝的工具,在
utils文件夹下的``torch_utils.py`文件中,其具体代码如下:def prune(model, amount=0.3): # Prune model to requested global sparsity import torch.nn.utils.prune as prune for name, m in model.named_modules(): if isinstance(m, nn.Conv2d): prune.l1_unstructured(m, name='weight', amount=amount) # prune prune.remove(m, 'weight') # make permanent LOGGER.info(f'Model pruned to {sparsity(model):.3g} global sparsity')可以发现它使用了pytorch的API接口进行模型剪枝,对每个含有卷积的层都进行了默认30%的剪枝。
在
val.py中嵌入以上代码后,开始对验证集进行推理,查看变化。其结果如下:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yoOiHobg-1690719177666)(D:\学习资料\大三上\大三上资料\大三上资料\深度学习实践\作业\实验\实验5\文档记录.assets\image-20221206184905447.png)]](https://img-blog.csdnimg.cn/6905d8310a7240bdb7a939fb7fdb0f27.png)
可以看到其精确率、召回率、mAP50的值均有稍微降低,而其运行时间基本上没有太大变化。在后面查看yolo上github的issue后发现他们的结果也是差不多的,剪枝后效果基本没有,大小也并没有给压缩。
-
另外的剪枝方法
除了yolo提供的剪枝方法后,在网络上(https://github.com/ZJU-lishuang/yolov5_prune)也找到了另外的一些剪枝方法。现尝试此方法对模型进行剪枝。
然而在测试后发现,此方法并不完善,在处理过很多次报错后均无法进行下一步的运行,所以最后放弃剪枝的方法。
算式检测模型量化
尝试寻找yolo的检测模型的量化方法,但是一直未找到,最后在github的issue中找到了对应的yolov5模型量化的问题,但是发现问题是20年提出的,但是在22年却仍未解决,yolo作者说cpu上运行的yolo无法进行int8量化,所以最后放弃了模型的量化。
https://github.com/ultralytics/yolov5/issues/1288
算式识别模型压缩优化
对于算式识别模型我使用的是模型量化的方法进行压缩优化,此处的算式识别模型是之前放弃的一个文字识别模型,此模型是直接选取easyocr提供的,由于后期选用的是paddleocr进行训练,所以放弃了easyocr,而paddleocr暂未训练完成所以此处选用easyocr作为实验对象对其进行压缩优化。
而对于压缩优化,我选用了量化的方法,将32位浮点数变为int8以实现在存储上的压缩以及推理的加速,此处只用于对模型进行压缩,而推理并不做评价。
-
模型下载
模型的下载主要是参考与作者github的链接:https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md
下载完成后有三个文件分别为
custom_example.pth、custom_example.py、custom_example.yaml,其分别为权重文件、神经网络文件以及配置文件,此处只用到前两个。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ewzMjWRD-1690719177667)(D:\学习资料\大三上\大三上资料\大三上资料\深度学习实践\作业\实验\实验5\文档记录.assets\image-20221206214753514.png)]](https://img-blog.csdnimg.cn/4355cbc8ac3c493682d898c96a8b7e17.png)
-
模型加载
对于模型的加载直接在
custom_example.py中编辑即可,在源代码的基础上加上下面的代码即可加载完毕,
# 模型加载 model = Model(input_channel=1,output_channel=256,hidden_size=256,num_class=97) dic = torch.load(f'./custom_example.pth') model.load_state_dict(dic,False) -
动态量化
可以知道此神经网络拥有很多的LSTM层,所以此处适合用动态量化。动态量化代码如下:
model_int8 = torch.quantization.quantize_dynamic( model, {torch.nn.Linear, torch.nn.LSTM}, dtype=torch.qint8) -
量化结果前后对比
对于量化的结果此处只讨论模型大小,定义一函数来获取模型的大小并进行比较。其代码如下:
def print_size_of_model(model, label=""): torch.save(model.state_dict(), "temp.p") size=os.path.getsize("temp.p") print("model: ",label,' \t','Size (KB):', size/1e3) os.remove('temp.p') return size # 模型大小比较 f=print_size_of_model(model,"fp32") q=print_size_of_model(model_int8,"int8")输出的结果如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9rubvI7A-1690719177669)(D:\学习资料\大三上\大三上资料\大三上资料\深度学习实践\作业\实验\实验5\文档记录.assets\image-20221206215301213-16703347822271.png)]](https://img-blog.csdnimg.cn/34c362e04a814d029e6307f2527ca1a5.png)
可以看到模型的大小压缩到了原来的 1 2 \frac{1}{2} 21,说明动态量化对模型起到了一定的优化。
实验结论
在本次实验中,成功完成了基本要求中的多项练习,包括探讨架构设计中通道数改变对神经网络的影响、学生网络网络最终并不能比教师网络好的原因、剪枝参数的影响、pytorch量化方法的实现等等。其中发现模型架构设计练习中模型大小与base值和width_mult值均为正相关关系。在知识蒸馏的练习中,发现阻碍学生网络进一步提升的原因可能为神经网络的架构,教师网络相对学生网络更深,效果也更好。在模型量化练习中,复现了动态量化和静态量化,发现动态量化更适合于存在线性层和LSTM的神经网络使用,而静态量化更适合卷积神经网络使用。
除了完成基本要求外,我还对算式检测模型和算式内容提取模型尝试了压缩优化。对于检测模型,由于是使用yolo工具进行训练和使用的,所以直接使用了yolo的模型剪枝接口进行了压缩,然而压缩后的结果却并不好,其准确率有稍微降低,但是模型大小却无变化,推理的速度也无变化。最后猜测这可能剪枝接口直接将参数变为0而不是去除有关,而且还可能与运行的设备为CPU存在关联。对于内容提取的模型,我使用的是easyocr的模型。对于此模型我对它使用了量化的方法将其参数从32位浮点数变为了8位浮点数,最后模型的大小缩小了一般,同时验证优化的成功性。
![【PWN · 栈迁移】[BUUCTF]ciscn_2019_es_2](https://s3-us-west-2.amazonaws.com/secure.notion-static.com/4f7d2562-49df-4956-9ae7-8351c56d1820/Untitled.png)