在 IntelliJ 平台中解析文件是一个两步过程:
- 首先,构建抽象语法树 (AST),定义程序的结构。AST 节点由 IDE 在内部创建,具体是由类ASTNode类来创建的。 每个 AST 节点都有一个关联的元素类弄IElementType实例,元素类型由语言插件定义。AST 树的顶级节点需要有一个特殊的元素类型IFileElementType。AST 节点直接映射到基础文档中的文本范围。AST 的最底部节点匹配词法分析器返回的单个标记,而更高级别的节点匹配多个标记片段。在 AST 树的节点上执行的操作,例如插入、删除、重新排序节点等,会立即反映为对基础文档文本的更改。
- 其次,PSI 或程序结构接口树构建在 AST 之上,添加了用于操作特定语言结构的语义和方法。PSI 树的节点由PsiElement实现,具体是由语言插件的ParserDefinition.createElement()创建。文件的PSI树的顶级节点需要实现接口PsiFile,具体由ParserDefinition.createFile()创建;
IntelliJ Platform提供了PsiFileBase、PsiFile、ASTWrapperPsiElement的基本实现,可参考以下示例:
ublic class PropertiesParserDefinition implements ParserDefinition {
public static final ILightStubFileElementType FILE_ELEMENT_TYPE = new ILightStubFileElementType("properties", PropertiesLanguage.INSTANCE) {
@Override
public FlyweightCapableTreeStructure<LighterASTNode> parseContentsLight(ASTNode chameleon) {
PsiElement psi = chameleon.getPsi();
assert psi != null : "Bad chameleon: " + chameleon;
Project project = psi.getProject();
PsiBuilderFactory factory = PsiBuilderFactory.getInstance();
PsiBuilder builder = factory.createBuilder(project, chameleon);
ParserDefinition parserDefinition = LanguageParserDefinitions.INSTANCE.forLanguage(getLanguage());
assert parserDefinition != null : this;
PropertiesParser parser = new PropertiesParser();
return parser.parseLight(this, builder);
}
};
@Override
@NotNull
public Lexer createLexer(Project project) {
return new PropertiesLexer();
}
@Override
public @NotNull IFileElementType getFileNodeType() {
return FILE_ELEMENT_TYPE;
}
@Override
@NotNull
public TokenSet getWhitespaceTokens() {
return PropertiesTokenTypes.WHITESPACES;
}
@Override
@NotNull
public TokenSet getCommentTokens() {
return PropertiesTokenTypes.COMMENTS;
}
@Override
@NotNull
public TokenSet getStringLiteralElements() {
return TokenSet.EMPTY;
}
@Override
@NotNull
public PsiParser createParser(final Project project) {
return new PropertiesParser();
}
@Override
public @NotNull PsiFile createFile(@NotNull FileViewProvider viewProvider) {
return new PropertiesFileImpl(viewProvider);
}
@Override
public @NotNull SpaceRequirements spaceExistenceTypeBetweenTokens(ASTNode left, ASTNode right) {
if (left.getElementType() == PropertiesTokenTypes.END_OF_LINE_COMMENT) {
return SpaceRequirements.MUST_LINE_BREAK;
}
return SpaceRequirements.MAY;
}
@Override
@NotNull
public PsiElement createElement(ASTNode node) {
final IElementType type = node.getElementType();
if (type == PropertiesElementTypes.PROPERTY) {
return new PropertyImpl(node);
}
else if (type == PropertiesElementTypes.PROPERTIES_LIST) {
return new PropertiesListImpl(node);
}
throw new AssertionError("Alien element type [" + type + "]. Can't create Property PsiElement for that.");
}
}为避免在初始化
ParserDefinition扩展点实现时进行不必要的类加载,所有TokenSet返回值都应使用专用$Language$TokenSets类中的常量。
一、Parse and PSI
1、实现Parse
这块建议用Grammar-Kit或Gradle Grammar-Kit插件从语法解析器生成相应的PSI类,则不要自己生动编程。因为生成的代码中同时还提供了语法高亮、快速导航、重构等能力。
语言插件同时也提供了一个从ParserDefinition.createParser()方法返回的PsiParser接口实例的实现。 该实例用于从词法分析器获取标记流并保存正在构建的 AST 的中间状态。解析器必须处理词法分析器返回的所有标记,直到流的末尾,换句话说,直到PsiBuilder.getTokenType()返回null,即使根据语言语法这些标记是无效的,参考示例:
public class PropertiesParser implements PsiParser {
private static final TripleFunction<ASTNode,LighterASTNode,FlyweightCapableTreeStructure<LighterASTNode>,ThreeState>
MATCH_BY_KEY = (oldNode, newNode, structure) -> {
if (oldNode.getElementType() == PropertiesElementTypes.PROPERTY) {
ASTNode oldName = oldNode.findChildByType(PropertiesTokenTypes.KEY_CHARACTERS);
if (oldName != null) {
CharSequence oldNameStr = oldName.getChars();
CharSequence newNameStr = findKeyCharacters(newNode, structure);
if (!Comparing.equal(oldNameStr, newNameStr)) {
return ThreeState.NO;
}
}
}
return ThreeState.UNSURE;
};
private static CharSequence findKeyCharacters(LighterASTNode newNode, FlyweightCapableTreeStructure<LighterASTNode> structure) {
Ref<LighterASTNode[]> childrenRef = Ref.create(null);
int childrenCount = structure.getChildren(newNode, childrenRef);
LighterASTNode[] children = childrenRef.get();
try {
for (LighterASTNode aChildren : children) {
if (aChildren.getTokenType() == PropertiesTokenTypes.KEY_CHARACTERS) {
return ((LighterASTTokenNode)aChildren).getText();
}
}
return null;
}
finally {
structure.disposeChildren(children, childrenCount);
}
}
@Override
@NotNull
public ASTNode parse(@NotNull IElementType root, @NotNull PsiBuilder builder) {
doParse(root, builder);
return builder.getTreeBuilt();
}
@NotNull
public FlyweightCapableTreeStructure<LighterASTNode> parseLight(IElementType root, PsiBuilder builder) {
doParse(root, builder);
return builder.getLightTree();
}
public void doParse(IElementType root, PsiBuilder builder) {
builder.putUserData(PsiBuilderImpl.CUSTOM_COMPARATOR, MATCH_BY_KEY);
final PsiBuilder.Marker rootMarker = builder.mark();
final PsiBuilder.Marker propertiesList = builder.mark();
if(builder.eof()){
propertiesList.setCustomEdgeTokenBinders(WhitespacesBinders.GREEDY_LEFT_BINDER, WhitespacesBinders.GREEDY_RIGHT_BINDER);
}
else{
propertiesList.setCustomEdgeTokenBinders(WhitespacesBinders.GREEDY_LEFT_BINDER, null);
}
while (!builder.eof()) {
Parsing.parseProperty(builder);
}
propertiesList.done(PropertiesElementTypes.PROPERTIES_LIST);
rootMarker.done(root);
}
}解析器通过在从词法分析器接收到的标记流中设置成对的标记( PsiBuilder.Marker实例)来工作。每对标记定义了 AST 树中单个节点的词法分析器标记的范围。如果一对标记嵌套在另一对中(在其开始之后开始并在其结束之前结束),则它成为外部对的子节点。
通过调用PsiBuilder.Marker.done(),标记对和从它创建的 AST 节点的元素类型在设置结束标记时指定,此外也可以在设置结束标记之前删除开始标记。drop()方法只删除一个开始标记而不影响在它之后添加的任何标记,rollbackTo()方法删除开始标记和在它之后添加的所有标记并将词法分析器位置恢复到开始标记。这些方法可用于在解析前。
如果需要读取完数据才知道特定位置需要多少个标记时可以使用从右到左的解析方法PsiBuilder.Marker.precede()。比如二进制表达式a+b+c需要解析为( (a+b) + c )。因此,在标记“a”的位置需要两个开始标记,但直到读取标记“c”时才知道。当解析器到达 'b' 之后的 '+' 标记时,它可以调用precede()在 'a' 位置复制开始标记,然后将其匹配的结束标记放在 'c' 之后。
空格和注释
PsiBuilder也可以对空格和注释进行处理。ParserDefinition中的getWhitespaceTokens()和getCommentTokens()可以定义空格和注释标记类型。PsiBuilder会自动忽略掉PsiParser处理的数据中相关的流信息,并并调整 AST 节点的令牌范围,以便节点中不包含前导和尾随的空白令牌。但一般不需要重写上面两个方法,使用默认实现就好,处理流程如下:
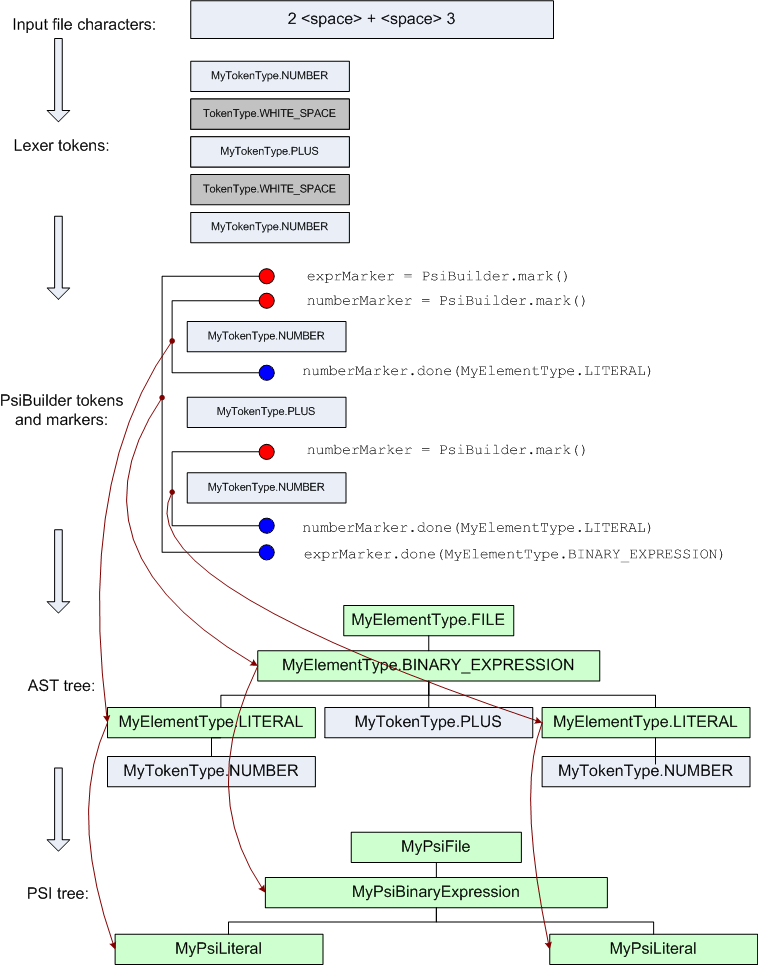
2、实现PSI
一般来说,为自定义语言实现 PSI 没有唯一正确的方法,插件作者可以选择最适合使用 PSI 的代码的 PSI 结构和方法集(错误分析、重构和很快),但都需要实现一个基本的的PSI实现,比如支持重命名功能(通过调用PsiNamedElement的getName()和setName())。
所有实现PSI的API都放在了com.intellij.psi.util包下面,最实用的是PsiUtilCore和PsiTreeUtil工具类。
三、实现示例
1、定义TokenType
public class SimpleTokenType extends IElementType {
public SimpleTokenType(@NotNull @NonNls String debugName) {
super(debugName, SimpleLanguage.INSTANCE);
}
@Override
public String toString() {
return "SimpleTokenType." + super.toString();
}
}2、定义ElementType
public class SimpleElementType extends IElementType {
public SimpleElementType(@NotNull @NonNls String debugName) {
super(debugName, SimpleLanguage.INSTANCE);
}
}3、定义Grammar
在org /intellij /sdk /language /Simple.bnf文件中定义简单语言的语法。
{
parserClass="org.intellij.sdk.language.parser.SimpleParser"
extends="com.intellij.extapi.psi.ASTWrapperPsiElement"
psiClassPrefix="Simple"
psiImplClassSuffix="Impl"
psiPackage="org.intellij.sdk.language.psi"
psiImplPackage="org.intellij.sdk.language.psi.impl"
elementTypeHolderClass="org.intellij.sdk.language.psi.SimpleTypes"
elementTypeClass="org.intellij.sdk.language.psi.SimpleElementType"
tokenTypeClass="org.intellij.sdk.language.psi.SimpleTokenType"
psiImplUtilClass="org.intellij.sdk.language.psi.impl.SimplePsiImplUtil"
}
simpleFile ::= item_*
private item_ ::= (property|COMMENT|CRLF)
property ::= (KEY? SEPARATOR VALUE?) | KEY {
pin=3
recoverWhile="recover_property"
mixin="org.intellij.sdk.language.psi.impl.SimpleNamedElementImpl"
implements="org.intellij.sdk.language.psi.SimpleNamedElement"
methods=[getKey getValue getName setName getNameIdentifier getPresentation]
}
private recover_property ::= !(KEY|SEPARATOR|COMMENT)语法规则大致如下图所示,详细可参考GitHub - JetBrains/Grammar-Kit: Grammar files support & parser/PSI generation for IntelliJ IDEA中的说明。

4、实现语法解析器
这一步不需要自己编码,安装Grammar-Kit或Gradle Grammar-Kit插件后,右键选择上面的.bnf文件,会有以下三个选项,选择Generate Parser Code ,解析代码会生成在 /src/main/gen中:

还需在build.gradle.kts文件配置下gen为源码目录:
sourceSets {
main {
java {
srcDirs("src/main/gen")
}
}
}5、测试运行
在新建的test.simple类中输入一个汉字会得到提示信息,因为上面规定了此文件不接收汉字。