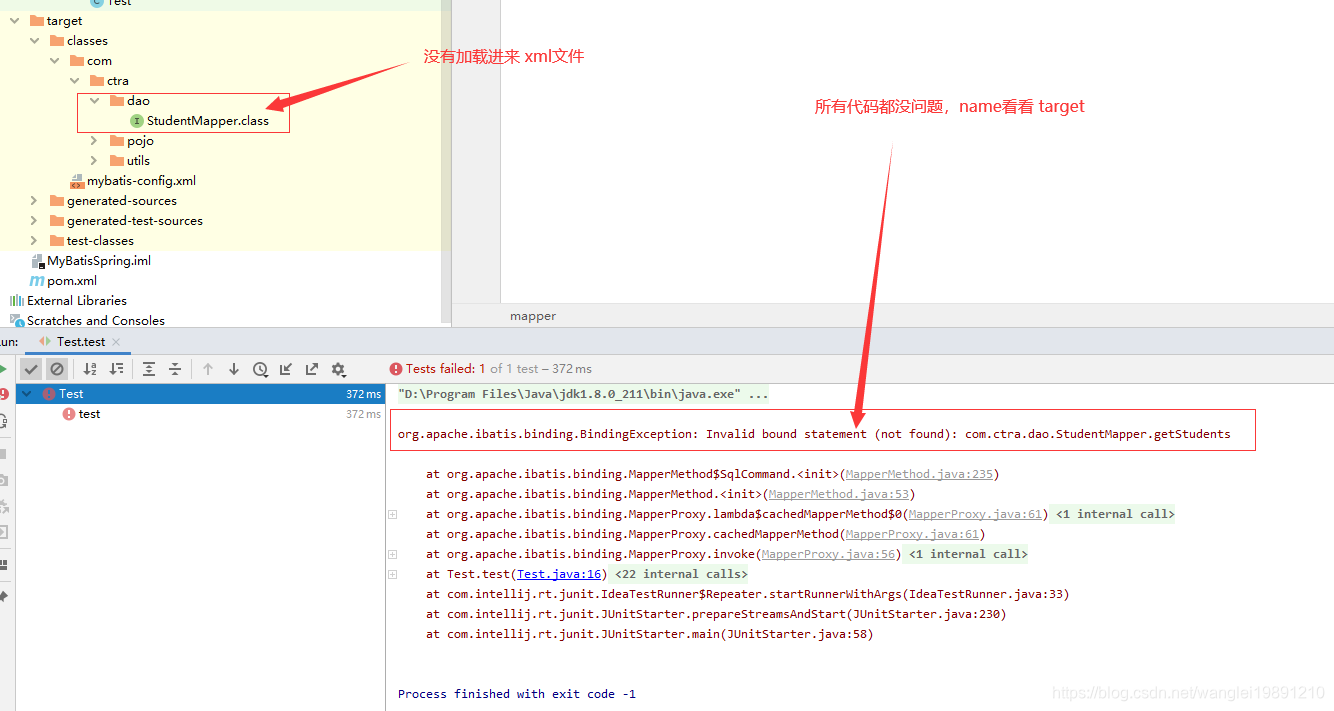
我们设计一个简单的smpliekv数据库,来体验简直数据库包含什么
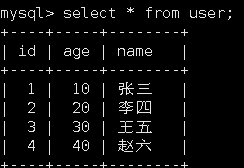
体来说,一个键值数据库包括了访问框架、索引模块、操作模块和存储模块四部分(见
下图)。接下来,我们就从这四个部分入手,继续构建我们的 SimpleKV。

采用什么样的访问模式呢?
访问模式通常有两种:一种是通过函数库调用的方式供外部应用使用,比如,上图中的
libsimplekv.so,就是以动态链接库的形式链接到我们自己的程序中,提供键值存储功能;
另一种是通过网络框架以 Socket 通信的形式对外提供键值对操作,这种形式可以提供广
泛的键值存储服务。在上图中,我们可以看到,网络框架中包括 Socket Server 和协议解
析
不同的键值数据库服务器和客户端交互的协议并不相同,我们在对键值数据库进行二次开
发、新增功能时,必须要了解和掌握键值数据库的通信协议,这样才能开发出兼容的客户
端。
实际的键值数据库也基本采用上述两种方式,例如,RocksDB 以动态链接库的形式使用,
而 Memcached 和 Redis 则是通过网络框架访问。后面我还会给你介绍 Redis 现有的客户
端和通信协议。
通过网络框架提供键值存储服务,一方面扩大了键值数据库的受用面,但另一方面,也给
键值数据库的性能、运行模型提供了不同的设计选择,带来了一些潜在的问题。
举个例子,当客户端发送一个如下的命令后,该命令会被封装在网络包中发送给键值数据
库:
PUT hello world
键值数据库网络框架接收到网络包,并按照相应的协议进行解析之后,就可以知道,客户
端想写入一个键值对,并开始实际的写入流程。此时,我们会遇到一个系统设计上的问
题,简单来说,就是网络连接的处理、网络请求的解析,以及数据存取的处理,是用一个
线程、多个线程,还是多个进程来交互处理呢?该如何进行设计和取舍呢?我们一般把这
个问题称为 I/O 模型设计。不同的 I/O 模型对键值数据库的性能和可扩展性会有不同的影
响。
举个例子,如果一个线程既要处理网络连接、解析请求,又要完成数据存取,一旦某一步
操作发生阻塞,整个线程就会阻塞住,这就降低了系统响应速度。如果我们采用不同线程
处理不同操作,那么,某个线程被阻塞时,其他线程还能正常运行。但是,不同线程间如
果需要访问共享资源,那又会产生线程竞争,也会影响系统效率,这又该怎么办呢?所
以,这的确是个“两难”选择,需要我们进行精心的设计。
你可能经常听说 Redis 是单线程,那么,Redis 又是如何做到“单线程,高性能”的呢?
这个问题以后再说
如何定位键值对的位置?
索引的类型有很多,常见的有哈希表、B+ 树、字典树等。不同的索引结构在性能、空间消
耗、并发控制等方面具有不同的特征。如果你看过其他键值数据库,就会发现,不同键值
数据库采用的索引并不相同,例如,Memcached 和 Redis 采用哈希表作为 key-value 索
引,而 RocksDB 则采用跳表作为内存中 key-value 的索引。
一般而言,内存键值数据库(例如 Redis)采用哈希表作为索引,很大一部分原因在于,
其键值数据基本都是保存在内存中的,而内存的高性能随机访问特性可以很好地与哈希表
O(1) 的操作复杂度相匹配。
SimpleKV 的索引根据 key 找到 value 的存储位置即可。但是,和 SimpleKV 不同,对于
Redis 而言,很有意思的一点是,它的 value 支持多种类型,当我们通过索引找到一个
key 所对应的 value 后,仍然需要从 value 的复杂结构(例如集合和列表)中进一步找到
我们实际需要的数据,这个操作的效率本身就依赖于它们的实现结构。
Redis 采用一些常见的高效索引结构作为某些 value 类型的底层数据结构,这一技术路线
为 Redis 实现高性能访问提供了良好的支撑
不同操作的具体逻辑是怎样的?
SimpleKV 的索引模块负责根据 key 找到相应的 value 的存储位置。对于不同的操作来
说,找到存储位置之后,需要进一步执行的操作的具体逻辑会有所差异。SimpleKV 的操
作模块就实现了不同操作的具体逻辑:
对于 GET/SCAN 操作而言,此时根据 value 的存储位置返回 value 值即可;
对于 PUT 一个新的键值对数据而言,SimpleKV 需要为该键值对分配内存空间;
对于 DELETE 操作,SimpleKV 需要删除键值对,并释放相应的内存空间,这个过程由
分配器完成。
如何实现重启后快速提供服务?
impleKV 虽然依赖于内存保存数据,提供快速访问,但是,我也希望 SimpleKV 重启后
能快速重新提供服务,所以,我在 SimpleKV 的存储模块中增加了持久化功能
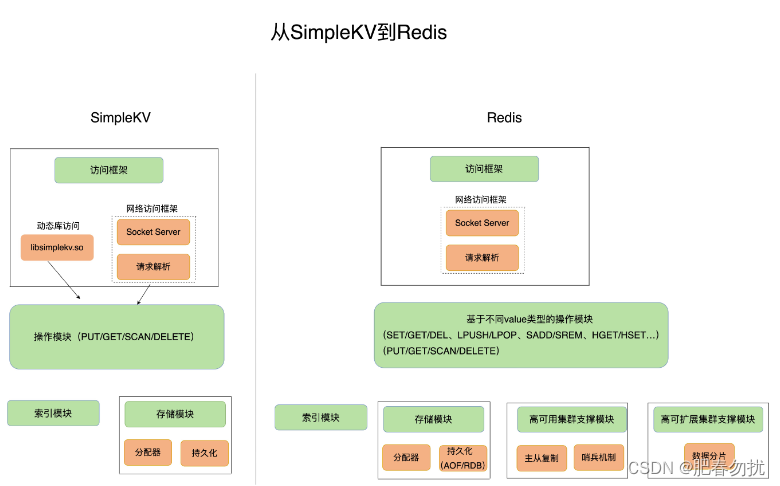
从这张对比图中,我们可以看到,从 SimpleKV 演进到 Redis,有以下几个重要变化: