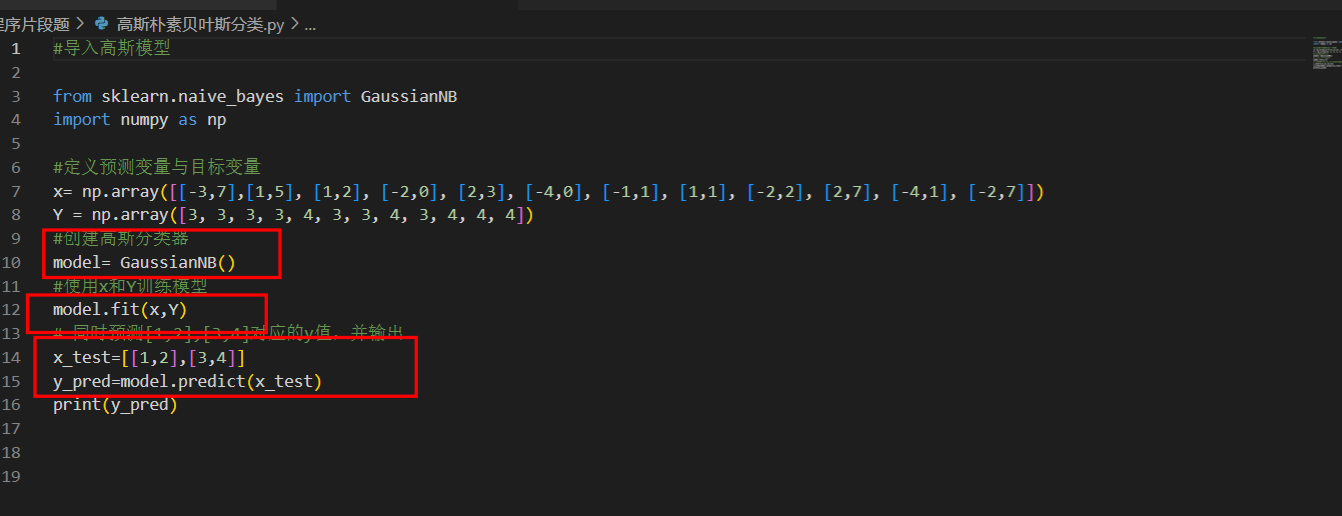
1. 前言
之前把ORT的一套推理环境框架搭好了,在项目中也运行得非常愉快,实现了cpu/gpu,fp32/fp16的推理运算,同onnx通用模型在不同推理框架下的性能差异对比贴一下,记录一下自己对各种推理框架的学习状况
| 模型名称 | 参数量 |
|---|---|
| NANO | 3.2M |
| ... | ... |
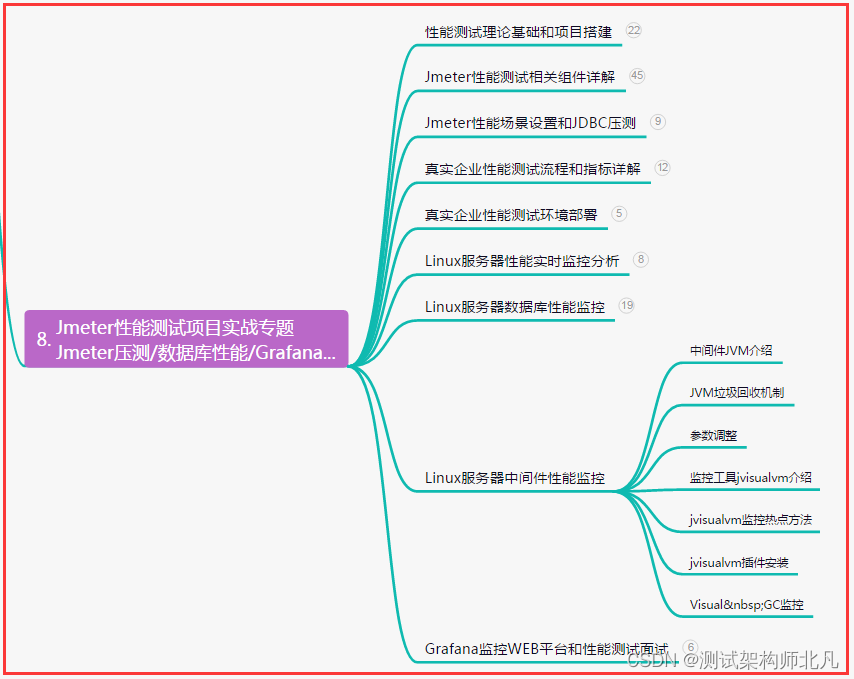
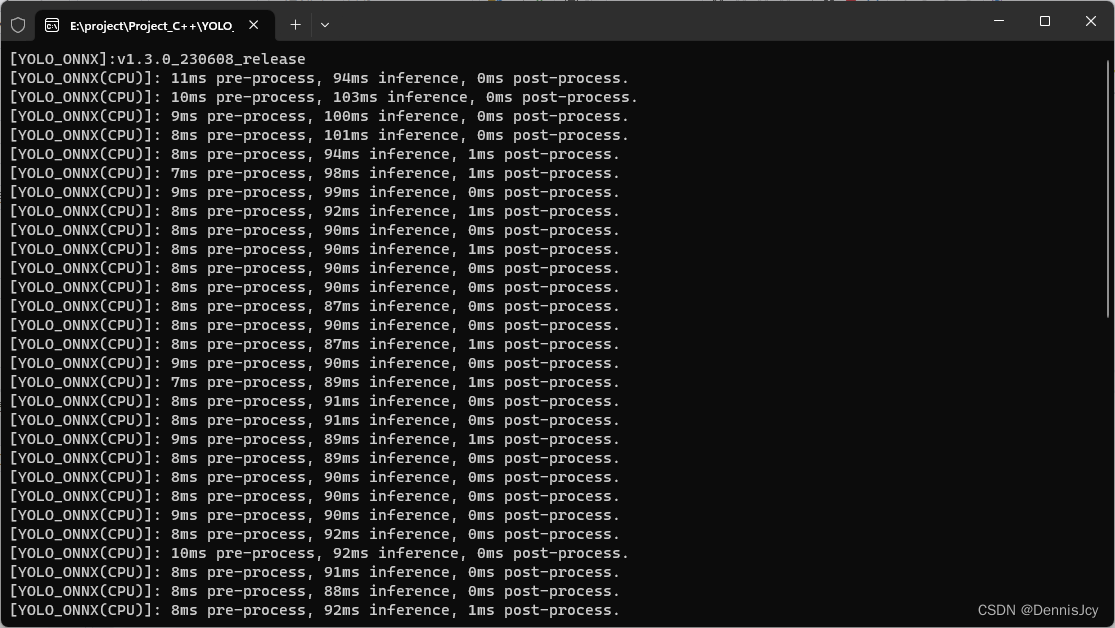
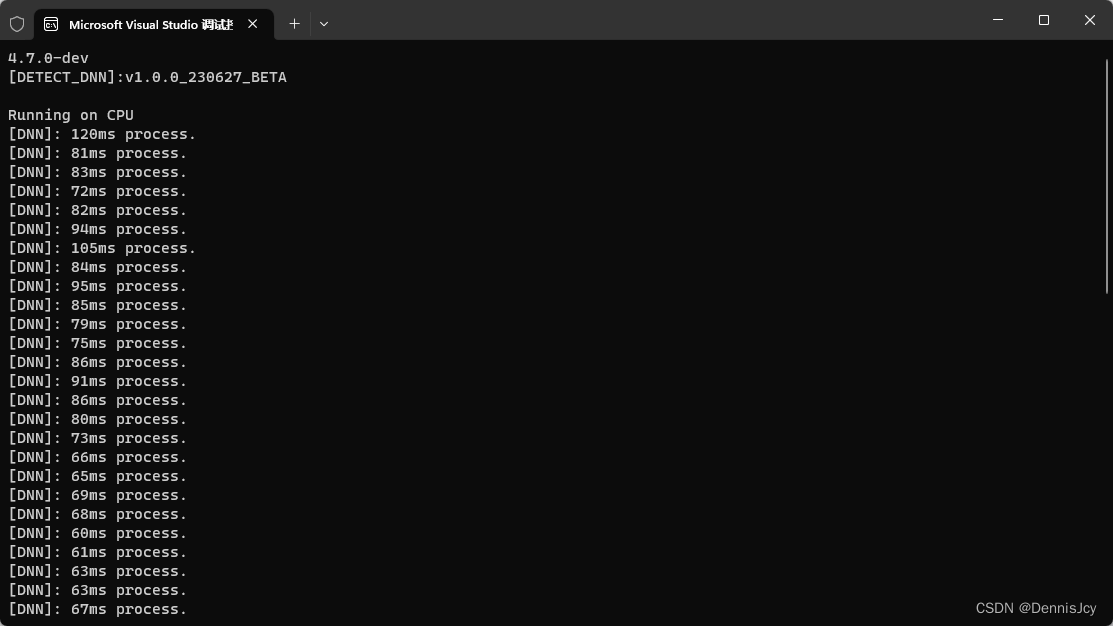
2. CPU篇
| 框架 | 推理耗时(i5-11400H@2.70GHz)/ms |
|---|---|
| OnnxRuntime | 95 |
| DNN | 80 |
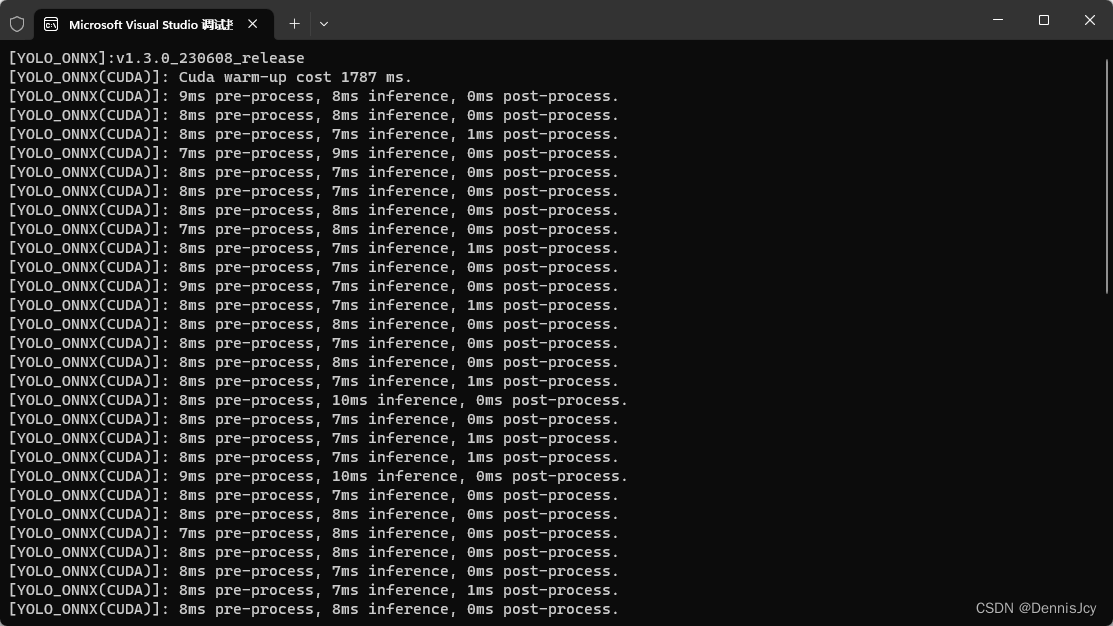
3. GPU篇
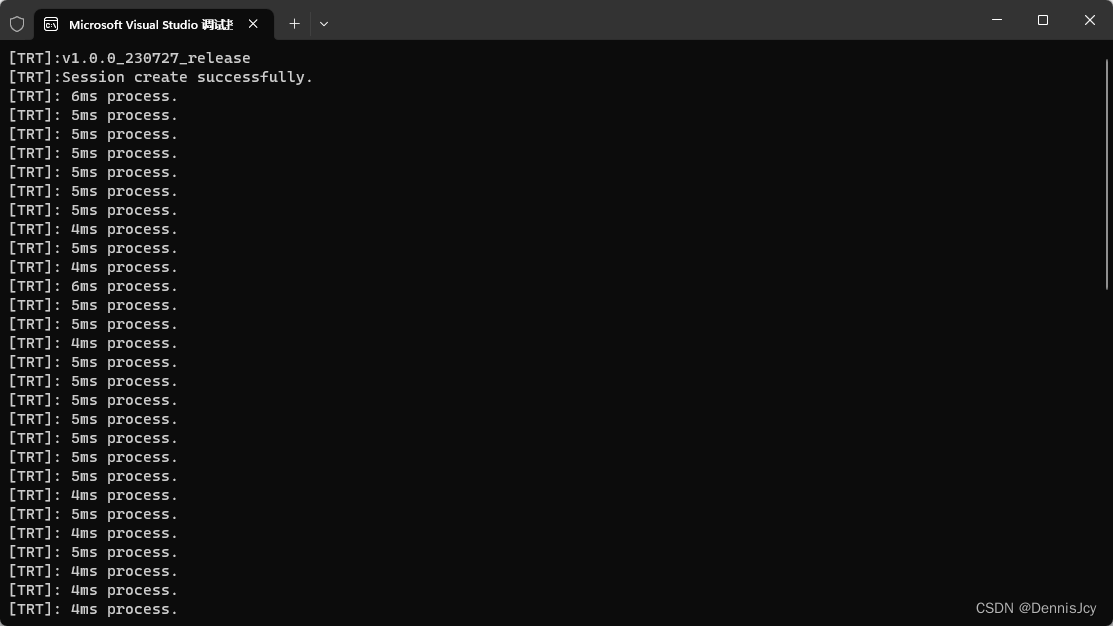
4. 总结
cpu选择onnxruntime或者dnn都可以,建议选择ort.gpu选择tensorrt,如果有兼容需求就只能选择onnxruntime了.
不得不说,gpu推理上TRT把ORT薄纱了,不需要warm-up,对工业生产环境非常友好,因为在实际生产环境中,都不是实时推理,而是有间隔的推理,ORT在一段间隔时间后cuda性能会有所衰减,当然也可能是我还没摸透ort这个框架,欢迎大佬指正.