实验一 array数组(01)
一、实验目的及要求
1.安装numpy环境,掌握基本的数组知识以及操作。
二、实验设备(环境)及要求
开发环境:jupyter notebook
开发语言以及相关的库:python开发语言、numpy库
三、实验内容与步骤
1.安装numpy库。
2.使用numpy函数创建数组
3.对数组进行简单操作
四、实验结果
1.利用numpy函数创建数组

2.对所有值进行+1操作

3.两数组进行操作

五、分析与讨论
数组是基本的使用方法,所以需要熟练掌握数组的基本操作及相关知识。
实验二 array数组(02)
一、实验目的及要求
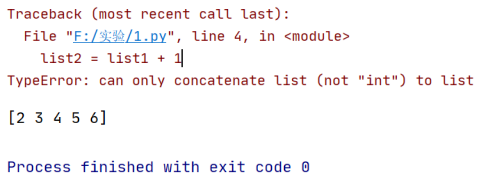
对array数组中每一个元素执行+1操作,可以直接执行吗?
二、实验设备(环境)及要求
Rtx2060
三、实验内容与步骤

四、实验结果
五、分析与讨论
List数组不能直接相加
Array可以
实验三 数组属性操作
一、实验目的及要求
数组属性操作
二、实验设备(环境)及要求
Rtx2060
三、实验内容与步骤

四、实验结果
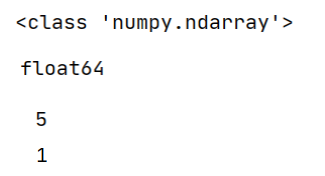
五、分析与讨论
Array数组有很多显示结果功能,对于写代码时很有帮助
实验四 鸢尾花数据集分类
一、实验目的及要求
支持向量机(SVM) )是一种最大化分类间隔的线性分类器(如果不考虑核函数)。通过使用核函数可以用于非线性分类。SVM是一种判别模型,既适用于分类也适用于回归问题,标准的 SVM是二分类器,可以采用“one vs one”或“one vs rest”策略解决多分类问题。通过对鸢尾花数据集分类的练习,可以掌握svm的使用。
二、实验设备(环境)及要求
1.学习机器学习的基本概念,特别是对有监督学习中分类的理解。
2.一台装有PyCharm/Anaconda集成开发环境、配置sklearn包的Windows系统。
3. PyCharm环境、Python 3.7. Pandas. NumPy、Matplotlib、sklearn.
三、实验内容与步骤
(一)任务实施
1.鸢尾花数据读取
2.数据分析
3.模型建立
4.模型训练
5.数据预测与模型的可视化
(二)相关代码
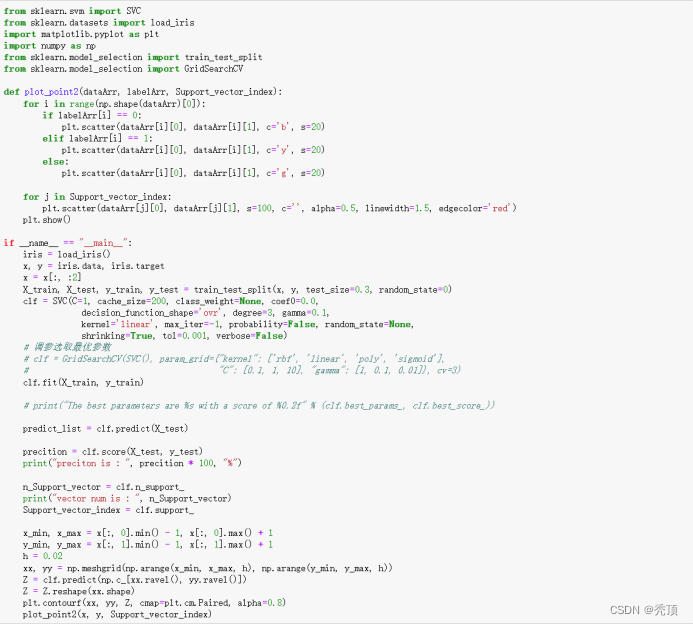
四、实验结果
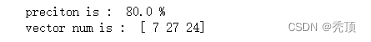
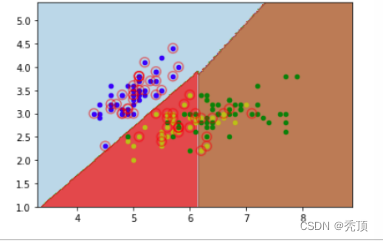
五、分析与讨论
本次实验过程主要包括三部分,导入整个模型包,训练模型,预测结果。从准确度来看,也预测结果一般。
实验五 航空公司客户价值分析LRMFC模型
一、实验目的及要求
1)了解K-Means 聚类算法在客户价值分析实例中的应用。
2)利用pandas快速实现数据z-score(标准差)标准化以及用scikit-learn的聚类库实现K-Means聚类。
二、实验设备(环境)及要求
1、python=3.8
2、使用了pandas、numpy等
三、实验内容与步骤
本实验内容包括以下两个方面:
依据航空公司客户价值分析的LRFMC模型提取客户信息的LRF"MC指标。对其进行标准差标准化并保存后,采用K-Means算法完成客户的聚类,分析每类客户的特征,从而获得每类客户的价值。
1)利用pandas库读入LRFMC 指物文件,分别计算各个指标的均值与其标准差,使用标准差标准化公式完成LRFMC指标的标准化,并将标准化后的数据进行保存。
2)编写Python程序,完成客户的K-Means聚类,获得聚类中心与类标号。输出聚类中心的特征图,并统计每个类别的客户数。
四、实验结果
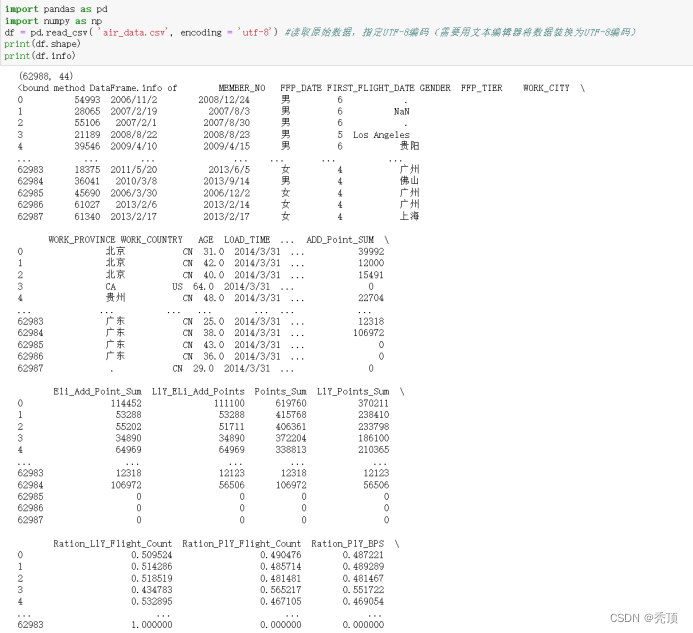
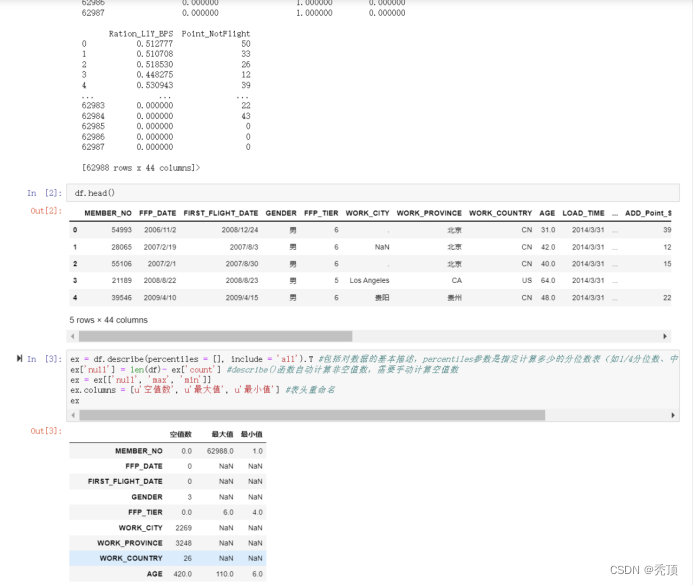
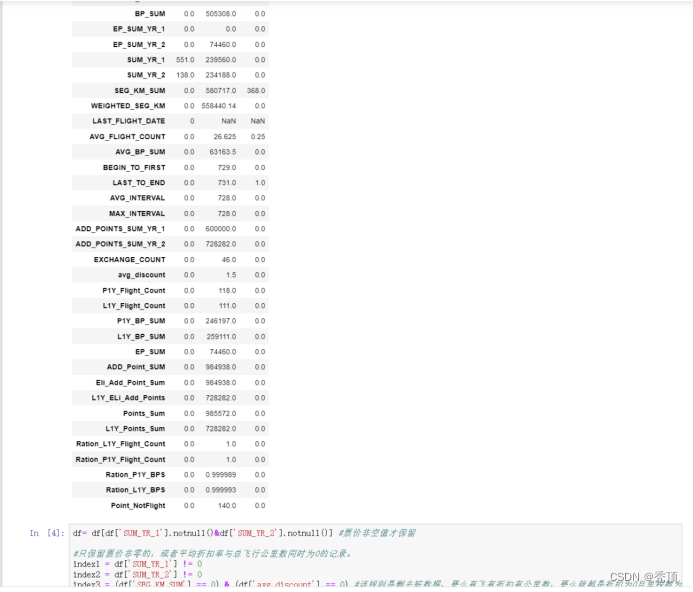
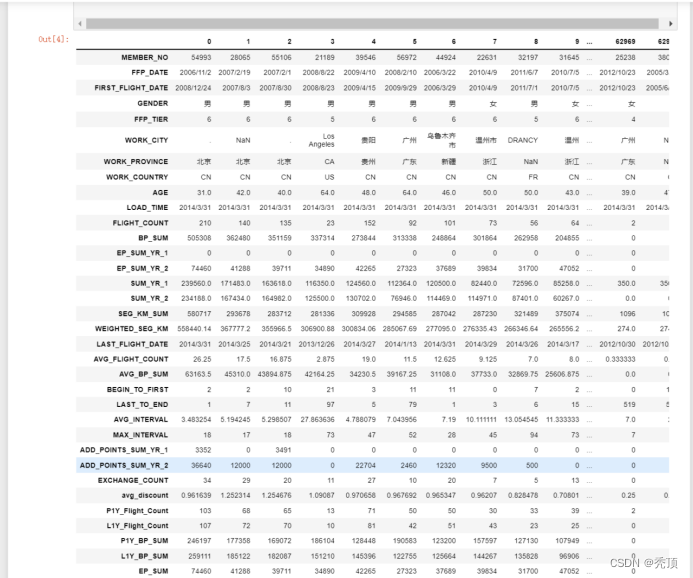

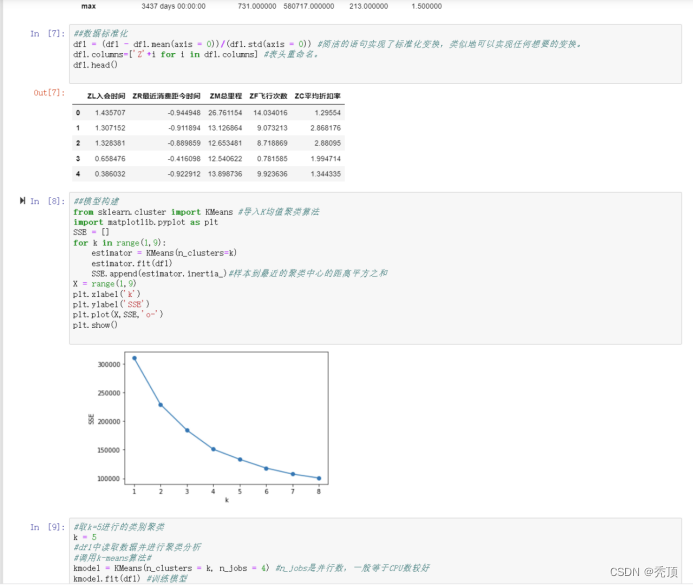
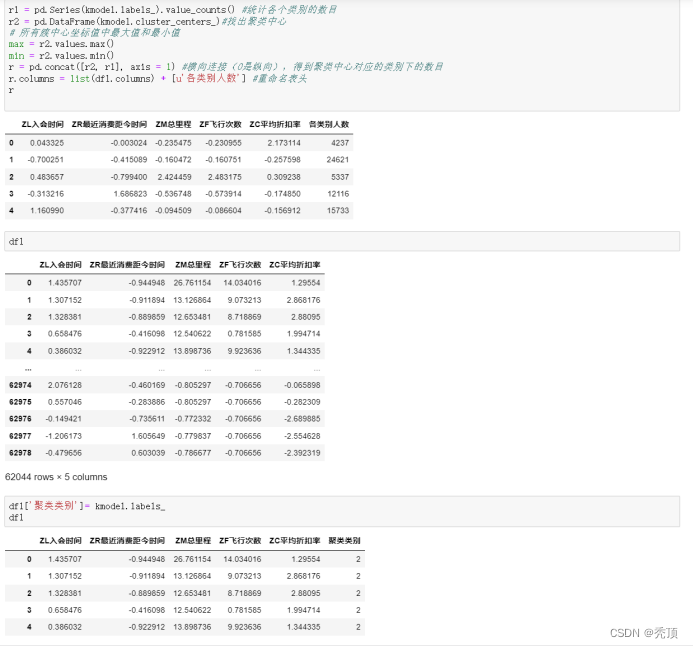
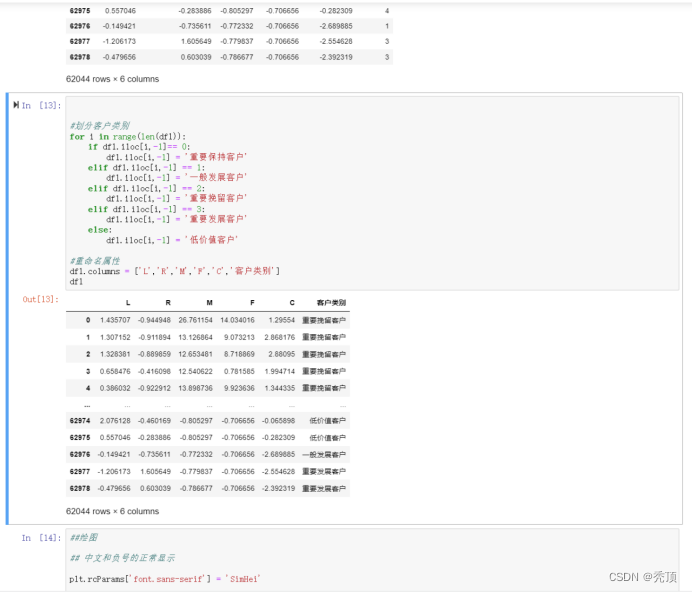
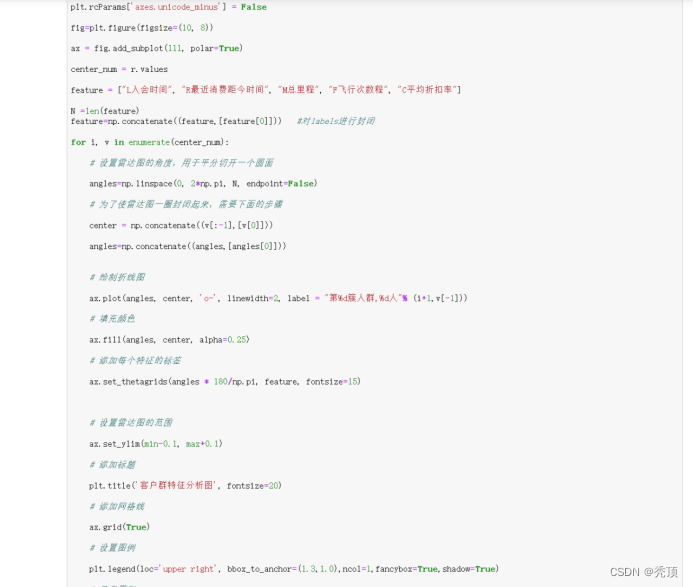
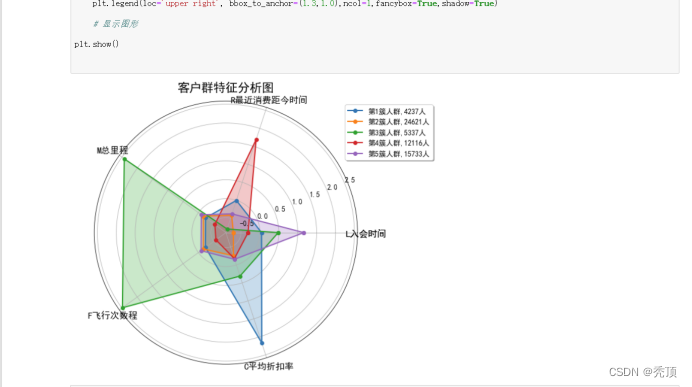
五、分析与讨论
对于LRMFC模型,其L\M\F\C指标越大越好,R指标越小越好,我们根据聚类中心结果来对各个客户群进行特征划分。依此找出每个特征对应的最大值、最小值、次大值、次小值。