前言
传送门:
stable diffusion:Git|论文
stable-diffusion-webui:Git
Google Colab Notebook:Git
kaggle Notebook:Git
今年AIGC实在是太火了,让人大呼许多职业即将消失,比如既能帮忙写代码,又能写文章的ChatGPT。当然,还有AI绘画,输入一段文本就能生成相关的图像,stable diffusion便是其中一个重要分支。自己对其中的原理比较感兴趣,因此开启这个系列的文章来对stable diffusion的原理进行学习(主要是针对“文生图”[text to image])。
上述的stable-diffusion-webui是AUTOMATIC1111开发的一套UI操作界面,可以在自己的主机上搭建,无限生成图像(实测2080ti完全能够胜任),如果没有资源,可以白嫖Google Colab或者kaggle的GPU算力。
其中stable diffusion的基础模型可以hugging face下载,而C站可以下载各种风格的模型。stable diffusion有一个很大的优势就是基于C站中各式各样的模型,我们可以进行不同风格的AI绘画。
而这篇文章,首先对其中的一个组件进行学习:Autoencoder。
原理简介
Stable Diffusion is a latent text-to-image diffusion model。stable diffusion本质是一种latent diffusion models(LDMs),隐向量扩散模型。diffusion models (DMs)将图像的形成过程分解为去噪自动编码器(denoising autoencoders)的一系列操作,但这些都是直接在像素空间上进行的操作,因此对于昂贵的计算资源,特别是高像素的图像。而LDMs则是引入隐向量空间,能够生成超高像素的图像。
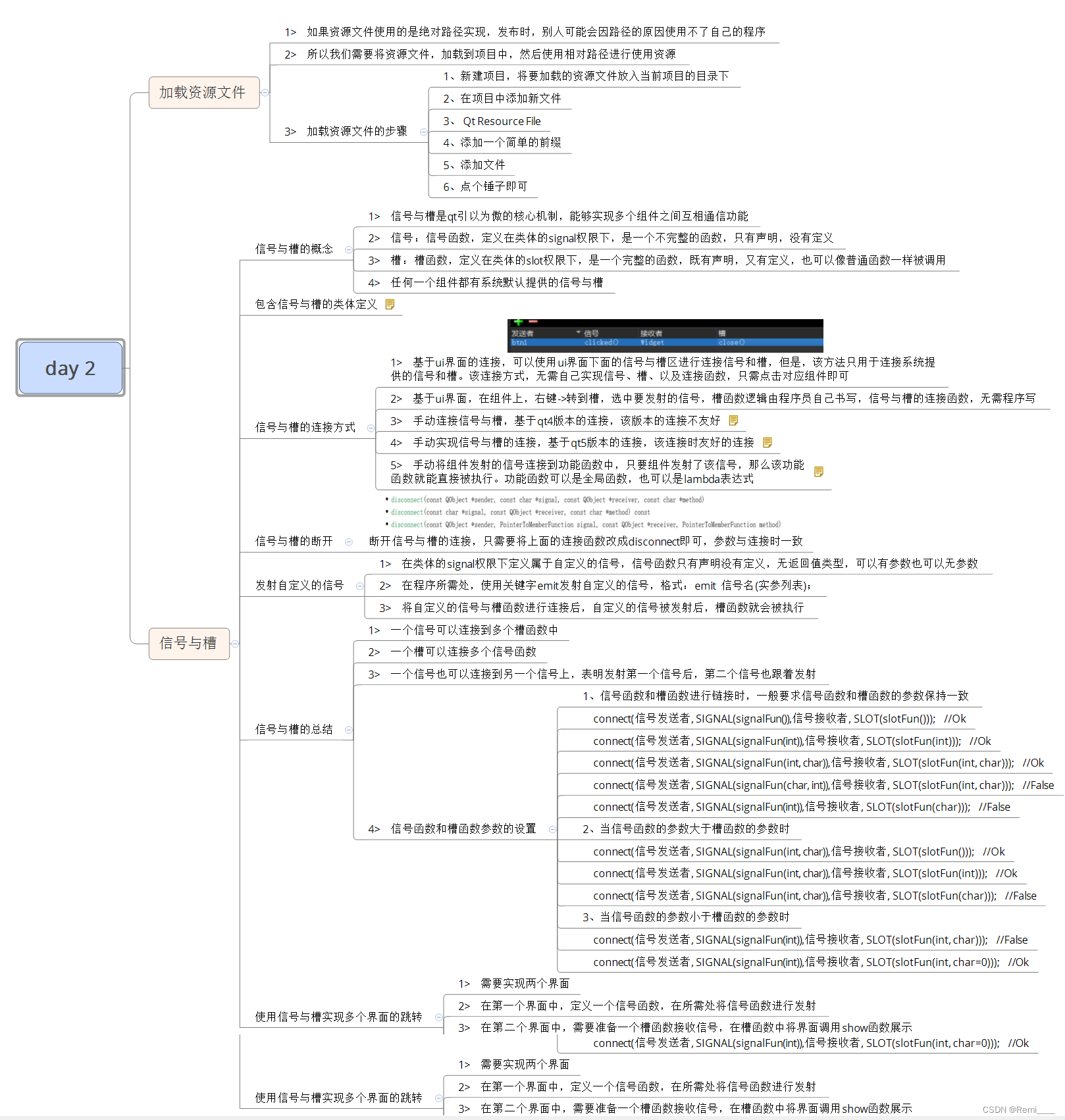
这里,我们先整体地来了解下stable diffusion的结构组成,后面再对每个组件进行拆开逐一理解。整体结构如下图[Stable Diffusion Architecture]:
- 文本编码器:人类输入的文本即prompt,经过CLIP模型中的Text Encoder,转化为语义向量(Token Embeddings);
- 图像生成器(Image information Creator):U-Net、采样器以及Autoencoder组成。由随机生成的纯噪声向量(即下图中的Noisey Image)开始,通过Autoencoder编码映射到低维的隐空间,文本语义向量作为控制条件进行指导,由U-Net和采样器不断迭代生成新的越具有丰富语义信息的隐向量,这就是扩散过程diffusion;
- 图像解码器(Image Decoder)- Autoencoder:迭代了一定次数之后,得到了包含丰富语义信息的隐向量(Processed Image Info Tensor),低维的隐向量经过Autoencoder解码到原始像素;
- 第2步就是LDMs和DMs的区别,LDMs是在latent space进行扩散,而DMs则是在pixel space,这也是性能提升的关键。
Autoencoder
[1] 论文:Taming Transformers for High-Resolution Image Synthesis
[2] Git:taming-transformers
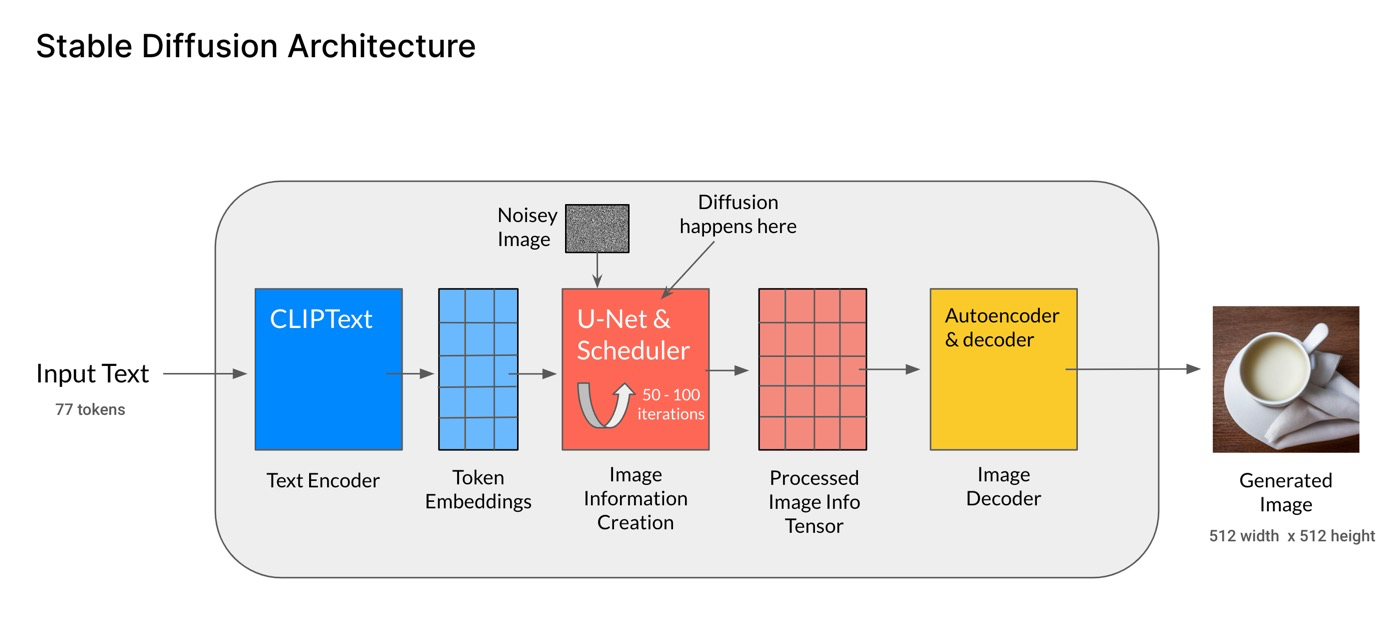
图片的隐空间表征从何而来:Autoencoder,既能够将图片从像素空间压缩到隐空间,让扩散过程在latent space中进行,又可以让图片从隐空间重建到像素空间(即图片重建),简化的过程如下图所示:
- 其中的encoder可以将一张图片从RGB空间即像素空间 x ∈ R H × W × 3 x\in \mathbb{R}^{H\times W \times 3} x∈RH×W×3,经过encoder编码到隐空间表征(latent representation) z = ε ( x ) z= \varepsilon(x) z=ε(x);
- decoder则是将隐空间表征重建到图片RGB x ~ = D ( z ) = D ( ε ( x ) ) \tilde{x}=D(z)=D(\varepsilon(x)) x~=D(z)=D(ε(x));
- 其中, z ∈ R h × w × c z\in \mathbb{R}^{h \times w \times c} z∈Rh×w×c,重要的是,控制隐空间大小的是编码器的下采样因子(downsampling factors): f = H / h = W / w , f = 2 m , m ∈ N f=H/h=W/w,f=2^m,m \in \mathbb{N} f=H/h=W/w,f=2m,m∈N
上述仅仅是从整体架构层面简单地描述了图片的隐空间与像素空间的转换与重建过程,但其实整个过程的细节还是比较复杂的,方法是出自VQGAN [ 1 ] ^{[1]} [1],其结构如下图所示:
- 论文认为高像素的图片合成需要模型能够理解图片的全局组成,使得局部和全局现实的生成能够保持一致。
- 因此,论文使用codebook来对图片的丰富视觉组成进行表征,而不是像素表征,codebook即是隐空间的表现形式。
- codebook可以大大减少的图片组成长度(相比像素),也使得能用transformer来高效地对图片内部的全局交互( global interrelations)进行建模。
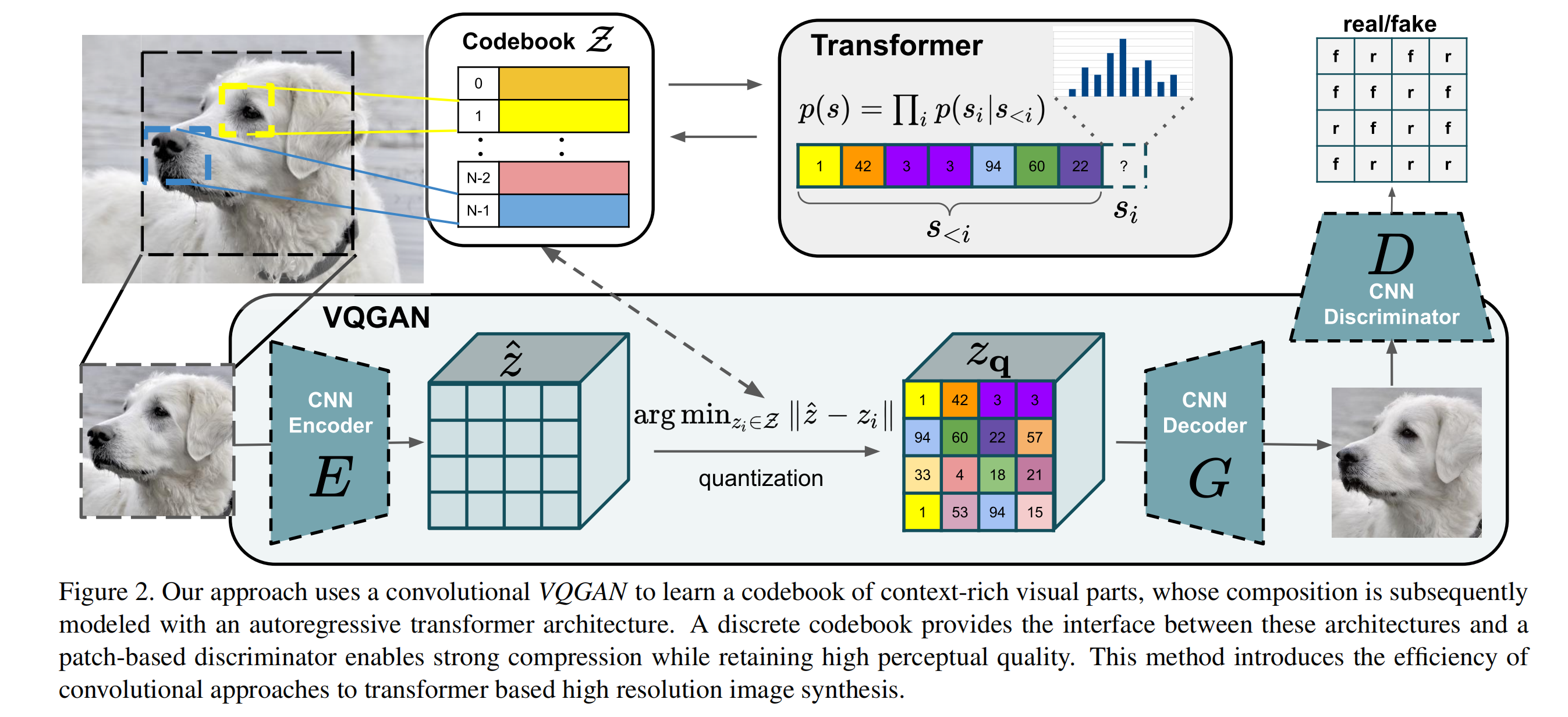
Codebook
给定一张图片 x ∈ R H × W × 3 x\in \mathbb{R}^{H\times W \times 3} x∈RH×W×3,需要将x表征为离散空间的codebook集合 z q ∈ R h × w × n z z_q \in \mathbb{R}^{h\times w \times n_z} zq∈Rh×w×nz,其中 h ⋅ w h \cdot w h⋅w可以认为是codebook中每个code的索引,而 n z n_z nz是code的维度。学习这样的codebook表征需要以下几个组件:
- 一个离散的codebook Z = { z k } k = 1 K ∈ R n z Z=\{z_k\}^K_{k=1} \in \mathbb{R}^{n_z} Z={zk}k=1K∈Rnz(可以当成embedding来理解,参数随机初始化,参与模型训练 ,但论文对这块没有清晰的描述,可以去看源码)
- CNN结构的encoder E,可以将图片 x x x编码为 z ^ ∈ R h × w × n z \hat{z} \in \mathbb{R}^{h\times w \times n_z} z^∈Rh×w×nz
- CNN结构的decoder G,能够将codebook z q z_q zq重建为图像 x ^ \hat{x} x^
- quantization操作,将 z ^ \hat{z} z^映射到 z q z_q zq
具体的
z
q
z_q
zq编码过程为:编码器E将x转化为
z
^
=
E
(
x
)
∈
R
h
×
w
×
n
z
\hat{z}=E(x) \in \mathbb{R}^{h\times w \times n_z}
z^=E(x)∈Rh×w×nz,然后通过element-wise quantization
q
(
⋅
)
q(\cdot)
q(⋅)将每个离散的code
z
^
i
j
∈
R
n
z
\hat{z}_{ij} \in \mathbb{R}^{n_z}
z^ij∈Rnz编码到距离最近的codebook entry
z
k
z_k
zk(这里产生的最邻近的
z
k
z_k
zk索引即为上图[VQGAN]的
s
i
s_i
si,后续会用到)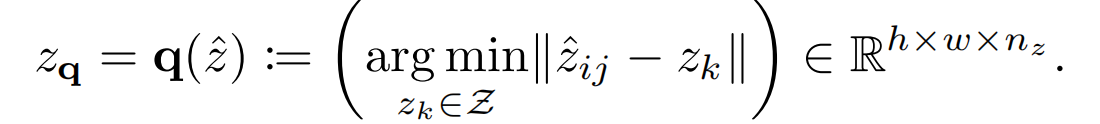
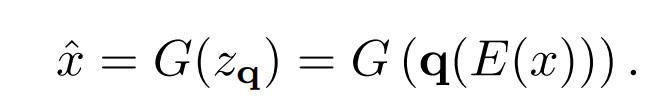
这部分的损失函数如下式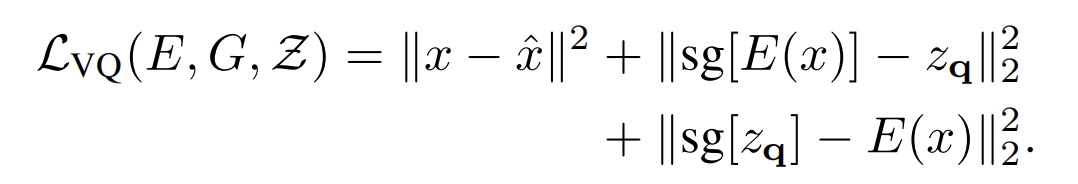
其中 L r e c = ∣ ∣ x − x ^ ∣ ∣ 2 L_{rec}=||x-\hat{x}||^2 Lrec=∣∣x−x^∣∣2为重建loss, s g [ ⋅ ] sg[\cdot] sg[⋅]为stop-gradient操作。由于 z q z_q zq的quantization操作是不可微分的,因此需要用到梯度拷贝(出自straight-through gradient estimator)
Discriminator
论文:Image-to-Image Translation with Conditional Adversarial Networks
Git:https://github.com/phillipi/pix2pix
使用transformer来表征图片的隐性图像成分的分布,需要进一步逼近图片压缩的极限和学习更富含信息的codebook,因此,论文还训练一个patch-based的判别器D,让它能够区分真实和重建的图片:
真实图像和重建图像都会经过一个CNN结构的Discriminator,然后得到每个patch的预估概率,模型的训练目标就是让真实图像的预估概率尽量都为1,而重建图像的预估概率尽量都为0,简而言之,就是让Discriminator能够识别每个patch是来自真实图像还是重建图像,如下图红框部分: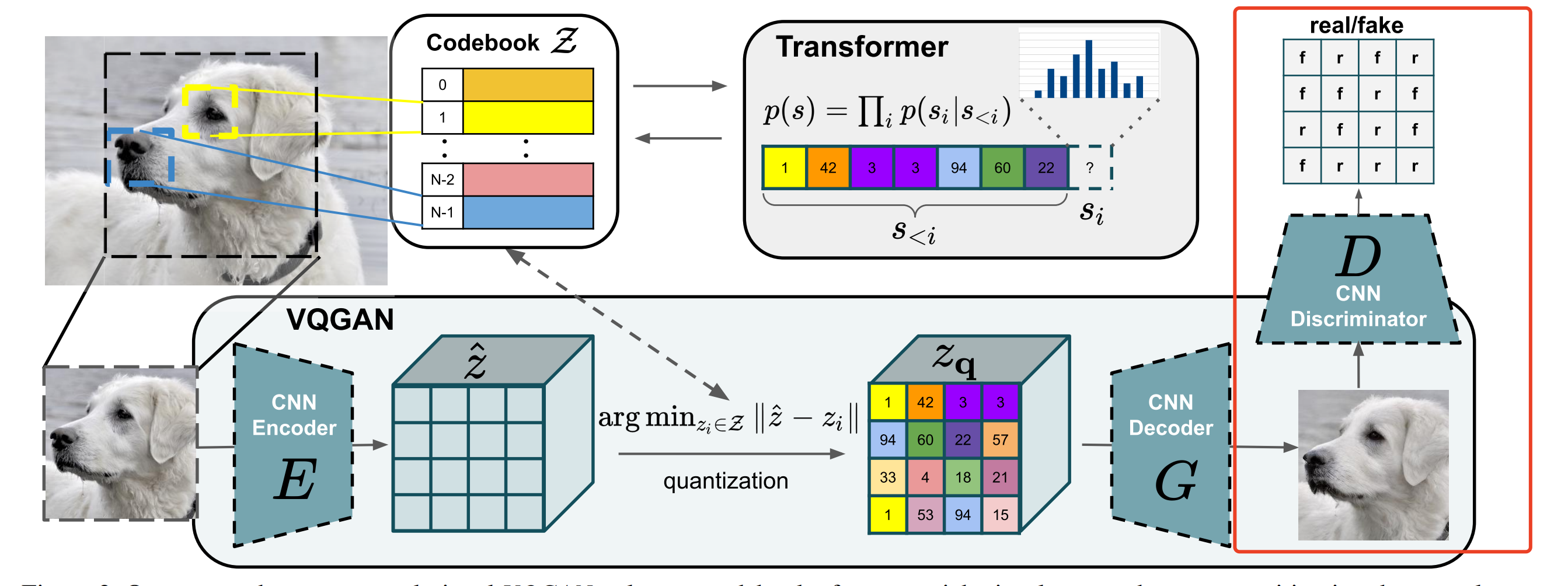
上述这两部分是联合训练:
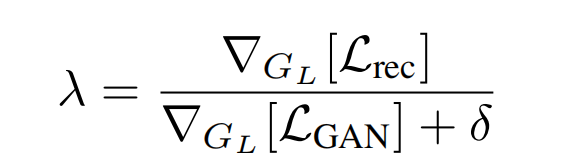
其中, ∇ G L [ ⋅ ] \nabla_{G_L}[\cdot] ∇GL[⋅]是decoder最后一层网络的梯度,而 δ = 1 0 − 6 \delta=10^{-6} δ=10−6。
Transformers
Latent Transformers.
编码器E和解码器G训练完成之后,按照上述同样的操作,通过E和quantization操作,可以将图片
x
x
x表征到codebook
z
q
=
q
(
E
(
x
)
)
∈
R
h
×
w
×
n
z
z_q=q(E(x)) \in \mathbb{R}^{h \times w \times n_z}
zq=q(E(x))∈Rh×w×nz,
h
⋅
w
h \cdot w
h⋅w可以认为是codebook中每个code的索引
s
i
s_i
si,然后将二维的索引变为一维的,相当于一个code序列
s
∈
{
0
,
.
.
.
,
∣
Z
∣
−
1
}
h
×
w
s \in \{0,...,|Z|-1\}^{h \times w}
s∈{0,...,∣Z∣−1}h×w: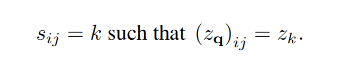
到这里,我们就可以按照NLP的自回归模型“预测下一个词”的思路来理解:给定code索引序列(上文)
s
<
i
s<i
s<i,利用transformer来学习下一个code索引(下文)的概率分布
p
(
s
i
∣
s
<
i
)
p(s_i|s<i)
p(si∣s<i),最大化完整表征序列的似然估计
p
(
s
)
=
∏
i
p
(
s
i
∣
s
<
i
)
p(s)=\prod_ip(s_i|s<i)
p(s)=∏ip(si∣s<i):
Conditioned Synthesis.
在许多图片合成任务中,往往会加入额外的信息来控制图片的合成过程,这个额外信息称为
c
c
c,它可以是一个对图片的标签描述或者另外的图片。那么,学习的似然估计则变为: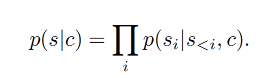
机制理解
在最后,通过源码仓库里的两个实操案例notebook来理解Autoencoder这些组建的工作机制。
图像重建.
VQGAN可以将图片输入编码到低维的codebook空间(隐空间),然后再对codebook空间重建为图片的像素空间,如下图所示。更重要的是,这个过程的中间产物-隐空间,相较于像素空间,能够以很小的特征空间来表征图片,可以迁移到attention机制底座的模型训练的下流任务,比如本文的主题:Stable Diffusion。
def reconstruct_with_vqgan(x, model):
# could also use model(x) for reconstruction but use explicit encoding and decoding here
z, _, [_, _, indices] = model.encode(x)
print(f"VQGAN --- {model.__class__.__name__}: latent shape: {z.shape[2:]}")
xrec = model.decode(z)
return xrec

草图绘画.
这里主要是可以帮助理解VQGAN中Transformer的作用:
- 草图经过VQGAN的编码器得到codebook索引序列c- s i s_i si(c-仅是前缀,为了与成品图进行区分);
- 随机生成 成品图的codebook索引序列z- s i s_i si;
- 然后草图的索引序列c- s i s_i si作为控制条件,即上述提到Conditioned Synthesis章节中的 c c c,拼接在z- s i s_i si的前面(z- s i s_i si每次截取一段),输入到Transformer,去预测z- s i s_i si的每一个位置,预测得到的索引逐步替代随机生成的索引序列;
- 最后,这个生成的索引序列再进入解码器G重建为图片(成品图)。