一、说明
每天,人类在执行诸如过马路之类的任务时都会做出被动预测,他们估计汽车的速度和与汽车的距离,或者通过猜测球的速度并相应地定位手来接球。这些技能是通过经验和实践获得的。然而,由于涉及众多变量,预测天气或经济等复杂现象可能很困难。在这种情况下使用时间和序列预测,依靠历史数据和数学模型对未来趋势和模式进行预测。在本文中,我们将看到使用航空公司数据集使用数学概念进行预测的示例。
二、第1部分:
2.1 数学概念
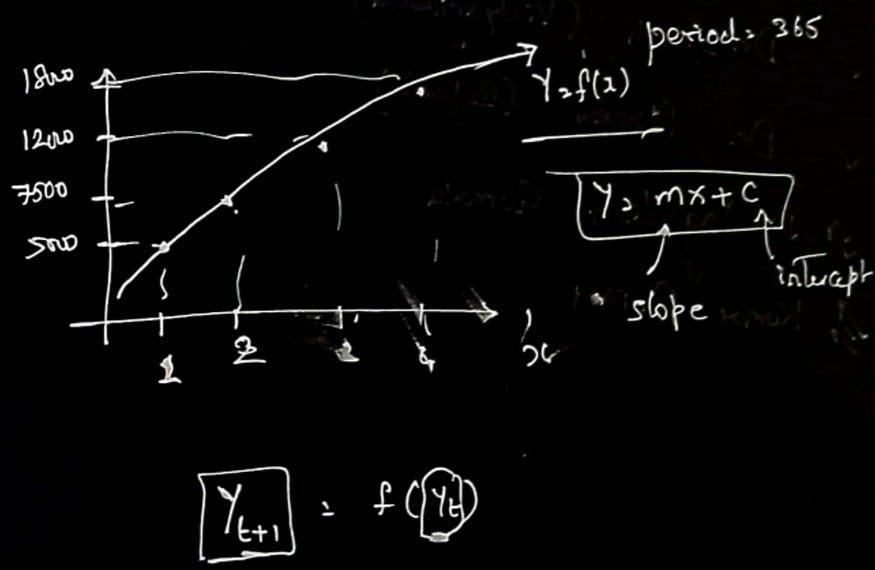
在本文使用的时间序列预测算法的上下文中,该算法不是手动计算线的斜率和截距,而是使用具有 LSTM 层的神经网络来学习时间序列数据中的基础模式和关系。神经网络在一部分数据上进行训练,然后用于对剩余部分进行预测。在该算法中,下一个时间步长的预测基于前面n_inputs的时间步长,类似于线性回归示例中使用 y(t) 预测 y(T+1) 的概念。但是,该算法中的预测不是使用简单的线性方程,而是使用 LSTM 层的激活函数生成的。激活函数允许模型捕获数据中的非线性关系,使其更有效地捕获时间序列数据中的复杂模式。
2.2 激活功能

摄影:@learnwithutsav
LSTM 模型中使用的激活函数是整流线性单元 (ReLU) 激活函数。这种激活函数通常用于深度学习模型,因为它在处理梯度消失问题方面简单有效。在 LSTM 模型中,ReLU 激活函数应用于每个 LSTM 单元的输出,以在模型中引入非线性,并允许它学习数据中的复杂模式。ReLU 函数具有简单的阈值行为,其中任何负输入都映射到零,任何正输入都保持不变地通过,从而使其计算效率高。
三、第 2 部分:
3.1 实施
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('airline-passengers.csv', index_col='Month', parse_dates=True)
df.index.freq = 'MS'
df.shape
df.columns
plt.figure(figsize=(20, 4))
plt.plot(df.Passengers, linewidth=2)
plt.show()该代码导入了三个重要的库:numpy、pandas 和 matplotlib。熊猫库用于读取“航空公司乘客.csv”文件,并将“月”列设置为索引,从而允许随时间分析数据。然后,该代码使用 matplotlib 库创建一个线图,显示一段时间内的航空公司乘客数量。最后,使用“plt.show”功能显示绘图。此代码对于任何对分析时序数据感兴趣的人都很有用,它演示了如何使用 pandas 和 matplotlib 来可视化数据趋势。

nobs = 12
df_train = df.iloc[:-nobs]
df_test = df.iloc[-nobs:]
df_train.shape
df_test.shape此代码通过将现有时间序列数据帧“df”拆分为训练集和测试集来创建两个新的数据帧“df_train”和“df_test”。“nobs”变量设置为 12,这意味着“df”的最后 12 个观测值将用于测试,而其余数据将用于训练。训练集存储在“df_train”中,由“df”中除最后12行以外的所有行组成,而测试集存储在“df_test”中,仅由“df”的最后12行组成。然后使用“shape”属性打印每个数据框中的行数和列数,从而确认拆分正确完成。此代码通过将时序数据拆分为两组,可用于准备用于建模和测试目的的时序数据。
3.2 模型架构
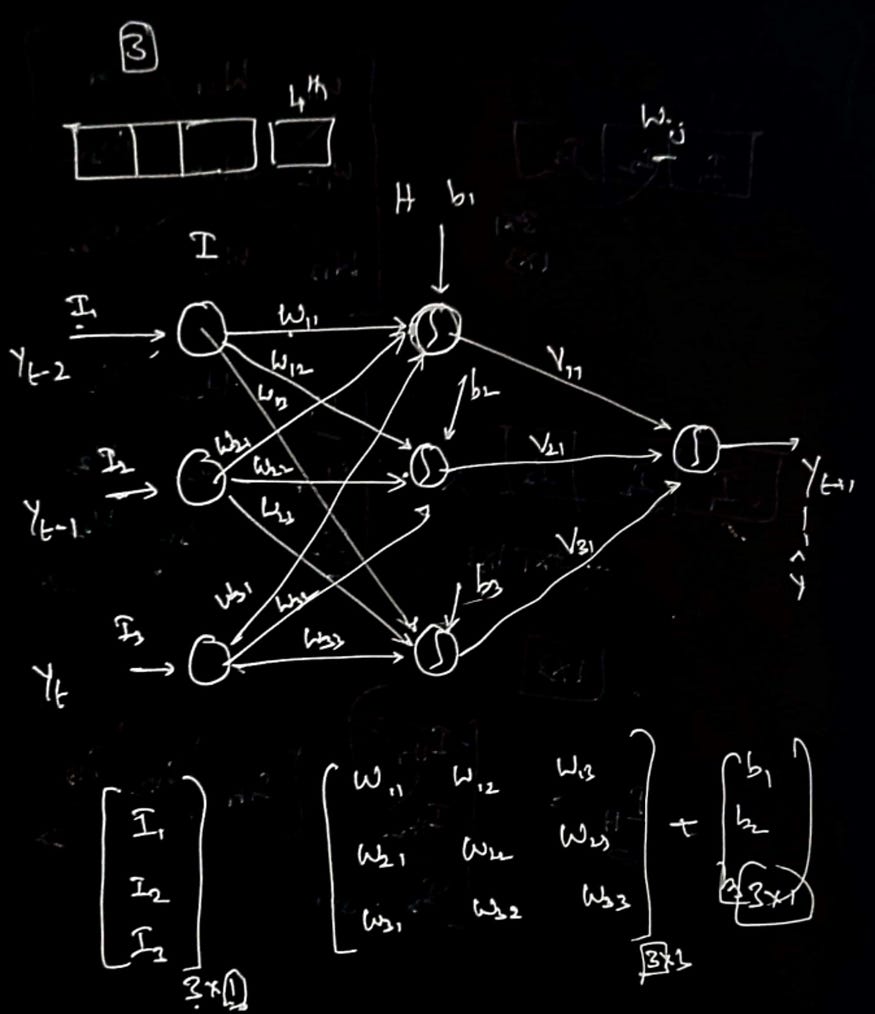
图片来源:@learnwithutsav
from keras.preprocessing.sequence import TimeseriesGenerator
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(df_train)
scaled_train = scaler.transform(df_train)
scaled_test = scaler.transform(df_test)n_inputs = 12
n_features = 1
generator = TimeseriesGenerator(scaled_train, scaled_train, length = n_inputs, batch_size =1)
for i in range(len(generator)):
X, y = generator[i]
print(f' \n {X.flatten()} and {y}')此代码片段演示了如何使用 Keras 的“TimeseriesGenerator”类和 scikit-learn 的“MinMaxScaler”类为时间序列预测模型生成输入和输出数组。代码首先创建“MinMaxScaler”类的实例,并将其拟合到训练数据集(“df_train”),以便缩放数据。然后将缩放后的数据存储在“scaled_train”和“scaled_test”数据框中。时间步长数 ('n_inputs“) 设置为 12,要素数 ('n_features') 设置为 1。使用“scaled_train”数据创建“TimeseriesGenerator”对象,窗口长度为“n_inputs”,批大小为 1。最后,循环用于迭代“生成器”对象并打印出每个时间步的输入和输出数组。“X”和“y”变量分别表示每个时间步长的输入和输出数组。“flatten()”方法用于将输入数组转换为一维数组,以便于打印。总体而言,此代码对于准备使用滑动窗口方法预测模型的时间序列数据非常有用。

X.shape此代码返回数组或矩阵“X”的形状。“shape”属性是 NumPy 数组的一个属性,并返回一个表示数组维度的元组。该代码没有提供任何其他上下文,因此不清楚“X”的形状是什么。输出将采用以下格式(行、列)。

from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
model = Sequential()
model.add(LSTM(200, activation='relu', input_shape = (n_inputs, n_features)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
model.summary()此代码演示如何使用 Keras 创建用于时间序列预测的 LSTM 神经网络模型。首先,导入必要的 Keras 类,包括“顺序”、“密集”和“LSTM”。该模型被创建为“顺序”对象,并添加了一个包含 200 个神经元、“relu”激活函数以及由“n_inputs”和“n_features”定义的输入形状的 LSTM 层。然后将 LSTM 层输出传递到具有单个输出神经元的“密集”层。该模型使用“adam”优化器和均方误差(“mse”)损失函数进行编译。'summary()' 方法用于显示架构的摘要,包括参数的数量以及每层输入和输出张量的形状。此代码可用于创建用于时间序列预测的 LSTM 模型,因为它提供了一个易于遵循的示例,可以适应不同的数据集和预测问题。

3.3 训练阶段

model.fit(generator, epochs = 50)此代码使用 Keras 中的“fit()”方法训练 LSTM 神经网络模型 50 个 epoch。“TimeseriesGenerator”对象生成成批的输入/输出对,供模型学习。'fit()' 方法使用基于模型编译期间定义的损失函数和优化器的反向传播来更新模型参数。通过训练模型,它学习根据训练数据中学习的模式对新的、看不见的数据进行预测。

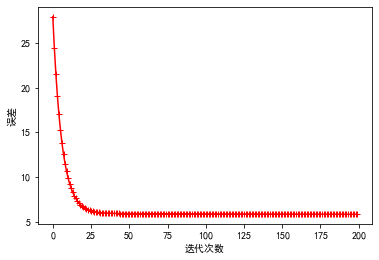
plt.plot(model.history.history['loss'])
last_train_batch = scaled_train[-12:]
last_train_batch = last_train_batch.reshape(1, 12, 1)
last_train_batch
model.predict(last_train_batch)此代码使用经过训练的 LSTM 神经网络模型对新数据点进行预测。从训练数据中选择、缩放并调整为模型的适当格式。在模型上调用“predict()”方法,将重塑的数据作为输入,输出是时间序列中下一个时间步长的预测值。这是使用 LSTM 模型进行时间序列预测的重要步骤。
<span style="background-color:#f9f9f9"><span style="color:#242424">scaled_test[0]</span></span>此代码打印缩放测试数据数组的第一个元素。“scaled_test”变量是使用“MinMaxScaler”对象转换的测试数据的 NumPy 数组。打印此数组的第一个元素将显示测试数据中第一个时间步长的缩放值。
![]()
3.4 预测
y_pred = []
first_batch = scaled_train[-n_inputs:]
current_batch = first_batch.reshape(1, n_inputs, n_features)
for i in range(len(scaled_test)):
batch = current_batch
pred = model.predict(batch)[0]
y_pred.append(pred)
current_batch = np.append(current_batch[:,1:, :], [[pred]], axis = 1)
y_pred
scaled_test此代码使用经过训练的 LSTM 模型生成测试数据的预测。它使用 for 循环循环遍历缩放测试数据中的每个元素。在每次迭代中,当前批处理用于使用模型的“predict()”方法进行预测。然后将预测值添加到“y_pred”列表中,并更新当前批次。最后,将“y_pred”列表与“scaled_test”数据一起打印,以将预测值与实际值进行比较。此步骤对于评估 LSTM 模型在测试数据上的性能至关重要。

df_test
y_pred_transformed = scaler.inverse_transform(y_pred)
y_pred_transformed = np.round(y_pred_transformed,0)
y_pred_final = y_pred_transformed.astype(int)
y_pred_final此代码使用 scaler 对象的“inverse_transform()”方法将上一步中生成的预测值转换回原始比例。转换后的值使用 'round()' 函数舍入到最接近的整数,并使用 'astype()' 方法转换为整数。打印生成的预测值数组“y_pred_final”,以显示测试数据的最终预测值。此步骤对于评估 LSTM 模型在数据原始尺度上的预测的准确性非常重要。

df_test.values, y_pred_final
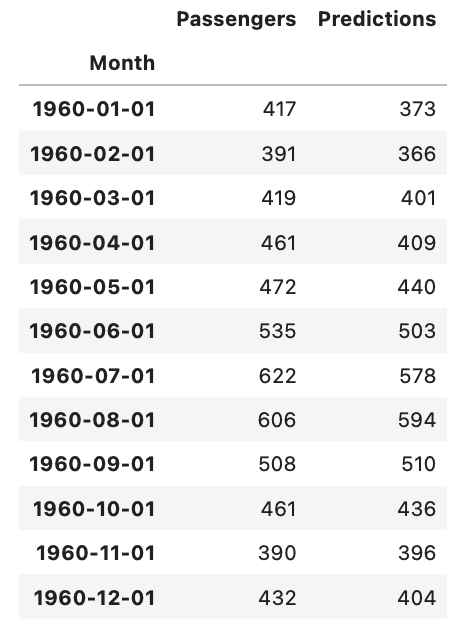
df_test['Predictions'] = y_pred_final
df_test上面的代码显示了添加到原始测试数据集的 LSTM 模型生成的预测值。首先,“values”属性用于提取“df_test”数据帧的值,然后将其与预测值“y_pred_final”配对。然后,将一个名为“预测”的新列添加到“df_test”数据帧以存储预测值。最后,使用新添加的“预测”列打印“df_test”数据帧。此步骤对于直观地将测试数据集的实际值与预测值进行比较并评估模型的准确性非常重要。
plt.figure(figsize=(15, 6))
plt.plot(df_train.index, df_train.Passengers, linewidth=2, color='black', label='Train Values')
plt.plot(df_test.index, df_test.Passengers, linewidth=2, color='green', label='True Values')
plt.plot(df_test.index, df_test.Predictions, linewidth=2, color='red', label='Predicted Values')
plt.legend()
plt.show()此代码块正在使用库生成绘图。它首先设置图形大小,然后将训练数据绘制为黑线,将真实测试值绘制为绿线,将预测的测试值绘制为红线。它还向绘图添加图例,并使用该方法显示图例。matplotlibshow()

3.5均方误差

均方误差 (MSE) 是回归线与一组点的接近程度的度量。它是通过取预测值和实际值之间的平方差的平均值来计算的。MSE 的平方根称为均方根误差 (RMSE),这是预测准确性的常用度量。在此代码块中,RMSE 是使用模块中的函数和模块 中的函数计算的 。RMSE 用于评估 LSTM 模型预测的准确性与测试集中的真实值相比。mean_squared_errorsklearn.metricssqrtmath
from sklearn.metrics import mean_squared_error
from math import sqrt
sqrt(mean_squared_error(df_test.Passengers, df_test.Predictions)) 此代码计算测试集中的实际乘客值 () 与预测乘客值 () 之间的均方根误差 (RMSE)。RMSE 是评估回归模型性能的常用指标。它测量预测值和实际值之间的平均距离,同时考虑它们之间差值的平方。RMSE 是一个有用的指标,因为它对大误差的惩罚比小误差更严重,使其成为模型预测整体准确性的良好指标。df_test.Passengersdf_test.Predictions
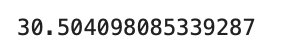
总之,我们在 Keras 中使用 LSTM 算法实现了时间序列预测模型。我们在每月航空公司乘客数据集上训练了模型,并使用它来预测未来 12 个月。该模型表现良好,均方根误差为 30.5。真实值、预测值和训练值的可视化表明,该模型能够捕获数据中的总体趋势和季节性。这证明了 LSTM 在捕获时间序列数据中复杂时间关系方面的强大功能及其进行准确预测的潜力。
四、结论
本文示例是一个典型的时间序列处理办法,可以当作经典来用。读者可以多花一些时间消化该案例;事实表明,用LSTM这种工具不仅可以处理NLP,而且可以针对任何的时间序列,比如股票预测。