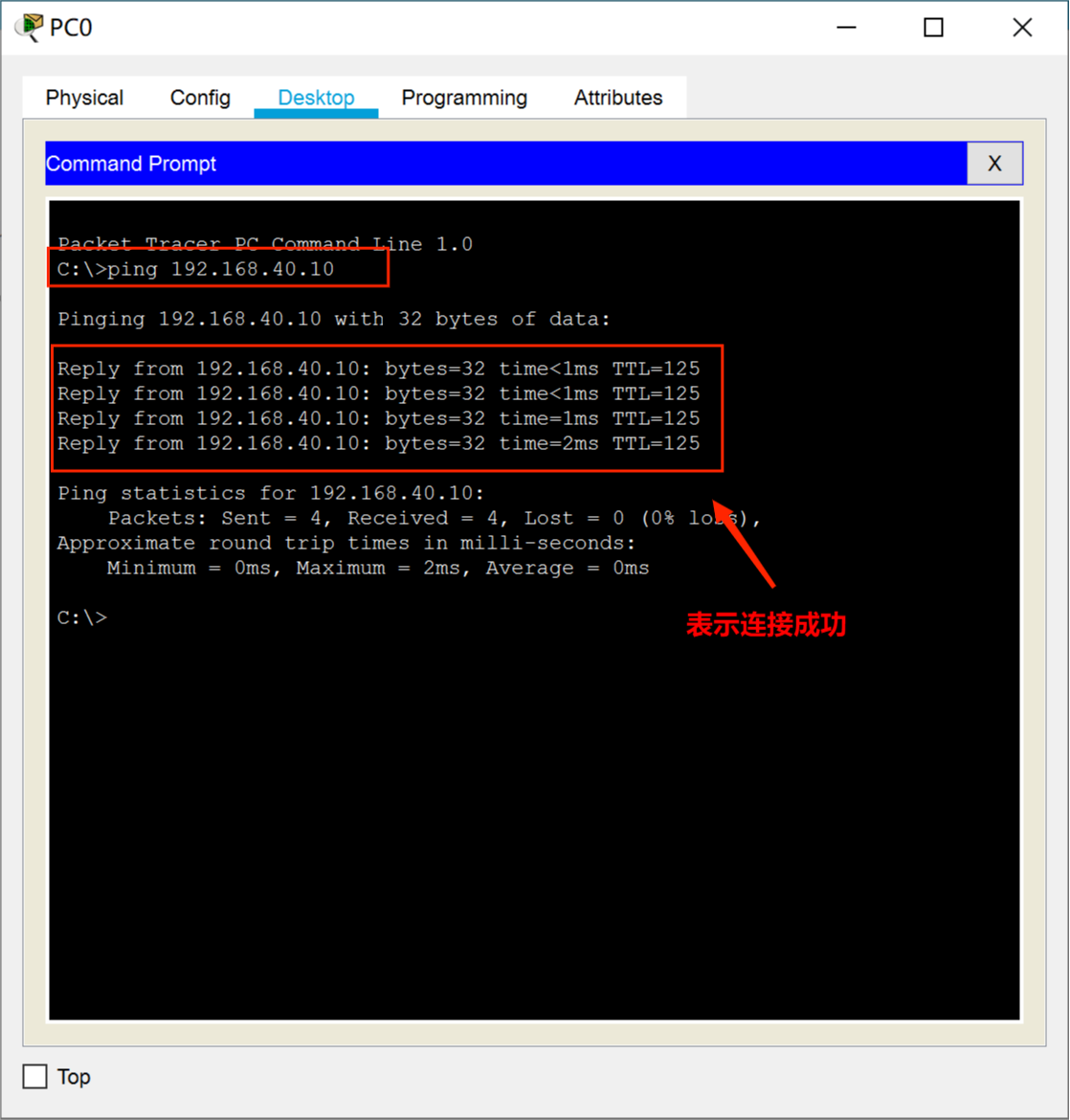
中文通用大模型综合性测评基准(SuperCLUE),是针对中文可用的通用大模型的一个测评基准。
它主要要回答的问题是:在当前通用大模型大力发展的情况下,中文大模型的效果情况。包括但不限于:这些模型哪些相对效果情况、相较于国际上的代表性模型做到了什么程度、 这些模型与人类的效果对比如何?
它尝试在一系列国内外代表性的模型上使用多个维度能力进行测试。SuperCLUE,是中文语言理解测评基准(CLUE)在通用人工智能时代的进一步发展。
SuperCLUE基准计划按照月度进行更新,数据集和进一步信息计划在下一次更新时公开,敬请期待。
Github项目地址:https://github.com/CLUEbenchmark/SuperCLUE



SuperCLUE的构成
着眼于综合评价大模型的能力,使其能全面的测试大模型的效果,又能考察模型在中文上特有任务的理解和积累,我们对能力进行了划分。SuperCLUE从三个不同的维度评价模型的能力:基础能力、专业能力和中文特性能力。
-
基础能力:
包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色扮演、代码、生成与创作等10项能力。 -
专业能力:
包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力。 -
中文特性能力:
针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等10项多种能力。
SuperCLUE的特点
-
多个维度能力考察(3大类70+子能力):从三个不同角度对中文大模型进行测试,以考察模型的综合能力;并且每一个子能力又含有十项或以上不同的细分能力。
-
自动化测评(一键测评):通过自动化测评方式以相对客观形式测试不同模型的效果,可以一键对大模型进行测评。
-
广泛的代表性模型(9个模型):选取了多个国内外有代表性的可用的模型进行测评,以反应国内大模型的发展现状并了解与国际领先模型的差距或相对优劣势。
-
人类基准:在通用人工智能发展的情况下,也提供了模型相对于人类效果的指标对比。
SuperCLUE的不足与局限
-
基础能力、中文特性能力:虽然每一部分都包含了10类子能力,但这两个能力的总数据量比较少,可能存在需要扩充数据集的问题。
-
选取模型的不完全:我们测试了9个模型,但还存在着更多的可用中文大模型。需要后续进一步添加并测试;有的模型由于没有广泛对外提供服务,我们没能获取到可用的测试版本。
-
选取的能力范围:我们尽可能的全面、综合衡量模型的多维度能力,但是可能有一些模型能力没有在我们的考察范围内。后续也存在扩大考察范围的可能。
-
客观考察的不足:我们以相对客观形式考察模型能力,但一些主观、开放性问题的模型能力的考察可能存在不足。
SuperCLUE总榜单

SuperCLUE基础能力榜单

SuperCLUE中文特性榜单

SuperCLUE开源榜单