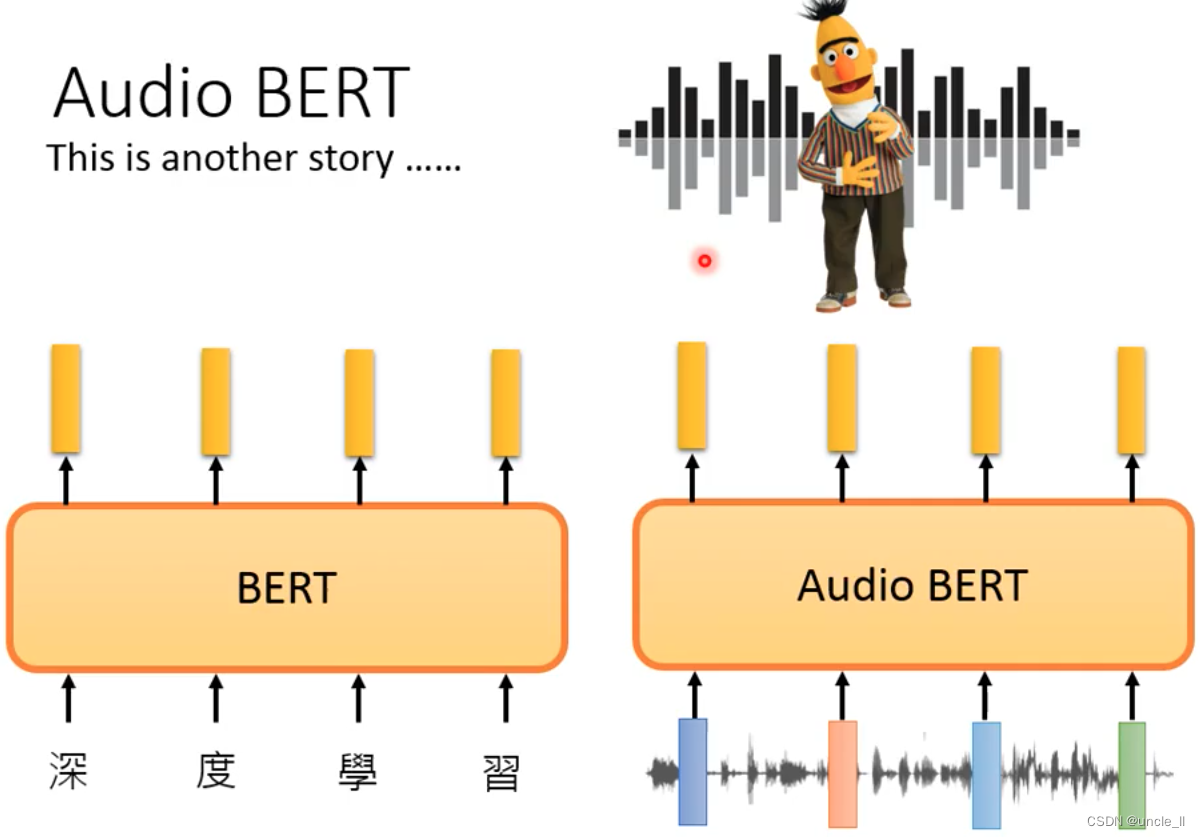
Bert
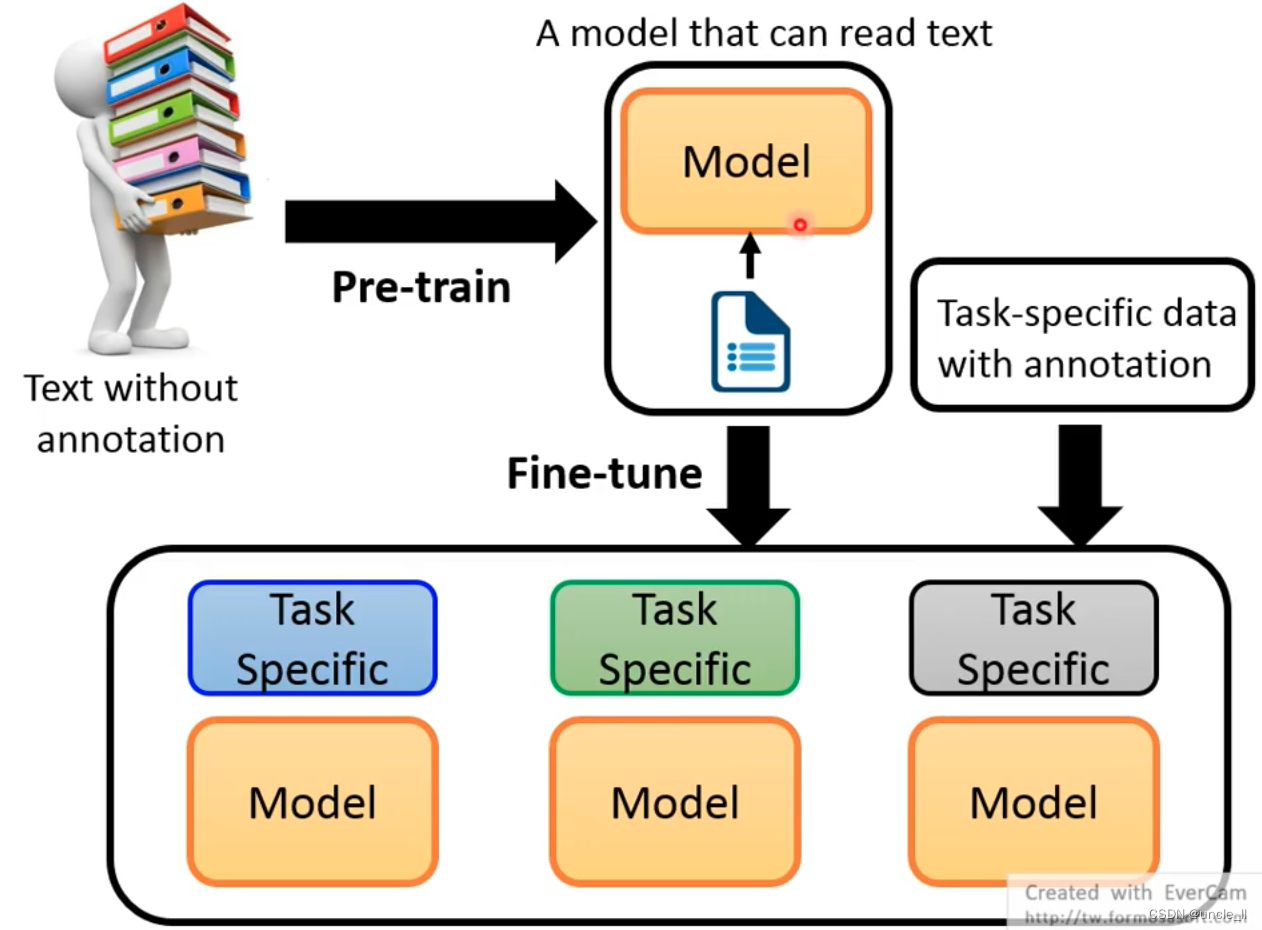
先用无监督的语料去训练通用模型,然后再针对小任务进行专项训练学习。
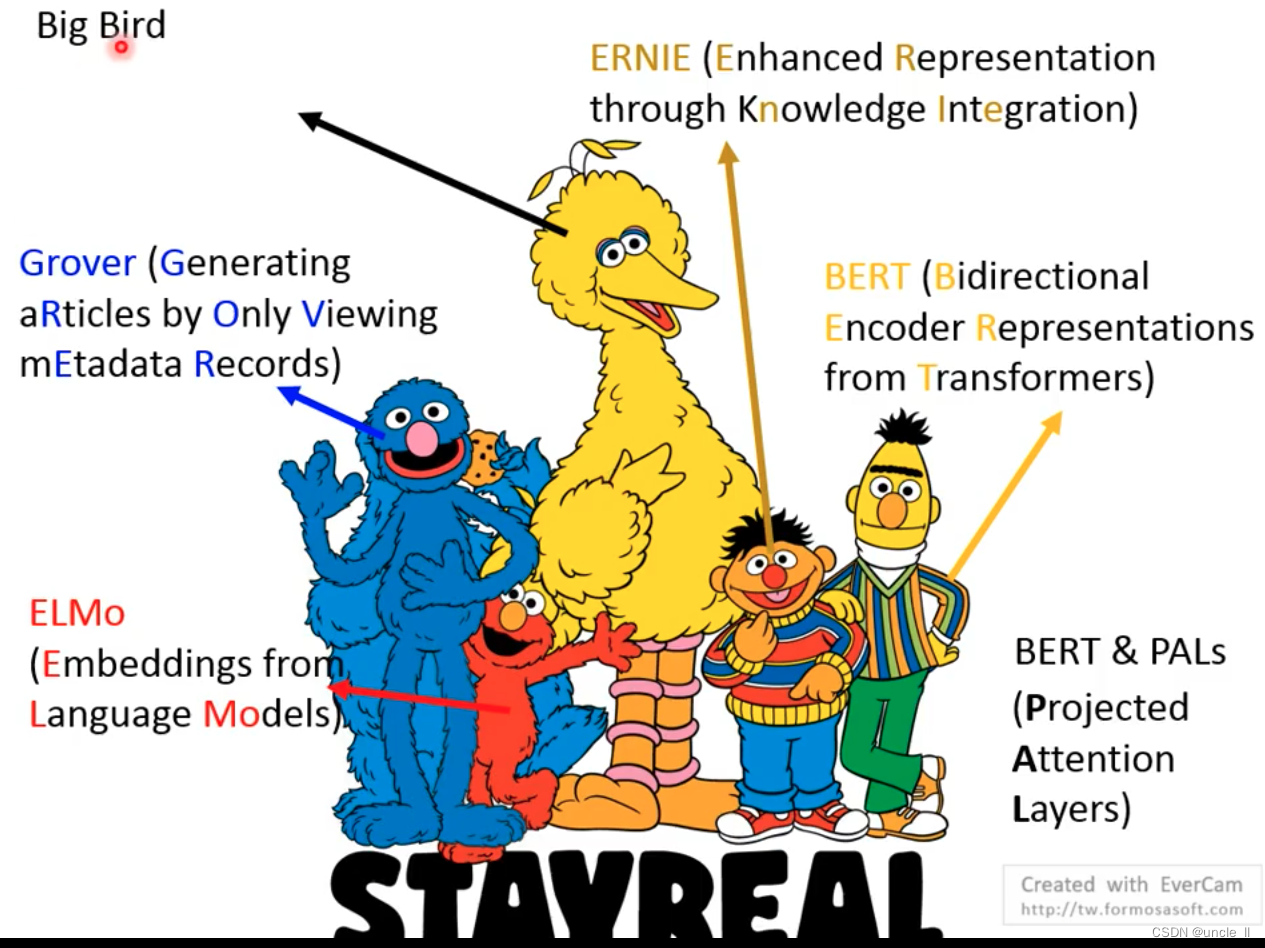
- ELMo
- Bert
- ERNIE
- Grover
- Bert&PALS
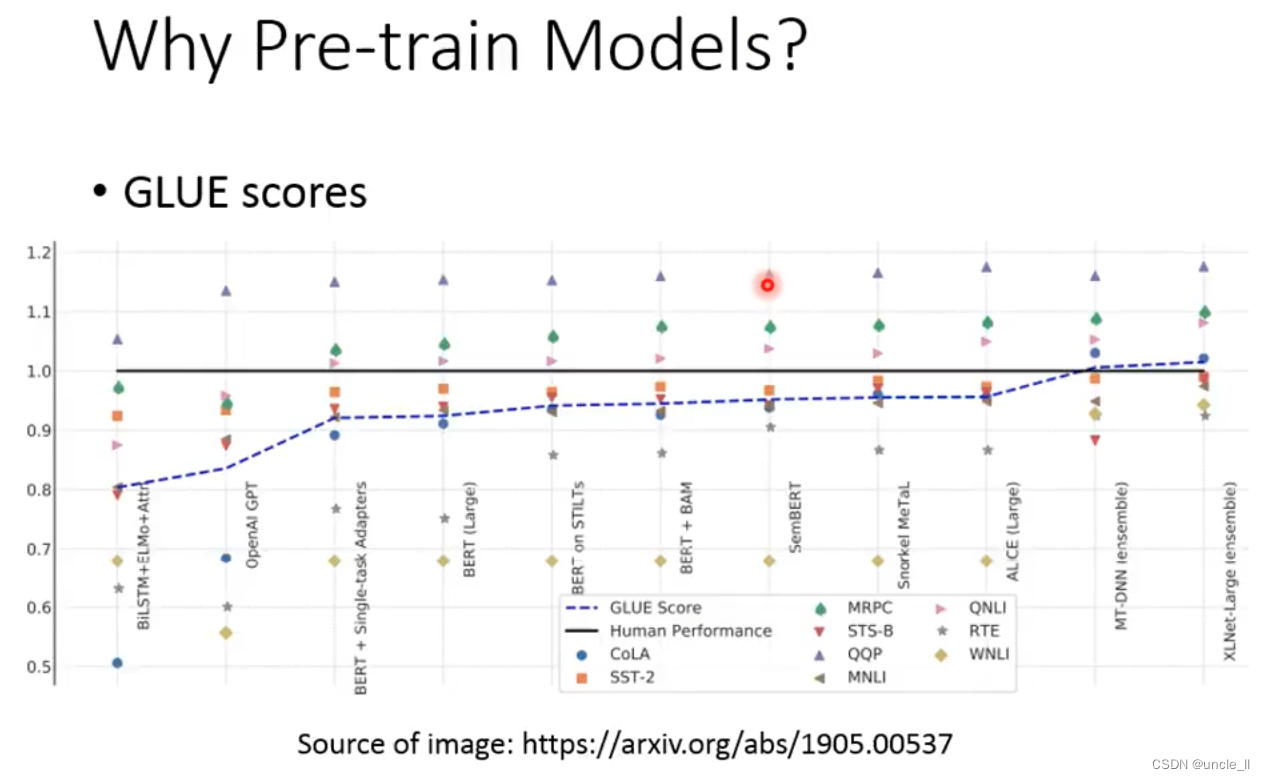
Outline
Pre-train Model

首先介绍预训练模型,预训练模型的作用是将一些token表示成一个vector
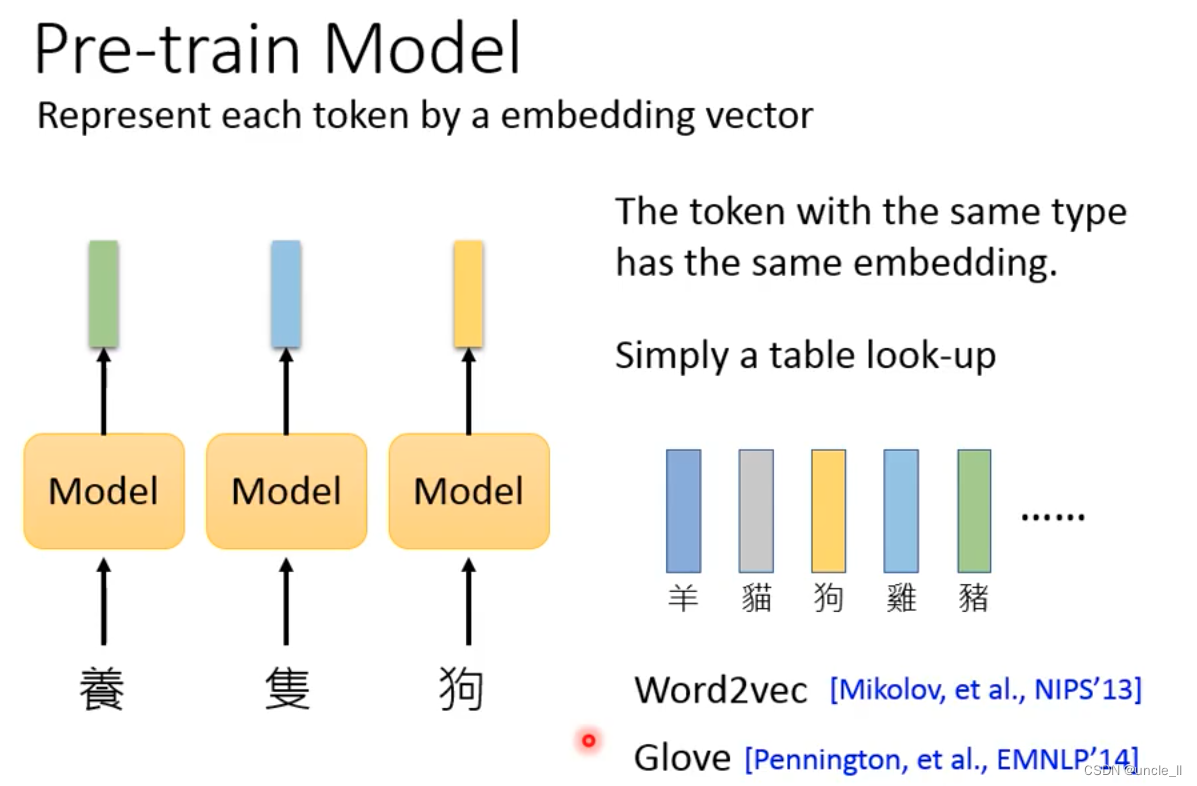
比如:
- Word2vec
- Glove
但是对于英文,有太多的英文单词,这个时候应该对单个字符进行编码:
- FastText
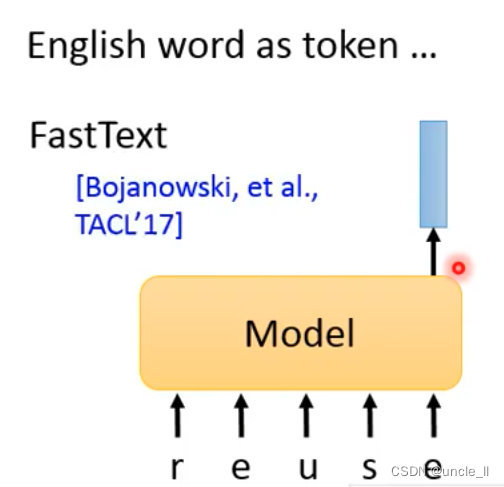
对于中文,可以对部首偏旁,或者把中文字当做图片送人网络中得到输出:
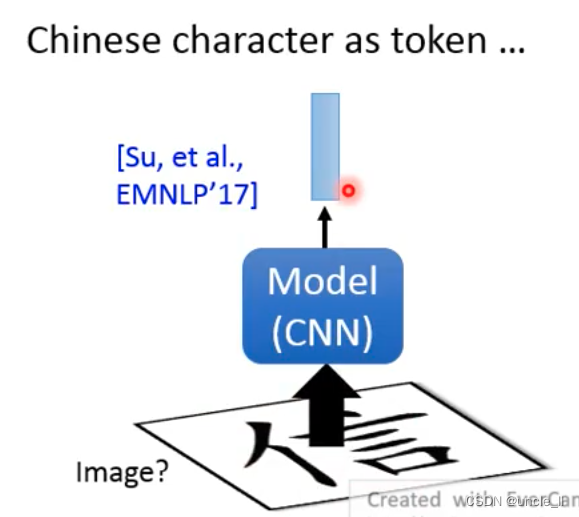
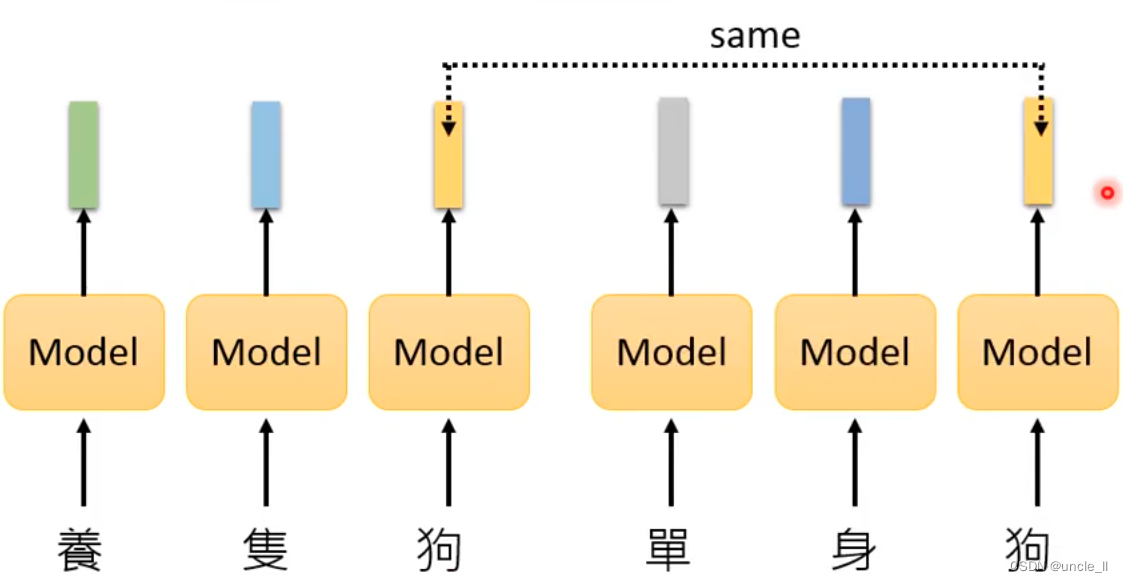
上述方法的问题不会考虑每个句子意思中相同字会有不同的意思,产生相同的token:
contextualized word embedding
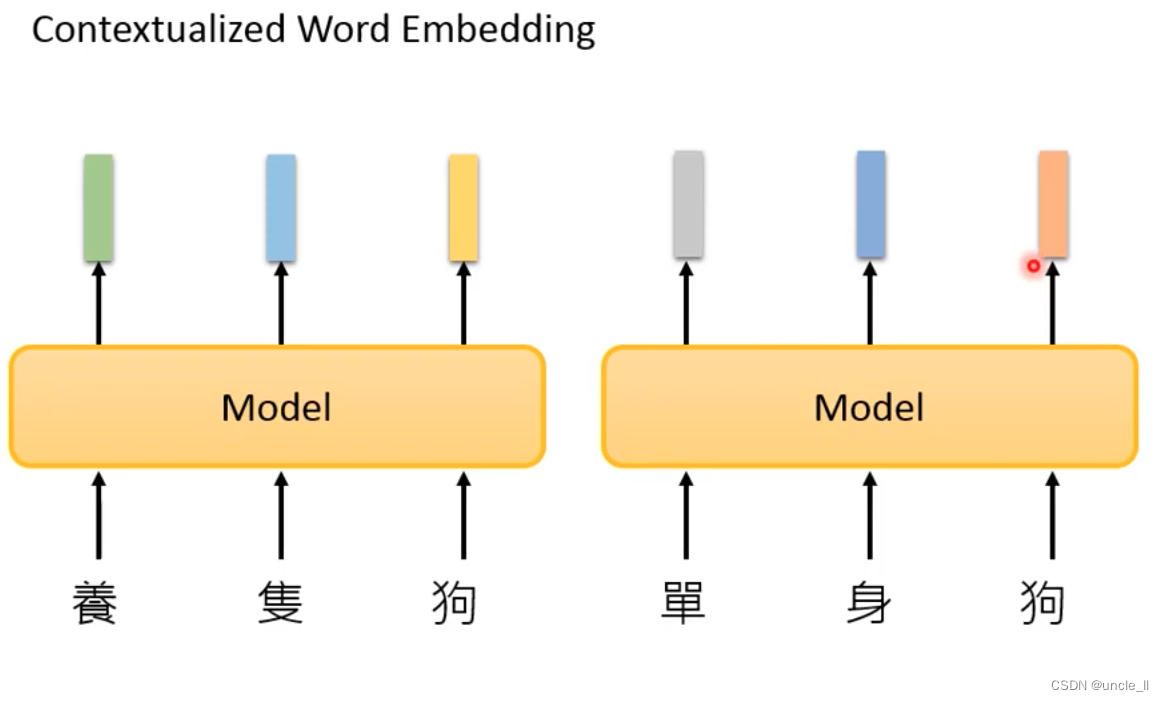
类似于sequence2sequence模型的encoder一样。
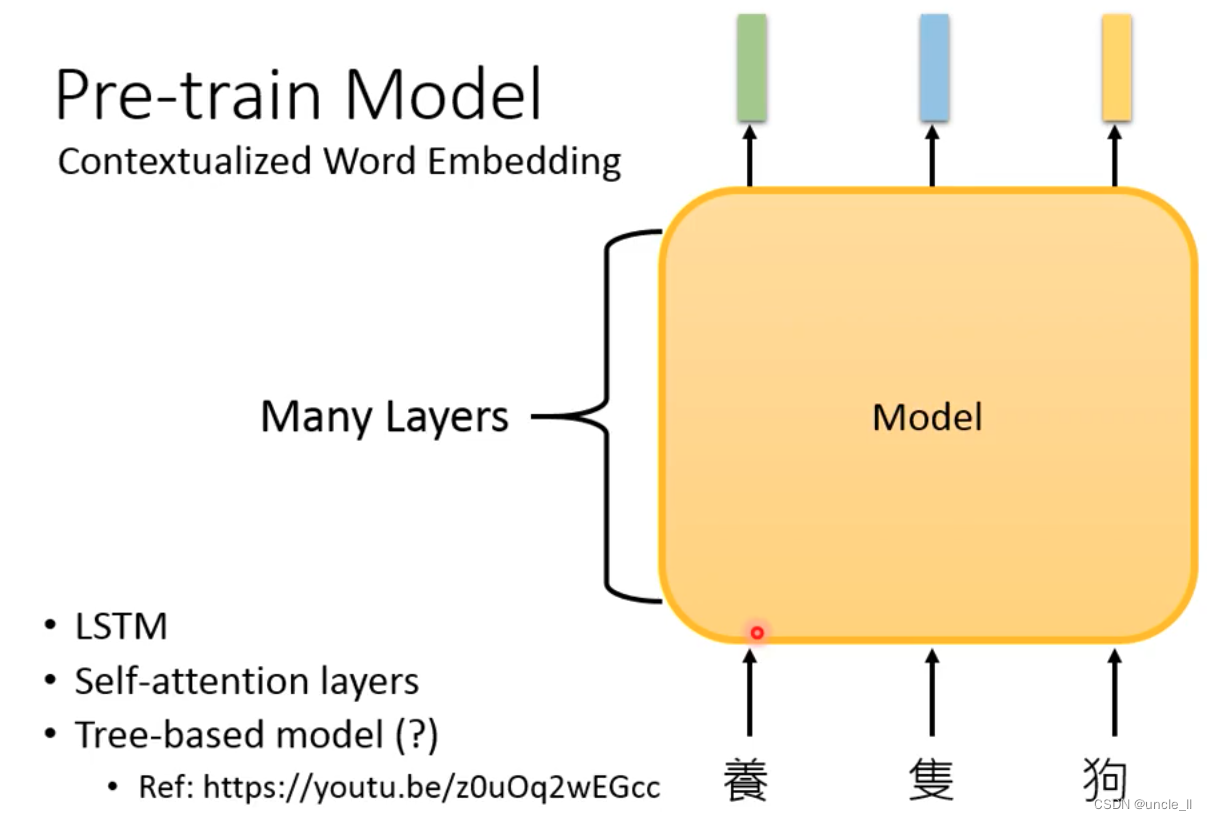
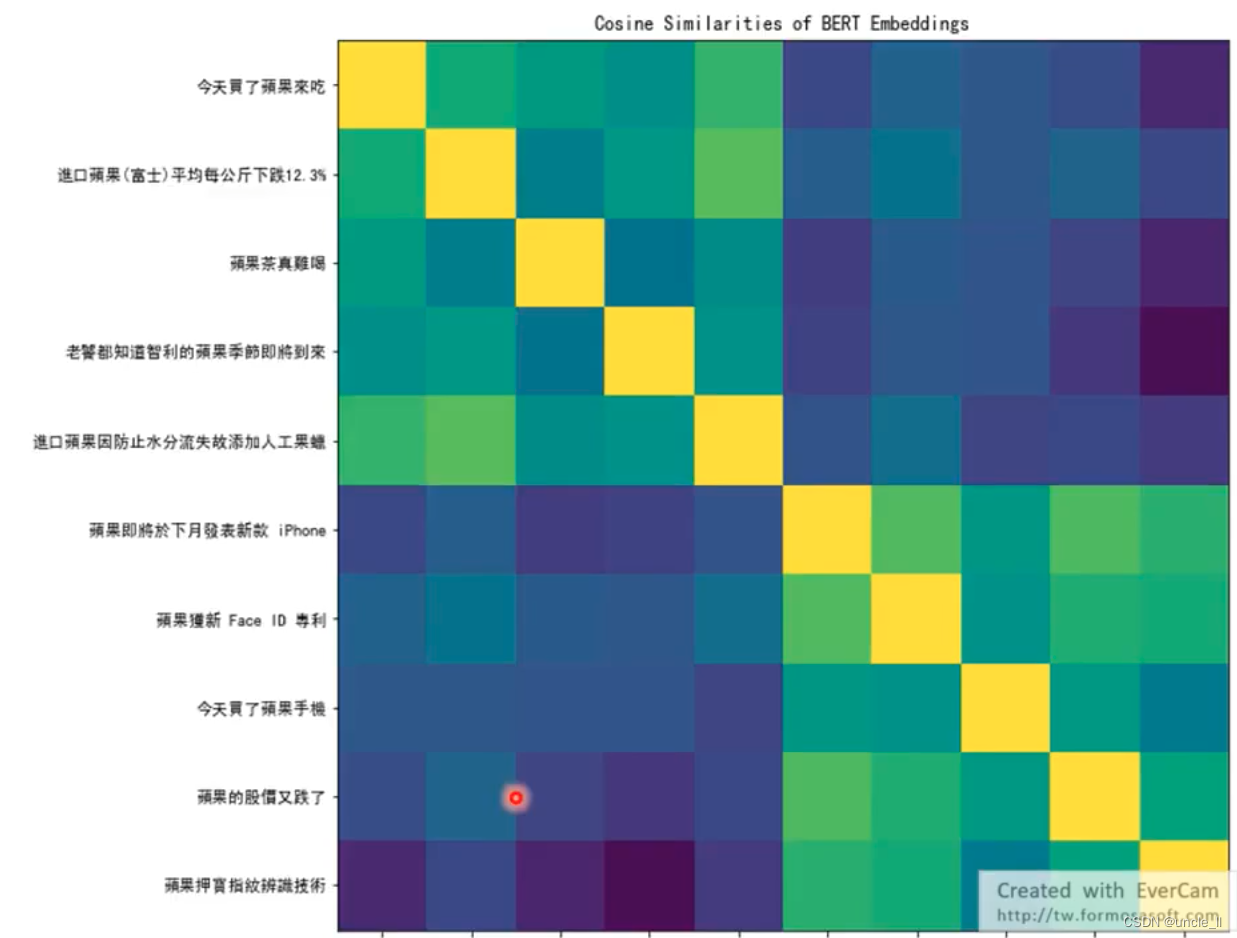
同样的token,给出不一样的embedding,上述句子都有苹果两字。
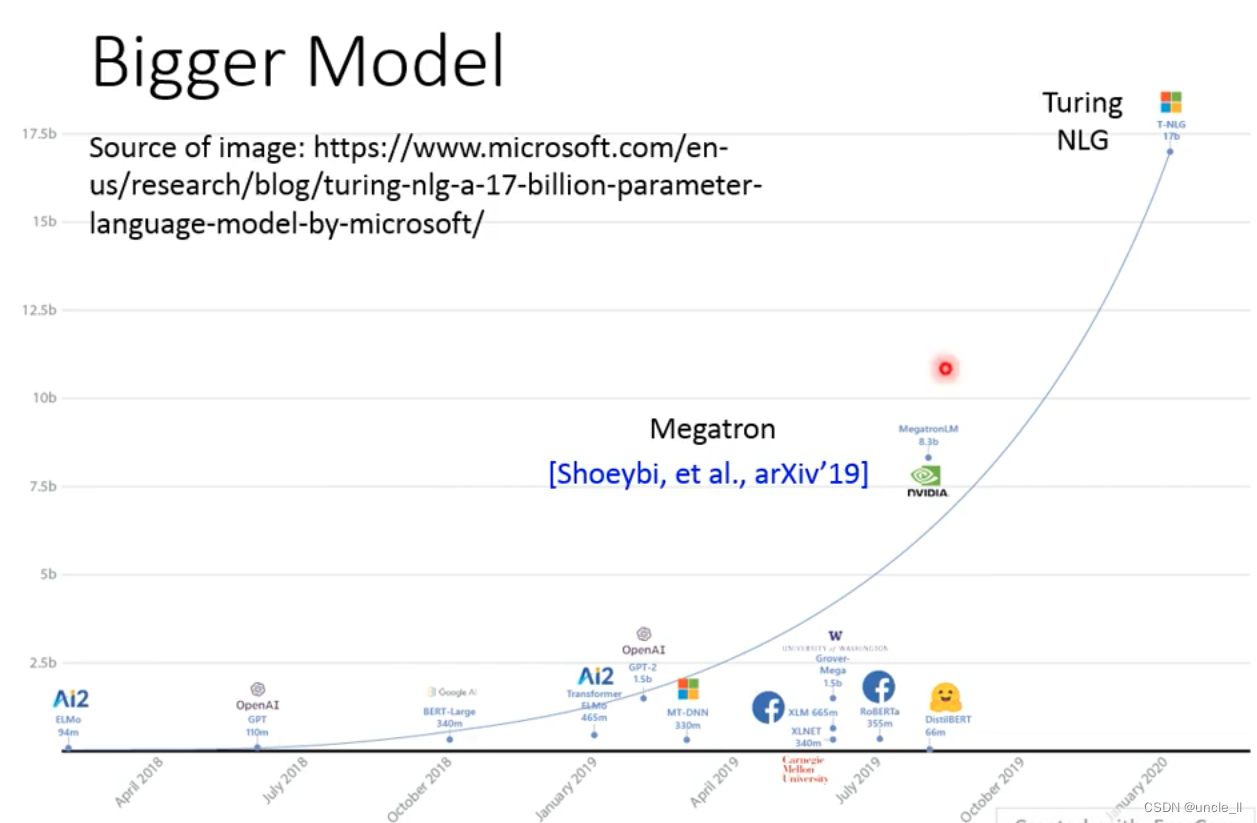
- Bigger Model
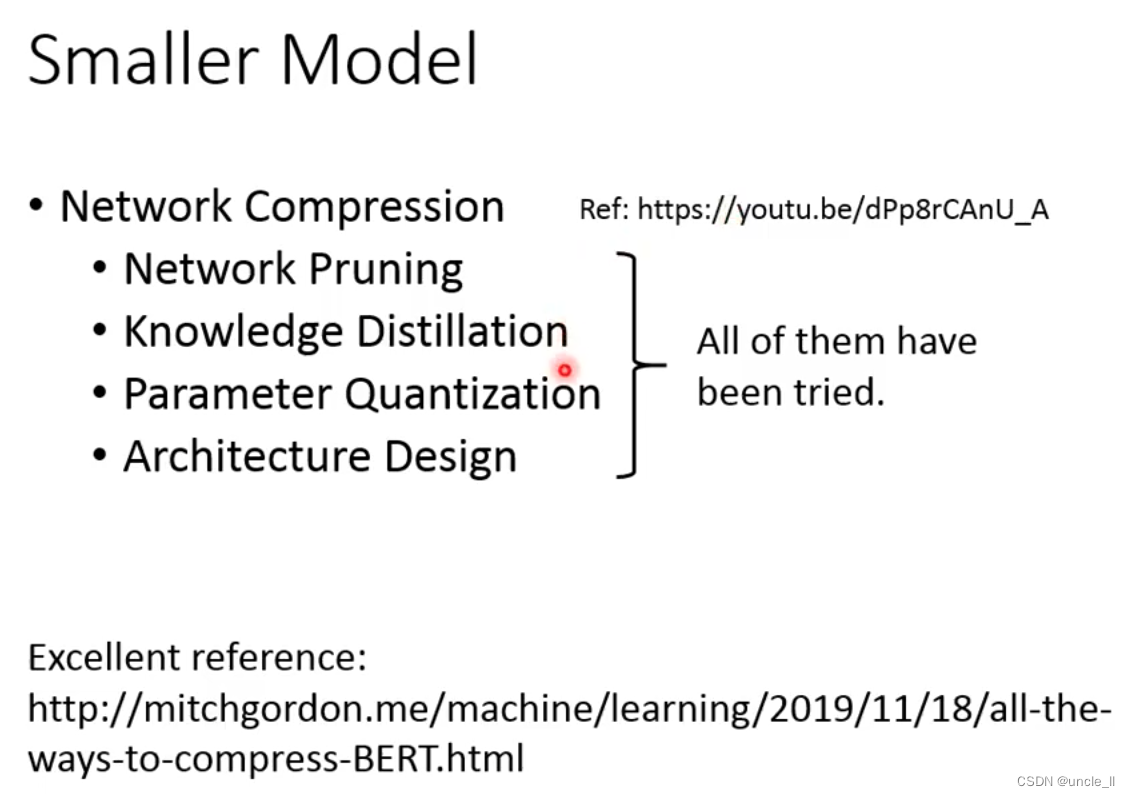
- Smaller Model

重点关注ALBERT,将模型变小的技术:
网络架构设计:
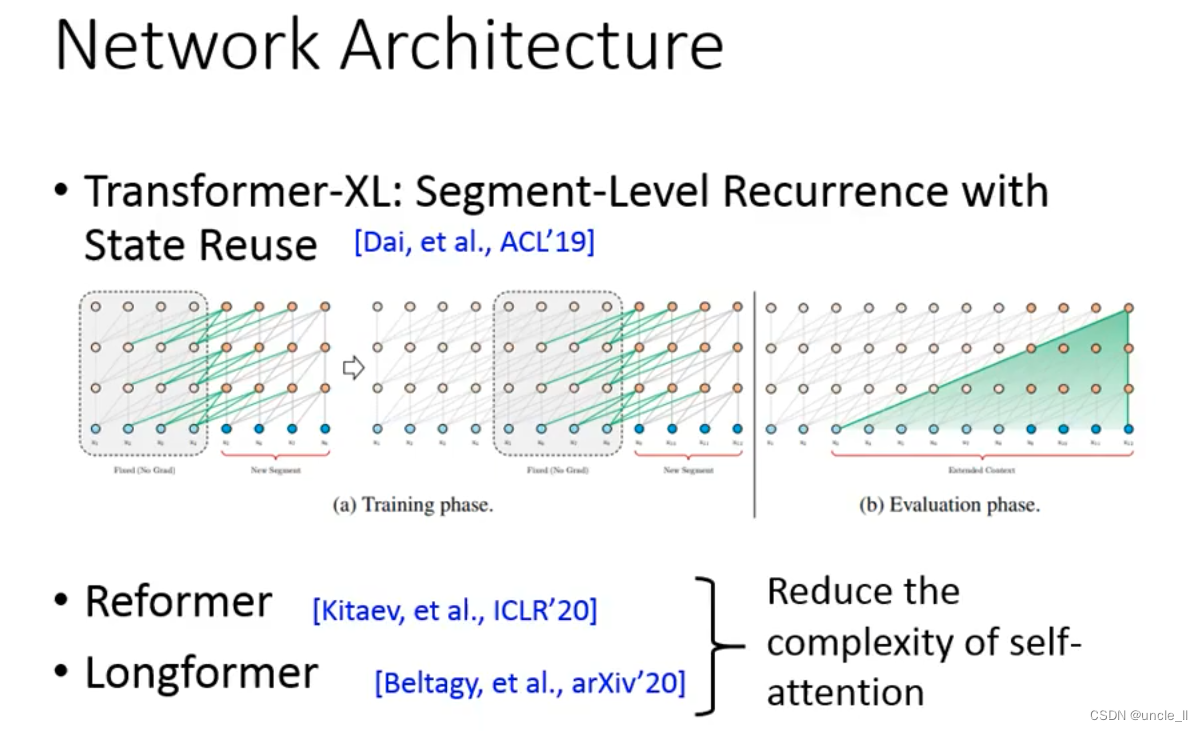
让模型能读很长的内容,不仅是一篇文章,有可能是一本书。 - Transformer-XL
- Reformer
- Longformer
self-attention的计算复杂度是 O ( n 2 ) O(n^2) O(n2)
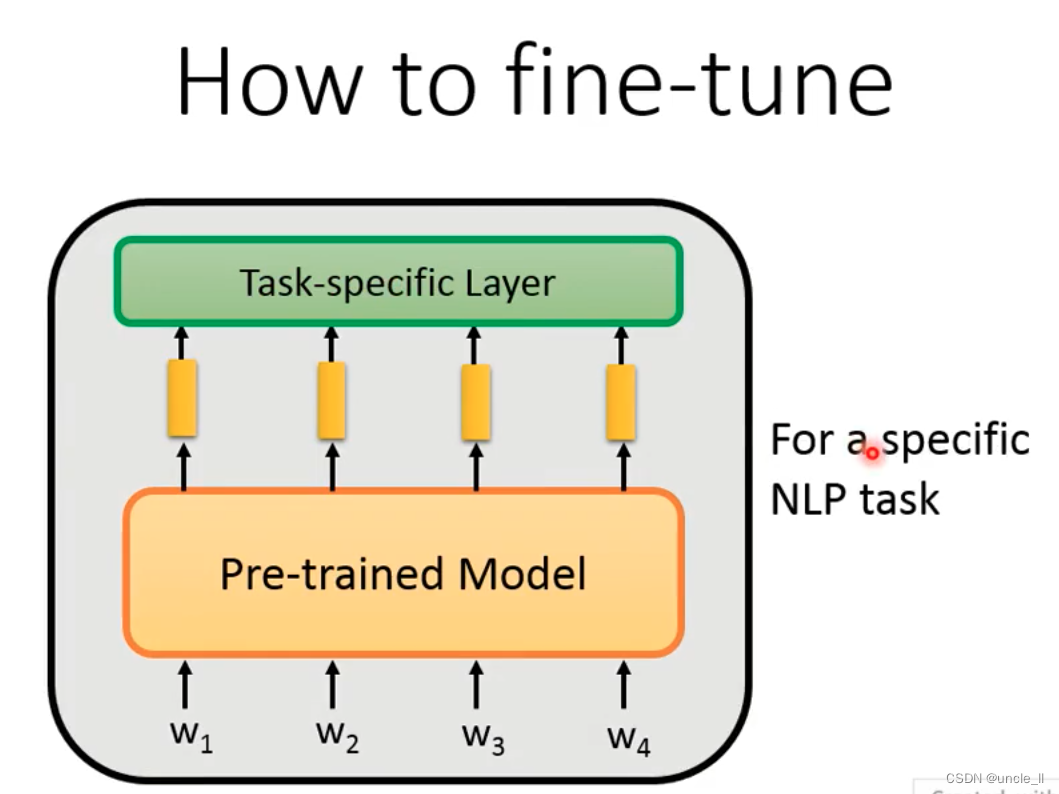
How to fine-tune
如何进行预训练
- 输入:
一个句子还是两个句子,[sep]进行分割。
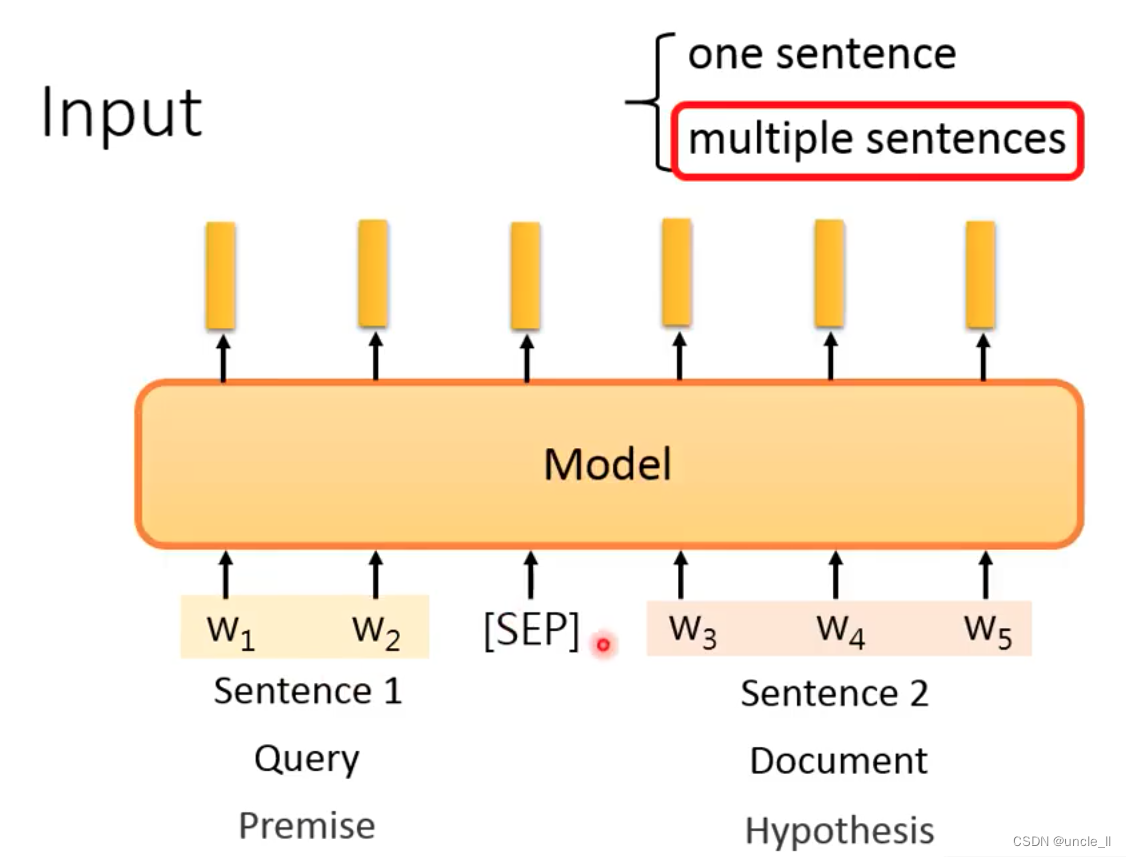
- 输出部分:
输出一个class,加入一个[cls],产生跟整个句子有关的embedding
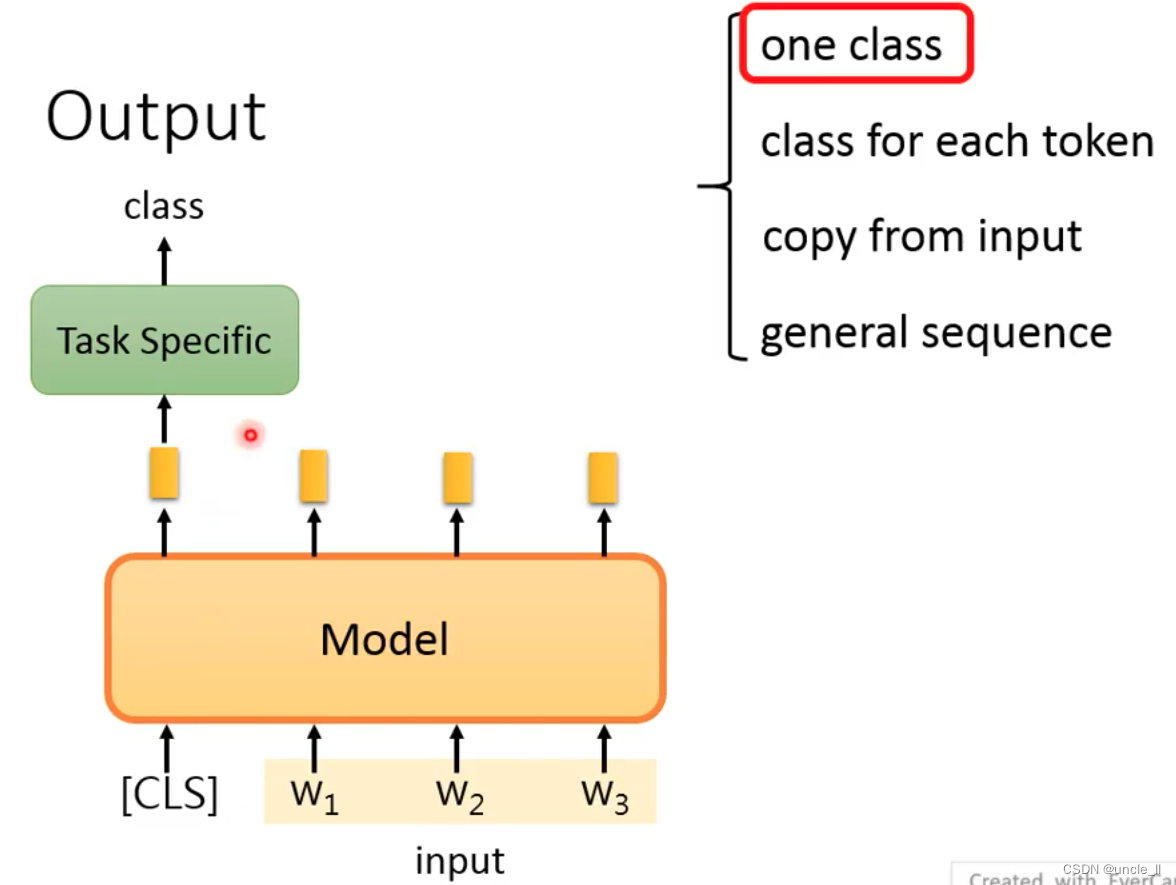
如果没有cls,就是把所有的embedding合起来送入模型,得到一个输出。
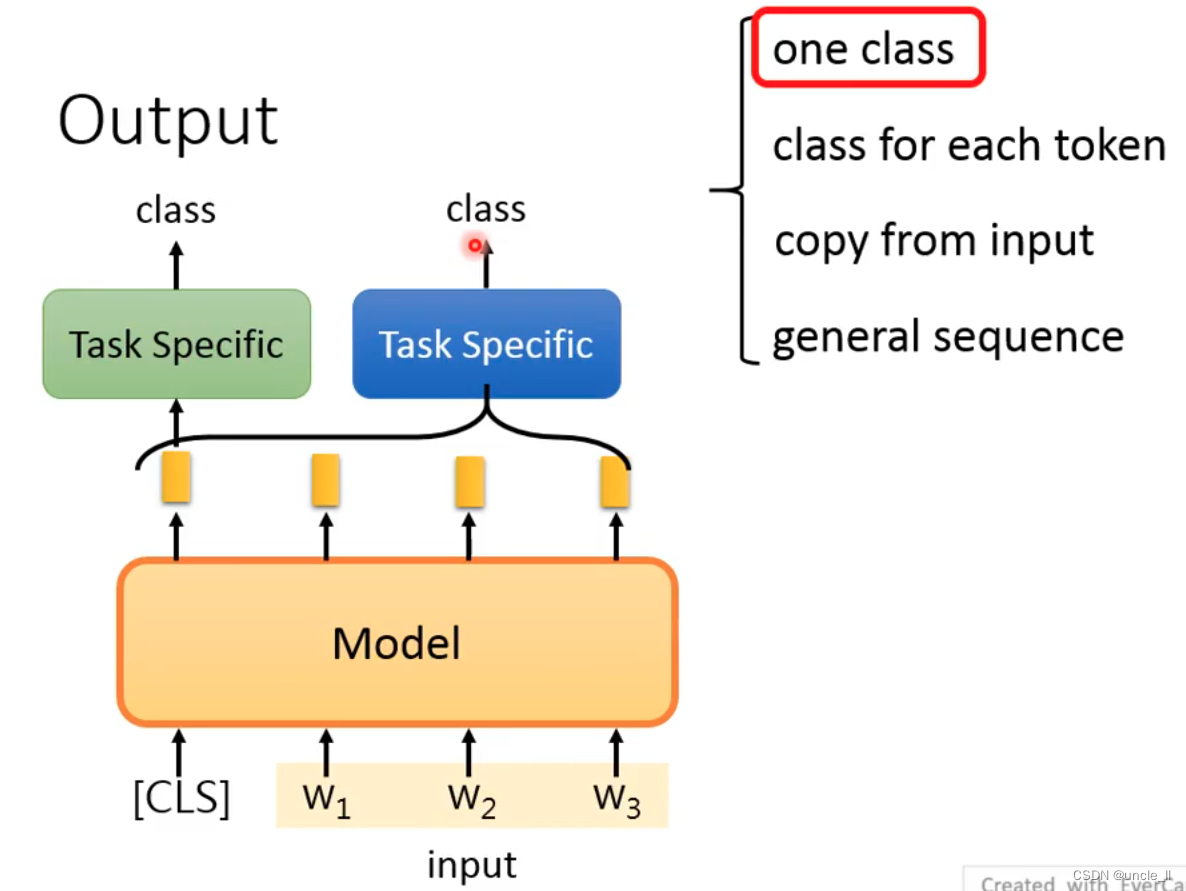
第二种就是给每个token一个class,相当于每个embedding一个class
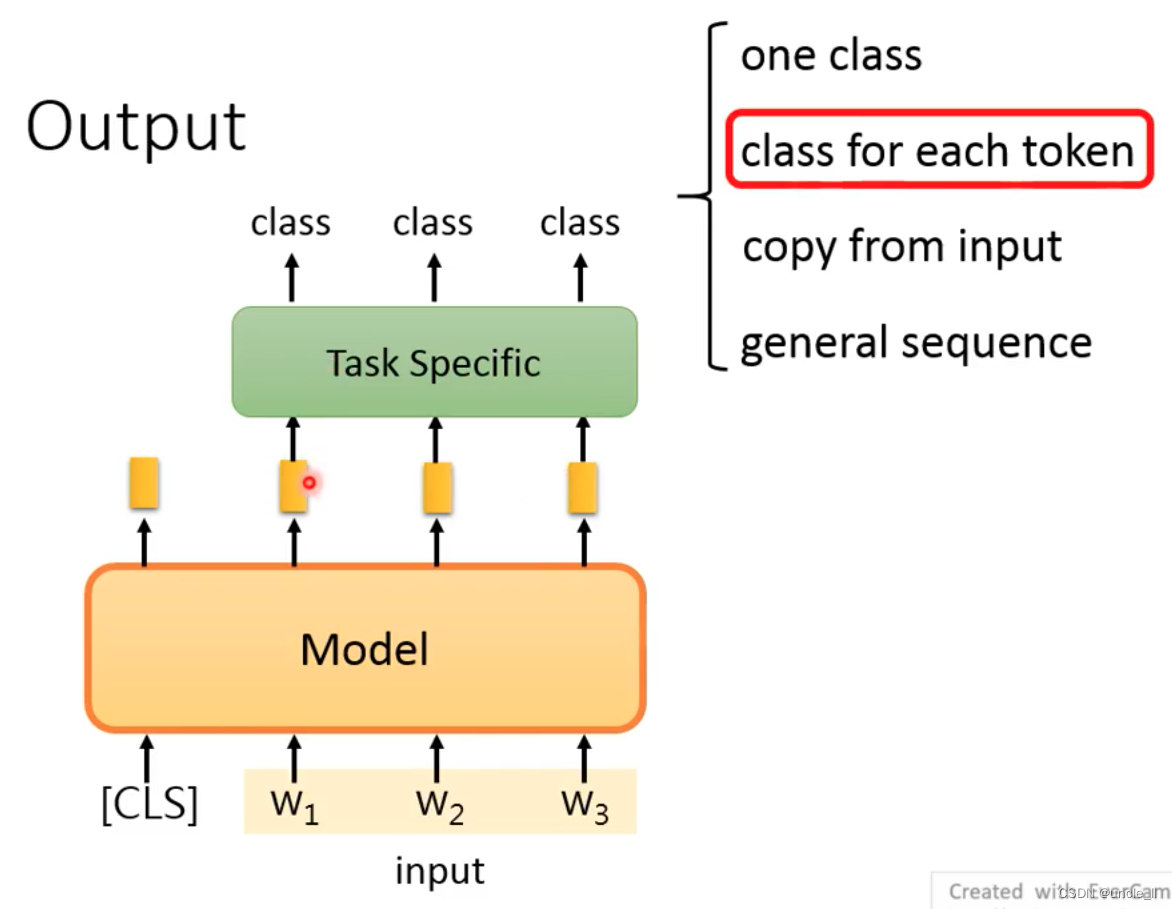
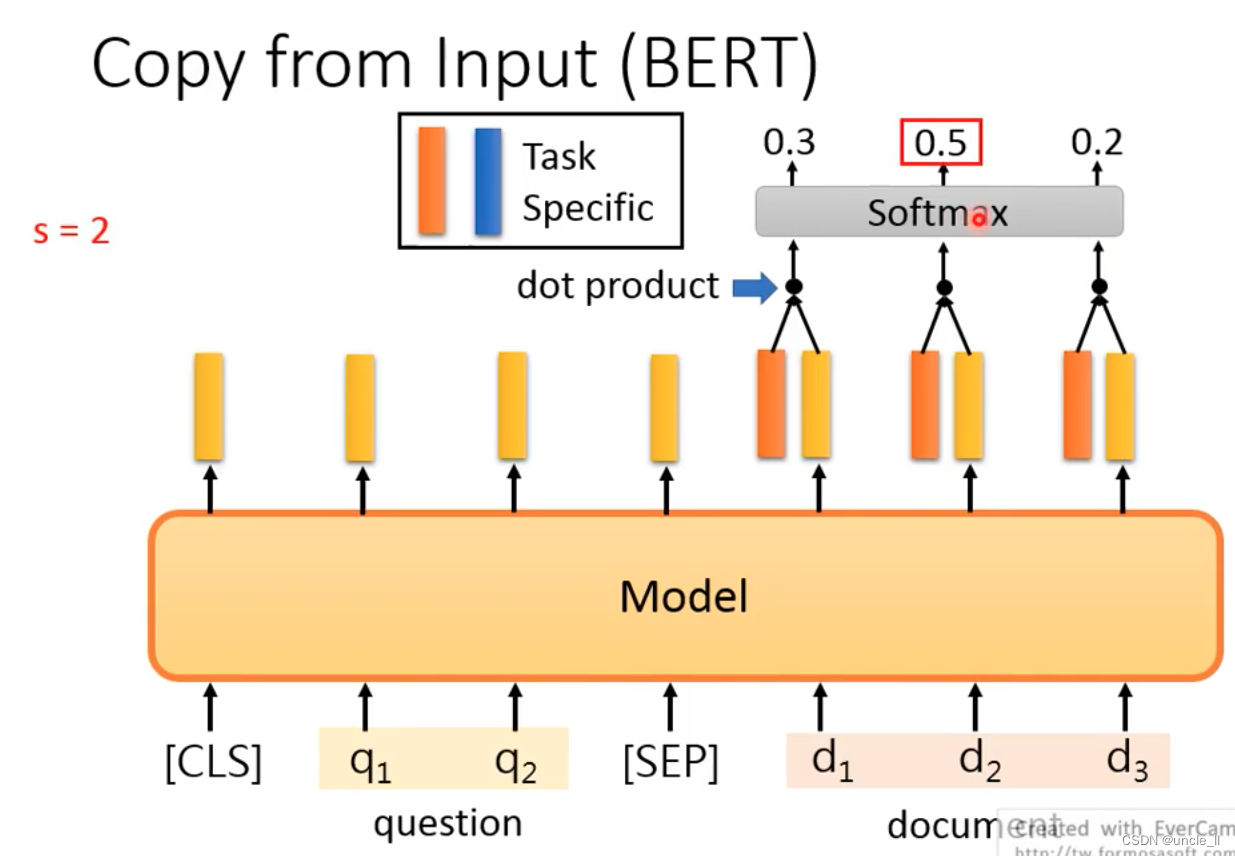
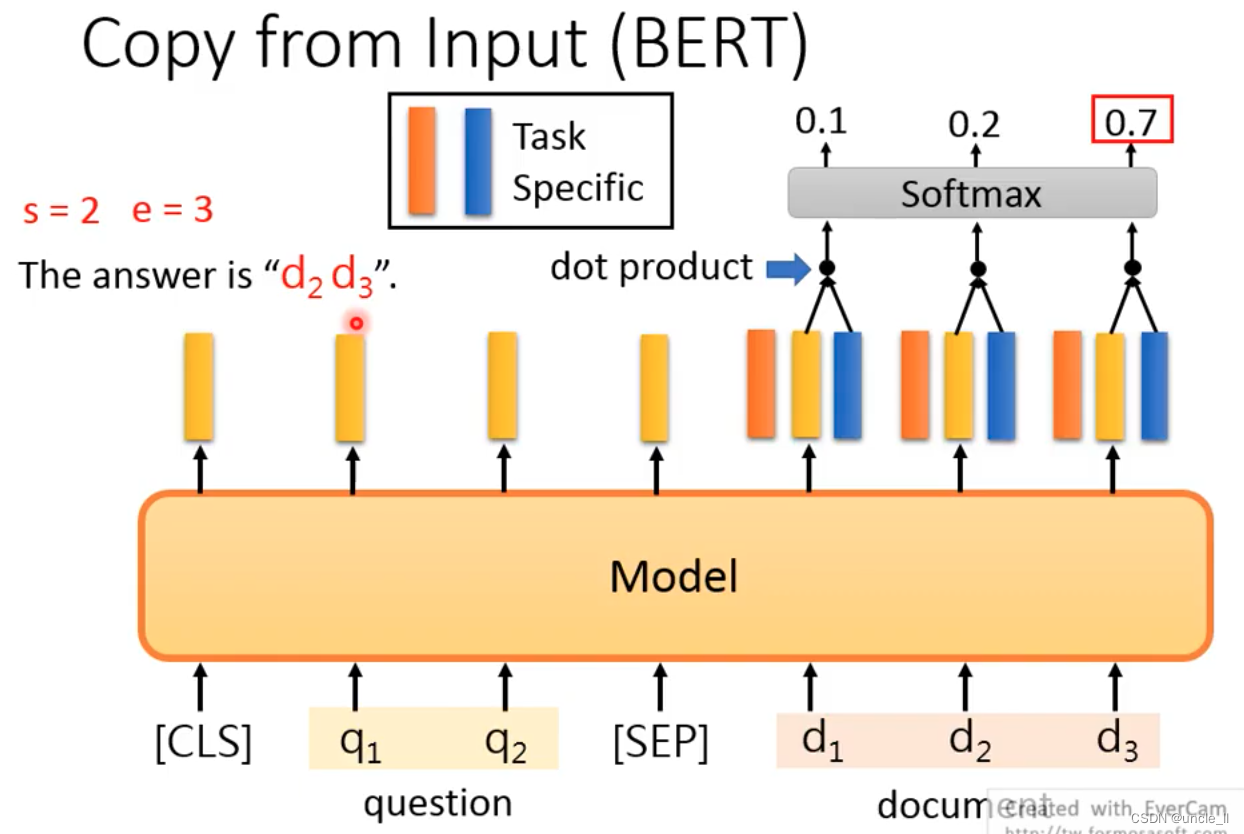
Extraction-based QA

General Sequence
如何用在生成文本呢?
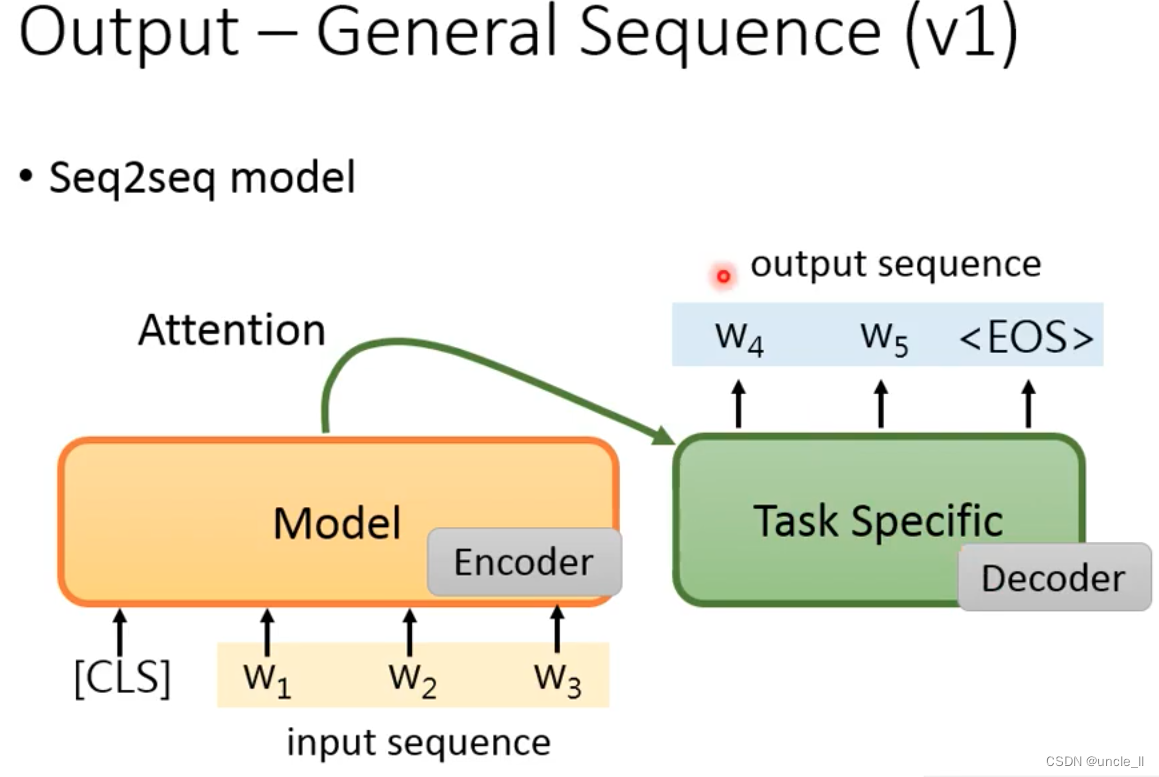
上述结构encoder得不到好的使用
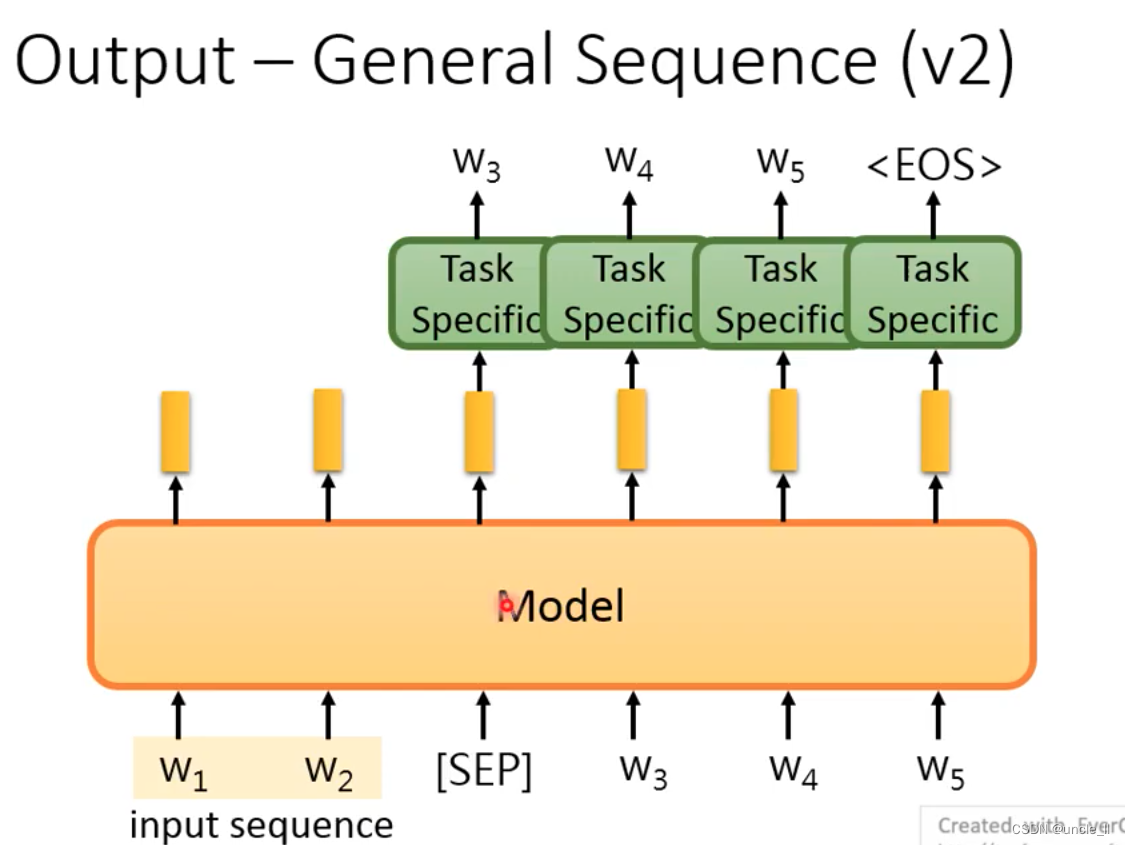
将预训练模型当做encoder使用,每次产生一个word后,送入模型继续生成,直到产生eos结束符。
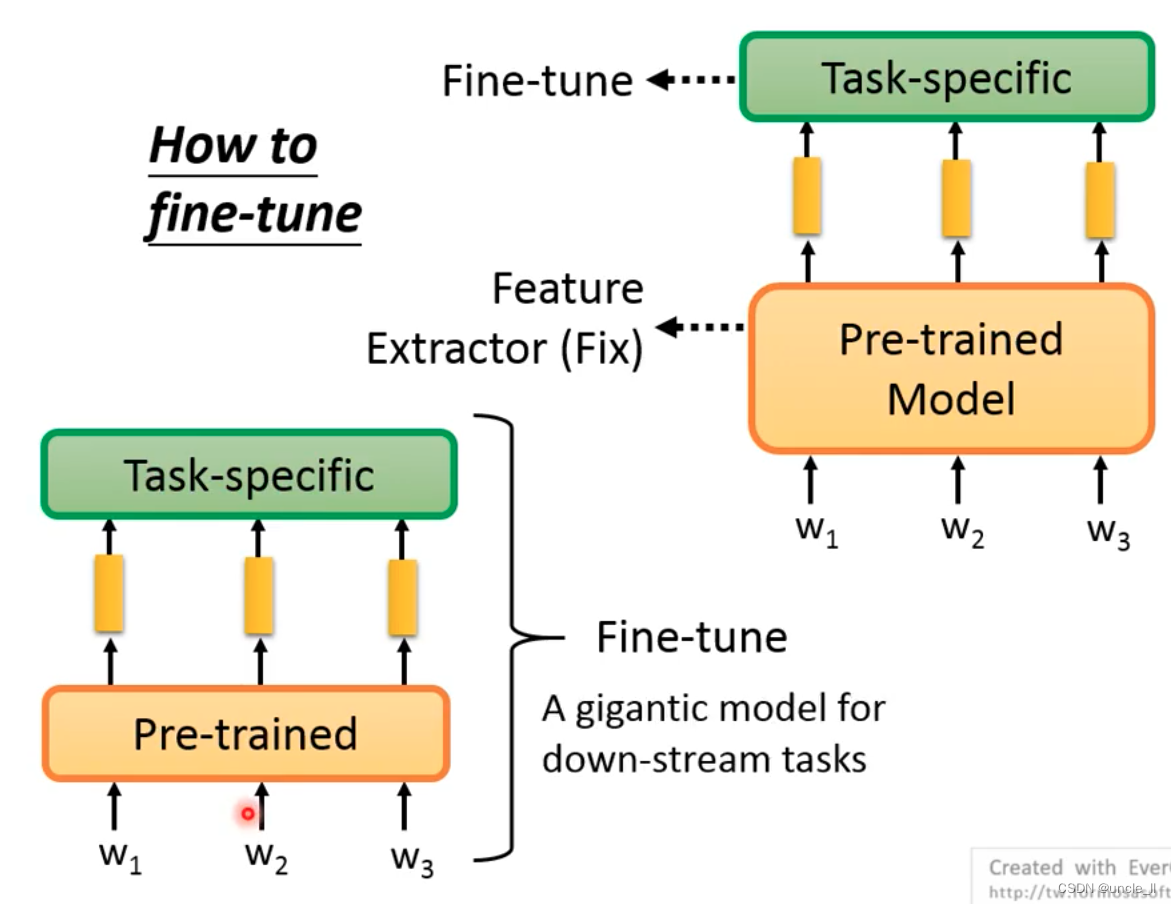
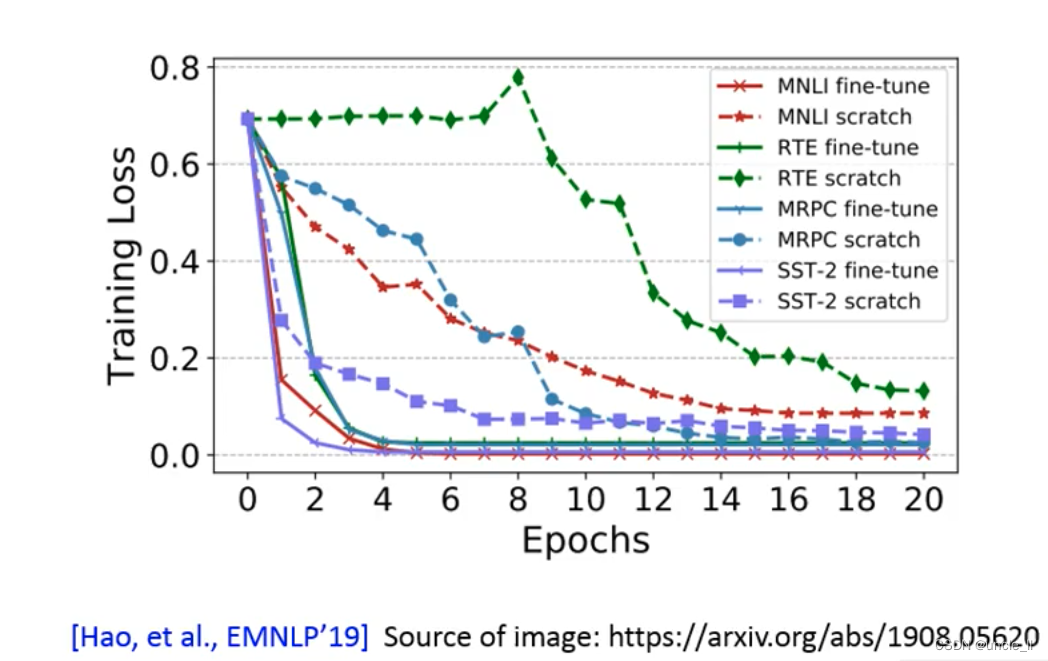
微调有两种方法:
- 第一种:预训练模型不动,对其产生的embedding 针对具体任务进行训练,只对上层模型微调;
- 第二种:预训练模型和具体任务模型联合到一起训练,消耗会大一些;
第二种方法会比对第一种方法获得的效果要更好一点,但是训练整个模型会遇到的一些问题:
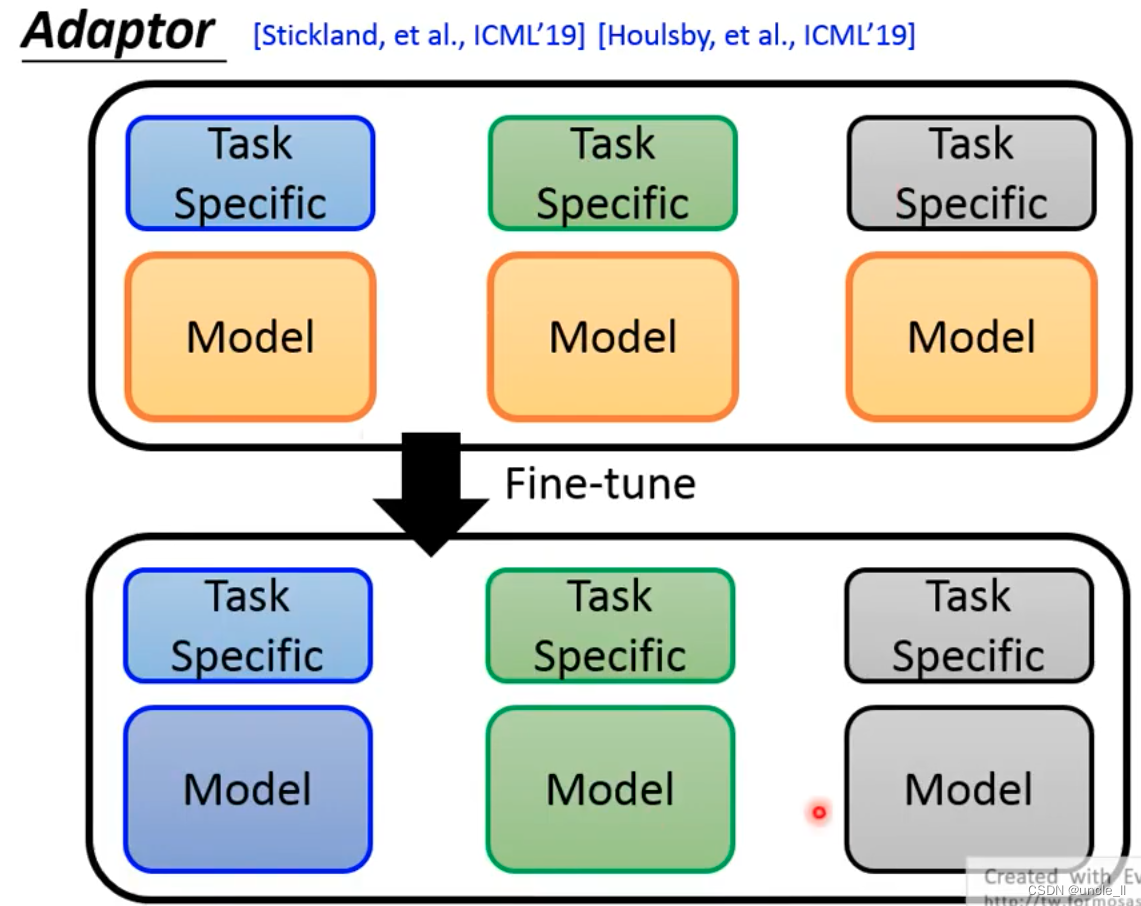
- 训练完了之后预训练模型也发生了改变,相当于每个任务都会有一个不同的预训练模型,每个模型都比较大,这样非常的浪费。
针对上述问题,解决方法:
- Adapter:只训练少量的参数结构APT

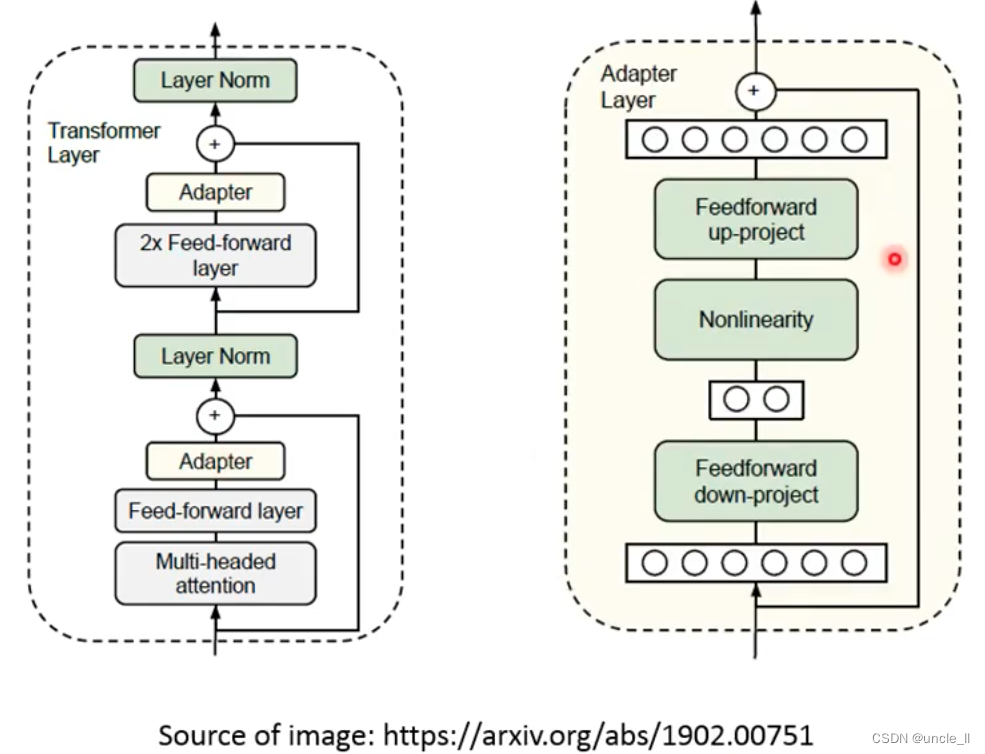
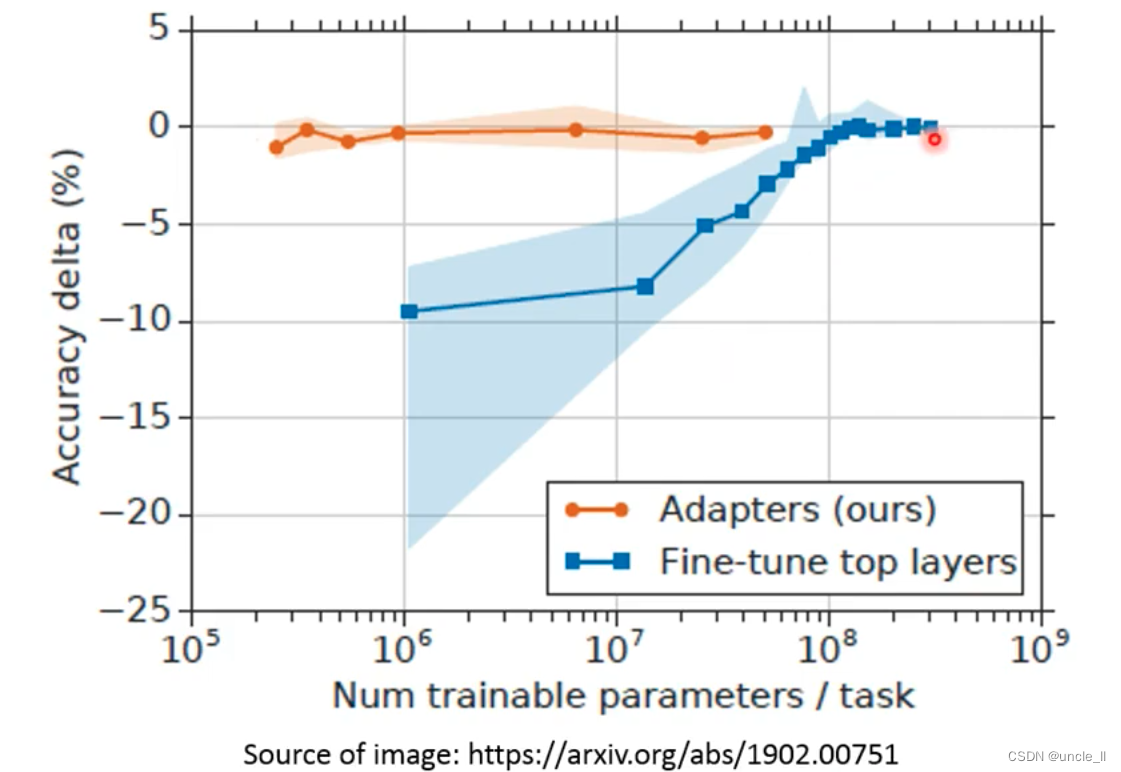
fine-tune的时候只会调APT结构的参数,但是是插入到transformer结构中,加深了网络:
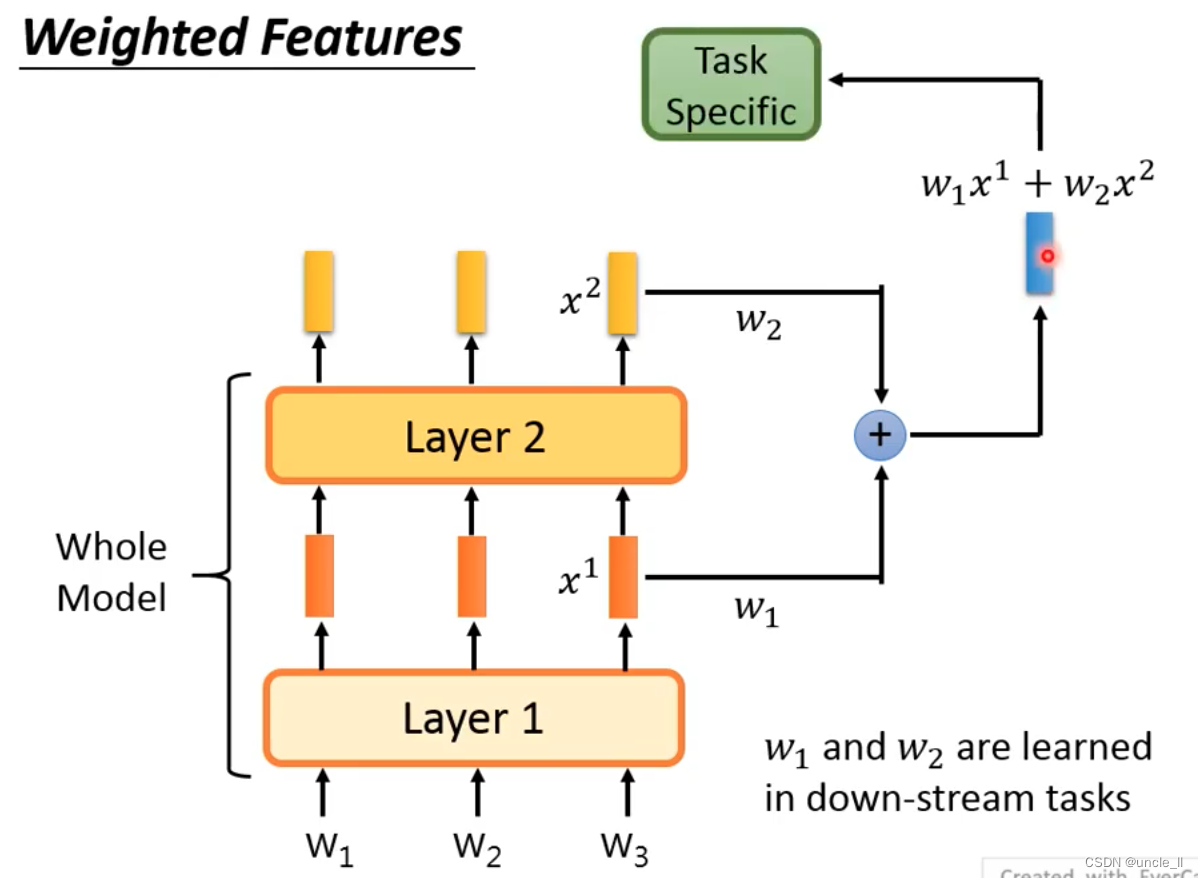
- Weighted Features
综合每一层的embedding,送到具体的任务中学习,权重参数可以学出来。
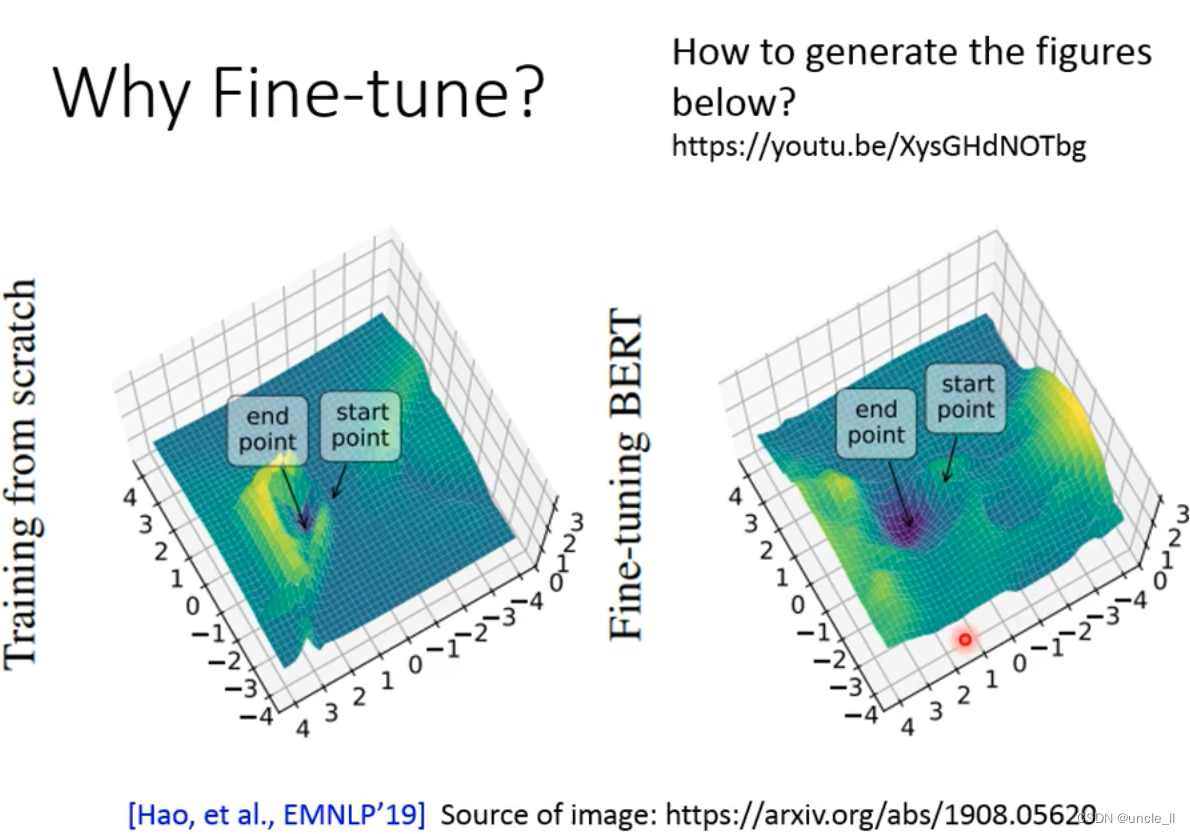
模型的loss,泛化能力。start-point到end-point,两点间距离越宽,凹的越浅说明泛化能力越一般;两点间距离越近,凹得越深说明泛化能力越好。
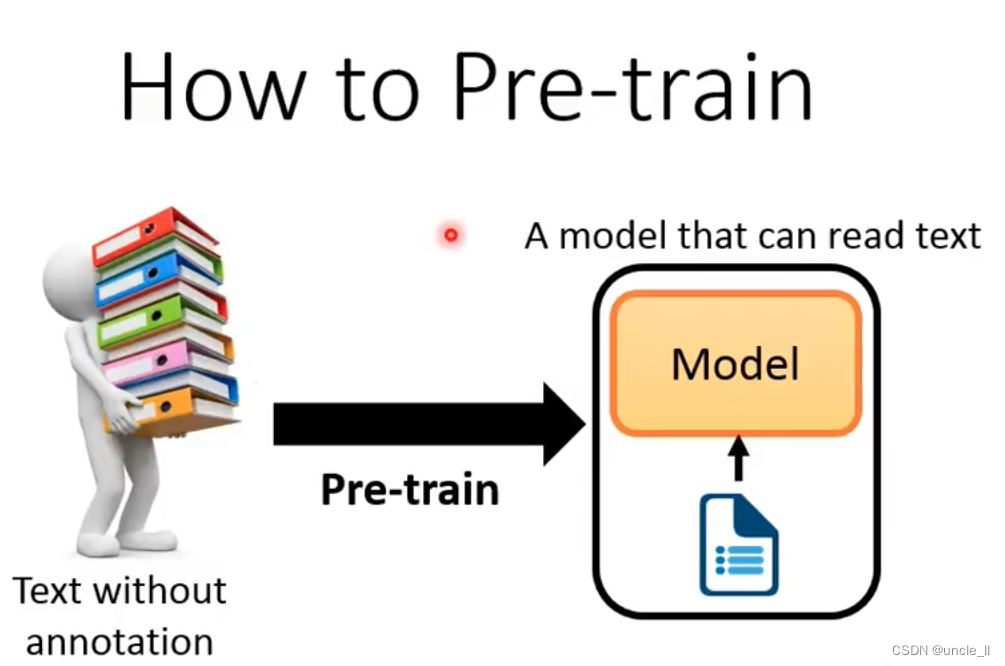
How to pre-train
如何进行预训练:
翻译任务
- Context Vector(Cove)
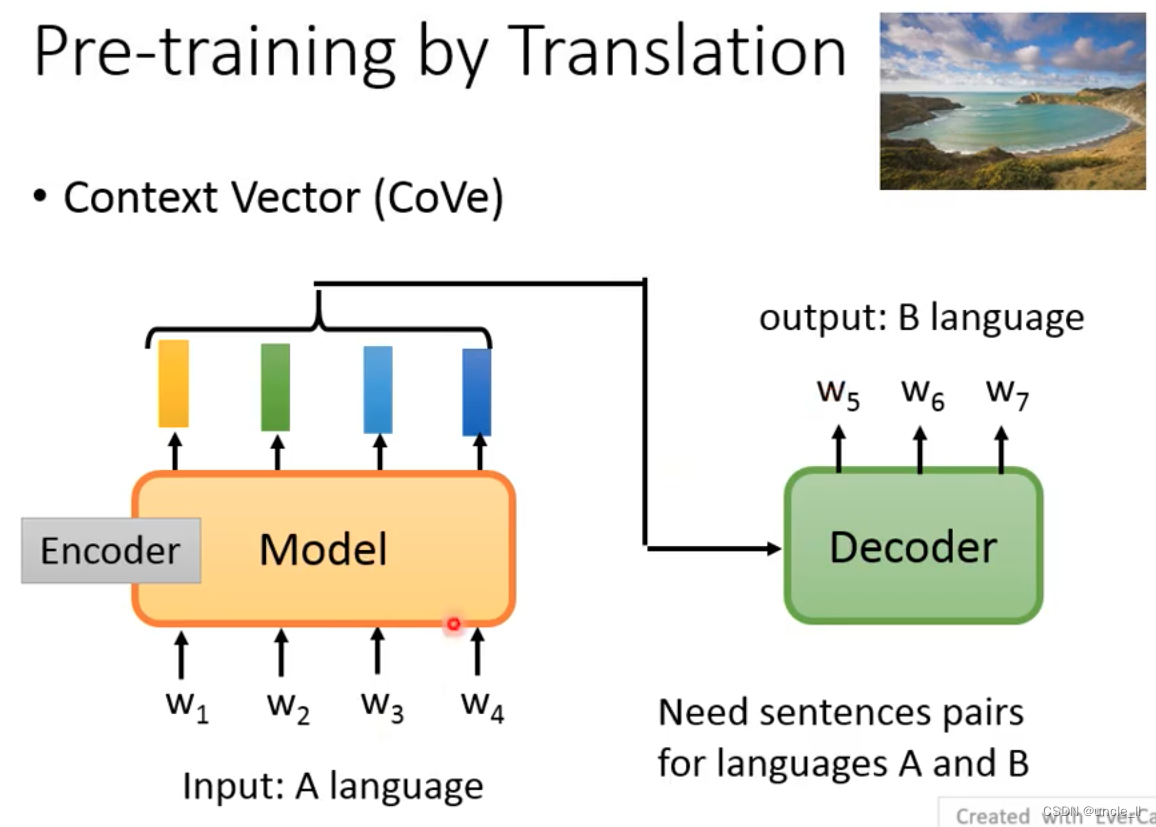
把输入的句子A送入encoder,然后decoder得到句子B,需要大量的pair对data
Self-supervised Learning
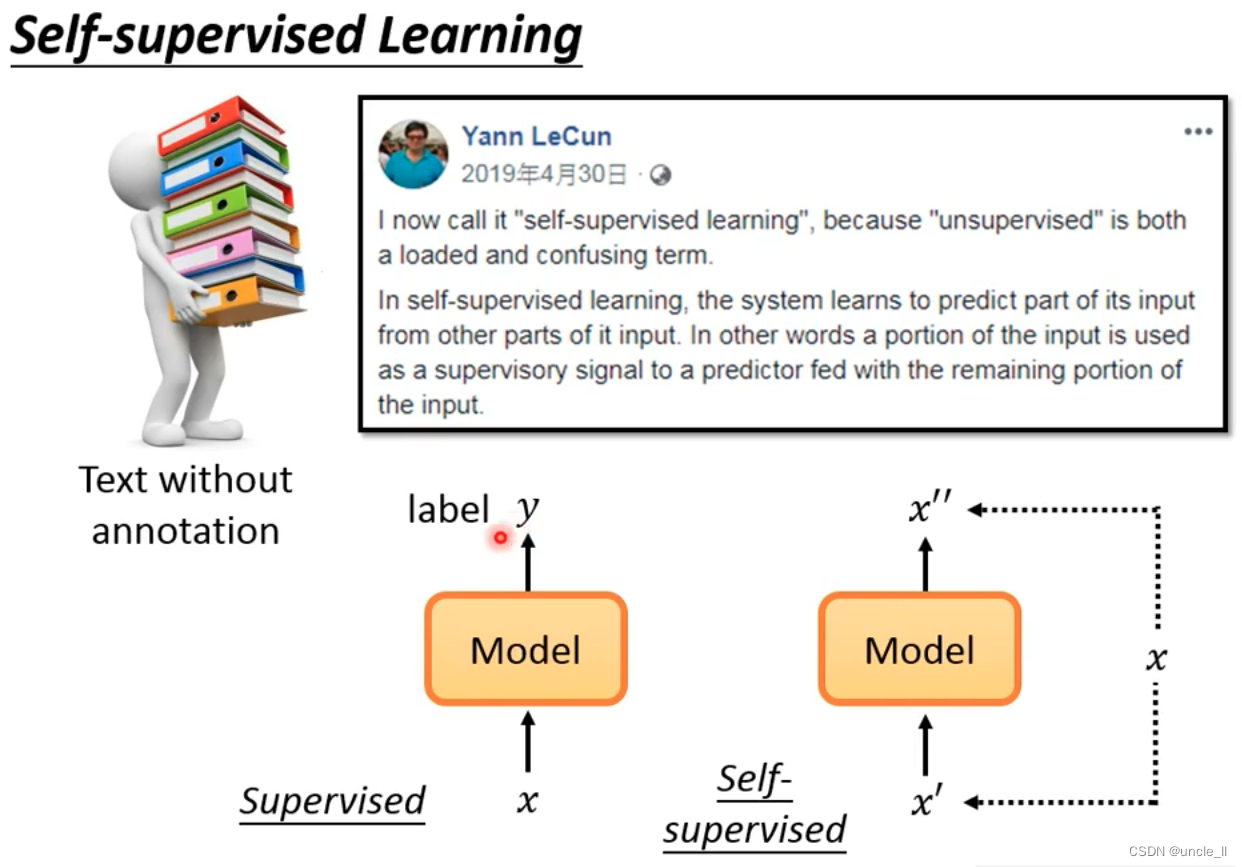
self-supervised的input和output是自己产生出来的。
Predict Next Token
给定输入,预测下一个token
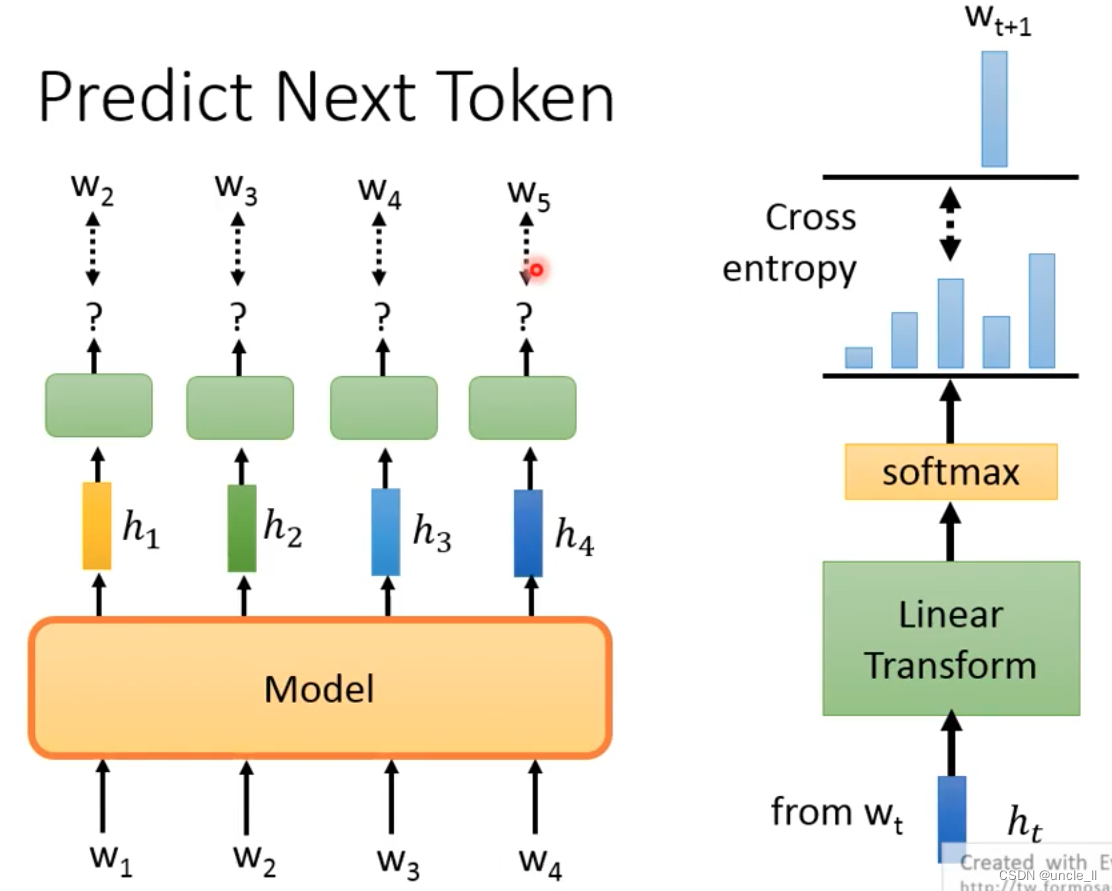
有了w1预测w2,用w1, w2预测w3, 然后用w1,w2,w3预测w4, 但是不能用右边的数据用来预测左边的数据:
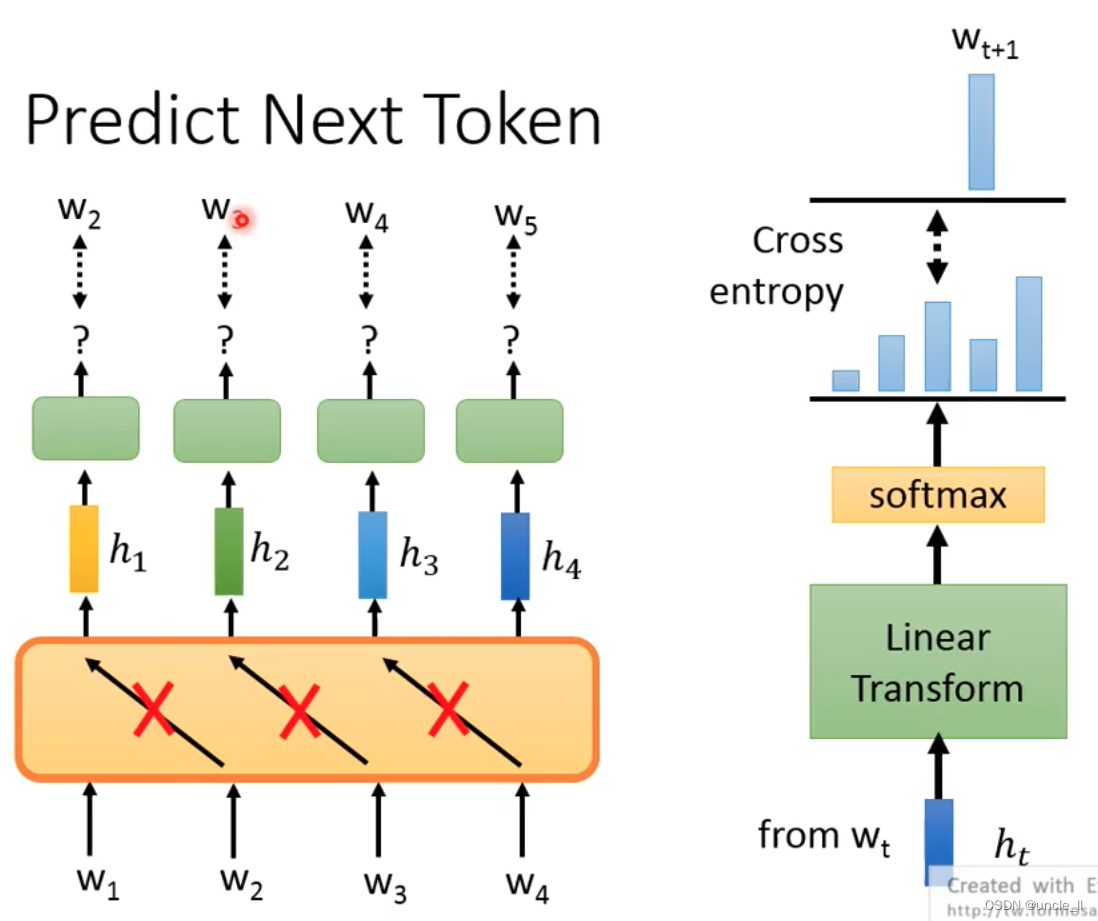
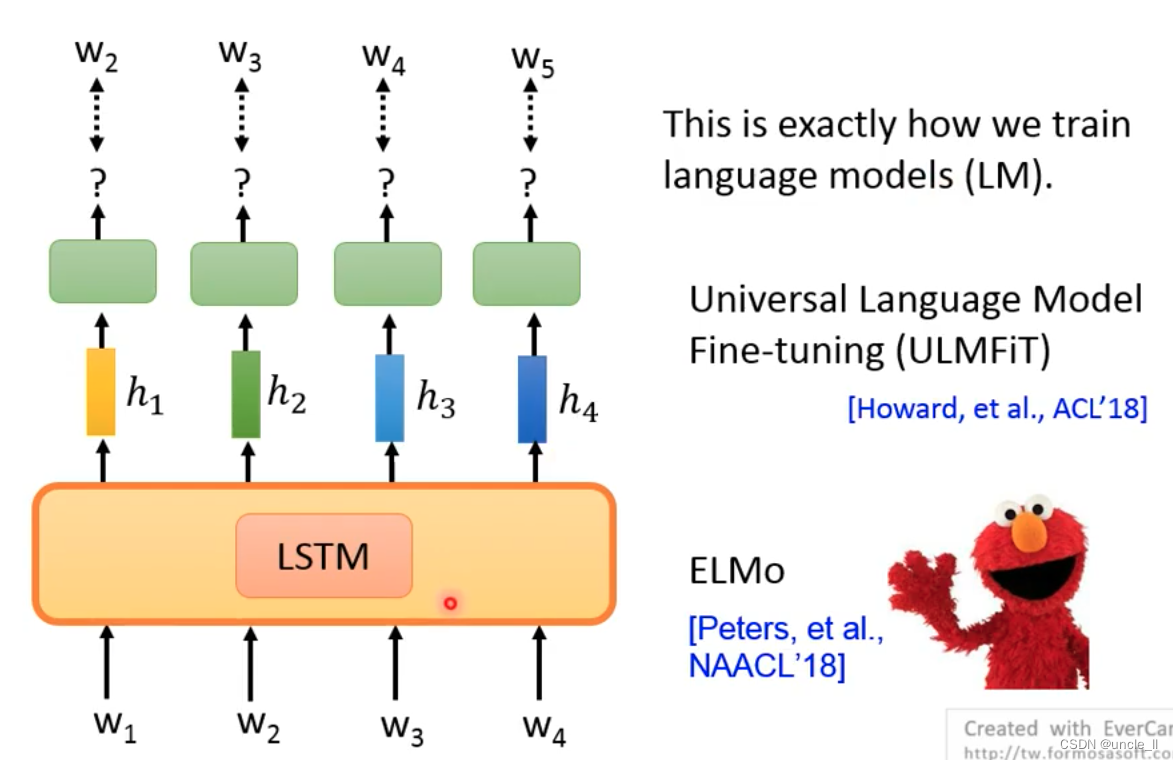
基础架构网络使用的是LSTM:
- LM
- ELMo
- ULMFiT
后续一些算法将LSTM换成Self-attention
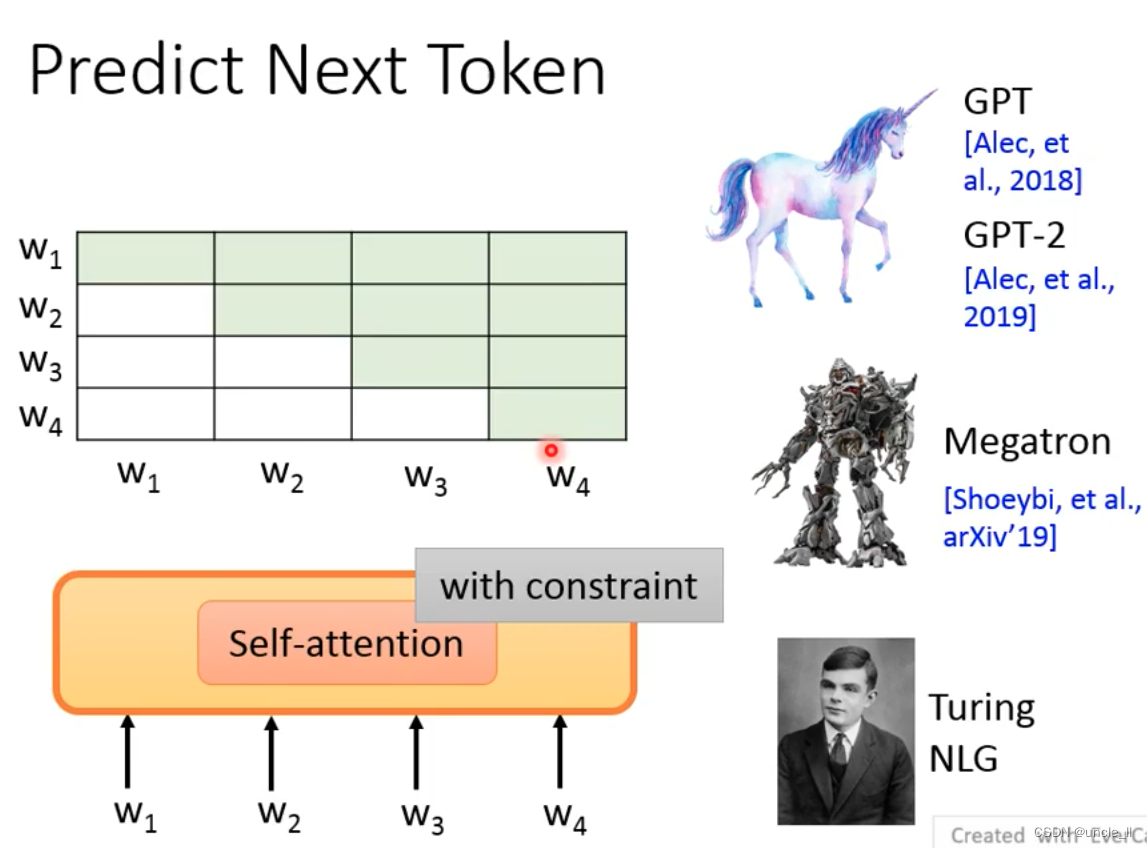
- GPT
- Megatron
- Turing NLG
注意:控制Attention的范围

可以用来生成文章: talktotransformer.com



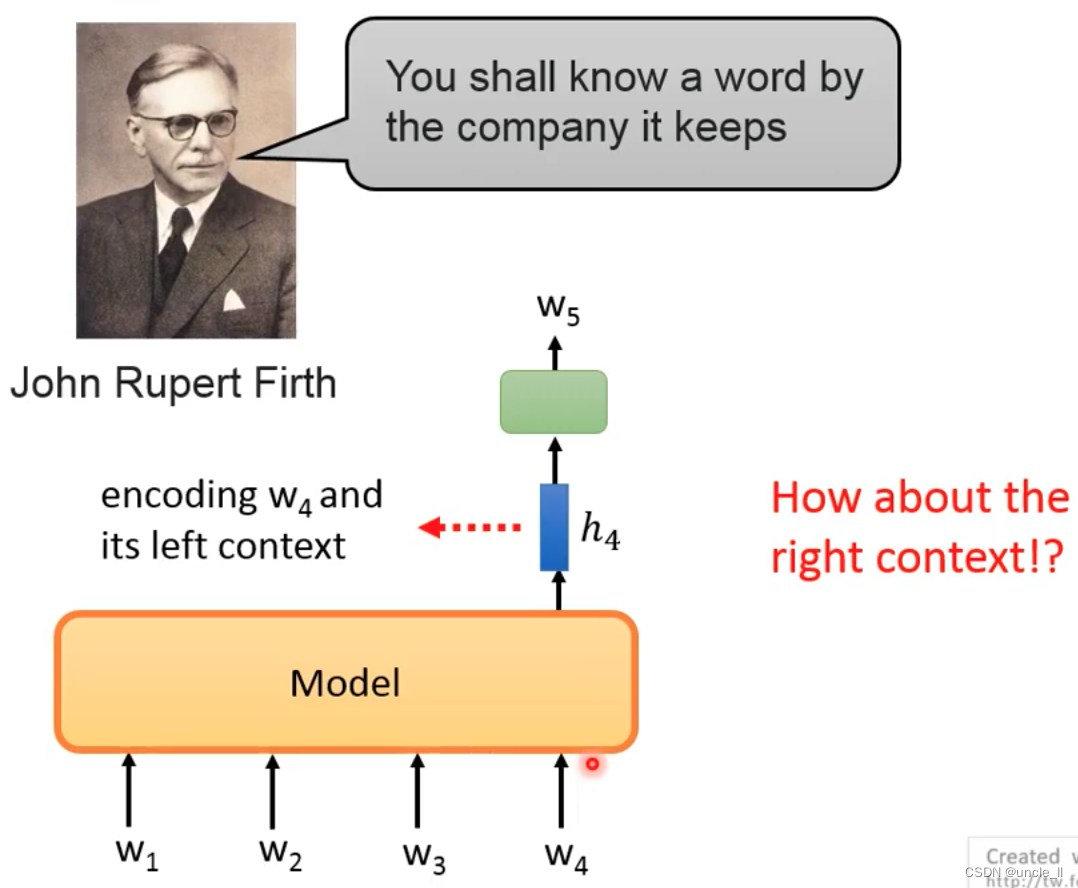
如果只考虑左边的出现关系,为什么不考虑右边文本呢?
Predict Next Token-Bidrectional
左右两边产生的context,二者联合起来作为最终表示:
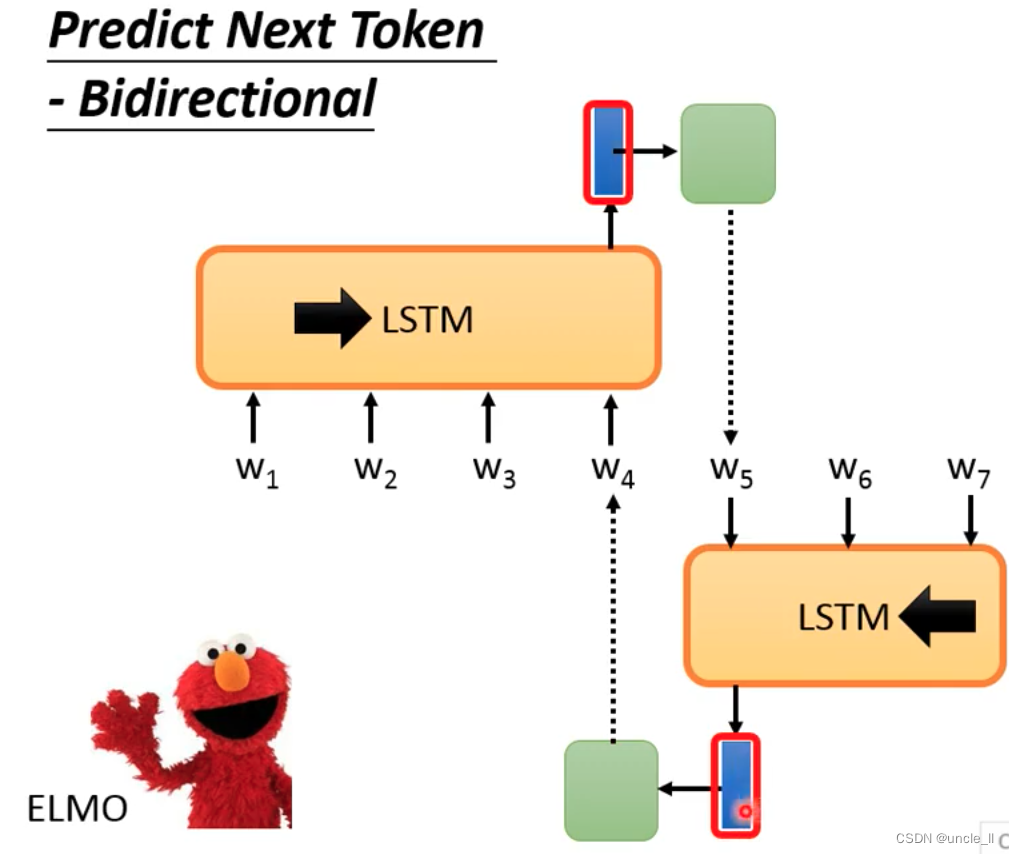
但是问题是左边只能看到左边的,无法看到右边的结束,右边只能看到右边的,无法看到左边的开始。
Masking input
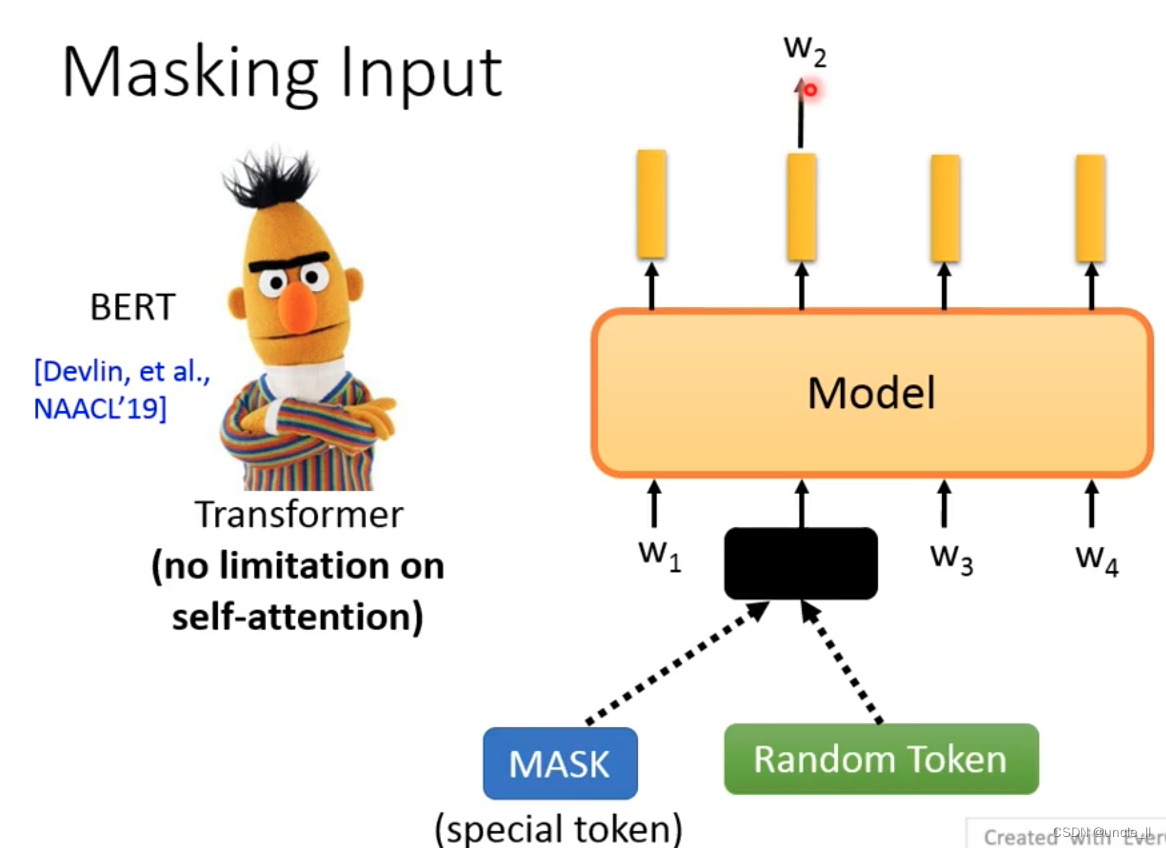
随机的盖住某个词,是看到了完整的句子才来预测这个词是什么。
这种思想往前推,跟以前的cbow非常像:
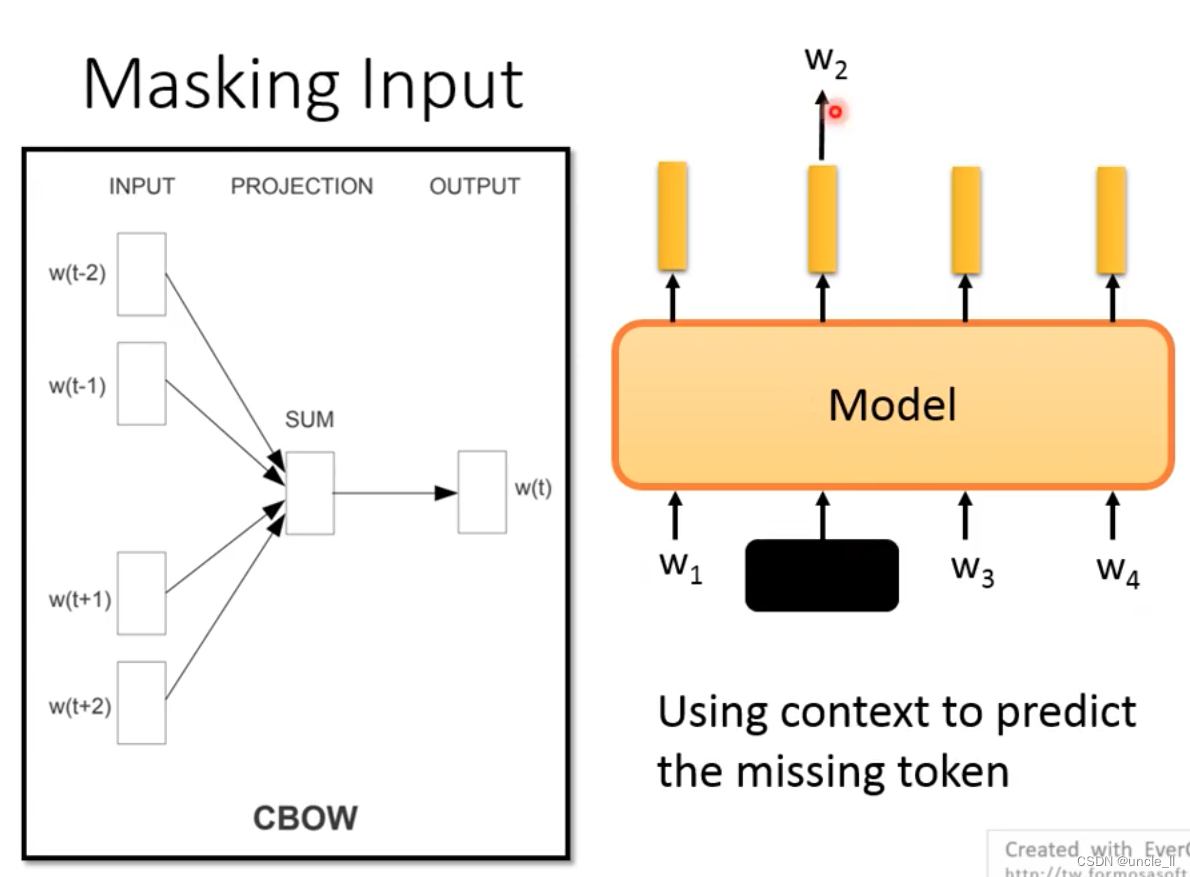
Bert与cbow的区别就是左右两边的长度可以无限,而不是有个window窗口长度。
随机mask是否够好呢?有几种mask方法:
- wwm
- ERNIE
- SpanBert
- SBO

盖住一整个句子或者盖住好几个词。或者先把Entity找出来,然后把这些词盖住:

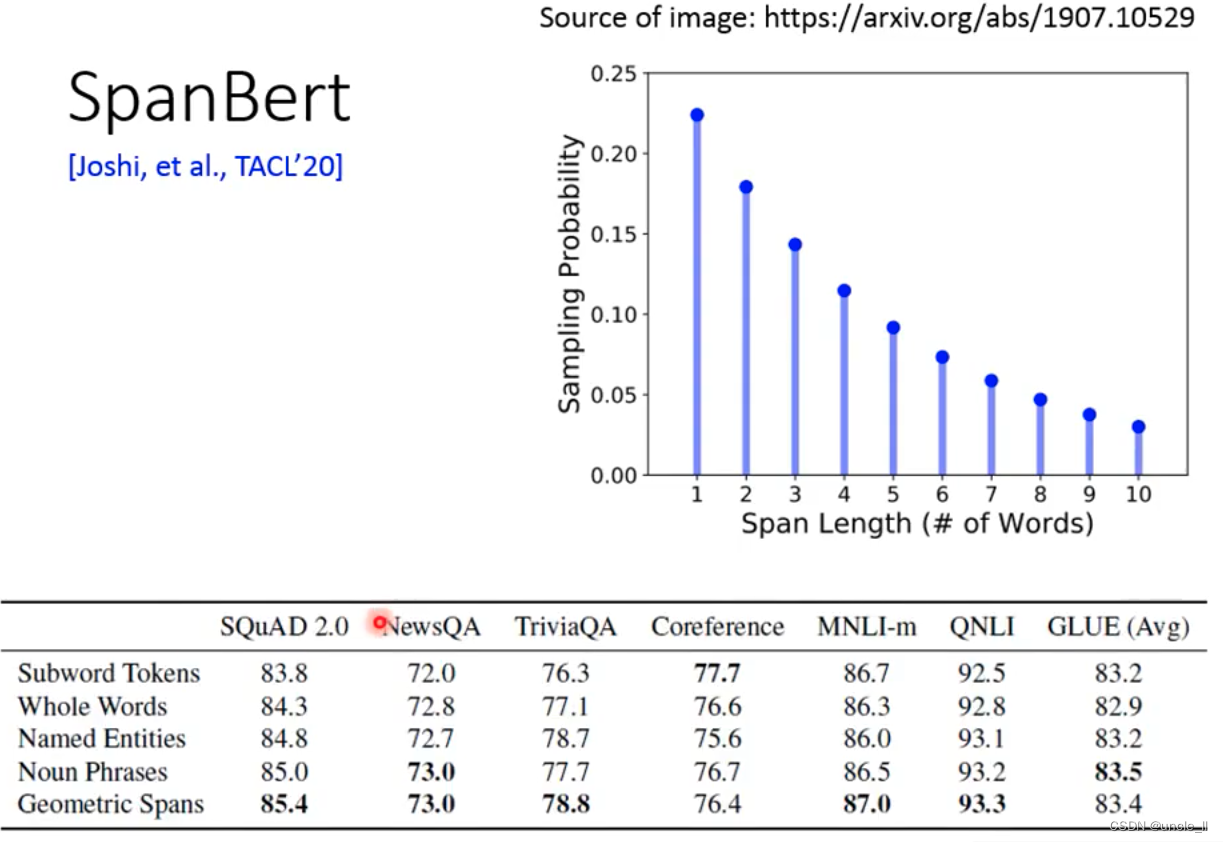
盖住的长度按照上述图的出现概率。
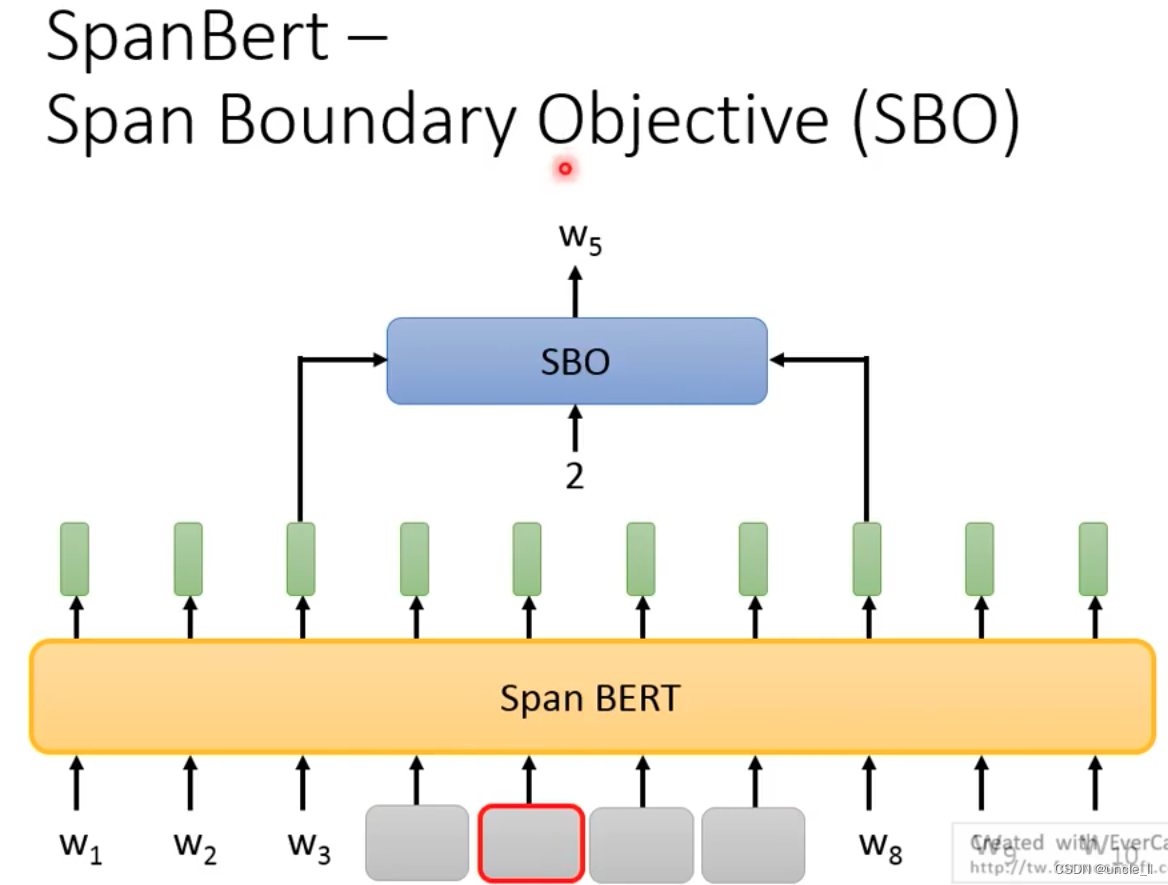
盖住的左右两边的embedding来预测,以及输入的index来恢复中间的哪个词。
SBO的设计期待左右两边的token embedding能够包含左右两边的embeeding信息。
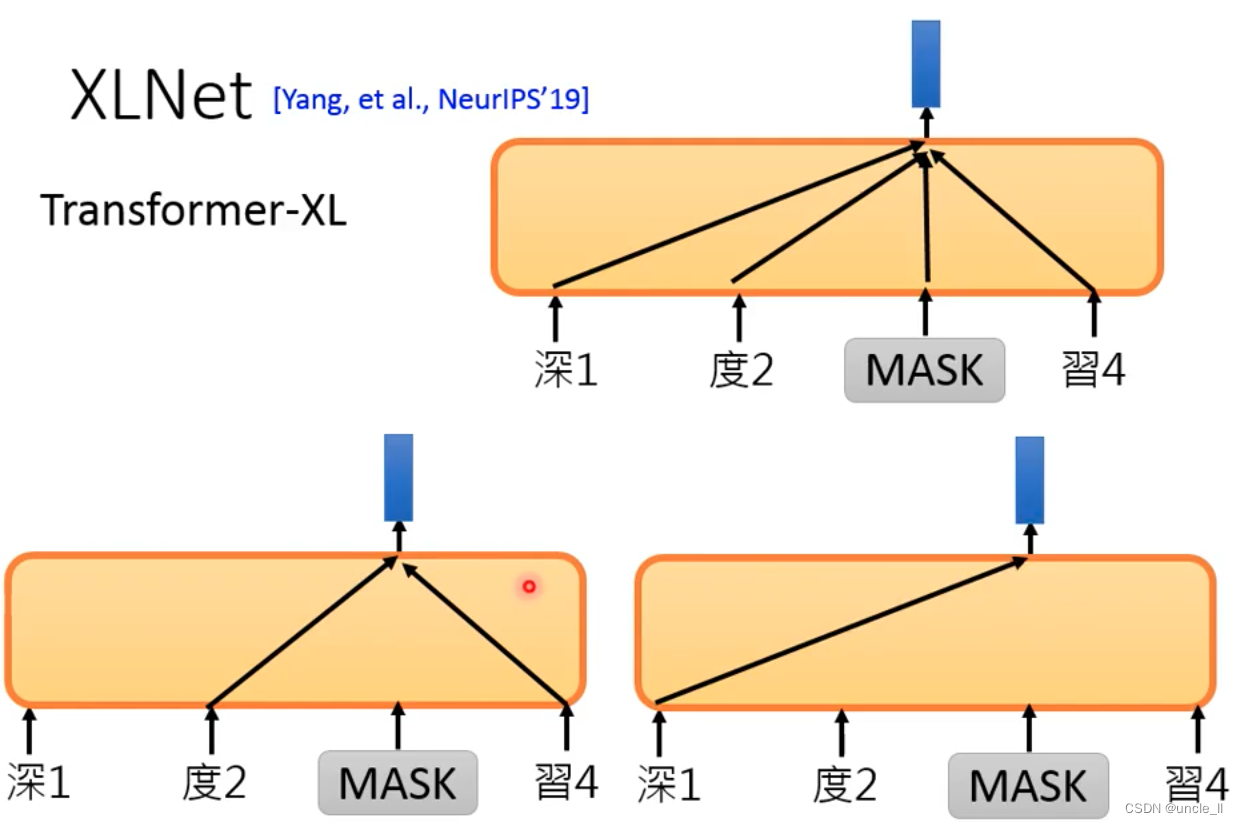
XLNet
结构不是使用的Transformer,而是使用Transformer-XL
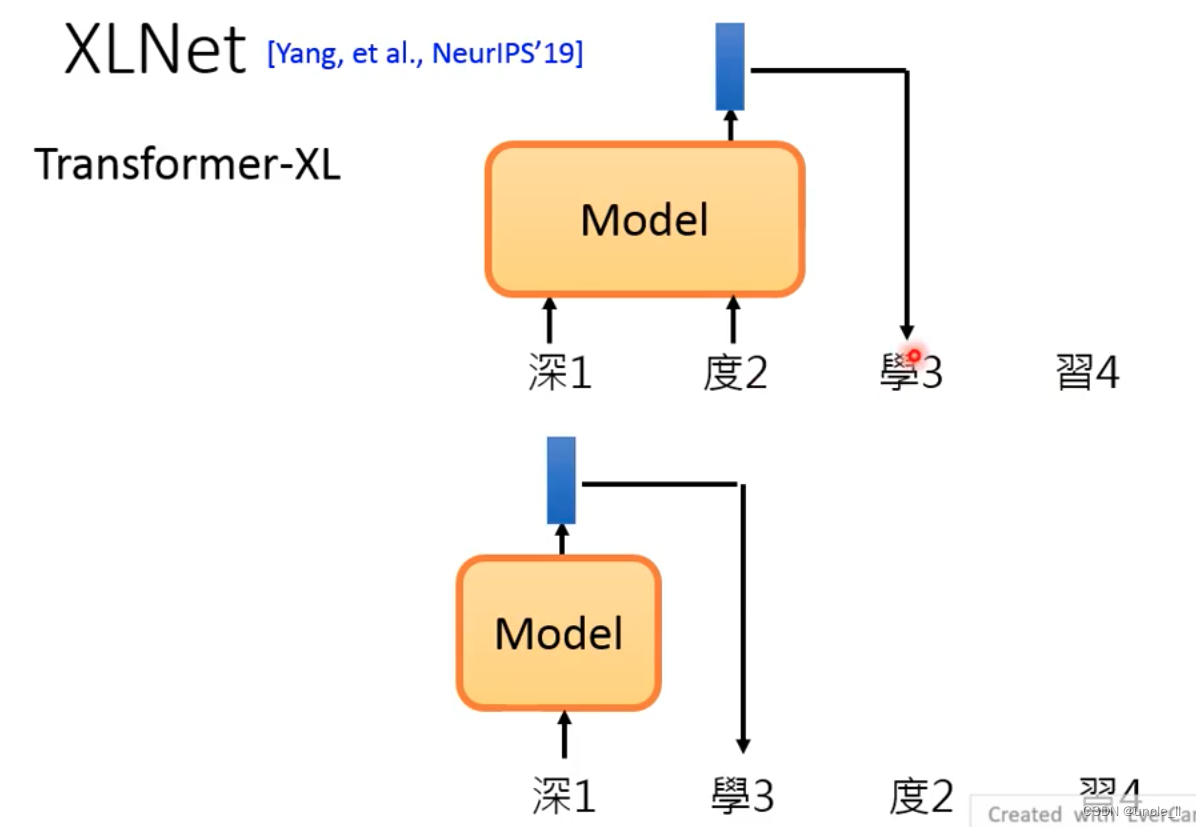
随机把顺序打乱,用各式各样不同的信息训练一个token。
Bert的训练语料比较规整:
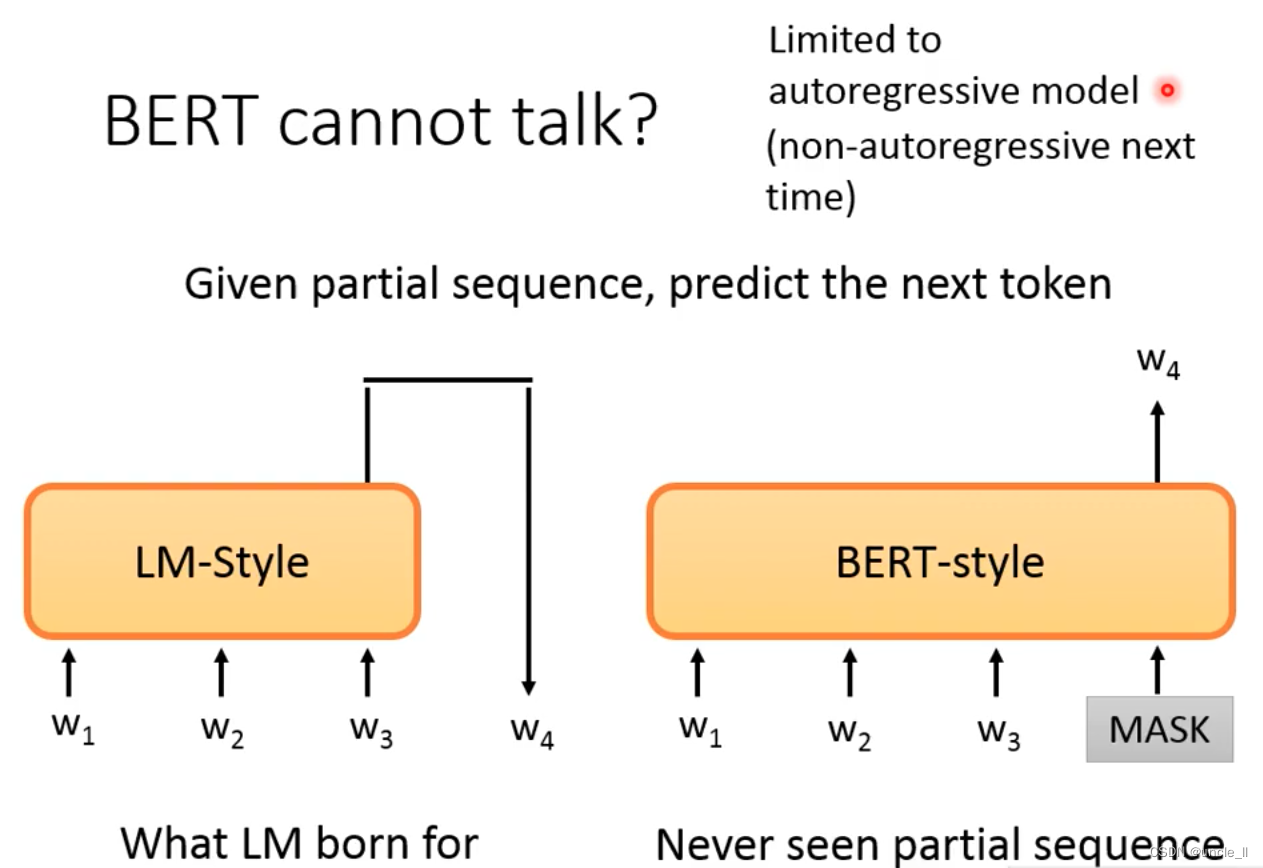
Bert不擅长做Generative任务,因为bert训练的时候给的是整个句子,而generative只是给一部分,然后由左得右预测下一个token
MASS/BART
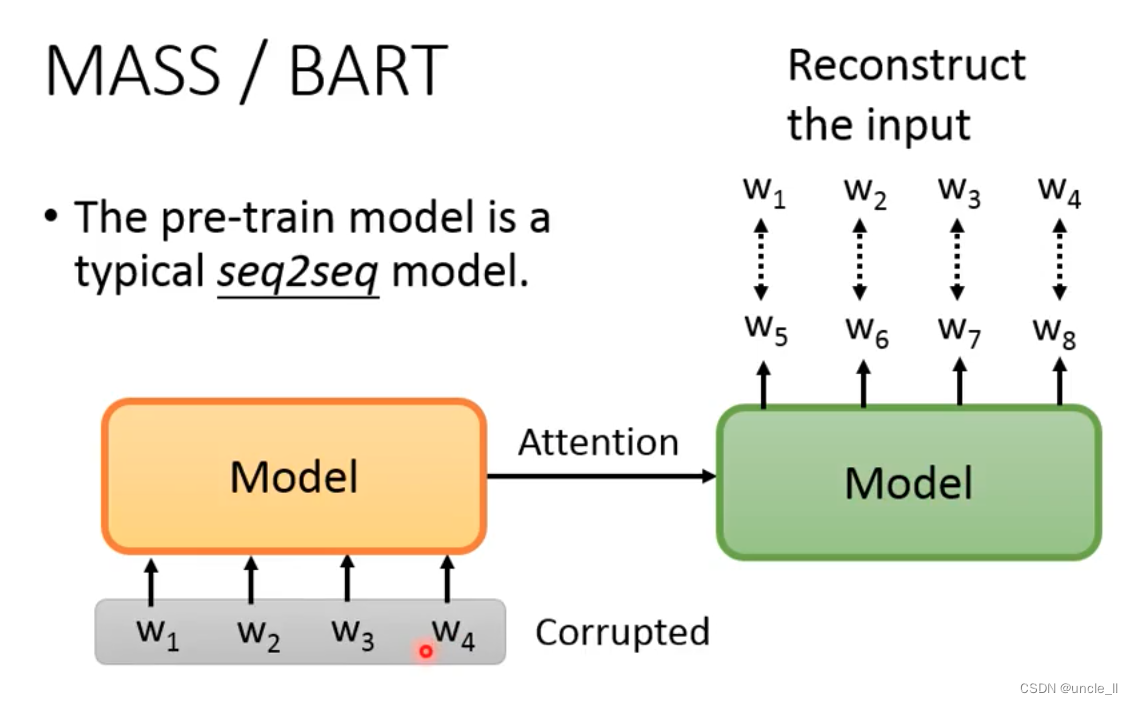
要对w1,w2, w3,w4进行一些破坏,不然model学不到任何东西,破坏的方法:

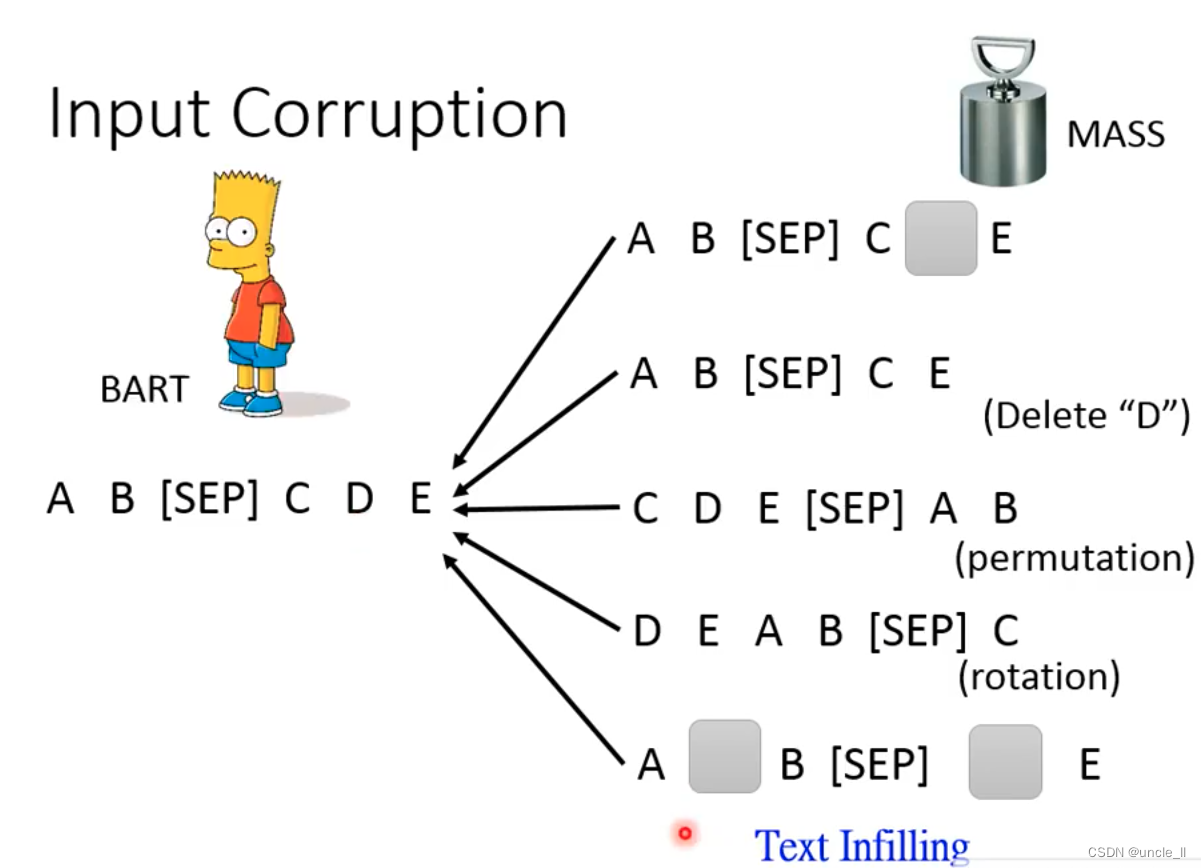
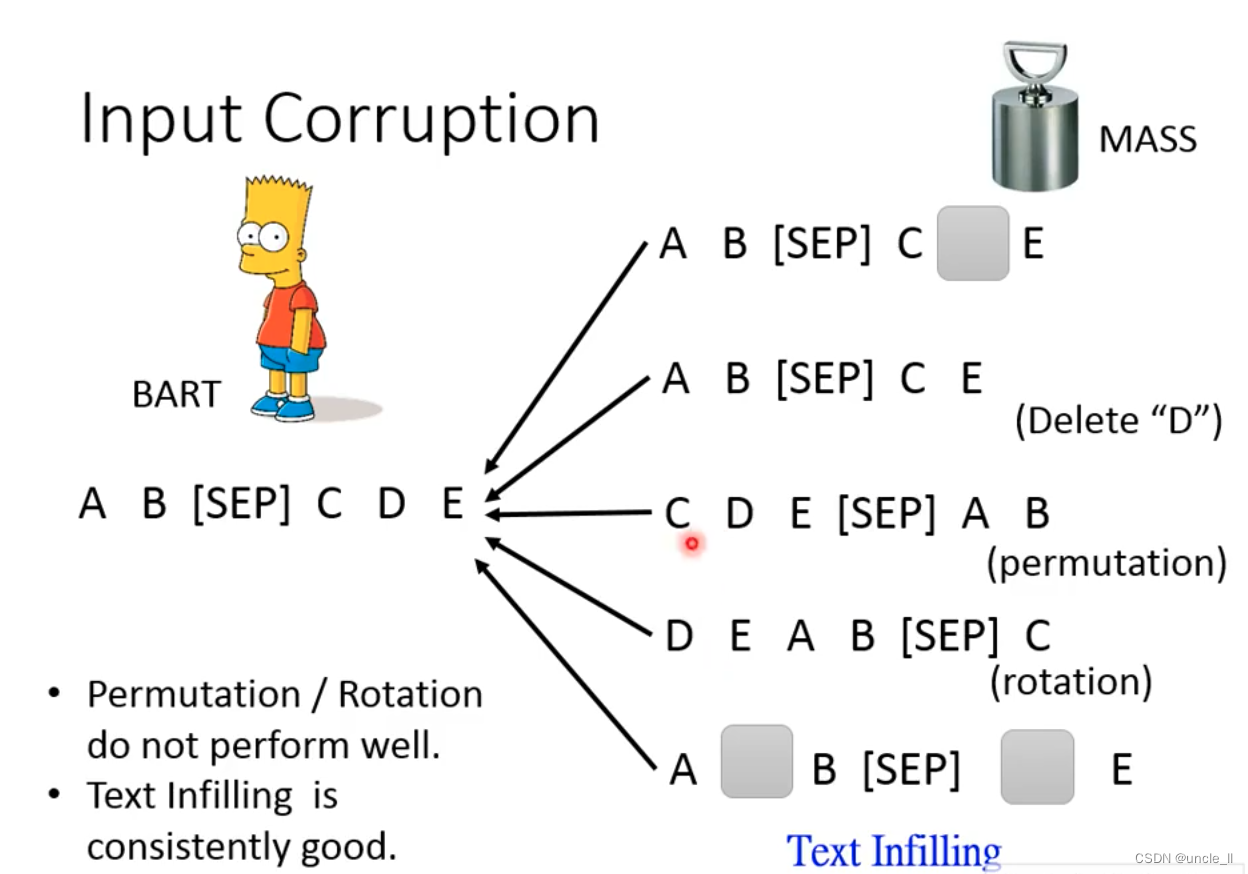
- mask(随机mask)
- delete(直接删掉)
- permutation(打乱)
- rotation(改变起始位置)
- Text Infilling (插入一个别的误导,少掉一个mask)
结果是:
UniLM
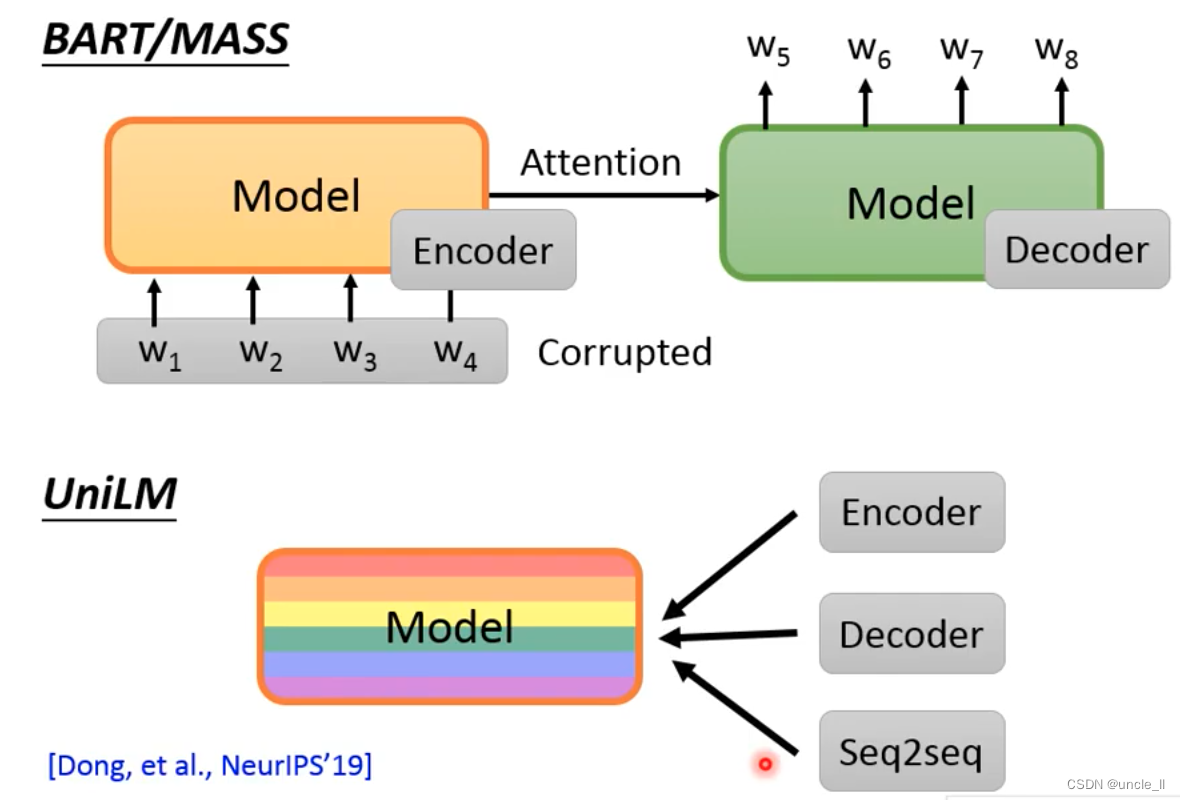
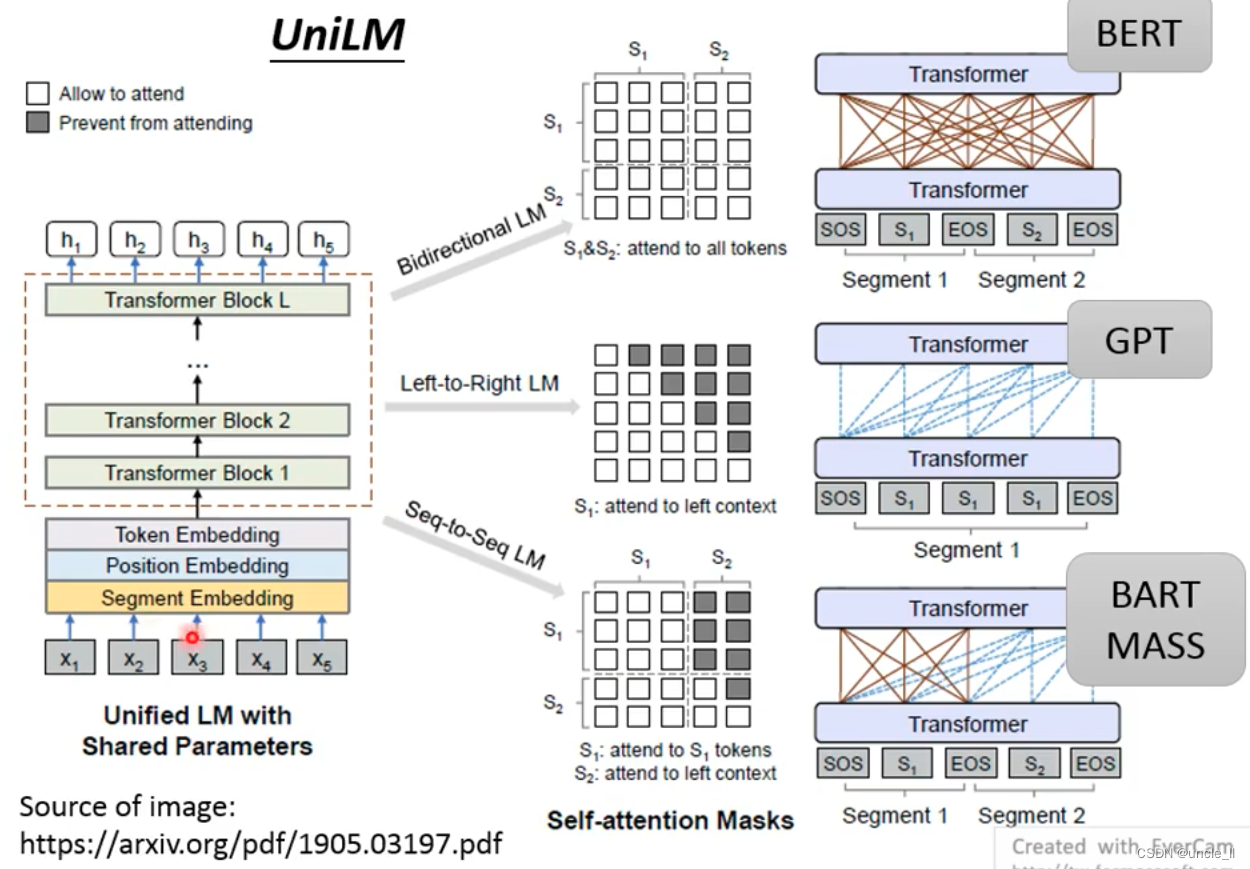
UniLM进行多项训练
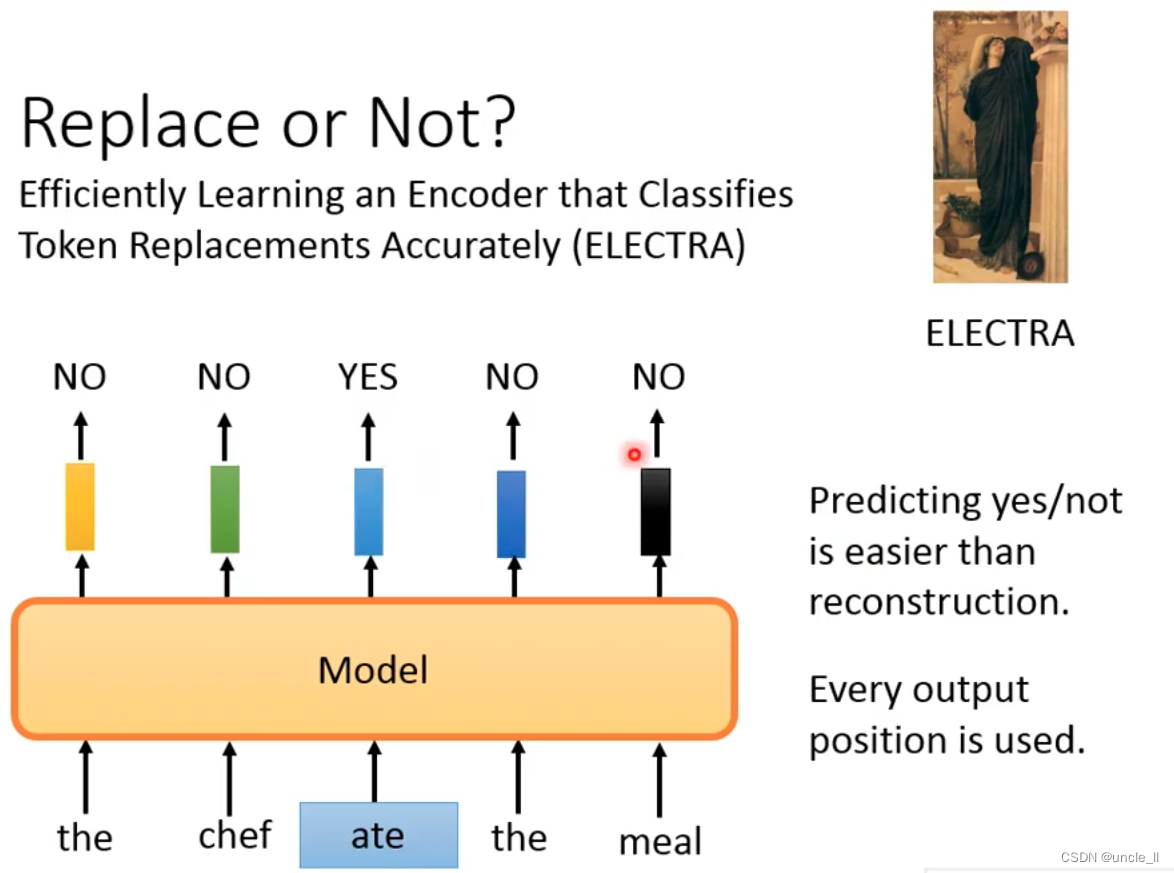
Replace or Not
- ELECTRA,避开了需要训练和生成的东西,判断哪个位置是否被置换,训练非常简单,另外每个输出都被用到。
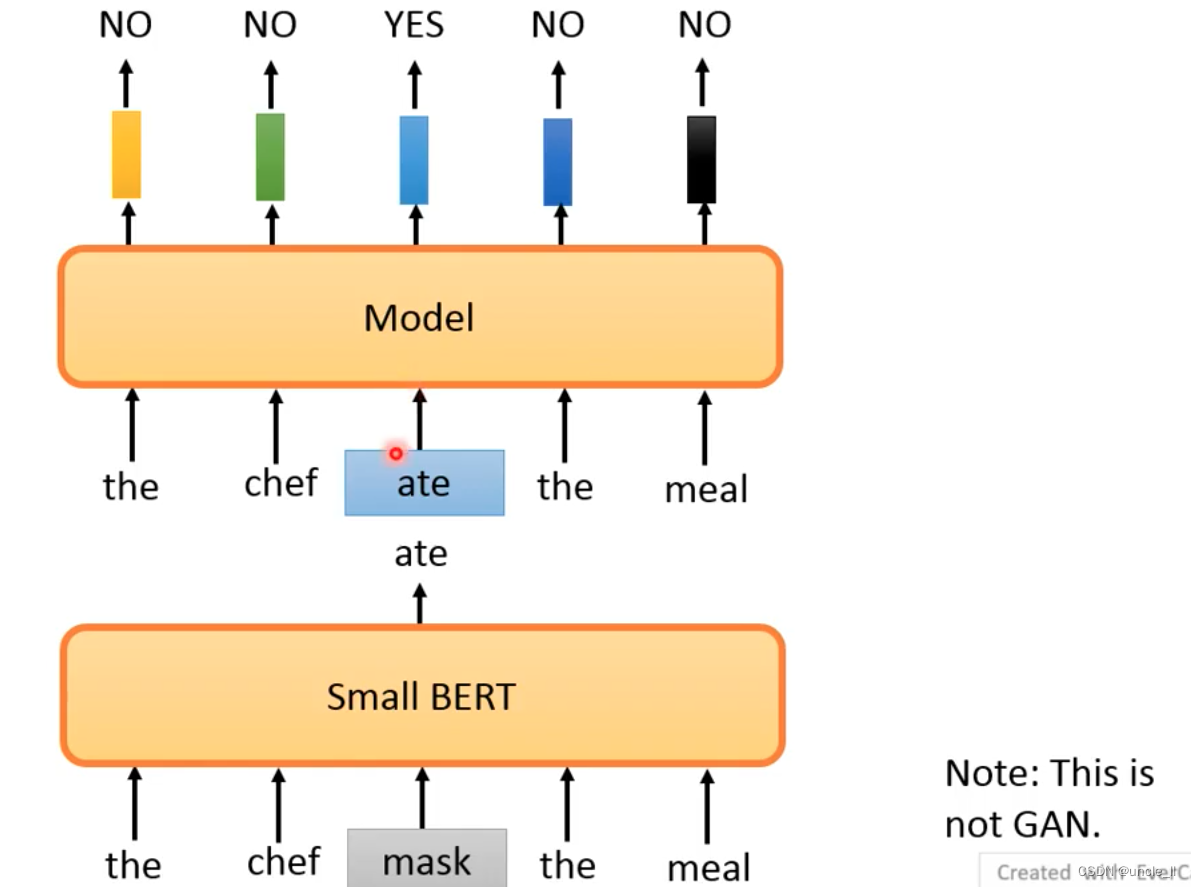
*
置换的词不好弄,如果是随便置换肯定很容易知道。所以有了下面的结果,用一个小的bert预测的结果作为替换的结果,小的bert效果不要太好,不然预测的结果跟真实的一样,得不到替换的效果,因为替换的结果是一模一样的。
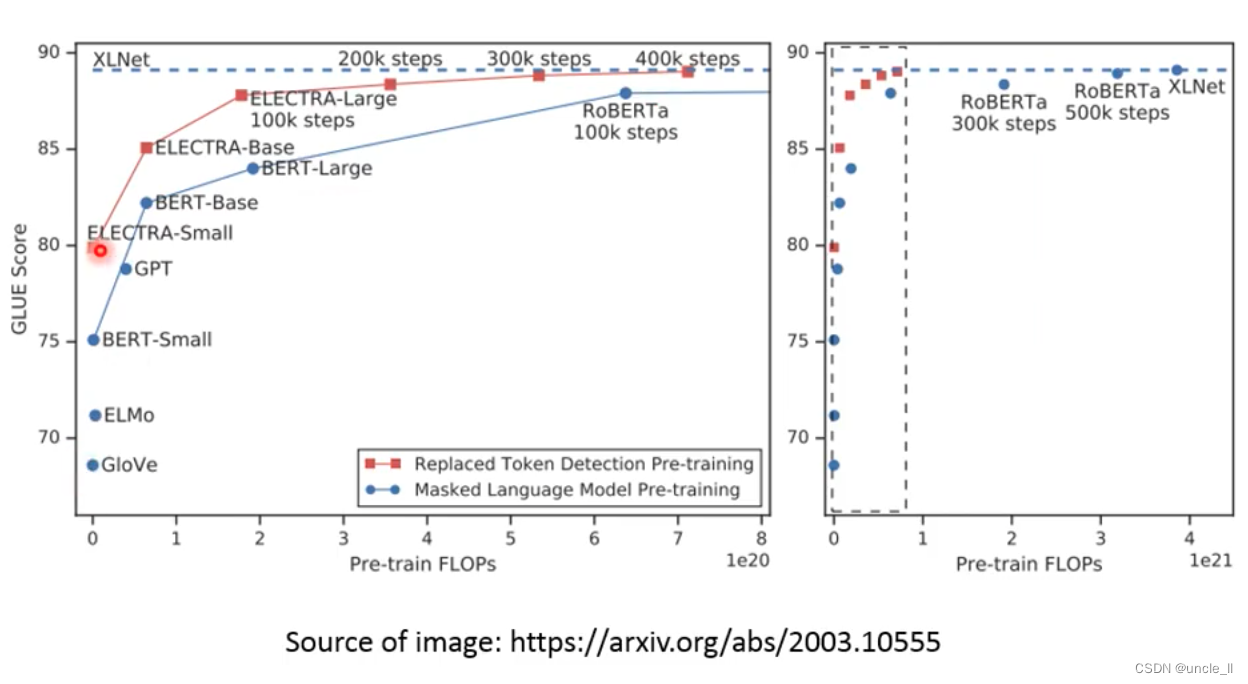
只需要四分之一的计算量,就能达到XLNet的效果。
Sentence Level
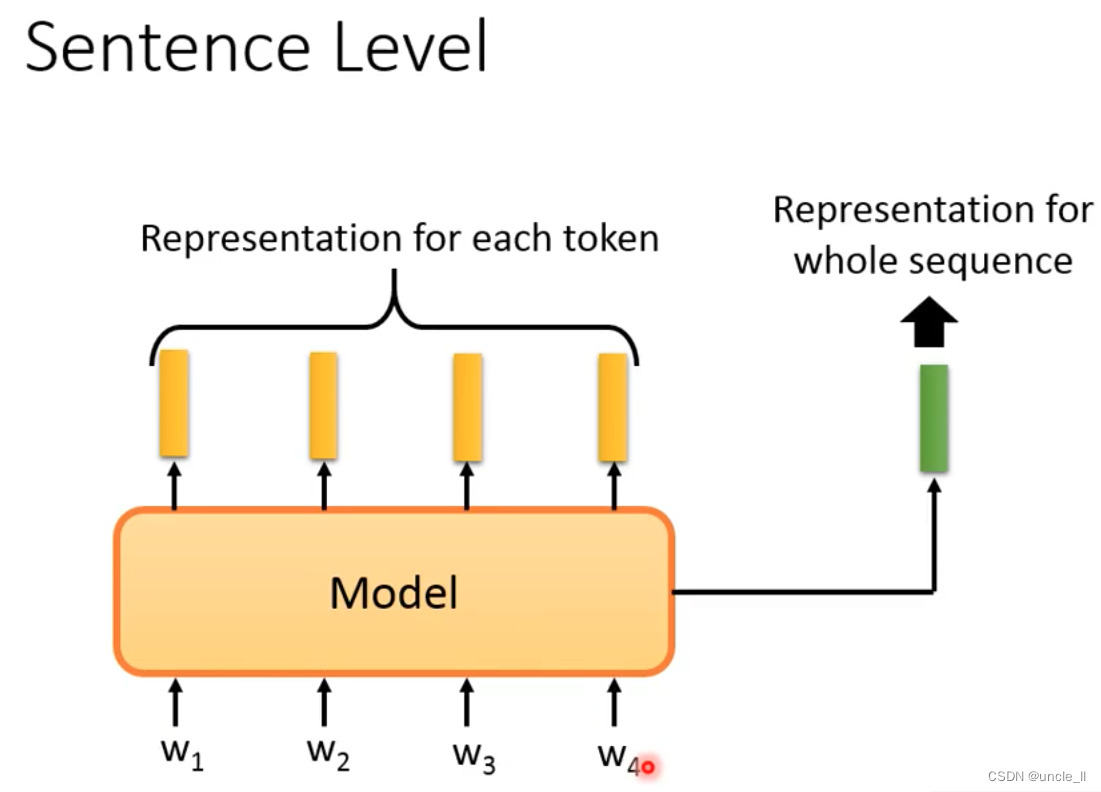
需要整个句子的embedding。
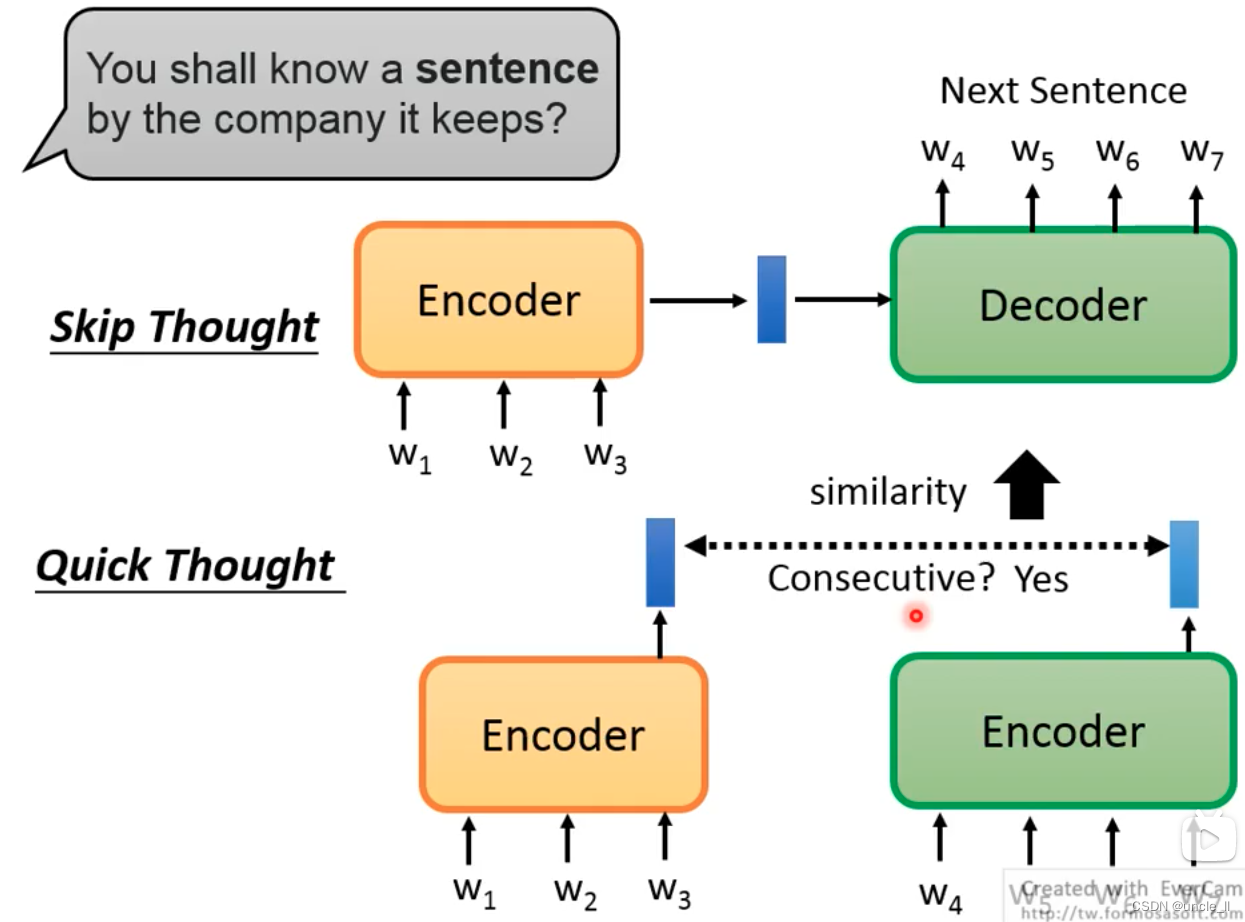
- 使用skip thought,如果两个句子的预测结果比较像,那么两个输入句子也比较像。
- quick thought,如果两个句子的输出是相连的,让相似的句子距离越近越好。
上述方法避开做生成的任务。
原始的Bert其实还有一项任务NSP,预测两个句子是否是相接的还是不相接的。两个句子中间用sep符号分割。
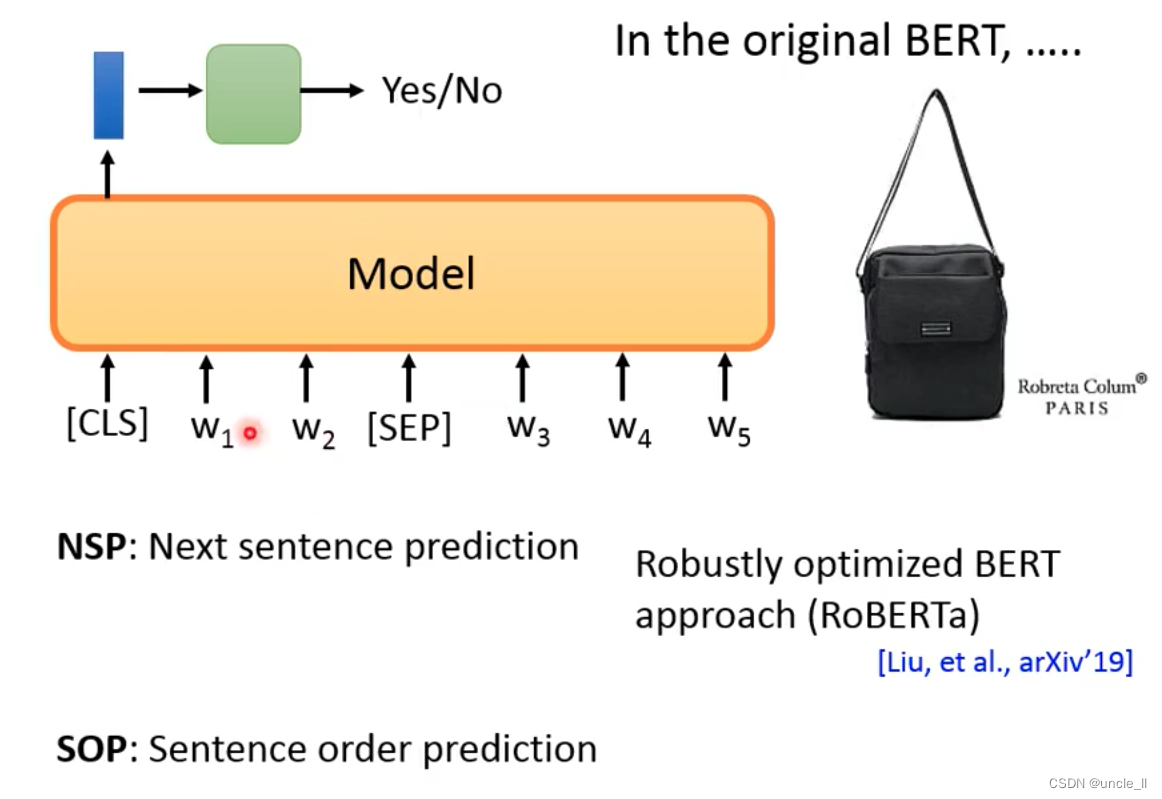
- nsp:效果表现不好
- Roberta:效果一般
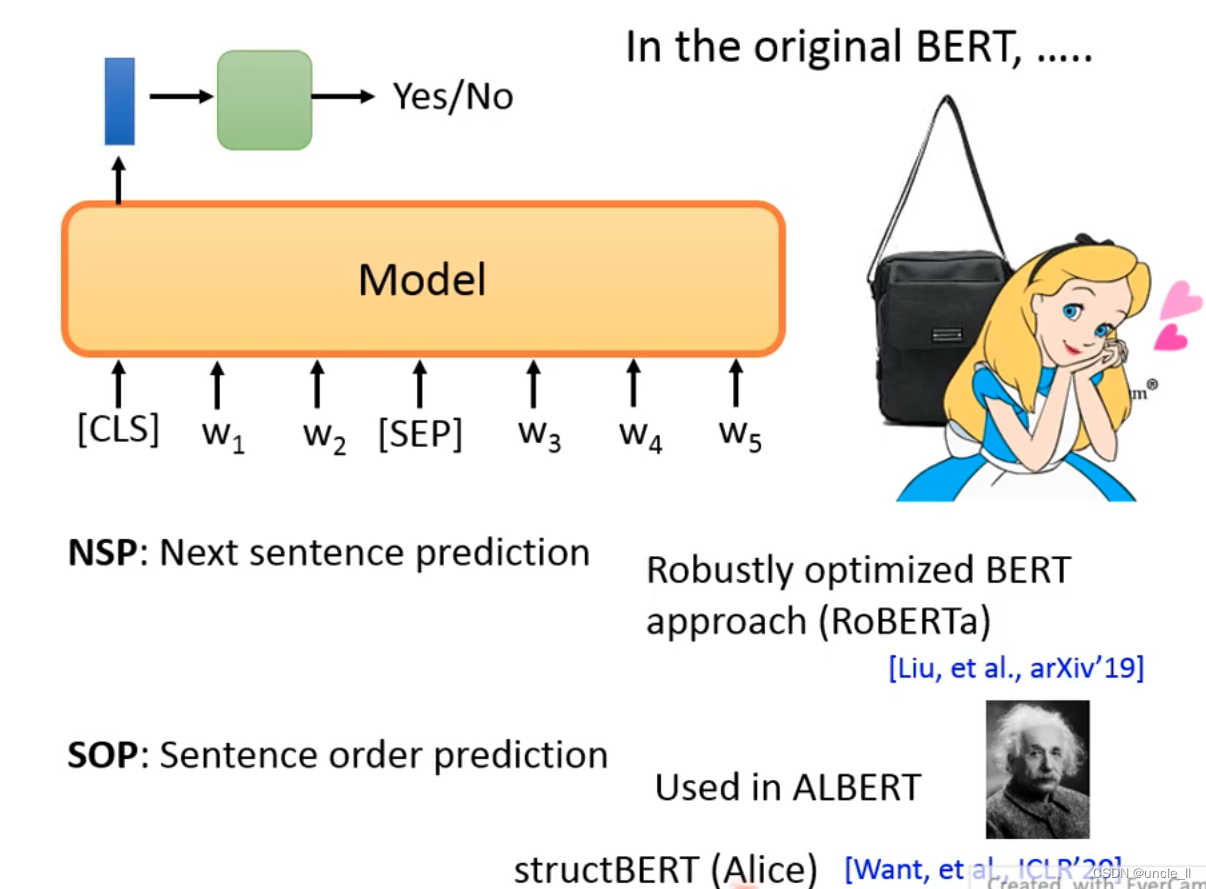
- sop: 正向是相接,反向是不相接,被用在ALBERT
- structBert:Alice,
T5 Comparison
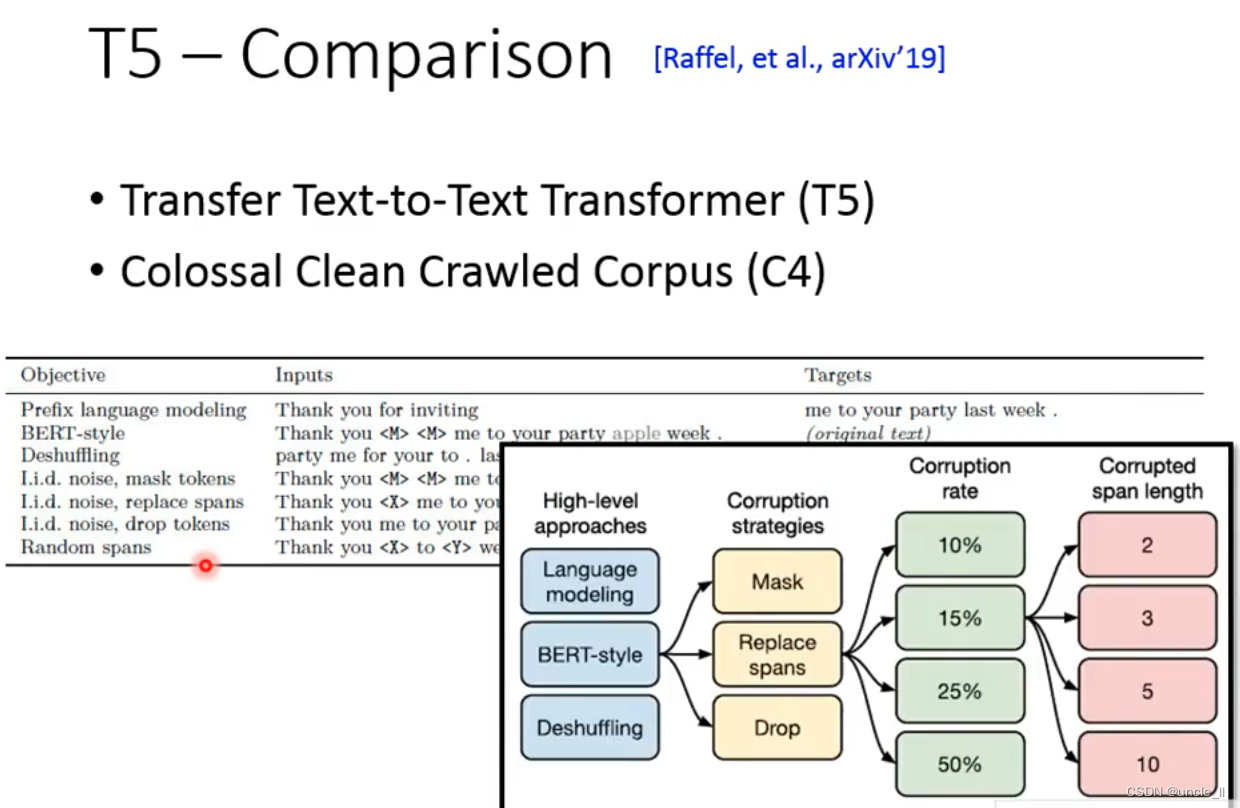
5个T就叫T5
4个C就叫C4
ERNIE
希望在train的时候加入knowledge

Audio Bert