正则表达式 (Regular Expression, RE, 或称为常规表达式)是通过一些特殊字符的排列,用以“搜寻/取代/删除”一列或多列文字字串, 简单的说,正则表达式就是用在字串的处理上面的一项“表示式”。正则表达式并不是一个工具程序, 而是一个字串处理的标准依据,如果想要以正则表达式的方式处理字串,就得要使用支持正则表达式的工具程序才行, 这类的工具程序很多,例如 vi, sed, awk 等等。
11.1 什么是正则表达式
正则表达式就是处理字串的方法,他是以行为单位来进行字串的处理行为, 正则表达式通过一些特殊符号的辅助,可以让使用者轻易的达到“搜寻/删除/取代”某特定字串的处理程序。
正则表达式基本上是一种“表达式”, 只要工具程序支持这种表达式,那么该工具程序就可以用来作为正则表达式的字串处理之用。 例如 vi, grep, awk,sed 等等工具,因为她们有支持正则表达式, 所以,这些工具就可以使用正则表达式的特殊字符来进行字串的处理。但例如 cp, ls 等指令并未支持正则表达式, 所以就只能使用 bash 自己本身的万用字符而已。
11.2 基础正则表达式
11.2.1 语系对正则表达式的影响
在英文大小写的编码顺序中,zh_TW.big5 及 C 这两种语系的输出结果分别如下:
LANG=C 时:0 1 2 3 4 ... A B C D ... Z a b c d ...
LANG=zh_TW 时:0 1 2 3 4 ... a A b B c C d D ... z Z

11.2.2 grep 的一些进阶选项

grep 是一个很常见也很常用的指令,他最重要的功能就是进行字串数据的比对,然后将符合使用者需求的字串行印出来。 需要说明的是“grep 在数据中查寻一个字串时,是以 "整行" 为单位来进行数据的撷取的!”也就是说,假如一个文件内有 10 行,其中有两行具有你所搜寻的字串,则将那两行显示在屏幕上,其他的就丢弃了。
11.2.4 基础正则表达式字符汇整(characters)
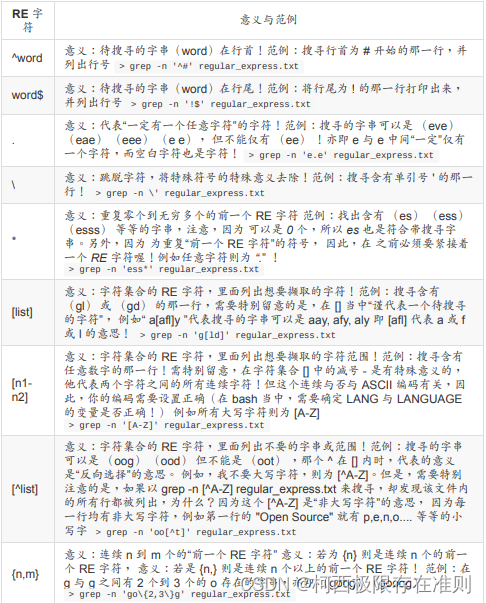
举例来说,不支持正则表达式的 ls 这个工具中,若我们使用 “ls -l ” 代表的是任意文件名的文件,而 “ls -l a ”代表的是以 a 为开头的任何文件名的文件, 但在正则表达式中,我们要找到含有以 a 为开头的文件,则必须要这样:(需搭配支持正则表达式的工具)
ls | grep -n '^a.*'![「网络编程」传输层协议_ TCP协议学习_及原理深入理解(一)[万字详解]](https://img-blog.csdnimg.cn/8fc4a7c73e5b49629dd35f838cc5cbfd.png)