说在前面
在40岁老架构师 尼恩的读者社区(50+)中,最近有小伙伴拿到了一线互联网企业如极兔、有赞、希音、百度、网易、滴滴的面试资格,遇到一几个很重要的面试题:
(1) 什么是熔断,降级?如何实现?
(2) 服务熔断,解决灾难性雪崩效应的有效利器
(3) 说一下限流、熔断、高可用
等等等等…
**熔断,降级,防止雪崩,是面试的重点和高频点。**尼恩作为技术中台、数据中台的架构师,致力于为大家研究出一个 3高架构知识宇宙, 所以这里,结合亿级qps微信后台是如何熔断降级方案,带大家完成一个亿级用户场景,如何一步一步,进行熔断,降级,防止雪崩架构。
当然,作为一篇文章,仅仅是抛砖引玉,后面有机会,带大家做一下这个高质量的实操,并且指导大家写入简历。
让面试官爱到 “不能自已、口水直流”。
也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典》V86版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从公号 【技术自由圈】获取。
文章目录
- 说在前面
- 亿级qps微信后台是如何熔断降级,防止崩溃的?
- 降级保护的基本原理
- 什么是降级?
- 降级保护的几个核心策略
- 资源隔离
- 限流降级
- 超时降级
- 失败次数降级
- 熔断降级(过载保护)
- 过载保护的好处
- 如何判断过载
- 降级保护的主流架构方案
- Hystrix 熔断降级、限流降级
- Hystrix 限流降级
- Hystrix 异常降级
- Hystrix 调用超时降级
- Hystrix 资源隔离
- 线程池隔离(舱壁模式)
- Hystrix线程池隔离
- Hystrix线程池隔离配置
- Hystrix信号量隔离
- 线程池与信号量区别
- Hystrix 熔断降级(过载保护)
- 断路器有3种状态:
- Hystrix 实现熔断机制
- 熔断器状态变化的演示实例
- 熔断器和滑动窗口的配置属性
- Hystrix命令的执行流程
- Sentinel 限流降级
- 基本的参数
- 流控的几种 strategy:
- 直接失败模式 限流
- Sentinel 关联模式限流
- Warm up(预热)模式 限流
- Sentinel 熔断降级
- 什么是Sentinel熔断降级
- Sentinel 熔断降级规则
- 几种降级策略
- 熔断降级代码实现
- 控制台降级规则
- Sentinel 与 Hystrix对比
- 1、资源模型和执行模型上的对比
- 2、隔离设计上的对比
- 3、熔断降级的对比
- Sentinel 与 Hystrix的不足
- 分层分级细粒度、高精准熔断限流降级策略
- 微信后台亿级QPS吞吐量的过载场景
- 微信后台如何判断过载
- 微信后台的限流降级策略(过载保护策略)
- 分层分级细粒度、高精准熔断限流降级策略
- 1)业务分层
- 2)用户分级
- 3)分层分级二维限流降级控制
- 4)RPC组件客户端限流
- 微信整个负载控制的流程
- 说在最后
- 作者介绍
- 参考文献
- 推荐相关阅读
亿级qps微信后台是如何熔断降级,防止崩溃的?
微信作为月活过10亿的国民级应用,是中国最受欢迎的社交网络平台之一,拥有庞大的用户群体和广泛的社交功能,包括朋友圈、微信支付、小程序、公众号等。
同时,微信也在不断地进行创新和扩展,如推出微信小程序、微信支付海外版等,以满足不同用户的需求。
微信的日活用户数量一直在增长,截至2022年第一季度,微信的日活用户数量已经达到了10亿
微信的月活用户数量也在不断增长,截至2022年第三季度,微信的月活用户数量已经达到了13.09亿
微信作为当之无愧的国民级应用,系统复杂程度超乎想象:
- 其后台由三千多个移动服务构成,
- 每天需处理大约十的10~11次方个外部请求,
- 整体需要每秒处理大约几亿个请求! 亿级QPS吞吐量规模
作为顶级、超级互联网应用,微信和其他的分布式、微服务应用一样,经常面临特殊节点消息量暴增的问题,服务很容易出现过载问题。
但微信的服务一直比较稳定,是如何做到的呢?
尼恩带着大家,从降级保护的基本原理 讲起。
并且将微信和hystrix、sentinel 对比介绍。
降级保护的基本原理
什么是降级?
所谓降级,一般指整体的资源即将耗尽,为了保留关键的服务,舍弃非核心的服务。
核心链路又称 黄金链路。
黄金链路是团队的生命线链路,由最核心的应用,最关键的DB,最需要死保的接口,支撑的最核心业务。
黄金链路的治理就一个目标:不要让非核心的东西影响了核心的。
这里的“东西”包括业务、系统、DB 等等
降级保护的几个核心策略
- 资源隔离
- 限流降级
- 超时降级
- 故障降级
- 失败次数降级
- 熔断降级
- 分层分级细粒度高精准降级
资源隔离
所谓资源隔离 ,就是 隔离 黄金链路和 非核心链路, 对非核心链路进行降级, 对黄金链路进行 保护。
具体来说,对黄金链路上的,每一个服务乃至其对应的数据库,分配独立的服务器资源、网络资源、数据库资源,进行独立部署就行!
对黄金链路进行资源重点投入,做好链路的高并发、高性能、高可用设计。
这样,当非核心链路某个服务出现了故障,就不会影响到黄金链路,达到一种物理层面上的隔离!
资源隔离是一种隐性的降级策略,为什么叫做隐性而不是显性呢?
资源隔离相当于对不同的链路分级对待,对非核心链路,本质是一种降级处理。
限流降级
当访问量太大而导致系统崩溃时,使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级。
限流降级,兜底的处理方案可以是:
- 排队页面
- 错误页等
超时降级
超时降级是当某个微服务响应时间过长,超过了 正常的响应时长,我们不能让他一直卡在那里,所以要在准备一个兜底的策略,当发生这种问题的时候,我们直接调用一个降级方法来快速返回,不让他一直卡在那 。
超时降级的策略为:
- 配置好超时时间和超时重试次数
- 失败后调用降级方法,拿到降级的结果返回
- 随后的请求快速失败,
- 并且使用异步机制,探测恢复情况。一直到接口回复。
失败次数降级
失败次数降级是当某个微服务总是调用失败,我们不能让他一直失败,所以要在准备一个兜底的策略,当发生这种问题的时候,我们直接调用一个降级方法来快速返回,不让他一直卡在那 。
失败降级的策略为:
- 主要是一些不稳定的api,当失败调用次数达到一定阀值自动降级,
- 降级后的数据,可以是默认值(比如库存服务挂了,返回默认现货)、兜底数据(比如广告挂了,返回提前准备好的一些静态页面)、缓存(之前暂存的一些缓存数据)
- 同样要使用异步机制探测回复情况。
熔断降级(过载保护)
互联网应用,天生就会有突发流量。
秒杀、抢购、突发大事件、节日甚至恶意攻击等,都会造成服务承受平时数倍的压力。
比如,微博经常出现某明星官宣结婚或者离婚导致服务器崩溃的场景,这就是服务过载。
服务过载是什么意思呢?
就是服务的请求量,超过服务所能承受的最大值,从而导致服务器负载过高,响应延迟加大。
下游客户端的表现:RT响应时间变长,加载缓慢,甚至无法加载。
服务过载的存在级联效应:
下游会进一步的重试,导致上游服务一直在处理无效请求,导致有效请求跌 0,甚至导致整个系统产生雪崩。
熔断就像是家里的保险丝一样,当电流达到一定条件时,比如保险丝能承受的电流是5A,如果电流达到了6A,因为保险丝承受不了这么高的电流,保险丝就会融化,电路就会断开,起到了保护电器的作用;
在微服务里面也是一样,当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用;
所以,在互联网应用中,由于某些原因使得服务出现了过载现象,为防止造成整个系统故障,从而采用的一种熔断降级(过载保护)措施。
过载保护的好处
服务过载容易导致系统瘫痪,系统雪崩,系统雪崩就意味着用户流失、口碑变差、导致巨大的经济损失(亿级以上),和巨大的品牌损失(无法估量)。
提升用户体验、保障服务质量。在发生突发流量时仍然能够提供一部分服务能力,而不是整个系统瘫痪,
如何判断过载
通常判断过载的方式很多,比如:
- 使用 吞吐量 判断过载
- 使用 访问延迟 判断过载
- 使用 CPU 使用率 判断过载
- 使用 丢包率 判断过载
- 使用 失败率 判断过载
- 使用 待处理请求数 判断过载
- 使用 请求处理事件 判断过载
- 请求在队列中的平均等待时间 判断过载
Hystrix 、Sentinel 主要使用 使用 失败率 判断过载
微信 使用 请求在队列中的平均等待时间 判断过载, 并且进行 分级分层细粒度 熔断降级策略。
降级保护的主流架构方案
在大规模分布式微服务应用中,主流的架构方案有
- 基于 Hystrix 熔断降级、限流降级 架构方案
- 基于 Sentinel 熔断降级、限流降级 架构方案
Hystrix 熔断降级、限流降级
Spring Cloud Hystrix 是一款优秀的服务容错与保护组件,也是 Spring Cloud 中最重要的组件之一。
Spring Cloud Hystrix 是基于 Netflix 公司的开源组件 Hystrix 实现的,它提供了熔断器功能,能够有效地阻止分布式微服务系统中出现联动故障,以提高微服务系统的弹性。
Spring Cloud Hystrix 具有服务降级、服务熔断、线程隔离、请求缓存、请求合并以及实时故障监控等强大功能。
Hystrix [hɪst’rɪks],中文含义是豪猪,豪猪的背上长满了棘刺,使它拥有了强大的自我保护能力。而 Spring Cloud Hystrix 作为一个服务容错与保护组件,也可以让服务拥有自我保护的能力,因此也有人将其戏称为“豪猪哥”。
熔断器(Circuit Breaker)一词来源物理学中的电路知识,它的作用是当线路出现故障时,迅速切断电源以保护电路的安全。
在微服务领域,熔断器最早是由 Martin Fowler 在他发表的 《Circuit Breaker》一文中提出。与物理学中的熔断器作用相似,微服务架构中的熔断器能够在某个服务发生故障后,向服务调用方返回一个符合预期的、可处理的降级响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常。这样就保证了服务调用方的线程不会被长时间、不必要地占用,避免故障在微服务系统中的蔓延,防止系统雪崩效应的发生。
hystrix通过命令模式,将每个请求封装成一个Command,每个类型的Command对应一个线程池 (例如商品服务Command)

请求过来,为请求创建Command
如果Command开启了缓存(配置的一个参数) ,会先向requestCache查询调用服务的结果,如果有直接返回
每个Command执行完会上报自己的执行结果状态给熔断器Circuit breaker,状态包括:成功,失败,超时,拒绝等,熔断器会统计这些数据, 来决定是否降级:
- 如果一个Command执行报错或者超时会直接做fallback降级处理
- 如果熔断器已经开启了,那么所有的请求都直接做降级处理
- 如果同一类型Command的线程池或信号量已经满了,再来的请求会直接做fallback降级
在微服务系统中,Hystrix 能够帮助我们实现以下目标:
- Hystrix 限流降级
- Hystrix 异常降级
- Hystrix 资源隔离降级
- Hystrix 熔断降级(过载保护)
Hystrix 限流降级
同样是A服务调用B服务,服务A的连接已超过自身能承载的最大连接数,比如说A能承载的连接数为5,但是目前的并发有6个请求同时进行,前5请求能正常请求,最后一个会直接拒绝,执行fallback降级逻辑;

Hystrix 支持线程池或者信号量限流, 只要线程池满,或者无限号,就进行限流降级,返回降级后的兜底结果。
hystrix可以使用信号量和线程池来进行限流。
线程池限流
hystrix也可以使用线程池进行限流,在提供服务的方法上加下面的注解
@HystrixCommand(
commandProperties = {
@HystrixProperty(name = "execution.isolation.strategy", value = "THREAD")
},
threadPoolKey = "createOrderThreadPool",
threadPoolProperties = {
@HystrixProperty(name = "coreSize", value = "20"),
@HystrixProperty(name = "maxQueueSize", value = "100"),
@HystrixProperty(name = "maximumSize", value = "30"),
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "120")
},
fallbackMethod = "errMethod"
)
这里要注意:queueSizeRejectionThreshold 建议大于 maxQueueSize
在java的线程池中,如果线程数量超过coreSize,创建线程请求会优先进入队列,如果队列满了,就会继续创建线程直到线程数量达到maximumSize,之后走拒绝策略。
但在hystrix配置的线程池中多了一个参数queueSizeRejectionThreshold,如果queueSizeRejectionThreshold < maxQueueSize,队列数量达到queueSizeRejectionThreshold就会走拒绝策略了,因此maximumSize失效了。
如果queueSizeRejectionThreshold > maxQueueSize,队列数量达到maxQueueSize时,maximumSize是有效的,系统会继续创建线程直到数量达到maximumSize。
信号量限流
hystrix可以使用信号量进行限流,比如在提供服务的方法上加下面的注解。
这样只能有20个并发线程来访问这个方法,超过的就被转到了errMethod这个降级方法。
@HystrixCommand(
commandProperties= {
@HystrixProperty(name="execution.isolation.strategy", value="SEMAPHORE"),
@HystrixProperty(name="execution.isolation.semaphore.maxConcurrentRequests", value="20")
},
fallbackMethod = "errMethod"
)
Hystrix 异常降级
hystrix降级时可以忽略某个异常,在方法上加上@HystrixCommand注解:
下面的代码定义降级方法是errMethod,对ParamErrorException和BusinessTypeException这两个异常不做降级处理。
@HystrixCommand(
fallbackMethod = "errMethod",
ignoreExceptions = {ParamErrorException.class, BusinessTypeException.class}
)
Hystrix 调用超时降级
专门针对调用第三方接口超时降级。
同样是A服务调用B服务,B服务响应超过了A服务设定的阈值后,就会执行降级逻辑;

下面的方法是调用第三方接口3秒未收到响应就降级到errMethod方法。
@HystrixCommand(
commandProperties = {
@HystrixProperty(name="execution.timeout.enabled", value="true"),
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds", value="3000"),
},
fallbackMethod = "errMethod"
)
Hystrix 资源隔离
前面讲到: 资源隔离相当于对不同的链路分级对待,对非核心链路,本质是一种降级处理。
Hystrix 里面核心的一项功能,其实就是所谓的资源隔离,要解决的最最核心的问题,就是将多个依赖服务的调用分别隔离到各自的资源池内。
一旦说某个服务的线程资源全部耗尽的话,就可能导致服务崩溃,甚至说这种故障会不断蔓延。Hystrix 资源隔离避免,就是对某一个依赖服务的调用,因为依赖服务的接口调用的延迟或者失败,导致服务所有的线程资源全部耗费在这个服务的接口调用上。
Hystrix 实现资源隔离,主要有两种技术:
- 线程池
- 信号量
默认情况下,Hystrix 使用线程池模式。
线程池隔离(舱壁模式)
线程池隔离,本质上来说,就是舱壁模式。
船舶工业上为了使船不容易沉没,使用舱壁将船舶划分为几个部分,以便在船体遭到破坏的情况下可以将船舶各个部件密封起来。
泰坦尼克号沉没的主要原因之一:就是其舱壁设计不合理,水可以通过上面的甲板进入舱壁的顶部,导致整个船体淹没。
在RPC调用过程中,使用舱壁模式可以保护有限的系统资源不被耗尽。
在一个基于微服务的应用程序中,通常需要调用多个微服务提供者的接口才能完成一个特定任务。不使用舱壁模式,所有的RPC调用都从同一个线程池中获取线程,一个具体的实例如图6-4所示。
在该实例中,微服务提供者Provider A对依赖Provider B、Provider C、Provider D的所有RPC调用都从公共的线程池中获取线程。
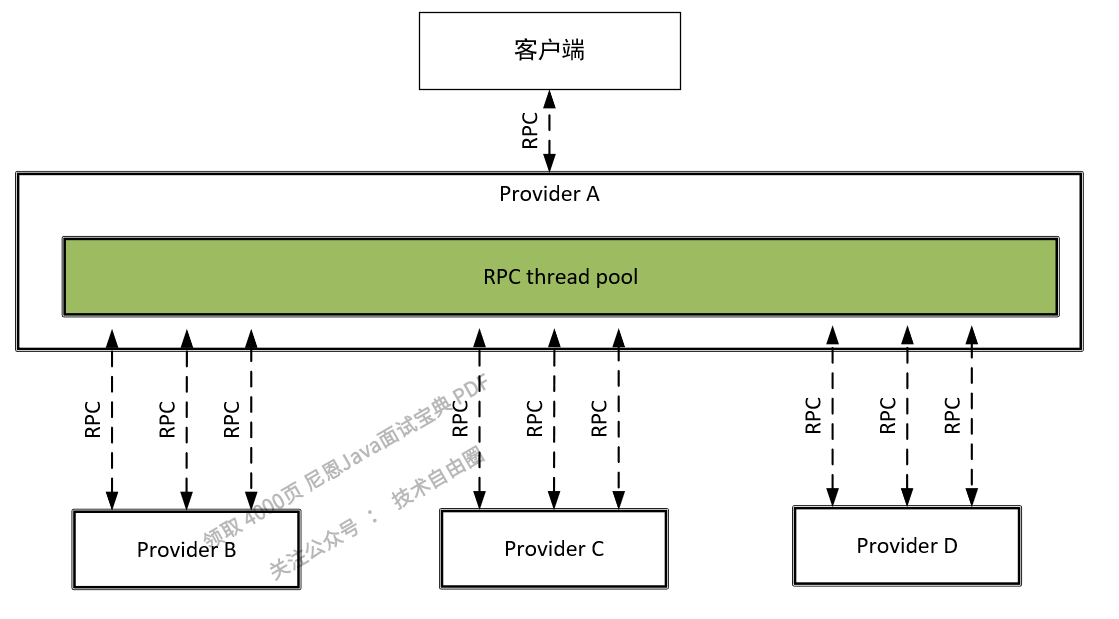
图6-4 公共的RPC线程池
在高服务器请求的情况下,对某个性能较低的微服务提供者的RPC调用很容易“霸占”整个公共的RPC线程池,对其他性能正常的微服务提供者的RPC调用往往需要等待线程资源的释放。最后,整个Web容器(Tomcat)会崩溃。现在假定Provider A的RPC线程个数为1000,而并发量非常大,其中有500个线程来执行Provider B的RPC调用,如果Provider B不小心宕机了,那么这500个线程都会超时,此时剩下的服务Provider C、Provider D的总共可用的线程为500个,随着并发量的增大,剩余的500个线程估计也会被Provider B的RPC耗尽,然后Provider A进入瘫痪,最后导致整个系统的所有服务都不可用,这就是服务的雪崩效应。
为了最大限度地减少Provider之间的相互影响,一个很好的做法是对于不同的微服务提供者设置不同的RPC调用线程池,让不同RPC通过专门的线程池请求到各自的Provider微服务提供者,像舱壁一样对Provider进行隔离。对于不同的微服务提供者设置不同的RPC调用线程池,这种模式就叫作舱壁模式,如图6-5所示。
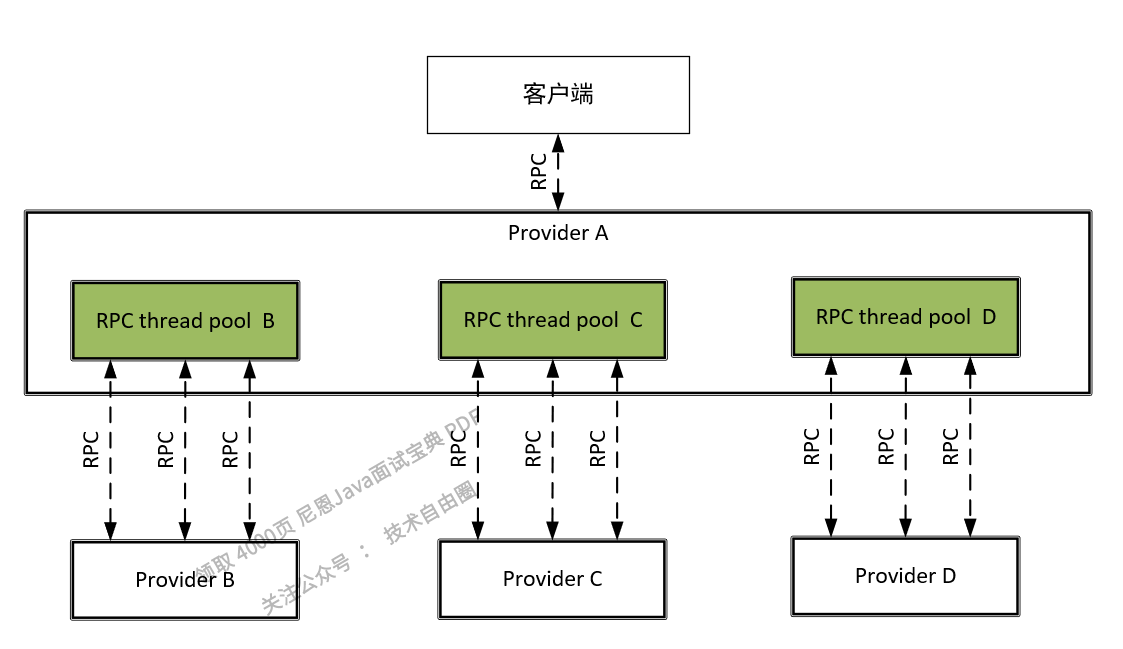
图6-5 舱壁模式的RPC线程池
使用舱壁模式可以避免对单个Provider的RPC消耗掉所有资源,从而防止由于某一个服务性能底而引起的级联故障和雪崩效应。在Provider A中,假定对服务Provider B的RPC调用分配专门的线程池,该线程池叫作Thread Pool B,其中有10个线程,只要对Provider B的RPC并发量超过了10,后续的RPC就走降级服务,就算服务的Provider B挂了,最多也就导致Thread Pool B不可用,而不会影响系统中的其他服务的RPC。
一般来说,RPC线程与Web容器的IO线程也是需要隔离的。
如图6-6所示,当Provider A的用户请求涉及Provider B和Provider C的RPC的时候,Provider A的IO线程会将任务交给对应的RPC线程池里面的RPC线程来执行,Provider A的IO线程就可以去干别的事情去了,当RPC线程执行完远程调用的任务之后,就会将调用的结果返回给IO线程。如果RPC线程池耗尽了,IO线程池也不会受到影响,从而实现RPC线程与Web容器的IO线程的相互隔离。
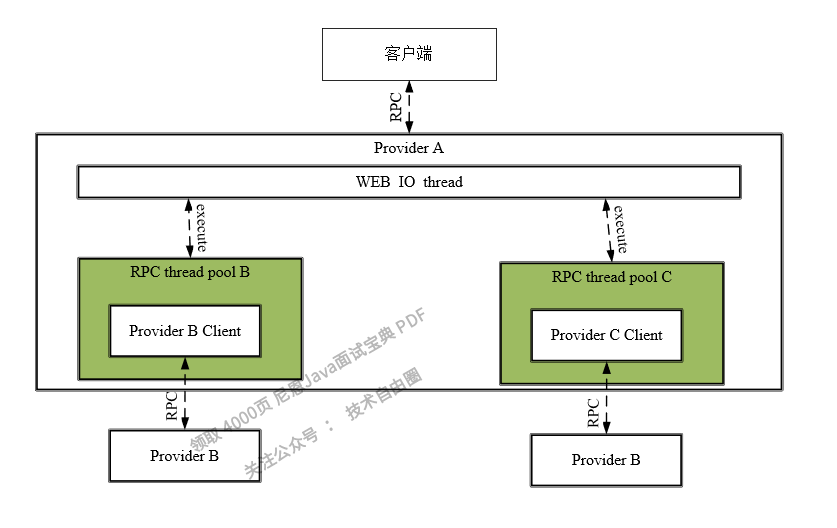
图6-6 RPC线程与Web容器的IO线程相互隔离
虽然线程在就绪状态、运行状态、阻塞状态、终止状态间转变时需要由操作系统调度,这会带来一定的性能消耗,但是Netflix详细评估了使用异步线程和同步线程带来的性能差异,结果表明在99%的情况下异步线程带来的延迟仅为几毫秒,这种性能的损耗对于用户程序来说是完全可以接受的。
Hystrix线程池隔离
Hystrix既可以为HystrixCommand命令默认创建一个线程池,也可以关联上一个指定的线程池。每一个线程池都有一个Key,叫作Thread Pool Key(线程池名)。
如果没有为HystrixCommand指定线程池,Hystrix会为HystrixCommand创建一个与Group Key(命令组Key)同名的线程池,当然,如果与Group Key同名的线程池已经存在,则直接进行关联。也就是说,默认情况下,HystrixCommand命令的Thread Pool Key与Group Key是相同的。
总体来说,线程池就是隔离的关键,所有的监控、调用、缓存等都围绕线程池展开。
如果要指定线程池,可以通过如下代码在Setter中定制线程池的Key和属性:
/**
*在Setter实例中指定线程池的Key和属性
*/
HystrixCommand.Setter rpcPool1_setter = HystrixCommand.Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey("group1"))
.andCommandKey(HystrixCommandKey.Factory.asKey("command1"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("threadPool1"))
.andThreadPoolPropertiesDefaults(
HystrixThreadPoolProperties.Setter()
.withCoreSize(10) //配置线程池里的线程数
.withMaximumSize(10)
);
然后,可以通过HystrixCommand或者HystrixObservableCommand的构造函数传入Setter配置 实例:
public class HttpGetterCommand extends HystrixCommand<String>
{
private String url;
...
public HttpGetterCommand(String url, Setter setter)
{
super(setter);
this.url = url;
}
...
}
HystrixThreadPoolKey是一个接口,它有一个辅助工厂类Factory,它的asKey(String)方法专门用于创建一个线程池的Key,示例代码如下:
HystrixThreadPoolKey.Factory.asKey("threadPoolN")
下面是一个完整的线程池隔离演示例子:创建了两个线程池threadPool1和threadPool2,然后通过这两个线程池发起简单的RPC远程调用,其中,通过threadPool1 线程池访问一个错误连接ERROR_URL,通过threadPool2访问一个正常连接HELLO_TEST_URL。在实验过程中,可以通过调整RPC的次数多次运行程序,然后通过结果查看线程池的具体隔离效果。
线程池隔离实例的代码如下:
package com.crazymaker.demo.hystrix;
//省略import
@Slf4j
public class IsolationStrategyDemo
{
/**
* 测试:线程池隔离
*/
@Test
public void testThreadPoolIsolationStrategy() throws Exception
{
/**
* RPC线程池1
*/
HystrixCommand.Setter rpcPool1_Setter = HystrixCommand.Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey("group1"))
.andCommandKey(HystrixCommandKey.Factory.asKey("command1"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("threadPool1"))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(5000) //配置执行时间上限
).andThreadPoolPropertiesDefaults(
HystrixThreadPoolProperties.Setter()
.withCoreSize(10) //配置线程池里的线程数
.withMaximumSize(10)
);
/**
* RPC线程池2
*/
HystrixCommand.Setter rpcPool2_Setter = HystrixCommand.Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey("group2"))
.andCommandKey(HystrixCommandKey.Factory.asKey("command2"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("threadPool2"))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(5000) //配置执行时间上限
).andThreadPoolPropertiesDefaults(
HystrixThreadPoolProperties.Setter()
.withCoreSize(10) //配置线程池里的线程数
.withMaximumSize(10)
);
/**
* 访问一个错误连接,让threadpool1 耗尽
*/
for (int j = 1; j <= 5; j++)
{
new HttpGetterCommand(ERROR_URL, rpcPool1_Setter)
.toObservable()
.subscribe(s -> log.info(" result:{}", s));
}
/**
* 访问一个正确连接,观察threadpool2是否正常
*/
for (int j = 1; j <= 5; j++)
{
new HttpGetterCommand(HELLO_TEST_URL, rpcPool2_Setter)
.toObservable()
.subscribe(s -> log.info(" result:{}", s));
}
Thread.sleep(Integer.MAX_VALUE);
}
}
运行这个演示程序,输出的结果节选如下:
[hystrix-threadPool1-4] INFO c.c.d.h.HttpGetterCommand - req1 begin...
[hystrix-threadPool1-3] INFO c.c.d.h.HttpGetterCommand - req4 begin...
[hystrix-threadPool2-3] INFO c.c.d.h.HttpGetterCommand - req10 begin...
[hystrix-threadPool2-5] INFO c.c.d.h.HttpGetterCommand - req7 begin...
[hystrix-threadPool1-5] INFO c.c.d.h.HttpGetterCommand - req9 begin...
[hystrix-threadPool2-1] INFO c.c.d.h.HttpGetterCommand - req6 begin...
[hystrix-threadPool1-1] INFO c.c.d.h.HttpGetterCommand - req8 begin...
[hystrix-threadPool1-2] INFO c.c.d.h.HttpGetterCommand - req2 begin...
[hystrix-threadPool2-4] INFO c.c.d.h.HttpGetterCommand - req5 begin...
[hystrix-threadPool2-2] INFO c.c.d.h.HttpGetterCommand - req3 begin...
[hystrix-threadPool1-1] INFO c.c.d.h.HttpGetterCommand - req8 fallback: 熔断false,直接失败false
[hystrix-threadPool1-4] INFO c.c.d.h.HttpGetterCommand - req1 fallback: 熔断false,直接失败false
[hystrix-threadPool1-2] INFO c.c.d.h.HttpGetterCommand - req2 fallback: 熔断false,直接失败false
[hystrix-threadPool1-3] INFO c.c.d.h.HttpGetterCommand - req4 fallback: 熔断false,直接失败false
[hystrix-threadPool1-5] INFO c.c.d.h.HttpGetterCommand - req9 fallback: 熔断false,直接失败false
...
[hystrix-threadPool2-4] INFO c.c.d.h.HttpGetterCommand - req5 end: {"respCode":0,"respMsg":"操作成功...}
[hystrix-threadPool2-2] INFO c.c.d.h.HttpGetterCommand - req3 end: {"respCode":0,"respMsg":"操作成功...}
[hystrix-threadPool2-3] INFO c.c.d.h.HttpGetterCommand - req10 end: {"respCode":0,"respMsg":"操作成功...}
[hystrix-threadPool2-1] INFO c.c.d.h.HttpGetterCommand - req6 end: {"respCode":0,"respMsg":"操作成功...}
[hystrix-threadPool2-5] INFO c.c.d.h.HttpGetterCommand - req7 end: {"respCode":0,"respMsg":"操作成功...}
...
从上面的结果可知:threadPool1的线程使用和threadPool2的线程使用是完全地相互独立和相互隔离的,无论threadPool1是否耗尽,threadPool2的线程都可以正常发起RPC请求。
默认情况下,在Spring Cloud中,Hystrix会为每一个Command Group Key(命令组Key)自动创建一个同名的线程池。
而在Hystrix客户端,每一个RPC目标Provider的Command Group Key(命令组Key)的默认值为它的应用名称(application name)。
比如,demo-provider服务的Command Group Key默认值为其名称“demo-provider”。
所以,如果某个Provider(如uaa-provider)需发起对demo-Provider的远程调用,则Hystrix为该Provider创建的RPC线程池的名称默认为“demo-provider”,专用于对demo-provider的REST服务进行RPC调用和隔离,如图6-7所示。
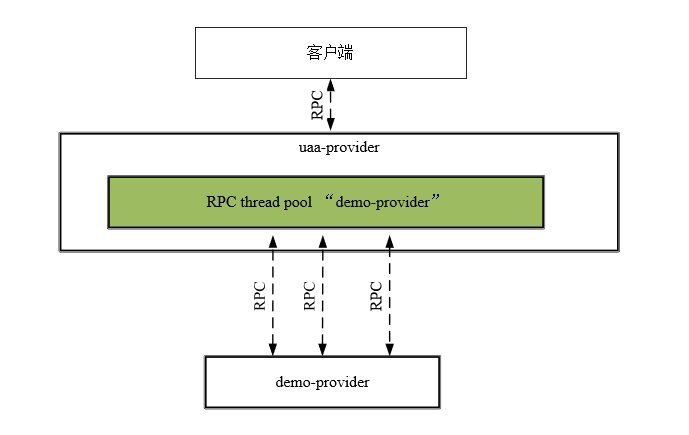
图6-7 对demo-provider服务进行RPC调用的专用线程池
Hystrix线程池隔离配置
在Spring Cloud微服务提供者中,如果需使用Hystrix线程池进行RPC隔离,可以在应用配置文件中进行相应配置。下面是demo-provider的RPC线程池配置的实例:
hystrix:
threadpool:
default:
coreSize: 10 # 线程池核心线程数
maximumSize: 20 # 线程池最大线程数
allowMaximumSizeToDivergeFromCoreSize: true # 线程池maximumSize最大线程数是否生效
keepAliveTimeMinutes:10 # 设置可空闲时间,单位为分钟
command:
default: #全局默认配置
execution: #RPC隔离的相关配置
isolation:
strategy: THREAD #配置请求隔离的方式,这里采用线程池方式
thread:
timeoutInMilliseconds: 100000 #RPC执行的超时时间,默认为1000毫秒
interruptOnTimeout: true #发生超时后是否中断方法的执行,默认值为true
对上面实例中用到的与Hystrix线程池有关的配置项介绍如下:
(1)hystrix.threadpool.default.coreSize
设值线程池的核心线程数。
(2)hystrix.threadpool.default.maximumSize
设值线程池的最大线程数,起作用的前提是allowMaximumSizeToDrivergeFromCoreSize的属性值为true。maximumSize属性值可以等于或者大于coreSize值,当线程池的线程不够用时,Hystrix会创建新的线程,直到线程数达到maximumSize的值,创建的线程为非核心线程。
(3)hystrix.threadpool.default.allowMaximumSizeToDivergeFromCoreSize
该属性允许maximumSize起作用。
(4)hystrix.threadpool.default.keepAliveTimeMinutes
该属性设置非核心线程的存活时间,如果某个非核心线程的空闲时间超过keepAliveTimeMinutes设置的时间,非核心线程将被释放。其单位为分钟,默认值为1,默认情况下非核心线程空闲1分钟后释放。
(5)hystrix.command.default.execution.isolation.strategy
该属性设置完成RPC远程调用HystrixCommand命令的隔离策略。它有两个可选值:THREAD、SEMAPHORE,默认值为THREAD。THREAD表示使用线程池进行RPC隔离,SEMAPHORE表示通过信号量来进行RPC隔离和限制并发量。
(6)hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds
设置调用者等待HystrixCommand命令执行的超时限制,超过此时间,HystrixCommand被标记为TIMEOUT,并执行回退逻辑。超时会作用在HystrixCommand.queue(),即使调用者没有调用get()去获得Future对象。
以上的配置是application应用级别的默认线程池配置,覆盖的范围为系统中的所有RPC线程池。有时,需要为特定的Provider微服务提供者做特殊的配置,比如当某一个Provider的接口访问的并发量非常大,是其他Provider的几十倍时,则其远程调用需要更多的RPC线程,这时候,可以单独为它进行专门的RPC线程池配置。作为示例,在demo-Provider中对uaa-provider的RPC线程池配置如下:
hystrix:
threadpool:
default:
coreSize: 10 # 线程池核心线程数
maximumSize: 20 # 线程池最大线程数
allowMaximumSizeToDivergeFromCoreSize: true # 线程池最大线程数是否有效
uaa-provider:
coreSize: 20 # 线程池核心线程数
maximumSize: 100 # 线程池最大线程数
allowMaximumSizeToDivergeFromCoreSize: true # 线程池最大线程数是否有效
上面的配置中使用了hystrix.threadpool.uaa-provider配置项前缀,其中uaa-provider部分为RPC线程池的Thread Pool Key(线程池名称),也就是默认的Command Group Key(命令组名)。
在调用处理器HystrixInvocationHandler的invoke(…)方法内打上断点,在调试时,通过查看hystrixCommand对象的值可以看出,demo-provider中针对微服务提供者uaa-provider的RPC线程池配置已经生效,如图6-8所示。
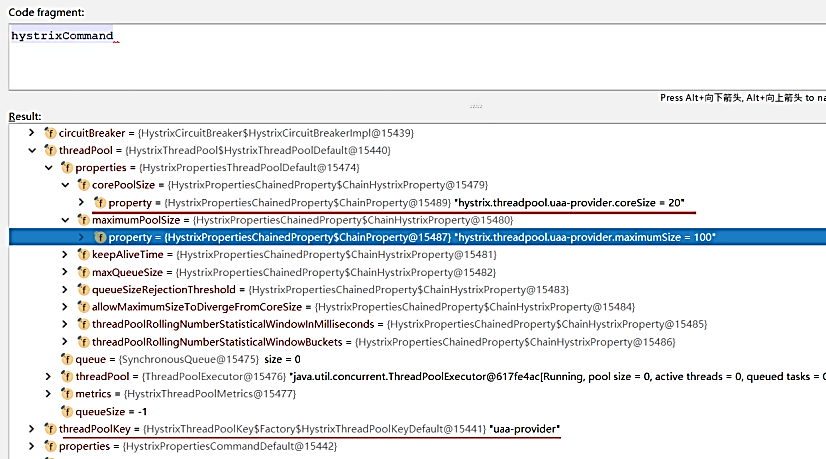
图6-8 针对uaa-provider的RPC线程池配置已经生效
Hystrix信号量隔离
除了使用线程池进行资源隔离之外,Hystrix还可以使用信号量机制完成资源隔离。信号量所起到的作用就像一个开关,而信号量的值就是每个命令的并发执行数量,当并发数高于信号量的值时,就不再执行命令。
比如,如果Provider A的RPC信号量大小为10,那么它同时只允许有10个RPC线程来访问Provider A,其他的请求都会被拒绝,从而达到资源隔离和限流保护的作用。
Hystrix信号量机制不提供专用的线程池,也不提供额外的线程,在获取信号量之后,执行HystrixCommand命令逻辑的线程还是之前Web容器的IO线程。
信号量可以细分为run执行信号量和fallback回退信号量。
IO线程在执行HystrixCommand命令之前,需要抢到run执行信号量,成功之后才允许执行HystrixCommand.run()方法。如果争抢失败,就准备回退,但是在执行HystrixCommand.getFallback()回退方法之前,还需要争抢fallback回退信号量,成功之后才允许执行HystrixCommand.getFallback()回退方法。如果都获取失败,则操作直接终止。
在如图6-9所示的例子中,假设有5个Web容器的IO线程并发进行RPC远程调用,但是执行信号量的大小为3,也就是只有3个IO线程能够真正地抢到run执行信号量,争抢成功后这些线程才能发起RPC调用。剩下的2个IO线程准备回退,去抢fallback回退信号量,争抢成功后执行HystrixCommand.getFallback()回退方法。
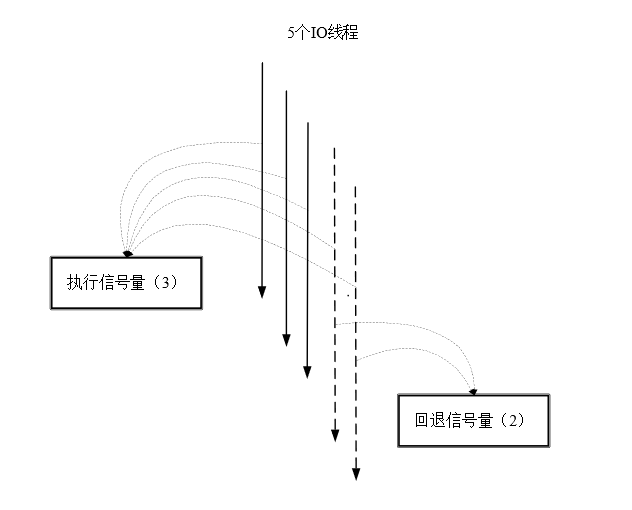
图6-9 5个Web容器的IO线程争抢信号量
下面是一个模拟Web容器进行RPC调用的演示程序,使用一个拥有50个线程的线程池模拟Web容器的IO线程池,并使用随书编写的HttpGetterCommand命令模拟RPC调用。实验之前,需要提前启动的demo-provider服务的REST接口/api/demo/hello/v1。
为了演示信号量隔离,演示程序所设置的run执行信号量和fallback回退信号量都为4,并且通过IO线程池同时提交了50个模拟的RPC调用去争抢这些信号量,具体的演示程序如下:
package com.crazymaker.demo.hystrix;
//省略import
@Slf4j
public class IsolationStrategyDemo
{
/**
* 测试: 信号量隔离
*/
@Test
public void testSemaphoreIsolationStrategy() throws Exception
{
/**
*命令属性实例
*/
HystrixCommandProperties.Setter commandProperties = HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(5000) //配置时间上限
.withExecutionIsolationStrategy(
//隔离策略为信号量隔离
HystrixCommandProperties.ExecutionIsolationStrategy.SEMAPHORE
)
//HystrixCommand.run()方法允许的最大请求数
.withExecutionIsolationSemaphoreMaxConcurrentRequests(4)
//HystrixCommand.getFallback()方法允许的最大请求数
.withFallbackIsolationSemaphoreMaxConcurrentRequests(4);
/**
* 命令的配置实例
*/
HystrixCommand.Setter setter = HystrixCommand.Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey("group1"))
.andCommandKey(HystrixCommandKey.Factory.asKey("command1"))
.andCommandPropertiesDefaults(commandProperties);
/**
* 模拟Web容器的IO线程池
*/
ExecutorService mock_IO_threadPool = Executors.newFixedThreadPool(50);
/**
* 模拟Web容器的并发50
*/
for (int j = 1; j <= 50; j++)
{
mock_IO_threadPool.submit(() ->
{
/**
* RPC调用
*/
new HttpGetterCommand(HELLO_TEST_URL, setter)
.toObservable()
.subscribe(s -> log.info(" result:{}", s));
});
}
Thread.sleep(Integer.MAX_VALUE);
}
}
在执行此演示程序之前,需要启动crazydemo.com(指向127.0.0.1)主机上的demo-provider微服务提供者。demo-provider启动之后,再执行上面的演示程序,运行的结果节选如下:
[pool-2-thread-35] INFO c.c.d.h.HttpGetterCommand - req3 fallback: 熔断false,直接失败true,失败次数3
[pool-2-thread-45] INFO c.c.d.h.HttpGetterCommand - req4 fallback: 熔断false,直接失败true,失败次数4
[pool-2-thread-7] INFO c.c.d.h.HttpGetterCommand - req2 fallback: 熔断false,直接失败true,失败次数2
[pool-2-thread-15] INFO c.c.d.h.HttpGetterCommand - req1 fallback: 熔断false,直接失败true,失败次数1
[pool-2-thread-35] INFO c.c.d.h.IsolationStrategyDemo - result:req3:调用失败
...
[pool-2-thread-27] INFO c.c.d.h.HttpGetterCommand - req7 begin...
[pool-2-thread-18] INFO c.c.d.h.HttpGetterCommand - req6 begin...
[pool-2-thread-13] INFO c.c.d.h.HttpGetterCommand - req5 begin...
[pool-2-thread-48] INFO c.c.d.h.HttpGetterCommand - req8 begin...
[pool-2-thread-18] INFO c.c.d.h.HttpGetterCommand - req6 end: {"respCode":0,"respMsg":"操作成功...}
[pool-2-thread-48] INFO c.c.d.h.HttpGetterCommand - req8 end: {"respCode":0,"respMsg":"操作成功...}
[pool-2-thread-27] INFO c.c.d.h.HttpGetterCommand - req7 end: {"respCode":0,"respMsg":"操作成功...}
[pool-2-thread-13] INFO c.c.d.h.HttpGetterCommand - req5 end: {"respCode":0,"respMsg":"操作成功...}
[pool-2-thread-13] INFO c.c.d.h.IsolationStrategyDemo - result:req5:{"respCode":0,"respMsg":"操作成...}
...
通过结果可以看出:
1)执行RPC远程调用的线程就是模拟IO线程池中的线程。
2)虽然提交了50个RPC调用,但是只有4个RPC调用抢到了执行信号量,分别为req5、req6、req7、req8。
3)虽然失败了46个RPC调用,但是只有4个RPC调用抢到了回退信号量,分别为req1、req2、req3、req4。
使用信号量进行RPC隔离时,是有自身弱点的。由于最终Web容器的IO线程完成实际RPC远程调用,这样就带来了一个问题:由于RPC远程调用是一种耗时的操作,如果IO线程被长时间占用,将导致Web容器请求处理能力下降,甚至可能会在一段时间内由于IO线程被占满而造成Web容器无法对新的用户请求及时响应,最终导致Web容器崩溃。因此,信号量隔离机制不适用于RPC隔离。但是,对于一些非网络的API调用或者耗时很小的API调用,信号量隔离机制比线程池隔离机制的效率更高。
再来看信号量的配置,这一次使用代码的方式进行命令属性配置,涉及Hystrix命令属性配置器HystrixCommandProperties.Setter()的以下实例方法:
(1)withExecutionIsolationSemaphoreMaxConcurrentRequests(int)
此方法设置使用执行信号量的大小,也就是HystrixCommand.run()方法允许的最大请求数。如果达到最大请求数,则后续的请求会被拒绝。
在Web容器中,抢占信号量的线程应该是容器(比如Tomcat)IO线程池的一小部分,所以信号量的数量不能大于容器线程池大小,否则起不到保护作用。执行信号量大小的默认值为10。
如果使用属性配置而不是代码方式进行配置,则以上代码配置所对应的配置项为:
hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests
(2)withFallbackIsolationSemaphoreMaxConcurrentRequests(int)
此方法设置使用回退信号量的大小,也就是HystrixCommand.getFallback()方法允许的最大请求数。如果达到最大请求数,则后续的回退请求会被拒绝。
如果使用属性配置而不是代码方式进行配置,则以上代码配置所对应的配置项为:
hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests
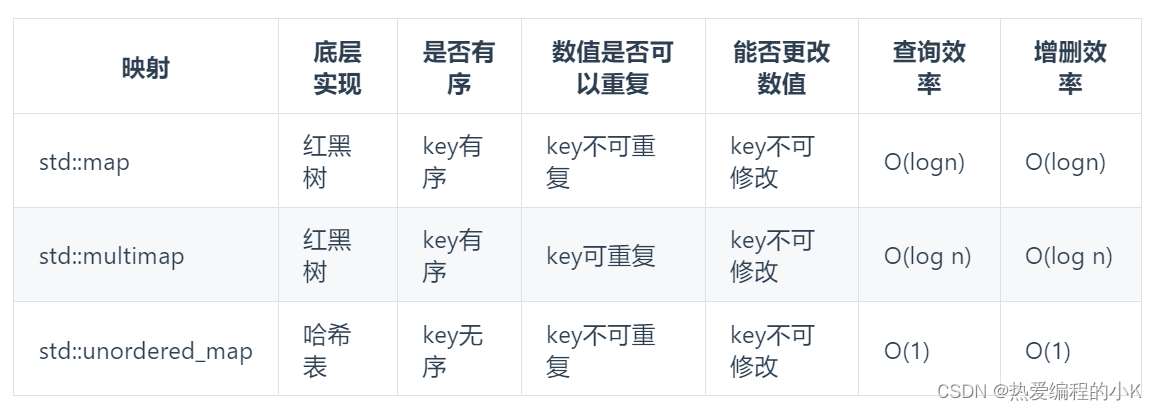
线程池与信号量区别
最后,介绍一下信号量隔离与线程池隔离的区别,分别从调用线程、开销、异步、并发量4个维度进行对比,具体如表6-1所示。
表6-1 调用线程、开销、异步、并发量4个维度的对比
| 线程池隔离 | 信号量隔离 | |
|---|---|---|
| 调用线程 | RPC线程与Web容器IO线程相互隔离 | RPC线程与Web容器IO线程相同 |
| 开销 | 存在请求排队、线程调度、线程上下文切换等开销 | 无线程切换,开销低 |
| 异步 | 支持 | 不支持 |
| 并发量 | 最大线程池大小 | 最大信号量上限,且最大信号量需要小于IO线程数 |
适用场景:
- 线程池技术,适合绝大多数场景,比如说我们对依赖服务的网络请求的调用和访问、需要对调用的 timeout 进行控制(捕捉 timeout 超时异常)。
- 信号量技术,适合不是对外部依赖的访问,而是对内部的一些比较复杂的业务逻辑的访问,并且系统内部的代码,其实不涉及任何的网络请求,那么只要做信号量的普通限流就可以了,因为不需要去捕获 timeout 类似的问题。
Hystrix 熔断降级(过载保护)
熔断器的工作机制为:统计最近RPC调用发生错误的次数,然后根据统计值中的失败比例等信息,决定是否允许后面的RPC调用继续,或者快速地失败回退。
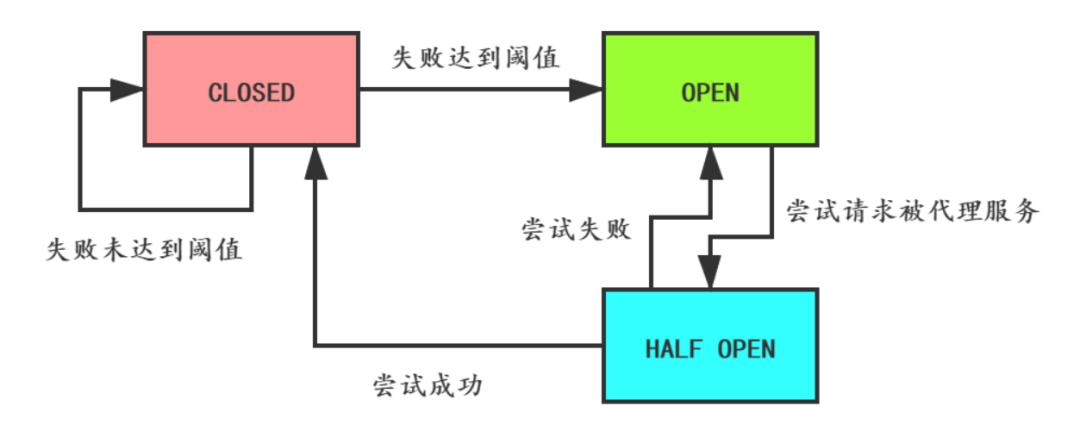
熔断器的3种状态如下:
1)closed:熔断器关闭状态,这也是熔断器的初始状态,此状态下RPC调用正常放行。
2)open:失败比例到一定的阈值之后,熔断器进入开启状态,此状态下RPC将会快速失败,执行失败回退逻辑。
3)half-open:在打开一定时间之后(睡眠窗口结束),熔断器进入半开启状态,小流量尝试进行RPC调用放行。如果尝试成功则熔断器变为closed状态,RPC调用正常;如果尝试失败则熔断器变为open状态,RPC调用快速失败。
断路器有3种状态:
- CLOSED:默认状态。
断路器观察到请求失败比例没有达到阈值,断路器认为被代理服务状态良好。
- OPEN:
断路器观察到请求失败比例已经达到阈值,断路器认为被代理服务故障,打开开关,请求不再到达被代理的服务,而是快速失败。
- HALF-OPEN:
断路器打开后,为了能自动恢复对被代理服务的访问,会切换到HALF-OPEN半开放状态,去尝试请求被代理服务以查看服务是否已经故障恢复。如果成功,会转成CLOSED状态,否则转到OPEN状态。
断路器的状态切换图如下:
Hystrix 实现熔断机制
在 Spring Cloud 中,熔断机制是通过 Hystrix 实现的。
Hystrix 会监控微服务间调用的状况,当失败调用到一定比例时(例如 5 秒内失败 20 次),就会启动熔断机制。
Hystrix 实现服务熔断的步骤如下:
- 当服务的调用出错率达到或超过 Hystix 规定的比率(默认为 50%)后,熔断器进入熔断开启状态。
- 熔断器进入熔断开启状态后,Hystrix 会启动一个休眠时间窗,在这个时间窗内,该服务的降级逻辑会临时充当业务主逻辑,而原来的业务主逻辑不可用。
- 当有请求再次调用该服务时,会直接调用降级逻辑快速地返回失败响应,以避免系统雪崩。
- 当休眠时间窗到期后,Hystrix 会进入半熔断转态,允许部分请求对服务原来的主业务逻辑进行调用,并监控其调用成功率。
- 如果调用成功率达到预期,则说明服务已恢复正常,Hystrix 进入熔断关闭状态,服务原来的主业务逻辑恢复;否则 Hystrix 重新进入熔断开启状态,休眠时间窗口重新计时,继续重复第 2 到第 5 步。
熔断器状态之间相互转换的逻辑关系如图6-10所示。
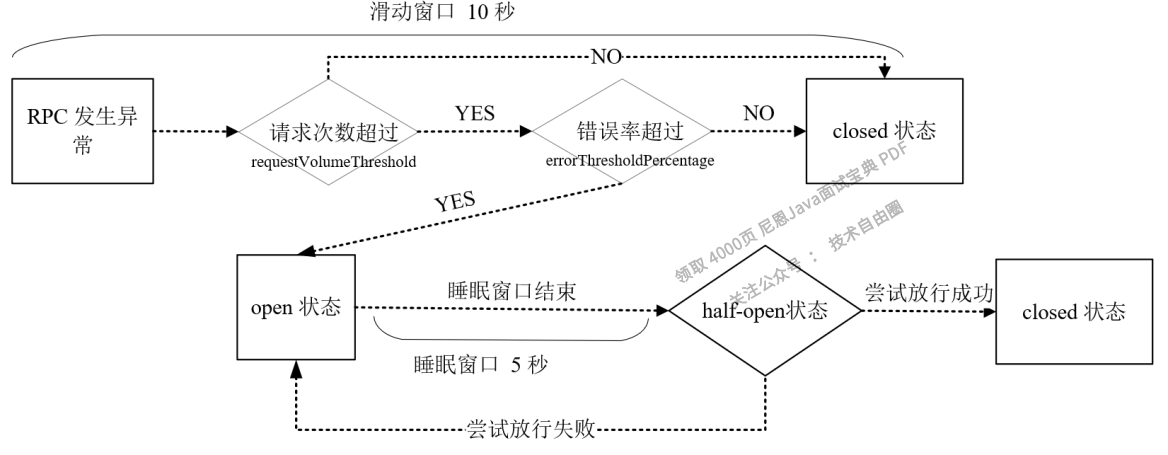
图6-10 熔断器状态之间的转换关系详细图
涉及到了 4 个与 Hystrix 熔断机制相关的重要参数,这 4 个参数的含义如下表。
| 参数 | 描述 |
|---|---|
| metrics.rollingStats.timeInMilliseconds | 统计时间窗。 |
| circuitBreaker.sleepWindowInMilliseconds | 休眠时间窗,熔断开启状态持续一段时间后,熔断器会自动进入半熔断状态,这段时间就被称为休眠窗口期。 |
| circuitBreaker.requestVolumeThreshold | 请求总数阀值。 在统计时间窗内,请求总数必须到达一定的数量级,Hystrix 才可能会将熔断器打开进入熔断开启转态,而这个请求数量级就是 请求总数阀值。Hystrix 请求总数阈值默认为 20,这就意味着在统计时间窗内,如果服务调用次数不足 20 次,即使所有的请求都调用出错,熔断器也不会打开。 |
| circuitBreaker.errorThresholdPercentage | 错误百分比阈值。 当请求总数在统计时间窗内超过了请求总数阀值,且请求调用出错率超过一定的比例,熔断器才会打开进入熔断开启转态,而这个比例就是错误百分比阈值。错误百分比阈值设置为 50,就表示错误百分比为 50%,如果服务发生了 30 次调用,其中有 15 次发生了错误,即超过了 50% 的错误百分比,这时候将熔断器就会打开。 |
熔断器状态变化的演示实例
为了观察熔断器的状态变化,通过继承HystrixCommand类,这里特别设计了一个能够设置运行时长的自定义命令类TakeTimeDemoCommand,通过设置其运行占用时间takeTime成员的值,可以控制其运行过程中是否超时。
演示实例的代码如下:
package com.crazymaker.demo.hystrix;
//省略import
@Slf4j
public class CircuitBreakerDemo
{
//执行的总次数,线程安全
private static AtomicInteger total = new AtomicInteger(0);
/**
* 内部类:一个能够设置运行时长的自定义命令类
*/
static class TakeTimeDemoCommand extends HystrixCommand<String>
{
//run方法是否执行
private boolean hasRun = false;
//执行的次序
private int index;
//运行的占用时间
long takeTime;
public TakeTimeDemoCommand(long takeTime, Setter setter)
{
super(setter);
this.takeTime = takeTime;
}
@Override
protected String run() throws Exception
{
hasRun = true;
index = total.incrementAndGet();
Thread.sleep(takeTime);
HystrixCommandMetrics.HealthCounts hc = super.getMetrics().getHealthCounts();
log.info("succeed- req{}:熔断器状态:{}, 失败率:{}%",
index, super.isCircuitBreakerOpen(), hc.getErrorPercentage());
return "req" + index + ":succeed";
}
@Override
protected String getFallback()
{
//是否直接失败
boolean isFastFall = !hasRun;
if (isFastFall)
{
index = total.incrementAndGet();
}
HystrixCommandMetrics.HealthCounts hc = super.getMetrics().getHealthCounts();
log.info("fallback- req{}:熔断器状态:{}, 失败率:{}%",
index, super.isCircuitBreakerOpen(), hc.getErrorPercentage());
return "req" + index + ":failed";
}
}
/**
* 测试用例:熔断器熔断
*/
@Test
public void testCircuitBreaker() throws Exception
{
/**
* 命令参数配置
*/
HystrixCommandProperties.Setter propertiesSetter =
HystrixCommandProperties.Setter()
//至少有3个请求, 熔断器才达到熔断触发的次数阈值
.withCircuitBreakerRequestVolumeThreshold(3)
//熔断器中断请求5秒后会进入half-open状态, 尝试放行
.withCircuitBreakerSleepWindowInMilliseconds(5000)
//错误率超过60%,快速失败
.withCircuitBreakerErrorThresholdPercentage(60)
//启用超时
.withExecutionTimeoutEnabled(true)
//执行的超时时间,默认为 1000毫秒,这里设置为500毫秒
.withExecutionTimeoutInMilliseconds(500)
//可统计的滑动窗口内的buckets数量,用于熔断器和指标发布
.withMetricsRollingStatisticalWindowBuckets(10)
//可统计的滑动窗口的时间长度
//这段时间内的执行数据用于熔断器和指标发布
.withMetricsRollingStatisticalWindowInMilliseconds(10000);
HystrixCommand.Setter rpcPool = HystrixCommand.Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey("group-1"))
.andCommandKey(HystrixCommandKey.Factory.asKey("command-1"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("threadPool-1"))
.andCommandPropertiesDefaults(propertiesSetter);
/**
* 首先设置运行时间为800毫秒,大于命令的超时限制500毫秒
*/
long takeTime = 800;
for (int i = 1; i <= 10; i++)
{
TakeTimeDemoCommand command = new TakeTimeDemoCommand(takeTime, rpcPool);
command.execute();
//健康信息
HystrixCommandMetrics.HealthCounts hc = command.getMetrics().getHealthCounts();
if (command.isCircuitBreakerOpen())
{
/**
* 熔断之后,设置运行时间为300毫秒,小于命令的超时限制 500毫秒
*/
takeTime = 300;
log.info("============ 熔断器打开了,等待休眠期(默认5秒)结束");
/**
* 等待7秒之后,再一次发起请求
*/
Thread.sleep(7000);
}
}
Thread.sleep(Integer.MAX_VALUE);
}
}
在上面的演示中,有以下配置器的配置命令需要重点说明:
1)通过withExecutionTimeoutInMilliseconds(int)方法将默认为1000毫秒的执行超时上限设置为 500毫秒,也就是说,只要TakeTimeDemoCommand.run()的执行超过500毫秒就会触发Hystrix超时回退。
2)通过withCircuitBreakerRequestVolumeThreshold(int)方法将熔断器触发熔断的最少请求次数的默认值20次改为了3次,这样更容易测试。
3)通过withCircuitBreakerErrorThresholdPercentage(int)方法设置错误率阈值百分比的值为 60,滑动窗口时间内当错误率超过此值时,熔断器进入open开启状态,所有请求都会触发失败回退(fallback),错误率阈值百分比的默认值为50。
执行上面的演示实例,运行的结果节选如下:
[HystrixTimer-1] INFO c.c.d.h.CircuitBreakerDemo - fallback- req1:熔断器状态:false, 失败率:0%
[HystrixTimer-1] INFO c.c.d.h.CircuitBreakerDemo - fallback- req2:熔断器状态:false, 失败率:100%
[HystrixTimer-2] INFO c.c.d.h.CircuitBreakerDemo - fallback- req3:熔断器状态:false, 失败率:100%
[HystrixTimer-1] INFO c.c.d.h.CircuitBreakerDemo - fallback- req4:熔断器状态:true, 失败率:100%
[main] INFO c.c.d.h.CircuitBreakerDemo - ============ 熔断器打开了,等待休眠期(默认5秒)结束
[hystrix-threadPool-1-5] INFO c.c.d.h.CircuitBreakerDemo - succeed- req5:熔断器状态:true, 失败率:100%
[hystrix-threadPool-1-6] INFO c.c.d.h.CircuitBreakerDemo - succeed- req6:熔断器状态:false, 失败率:0%
[hystrix-threadPool-1-7] INFO c.c.d.h.CircuitBreakerDemo - succeed- req7:熔断器状态:false, 失败率:0%
[hystrix-threadPool-1-8] INFO c.c.d.h.CircuitBreakerDemo - succeed- req8:熔断器状态:false, 失败率:0%
[hystrix-threadPool-1-9] INFO c.c.d.h.CircuitBreakerDemo - succeed- req9:熔断器状态:false, 失败率:0%
[hystrix-threadPool-1-10] INFO c.c.d.h.CircuitBreakerDemo - succeed- req10:熔断器状态:false, 失败率:0%
从上面的执行结果可知,在第四次请求req4 时,熔断器才达到熔断触发的次数阈值3,由于前3次皆为超时失败,失败率大于阈值60%,因此第四次请求执行之后,熔断器状态为open熔断状态。
在命令的熔断器打开后,熔断器默认会有5秒的睡眠等待时间,在这段时间内的所有请求直接执行回退方法;5秒之后,熔断器会进入half-open状态, 尝试放行一次命令执行,如果成功则关闭熔断器,状态转成closed,否则,熔断器回到open状态。
在上面的程序中,在熔断器熔断之后,演示程序将命令的运行时间takeTime改成了300毫秒,小于命令的超时限制500毫秒。在等待7秒之后,演示程序再一次发起请求,从运行结果可以看到,第5次请求req5 执行成功了,这是一次half-open状态的尝试放行,请求成功之后,熔断器的状态转成了open,后续请求将继续放行。注意,演示程序第5次请求req5后的熔断器状态值反映在第6次请求req6的执行输出中。
熔断器和滑动窗口的配置属性
熔断器的配置包含了滑动窗口的配置和熔断器自身的配置。
Hystrix的健康统计是通过滑动窗口来完成的,其熔断器的状态也是依据滑动窗口的统计数据来变化的,所以这里先介绍滑动窗口的配置。
先看看两个概念:滑动窗口和时间桶。
1. 滑动窗口
可以这么来理解滑动窗口:一位乘客坐在正在行驶的列车的靠窗座位上,列车行驶的公路两侧种着一排挺拔的白杨树,随着列车的前进,路边的白杨树迅速从窗口滑过,我们用每棵树来代表一个请求,用列车的行驶代表时间的流逝,那么,列车上的这个窗口就是一个典型的滑动窗口,这个乘客能通过窗口看到的白杨树的数量,就是滑动窗口要统计的数据。
2. 时间桶
时间桶是统计滑动窗口数据时的最小单位。同样类比列车窗口,在列车速度非常快时,如果每掠过一棵树就统计一次窗口内树的数据,显然开销非常大,如果乘客将窗口分成N份,前进行时列车每掠过窗口的N分之一就统计一次数据,开销就大大地减小了。简单来说,时间桶也就是滑动窗口的N分之一。
代码方式下熔断器的设置可以使用HystrixCommandProperties.Setter()配置器来完成,参考6.5.1节的实例,把自定义的TakeTimeDemoCommand中Setter()配置器的相关参数配置如下:
/**
* 命令参数配置
*/
HystrixCommandProperties.Setter propertiesSetter =
HystrixCommandProperties.Setter()
//至少有3个请求, 熔断器才达到熔断触发的次数阈值
.withCircuitBreakerRequestVolumeThreshold(3)
//熔断器中断请求5秒后会进入half-open状态,进行尝试放行
.withCircuitBreakerSleepWindowInMilliseconds(5000)
//错误率超过60%,快速失败
.withCircuitBreakerErrorThresholdPercentage(60)
//启用超时
.withExecutionTimeoutEnabled(true)
//执行的超时时间,默认为 1000毫秒,这里设置为500毫秒
.withExecutionTimeoutInMilliseconds(500)
//可统计的滑动窗口内的buckets数量,用于熔断器和指标发布
.withMetricsRollingStatisticalWindowBuckets(10)
//可统计的滑动窗口的时间长度
//这段时间内的执行数据用于熔断器和指标发布
.withMetricsRollingStatisticalWindowInMilliseconds(10000);
在以上配置中,与熔断器的滑动窗口相关的配置的具体含义为:
1)滑动窗口中,最少3个请求才会触发断路,默认值为20个。
2)错误率达到60%时才可能触发断路,默认值为50%。
3)断路之后的5000毫秒内,所有请求都直接调用getFallback()进行回退降级,不会调用run()方法;5000毫秒过后,熔断器变为half-open状态。
以上TakeTimeDemoCommand的熔断器滑动窗口的状态转换关系如图6-11所示。
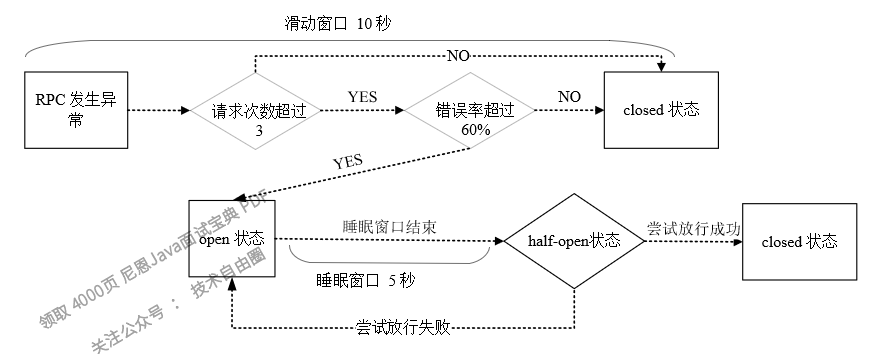
图6-11 TakeTimeDemoCommand的熔断器健康统计滑动窗口的状态转换关系图
大家已经知道,Hystrix熔断器的配置除了代码方式,还有properties文本属性配置的方式;
另外Hystrix熔断器相关的滑动窗口不止一个基础的健康统计滑动窗口,还包含一个百分比命令执行时间统计滑动窗口,两个窗口都可以进行配置。
下面以文本属性配置方式为主,详细介绍Hystrix基础健康统计滑动窗口的配置:
(1)hystrix.command.default.metrics.rollingStats.timeInMilliseconds
设置健康统计滑动窗口的持续时间(以毫秒为单位),默认值为 10000 毫秒。熔断器的状态会根据滑动窗口的统计值来计算,若滑动窗口时间内的错误率超过阈值,熔断器将进入open开启状态,滑动窗口将被进一步细分为时间桶,滑动窗口的统计值等于窗口内所有时间桶的统计信息的累加,每个时间桶的统计信息包含请求的成功(success)、失败(failure)、超时(timeout)、被拒(rejection)的次数。
此选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withMetricsRollingStatisticalWindowInMilliseconds(int)
(2)hystrix.command.default.metrics.rollingStats.numBuckets
设置健康统计滑动窗口被划分为时间桶的数量,默认值为10。若滑动窗口的持续时间为默认的10000毫秒,则一个时间桶(bucket)的时间即1秒。如果要做定制化的配置,则所设置的numBuckets(时间桶数量)值和timeInMilliseconds(滑动窗口时长)值有关联关系,必须符合timeInMilliseconds % numberBuckets == 0的规则,否则会抛出异常。例如二者的关联关系为70000(滑动窗口70秒)% 700(桶数)0是可以的,但是70000(70秒)% 600(桶数) 400将抛出异常。
此选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withMetricsRollingStatisticalWindowBuckets (int)
(3)hystrix.command.default.metrics.healthSnapshot.intervalInMilliseconds
设置健康统计滑动窗口拍摄运行状况统计指标的快照的时间间隔。什么是拍摄运行状况统计指标的快照呢?就是计算成功和错误百分比这些影响熔断器状态的统计数据。
拍摄快照的时间间隔的单位为毫秒,默认值为 500 毫秒。由于统计指标的计算是一个耗CPU的操作(CPU密集型操作),也就是说,高频率地计算错误百分比等健康统计数据会占用很多CPU资源,所以,在高并发RPC流量大的场景下,可以适当调大拍摄快照的时间间隔。
此选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withMetricsHealthSnapshotIntervalInMilliseconds (int)
Hystrix熔断器相关的滑动窗口不止一个基础的健康统计滑动窗口,还包含一个“百分比命令执行时间”统计滑动窗口。什么是“百分比命令执行时间”统计滑动窗口呢?该滑动窗口主要用于统计1%、10%、50%、90%、99%等一系列比例的命令执行平均耗时,主要用以生成统计图表。
带hystrix.command.default.metrics.rollingPercentile前缀的配置项,专门用于配置百分比命令执行时间统计窗口。
下面以文本属性配置方式为主,详细介绍Hystrix执行时间百分比统计滑动窗口的配置:
(1)hystrix.command.default.metrics.rollingPercentile.enabled:
该配置项用于设置百分比命令执行时间统计窗口是否生效,命令的执行时间是否被跟踪,并且计算各个百分比如1%、10%、50%、90%、99.5% 等的平均时间。该配置项默认为true。
(2)hystrix.command.default.metrics.rollingPercentile.timeInMilliseconds
设置百分比命令执行时间统计窗口的持续时间(以毫秒为单位),默认值为 60000 毫秒,当然,此滑动窗口也会被进一步细分为时间桶,以便提高统计的效率。
本选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withMetricsRollingPercentileWindowInMilliseconds(int)
(3)hystrix.command.default.metrics.rollingPercentile.numBuckets
设置百分比命令执行时间统计窗口被划分为时间桶的数量,默认值为 6。此滑动窗口的默认持续时间为默认的60000毫秒,即默认情况下,一个时间桶的时间为10秒。如果要做定制化的配置,此窗口所设置的numBuckets(时间桶数量)值和timeInMilliseconds(滑动窗口时长)值有关联关系,必须符合timeInMilliseconds(滑动窗口时长)% numberBuckets == 0 的规则,否则将抛出异常。
此选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withMetricsRollingPercentileWindowBuckets (int)
(4)hystrix.command.default.metrics.rollingPercentile.bucketSize
设置百分比命令执行时间统计窗口的时间桶内最大的统计次数,如果bucketSize为 100,而桶的时长为1秒,若这1秒里有500次执行,则只有最后100次执行的信息会被统计到桶里去。增加此配置项的值会导致内存开销及其他计算开销的上升,该配置项的默认值为100。
此选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withMetricsRollingPercentileBucketSize (int)
以上是Hystrix熔断器相关的滑动窗口的配置,接下来是熔断器本身的配置。
带hystrix.command.default.circuitBreaker前缀的配置项专门用于对熔断器本身进行配置。
下面以文本属性配置方式为主,对Hystrix熔断器的配置进行一下详细介绍:
(1)hystrix.command.default.circuitBreaker.enabled
该配置用来确定是否启用熔断器,默认值为true。
此选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withCircuitBreakerEnabled (boolean)
(2)hystrix.command.default.circuitBreaker.requestVolumeThreshold
该配置用于设置熔断器触发熔断的最少请求次数。如果设为20,那么当一个滑动窗口时间内(比如10秒)收到19个请求,即使19个请求都失败,熔断器也不会打开变成open状态。默认值为20。
此选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withCircuitBreakerRequestVolumeThreshold (int)
(3)hystrix.command.default.circuitBreaker.errorThresholdPercentage
该配置用于设置错误率阈值,当健康统计滑动窗口的错误率超过此值时,熔断器进入open开启状态,所有请求都会触发失败回退(fallback)。错误率阈值百分比的默认值为50。
此选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withCircuitBreakerErrorThresholdPercentage (int)
(4)hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds
此配置项指定了熔断器打开后经过多长时间允许一次请求尝试执行。熔断器打开时,Hystrix会在经过一段时间后就放行一条请求,如果这条请求执行成功了,说明此时服务很可能已经恢复了正常,那么就会关闭熔断器;如果此请求执行失败,则认为目标服务依然不可用,熔断器继续保持打开状态。
该配置用于配置熔断器的睡眠窗口,具体指的是熔断器打开之后过多长时间才允许一次请求尝试执行,默认值为5000毫秒,表示当熔断器开启(open)后,5000毫秒内会拒绝所有的请求,5000毫秒之后,熔断器才会进行入half-open状态。
此选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withCircuitBreakerSleepWindowInMilliseconds (int)
(5)hystrix.command.default.circuitBreaker.forceOpen
如果配置为true,则熔断器将被强制打开,所有请求将被触发失败回退(fallback)。此配置的默认值为false。
此选项通过代码方式配置时所对应的函数如下:
HystrixCommandProperties.Setter().withCircuitBreakerForceOpen (boolean)
下面是本书随书实例中demo-provider中的有关熔断器的配置,节选如下:
hystrix:
...
command:
...
default: #全局默认配置
circuitBreaker: #熔断器相关配置
enabled: true #是否启动熔断器,默认为true
requestVolumeThreshold: 20 #启用熔断器功能窗口时间内的最小请求数
sleepWindowInMilliseconds: 5000 #指定熔断器打开后多长时间内允许一次请求尝试执行
errorThresholdPercentage: 50 #窗口时间内超过50%的请求失败后就会打开熔断器
metrics:
rollingStats:
timeInMilliseconds: 6000
numBuckets: 10
UserClient#detail(Long): #独立接口配置,格式为: 类名#方法名(参数类型列表)
circuitBreaker: #熔断器相关配置
enabled: true #是否使用熔断器,默认为true
requestVolumeThreshold: 20 #窗口时间内的最小请求数
sleepWindowInMilliseconds: 5000 #打开后允许一次尝试的睡眠时间,默认配置为5秒
errorThresholdPercentage: 50 #窗口时间内熔断器开启的错误比例,默认配置为50
metrics:
rollingStats:
timeInMilliseconds: 10000 #滑动窗口时间
numBuckets: 10 #滑动窗口的时间桶数
使用文本格式配置时,可以对熔断器的参数值做默认配置,也可以对特定的RPC接口做个性化配置。对熔断器的参数值做默认配置时,使用hystrix.command.default默认前缀;对特定的RPC接口做个性化配置时,使用hystrix.command.FeignClient#Method格式的前缀。上面的演示例子中,对远程客户端Feign接口UserClient中的detail(Long)方法做了个性化的熔断器配置,其配置项的前缀为:
hystrix.command. UserClient#detail(Long)
Hystrix命令的执行流程
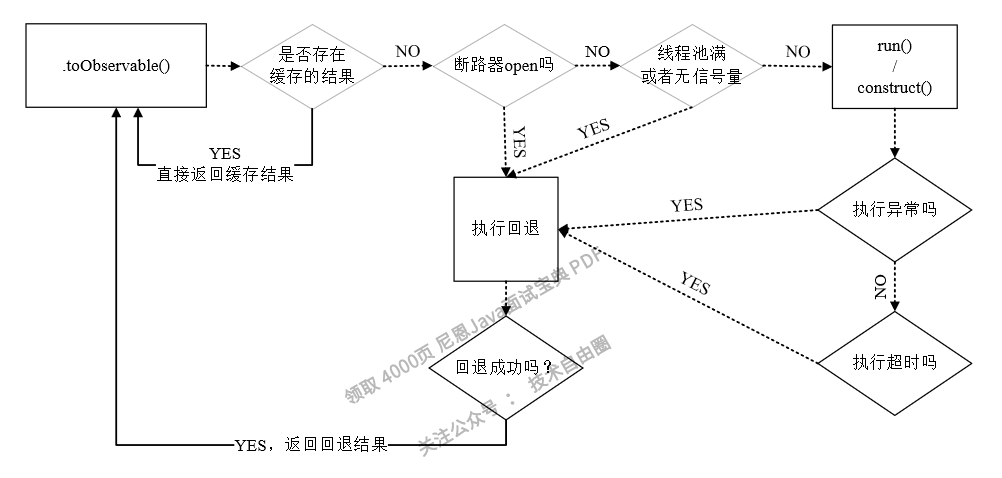
在获取HystrixCommand命令的执行结果时,无论是调用execute()和toObservable()方法,还是调用observe()方法,最终都会通过HystrixCommand.toObservable()订阅执行结果和返回。
在Hystrix内部,调用toObservable()方法返回一个观察的主题,当Subscriber订阅者订阅主题后,HystrixCommand会弹射一个事件,然后通过一系列的判断(顺序依次是缓存是否命中、熔断器是否打开、线程池是否占满),开始执行实际的HystrixCommand.run() 方法,该方法的实现主要为异步处理的业务逻辑,如果这其中任何一个环节出现错误或者抛出异常,它都会回退到getFallback()方法进行服务降级处理,当降级处理完成之后,它会将结果返回给实际的调用者。
HystrixCommand的工作流程,总结起来大致如下:
1)判断是否使用缓存响应请求,若启用了缓存,且缓存可用,则直接使用缓存响应请求。Hystrix支持请求缓存,但需要用户自定义启动。
2)判断熔断器是否开启,如果熔断器处于open状态,则跳到第5步。
3)如果使用线程池进行请求隔离,则判断线程池是否已满,已满则跳到第5步;如果使用信号量进行请求隔离,则判断信号量是否耗尽,耗尽则跳到第5步。
4)执行HystrixCommand.run()方法执行具体业务逻辑,如果执行失败或者超时,则跳到第5步,否则跳到第6步。
5)执行HystrixCommand.getFallback()服务降级处理逻辑。
6)返回请求响应。
以上流程如图6-12所示。
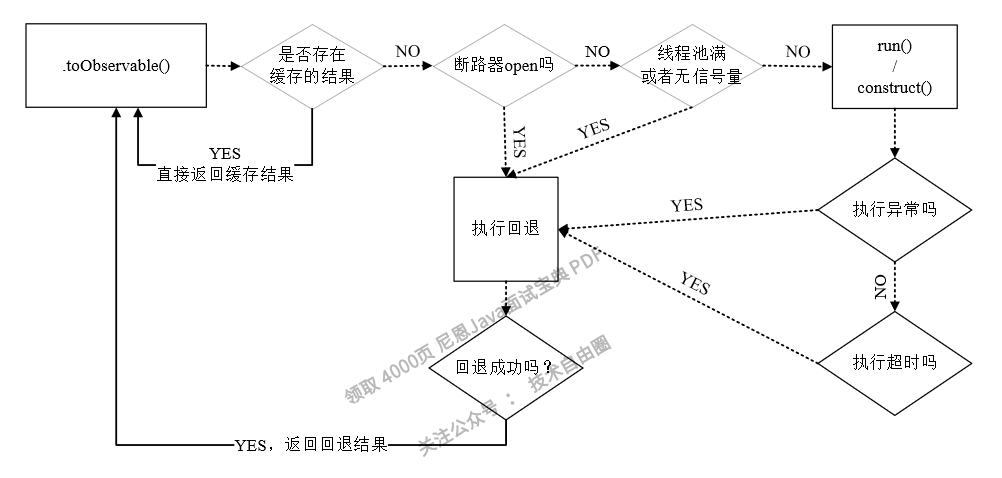
图6-12 HystrixCommand的执行流程示意图
什么场景下会触发fallback方法呢?请见表6-2。
表6-2 触发fallback方法的场景
| 名字 | 说明 | 触发fallback |
|---|---|---|
| EMIT | 值传递 | NO |
| SUCCESS | 执行完成,没有错误 | NO |
| FAILURE | 执行抛出异常 | YES |
| TIMEOUT | 执行开始,但没有在允许的时间内完成 | YES |
| BAD_REQUEST | 执行抛出HystrixBadRequestException | NO |
| SHORT_CIRCUITED | 熔断器打开,不尝试执行 | YES |
| THREAD_POOL_REJECTED | 线程池拒绝,不尝试执行 | YES |
| SEMAPHORE_REJECTED | 信号量拒绝,不尝试执行 | YES |
Sentinel 限流降级
Sentinel 限流降级的流量控制(Flow Control)策略,原理是监控应用流量的QPS或并发线程数等指标,当达到指定阈值时对流量进行控制,避免系统被瞬时的流量高峰冲垮,保障应用高可用性。
通过流控规则来指定允许该资源通过的请求次数,例如下面的代码定义了资源 HelloWorld 每秒最多只能通过 20 个请求。
参考的规则定义如下:
private static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("HelloWorld");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
一条限流规则主要由下面几个因素组成,我们可以组合这些元素来实现不同的限流效果:
resource:资源名,即限流规则的作用对象count: 限流阈值grade: 限流阈值类型(QPS 或并发线程数)limitApp: 流控针对的调用来源,若为default则不区分调用来源strategy: 调用关系限流策略controlBehavior: 流量控制效果(直接拒绝、Warm Up、匀速排队)
基本的参数
资源名:唯一名称,默认请求路径
针对来源:Sentinel可以针对调用者进行限流,填写微服务名,默认为default(不区分来源)
阈值类型/单机阈值:
- QPS:每秒请求数,当前调用该api的QPS到达阈值的时候进行限流
- 线程数:当调用该api的线程数到达阈值的时候,进行限流
是否集群:是否为集群
流控的几种 strategy:
- 直接:当api大达到限流条件时,直接限流
- 关联:当关联的资源到达阈值,就限流自己
- 链路:只记录指定路上的流量,指定资源从入口资源进来的流量,如果达到阈值,就进行限流,api级别的限流
直接失败模式 限流
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
完整内容,请参见 《尼恩Java面试宝典》V86版本,pdf 找尼恩获取
Sentinel 关联模式限流
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
完整内容,请参见 《尼恩Java面试宝典》V86版本,pdf 找尼恩获取
Warm up(预热)模式 限流
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
完整内容,请参见 《尼恩Java面试宝典》V86版本,pdf 找尼恩获取
Sentinel 熔断降级
什么是Sentinel熔断降级
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
完整内容,请参见 《尼恩Java面试宝典》V86版本,pdf 找尼恩获取
Sentinel 熔断降级规则
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
完整内容,请参见 《尼恩Java面试宝典》V86版本,pdf 找尼恩获取
几种降级策略
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
完整内容,请参见 《尼恩Java面试宝典》V86版本,pdf 找尼恩获取
熔断降级代码实现
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
完整内容,请参见 《尼恩Java面试宝典》V86版本,pdf 找尼恩获取
控制台降级规则
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
Sentinel 与 Hystrix对比
1、资源模型和执行模型上的对比
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
2、隔离设计上的对比
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
3、熔断降级的对比
… ,
由于公号字数限制,这里 公号放不下, 此处省略 100字+
Sentinel 与 Hystrix的不足
无论是 Sentinel 与 Hystrix, 都无法做到 分层分级细粒度 熔断限流,
所以,对于 微信中的 亿级QPS吞吐量规模过载场景, 没法直接使用 Sentinel 与 Hystrix 进行 , 没有办法进行 细粒度、 高精准 熔断保护(过载保护) 。
分层分级细粒度、高精准熔断限流降级策略
微信后台亿级QPS吞吐量的过载场景
微信作为当之无愧的国民级应用,系统复杂程度超乎想象:
- 其后台由三千多个移动服务构成,
- 每天需处理大约十的10~11次方个外部请求,
- 整体需要每秒处理大约几亿个请求! 亿级QPS吞吐量规模
微服务采用统一的 RPC 框架搭建一个个独立的服务,服务之间互相调用,实现各种各样的功能,这也是现代服务的基本架构。
微信的服务是分三层:接入服务、逻辑服务、基础服务。
大多数服务属于逻辑服务,接入服务如登录、发消息、支付服务,每日请求量在 10 亿-100 亿之间,入口协议触发对逻辑服务和基础服务更多的请求,核心服务每秒要处理上亿次的请求,qps> 1亿。

在大规模微服务场景下,过载会变得比较复杂。
如果是单体服务,一个事件只用一个请求。
但微服务下,一个事件可能要请求很多的服务,任何一个服务过载失败,就会造成其他的请求都是无效的。
如下图所示:

比如在一个转账服务下,需要查询分别两者的卡号,再查询 A 时成功了,但查询B失败,对于查卡号这个事件就算失败了,比如查询成功率只有 50%,那对于查询两者卡号这个成功率只有 50% * 50% = 25% 了,一个事件调用的服务次数越多,那成功率就会越低。
微信后台如何判断过载
通常,判断过载的方式很多,比如:
- 使用 吞吐量 判断过载
- 使用 访问延迟 判断过载
- 使用 CPU 使用率 判断过载
- 使用 丢包率 判断过载
- 使用 失败率 判断过载
- 使用 待处理请求数 判断过载
- 使用 请求处理事件 判断过载。
微信并没有使用 以上的常用方式,而是使用一种特殊的方式:
- 请求在队列中的平均等待时间 判断过载。
微信为啥不使用响应时间?
因为响应时间是跟服务相关的,很多微服务是链式调用,响应时间是不可控的,也是无法标准化的,很难作为一个统一的判断依据。
为微信为啥也不使用 CPU 负载作为判断标准呢?
因为 CPU 负载高不代表服务过载,一个服务请求处理及时,CPU 处于高位反而是比较良好的表现。
实际上 CPU 负载高,监控服务是会告警出来,但是并不会直接进入过载处理流程。
什么是 请求在队列中的平均等待时间 呢?
请求在队列中的等待时间 就是从 请求到达,到开始处理的时间。 平均等待时间的计算范围,以时间窗口(如s)划分时间范围,或者以 一定数量的请求划分范围(如每 2000 个请求)。
以超时时间为基础,腾讯微服务通过计算每秒或每 2000 个请求的平均等待时间是否超过 20ms,判断是否过载,这个 20ms 是根据微信后台 5 年摸索出来的门槛值。默认的超时时间是 500ms,
采用平均等待时间还有一个好处是:
这个是独立于服务的,可以应用于任何场景,而不用关联于业务,可以直接在框架上进行改造。
微信后台的限流降级策略(过载保护策略)
当平均等待时间大于 20ms 时,以一定的降速因子过滤调部分请求。 开始进行 限流降级 。
如果判断平均等待时间小于 20ms,则以一定的速率提升通过率。 开始 进行流量的恢复。
一般采用快降慢升的策略,防止大的服务波动。
整个策略相当于一个负反馈电路。

分层分级细粒度、高精准熔断限流降级策略
一旦检测到服务过载,需要按照一定的策略对请求进行过滤。
那么,有哪些进行流量过滤的策略呢?
- 策略一:随机丢弃
- 策略二:分层分级细粒度 过滤
对于链式调用的微服务场景,使用策略一进行随机丢弃请求,最终会导致整体服务的成功率很低。
所以,使用分层分级高精准细粒度限流降级策略,请求是按照优先级进行控制的, 优先级低的请求会优先丢弃。
什么是使用分层分级高精准细粒度限流降级策略?
具体来说:
- 业务分层
- 用户分级
1)业务分层
对于不同的业务场景优先的层级是不同的。
比如:登录场景是最重要的业务,也是最为核心的业务,如果不能登录,一切都白费。
另外:支付消息也比普通消息优先级高,因为用户对金钱是更敏感的。
再比如说:普通消息,又比朋友圈消息优先级高。
所以在微信内是天然存在业务层级的。
每个请求,从业务维度来说,都会分配一个业务层级。
在微服务的链式调用下,后端的请求业务层级,从请求链路的前段进行继承的。
比如我请求登录,那么后端的请求业务都是继承登录的业务层级。如检查账号密码等一系列的后续请求都是继承登录优先级的,这就保证了业务层级的一致性。
用一个hash表维护重要性很高的top N的业务层级,每个后台服务维护了业务层级的hash表。
当然,微信的业务太多,并非每个业务都记录在hash表里,不在hash表里的业务就是 低层级业务。限流的时候, 首先被限制。
hash表中的业务,都是高层级业务。限流的时候, 放在最后限制。

2)用户分级
每个业务的请求量很大,整块业务请求全部被限制, 那一定会造成负载的大幅波动。
所以不可能因为负载高,丢弃或允许通过一整个业务的请求。
很明显,只基于业务层级的控制是不够的。
解决这个问题,可以引入用户分级。
实际上,很多网站的用户天然是分级的,VIP用户的访问,需要优先保证。
微信如何对用户进行分级呢?
一个10亿级用户的APP,从业务维度来说,用户分级的方案,非常复杂。
除了从业务维度分级完成之后,按照二八定律, 普通人占80%, 这个依然是一个庞大的数字。
对于普通人来说,还需要继续进一步细分,这时候,可以通过 hash 用户唯一 ID,计算用户优先级。
3)分层分级二维限流降级控制
引入了用户优先级,那就和业务优先级组成了一个二维限流降级控制。
根据负载情况,决定这台服务器的准入优先级(B,U),二维限流降级控制具体为:
-
当过来的请求业务优先级大于 B,则通过
-
或者当过来的请求业务优先级不大于 B,但用户优先级高于 U 时,则通过,否则决绝。
两个条件,满足一个即可放行。
4)RPC组件客户端限流
为了进一步减轻过载机器的压力,能不能在upstream 后端过载的情况下,不把请求发到 后端呢?
否则 后端还是要接受请求、解包、丢弃请求,白白浪费带宽也加重了 后端的负载。
为了实现这个能力,进行RPC组件客户端限流:
- 在每次请求 后端(upstream上游)服务时, 后端把当前服务的准入优先级返回给 前端,
- RPC组件客户端维护上游服务的准入优先级,如果发现请求优先级达不到上游服务的准入门槛,直接丢弃,而不再请求upstream上游,进一步减轻upstream上游的压力。
微信整个负载控制的流程
微信整个负载控制的流程如图所示:
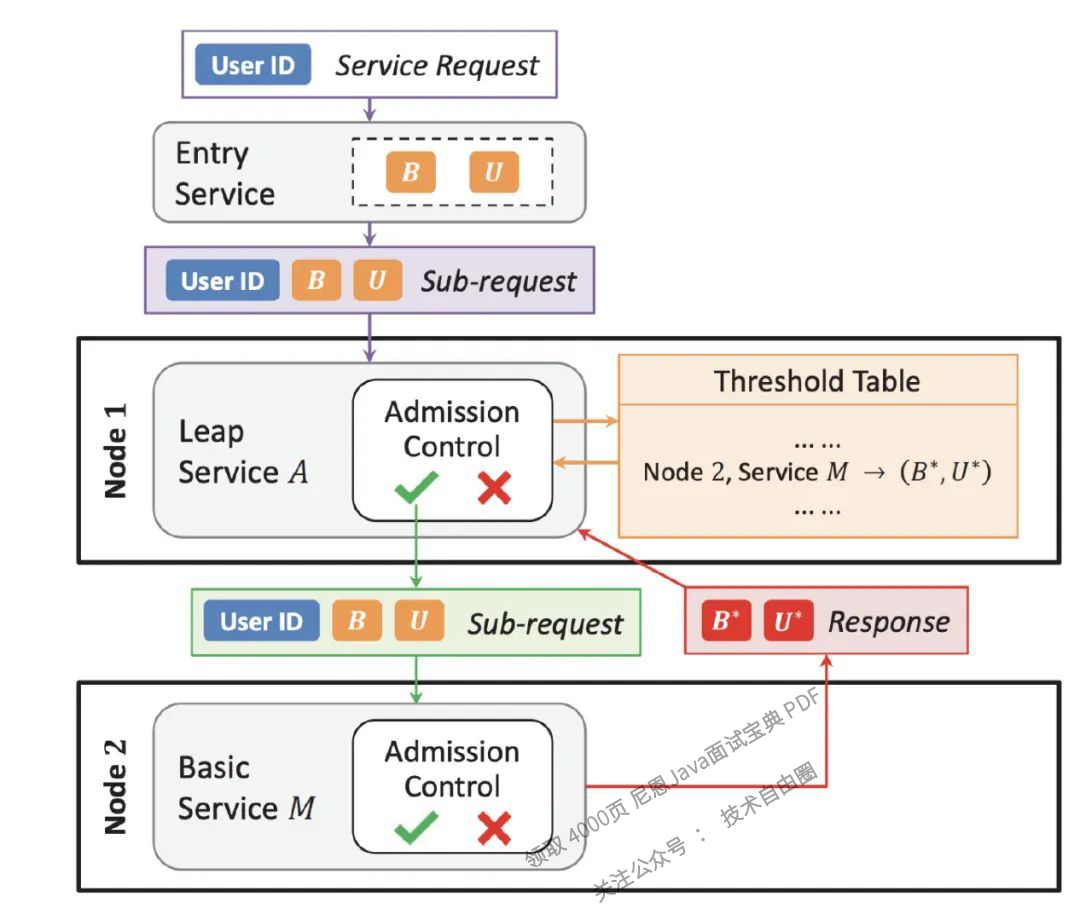
当用户从微信发起请求,请求被路由到接入层服务,分配统一的业务和用户优先级,所有到的upstream上游子请求都继承相同的优先级。根据业务逻辑调用1个或多个upstream上游服务。
当服务收到请求,首先根据自身服务准入优先级判断请求是接受还是丢弃。
服务本身根据负载情况周期性的调整准入优先级。
当服务通过RPC客户端需要再向upstream上游发起请求时,判断本地记录的upstream上游服务准入优先级。如果小于则丢弃,如果没有记录或优先级大于记录则向upstream上游发起请求。
upstream上游服务返回需要的信息,并且在信息中携带自身准入优先级。downstream下游接受到返回后解析信息,并更新本地记录的upstream服务准入优先级。
说在最后
熔断,降级,防止雪崩,是面试的重点和高频点。
(1) 什么是熔断,降级?如何实现?
(2) 服务熔断,解决灾难性雪崩效应的有效利器
(3) 说一下限流、熔断、高可用
等等等等…
参照上文的答案,如果大家能对答如流,最终,让面试官爱到 “不能自已、口水直流”。 offer, 也就来了。
学习过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。 加入社区的方式,请参见 公号【技术自由圈】 。
作者介绍
本文1作: Andy,资深架构师, 《Java 高并发核心编程 加强版 》作者之1 。
本文2作: 尼恩,41岁资深老架构师, 《Java 高并发核心编程 加强版 卷1、卷2、卷3》创世作者, 著名博主 。 《K8S学习圣经》《Docker学习圣经》《Go学习圣经》等11个PDF 圣经的作者。 也是一个 架构转化 导师, 已经指导了大量小伙伴成功 转型架构师, 最高的年薪拿到近100W。
参考文献
[1] Overload Control for Scaling WeChat Microservices
[2] 罗神解读“Overload Control for Scaling WeChat Microservices”
[3] 2W台服务器、每秒数亿请求,微信如何不“失控”?
[4] DAGOR:微信微服务过载控制系统
[5] 月活 12.8 亿的微信是如何防止崩溃的?
[6] 微信朋友圈千亿访问量背后的技术挑战和实践总结
[7] QQ 18年:解密8亿月活的QQ后台服务接口隔离技术
[8] 微信后台基于时间序的海量数据冷热分级架构设计实践
[9] 架构之道:3个程序员成就微信朋友圈日均10亿发布量》
[10] 快速裂变:见证微信强大后台架构从0到1的演进历程(一)
[11] 一份微信后台技术架构的总结性笔记》
https://juejin.cn/post/6844904006259572749
https://cloud.tencent.com/developer/article/1815254
https://blog.csdn.net/qq_27184497/article/details/119993725
https://blog.csdn.net/sh210106sh/article/details/116495124
推荐相关阅读
《从0开始,手写Redis》
《从0开始,手写MySQL事务管理器TM》
《从0开始,手写MySQL数据管理器DM》
《腾讯太狠:40亿QQ号,给1G内存,怎么去重?》
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓