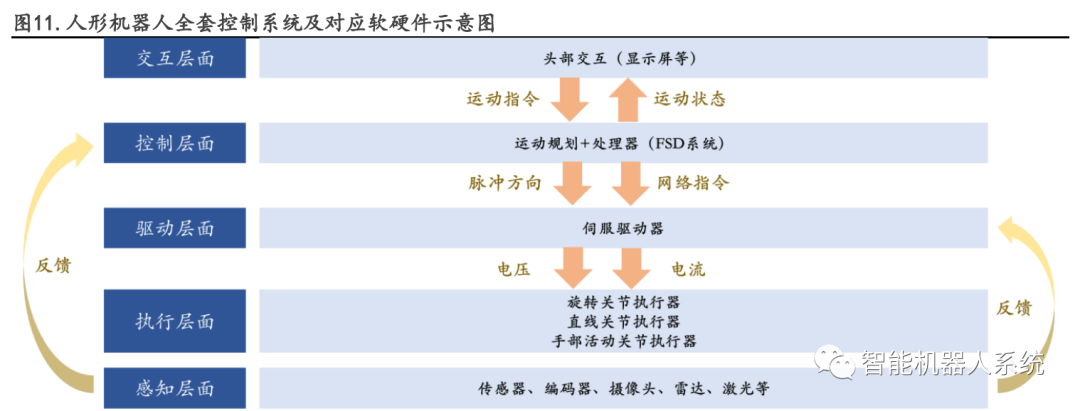
note
- 评估目的:检验LLM是否达到验收标准;分析改动对于LLM应用性能的影响
- 思路:利用语言模型和链,辅助评估
- 代理:
- 代理能方便地将LLM连接自己的信息来源(数据)、API等
PythonREPLTool工具,使能够结合自己的python代码场景执行过程,比如下面将姓名列表根据拼音进行排序。
文章目录
- note
- 一、评估
- 1. 创建测试用例数据
- 2. 评估
- 二、代理
- 1. 使用llm-math和wikipedia工具
- 2. 使用PythonREPLTool工具
- 3. 定义自己的工具并在代理中使用
- Reference
一、评估
1. 创建测试用例数据
- 从许多不同的数据点中获得更全面的模型表现情况
- 使用语言模型本身和链本身来评估其他语言模型、其他链和其他应用程序
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Author : andy
@Date : 2023/7/17 10:21
@Contact: 864934027@qq.com
@File : evaluate_test.py
"""
from langchain.chains import RetrievalQA #检索QA链,在文档上进行检索
from langchain.chat_models import ChatOpenAI #openai模型
from langchain.document_loaders import CSVLoader #文档加载器,采用csv格式存储
from langchain.indexes import VectorstoreIndexCreator #导入向量存储索引创建器
from langchain.vectorstores import DocArrayInMemorySearch #向量存储
#加载数据
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
data = loader.load()
#查看数据
import pandas as pd
test_data = pd.read_csv(file,header=None)
# name, description
'''
将指定向量存储类,创建完成后,我们将从加载器中调用,通过文档记载器列表加载
'''
import os
os.environ["OPENAI_API_KEY"] = ".."
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
#通过指定语言模型、链类型、检索器和我们要打印的详细程度来创建检索QA链
llm = ChatOpenAI(temperature = 0.0)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
verbose=True,
chain_type_kwargs = {
"document_separator": "<<<<>>>>>"
}
)
# 1. 创建评估数据点
data[10]#查看这里的一些文档,我们可以对其中发生的事情有所了解
# Document(page_content=": 10\nname: Cozy Comfort Pullover Set, Stripe\ndescription: Perfect for lounging, this striped knit set lives up to its name. We used ultrasoft fabric and an easy design that's as comfortable at bedtime as it is when we have to make a quick run out.\n\nSize & Fit\n- Pants are Favorite Fit: Sits lower on the waist.\n- Relaxed Fit: Our most generous fit sits farthest from the body.\n\nFabric & Care\n- In the softest blend of 63% polyester, 35% rayon and 2% spandex.\n\nAdditional Features\n- Relaxed fit top with raglan sleeves and rounded hem.\n- Pull-on pants have a wide elastic waistband and drawstring, side pockets and a modern slim leg.\n\nImported.", metadata={'source': 'OutdoorClothingCatalog_1000.csv', 'row': 10})
# 2. 创建测试数据用例, 但是这种方式不方便扩展
examples = [
{
"query": "Do the Cozy Comfort Pullover Set\
have side pockets?",
"answer": "Yes"
},
{
"query": "What collection is the Ultra-Lofty \
850 Stretch Down Hooded Jacket from?",
"answer": "The DownTek collection"
}
]
QAGenerateChain链接受文档后从每个文档创建一个问题答案对,每次将声测会给你的问答添加到已有的评估数据集中
# 3. 步骤一:通过langchain生成测试用例
from langchain.evaluation.qa import QAGenerateChain #导入QA生成链,它将接收文档,并从每个文档中创建一个问题答案对
example_gen_chain = QAGenerateChain.from_llm(ChatOpenAI())#通过传递chat open AI语言模型来创建这个链
data[:5]
new_examples = example_gen_chain.apply_and_parse(
[{"doc": t} for t in data[:5]]
) #我们可以创建许多例子
new_examples #查看用例数据
# 4. 组合用例数据
examples += new_examples
qa.run(examples[0]["query"])
# 5. 评估
'''
LingChainDebug工具可以了解运行一个实例通过链中间所经历的步骤
'''
import langchain
langchain.debug = True
qa.run(examples[0]["query"])#重新运行与上面相同的示例,可以看到它开始打印出更多的信息
可以根据data[10]的文档数据看出在描述纺织物、套头衫的内容,可以根据这些创建简单的测试用例数据。
[chain/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain] Entering Chain run with input:
{
"question": "Do the Cozy Comfort Pullover Set have side pockets?",
"context": ": 10\nname: Cozy Comfort Pullover Set, Stripe\ndescription: Perfect for lounging, this striped knit set lives up to its name. We used ultrasoft fabric and an easy design that's as comfortable at bedtime as it is when we have to make a quick run out.\n\nSize & Fit\n- Pants are Favorite Fit: Sits lower on the waist.\n- Relaxed Fit: Our most generous fit sits farthest from the body.\n\nFabric & Care\n- In the softest blend of 63% polyester, 35% rayon and 2% spandex.\n\nAdditional Features\n- Relaxed fit top with raglan sleeves and rounded hem.\n- Pull-on pants have a wide elastic waistband and drawstring, side pockets and a modern slim leg.\n\nImported.<<<<>>>>>: 73\nname: Cozy Cuddles Knit Pullover Set\ndescription: Perfect for lounging, this knit set lives up to its name. We used ultrasoft fabric and an easy design that's as comfortable at bedtime as it is when we have to make a quick run out. \n\nSize & Fit \nPants are Favorite Fit: Sits lower on the waist. \nRelaxed Fit: Our most generous fit sits farthest from the body. \n\nFabric & Care \nIn the softest blend of 63% polyester, 35% rayon and 2% spandex.\n\nAdditional Features \nRelaxed fit top with raglan sleeves and rounded hem. \nPull-on pants have a wide elastic waistband and drawstring, side pockets and a modern slim leg. \nImported.<<<<>>>>>: 632\nname: Cozy Comfort Fleece Pullover\ndescription: The ultimate sweater fleece – made from superior fabric and offered at an unbeatable price. \n\nSize & Fit\nSlightly Fitted: Softly shapes the body. Falls at hip. \n\nWhy We Love It\nOur customers (and employees) love the rugged construction and heritage-inspired styling of our popular Sweater Fleece Pullover and wear it for absolutely everything. From high-intensity activities to everyday tasks, you'll find yourself reaching for it every time.\n\nFabric & Care\nRugged sweater-knit exterior and soft brushed interior for exceptional warmth and comfort. Made from soft, 100% polyester. Machine wash and dry.\n\nAdditional Features\nFeatures our classic Mount Katahdin logo. Snap placket. Front princess seams create a feminine shape. Kangaroo handwarmer pockets. Cuffs and hem reinforced with jersey binding. Imported.\n\n – Official Supplier to the U.S. Ski Team\nTHEIR WILL TO WIN, WOVEN RIGHT IN. LEARN MORE<<<<>>>>>: 151\nname: Cozy Quilted Sweatshirt\ndescription: Our sweatshirt is an instant classic with its great quilted texture and versatile weight that easily transitions between seasons. With a traditional fit that is relaxed through the chest, sleeve, and waist, this pullover is lightweight enough to be worn most months of the year. The cotton blend fabric is super soft and comfortable, making it the perfect casual layer. To make dressing easy, this sweatshirt also features a snap placket and a heritage-inspired Mt. Katahdin logo patch. For care, machine wash and dry. Imported."
}
[llm/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain > 5:llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"System: Use the following pieces of context to answer the users question. \nIf you don't know the answer, just say that you don't know, don't try to make up an answer.\n----------------\n: 10\nname: Cozy Comfort Pullover Set, Stripe\ndescription: Perfect for lounging, this striped knit set lives up to its name. We used ultrasoft fabric and an easy design that's as comfortable at bedtime as it is when we have to make a quick run out.\n\nSize & Fit\n- Pants are Favorite Fit: Sits lower on the waist.\n- Relaxed Fit: Our most generous fit sits farthest from the body.\n\nFabric & Care\n- In the softest blend of 63% polyester, 35% rayon and 2% spandex.\n\nAdditional Features\n- Relaxed fit top with raglan sleeves and rounded hem.\n- Pull-on pants have a wide elastic waistband and drawstring, side pockets and a modern slim leg.\n\nImported.<<<<>>>>>: 73\nname: Cozy Cuddles Knit Pullover Set\ndescription: Perfect for lounging, this knit set lives up to its name. We used ultrasoft fabric and an easy design that's as comfortable at bedtime as it is when we have to make a quick run out. \n\nSize & Fit \nPants are Favorite Fit: Sits lower on the waist. \nRelaxed Fit: Our most generous fit sits farthest from the body. \n\nFabric & Care \nIn the softest blend of 63% polyester, 35% rayon and 2% spandex.\n\nAdditional Features \nRelaxed fit top with raglan sleeves and rounded hem. \nPull-on pants have a wide elastic waistband and drawstring, side pockets and a modern slim leg. \nImported.<<<<>>>>>: 632\nname: Cozy Comfort Fleece Pullover\ndescription: The ultimate sweater fleece – made from superior fabric and offered at an unbeatable price. \n\nSize & Fit\nSlightly Fitted: Softly shapes the body. Falls at hip. \n\nWhy We Love It\nOur customers (and employees) love the rugged construction and heritage-inspired styling of our popular Sweater Fleece Pullover and wear it for absolutely everything. From high-intensity activities to everyday tasks, you'll find yourself reaching for it every time.\n\nFabric & Care\nRugged sweater-knit exterior and soft brushed interior for exceptional warmth and comfort. Made from soft, 100% polyester. Machine wash and dry.\n\nAdditional Features\nFeatures our classic Mount Katahdin logo. Snap placket. Front princess seams create a feminine shape. Kangaroo handwarmer pockets. Cuffs and hem reinforced with jersey binding. Imported.\n\n – Official Supplier to the U.S. Ski Team\nTHEIR WILL TO WIN, WOVEN RIGHT IN. LEARN MORE<<<<>>>>>: 151\nname: Cozy Quilted Sweatshirt\ndescription: Our sweatshirt is an instant classic with its great quilted texture and versatile weight that easily transitions between seasons. With a traditional fit that is relaxed through the chest, sleeve, and waist, this pullover is lightweight enough to be worn most months of the year. The cotton blend fabric is super soft and comfortable, making it the perfect casual layer. To make dressing easy, this sweatshirt also features a snap placket and a heritage-inspired Mt. Katahdin logo patch. For care, machine wash and dry. Imported.\nHuman: Do the Cozy Comfort Pullover Set have side pockets?"
]
}
[llm/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain > 5:llm:ChatOpenAI] [1.70s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "Yes, the Cozy Comfort Pullover Set does have side pockets.",
"generation_info": {
"finish_reason": "stop"
},
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessage"
],
"kwargs": {
"content": "Yes, the Cozy Comfort Pullover Set does have side pockets.",
"additional_kwargs": {}
}
}
}
]
],
"llm_output": {
"token_usage": {
"prompt_tokens": 732,
"completion_tokens": 14,
"total_tokens": 746
},
"model_name": "gpt-3.5-turbo"
},
"run": null
}
[chain/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain] [1.70s] Exiting Chain run with output:
{
"text": "Yes, the Cozy Comfort Pullover Set does have side pockets."
}
[chain/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain] [1.70s] Exiting Chain run with output:
{
"output_text": "Yes, the Cozy Comfort Pullover Set does have side pockets."
}
[chain/end] [1:chain:RetrievalQA] [11.65s] Exiting Chain run with output:
{
"result": "Yes, the Cozy Comfort Pullover Set does have side pockets."
}
- 首先深入到检索QA链中,然后它进入了一些文档链。如上所述,我们正在使用stuff方法,现在我们正在传递这个上下文,可以看到,这个上下文是由我们检索到的不同文档创建的。因此,在进行问答时,当返回错误结果时,通常不是语言模型本身出错了,实际上是检索步骤出错了,仔细查看问题的确切内容和上下文可以帮助调试出错的原因。
- 然后,我们可以再向下一级,看看进入语言模型的确切内容,以及 OpenAI 自身,在这里,我们可以看到传递的完整提示,我们有一个系统消息,有所使用的提示的描述,这是问题回答链使用的提示,我们可以看到提示打印出来,使用以下上下文片段回答用户的问题。
- 然后我们看到一堆之前插入的上下文,我们还可以看到有关实际返回类型的更多信息。我们不仅仅返回一个答案,还有token的使用情况,可以了解到token数的使用情况
- 由于这是一个相对简单的链,我们现在可以看到最终的响应,舒适的毛衣套装,条纹款,有侧袋,正在起泡,通过链返回给用户,我们刚刚讲解了如何查看和调试单个输入到该链的情况。
2. 评估
'''
LingChainDebug工具可以了解运行一个实例通过链中间所经历的步骤
'''
import langchain
langchain.debug = True
qa.run(examples[0]["query"])#重新运行与上面相同的示例,可以看到它开始打印出更多的信息
# 我们需要为所有示例创建预测,关闭调试模式,以便不将所有内容打印到屏幕上
langchain.debug = False
# 通过LLM进行评估实例
predictions = qa.apply(examples) #为所有不同的示例创建预测
'''
对预测的结果进行评估,导入QA问题回答,评估链,通过语言模型创建此链
'''
from langchain.evaluation.qa import QAEvalChain #导入QA问题回答,评估链
#通过调用chatGPT进行评估
llm = ChatOpenAI(temperature=0)
eval_chain = QAEvalChain.from_llm(llm)
graded_outputs = eval_chain.evaluate(examples, predictions)#在此链上调用evaluate,进行评估
#我们将传入示例和预测,得到一堆分级输出,循环遍历它们打印答案
for i, eg in enumerate(examples):
print(f"Example {i}:")
print("Question: " + predictions[i]['query'])
print("Real Answer: " + predictions[i]['answer'])
print("Predicted Answer: " + predictions[i]['result'])
print("Predicted Grade: " + graded_outputs[i]['results'])
print()
'''
Example 5:
Question: What is the fabric composition of the Refresh Swimwear, V-Neck Tankini Contrasts?
Real Answer: The Refresh Swimwear, V-Neck Tankini Contrasts is made of 82% recycled nylon and 18% Lycra® spandex for the body, and 90% recycled nylon with 10% Lycra® spandex for the lining.
Predicted Answer: The fabric composition of the Refresh Swimwear, V-Neck Tankini Contrasts is 82% recycled nylon with 18% Lycra® spandex for the body, and 90% recycled nylon with 10% Lycra® spandex for the lining.
Predicted Grade: CORRECT
'''
评估思路:当它面前有整个文档时,它可以生成一个真实的答案,我们将打印出预测的答,当它进行QA链时,使用embedding和向量数据库进行检索时,将其传递到语言模型中,然后尝试猜测预测的答案,我们还将打印出成绩,这也是语言模型生成的。当它要求评估链评估正在发生的事情时,以及它是否正确或不正确。因此,当我们循环遍历所有这些示例并将它们打印出来时,可以详细了解每个示例。
模型评估的优势:你有这些答案,它们是任意的字符串。没有单一的真实字符串是最好的可能答案,有许多不同的变体,只要它们具有相同的语义,它们应该被评为相似。如果使用正则进行精准匹配就会丢失语义信息,到目前为止存在的许多评估指标都不够好。目前最有趣和最受欢迎的之一就是使用语言模型进行评估。
二、代理
1. 使用llm-math和wikipedia工具
初始化代理的参数:
agent: 代理类型。这里使用的是AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION。其中CHAT代表代理模型为针对对话优化的模型,REACT代表针对REACT设计的提示模版。handle_parsing_errors: 是否处理解析错误。当发生解析错误时,将错误信息返回给大模型,让其进行纠正。verbose: 是否输出中间步骤结果。
from langchain.agents import load_tools, initialize_agent
from langchain.agents import AgentType
from langchain.python import PythonREPL
from langchain.chat_models import ChatOpenAI
# 1. 初始化大模型
# 参数temperature设置为0.0,从而减少生成答案的随机性。
open_api_key = "..."
llm = ChatOpenAI(temperature=0, openai_api_key = open_api_key)
# 2. 加载工具包
tools = load_tools(
["llm-math","wikipedia"],
llm=llm #第一步初始化的模型
)
# 3. 初始化代理
agent= initialize_agent(
tools, #第二步加载的工具
llm, #第一步初始化的模型
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, #代理类型
handle_parsing_errors=True, #处理解析错误
verbose = True #输出中间步骤
)
# 4. 使用代理回答问题
agent("计算300的25%,思考过程请使用中文。")
# 思考,行动,观察,得到结果
2. 使用PythonREPLTool工具
PythonREPLTool工具,使能够结合自己的python代码场景执行过程,比如下面将姓名列表根据拼音进行排序。
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
agent = create_python_agent(
llm, #使用前面一节已经加载的大语言模型
tool=PythonREPLTool(), #使用Python交互式环境工具(REPLTool)
verbose=True #输出中间步骤
)
customer_list = ["小明","小黄","小红","小蓝","小橘","小绿",]
# !pip install -q pinyin
agent.run(f"""在这些客户名字转换为拼音\
并打印输出列表: {customer_list}\
思考过程请使用中文。""")
'''
> Entering new AgentExecutor chain...
我需要使用拼音转换库来将这些客户名字转换为拼音。我可以使用Python的pinyin库来完成这个任务。
Action: Python_REPL
Action Input: import pinyin
Observation:
Thought:我现在可以使用pinyin库来将客户名字转换为拼音。
Action: Python_REPL
Action Input: names = ['小明', '小黄', '小红', '小蓝', '小橘', '小绿']
pinyin_names = [pinyin.get(i, format='strip', delimiter='') for i in names]
print(pinyin_names)
Observation: ['xiaoming', 'xiaohuang', 'xiaohong', 'xiaolan', 'xiaoju', 'xiaolv']
Thought:我现在知道了最终答案。
Final Answer: ['xiaoming', 'xiaohuang', 'xiaohong', 'xiaolan', 'xiaoju', 'xiaolv']
> Finished chain.
'''
在调试(debug)模式下再次运行,我们可以把上面的6步分别对应到下面的具体流程
-
模型对于接下来需要做什么,给出思考(Thought)
-
[chain/start] [1:chain:AgentExecutor] Entering Chain run with input
-
[chain/start] [1:chain:AgentExecutor > 2:chain:LLMChain] Entering Chain run with input
-
[llm/start] [1:chain:AgentExecutor > 2:chain:LLMChain > 3:llm:ChatOpenAI] Entering LLM run with input
-
[llm/end] [1:chain:AgentExecutor > 2:chain:LLMChain > 3:llm:ChatOpenAI] [12.25s] Exiting LLM run with output
-
[chain/end] [1:chain:AgentExecutor > 2:chain:LLMChain] [12.25s] Exiting Chain run with output
-
-
模型基于思考采取行动(Action), 因为使用的工具不同,Action的输出也和之前有所不同,这里输出的为python代码
-
[tool/start] [1:chain:AgentExecutor > 4:tool:Python REPL] Entering Tool run with input
-
[tool/end] [1:chain:AgentExecutor > 4:tool:Python REPL] [2.2239999999999998ms] Exiting Tool run with output
-
-
模型得到观察(Observation)
-
[chain/start] [1:chain:AgentExecutor > 5:chain:LLMChain] Entering Chain run with input
-
-
基于观察,模型对于接下来需要做什么,给出思考(Thought)
-
[llm/start] [1:chain:AgentExecutor > 5:chain:LLMChain > 6:llm:ChatOpenAI] Entering LLM run with input
-
[llm/end] [1:chain:AgentExecutor > 5:chain:LLMChain > 6:llm:ChatOpenAI] [6.94s] Exiting LLM run with output
-
-
给出最终答案(Final Answer)
-
[chain/end] [1:chain:AgentExecutor > 5:chain:LLMChain] [6.94s] Exiting Chain run with output
-
-
返回最终答案。
-
[chain/end] [1:chain:AgentExecutor] [19.20s] Exiting Chain run with output
-
3. 定义自己的工具并在代理中使用
tool函数装饰器可以应用用于任何函数,将函数转化为LongChain工具,使其成为代理可调用的工具。
我们需要给函数加上非常详细的文档字符串, 使得代理知道在什么情况下、如何使用该函数/工具。比如下面的函数time,我们加上了详细的文档字符串,代理就会根据注释中的信息来判断何时调用、如何使用这个工具。
"""
返回今天的日期,用于任何与获取今天日期相关的问题。
输入应该始终是一个空字符串,该函数将始终返回今天的日期。
任何日期的计算应该在此函数之外进行。
"""
# 如果你需要查看安装过程日志,可删除 -q
# !pip install -q DateTime
# 导入tool函数装饰器
from langchain.agents import tool
from datetime import date
@tool
def time(text: str) -> str:
"""
返回今天的日期,用于任何需要知道今天日期的问题。\
输入应该总是一个空字符串,\
这个函数将总是返回今天的日期,任何日期计算应该在这个函数之外进行。
"""
return str(date.today())
# 初始化代理
agent= initialize_agent(
tools=[time], #将刚刚创建的时间工具加入代理
llm=llm, #初始化的模型
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, #代理类型
handle_parsing_errors=True, #处理解析错误
verbose = True #输出中间步骤
)
agent("今天的日期是?")
# {'input': '今天的日期是?', 'output': '今天的日期是2023-07-17。'}
总结:
-
模型对于接下来需要做什么,给出思考(Thought)
思考:我需要使用 `time` 工具来获取今天的日期
-
模型基于思考采取行动(Action), 因为使用的工具不同,Action的输出也和之前有所不同,这里输出的为python代码
行动: 使用time工具,输入为空字符串
-
模型得到观察(Observation)
观测: 2023-07-04
-
基于观察,模型对于接下来需要做什么,给出思考(Thought)
思考: 我已成功使用 time 工具检索到了今天的日期
-
给出最终答案(Final Answer)
最终答案: 今天的日期是2023-07-04.
-
返回最终答案。
Langchain的其他应用:基于CSV文件回答问题、查询sql数据库、与api交互,有很多例子通过Chain以及不同的提示(Prompts)和输出解析器(output parsers)组合得以实现。

Reference
[1] 精华笔记:吴恩达 x LangChain《基于LangChain的大语言模型应用开发》(下)
[2] https://python.langchain.com/docs/modules/agents/