1.惰性学习(消极学习):在训练数据集的时候不会创建目标函数,只是简单将训练样本存储。后期需要对新样本进行判断的时候分析新样本和已存储的样本之间的关系,并以此确定新样本的输出值。例如:knn算法。
2.急切学习(积极学习):根据训练数据的训练得到一个目标函数,后期对新样本进行判断的时候利用该目标函数进行判断,并得到输出值。例如:决策树。
3.knn算法原理:当预测一个新样本时,将新样本与所有点进行距离计算,再排序选择与新样本距离最近的k个训练样本(如果是二分类问题,k一般为奇数),根据这k个样本中出现频率最高的类别即是该新样本的所属类别。
4.常用距离公式(参考原帖):
欧氏距离:

曼哈顿距离:
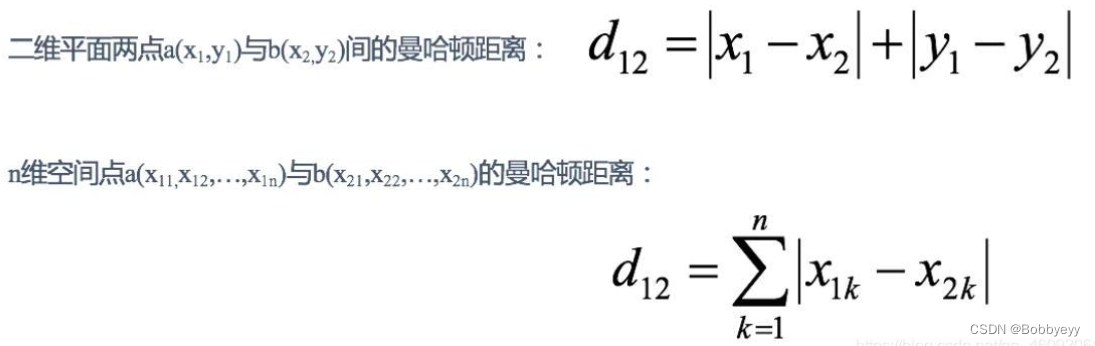
5.leave-one-out 测试(留一法LOO):每次只留一个样本作为验证集,其余N-1个样本作为测试集,不重复地循环N次直至所有样本都做过验证集。存在缺点:计算量过大。
6.k-Flod交叉验证(k折交叉验证):在进行验证之前将数据集分成k个子集,不重复地将每个子集作为验证集,其余k-1个子集作为训练集。根据经验一般k选择5或10。
7.评价指标(具体问题具体分析,选取或自定义所需评价指标,参考原文):
分类器:准确率、F1、召回率、ROC曲线等;
回归问题:MAE、MSE、RMSE等;
聚类问题:内部评价指标、外部评价指标。
8.M-distance算法原理:根据平均分来计算两个用户(或项目)之间的距离,与预测用户(或项目)平均值的差值达到一定阈值或者选取差值最小的k个值对应的用户(或项目),再回到原数据中求得的均值即为该预测值的输出值。
9.kMeans聚类算法原理(参考原文):
Step 1. (确定老大) 随机选择 k个点作为中心点.
Step 2. (分派别) 对于任意对象, 计算它到这 k个点的距离, 离谁最近, 就与它属于同一簇.
Step 3. (重新选择老大) 每个簇求虚拟中心, 将其作为老大.
Step 4. (判断是否收敛) 如果本轮的中心点与上一轮的中心点相同, 则结束; 否则转 Step 2.
注:step3中选择的为虚拟中心,即不一定刚好是数据集中真实存在的数据点;但是可以通过换成最近的点作为实际中心再聚类。
10.Naive Bayes算法原理:基于概率学的算法,基于贝叶斯定理和特征条件独立假设的分类方法。通过该公式(参考原文)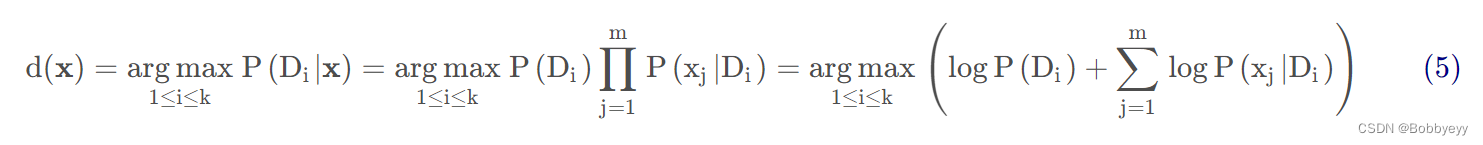
计算得出输出值,其中argmax 表示哪个类别的相对概率高, 我们就预测为该类别。